 एआई अनुवाद बिल्लियों की तस्वीरें कैसे उत्पन्न कर सकता है
एआई अनुवाद बिल्लियों की तस्वीरें कैसे उत्पन्न कर सकता है ।
2014 में प्रकाशित जेनेरिक
एडवरसैरियल नेट्स (GAN) शोध, जेनेरेटिव मॉडल के क्षेत्र में एक सफलता थी। लीड रिसर्चर यान लेकन ने एडवरसरी नेट को "पिछले बीस वर्षों में मशीन सीखने का सबसे अच्छा विचार" कहा। आज, इस वास्तुकला के लिए धन्यवाद, हम एक एआई बना सकते हैं जो बिल्लियों की यथार्थवादी छवियों को उत्पन्न करता है। वापस कूल!
 प्रशिक्षण के दौरान DCGAN
प्रशिक्षण के दौरान DCGANसभी वर्किंग कोड
जीथब रिपॉजिटरी में है । यदि आपके पास पायथन प्रोग्रामिंग, गहन शिक्षा, टेन्सरफ्लो के साथ काम करना और दृढ़ तंत्रिका नेटवर्क के साथ कोई अनुभव है, तो यह आपके लिए उपयोगी होगा।
और अगर आप गहरी सीखने के लिए नए हैं, तो मैं सुझाव देता हूं कि आप अपने आप को लेखों की उत्कृष्ट श्रृंखला से परिचित करें
मशीन लर्निंग फन है!DCGAN क्या है?
डीप कॉन्सटेक्शनल जेनरेटिव एडवरसियर नेटवर्क्स (DCGAN) एक डीप लर्निंग आर्किटेक्चर है जो ट्रेनिंग सेट से डेटा के समान डेटा जेनरेट करता है।
यह मॉडल पूरी तरह से जेनरल एडवरसैरियल नेटवर्क की कनेक्टेड लेयर्स को कंफ्यूजियल लेयर्स से बदल देता है। यह समझने के लिए कि DCGAN कैसे काम करता है, हम एक विशेषज्ञ कला समीक्षक और एक झूठा व्यक्ति के बीच टकराव के रूपक का उपयोग करते हैं।
फर्जी ("जनरेटर") एक नकली वान गाग चित्र बनाने और इसे एक वास्तविक के रूप में बंद करने की कोशिश कर रहा है।
एक कला समीक्षक ("विभेदक") वान गाग के वास्तविक कैनवस के अपने ज्ञान का उपयोग करते हुए, एक अपराधी को दोषी ठहराने की कोशिश कर रहा है।
समय के साथ, कला समीक्षक तेजी से नकली परिभाषित कर रहे हैं, और मिथ्यावादी उन्हें और अधिक परिपूर्ण बनाते हैं।
 जैसा कि आप देख सकते हैं, DCGAN दो अलग-अलग गहरे सीखने वाले तंत्रिका नेटवर्क से बने होते हैं जो एक दूसरे से प्रतिस्पर्धा करते हैं।
जैसा कि आप देख सकते हैं, DCGAN दो अलग-अलग गहरे सीखने वाले तंत्रिका नेटवर्क से बने होते हैं जो एक दूसरे से प्रतिस्पर्धा करते हैं।- जेनरेटर विश्वसनीय डेटा बनाने की कोशिश कर रहा है। वह नहीं जानता कि वास्तविक डेटा क्या है, लेकिन वह दुश्मन के तंत्रिका नेटवर्क की प्रतिक्रियाओं से सीखता है, प्रत्येक पुनरावृत्ति के साथ अपने काम के परिणामों को बदल रहा है।
- भेदभाव करने वाला नकली डेटा (वास्तविक लोगों के साथ तुलना) का निर्धारण करने की कोशिश करता है, ताकि वास्तविक डेटा के संबंध में झूठी सकारात्मक चीजों से बचा जा सके। इस मॉडल का परिणाम जनरेटर के लिए प्रतिक्रिया है।
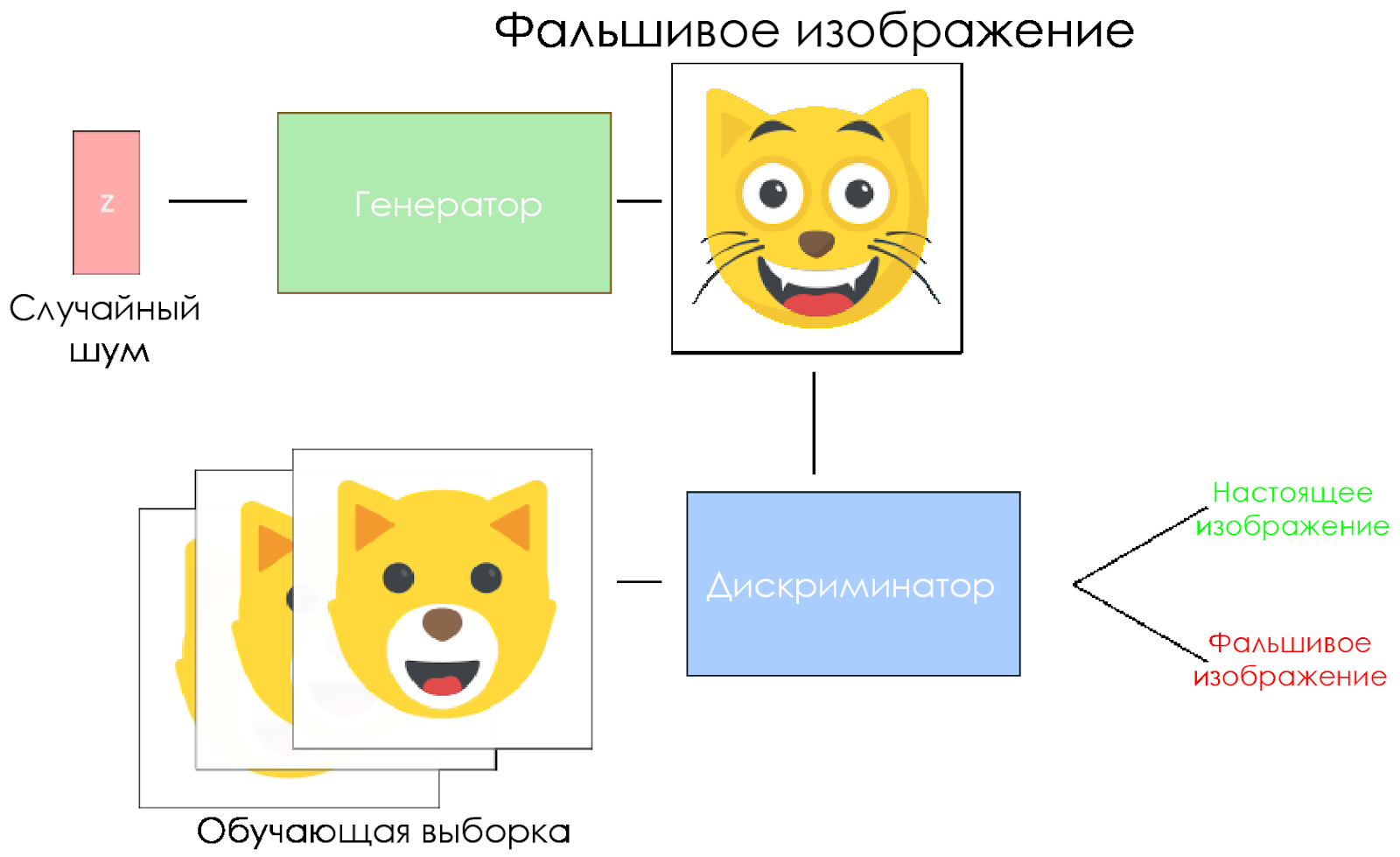 DCGAN स्कीमा।
DCGAN स्कीमा।- जनरेटर एक यादृच्छिक शोर वेक्टर लेता है और एक छवि उत्पन्न करता है।
- छवि को विवेचक को दिया जाता है, वह इसकी तुलना प्रशिक्षण नमूने से करता है।
- भेदभाव करने वाला एक नंबर देता है - 0 (नकली) या 1 (वास्तविक छवि)।
चलो एक DCGAN बनाएँ!
अब हम अपना AI बनाने के लिए तैयार हैं।
इस भाग में, हम अपने मॉडल के मुख्य घटकों पर ध्यान केंद्रित करेंगे। यदि आप पूरा कोड देखना चाहते हैं, तो
यहां जाएं ।
इनपुट डेटा
इनपुट के लिए स्टब्स बनाएं:
inputs_real लिए
inputs_z और
inputs_z लिए। कृपया ध्यान दें कि हमारे पास जनरेटर और भेदभाव के लिए अलग से दो सीखने की दरें होंगी।
DCGAN हाइपरपैरामीटर के प्रति बहुत संवेदनशील हैं, इसलिए उन्हें ठीक करने के लिए यह बहुत महत्वपूर्ण है।
def model_inputs(real_dim, z_dim): """ Create the model inputs :param real_dim: tuple containing width, height and channels :param z_dim: The dimension of Z :return: Tuple of (tensor of real input images, tensor of z data, learning rate G, learning rate D) """
भेदभाव करनेवाला और जनरेटर
हम दो कारणों से
tf.variable_scope उपयोग करते हैं।
सबसे पहले, यह सुनिश्चित करने के लिए कि सभी चर नाम जनरेटर / विवेचक के साथ शुरू होते हैं। बाद में यह हमें दो तंत्रिका नेटवर्क के प्रशिक्षण में मदद करेगा।
दूसरे, हम अलग-अलग इनपुट डेटा वाले इन नेटवर्कों का फिर से उपयोग करेंगे:
- हम जनरेटर को प्रशिक्षित करेंगे, और फिर इसके द्वारा उत्पन्न छवियों का एक नमूना लेंगे।
- भेदभाव करने वाले में, हम नकली और वास्तविक इनपुट छवियों के लिए चर साझा करेंगे।

चलो एक भेदभाव पैदा करते हैं। याद रखें कि इनपुट के रूप में, यह एक वास्तविक या नकली छवि लेता है और प्रतिक्रिया में 0 या 1 देता है।
कुछ नोट:
- हमें प्रत्येक दृढ़ परत में फ़िल्टर आकार को दोगुना करने की आवश्यकता है।
- डाउनसमलिंग का उपयोग करने की अनुशंसा नहीं की जाती है। इसके बजाय, केवल छीन दी गई परतें लागू होती हैं।
- प्रत्येक परत में, हम बैच सामान्यीकरण (इनपुट परत के अपवाद के साथ) का उपयोग करते हैं, क्योंकि यह कोवरियन शिफ्ट को कम करता है। इस अद्भुत लेख में और पढ़ें।
- हम एक सक्रियण समारोह के रूप में लीक रेलु का उपयोग करेंगे, यह "गायब" प्रवणता के प्रभाव से बचने में मदद करेगा।
def discriminator(x, is_reuse=False, alpha = 0.2): ''' Build the discriminator network. Arguments --------- x : Input tensor for the discriminator n_units: Number of units in hidden layer reuse : Reuse the variables with tf.variable_scope alpha : leak parameter for leaky ReLU Returns ------- out, logits: ''' with tf.variable_scope("discriminator", reuse = is_reuse):
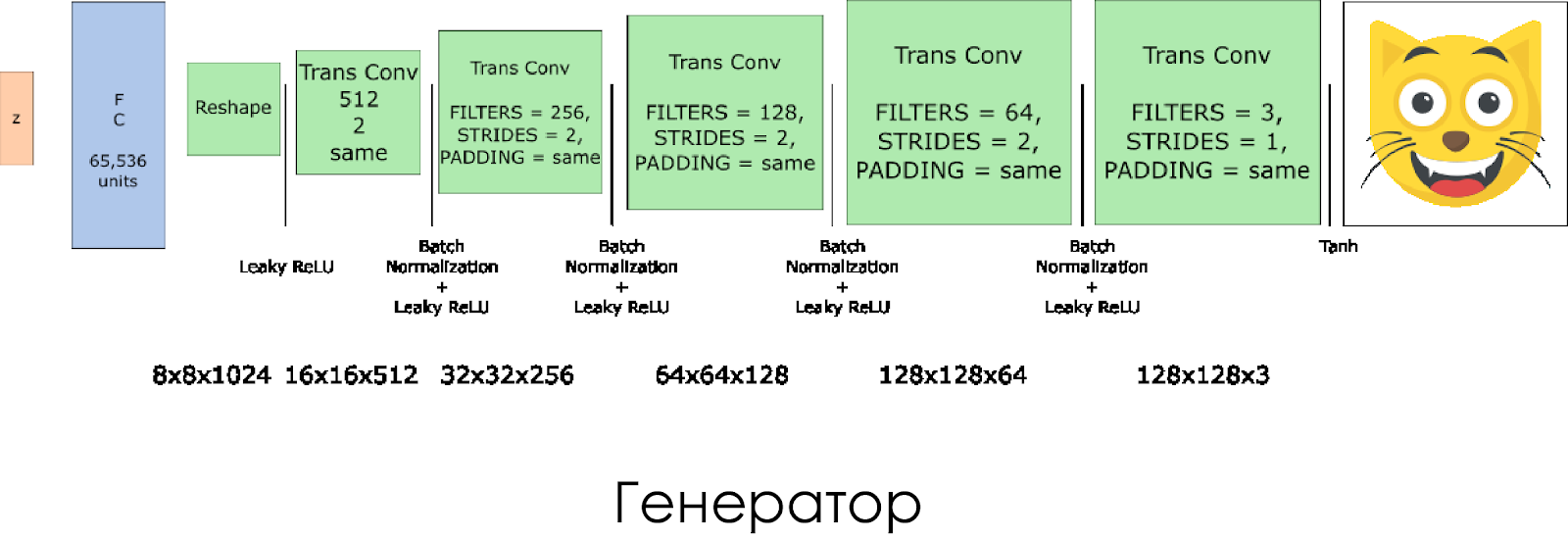
हमने एक जनरेटर बनाया है। याद रखें कि यह इनपुट के रूप में शोर वेक्टर (जेड) लेता है और, ट्रांसपोज़्ड कनवल्शन लेयर के लिए धन्यवाद, एक नकली छवि बनाता है।
प्रत्येक परत पर, हम फिल्टर के आकार को आधा कर देते हैं, और छवि के आकार को भी दोगुना कर देते हैं।
आउटपुट सक्रियण फ़ंक्शन के रूप में
tanh का उपयोग करते समय जनरेटर सबसे अच्छा काम करता है।
def generator(z, output_channel_dim, is_train=True): ''' Build the generator network. Arguments --------- z : Input tensor for the generator output_channel_dim : Shape of the generator output n_units : Number of units in hidden layer reuse : Reuse the variables with tf.variable_scope alpha : leak parameter for leaky ReLU Returns ------- out: ''' with tf.variable_scope("generator", reuse= not is_train):
विवेचक और जनरेटर में हानि
चूंकि हम जनरेटर और भेदभाव दोनों को प्रशिक्षित करते हैं, इसलिए हमें दोनों तंत्रिका नेटवर्क के लिए नुकसान की गणना करने की आवश्यकता है। विवेचक को 1 देना चाहिए जब वह छवि को "वास्तविक" मानता है, और यदि छवि नकली है, तो 0। इसके अनुसार और आपको नुकसान को कॉन्फ़िगर करने की आवश्यकता है। भेदभावपूर्ण नुकसान की गणना वास्तविक और नकली छवि के नुकसान के योग के रूप में की जाती है:
d_loss = d_loss_real + d_loss_fakeजहां
d_loss_real नुकसान होता है जब भेदभाव करने वाला छवि को गलत मानता है, लेकिन वास्तव में यह वास्तविक है। इसकी गणना इस प्रकार है:
- हम
d_logits_real उपयोग d_logits_real , सभी लेबल 1 के बराबर हैं (क्योंकि सभी डेटा वास्तविक हैं)। labels = tf.ones_like(tensor) * (1 - smooth) । चलो लेबल चौरसाई का उपयोग करें: भेदभाव को सामान्य बनाने में मदद करने के लिए लेबल मान को 1.0 से 0.9 तक कम करें।
d_loss_fake एक नुकसान है जब भेदभाव करने वाला छवि को वास्तविक मानता है, लेकिन वास्तव में यह नकली है।
- हम
d_logits_fake उपयोग d_logits_fake , सभी लेबल 0 हैं।
जनरेटर को खोने के लिए,
d_logits_fake से
d_logits_fake का उपयोग किया जाता है। इस बार, सभी लेबल 1 हैं, क्योंकि जनरेटर विवेचक को चकमा देना चाहता है।
def model_loss(input_real, input_z, output_channel_dim, alpha): """ Get the loss for the discriminator and generator :param input_real: Images from the real dataset :param input_z: Z input :param out_channel_dim: The number of channels in the output image :return: A tuple of (discriminator loss, generator loss) """
optimizers
नुकसान की गणना के बाद, जनरेटर और भेदभावकर्ता को व्यक्तिगत रूप से अपडेट किया जाना चाहिए। ऐसा करने के लिए, हमारे ग्राफ़ में परिभाषित सभी चर की सूची बनाने के लिए
tf.trainable_variables() उपयोग करें।
def model_optimizers(d_loss, g_loss, lr_D, lr_G, beta1): """ Get optimization operations :param d_loss: Discriminator loss Tensor :param g_loss: Generator loss Tensor :param learning_rate: Learning Rate Placeholder :param beta1: The exponential decay rate for the 1st moment in the optimizer :return: A tuple of (discriminator training operation, generator training operation) """
ट्रेनिंग
अब हम प्रशिक्षण समारोह को लागू करते हैं। यह विचार बहुत सरल है:
- हम अपने मॉडल को हर पांच अवधि (युग) में सहेजते हैं।
- हम प्रत्येक 10 प्रशिक्षित बैचों के साथ चित्र में फ़ोल्डर में चित्र को सहेजते हैं।
- हर 15 अवधि में हम
g_loss , d_loss और उत्पन्न छवि प्रदर्शित करते हैं। ऐसा इसलिए है क्योंकि बहुत अधिक चित्रों को प्रदर्शित करने पर जुपिटर नोटबुक दुर्घटनाग्रस्त हो सकती है। - या हम सीधे सहेजे गए मॉडल को लोड करके वास्तविक चित्र उत्पन्न कर सकते हैं (यह 20 घंटे के प्रशिक्षण को बचाएगा)।
def train(epoch_count, batch_size, z_dim, learning_rate_D, learning_rate_G, beta1, get_batches, data_shape, data_image_mode, alpha): """ Train the GAN :param epoch_count: Number of epochs :param batch_size: Batch Size :param z_dim: Z dimension :param learning_rate: Learning Rate :param beta1: The exponential decay rate for the 1st moment in the optimizer :param get_batches: Function to get batches :param data_shape: Shape of the data :param data_image_mode: The image mode to use for images ("RGB" or "L") """
कैसे चलाना है?
यह सब आपके कंप्यूटर पर सही तरीके से चलाया जा सकता है, यदि आप 10 साल इंतजार करने के लिए तैयार हैं। व्यक्तिगत रूप से, मैंने इस DCGAN को Microsoft Azure और उनके
डीप लर्निंग वर्चुअल मशीन पर 20 घंटे के लिए प्रशिक्षित किया। मेरा Azure के साथ कोई व्यावसायिक संबंध नहीं है, मुझे उनकी ग्राहक सेवा पसंद है।
यदि आपको वर्चुअल मशीन चलाने में कोई कठिनाई है, तो इस अद्भुत
लेख को देखें ।
यदि आप मॉडल में सुधार करते हैं, तो एक निवेदन करने के लिए स्वतंत्र महसूस करें।
