इस वर्ष की सर्दियों के अंत में, IEEE की सिग्नल प्रोसेसिंग सोसायटी - कैमरा मॉडल आइडेंटिफिकेशन प्रतियोगिता आयोजित की गई थी। मैंने मेंटर के रूप में इस टीम प्रतियोगिता में भाग लिया। टीम के निर्माण की एक वैकल्पिक विधि, निर्णय और कटौती के तहत दूसरे चरण के बारे में।
 tldr.py
tldr.pyfrom internet import yandex_fotki, flickr, wiki commons from Andres_Torrubia import Ivan_Romanov as pytorch_baseline import kaggle dataset = kaggle.data() for source in [yandex_fotki, flickr, wiki_commons]: dataset[train].append(source.download()) predicts = [] for model in [densenet201, resnext101, se_resnext50, dpn98, densenet161, resnext101 d4, se resnet50, dpn92]: with pytorch_baseline(): model.fit(dataset[train]) predicts.append(model.predict_tta(dataset[test])) kaggle.submit(gmean(predicts))
समस्या का बयानफोटोग्राफ से, उस डिवाइस को निर्धारित करना आवश्यक है जिस पर यह फोटोग्राफ प्राप्त किया गया था। डेटासेट में दस वर्गों के चित्र शामिल थे: दो आईफ़ोन, सात एंड्रॉइड स्मार्टफोन और एक कैमरा। प्रशिक्षण के नमूने में प्रत्येक कक्षा के 275 पूर्ण आकार के चित्र शामिल थे। परीक्षण के नमूने में, केवल केंद्रीय 512x512 फसल प्रस्तुत की गई थी। इसके अलावा, तीन वृद्धि में से एक को उनमें से 50 प्रतिशत पर लागू किया गया था: jpg संपीड़न, क्यूबिक प्रक्षेप, या गामा सुधार के साथ। बाहरी डेटा का उपयोग करना संभव था।
 सार (tm)
सार (tm)यदि आप सरल भाषा में कार्य को समझाने की कोशिश करते हैं, तो विचार नीचे दी गई तस्वीर में प्रस्तुत किया गया है। एक नियम के रूप में, आधुनिक तंत्रिका नेटवर्क को एक तस्वीर में वस्तुओं को भेद करने के लिए सिखाया जाता है। यानी आपको कुत्तों से बिल्लियों को अलग करना, स्विमसूट्स से पोर्नोग्राफी या सड़कों से टैंकों को सीखना आवश्यक है। उसी समय, यह हमेशा कैसे और किस डिवाइस पर एक बिल्ली और एक टैंक की तस्वीर लिया जाता है के प्रति उदासीन होना चाहिए।

एक ही प्रतियोगिता में, सब कुछ काफी विपरीत था। भले ही फोटो में क्या दिखाया गया है, आपको डिवाइस के प्रकार को निर्धारित करने की आवश्यकता है। यही है, मैट्रिक्स शोर, छवि प्रसंस्करण कलाकृतियों, ऑप्टिकल दोष, आदि जैसी चीजों का उपयोग करें। यह एक महत्वपूर्ण चुनौती थी - एक एल्गोरिथम विकसित करना जो छवियों के निम्न-स्तरीय विशेषताओं को पकड़ता है।
टीमवर्क सुविधाएँकागल टीमों का भारी बहुमत निम्नानुसार बनता है: लीडरबोर्ड पर एक निकट नेतृत्व वाले प्रतिभागियों को एक टीम में एकजुट किया जाता है, जबकि प्रत्येक व्यक्ति समाधान के अपने संस्करण को शुरू से अंत तक देख रहा है। मैंने इस तरह के भाषण के एक विशिष्ट उदाहरण के बारे में एक
पोस्ट लिखा था। हालाँकि, इस बार हम दूसरे रास्ते पर चले गए, अर्थात्: हमने निर्णय के कुछ हिस्सों को लोगों में बाँटा। इसके अलावा, प्रतियोगिता के नियमों के अनुसार, शीर्ष 3 छात्र टीमों को दूसरे चरण के लिए कनाडा का टिकट मिला। इसलिए, जब रीढ़ की हड्डी इकट्ठा हुई, तो हमने नियमों का पालन करने के लिए टीम को समझा।
निर्णयइस कार्य पर एक अच्छा परिणाम दिखाने के लिए, प्राथमिकताओं के अनुसार निम्नलिखित पहेली को इकट्ठा करना आवश्यक था:
- बाहरी डेटा ढूंढें और डाउनलोड करें। इस प्रतियोगिता को असीमित संख्या में बाहरी डेटा का उपयोग करने की अनुमति दी गई थी। और बहुत जल्दी यह स्पष्ट हो गया कि एक बड़ा बाहरी डेटासेट खींच रहा था।
- बाहरी डेटा को फ़िल्टर करें। लोग कभी-कभी संसाधित चित्र पोस्ट करते हैं, जो डिवाइस की सभी विशेषताओं को मारता है।
- विश्वसनीय स्थानीय सत्यापन योजना का उपयोग करें। चूँकि यहां तक कि एक मॉडल ने 0.98+ के क्षेत्र में सटीकता दिखाई, और परीक्षण में केवल 2k शॉट्स थे, मॉडल का चेकपॉइंट चुनना एक अलग कार्य था
- ट्रेन के मॉडल। मंच पर बहुत शक्तिशाली बेस लाइन पोस्ट की गई थी। हालांकि, एक चुटकी जादू के बिना, उन्होंने केवल चांदी की अनुमति दी।
डेटा संग्रहइस हिस्से पर
आर्थर फत्तखोव का कब्जा था। इस कार्य के लिए, बाहरी डेटा प्राप्त करना काफी आसान था, ये कुछ फ़ोन मॉडल से केवल चित्र हैं। आर्थर ने एक अजगर लिपि लिखी जिसमें लाइब्रेरी का इस्तेमाल
ब्यूटीफुल नामक एचटीएमएल पेज को आसानी से पार्स करने के लिए किया गया है। लेकिन, उदाहरण के लिए, फ़्लिकर एल्बम पृष्ठ पर, फ़ोटो के ब्लॉक गतिशील रूप से लोड किए जाते हैं, और इसके चारों ओर जाने के लिए मुझे
सेलेनियम का उपयोग करना पड़ता था, जो ब्राउज़र की कार्रवाई का अनुकरण करता था। Yandex.fotki, flickr, wiki commons से कुल 500+ GB फ़ोटो डाउनलोड की गईं।
डेटा फ़िल्टरिंगकोड के रूप में समाधान के लिए यह मेरा एकमात्र योगदान था। मैंने अभी देखा कि कच्ची तस्वीरें कैसे दिखती हैं और नियमों का एक गुच्छा बना है: 1) एक विशेष मॉडल के लिए विशिष्ट आकार 2) jpg गुणवत्ता थ्रेशोल्ड 3 से ऊपर है) मॉडल 4 के आवश्यक मेटा-टैग की उपस्थिति) सही सॉफ्टवेयर जो संसाधित किया गया था।
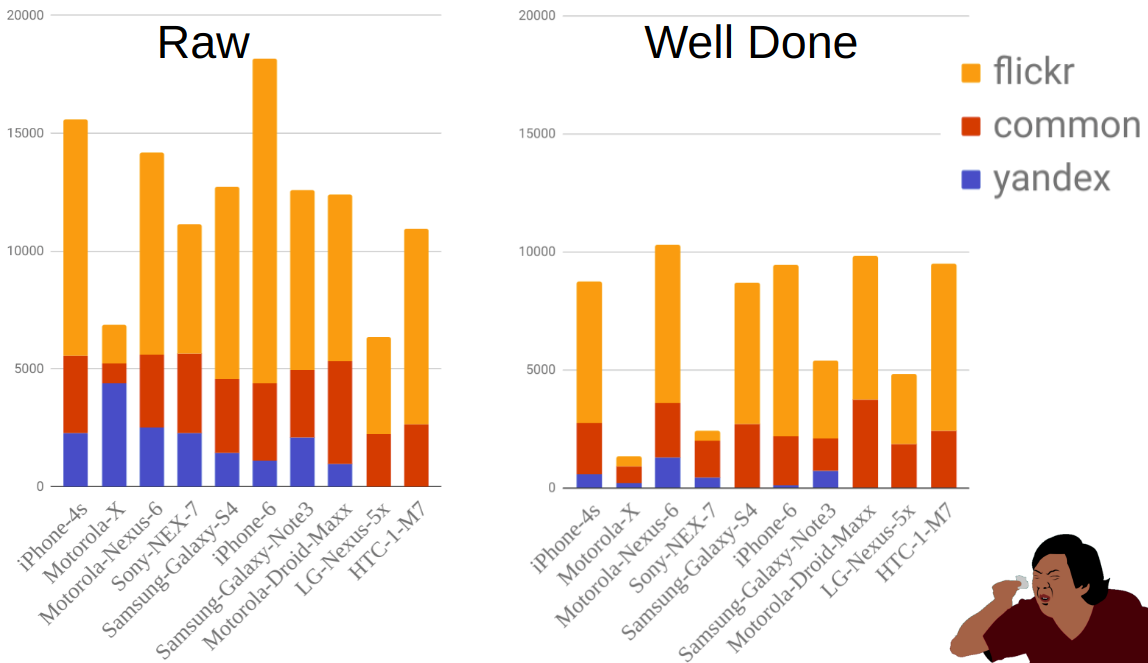
आंकड़ा फ़िल्टर करने से पहले और बाद में स्रोत और मोबाइल द्वारा तस्वीरों के वितरण को दर्शाता है। जैसा कि आप देख सकते हैं, उदाहरण के लिए, मोटो-एक्स अन्य फोन की तुलना में बहुत छोटा है। उसी समय, फ़िल्टर करने से पहले उनमें से बहुत सारे थे, लेकिन उनमें से ज्यादातर को इस तथ्य के कारण समाप्त कर दिया गया था कि इस फोन के लिए कई विकल्प हैं और मालिकों ने हमेशा मॉडल को सही ढंग से इंगित नहीं किया।
मान्यताप्रशिक्षण और सत्यापन के साथ भाग का कार्यान्वयन
इल्या किबार्डिन द्वारा किया गया था। कागल ट्रेन के एक टुकड़े पर सत्यापन बिल्कुल भी काम नहीं करता था - ग्रिड ने लगभग 1.0 सटीकता से दस्तक दी, और लीडरबोर्ड पर यह लगभग 0.96 था।
इसलिए, सत्यापन को
ग्लीब पॉसोबिन की तस्वीरें ली
गईं , जो उन्होंने फोन समीक्षा के साथ सभी साइटों से ली
थीं । इसमें एक गलती थी: iPhone 6 के बजाय एक iPhone 6+ था। हमने इसे असली आईफोन 6 से बदल दिया और कक्षाओं को संतुलित करने के लिए कागला की ट्रेन से 10% छवियों को गिरा दिया।
जब मीट्रिक सीखना निम्नानुसार माना जाता था:
- हम मान्यता से फसल के केंद्र पर क्रॉस एन्ट्रापी और akurasi मानते हैं।
- हम 8 जोड़ियों में से प्रत्येक के लिए क्रॉस एन्ट्रापी और akurasi (फसल के जोड़-तोड़ + केंद्र) पर विचार करते हैं। एक अंकगणितीय माध्य के साथ आठ जोड़तोड़ पर उन्हें प्रदान करते हैं।
- हम वजन 1 और आइटम 2 की गति को वजन 0.7 और 0.3 के साथ जोड़ते हैं।
सर्वश्रेष्ठ चौकियों को धारा 3 में प्राप्त भारित क्रॉस एन्ट्रोपी के अनुसार चुना गया था।
मॉडल प्रशिक्षणप्रतियोगिता के बीच में,
एंड्रेस टोरूबिया ने
अपने फैसले के लिए पूरे
कोड को पोस्ट किया। वह अंतिम मॉडलों की सटीकता के मामले में इतना अच्छा था कि टीमों का एक समूह लीडरबोर्ड के साथ उड़ गया। हालाँकि, वह केरस में लिखा गया था और कोड स्तर वांछित था।
स्थिति दूसरी बार बदल गई जब
इवान रोमानोव ने इस कोड
का एक
पाइटोरच संस्करण पोस्ट किया। यह तेज था, और इसके अलावा, यह आसानी से कई वीडियो कार्ड के लिए समान है। कोड स्तर, हालांकि, अभी भी बहुत अच्छा नहीं था, लेकिन यह इतना महत्वपूर्ण नहीं है।
दुख की बात यह है कि ये लोग क्रमशः 30 वें और 45 वें स्थान पर रहे, लेकिन हमारे दिलों में वे हमेशा शीर्ष पर रहे।
हमारी टीम में इल्या ने मिशा का कोड लिया और निम्नलिखित बदलाव किए।
preprocessing:- मूल चित्र से एक यादृच्छिक फसल 960x960 बनाई जाती है।
- 0.5 की संभावना के साथ, एक यादृच्छिक हेरफेर लागू किया जाता है। (यह प्रयोग किया जाता है पर निर्भर करता है, is_manip = 1 या 0 सेट है)
- एक यादृच्छिक फसल 480x480 बनाई जाती है
- दो प्रशिक्षण विकल्प थे: या तो 90 डिग्री का एक यादृच्छिक घुमाव एक विशिष्ट दिशा (मोबाइल फोन के लिए क्षैतिज / ऊर्ध्वाधर शूटिंग का अनुकरण), या डी 4 समूह का एक यादृच्छिक रूपांतरण है।
 ट्रेनिंग
ट्रेनिंगप्रशिक्षण पूरी तरह से नेटवर्क फाइनेंस द्वारा लिया गया, बिना क्लासिफायर के कंफर्टेबल लेयर्स को फ्रीज किए (हमारे पास बहुत सारा डेटा + सहजता से, वज़न जो बिल्लियों / कुत्तों के रूप में उच्च-स्तरीय ऑब्जेक्ट्स को एक्सट्रैक्ट करता है, उन्हें विस्तारित किया जा सकता है, क्योंकि हमें निम्न-स्तरीय विशेषताओं की आवश्यकता है)।
 Sheduling:
Sheduling:एडम के साथ lr = 1e-4। जब सत्यापन की हानि 2-3 अवधि के दौरान सुधार करना बंद कर देती है, तो हम एलआर को आधे से कम कर देते हैं। तो अभिसार करने के लिए। एडम को SGD से बदलें और 1e-3 से 1e-6 तक एक चक्रीय lr के साथ तीन चक्र सीखें।
अंतिम पहनावा:मैंने इल्या को पिछली प्रतियोगिता से अपने दृष्टिकोण को लागू करने के लिए कहा। फिलाडल पहनावा के लिए, हमने 9 मॉडलों को प्रशिक्षित किया, प्रत्येक से हमने 3 सर्वश्रेष्ठ चौकियों का चयन किया, प्रत्येक चेकपॉइंट को टीटीए के साथ भविष्यवाणी की गई और अंतिम में सभी भविष्यवाणियां ज्यामितीय माध्य से औसतन हुईं।
 पहले चरण के बाद
पहले चरण के बादपरिणामस्वरूप, हमने लीडरबोर्ड पर दूसरा स्थान और छात्र टीमों के बीच पहला स्थान लिया। और इसका मतलब यह है कि हमें इस प्रतियोगिता के दूसरे चरण के रूप में कनाडा में
2018 IEEE इंटरनेशनल कॉन्फ्रेंस ऑन एकाउटिक्स, स्पीच एंड सिग्नल प्रोसेसिंग के हिस्से के रूप में मिला। उल्लेखनीय में से, तीसरा स्थान लेने वाली टीम भी औपचारिक रूप से छात्र थी। यदि हम गति की गणना करते हैं, तो यह पता चलता है कि हम सही ढंग से भविष्यवाणी की गई तस्वीर के साथ इसके चारों ओर गए थे।
फाइनल IEEE सिग्नल प्रोसेसिंग कप 2018हमें सभी पुष्टिकरण प्राप्त होने के बाद, मैं, वालेरी और एंड्री ने दूसरे चरण के लिए कनाडा नहीं जाने का फैसला किया। इल्या और आर्थर एफ ने जाने का फैसला किया, उन्होंने सब कुछ व्यवस्थित करना शुरू कर दिया और उन्हें वीजा नहीं दिया गया। रूस के सबसे मजबूत वैज्ञानिकों के उत्पीड़न पर एक अंतरराष्ट्रीय घोटाले से बचने के लिए, ऑर्गेज को दूर से भाग लेने की अनुमति दी गई थी।
समयरेखा इस प्रकार थी:
03.03 - ट्रेन का डेटा दिया गया
04.09 - जारी किया गया परीक्षण डेटा
12.04 - हमें दूरस्थ रूप से भाग लेने की अनुमति दी गई थी
13.04 - हमने यह देखना शुरू किया कि डेटा के साथ क्या है
04/16 - अंतिम
दूसरे चरण की विशेषताएंदूसरे चरण में कोई लीडरबोर्ड नहीं था: बहुत अंत में केवल एक जमा भेजना आवश्यक था। यही है, यहां तक कि भविष्यवाणियों के प्रारूप को भी सत्यापित नहीं किया जा सकता है। इसके अलावा, कैमरा मॉडल ज्ञात नहीं थे। और इसका मतलब है एक ही बार में दो फाइलें: यह बाहरी डेटा का उपयोग करके काम नहीं करेगा और स्थानीय सत्यापन बहुत अप्रमाणित हो सकता है।
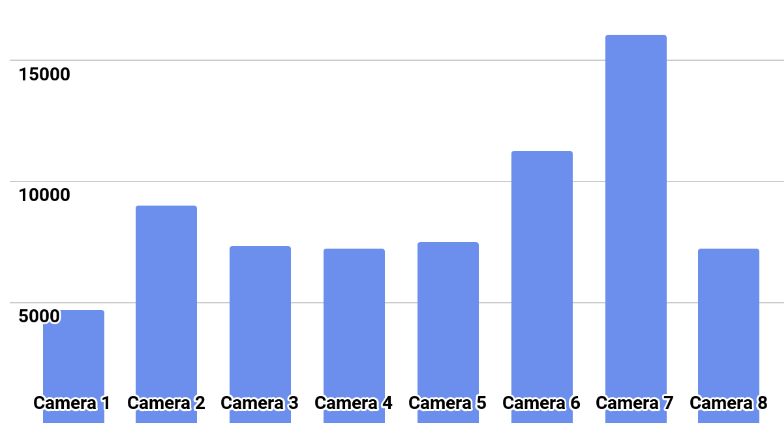
कक्षा वितरण चित्र में दिखाया गया है।
निर्णयहमने पहले चरण से सर्वश्रेष्ठ मॉडल के तराजू से एक योजना के साथ मॉडल को प्रशिक्षित करने की कोशिश की। सभी मॉडलों ने अपने सिलवटों पर 0.97+ सटीकता से प्रशिक्षण दिया, लेकिन परीक्षण में उन्होंने 0.87 के क्षेत्र में भविष्यवाणियों का प्रतिच्छेदन दिया।
मैंने हार्ड ओवरफिट के रूप में क्या व्याख्या की। इसलिए, उन्होंने एक नई योजना प्रस्तावित की:
- हम फीचर एक्सट्रैक्टर्स के रूप में पहले चरण के अपने सर्वश्रेष्ठ मॉडल लेते हैं।
- हम पीसीए को निकाले गए फीचर्स से लेते हैं ताकि रात भर सब कुछ सीखे।
- लर्निंग लाइट जीबीएम।

यहाँ तर्क इस प्रकार है। तंत्रिका नेटवर्क पहले से ही सेंसर, प्रकाशिकी, डेमो एल्गोरिदम की निम्न-स्तरीय विशेषताओं को निकालने के लिए प्रशिक्षित होते हैं, और एक ही समय में संदर्भ से चिपके नहीं होते हैं। इसके अलावा, अंतिम क्लासिफायर (वास्तव में, लॉजिस्टिक रिग्रेशन) से पहले निकाले गए फीचर एक जोरदार गैर-रेखीय परिवर्तन का परिणाम हैं। इसलिए, कोई व्यक्ति कुछ सरल सिखा सकता है, न कि पीछे हटने का खतरा, जैसे कि लॉजिस्टिक रिग्रेशन। हालांकि, चूंकि नया डेटा पहले चरण के डेटा से बहुत अलग हो सकता है, इसलिए गैर-रैखिक को प्रशिक्षित करने के लिए अभी भी बेहतर है, उदाहरण के लिए, निर्णय के पेड़ों पर ढाल को बढ़ावा देना। मैंने कई प्रतियोगिताओं में इस दृष्टिकोण का उपयोग किया, जहां मैंने कोड पोस्ट किया।
चूंकि एक जमा था, मेरे पास अपने दृष्टिकोण का परीक्षण करने का कोई विश्वसनीय तरीका नहीं है। हालाँकि, DenseNet सबसे अच्छा फीचर निकालने वाला साबित हुआ। Resnext और SE-Resnext नेटवर्क ने स्थानीय सत्यापन पर कम प्रदर्शन दिखाया। इसलिए, अंतिम निर्णय इस तरह से देखा गया।
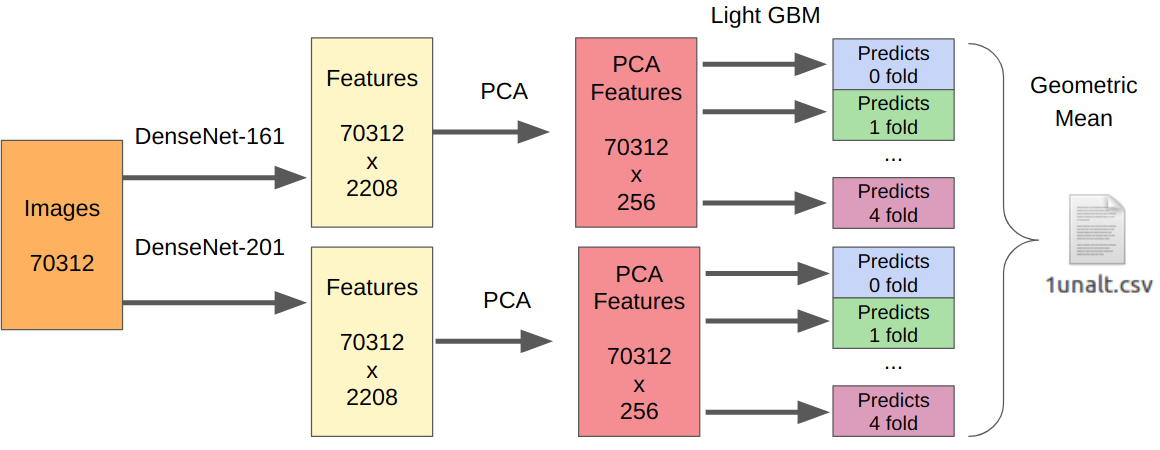
जोड़तोड़ के साथ भाग के लिए, सभी प्रशिक्षण नमूनों की संख्या को 7 से गुणा करने की आवश्यकता है, क्योंकि मैंने प्रत्येक हेरफेर से सुविधाओं को अलग से निकाला है।
अंतभाषणनतीजतन, अंतिम चरण में हमने दूसरा स्थान लिया, लेकिन कई आरक्षण हैं। शुरू करने के लिए, एल्गोरिथम की सटीकता के अनुसार जगह नहीं दी गई थी, लेकिन जूरी की प्रस्तुति के अनुमान के अनुसार। टीम, जिसे पहले स्थान से सम्मानित किया गया था, ने न केवल एक पूर्वग्रह बनाया, बल्कि उनके एल्गोरिदम के काम के साथ एक लाइव डेमो भी किया। खैर, हम अभी भी प्रत्येक टीम की अंतिम गति को नहीं जानते हैं, और प्रत्यक्ष प्रश्नों के बाद भी ऑर्ग्स उन्हें पत्राचार में प्रकट नहीं करते हैं।
मजेदार चीजों में से: पहले चरण में, हमारे समुदाय की सभी टीमों ने टीम के नाम [ओडेसाई] में संकेत दिया और लीडरबोर्ड पर काफी शक्तिशाली कब्जा कर लिया। उसके बाद,
उलटा और गिबा जैसे किगल किंवदंतियों ने हमारे साथ जुड़ने का फैसला किया कि हम यहां क्या कर रहे थे।

मैंने वास्तव में एक संरक्षक के रूप में भाग लेने का आनंद लिया। पिछली प्रतियोगिताओं में भाग लेने के अनुभव के आधार पर, मैं बेसलाइन में सुधार करने के साथ-साथ स्थानीय सत्यापन के निर्माण पर कई मूल्यवान सुझाव देने में सक्षम था। भविष्य में, इस तरह का प्रारूप मामला होने से अधिक होगा: कोड लिखने और परिकल्पनाओं के परीक्षण के लिए समाधान + 2-3 केगल एक्सपर्ट के वास्तुकार के रूप में केगल मास्टर / ग्रैंडमास्टर। मेरी राय में, यह शुद्ध जीत-जीत है, क्योंकि अनुभवी प्रतिभागी पहले से ही कोड लिखने के लिए बहुत आलसी हैं और शायद इतना समय नहीं है, और शुरुआती को बेहतर परिणाम मिलता है, अनुभवहीनता द्वारा केले की गलतियां न करें और अनुभव भी तेजी से प्राप्त करें।
→
हमारे समाधान का कोड→
ML वर्कआउट के साथ रिकॉर्डिंग का प्रदर्शन