आवेदन परीक्षण विकसित करना एक सुखद अनुभव नहीं है। इस प्रक्रिया में लंबा समय लगता है, इसके लिए बहुत अधिक एकाग्रता की आवश्यकता होती है और यह मांग में अत्यधिक है। कोटलिन भाषा उपकरण का एक सेट प्रदान करती है जो आपकी समस्या-उन्मुख भाषा (डीएसएल) बनाने में काफी आसान बनाता है। वहाँ अनुभव है जब कोटलिन डीएसएल ने रिसोर्स प्लानिंग मॉड्यूल के परीक्षण के लिए बिल्डरों और स्थैतिक तरीकों को बदल दिया, जिसने नए परीक्षणों को जोड़ा और पुराने लोगों को एक मजेदार प्रक्रिया से समर्थन दिया।
लेख के पाठ्यक्रम में, हम डेवलपर के शस्त्रागार से सभी मुख्य उपकरणों का विश्लेषण करेंगे और परीक्षण समस्याओं को हल करने के लिए उन्हें कैसे जोड़ा जा सकता है। हम कोटलिन-आधारित संसाधन नियोजन प्रणाली के लिए सबसे अनुमानित, स्वच्छ और समझने योग्य परीक्षण शुरू करने के लिए आदर्श परीक्षण को डिजाइन करने से सभी तरह से जाएंगे।
लेख इंजीनियरों को अभ्यास करने के लिए उपयोगी होगा, जो आराम से कॉम्पैक्ट परीक्षण लिखने के लिए कोटलिन को एक भाषा मानते हैं, और जो लोग अपनी परियोजना में परीक्षण प्रक्रिया में सुधार करना चाहते हैं।
यह लेख इवान
ओसिपोव (
i_osipov ) द्वारा JPoint सम्मेलन में एक प्रस्तुति पर आधारित है। आगे का कथन उसकी ओर से किया जाता है। इवान Haulmont में एक प्रोग्रामर के रूप में काम करता है। कंपनी का मुख्य उत्पाद CUBA है, जो उद्यम और विभिन्न वेब अनुप्रयोगों के विकास के लिए एक मंच है। विशेष रूप से, इस प्लेटफॉर्म पर आउटसोर्सिंग परियोजनाएं बनाई जा रही हैं, जिनमें से शिक्षा के क्षेत्र में हाल ही में एक परियोजना थी, जिसमें इवान एक शैक्षिक संस्थान के लिए एक कार्यक्रम बनाने में लगे हुए थे। ऐसा हुआ कि पिछले तीन वर्षों से इवान योजनाकारों के साथ एक या दूसरे तरीके से काम कर रहा है, और विशेष रूप से हौलमोंट में वे एक साल से इस योजनाकार का परीक्षण कर रहे हैं।
उन लोगों के लिए जो उदाहरण चलाना चाहते हैं -
GitHub का लिंक रखें । लिंक के तहत आपको वह सभी कोड मिलेंगे जिन्हें हम आज पार्स करेंगे, चलाएंगे और लिखेंगे। कोड खोलें और जाओ!

आज हम चर्चा करेंगे:
- समस्या-उन्मुख भाषाएं क्या हैं;
- अंतर्निहित समस्या-उन्मुख भाषाएं;
- एक शैक्षिक संस्थान के लिए एक कार्यक्रम का निर्माण;
- यह सब कैसे कोटलिन के साथ परीक्षण किया गया है।
आज मैं उन उपकरणों के बारे में विस्तार से बात करूंगा जो हमारे पास भाषा में हैं, आपको कुछ डेमो दिखाते हैं, और हम शुरुआत से अंत तक पूरी परीक्षा लिखेंगे। साथ ही, मैं अधिक उद्देश्यपूर्ण होना चाहूंगा, इसलिए मैं विकास के दौरान अपने लिए पहचाने जाने वाले कुछ नुकसानों के बारे में बात करूंगा।
चलो शेड्यूल बिल्डिंग मॉड्यूल के बारे में बात करके शुरू करते हैं। इसलिए, शेड्यूल का निर्माण कई चरणों में होता है। इनमें से प्रत्येक चरण को अलग से परीक्षण करने की आवश्यकता है। आपको यह समझने की आवश्यकता है कि इस तथ्य के बावजूद कि चरण अलग हैं, हमारे पास एक सामान्य डेटा मॉडल है।

इस प्रक्रिया को निम्नानुसार दर्शाया जा सकता है: इनपुट पर एक सामान्य मॉडल के साथ कुछ डेटा होता है, आउटपुट पर एक शेड्यूल होता है। डेटा को मान्य किया जाता है, फ़िल्टर किया जाता है, फिर प्रशिक्षण समूह बनाए जाते हैं। यह शैक्षिक संस्थान के लिए अनुसूची के विषय क्षेत्र को संदर्भित करता है। निर्मित समूहों के आधार पर और कुछ अन्य आंकड़ों के आधार पर, हम पाठ को जगह देते हैं। आज हम केवल अंतिम चरण के बारे में बात करेंगे - कक्षाओं के प्लेसमेंट के बारे में।

अनुसूचक के परीक्षण के बारे में थोड़ा सा।
सबसे पहले, जैसा कि आप पहले से ही समझ चुके हैं, विभिन्न चरणों का अलग-अलग परीक्षण किया जाना चाहिए। कोई भी परीक्षण शुरू करने की अधिक या कम मानक प्रक्रिया को एकल कर सकता है: डेटा आरंभीकरण है, एक अनुसूचक प्रक्षेपण है, इस अनुसूचक के परिणामों की जाँच है। विभिन्न व्यावसायिक मामलों की एक बड़ी संख्या है, जिन्हें कवर करने की आवश्यकता है और विभिन्न स्थितियों को ध्यान में रखना आवश्यक है ताकि एक शेड्यूल बनाते समय, ये स्थितियाँ भी बनी रहें।
एक मॉडल कभी-कभी वजनदार हो सकता है, और एकल इकाई बनाने के लिए, पांच अतिरिक्त संस्थाओं को शुरू करना आवश्यक है, या इससे भी अधिक। इस प्रकार, कुल मिलाकर, बड़ी मात्रा में कोड प्राप्त होता है, जिसे हम प्रत्येक परीक्षण के लिए बार-बार लिखते हैं। ऐसे परीक्षणों के लिए समर्थन में काफी समय लगता है। यदि आप मॉडल को अपडेट करना चाहते हैं, और यह कभी-कभी होता है, तो परिवर्तनों का पैमाना परीक्षणों को प्रभावित करता है।
आइए एक परीक्षण लिखें:

आइए सबसे सरल परीक्षण लिखें ताकि आप आमतौर पर तस्वीर को समझ सकें।
जब आप परीक्षण के बारे में सोचते हैं तो सबसे पहले क्या ख्याल आता है? शायद ये इस तरह के कुछ आदिम परीक्षण हैं: आप एक वर्ग बनाते हैं, इसमें एक विधि बनाते हैं, इसे एनोटेशन
टेस्ट के साथ चिह्नित करते हैं। परिणामस्वरूप, हम JUnit की क्षमताओं का उपयोग करते हैं, और कुछ डेटा, डिफ़ॉल्ट मानों, फिर परीक्षण-विशिष्ट मानों को आरंभ करते हैं, बाकी मॉडल के लिए भी ऐसा ही करते हैं, और अंत में एक अनुसूचक वस्तु बनाते हैं, हमारे डेटा को इसमें स्थानांतरित करते हैं, हम शुरू करते हैं, हम परिणाम प्राप्त करते हैं और हम उनकी जांच करते हैं। अधिक या कम मानक प्रक्रिया। लेकिन इसमें स्पष्ट रूप से कोड दोहराव है। पहली बात जो दिमाग में आती है वह है सब कुछ स्थैतिक तरीकों में डालने की क्षमता। चूंकि डिफ़ॉल्ट मानों का एक समूह है, इसलिए इसे छिपाएं नहीं?

नकल को कम करने की दिशा में यह एक अच्छा पहला कदम है।

इसे देखते हुए, आप समझते हैं कि मैं मॉडल को अधिक कॉम्पैक्ट रखना चाहूंगा। यहां हमारे पास एक बिल्डर पैटर्न है जिसमें कहीं न कहीं हुड के नीचे, डिफ़ॉल्ट मान को आरंभीकृत किया गया है, और परीक्षण-विशिष्ट मान प्रारंभिक रूप से वहीं हैं। यह बेहतर हो रहा है, हालांकि, हम अभी भी बॉयलरप्लेट कोड लिख रहे हैं, और हम इसे हर बार फिर से लिख रहे हैं। 200 टेस्ट की कल्पना करें - आपको इन तीन लाइनों को 200 बार लिखना होगा। जाहिर है, मैं इससे किसी तरह छुटकारा पाना चाहूंगा। विचार विकसित करना, हम एक निश्चित सीमा तक आते हैं। इसलिए, उदाहरण के लिए, हम सामान्य रूप से हर चीज के लिए एक पैटर्न बिल्डर बना सकते हैं।

आप स्क्रैच से अंत तक एक शेड्यूलर बना सकते हैं, हमारे द्वारा आवश्यक सभी मान सेट करें, शेड्यूलिंग शुरू करें और सब कुछ बहुत अच्छा है। यदि आप इस उदाहरण को विस्तार से देखते हैं और विस्तार से विश्लेषण करते हैं, तो यह पता चलता है कि बहुत सारे अनावश्यक कोड लिखे जा रहे हैं। मैं परीक्षणों को और अधिक पठनीय बनाना चाहता हूं ताकि आप पैटर्न और अन्य चीजों पर ध्यान दिए बिना एक नज़र डाल सकें और तुरंत समझ सकें।
इसलिए, हमारे पास कुछ अनावश्यक कोड हैं। सरल गणित से पता चलता है कि हमारी ज़रूरत से 55% अधिक पत्र हैं, और मैं किसी भी तरह उनसे दूर होना चाहूंगा।

कुछ समय बाद, हमारे परीक्षणों का समर्थन अधिक महंगा हो जाता है, क्योंकि आपको अधिक कोड का समर्थन करने की आवश्यकता होती है। कभी-कभी, यदि हम कोई प्रयास नहीं करते हैं, तो पठनीयता या तो वांछित होने के लिए बहुत कुछ छोड़ देती है, या यह स्वीकार्य हो जाती है, लेकिन हम और भी बेहतर चाहेंगे। शायद बाद में हम परीक्षणों को लिखने में आसान बनाने के लिए कुछ प्रकार के ढांचे, पुस्तकालयों को जोड़ना शुरू करेंगे। इसके कारण, हम अपने आवेदन के परीक्षण में प्रवेश के स्तर को बढ़ाते हैं। यहां हमारे पास पहले से ही जटिल एप्लिकेशन है, इसके परीक्षण में प्रवेश का स्तर महत्वपूर्ण है, और हम इसे और भी अधिक बढ़ा रहे हैं।
बिल्कुल सही परीक्षण
यह कहना बहुत अच्छा है कि सब कुछ कितना बुरा है, लेकिन आइए इस बारे में सोचें कि यह कितना अच्छा होगा। एक आदर्श उदाहरण जिसके परिणामस्वरूप हम प्राप्त करना चाहेंगे:

कल्पना करें कि कुछ घोषणा है जिसमें हम कहते हैं कि यह एक विशिष्ट नाम के साथ एक परीक्षा है, और हम नाम में शब्दों को अलग करने के लिए एक स्थान का उपयोग करना चाहते हैं, न कि कैमलकेज़। हम एक शेड्यूल बना रहे हैं, हमारे पास कुछ डेटा हैं, और प्लानर के परिणामों की जाँच की जाती है। चूंकि हम मुख्य रूप से जावा के साथ काम करते हैं, और मुख्य एप्लिकेशन के सभी कोड इस भाषा में लिखे गए हैं, इसलिए मैं संगत परीक्षण क्षमता रखना चाहूंगा। मैं पाठक को यथासंभव डेटा इनिशियलाइज़ करना चाहूंगा। मैं कुछ सामान्य डेटा और उस मॉडल के हिस्से को इनिशियलाइज़ करना चाहता हूं, जिसकी हमें ज़रूरत है। उदाहरण के लिए, छात्र, शिक्षक बनाएँ, और जब वे उपलब्ध हों तब वर्णन करें। यह हमारा आदर्श उदाहरण है।
डोमेन विशिष्ट भाषा

यह सब देखते हुए, ऐसा लगने लगता है कि यह किसी प्रकार की समस्या उन्मुख भाषा की तरह लग रहा है। आपको यह समझने की जरूरत है कि यह क्या है और क्या अंतर है। भाषाओं को दो प्रकारों में विभाजित किया जा सकता है: सामान्य-उद्देश्य वाली भाषाएं (जो हम लगातार लिखते हैं, बिल्कुल किसी भी कार्य को हल करते हैं और पूरी तरह से सब कुछ के साथ सामना करते हैं) और समस्या-उन्मुख भाषाएं। इसलिए, उदाहरण के लिए, SQL हमें डेटाबेस से डेटा को पूरी तरह से खींचने में मदद करता है, और कुछ अन्य भाषाएँ भी अन्य विशिष्ट समस्याओं को हल करने में मदद करती हैं।

समस्या-उन्मुख भाषाओं को लागू करने का एक तरीका एम्बेडेड भाषाओं, या आंतरिक है। ऐसी भाषाओं को एक सामान्य उद्देश्य वाली भाषा के आधार पर लागू किया जाता है। यही है, हमारी सामान्य प्रयोजन की भाषा के कई निर्माण एक आधार की तरह बनते हैं - यही वह है जो हम एक समस्या-उन्मुख भाषा के साथ काम करते समय उपयोग करते हैं। इस मामले में, निश्चित रूप से, एक समस्या-उन्मुख भाषा में एक अवसर उत्पन्न होता है जो सामान्य उद्देश्य वाली भाषा से आने वाली सभी विशेषताओं और सुविधाओं का उपयोग करता है।

फिर, हमारे आदर्श उदाहरण पर एक नज़र डालें और सोचें कि किस भाषा का चयन करना है। हमारे पास तीन विकल्प हैं।

पहला विकल्प ग्रूवी है। एक अद्भुत, गतिशील भाषा जिसने खुद को समस्या-उन्मुख भाषाओं के निर्माण में सिद्ध किया है। फिर, आप ग्रैडल में एक बिल्ड फ़ाइल का एक उदाहरण दे सकते हैं, जिसका हम में से कई उपयोग करते हैं। स्काला भी है, जिसके पास अपनी खुद की किसी चीज़ के कार्यान्वयन के लिए अवसरों की एक बड़ी संख्या है। और अंत में, कोटलिन है, जो हमें एक समस्या-उन्मुख भाषा बनाने में भी मदद करता है, और आज इस पर चर्चा की जाएगी। मैं युद्ध नहीं करना चाहता और कोटलिन की तुलना किसी और चीज से करना चाहता हूं, बल्कि, यह आपके विवेक पर रहता है। आज मैं आपको दिखाऊंगा कि समस्याग्रस्त भाषाओं को विकसित करने के लिए कोटलिन के पास क्या है। जब आप इसकी तुलना करना चाहते हैं और कहते हैं कि कुछ भाषा बेहतर है, तो आप इस लेख पर लौट सकते हैं और आसानी से अंतर देख सकते हैं।

कोटलिन हमें एक समस्या-उन्मुख भाषा विकसित करने के लिए क्या देता है?
सबसे पहले, यह एक स्थिर टाइपिंग है, और इस से सभी आगामी है। संकलन के चरण में, बड़ी संख्या में समस्याओं का पता लगाया जाता है, और यह बहुत बचत करता है, विशेष रूप से उस स्थिति में जब आप सिंटैक्स और परीक्षणों में लिखने से संबंधित समस्याओं को प्राप्त नहीं करना चाहते हैं।
फिर, एक महान प्रकार की अनुमान प्रणाली है जो कोटलिन से आती है। यह अद्भुत है, क्योंकि बार-बार किसी भी प्रकार को लिखने की आवश्यकता नहीं है, सब कुछ कंपाइलर द्वारा धमाके के साथ प्रदर्शित किया जाता है।
तीसरा, विकास पर्यावरण के लिए उत्कृष्ट समर्थन है, और यह आश्चर्य की बात नहीं है, क्योंकि एक ही कंपनी आज के लिए मुख्य विकास वातावरण बनाती है, और यह कोटलिन करती है।
अंत में, DSL के अंदर, जाहिर है हम Kotlin का उपयोग कर सकते हैं। मेरे व्यक्तिपरक राय में, उपयोगिता वर्गों का समर्थन करने की तुलना में DSL का समर्थन करना बहुत आसान है। जैसा कि आप बाद में देखेंगे, बिल्डरों की तुलना में पठनीयता थोड़ी बेहतर है। मुझे "बेहतर" से क्या मतलब है: आपको थोड़ा कम वाक्यविन्यास मिलता है जिसे आपको लिखने की ज़रूरत है - कोई व्यक्ति जो आपकी समस्या-उन्मुख भाषा पढ़ता है, उसे तेज़ी से ले जाएगा। अंत में, अपनी बाइक लिखना बहुत अधिक मजेदार है! लेकिन वास्तव में, एक समस्या-उन्मुख भाषा को लागू करना कुछ नए ढांचे को सीखने की तुलना में बहुत आसान है।
मैं एक बार फिर
से GitHub के
लिंक को याद
दिलाऊंगा , अगर आप आगे डेमो लिखना चाहते हैं, तो आप लिंक में जाकर कोड चुन सकते हैं।
कोटलिन पर आदर्श डिजाइन करना
चलो अपने आदर्श को डिजाइन करने के लिए आगे बढ़ते हैं, लेकिन पहले से ही कोटलिन में। हमारे उदाहरण पर एक नज़र डालें:

और चरणों में हम इसे फिर से बनाना शुरू करेंगे।
हमारे पास एक परीक्षण है जो कोटलिन में एक फ़ंक्शन में बदल जाता है, जिसे रिक्त स्थान का उपयोग करके नाम दिया जा सकता है।

हम इसे
टेस्ट एनोटेशन के साथ चिह्नित करेंगे, जो कि JUnit से हमारे लिए उपलब्ध है। कोटलिन में, आप लेखन कार्यों के लिए संक्षिप्त रूप का उपयोग कर सकते हैं और,
= के माध्यम से
, फ़ंक्शन के लिए अतिरिक्त घुंघराले ब्रेसिज़ से छुटकारा पा सकते हैं।
अनुसूची हम एक ब्लॉक में बदल जाते हैं। एक ही बात बहुत सारे डिजाइन के साथ होती है, क्योंकि हम अभी भी कोटलिन में काम करते हैं।

बाकी पर चलते हैं। घुंघराले ब्रेस फिर से दिखाई देते हैं, हम उनसे छुटकारा नहीं पाते हैं, लेकिन कम से कम हमारे उदाहरण के करीब पहुंचने की कोशिश करते हैं। रिक्त स्थान के साथ निर्माण करके, हम किसी तरह खुद को परिष्कृत कर सकते हैं और उन्हें किसी तरह अलग कर सकते हैं, लेकिन यह मुझे लगता है कि सामान्य तरीकों को बनाना बेहतर है जो प्रसंस्करण को बाधित करेगा, लेकिन सामान्य तौर पर यह उपयोगकर्ता के लिए स्पष्ट होगा ।

हमारा छात्र एक ब्लॉक में बदल जाता है जिसमें हम गुणों के साथ, विधियों के साथ काम करते हैं, और हम आपके साथ इसका विश्लेषण करना जारी रखेंगे।

अंत में, शिक्षकों। यहां हमारे पास कुछ नेस्टेड ब्लॉक हैं।

नीचे दिए गए कोड में, हम चेक पर जाते हैं। हमें जावा भाषाओं के साथ संगतता की जांच की आवश्यकता है - और हां, कोटलिन जावा के साथ संगत है।

कोटलिन में DSL विकास का शस्त्रागार

आइए हम उन उपकरणों की सूची पर चलते हैं जो हमारे पास हैं। यहां मैं एक टैबलेट लाया, हो सकता है कि यह सब कुछ सूचीबद्ध करता है जो कोटलिन में समस्या-उन्मुख भाषाओं को विकसित करने के लिए आवश्यक है। आप समय-समय पर उसके पास वापस आ सकते हैं और उसकी याददाश्त को ताज़ा कर सकते हैं।
तालिका समस्या-उन्मुख सिंटैक्स और भाषा में उपलब्ध सामान्य सिंटैक्स की कुछ तुलना दिखाती है।
कोटलिन में लम्बदा
val lambda: () -> Unit = { }आइए सबसे मूल ईंट से शुरू करें जो हमारे पास कोटलिन में हैं - ये लंबोदा हैं।
आज, लंबोदर प्रकार से, मेरा मतलब केवल एक कार्यात्मक प्रकार होगा। लंबोदर को निम्नानुसार दर्शाया जाता है:
( ) -> ।
हम घुंघराले ब्रेसिज़ की मदद से लैम्ब्डा को इनिशियलाइज़ करते हैं, उनके अंदर हम कुछ कोड लिख सकते हैं जिन्हें कहा जाएगा। यही है, एक लंबोदर, वास्तव में, इस कोड को अपने आप में छिपाता है। ऐसे लंबोदर को चलाने से एक फ़ंक्शन कॉल लगता है, बस कोष्ठक।

यदि हम किसी प्रकार के पैरामीटर को पास करना चाहते हैं, तो सबसे पहले, हमें इसका प्रकार में वर्णन करना चाहिए।
दूसरे, हमारे पास डिफ़ॉल्ट पहचानकर्ता तक पहुंच है, जिसका हम उपयोग कर सकते हैं, हालांकि, अगर यह हमें किसी भी तरह से सूट नहीं करता है, तो हम अपना स्वयं का पैरामीटर नाम सेट कर सकते हैं और उनका उपयोग कर सकते हैं।

उसी समय, हम इस पैरामीटर के उपयोग को छोड़ सकते हैं और पहचानकर्ताओं का उत्पादन न करने के लिए अंडरस्कोर का उपयोग कर सकते हैं। इस मामले में, पहचानकर्ता की उपेक्षा करने के लिए, कुछ भी नहीं लिखना संभव होगा, लेकिन सामान्य पैरामीटर में कई मापदंडों के लिए "_" उल्लेख किया गया है।

यदि हम एक से अधिक पैरामीटर पास करना चाहते हैं, तो हमें उनके पहचानकर्ताओं को स्पष्ट रूप से परिभाषित करने की आवश्यकता है।

अंत में, अगर हम लंबोदा को किसी समारोह में पास करने और उसे वहां चलाने की कोशिश करेंगे तो क्या होगा। यह प्रारंभिक सन्निकटन में निम्नानुसार दिखता है: हमारे पास एक फ़ंक्शन है जिसमें हम लंबो को घुंघराले ब्रैकेट में पास करते हैं, और यदि कोटलिन लैम्ब्डा में अंतिम पैरामीटर के रूप में लिखा जाता है, तो हम इसे इन ब्रैकेट से बाहर कर सकते हैं।

यदि कोष्ठक में कुछ भी नहीं बचा है, तो हम कोष्ठक हटा सकते हैं। ग्रूवी से परिचित लोगों को इससे परिचित होना चाहिए।

यह कहां लागू होता है? हर जगह बिल्कुल। यही है, बहुत घुंघराले ब्रेसिज़ जिनके बारे में हम पहले ही बात कर चुके हैं, हम उनका उपयोग करते हैं, ये बहुत ही लंबोदर हैं।

अब हम लंबोदर की किस्मों में से एक को देखें, मैं उन्हें संदर्भ के साथ लंबोदा कहता हूं। आपको कुछ अन्य नाम मिलेंगे, उदाहरण के लिए, रिसीवर के साथ लैम्ब्डा, और वे एक प्रकार की घोषणा करते समय साधारण लैम्ब्डा से भिन्न होते हैं: बाईं ओर, हम कुछ संदर्भ वर्ग जोड़ते हैं, यह किसी भी वर्ग हो सकता है।

यह किस लिए है? यह आवश्यक है ताकि लैम्ब्डा के अंदर हमारे पास इस कीवर्ड तक पहुंच हो - यह कीवर्ड ही है, यह हमें अपना संदर्भ बताता है, अर्थात किसी वस्तु से, जिसे हमने अपने लैम्बडा से जोड़ा है। इसलिए, उदाहरण के लिए, हम एक लैम्ब्डा बना सकते हैं जो कुछ स्ट्रिंग को आउटपुट करेगा, स्वाभाविक रूप से, हम एक संदर्भ घोषित करने के लिए स्ट्रिंग क्लास का उपयोग करेंगे और इस तरह के लैम्बडा की कॉल इस तरह दिखाई देगी:



यदि आप एक संदर्भ को एक पैरामीटर के रूप में पारित करना चाहते हैं, तो आप इसे भी कर सकते हैं। हालाँकि, हम पूरी तरह से संदर्भ को व्यक्त नहीं कर सकते हैं, अर्थात, एक संदर्भ के साथ एक लंबोदर को ध्यान देने की आवश्यकता है! - संदर्भ, हाँ। यदि हम किसी विधि के संदर्भ में लंबोतरा को पारित करना शुरू करते हैं तो क्या होगा? यहां हम अपनी निष्पादन पद्धति को फिर से देखते हैं:

इसे छात्र विधि में बदलें - कुछ भी नहीं बदला है:

इसलिए हम धीरे-धीरे अपने निर्माण, छात्र निर्माण की ओर बढ़ते हैं, जो ब्रेसिज़ के नीचे सभी आरंभिकता को छुपाता है।

चलिए इसका पता लगाते हैं। हमारे पास कुछ प्रकार के छात्र कार्य हैं जो छात्र के संदर्भ में एक लंबोदर लेते हैं।

जाहिर है, हमें संदर्भ की जरूरत है।

यहां हम एक ऑब्जेक्ट बनाते हैं और उस पर इस लैम्ब्डा को चलाते हैं।

नतीजतन, हम लंबोदा लॉन्च करने से पहले कुछ डिफ़ॉल्ट मूल्यों को भी इनिशियलाइज़ कर सकते हैं, इसलिए हम फ़ंक्शन के लिए आवश्यक सभी चीजों को इनकैप्सुलेट करते हैं।

इसके कारण, लैम्ब्डा के अंदर, हमें इस कीवर्ड तक पहुँच मिलती है - यही कारण है कि, शायद, संदर्भ के साथ लैम्ब्डा हैं।

स्वाभाविक रूप से, हम इस कीवर्ड से छुटकारा पा सकते हैं और हमें ऐसे निर्माणों को लिखने का अवसर मिलता है।

फिर, अगर हमारे पास न केवल मालिकाना है, बल्कि कुछ तरीके भी हैं, तो हम उन्हें कॉल भी कर सकते हैं, यह बहुत स्वाभाविक लगता है।

आवेदन
कोड में ये सभी लंबदा संदर्भ लंबोदर हैं। बड़ी संख्या में संदर्भ हैं, वे एक तरह से या किसी अन्य में अंतर करते हैं और हमें अपनी समस्या-उन्मुख भाषा बनाने की अनुमति देते हैं।

लंबोदर को सारांशित करना - हमारे पास साधारण लंबोदर हैं, संदर्भ के साथ हैं, और उन और अन्य का उपयोग किया जा सकता है।

ऑपरेटरों
कोटलिन के पास ऑपरेटरों का एक सीमित सेट है जिसे आप सम्मेलनों और ऑपरेटर कीवर्ड का उपयोग करके ओवरराइड कर सकते हैं।
आइए शिक्षक और उसकी पहुंच पर गौर करें। मान लीजिए कि हम कहते हैं कि शिक्षक सुबह 8 बजे से 1 घंटे के लिए काम करता है। हम यह भी कहना चाहते हैं कि, इस एक घंटे के अलावा, यह 1 घंटे के लिए 13.00 से काम करता है। मैं इसे
+ ऑपरेटर का उपयोग करके व्यक्त करना चाहता हूं। यह कैसे किया जा सकता है?

कुछ उपलब्धता विधि है जो एक
AvailabilityTable संदर्भ के साथ एक लंबो स्वीकार करता है। इसका मतलब है कि कुछ वर्ग ऐसा है जिसे कहा जाता है, और इस वर्ग में सोमवार विधि घोषित की जाती है। इस विधि के बाद से
DayPointer देता है आपको कुछ करने के लिए हमारे ऑपरेटर को संलग्न करने की आवश्यकता है।

आइए जानें कि डे पॉइन्टर क्या है। यह कुछ शिक्षक की उपलब्धता तालिका के लिए एक संकेतक है, और दिन अपने समय पर है। हमारे पास एक समय फ़ंक्शन भी है जो किसी तरह कुछ पंक्तियों को पूर्णांक सूचकांकों में बदल देगा:
IntRange हमारे पास इसके लिए एक
IntRange क्लास है।
बाईं ओर
DayPointer , दाईं ओर समय है, और हम उन्हें
+ ऑपरेटर के साथ संयोजित करना चाहेंगे। ऐसा करने के लिए, आप
DayPointer वर्ग में हमारे ऑपरेटर बना सकते हैं। यह Int के प्रकारों की एक श्रृंखला
DayPointer और
DayPointer ताकि हम अपने DSL को बार-बार चेन कर सकें।
अब, आइए मुख्य डिजाइन पर एक नज़र डालें जिसके साथ यह सब शुरू होता है, जिसके साथ हमारा डीएसएल शुरू होता है। इसका कार्यान्वयन थोड़ा अलग है, और अब हम इसका पता लगाएंगे।
कोटलिन की भाषा में एक एकल अवधारणा का निर्माण किया गया है। ऐसा करने के लिए, क्लास कीवर्ड के बजाय
object कीवर्ड का उपयोग किया जाता है। यदि हम एक सिंगलटन के अंदर एक विधि बनाते हैं, तो हम इसे इस तरह से एक्सेस कर सकते हैं कि इस वर्ग का एक उदाहरण फिर से बनाने की कोई आवश्यकता नहीं है। हम इसे एक कक्षा में एक स्थिर विधि के रूप में संदर्भित करते हैं।

यदि आप विघटन के परिणाम को देखते हैं (जो कि विकास के माहौल में है, तो उपकरण पर क्लिक करें -> कोटलिन -> कोटलिन बायटेकोड दिखाएं -> Decompile), आप निम्नलिखित सिंगलटन कार्यान्वयन देख सकते हैं:

यह सिर्फ एक साधारण वर्ग है, और यहाँ कुछ भी अलौकिक नहीं होता है।
एक और दिलचस्प उपकरण
invoke स्टेटमेंट है। कल्पना करें कि हमारे पास कुछ वर्ग ए है, हमारे पास इसका उदाहरण है, और हम इस उदाहरण को चलाना चाहते हैं, अर्थात्, इस वर्ग की एक वस्तु पर कोष्ठक को कॉल करना है, और हम इसे
invoke ऑपरेटर के लिए धन्यवाद कर सकते हैं।

वास्तव में, कोष्ठक हमें आह्वान विधि को कॉल करने की अनुमति देता है और एक ऑपरेटर संशोधक होता है। यदि हम इस ऑपरेटर के संदर्भ में एक लंबोदा पास करते हैं, तो हमें ऐसा निर्माण मिलता है।

हर बार उदाहरण बनाना एक अन्य गतिविधि है, इसलिए हम पिछले और वर्तमान ज्ञान को जोड़ सकते हैं।
चलो एक सिंगलटन बनाते हैं, इसे शेड्यूल करते हैं, इसके अंदर हम इनवोक ऑपरेटर की घोषणा करेंगे, अंदर हम एक संदर्भ बनाएंगे, और यह उस संदर्भ के साथ एक मेमना स्वीकार करेगा जो हम यहां बनाते हैं। यह हमारे डीएसएल में एक एकल प्रवेश बिंदु को बदल देता है, और, परिणामस्वरूप, हमें एक ही निर्माण मिलता है - घुंघराले ब्रेस के साथ अनुसूची।

खैर, हमने शेड्यूल के बारे में बात की, चलो हमारे चेक पर एक नज़र डालें।
हमारे पास शिक्षक हैं, हमने किसी प्रकार का शेड्यूल बनाया है, और हम यह जाँचना चाहते हैं कि इस शिक्षक की अनुसूची में किसी निश्चित दिन में एक निश्चित पाठ में कोई वस्तु है जिसके साथ हम काम करेंगे।

मैं वर्ग कोष्ठक का उपयोग करना चाहता हूं और हमारे शेड्यूल को इस तरह से एक्सेस करना चाहता हूं कि नेत्रहीन रूप से सरणियों तक पहुंच हो।

यह ऑपरेटर का उपयोग करके किया जा सकता है: प्राप्त करें / सेट करें:

यहां हम कुछ नया नहीं कर रहे हैं, बस सम्मेलनों का पालन करें। सेट ऑपरेटर के मामले में, हमें अतिरिक्त रूप से मानों को अपनी विधि में पास करना होगा:

तो, पढ़ने के लिए वर्ग कोष्ठक में बदल जाता है, और वर्ग कोष्ठक जिसके माध्यम से हम सेट में बदल जाते हैं।
डेमो: ऑब्जेक्ट, ऑपरेटर
आप या तो आगे का पाठ पढ़ सकते हैं या
यहां वीडियो देख सकते हैं । वीडियो का स्पष्ट प्रारंभ समय है, लेकिन कोई अंतिम समय निर्दिष्ट नहीं है - सिद्धांत रूप में, एक बार शुरू होने के बाद, आप इसे लेख के अंत से पहले देख सकते हैं।
सुविधा के लिए, मैं पाठ में सीधे वीडियो के सार को संक्षेप में बताऊंगा।
चलो एक परीक्षण लिखें। हमारे पास कुछ शेड्यूल ऑब्जेक्ट है, और अगर हम ctrl + b के माध्यम से इसके कार्यान्वयन पर जाते हैं, तो हम वह सब कुछ देखेंगे जो मैंने पहले के बारे में बात की थी।

शेड्यूल ऑब्जेक्ट के अंदर, हम डेटा को इनिशियलाइज़ करना चाहते हैं, फिर कुछ चेक करते हैं, और डेटा के भीतर, हम यह कहना चाहेंगे:
- हमारा स्कूल सुबह 8 बजे से खुला रहता है;
- आइटम का एक निश्चित सेट है जिसके लिए हम एक शेड्यूल बनाएंगे;
- कुछ शिक्षक हैं जिन्होंने किसी प्रकार की पहुँच का वर्णन किया है;
- एक छात्र है;
- सिद्धांत रूप में, एक छात्र के लिए हमें केवल यह कहना होगा कि वह एक विशिष्ट विषय का अध्ययन कर रहा है।

और यहां कोटलिन और समस्या-उन्मुख भाषाओं की कमियों में से एक सिद्धांत में प्रकट होता है: कुछ वस्तुओं को संबोधित करना काफी मुश्किल है जो हमने पहले बनाई थी। इस डेमो में, मैं सब कुछ सूचकांकों के रूप में इंगित करूंगा, अर्थात, रस 0 है, गणित सूचकांक 2 है। और शिक्षक स्वाभाविक रूप से कुछ का नेतृत्व भी करते हैं। वह सिर्फ काम पर नहीं जाता, बल्कि किसी काम में लगा रहता है। इस लेख के पाठकों के लिए, मैं संबोधित करने के लिए एक और विकल्प प्रदान करना चाहूंगा, आप अनन्य टैग बना सकते हैं और उन पर मानचित्र में इकाइयाँ संग्रहीत कर सकते हैं, और जब आपको उनमें से किसी एक का उपयोग करने की आवश्यकता होती है, तो आप इसे हमेशा टैग द्वारा पा सकते हैं। DSL को अलग करना जारी रखें।
यहां, क्या ध्यान दिया जाना चाहिए: सबसे पहले, हमारे पास + ऑपरेटर है, जिसके कार्यान्वयन के लिए हम भी जा सकते हैं और देख सकते हैं कि हमारे पास वास्तव में डेपॉइंटर क्लास है, जो हमें ऑपरेटर की मदद से यह सब बांधने में मदद करता है।
और इस तथ्य के लिए धन्यवाद कि हमारे पास संदर्भ तक पहुंच है, विकास का माहौल हमें बताता है कि इस कीवर्ड के माध्यम से हमारे संदर्भ में, हमारे पास कुछ संग्रह तक पहुंच है, और हम इसका उपयोग करेंगे।

यही है, हमारे पास घटनाओं का एक संग्रह है। घटना गुणों के एक समूह का उदाहरण देती है, उदाहरण के लिए: एक छात्र, एक शिक्षक, किस दिन वे किस पाठ में मिलते हैं।

हम आगे भी परीक्षा लिखना जारी रखते हैं।

यहां, फिर से, हम प्राप्त ऑपरेटर का उपयोग करते हैं, इसके कार्यान्वयन के लिए इतना आसान नहीं है, लेकिन हम इसे कर सकते हैं।

वास्तव में, हम केवल समझौते का पालन करते हैं, इसलिए हमें इस डिजाइन तक पहुंच प्राप्त होती है।
आइए प्रस्तुति पर वापस जाते हैं और कोटलिन के बारे में बातचीत जारी रखते हैं। हम कोटलिन पर लागू चेक चाहते थे, और हम इन घटनाओं से गुजरे:

एक घटना अनिवार्य रूप से 4 संपत्तियों का एक समझाया सेट है। मैं इस घटना को टपल की तरह गुणों के एक समूह में विघटित करना चाहूंगा। रूसी में, इस तरह के निर्माण को
बहु-घोषणा कहा जाता है (मुझे केवल ऐसा अनुवाद मिला), या
विनाशकारी घोषणा , और यह निम्नानुसार काम करता है:

यदि आप में से कोई भी इस सुविधा से परिचित नहीं है, तो यह इस तरह से काम करता है: आप ईवेंट ले सकते हैं, और जिस स्थान पर इसका उपयोग किया जाता है, कोष्ठक का उपयोग करते हुए, इसे गुणों के एक सेट में विघटित करते हैं।

यह इसलिए काम करता है क्योंकि हमारे पास एक कंपोनेंट मेथड है, अर्थात यह एक ऐसा तरीका है जो कंपाइलर द्वारा डेटा मॉडिफायर के कारण होता है जिसे हम क्लास से पहले लिखते हैं।

इसके साथ ही, बड़ी संख्या में अन्य तरीके हमारे लिए उड़ान भरते हैं। हम कंपोनेंट विधि में रुचि रखते हैं, जो प्राथमिक कंस्ट्रक्टर के मापदंडों की सूची में सूचीबद्ध गुणों के आधार पर उत्पन्न होती है।

यदि हमारे पास डेटा संशोधक नहीं है, तो एक ऑपरेटर को मैन्युअल रूप से लिखना आवश्यक होगा जो एक ही काम करेगा।


इसलिए, हमारे पास कुछ कंपोनेंट विधियां हैं, और वे इस तरह के कॉल में विघटित होते हैं:

संक्षेप में, यह कई विधियों के आह्वान पर वाक्यगत शर्करा है।
हमने पहले से ही उपलब्धता की कुछ तालिका के बारे में बात की है, और वास्तव में, मैंने आपको धोखा दिया है। ऐसा होता है। कोई
avaiabilityTable मौजूद नहीं है, यह प्रकृति में नहीं है, लेकिन बूलियन मूल्यों का एक मैट्रिक्स है।

किसी अतिरिक्त वर्ग की आवश्यकता नहीं है: आप बूलियन मूल्यों के मैट्रिक्स को ले सकते हैं और अधिक स्पष्टता के लिए इसका नाम बदल सकते हैं। यह तथाकथित
टाइपेलियास या
टाइप उर्फ का उपयोग करके किया जा सकता है। दुर्भाग्य से, हमें इससे कोई अतिरिक्त बोनस नहीं मिलता है, यह सिर्फ एक नामकरण है। यदि आप उपलब्धता लेते हैं और इसे बूलियन मूल्यों के मैट्रिक्स में वापस नाम देते हैं, तो कुछ भी नहीं बदलेगा। कोड काम किया और काम करेगा।
आइए शिक्षक पर एक नज़र डालें, यह वास्तव में इस पहुंच है, और उसके बारे में बात करते हैं:
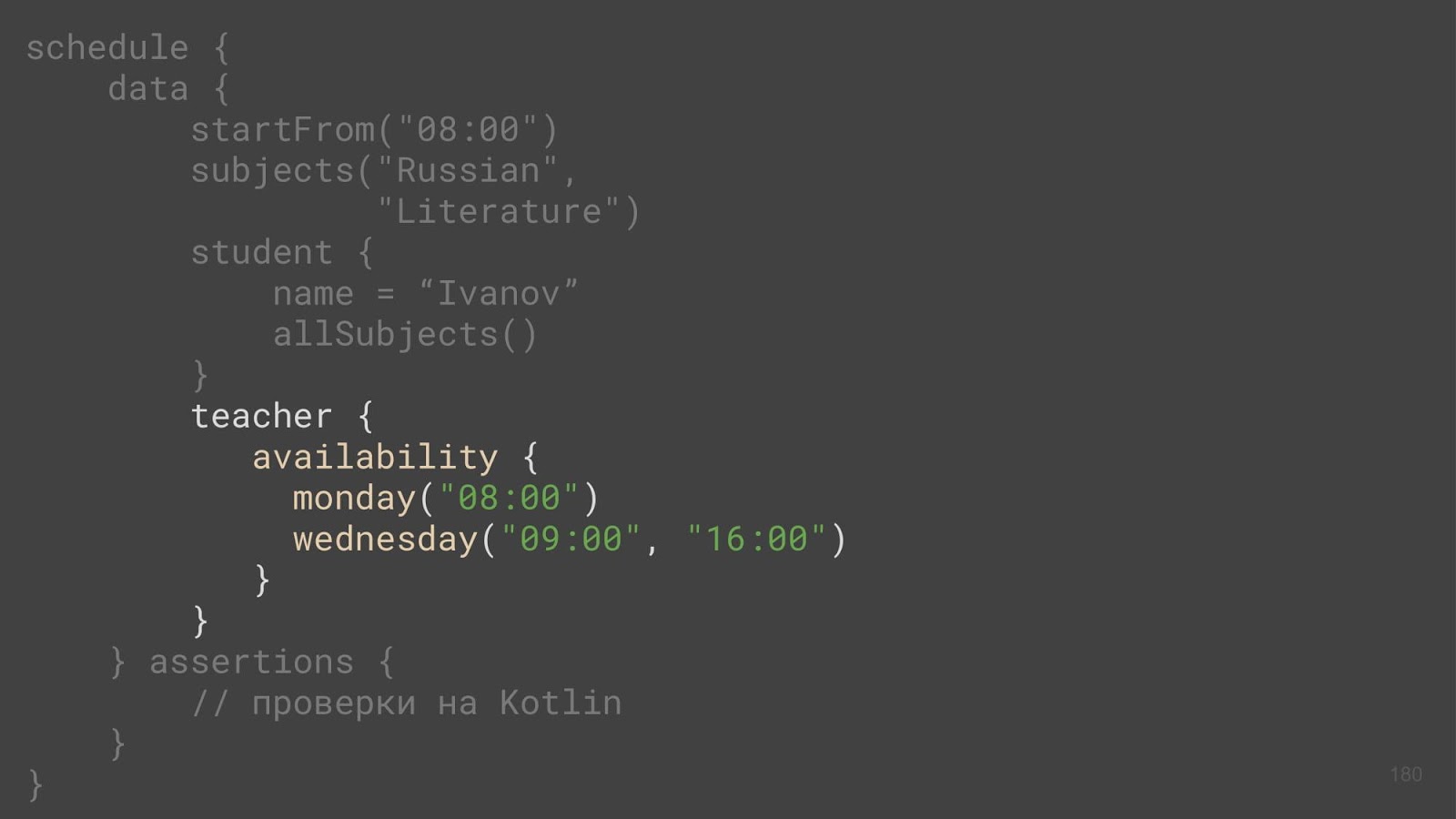
हमारे पास एक शिक्षक है, और उपलब्धता विधि कहा जाता है (क्या आपने अभी तक तर्क का धागा नहीं खोया है? :-) वह कहां से आया? यही है, एक शिक्षक कुछ प्रकार की संस्था है जिसमें एक वर्ग है, और यह एक व्यावसायिक कोड है। और कोई अतिरिक्त विधि नहीं हो सकती है।

यह विधि विस्तार कार्यों के कारण दिखाई देती है। हम अपनी कक्षा में कुछ अन्य प्रकार्य लेते हैं और उपवास करते हैं जिसे हम इस वर्ग की वस्तुओं पर चला सकते हैं।
यदि हम इस फ़ंक्शन में कुछ लंबो पास करते हैं, और फिर इसे किसी मौजूदा संपत्ति पर चलाते हैं, तो सब कुछ ठीक है - इसके कार्यान्वयन में उपलब्धता विधि उपलब्धता संपत्ति को आरंभीकृत करती है। आप इससे छुटकारा पा सकते हैं। हम पहले से ही आह्वान ऑपरेटर के बारे में जानते हैं, जो एक प्रकार से जुड़ा हो सकता है, और एक ही समय में एक एक्सटेंशन फ़ंक्शन हो सकता है। यदि आप इस ऑपरेटर के लिए एक लैम्ब्डा पास करते हैं, तो वहीं, इस कीवर्ड पर, हम इस लैम्ब्डा को चला सकते हैं। नतीजतन, जब हम एक शिक्षक के साथ काम करते हैं, तो एक्सेसिबिलिटी शिक्षक की एक संपत्ति होती है, न कि कुछ अतिरिक्त विधि, और यहां कोई रस्सिनस्ट्रक्चर नहीं होता है।

एक बोनस के रूप में, विस्तार कार्यों को अशक्त प्रकारों के लिए बनाया जा सकता है। यह अच्छा है, क्योंकि अगर अशक्त प्रकार के साथ एक चर है, जिसमें एक अशक्त मान है, तो हमारा फ़ंक्शन इसके लिए पहले से ही तैयार है, और NullPointer से नहीं गिरेगा। इस फ़ंक्शन के अंदर, यह अशक्त हो सकता है, और इसे संभालने की आवश्यकता है।

विस्तार कार्यों को सारांशित करना: आपको यह समझने की आवश्यकता है कि केवल कक्षा के सार्वजनिक एपीआई तक ही पहुँच है, और वर्ग को किसी भी तरह से संशोधित नहीं किया गया है। एक विस्तार फ़ंक्शन चर के प्रकार से निर्धारित होता है, और वास्तविक प्रकार से नहीं। इसके अलावा, एक ही हस्ताक्षर वाले वर्ग के एक सदस्य को प्राथमिकता दी जाएगी। आप एक वर्ग के लिए एक एक्सटेंशन फ़ंक्शन बना सकते हैं, लेकिन इसे पूरी तरह से अलग कक्षा में लिख सकते हैं, और इस एक्सटेंशन फ़ंक्शन के अंदर एक साथ दो संदर्भों तक पहुंच होगी। यह संदर्भों के प्रतिच्छेदन को दर्शाता है। और अंत में, यह सामान्य रूप से किसी भी स्थान पर ऑपरेटरों को लेने और जकड़ने का एक शानदार अवसर है जहां हम चाहते हैं।

अगला उपकरण infix फ़ंक्शन है। डेवलपर के हाथों में एक और खतरनाक हथौड़ा। क्यों खतरनाक है? आप जो देख रहे हैं वह कोड है। इस तरह के कोड को कोटलिन में लिखा जा सकता है, और यह मत करो! कृपया ऐसा न करें। फिर भी, दृष्टिकोण अच्छा है। इसके लिए धन्यवाद, डॉट्स, कोष्ठक से छुटकारा पाना संभव है - उस सभी शोर सिंटैक्स से, जहां से हम जितना संभव हो उतना दूर होने की कोशिश कर रहे हैं और हमारे कोड को थोड़ा क्लीनर बना सकते हैं।

यह कैसे काम करता है? आइए एक सरल उदाहरण लेते हैं - एक पूर्णांक चर। चलो इसके लिए एक एक्सटेंशन फ़ंक्शन बनाएं, चलो इसे कॉल करेंबेकल, यह कुछ करेगा, लेकिन यह दिलचस्प नहीं है। यदि हम इसके बाईं ओर infix संशोधक जोड़ते हैं, तो यह पर्याप्त है। आप डॉट्स और ब्रैकेट से छुटकारा पा सकते हैं, लेकिन कुछ बारीकियां हैं।

इसके आधार पर, बस डेटा और अभिकथन निर्माण को लागू किया जाता है, एक साथ बन्धन किया जाता है।

चलिए इसका पता लगाते हैं। हमारे पास शेड्यूलिंग स्टार्टअप का सामान्य संदर्भ - एक शेड्यूलिंगकोटेक्स्ट है। एक डेटा फ़ंक्शन है जो इस योजना का परिणाम देता है। उसी समय, हम एक एक्सटेंशन फ़ंक्शन बनाते हैं और एक ही समय में इनफ़िक्स फ़ंक्शन का दावा करते हैं, जो एक लंबो लॉन्च करेगा जो हमारे मूल्यों की जांच करता है।

एक विषय, वस्तु और कार्रवाई है, और आपको किसी तरह उन्हें कनेक्ट करने की आवश्यकता है। इस मामले में, घुंघराले ब्रेस के साथ डेटा निष्पादित करने का परिणाम विषय है। हम जिस लैम्बडा को अभिकथन विधि से पास करते हैं वह एक वस्तु है, और अभिकथन विधि स्वयं एक क्रिया है। यह सब एक साथ रहने लगता है।

फ़ंक्शन इन्फिक्स की बात करें, तो यह समझना महत्वपूर्ण है कि यह शोर सिंटैक्स से छुटकारा पाने के लिए एक कदम है। हालाँकि, हमारे पास इस कार्रवाई का एक विषय और एक वस्तु होनी चाहिए, और हमें infix संशोधक का उपयोग करने की आवश्यकता है। ठीक एक पैरामीटर हो सकता है - अर्थात, शून्य पैरामीटर नहीं हो सकता है, दो नहीं हो सकते हैं, तीन - ठीक है, आप समझते हैं। आप इस फ़ंक्शन के लिए, उदाहरण के लिए, लैम्ब्डा पास कर सकते हैं, और इस तरह से निर्माण करते हैं जो आपने पहले नहीं देखा है।
चलो अगले डेमो पर चलते हैं। वीडियो देखना बेहतर है, न कि टेक्स्ट पढ़ना।
अब सब कुछ तैयार दिखता है: आपने देखा गया फ़ंक्शन infix, आपके द्वारा देखे गए फ़ंक्शन का विस्तार, विनाशकारी घोषणा तैयार है।
आइए अपनी प्रस्तुति पर वापस जाएं, और यहां हम समस्या-उन्मुख भाषाओं का निर्माण करते समय एक महत्वपूर्ण बिंदु पर आगे बढ़ेंगे - संदर्भ नियंत्रण के बारे में आपको क्या सोचना चाहिए।

ऐसी स्थितियां हैं जब हम डीएसएल ले सकते हैं और इसे सही तरीके से इसके अंदर पुन: उपयोग कर सकते हैं, लेकिन हम ऐसा नहीं करना चाहते हैं। हमारा उपयोगकर्ता (संभवतः एक अनुभवहीन उपयोगकर्ता) डेटा के अंदर डेटा लिखता है, और इससे कोई मतलब नहीं है। हम किसी भी तरह उसे ऐसा करने से मना करेंगे।
कोटलिन संस्करण 1.1 से पहले, हमें निम्न कार्य करना था: इस तथ्य के जवाब में कि हमारे पास
SchedulingContext में एक डेटा विधि है, हमें
DataContext में एक और डेटा विधि तैयार करनी थी, जिसमें हम एक लैम्ब्डा स्वीकार करते हैं (कार्यान्वयन के बिना एलिट)। एनोटेशन
@Deprecated और संकलनकर्ता को यह संकलन न करने के लिए कहें। आप देखते हैं कि यह विधि शुरू होती है - संकलन न करें। इस दृष्टिकोण का उपयोग करते हुए, हम तब भी कुछ सार्थक संदेश प्राप्त करते हैं जब हम अर्थहीन कोड लिखते हैं।

संस्करण Kotlin 1.1 के बाद, एक अद्भुत एनोटेशन
@DslMarker । व्युत्पन्न एनोटेशन को ध्वजांकित करने के लिए इस एनोटेशन की आवश्यकता है। उनके साथ, बदले में, हम समस्या-उन्मुख भाषाओं को चिह्नित करेंगे। प्रत्येक समस्या-उन्मुख भाषा के लिए, आप एक एनोटेशन बना सकते हैं जिसे आप
@DslMarker चिह्नित
@DslMarker और इसे प्रत्येक संदर्भ पर लटकाते हैं जो आवश्यक है। अतिरिक्त तरीकों को लिखने की आवश्यकता नहीं है जो संकलन से निषिद्ध होना चाहिए - यह सब काम करता है। संकलित नहीं।
हालांकि, एक ऐसा विशेष मामला है जब हम अपने बिजनेस मॉडल के साथ काम करते हैं। यह आमतौर पर जावा में लिखा जाता है। , , . , ?
Student . – -, Kotlin .


- , : . , , .

.
- , . StudentContext. , . – , , , .
- – , , . . StudentContext , IStudent . , Student, IStudent StudentContext. DslMarker , .
- : deprecated . , . , . extension-, . .

, , , .

. . , , , . , . @DslMarker, . , @DslMarker, @Deprecated, , .
, :

-, DSL. , DSL . , , , .
, - , , , , - , . ? for — . DSL, , , DSL. this it. , Kotlin 1.2.20 , . , it.
. DSL, --, , . , . , , , - , , . . , - , ..
, . , - – DSL. , Kotlin-, . , DSL , , Kotlin- . -? Gradle-, , , , - . - , , – , DSL.

DSL' , . , . , DSL , , . - – . -, - . , - .
, Kotlin. , , , , , , . (, - , ), , DSL , , , . .
«», . , Kotlin . , , . , — , .
, DSL. , - . DSL, , 10 , , - . DSL – , , .
, . , Telegram:
@ivan_osipov , Twitter:
@_osipov_ , :
i_osipov . .
विज्ञापन का मिनट। JPoint — , 19-20 - Joker 2018 — Java-. . , .