मैंने खुद के लिए ध्यान दिया कि मैं लगातार सभी प्रकार की छोटी चीजों, उपयोगी जानकारी को लिखता हूं, सिर्फ क्लिपबोर्ड से सीधे पाठ संपादक में कुछ। पृष्ठभूमि में हमेशा कहीं न कहीं एक खुला उदात्त पाठ होता है जिसमें टैब लटका हुआ होता है।
और मैंने यह भी देखा कि मार्कडाउन सिंटैक्स का उपयोग करके एक फ़ाइल में जानकारी की संरचना करना मेरे लिए सबसे सुविधाजनक है - यह स्रोत पाठ की तुलना में अधिक सुखद है, और एक ही गीथब पर प्रदर्शित परिणाम नहीं है।
समय के साथ, मैंने देखा कि इस तरह की बहुत सारी सहेजी गई फाइलें थीं, और खुले टैब घटने वाले नहीं हैं। लेकिन एक लापरवाह आंदोलन और सभी सहेजे गए संचित जानकारी गुम हो जाएगी, और आप अन्य उपकरणों से भी नहीं देखेंगे, और डैडीज़ को बिखेरना भी बहुत सुविधाजनक नहीं है।
इस सबने मुझे एक जगह और एक सुविधाजनक रूप में सभी जानकारी संग्रहीत करने के लिए अपने स्वयं के इंजन की तरह कुछ लिखने के लिए प्रेरित किया। हां, हां, एवरनोट के सभी प्रकार का एक गुच्छा है, कुछ नोट्स जो मैकओएस / आईओएस में बनाया गया है और इस तरह दोनों में सिंक्रोनाइज़ेशन और फीचर उपयोगी हैं - लेकिन जैसा कि वे कहते हैं, आप कुछ अच्छा करना चाहते हैं (अपने लिए), इसे करें खुद को। और, लगभग किसी भी प्रोग्रामर की तरह, किसी भी असंगत स्थिति में मैं खुद सब कुछ लेता और लिखता हूं। तो इस बार ऐसा ही हुआ।
क्यों?
इसी तरह की परियोजनाएं पहले से मौजूद हैं, और उपर्युक्त राक्षस सेवाएं भी काफी सुविधाजनक हैं, लेकिन मेरी परियोजना में उनकी कुछ विशेषताएं कुछ फायदे प्रदान करती हैं।
सबसे पहले, यह परियोजना के लिए प्रलेखन के रूप में इसका उपयोग करने के लिए सबसे सुविधाजनक है (वास्तव में, प्रेरणा कोटलिन पर प्रलेखन के साथ साइट से आई थी, जहां से मैंने उत्पन्न सामग्री के लिए अधिकांश शैलियों को उधार लिया था)।
परियोजना पूरी तरह से स्वतंत्र है और सार्वजनिक डोमेन में है, लेख के अंत में गिटब का लिंक।
क्या कर सकते हैं?
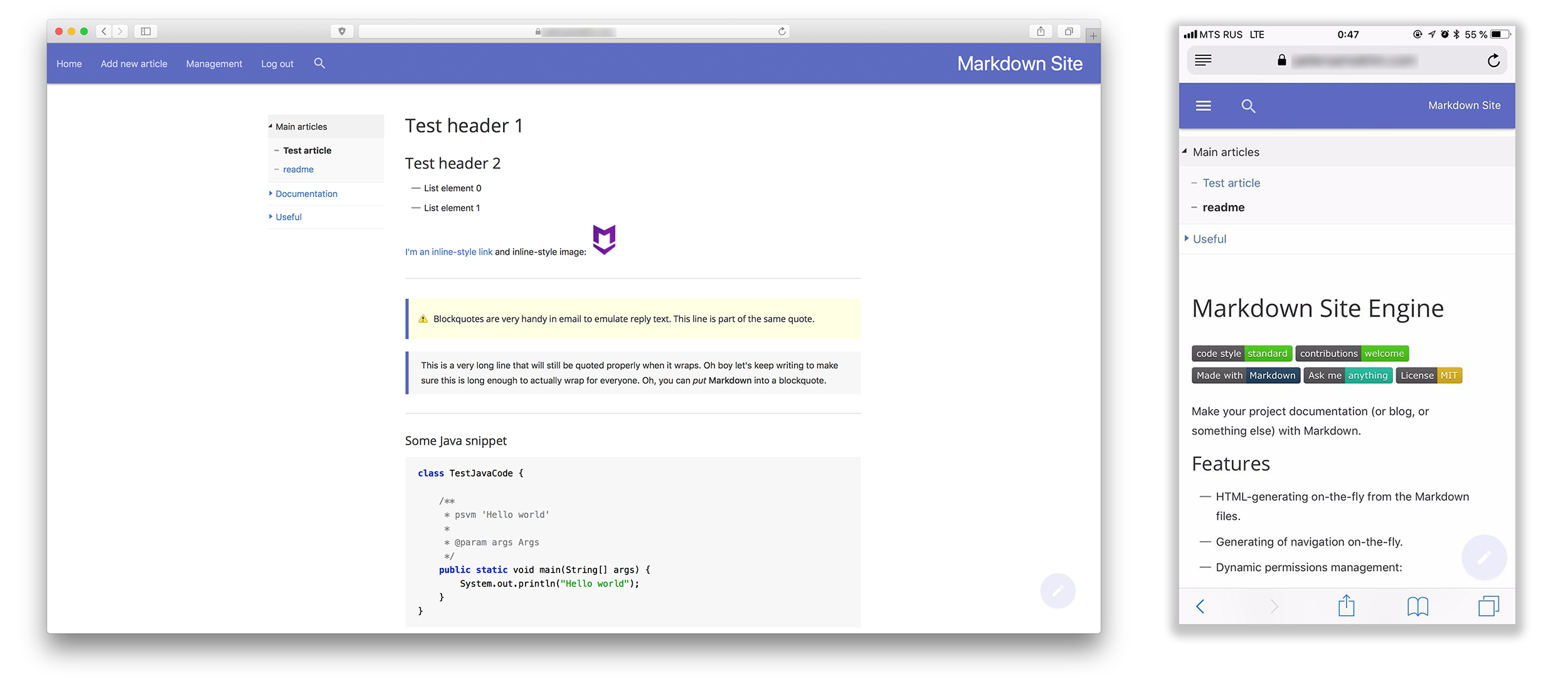
- मक्खी पर HTML पीढ़ी - परिणाम सहेजा नहीं गया है। तैयार किए गए लेख पूरे फ़ोल्डर में वांछित परियोजना निर्देशिका में कॉपी किए जा सकते हैं। सभी जोड़े गए और हटाए गए फ़ाइलों को स्वचालित रूप से अनुक्रमित किया जाता है।
- नेविगेशन भी उत्पन्न होता है, हार्डकोड नहीं।
- सामग्री द्वारा खोजें।
- अभिगम नियंत्रण - यह जीथूब पर संगठनों के लिए लगभग "समूहों" की तरह काम करता है: प्रत्येक समूह (मैंने उनकी भूमिका का नाम दिया है) के पास उपयोगकर्ताओं की एक सूची और फ़ोल्डर / फ़ाइलों के लिए पथों की एक सूची है जो इस समूह के उपयोगकर्ता देख सकते हैं।
- खोज करते समय, नेविगेशन में, आदि। उपयोगकर्ता उन पृष्ठों को नहीं देखेगा जिनके पास उसकी पहुंच नहीं है।
- लेखों को एक दृश्य संपादक में भी जोड़ा जा सकता है (इसमें सिंटैक्स हाइलाइटिंग है, जीथब पर बटन, पूर्वावलोकन, आदि)
- सेटिंग्स पेज के माध्यम से सब कुछ आसानी से कॉन्फ़िगर किया गया है, जो भी उत्पन्न होता है (और आप कठिनाई के बिना नए आइटम जोड़ सकते हैं)। कुल - आप प्रोजेक्ट को स्थानीय रूप से आदेशों के एक जोड़े में स्थापित कर सकते हैं, समाप्त मार्कडाउन फ़ाइलों को अपने डैडी में ड्रॉप कर सकते हैं, जल्दी से एक्सेस और उपयोग को कॉन्फ़िगर कर सकते हैं।
- अन्य छोटे चिप्स का एक गुच्छा, जैसे सभी हेडर के लिए लंगर लिंक, कोड के साथ स्निपेट पर कॉपी करने के लिए बटन, आदि। आदि
यह कैसे काम करता है?
किस पर?
मैंने NodeJS और express उपयोग किया, क्योंकि मेरे लिए यह स्टैक इस विशेष कार्य को लागू करने के लिए सबसे कम समय लगता था।
पहुँच अधिकार
तर्क बहुत सरल है - passport प्राधिकरण के साथ सभी समस्याओं को हल करता है। उपयोगकर्ताओं और लेखों के लिए अधिकार MongoDB में संग्रहीत हैं, और लेखों के पथ डिस्क पर फ़ाइलों के पथ के अनुरूप हैं।
"समूह" स्वयं कहीं भी संग्रहीत नहीं हैं, नियंत्रण "नीचे से" होता है: प्रत्येक उपयोगकर्ता और पथ (लेख या श्रेणी के लिए - यानी फ़ाइल और फ़ोल्डर में) "भूमिकाओं" की अपनी सूची है। यदि कोई उपयोगकर्ता जिस मार्ग का अनुसरण करता है, उसकी सूची से कम से कम एक "भूमिका" होती है, तो माना जाता है कि उसकी पहुंच है। किसी भी मार्ग को देखने के लिए, उपयोगकर्ता के पास स्वयं और सभी माता-पिता के लिए पथ का उपयोग होना चाहिए: उदाहरण के लिए, पृष्ठ /pages/Documentation/Habr , आपके पास /pages , /pages/Documentation और /pages/Documentation/Habr तक पहुंच होनी चाहिए।
यदि उपयोगकर्ता पृष्ठ देख सकता है, तो हम डिस्क पर फ़ाइल को चालू करते हैं, इसकी सामग्री पढ़ते हैं और इसे प्रदर्शित करते हैं।
सामग्री
रूपांतरण के लिए, Ruby लिए एक पुस्तकालय Ruby , जिसे kramdown कहा जाता है - इसकी सभी विशेषताएं भी समर्थित हैं।
HTML उत्पन्न करने के बाद, मार्कअप को तैयार किए गए टेम्प्लेट में एम्बेड किया जाता है, जहां उत्पन्न नेविगेशन भी एम्बेडेड होता है।
नेविगेशन की पीढ़ी काफी सरलता से काम करती है - पुनरावर्ती रूप से आपको सभी फ़ाइलों और फ़ोल्डरों की पूरी सूची मिलती है, फिर उन्हें उपयोगकर्ता अधिकारों द्वारा फ़िल्टर किया जाता है, और परिणामी संरचना टेम्पलेट में "संलग्न" होती है।
खोज उसी तरह काम करती है।
डिजाइन के लिए, मैंने खुद लेखों के लिए कोटलिन प्रलेखन स्थल से materialize उपयोग किया, शैली का उपयोग किया, जीथब पर संपादक से विचार लिया, आदि।
→ सोर्स कोड यहां उपलब्ध है।
मैं NodeJS नहीं NodeJS - या एक बैकएंड डेवलपर, लेकिन मुझे कुछ दिलचस्प से विचलित होना पसंद है। मैंने लेख इसलिए लिखा क्योंकि मुझे लगा कि वह चीज़ काफी उपयोगी है।
हां, एक ही विचार के साथ एनालॉग हैं (ईमानदार होने के लिए, मुझे विकास के बाद पता चला) - लेकिन उनके पास ऊपर वर्णित कई विशेषताएं नहीं हैं (और यहां वर्णित नहीं है), और कार्यान्वयन अधिक जटिल दिखता है: एक ही प्रलेखन साइट कोटलिन हार्डकवर नेविगेशन, अतिरिक्त सुविधाओं को निष्पादित करने का तरीका जानता है। कोड और, ऐसा लगता है, सब कुछ - हालांकि परियोजना ही बड़ी है।
PS मुझे Habr के नियमों का उल्लंघन नहीं लगता है, और लेख में जीथब के लिंक के अलावा एक सामान्य विवरण नहीं है। यदि अचानक लोग रुचि दिखाते हैं, तो मैं संपूर्ण विकास प्रक्रिया या विशिष्ट बिंदुओं के विस्तृत विवरण के साथ लेखों की एक श्रृंखला लिख सकता हूं - क्योंकि यह संभावना नहीं है कि हम यहां एक लेख से दूर हो सकते हैं।