
C ++ के संदर्भ में "पैटर्न" आमतौर पर बहुत विशिष्ट भाषा निर्माणों को संदर्भित करता है। सरल टेम्पलेट हैं जो एक ही प्रकार के कोड के साथ काम करना सरल करते हैं - ये वर्ग और फ़ंक्शन टेम्पलेट हैं। यदि किसी टेम्प्लेट में पैरामीटर अपने आप में से एक है, तो यह दूसरे क्रम के टेम्पलेट कहे जा सकते हैं और वे अपने मापदंडों के आधार पर अन्य टेम्प्लेट उत्पन्न करते हैं। लेकिन क्या होगा अगर उनकी क्षमताएं स्रोत पाठ को तुरंत उत्पन्न करने के लिए पर्याप्त और आसान न हों? स्रोत कोड के बहुत सारे?
जिनज 2 नामक टेक्स्ट टेम्प्लेट के साथ काम करने के लिए पायथन और एचटीएमएल-लेआउट के प्रशंसक उपकरण (इंजन, लाइब्रेरी) से
परिचित हैं । इनपुट पर, यह इंजन एक टेम्प्लेट फ़ाइल प्राप्त करता है जिसमें पाठ को नियंत्रण संरचनाओं के साथ मिलाया जा सकता है, आउटपुट स्पष्ट पाठ होता है जिसमें सभी नियंत्रण संरचनाओं को पाठ के साथ बाहर (या अंदर से निर्दिष्ट) मापदंडों के अनुसार बदल दिया जाता है। मोटे तौर पर, यह एएसपी पृष्ठों (या सी ++ - प्रीप्रोसेसर) जैसा कुछ है, केवल मार्कअप भाषा अलग है।
अब तक, इस इंजन का कार्यान्वयन केवल पायथन के लिए किया गया है। अब यह C ++ के लिए है। यह कैसे और क्यों हुआ, और इस बारे में लेख में चर्चा की जाएगी।
मैंने भी इसे क्यों लिया
वास्तव में, क्यों? आखिरकार, पायथन है, इसके लिए - एक उत्कृष्ट कार्यान्वयन, सुविधाओं का एक गुच्छा, भाषा के लिए एक पूर्ण विनिर्देश। लो और उपयोग करो! मुझे पायथन पसंद नहीं है - आप C + में जिंजा 2
लेपलाइट या
इंजा , आंशिक जिंजा 2 पोर्ट ले सकते हैं। आप अंत में, C ++ पोर्ट {{
मूंछ }} ले सकते हैं। शैतान, हमेशा की तरह, विवरण में। तो, मान लीजिए, मुझे जिनजा 2 से फिल्टर की कार्यक्षमता और निर्माण की क्षमताओं की आवश्यकता है, जो आपको एक्स्टेंसिबल टेम्पलेट बनाने की अनुमति देता है (और मैक्रोज़ भी शामिल हैं और शामिल हैं, लेकिन यह बाद में)। और उल्लिखित कार्यान्वयनों में से कोई भी इसका समर्थन नहीं करता है। क्या मैं यह सब बिना कर सकता था? एक अच्छा प्रश्न भी। खुद के लिए जज। मेरे पास एक
परियोजना है जिसका लक्ष्य सी ++ - टू-सी ++ बॉयलरप्लेट कोड जनरेटर बनाना है। यह ऑटोगेनेरेटर, संरचनाओं या एनमों के साथ मैन्युअल रूप से लिखी गई हेडर फ़ाइल को प्राप्त करता है, कहता है, और इसके आधार पर क्रमबद्धता / विचलन का कार्य करता है या, कहते हैं, एनम तत्वों को स्ट्रिंग्स (और इसके विपरीत) में परिवर्तित करता है। आप इस उपयोगिता के बारे में अधिक विवरण मेरी रिपोर्टों में (eng) या
यहाँ (rus) सुन सकते हैं।
तो, उपयोगिता पर काम करने की प्रक्रिया में हल किया गया एक विशिष्ट कार्य हेडर फ़ाइलों का निर्माण है, जिनमें से प्रत्येक में एक हेडर है (ifdefs और शामिल है), मुख्य सामग्री और एक पाद के साथ एक शरीर। इसके अलावा, मुख्य सामग्री नेमस्पेस द्वारा तैयार की गई घोषणाएं हैं। सी ++ निष्पादन में, ऐसी हेडर फ़ाइल बनाने का कोड कुछ इस तरह दिखता है (और यह सब नहीं है):
बहुत सारे C ++ कोडvoid Enum2StringGenerator::WriteHeaderContent(CppSourceStream &hdrOs) { std::vector<reflection::EnumInfoPtr> enums; WriteNamespaceContents(hdrOs, m_namespaces.GetRootNamespace(), [this, &enums](CppSourceStream &os, reflection::NamespaceInfoPtr ns) { for (auto& enumInfo : ns->enums) { WriteEnumToStringConversion(os, enumInfo); WriteEnumFromStringConversion(os, enumInfo); enums.push_back(enumInfo); } }); hdrOs << "\n\n"; { out::BracedStreamScope flNs("\nnamespace flex_lib", "\n\n", 0); hdrOs << out::new_line(1) << flNs; for (reflection::EnumInfoPtr enumInfo : enums) { auto scopedParams = MakeScopedParams(hdrOs, enumInfo); { hdrOs << out::new_line(1) << "template<>"; out::BracedStreamScope body("inline const char* Enum2String($enumFullQualifiedName$ e)", "\n"); hdrOs << out::new_line(1) << body; hdrOs << out::new_line(1) << "return $namespaceQual$::$enumName$ToString(e);"; } { hdrOs << out::new_line(1) << "template<>"; out::BracedStreamScope body("inline $enumFullQualifiedName$ String2Enum<$enumFullQualifiedName$>(const char* itemName)", "\n"); hdrOs << out::new_line(1) << body; hdrOs << out::new_line(1) << "return $namespaceQual$::StringTo$enumName$(itemName);"; } } } { out::BracedStreamScope flNs("\nnamespace std", "\n\n", 0); hdrOs << out::new_line(1) << flNs; for (reflection::EnumInfoPtr enumInfo : enums) { auto scopedParams = MakeScopedParams(hdrOs, enumInfo); out::BracedStreamScope body("inline std::string to_string($enumFullQualifiedName$ e)", "\n"); hdrOs << out::new_line(1) << body; hdrOs << out::new_line(1) << "return $namespaceQual$::$enumName$ToString(e);"; } } }
यहाँ से ।
इसके अलावा, यह कोड फ़ाइल से फ़ाइल में बहुत कम बदलता है। बेशक, आप स्वरूपण के लिए क्लैंग-प्रारूप का उपयोग कर सकते हैं। लेकिन यह स्रोत टेक्स्ट जनरेट करने पर बाकी मैनुअल काम को रद्द नहीं करता है।
और फिर एक ठीक क्षण, मुझे एहसास हुआ कि मेरे जीवन को सरल बनाया जाना चाहिए। अंतिम परिणाम का समर्थन करने की जटिलता के कारण मैंने एक पूर्ण-पटकथा वाली भाषा को खराब करने के विकल्प पर विचार नहीं किया। लेकिन एक उपयुक्त टेम्पलेट इंजन खोजने के लिए - क्यों नहीं? मुझे यह खोज करने के लिए उपयोगी लगा, मुझे यह मिला, फिर मैंने जिन्जा 2 विनिर्देशन पाया और महसूस किया कि यह वही है जो मुझे चाहिए। इस युक्ति के अनुसार, हेडर बनाने के लिए टेम्पलेट इस तरह दिखेंगे:
{% extends "header_skeleton.j2tpl" %} {% block generator_headers %} #include <flex_lib/stringized_enum.h> #include <algorithm> #include <utility> {% endblock %} {% block namespaced_decls %}{{super()}}{% endblock %} {% block namespace_content %} {% for enum in ns.enums | sort(attribute="name") %} {% set enumName = enum.name %} {% set scopeSpec = enum.scopeSpecifier %} {% set scopedName = scopeSpec ~ ('::' if scopeSpec) ~ enumName %} {% set prefix = (scopedName + '::') if not enumInfo.isScoped else (scopedName ~ '::' ~ scopeSpec ~ ('::' if scopeSpec)) %} inline const char* {{enumName}}ToString({{scopedName}} e) { switch (e) { {% for itemName in enum.items | map(attribute="itemName") | sort%} case {{prefix}}{{itemName}}: return "{{itemName}}"; {% endfor %} } return "Unknown Item"; } inline {{scopedName}} StringTo{{enumName}}(const char* itemName) { static std::pair<const char*, {{scopedName}}> items[] = { {% for itemName in enum.items | map(attribute="itemName") | sort %} {"{{itemName}}", {{prefix}}{{itemName}} } {{',' if not loop.last }} {% endfor %} }; {{scopedName}} result; if (!flex_lib::detail::String2Enum(itemName, items, result)) flex_lib::bad_enum_name::Throw(itemName, "{{enumName}}"); return result; } {% endfor %}{% endblock %} {% block global_decls %} {% for ns in [rootNamespace] recursive %} {% for enum in ns.enums %} template<> inline const char* flex_lib::Enum2String({{enum.fullQualifiedName}} e) { return {{enum.namespaceQualifier}}::{{enum.name}}ToString(e); } template<> inline {{enum.fullQualifiedName}} flex_lib::String2Enum<{{enum.fullQualifiedName}}>(const char* itemName) { return {{enum.namespaceQualifier}}::StringTo{{enum.name}}(itemName); } inline std::string to_string({{enum.fullQualifiedName}} e) { return {{enum.namespaceQualifier}}::{{enum.name}}ToString(e); } {% endfor %} {{loop(ns.namespaces)}} {% endfor %} {% endblock %}
यहाँ से ।

केवल एक ही समस्या थी: जिन इंजनों को मैंने पाया उनमें से एक भी नहीं था जो मुझे आवश्यक सुविधाओं के पूरे सेट का समर्थन करता था। खैर, निश्चित रूप से, सभी के पास एक मानक
घातक दोष था । मैंने थोड़ा सोचा और फैसला किया कि टेम्पलेट इंजन के एक और कार्यान्वयन से कोई दूसरी दुनिया खराब नहीं होगी। इसके अलावा, अनुमान के मुताबिक, बुनियादी कार्यक्षमता को लागू करना इतना मुश्किल नहीं था। आखिरकार, अब C ++ में regexp हैं!
और इसलिए
जिंजाकोप परियोजना
के बारे में आया । बुनियादी (बहुत बुनियादी) कार्यक्षमता को लागू करने की जटिलता की कीमत पर, मैंने लगभग अनुमान लगाया था। कुल मिलाकर, मैं वास्तव में पाई गुणांक चुकता करने से चूक गया: मुझे अपनी जरूरत की हर चीज को लिखने में तीन महीने से भी कम समय लगा। लेकिन जब सब कुछ समाप्त हो गया, समाप्त हो गया और "ऑटो प्रोग्रामर" में डाला गया - मुझे एहसास हुआ कि मैंने व्यर्थ में कोशिश नहीं की। वास्तव में, कोड जनरेशन उपयोगिता को टेम्पलेट्स के साथ संयुक्त रूप से एक शक्तिशाली स्क्रिप्टिंग भाषा प्राप्त हुई, जिसने इसके लिए पूरी तरह से नए विकास के अवसर खोले।
नायब: मुझे पायथन (या लुआ) को जकड़ने का विचार था। लेकिन मौजूदा पूर्ण विकसित स्क्रिप्टिंग इंजन में से कोई भी "टेम्पलेट से बॉक्स" मुद्दों को हल नहीं करता है। यही है, पायथन को अभी भी एक ही जिंजा 2 को पेंच करना होगा, लेकिन लूआ के लिए, कुछ अलग करना होगा। मुझे इस अतिरिक्त लिंक की आवश्यकता क्यों थी?
पार्सर कार्यान्वयन
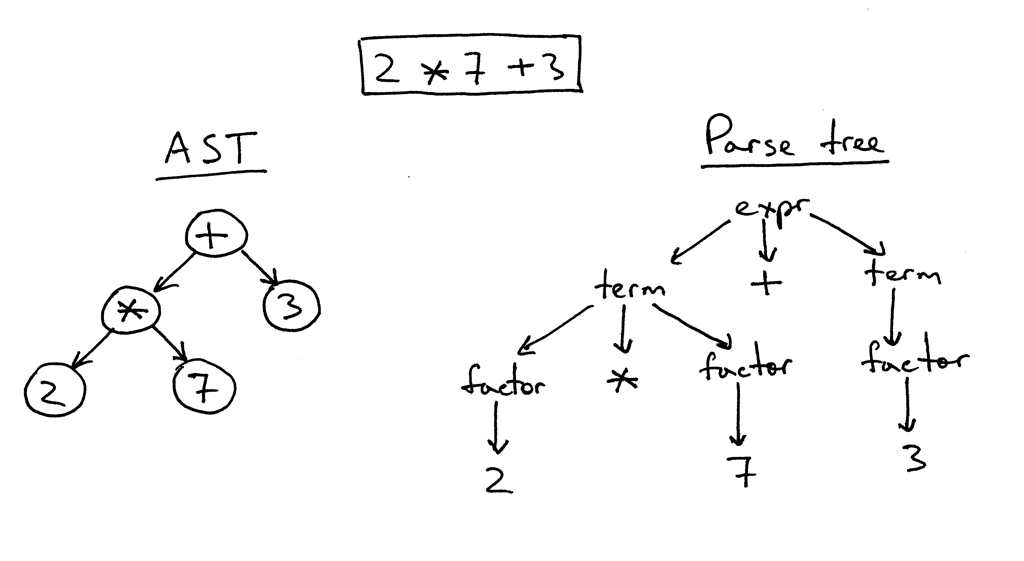
Jinja2 टेम्पलेट्स की संरचना के पीछे विचार बहुत सरल है। यदि "{{" / "/}}" की जोड़ी में संलग्न पाठ में कुछ है, तो यह "कुछ" है - एक अभिव्यक्ति जिसका मूल्यांकन किया जाना चाहिए, एक पाठ प्रतिनिधित्व में परिवर्तित हो जाएगा और अंतिम परिणाम में डाला जाएगा। जोड़ी के अंदर "{%" / "%}" ऑपरेटर हैं, जैसे, अगर, सेट, आदि, "{#" / "# #" टिप्पणी में हैं। जिन्जाकांपलाइट के कार्यान्वयन का अध्ययन करने के बाद, मैंने तय किया कि टेम्पलेट टेक्स्ट में इन सभी नियंत्रण संरचनाओं को मैन्युअल रूप से खोजने की कोशिश करना बहुत अच्छा विचार नहीं था। इसलिए, मैंने अपने आप को एक बहुत ही सरल regexp के साथ सशस्त्र किया: (((\ {\ {) | (\} \}) | (\ {%) | (% \}) | (\ {#) | (# \ _}) (\ _) | n)), जिसकी सहायता से उसने पाठ को आवश्यक अंशों में तोड़ा। और इसे पार्सिंग का मोटा चरण कहा। कार्य के प्रारंभिक चरण में, विचार ने अपनी प्रभावशीलता दिखाई (हाँ, वास्तव में, यह अभी भी पता चलता है), लेकिन, एक अच्छे तरीके से, भविष्य में इसे फिर से बनाने की आवश्यकता होगी, क्योंकि अब खाका पाठ पर मामूली प्रतिबंध लगाए गए हैं: "{" और "}}" पाठ में "माथे" को भी संसाधित किया जाता है।
दूसरे चरण में, केवल "कोष्ठक" के अंदर जो है, उसे विस्तार से बताया गया है। और यहाँ मुझे टिंकर करना पड़ा। Inja के साथ, Jinja2CppLight के साथ, अभिव्यक्ति पार्सर बहुत सरल है। पहले मामले में - एक ही rexxp'ah पर, दूसरे में - हस्तलिखित, लेकिन केवल बहुत सरल डिजाइनों का समर्थन करना। फ़िल्टर, परीक्षक, जटिल अंकगणित या अनुक्रमण के लिए समर्थन प्रश्न से बाहर है। और यह ठीक जिन्ना 2 की विशेषताएं थीं जो मैं सबसे अधिक चाहता था। इसलिए, मेरे पास कोई पूर्ण विकल्प एलएल (1) पार्सर (कुछ स्थानों पर - संदर्भ-संवेदनशील) को रफ करने के अलावा कोई अन्य विकल्प नहीं था जो आवश्यक व्याकरण को लागू करता है। लगभग दस से पंद्रह साल पहले, मैं शायद इसके लिए बाइसन या ANTLR ले लूंगा और उनकी मदद से एक पार्सर लागू करूंगा। लगभग सात साल पहले मैंने Boost.Spirit की कोशिश की होगी। अब मैंने सिर्फ उस पार्सर को लागू किया जिसकी मुझे आवश्यकता है, पुनरावर्ती वंश विधि द्वारा काम करना, बिना अनावश्यक निर्भरता पैदा किए और संकलन समय में काफी वृद्धि करना, जैसे कि बाहरी उपयोगिताओं या Boost.Spirit का उपयोग किया जाता है। पार्सर के उत्पादन में, मुझे एएसटी (अभिव्यक्ति के लिए या ऑपरेटरों के लिए) मिलता है, जिसे एक टेम्पलेट के रूप में सहेजा जाता है, जो बाद के प्रतिपादन के लिए तैयार है।
पार्सिंग तर्क का एक उदाहरण ExpressionEvaluatorPtr<FullExpressionEvaluator> ExpressionParser::ParseFullExpression(LexScanner &lexer, bool includeIfPart) { ExpressionEvaluatorPtr<FullExpressionEvaluator> result; LexScanner::StateSaver saver(lexer); ExpressionEvaluatorPtr<FullExpressionEvaluator> evaluator = std::make_shared<FullExpressionEvaluator>(); auto value = ParseLogicalOr(lexer); if (!value) return result; evaluator->SetExpression(value); ExpressionEvaluatorPtr<ExpressionFilter> filter; if (lexer.PeekNextToken() == '|') { lexer.EatToken(); filter = ParseFilterExpression(lexer); if (!filter) return result; evaluator->SetFilter(filter); } ExpressionEvaluatorPtr<IfExpression> ifExpr; if (lexer.PeekNextToken() == Token::If) { if (includeIfPart) { lexer.EatToken(); ifExpr = ParseIfExpression(lexer); if (!ifExpr) return result; evaluator->SetTester(ifExpr); } } saver.Commit(); return evaluator; } ExpressionEvaluatorPtr<Expression> ExpressionParser::ParseLogicalOr(LexScanner& lexer) { auto left = ParseLogicalAnd(lexer); if (!left) return ExpressionEvaluatorPtr<Expression>(); if (lexer.NextToken() != Token::LogicalOr) { lexer.ReturnToken(); return left; } auto right = ParseLogicalOr(lexer); if (!right) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<BinaryExpression>(BinaryExpression::LogicalOr, left, right); } ExpressionEvaluatorPtr<Expression> ExpressionParser::ParseLogicalAnd(LexScanner& lexer) { auto left = ParseLogicalCompare(lexer); if (!left) return ExpressionEvaluatorPtr<Expression>(); if (lexer.NextToken() != Token::LogicalAnd) { lexer.ReturnToken(); return left; } auto right = ParseLogicalAnd(lexer); if (!right) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<BinaryExpression>(BinaryExpression::LogicalAnd, left, right); } ExpressionEvaluatorPtr<Expression> ExpressionParser::ParseLogicalCompare(LexScanner& lexer) { auto left = ParseStringConcat(lexer); if (!left) return ExpressionEvaluatorPtr<Expression>(); auto tok = lexer.NextToken(); BinaryExpression::Operation operation; switch (tok.type) { case Token::Equal: operation = BinaryExpression::LogicalEq; break; case Token::NotEqual: operation = BinaryExpression::LogicalNe; break; case '<': operation = BinaryExpression::LogicalLt; break; case '>': operation = BinaryExpression::LogicalGt; break; case Token::GreaterEqual: operation = BinaryExpression::LogicalGe; break; case Token::LessEqual: operation = BinaryExpression::LogicalLe; break; case Token::In: operation = BinaryExpression::In; break; case Token::Is: { Token nextTok = lexer.NextToken(); if (nextTok != Token::Identifier) return ExpressionEvaluatorPtr<Expression>(); std::string name = AsString(nextTok.value); bool valid = true; CallParams params; if (lexer.NextToken() == '(') params = ParseCallParams(lexer, valid); else lexer.ReturnToken(); if (!valid) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<IsExpression>(left, std::move(name), std::move(params)); } default: lexer.ReturnToken(); return left; } auto right = ParseStringConcat(lexer); if (!right) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<BinaryExpression>(operation, left, right); }
यहाँ से ।
एएसटी एक्सप्रेशन ट्री क्लासेज की खुशबू class ExpressionFilter; class IfExpression; class FullExpressionEvaluator : public ExpressionEvaluatorBase { public: void SetExpression(ExpressionEvaluatorPtr<Expression> expr) { m_expression = expr; } void SetFilter(ExpressionEvaluatorPtr<ExpressionFilter> expr) { m_filter = expr; } void SetTester(ExpressionEvaluatorPtr<IfExpression> expr) { m_tester = expr; } InternalValue Evaluate(RenderContext& values) override; void Render(OutStream &stream, RenderContext &values) override; private: ExpressionEvaluatorPtr<Expression> m_expression; ExpressionEvaluatorPtr<ExpressionFilter> m_filter; ExpressionEvaluatorPtr<IfExpression> m_tester; }; class ValueRefExpression : public Expression { public: ValueRefExpression(std::string valueName) : m_valueName(valueName) { } InternalValue Evaluate(RenderContext& values) override; private: std::string m_valueName; }; class SubscriptExpression : public Expression { public: SubscriptExpression(ExpressionEvaluatorPtr<Expression> value, ExpressionEvaluatorPtr<Expression> subscriptExpr) : m_value(value) , m_subscriptExpr(subscriptExpr) { } InternalValue Evaluate(RenderContext& values) override; private: ExpressionEvaluatorPtr<Expression> m_value; ExpressionEvaluatorPtr<Expression> m_subscriptExpr; }; class ConstantExpression : public Expression { public: ConstantExpression(InternalValue constant) : m_constant(constant) {} InternalValue Evaluate(RenderContext&) override { return m_constant; } private: InternalValue m_constant; }; class TupleCreator : public Expression { public: TupleCreator(std::vector<ExpressionEvaluatorPtr<>> exprs) : m_exprs(std::move(exprs)) { } InternalValue Evaluate(RenderContext&) override; private: std::vector<ExpressionEvaluatorPtr<>> m_exprs; };
यहाँ से ।
एएसटी ट्री ऑपरेटरों के उदाहरण वर्ग struct Statement : public RendererBase { }; template<typename T = Statement> using StatementPtr = std::shared_ptr<T>; template<typename CharT> class TemplateImpl; class ForStatement : public Statement { public: ForStatement(std::vector<std::string> vars, ExpressionEvaluatorPtr<> expr, ExpressionEvaluatorPtr<> ifExpr, bool isRecursive) : m_vars(std::move(vars)) , m_value(expr) , m_ifExpr(ifExpr) , m_isRecursive(isRecursive) { } void SetMainBody(RendererPtr renderer) { m_mainBody = renderer; } void SetElseBody(RendererPtr renderer) { m_elseBody = renderer; } void Render(OutStream& os, RenderContext& values) override; private: void RenderLoop(const InternalValue& val, OutStream& os, RenderContext& values); private: std::vector<std::string> m_vars; ExpressionEvaluatorPtr<> m_value; ExpressionEvaluatorPtr<> m_ifExpr; bool m_isRecursive; RendererPtr m_mainBody; RendererPtr m_elseBody; }; class ElseBranchStatement; class IfStatement : public Statement { public: IfStatement(ExpressionEvaluatorPtr<> expr) : m_expr(expr) { } void SetMainBody(RendererPtr renderer) { m_mainBody = renderer; } void AddElseBranch(StatementPtr<ElseBranchStatement> branch) { m_elseBranches.push_back(branch); } void Render(OutStream& os, RenderContext& values) override; private: ExpressionEvaluatorPtr<> m_expr; RendererPtr m_mainBody; std::vector<StatementPtr<ElseBranchStatement>> m_elseBranches; }; class ElseBranchStatement : public Statement { public: ElseBranchStatement(ExpressionEvaluatorPtr<> expr) : m_expr(expr) { } bool ShouldRender(RenderContext& values) const; void SetMainBody(RendererPtr renderer) { m_mainBody = renderer; } void Render(OutStream& os, RenderContext& values) override; private: ExpressionEvaluatorPtr<> m_expr; RendererPtr m_mainBody; };
यहाँ से ।
एएसटी नोड्स केवल टेम्प्लेट के पाठ से जुड़े होते हैं और रेंडरिंग के समय कुल मूल्यों में बदल जाते हैं, वर्तमान रेंडरिंग संदर्भ और इसके मापदंडों को ध्यान में रखते हैं। इससे हमें थ्रेड-सेफ पैटर्न बनाने की अनुमति मिली। लेकिन वास्तविक प्रतिपादन के संदर्भ में इसके बारे में और अधिक।
प्राथमिक टोकन के रूप में, मैंने
लेक्सर्टक लाइब्रेरी को चुना। इसके पास लाइसेंस की आवश्यकता है और मुझे केवल हेडर चाहिए। सच है, मुझे कोष्ठक और इतने पर संतुलन की गणना करने के सभी घंटियाँ और सीटी काटनी पड़ीं और केवल एक टोकन छोड़ दिया, जो (एक फ़ाइल के साथ थोड़ा सीधा होने के बाद) न केवल चार के साथ काम करना सीखा, बल्कि wchar_t अक्षर भी। इस टोकन के शीर्ष पर, मैंने एक और वर्ग लपेटा है जो तीन मुख्य कार्य करता है: ए) यह वर्णों के प्रकार से पार्सर कोड को अमूर्त करता है जिसके साथ हम काम कर रहे हैं, ख) यह जिंजा 2 के लिए विशिष्ट कीवर्ड को पहचानता है, और सी) यह टोकन स्ट्रीम के साथ काम करने के लिए एक सुविधाजनक इंटरफ़ेस प्रदान करता है:
LexScanner class LexScanner { public: struct State { Lexer::TokensList::const_iterator m_begin; Lexer::TokensList::const_iterator m_end; Lexer::TokensList::const_iterator m_cur; }; struct StateSaver { StateSaver(LexScanner& scanner) : m_state(scanner.m_state) , m_scanner(scanner) { } ~StateSaver() { if (!m_commited) m_scanner.m_state = m_state; } void Commit() { m_commited = true; } State m_state; LexScanner& m_scanner; bool m_commited = false; }; LexScanner(const Lexer& lexer) { m_state.m_begin = lexer.GetTokens().begin(); m_state.m_end = lexer.GetTokens().end(); Reset(); } void Reset() { m_state.m_cur = m_state.m_begin; } auto GetState() const { return m_state; } void RestoreState(const State& state) { m_state = state; } const Token& NextToken() { if (m_state.m_cur == m_state.m_end) return EofToken(); return *m_state.m_cur ++; } void EatToken() { if (m_state.m_cur != m_state.m_end) ++ m_state.m_cur; } void ReturnToken() { if (m_state.m_cur != m_state.m_begin) -- m_state.m_cur; } const Token& PeekNextToken() const { if (m_state.m_cur == m_state.m_end) return EofToken(); return *m_state.m_cur; } bool EatIfEqual(char type, Token* tok = nullptr) { return EatIfEqual(static_cast<Token::Type>(type), tok); } bool EatIfEqual(Token::Type type, Token* tok = nullptr) { if (m_state.m_cur == m_state.m_end) { if(type == Token::Type::Eof && tok) *tok = EofToken(); return type == Token::Type::Eof; } if (m_state.m_cur->type == type) { if (tok) *tok = *m_state.m_cur; ++ m_state.m_cur; return true; } return false; } private: State m_state; static const Token& EofToken() { static Token eof; eof.type = Token::Eof; return eof; } };
यहाँ से ।
इस प्रकार, इस तथ्य के बावजूद कि इंजन चार और wchar_t- टेम्पलेट्स के साथ काम कर सकता है, मुख्य पार्सिंग कोड चरित्र के प्रकार पर निर्भर नहीं करता है। लेकिन चरित्र प्रकारों के साथ रोमांच पर इस अनुभाग में अधिक।
अलग-अलग, मुझे नियंत्रण संरचनाओं के साथ टिंकर करना पड़ा। जिनजा 2 में, उनमें से कई जोड़े हैं। उदाहरण के लिए, / एंडफोर के लिए, यदि / एंडिफ, ब्लॉक / एंडब्लॉक, आदि। जोड़ी का प्रत्येक तत्व अपने स्वयं के "कोष्ठक" में जाता है, और तत्वों के बीच सब कुछ का एक गुच्छा हो सकता है: बस सादा पाठ और अन्य नियंत्रण ब्लॉक। इसलिए, टेम्पलेट को पार्स करने के लिए एल्गोरिथ्म को स्टैक के आधार पर, वर्तमान ऊपरी तत्व के लिए किया जाना था, जिसमें सभी नए निर्माण और निर्देश, साथ ही उनके बीच सरल पाठ के टुकड़े, "क्लिंग"। एक ही स्टैक का उपयोग करते हुए, अगर-के लिए एंडिफ-एंडफोर प्रकार के असंतुलित होने की अनुपस्थिति की जांच की जाती है। इस सब के परिणामस्वरूप, कोड "कॉम्पैक्ट" के रूप में नहीं निकला, जैसे कि, जिंजाकोप्प्लाइट (या इंजा), जहां पूरा कार्यान्वयन एक स्रोत (या हेडर) में है। लेकिन पार्सिंग लॉजिक और, वास्तव में, कोड में व्याकरण अधिक स्पष्ट रूप से दिखाई देता है, जो इसके समर्थन और विस्तार को सरल करता है। कम से कम मैं यही चाहता था। निर्भरता की संख्या या कोड की मात्रा को कम करना अभी भी संभव नहीं है, इसलिए आपको इसे और अधिक समझने की आवश्यकता है।
अगले भाग में, हम टेम्प्लेट को प्रस्तुत करने की प्रक्रिया के बारे में बात करेंगे, लेकिन अभी के लिए - लिंक:
जिनजा 2 विनिर्देश:
http://jinja.pocoo.org/docs/2.10/templates/जिंजाकोप लागू:
https://github.com/flexferrum/Jinja2Cppजिंजाकोप्प्लाइट कार्यान्वयन:
https://github.com/hughperkins/Jinja2CppLightचोटिल कार्यान्वयन:
https://github.com/pantor/injaजिनजा 2 टेम्प्लेट के आधार पर कोड जनरेट करने की उपयोगिता:
https://github.com/flexferrum/autoprogrammer/tree/jinja2cpp_refactor