
मैं Habr के पाठकों का स्वागत करता हूँ। आपका ध्यान लेख के अनुवाद के लिए आमंत्रित किया गया है
"एआई के बारे में आपको जो कुछ भी जानने की जरूरत है - 8 मिनट के भीतर।" । सामग्री उन लोगों के उद्देश्य से है जो एआई के क्षेत्र से परिचित नहीं हैं और जो इसके बारे में एक सामान्य विचार प्राप्त करना चाहते हैं, तो, शायद, इसकी किसी भी विशिष्ट शाखा में तल्लीन करना।
कभी-कभी एक चीज के बारे में बहुत कुछ जानने की तुलना में सब कुछ के बारे में थोड़ा जानना (कम से कम शुरुआती के लिए लोकप्रिय तकनीकी क्षेत्रों में नेविगेट करने की कोशिश करना) के लिए यह अधिक उपयोगी है।
बहुत से लोग सोचते हैं कि वे एआई से थोड़ा परिचित हैं। लेकिन यह क्षेत्र इतना युवा और इतना तेजी से बढ़ रहा है कि लगभग हर दिन ब्रेकआउट होते हैं। इस वैज्ञानिक क्षेत्र में खोज करने के लिए इतना कुछ है कि अन्य क्षेत्रों के विशेषज्ञ जल्दी से एआई अनुसंधान में शामिल हो सकते हैं और महत्वपूर्ण परिणाम प्राप्त कर सकते हैं।
यह लेख सिर्फ उनके लिए है। मैंने खुद को एक छोटी संदर्भ सामग्री बनाने का लक्ष्य निर्धारित किया, जो तकनीकी रूप से शिक्षित लोगों को एआई को विकसित करने के लिए इस्तेमाल की जाने वाली शब्दावली और उपकरणों को जल्दी से समझने की अनुमति देगा। मुझे उम्मीद है कि यह सामग्री एआई में रुचि रखने वाले ज्यादातर लोगों के लिए उपयोगी होगी जो इस क्षेत्र में विशेषज्ञ नहीं हैं।
परिचय
आर्टिफिशियल इंटेलिजेंस (एआई), मशीन लर्निंग और न्यूरल नेटवर्क का उपयोग मशीन लर्निंग पर आधारित शक्तिशाली तकनीकों का वर्णन करने के लिए किया जाता है जो वास्तविक दुनिया से कई समस्याओं को हल कर सकते हैं।
विचार करते समय, निर्णय लेना आदि। मशीनों में मानव मस्तिष्क की क्षमताओं की तुलना में, वे आदर्श से दूर हैं (वे आदर्श नहीं हैं, ज़ाहिर है, मनुष्यों में भी), हाल ही में, एआई प्रौद्योगिकियों और संबंधित एल्गोरिदम के क्षेत्र में कई महत्वपूर्ण खोजें की गई हैं। प्रशिक्षण एआई के लिए उपलब्ध विविध डेटा के बड़े नमूनों की बढ़ती संख्या द्वारा एक महत्वपूर्ण भूमिका निभाई जाती है।
एआई का क्षेत्र गणित, सांख्यिकी, संभाव्यता सिद्धांत, भौतिकी, सिग्नल प्रोसेसिंग, मशीन लर्निंग, कंप्यूटर विजन, मनोविज्ञान, भाषा विज्ञान और मस्तिष्क के विज्ञान सहित कई अन्य क्षेत्रों के साथ प्रतिच्छेद करता है। सामाजिक जिम्मेदारी से संबंधित मुद्दे और एआई बनाने की नैतिकता दर्शन में शामिल इच्छुक लोगों को आकर्षित करती है।
एआई प्रौद्योगिकी के विकास के लिए प्रेरणा यह है कि कई परिवर्तनीय कारकों पर निर्भर करने वाले कार्यों के लिए बहुत जटिल समाधानों की आवश्यकता होती है जिन्हें समझना मुश्किल है और मैन्युअल रूप से एल्गोरिदम को कठिन बनाना है।
मशीन लर्निंग के लिए निगमों, शोधकर्ताओं और आम लोगों की उम्मीदें उन समस्याओं के समाधान प्राप्त करने के लिए बढ़ रही हैं जिन्हें किसी व्यक्ति को विशिष्ट एल्गोरिदम का वर्णन करने की आवश्यकता नहीं है। ब्लैक बॉक्स दृष्टिकोण पर बहुत ध्यान दिया जाता है। मॉडलिंग के लिए उपयोग किए जाने वाले एल्गोरिदम का प्रोग्रामिंग करना और बड़ी मात्रा में डेटा से जुड़ी समस्याओं को हल करना डेवलपर्स से बहुत समय लेता है। यहां तक कि जब हम कोड लिखने का प्रबंधन करते हैं जो बड़ी मात्रा में विभिन्न डेटा को संसाधित करता है, तो यह अक्सर बहुत बोझिल हो जाता है, इसे बनाए रखना मुश्किल होता है और परीक्षण करना कठिन होता है (परीक्षणों के लिए भी बड़ी मात्रा में डेटा का उपयोग करने की आवश्यकता के कारण)।
मशीन लर्निंग और एआई की आधुनिक प्रौद्योगिकियां, सिस्टम के लिए सही ढंग से चयनित और तैयार "प्रशिक्षण" डेटा के साथ मिलकर हमें कंप्यूटर सिखाने के लिए अनुमति दे सकती हैं कि हमारे साथ कैसे प्रोग्राम करें।

सिंहावलोकन
बुद्धिमत्ता - वातावरण या संदर्भ में अनुकूली व्यवहार के निर्माण के लिए सूचना को देखने और उसे ज्ञान के रूप में सहेजने की क्षमता(अंग्रेजी) विकिपीडिया से बुद्धिमत्ता की इस परिभाषा को कार्बनिक मस्तिष्क और मशीन दोनों पर लागू किया जा सकता है।
बुद्धि की उपस्थिति चेतना की उपस्थिति का अर्थ नहीं है । यह विज्ञान कथा लेखकों द्वारा दुनिया के लिए एक आम गलत धारणा है।
AI के उदाहरणों के लिए इंटरनेट पर खोज करने का प्रयास करें - और आप शायद मशीन लर्निंग एल्गोरिदम का उपयोग करके IBM Watson के लिए कम से कम एक लिंक प्राप्त करेंगे, जो 2011 में "Jeopardy" नामक गेम शो जीतने के बाद प्रसिद्ध हो गया था। तब से, एल्गोरिथ्म में कुछ बदलाव हुए हैं और इसका उपयोग किया गया था कई अलग-अलग वाणिज्यिक अनुप्रयोगों के लिए एक टेम्पलेट के रूप में। Apple, Amazon और Google सक्रिय रूप से हमारे घरों और जेबों में समान सिस्टम बनाने के लिए काम कर रहे हैं।
प्राकृतिक भाषा प्रसंस्करण और भाषण मान्यता मशीन सीखने के व्यावसायिक उपयोग के पहले उदाहरण थे। उनके बाद कार्य दिखाई दिए, मान्यता स्वचालन के अन्य कार्य (पाठ, ऑडियो, चित्र, वीडियो, चेहरे, आदि)। इन प्रौद्योगिकियों के अनुप्रयोगों की श्रेणी लगातार बढ़ रही है और इसमें मानव रहित वाहन, चिकित्सा निदान, कंप्यूटर गेम, खोज इंजन, स्पैम फ़िल्टर, अपराध नियंत्रण, विपणन, रोबोट नियंत्रण, कंप्यूटर दृष्टि, परिवहन, संगीत मान्यता और बहुत कुछ शामिल हैं।
एआई आधुनिक प्रौद्योगिकियों में इतनी कसकर अंतर्निहित है कि हम इसका उपयोग करते हैं कि कई इसे "एआई" के रूप में भी नहीं सोचते हैं, अर्थात, वे इसे पारंपरिक कंप्यूटर प्रौद्योगिकियों से अलग नहीं करते हैं। किसी भी राहगीर से पूछें कि क्या उसके स्मार्टफोन में कृत्रिम बुद्धिमत्ता है, और वह शायद जवाब देगा: "नहीं"। लेकिन एआई एल्गोरिदम हर जगह हैं: दर्ज किए गए पाठ की भविष्यवाणी करने से लेकर कैमरे के स्वचालित फोकस तक। कई लोग मानते हैं कि एआई को भविष्य में दिखाई देना चाहिए। लेकिन वह कुछ समय पहले दिखाई दिया और पहले से ही यहां है।
"एआई" शब्द काफी सामान्यीकृत है। अधिकांश शोध अब तंत्रिका नेटवर्क और गहन शिक्षण के एक संकीर्ण क्षेत्र पर ध्यान केंद्रित कर रहे हैं।
हमारा दिमाग कैसे काम करता है
मानव मस्तिष्क एक जटिल कार्बन कंप्यूटर है, जो किसी न किसी अनुमान के अनुसार, 20 वाट ऊर्जा की खपत करते हुए, प्रति सेकंड (1000 पेटाफ्लॉप्स) एक बिलियन अरब ऑपरेशन करता है। एक चीनी सुपरकंप्यूटर जिसे "तियानहे -2" (लेखन के समय दुनिया में सबसे तेज) कहा जाता है, प्रति सेकंड 33,860 ट्रिलियन ऑपरेशन (33.86 पेटाफ्लॉप्स) करता है और 1,600,000 वाट (17.6 मेगावाट) की खपत करता है। हमारे सिलिकॉन कंप्यूटरों के विकास के परिणामस्वरूप बनने वाले कार्बन की तुलना करने से पहले हमें एक निश्चित मात्रा में काम करना होगा।
हमारे दिमाग द्वारा "सोचने" के लिए उपयोग किए जाने वाले तंत्र का सटीक विवरण चर्चा और आगे के शोध का विषय है (मैं व्यक्तिगत रूप से इस सिद्धांत को पसंद करता हूं कि मस्तिष्क का काम क्वांटम प्रभावों से जुड़ा है, लेकिन यह एक अन्य लेख के लिए एक विषय है)। हालांकि, मस्तिष्क के अंगों के काम का तंत्र आमतौर पर न्यूरॉन्स और तंत्रिका नेटवर्क की अवधारणा का उपयोग करके बनाया गया है। अनुमान है कि मस्तिष्क में लगभग 100 बिलियन न्यूरॉन होते हैं।
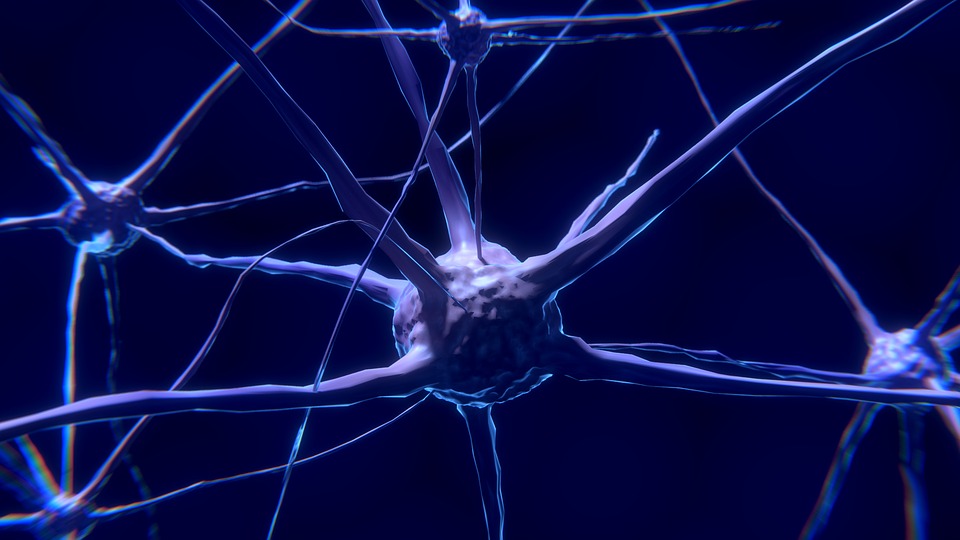
न्यूरॉन्स विशेष चैनलों का उपयोग करते हुए एक दूसरे के साथ बातचीत करते हैं जो उन्हें सूचनाओं के आदान-प्रदान की अनुमति देते हैं। व्यक्तिगत न्यूरॉन्स के संकेतों को अन्य न्यूरॉन्स को सक्रिय करने से पहले एक दूसरे के साथ तौला और संयुक्त किया जाता है। प्रेषित संदेशों की यह प्रक्रिया, अन्य न्यूरॉन्स के संयोजन और सक्रियण को मस्तिष्क की विभिन्न परतों में दोहराया जाता है। यह देखते हुए कि हमारे मस्तिष्क में 100 बिलियन न्यूरॉन हैं, इन संकेतों के भारित संयोजनों की समग्रता काफी जटिल है। और यही कहना है कि कम से कम।
लेकिन बात यहीं खत्म नहीं होती है। प्रत्येक न्यूरॉन एक सक्रियता या परिवर्तन को लागू करता है, भारित इनपुट संकेतों की जाँच करने से पहले कि क्या इसकी सक्रियता सीमा तक पहुँच गई है। इनपुट सिग्नल का रूपांतरण रैखिक या गैर-रैखिक हो सकता है।
प्रारंभ में, इनपुट सिग्नल विभिन्न स्रोतों से आते हैं: हमारी इंद्रियां, शरीर के कामकाज की आंतरिक निगरानी (रक्त में ऑक्सीजन का स्तर, पेट की सामग्री, आदि) और अन्य। एक एकल न्यूरॉन सैकड़ों हज़ारों इनपुट संकेतों को प्राप्त करने से पहले यह तय कर सकता है कि कैसे प्रतिक्रिया दें।
सोच (या सूचना प्रसंस्करण) और इसके परिणामस्वरूप होने वाले निर्देश, हमारी मांसपेशियों और अन्य अंगों को प्रेषित तंत्रिका नेटवर्क की विभिन्न परतों से न्यूरॉन्स के बीच इनपुट संकेतों के रूपांतरण और संचरण का परिणाम है। लेकिन मस्तिष्क में तंत्रिका नेटवर्क को बदल दिया जा सकता है और अद्यतन किया जा सकता है, जिसमें न्यूरॉन्स के बीच प्रेषित संकेतों को भारित करने के लिए एल्गोरिथ्म में परिवर्तन शामिल है। यह सीखने और अनुभव के कारण है।
मानव मस्तिष्क के इस मॉडल का उपयोग कंप्यूटर सिमुलेशन में मस्तिष्क की क्षमताओं को पुन: पेश करने के लिए एक टेम्पलेट के रूप में किया गया था - एक कृत्रिम तंत्रिका नेटवर्क।
कृत्रिम तंत्रिका नेटवर्क (एएनएन)
कृत्रिम तंत्रिका नेटवर्क जैविक तंत्रिका नेटवर्क के साथ सादृश्य द्वारा बनाए गए गणितीय मॉडल हैं। एएनएन इनपुट और आउटपुट सिग्नल के बीच गैर-संबंध संबंधों को मॉडल और संसाधित करने में सक्षम हैं। कृत्रिम न्यूरॉन्स के बीच संकेतों के अनुकूली भार को एक लर्निंग एल्गोरिदम के लिए प्राप्त किया जाता है जो अवलोकन किए गए डेटा को पढ़ता है और उनके प्रसंस्करण के परिणामों को बेहतर बनाने की कोशिश करता है।

एएनएन के संचालन में सुधार के लिए, विभिन्न अनुकूलन तकनीकों का उपयोग किया जाता है। ऑप्टिमाइज़ेशन को सफल माना जाता है यदि ANN किसी समय में स्थापित फ्रेमवर्क से अधिक समय में कार्य को हल कर सकता है (समय सीमा, निश्चित रूप से, कार्य से कार्य के लिए भिन्न)।
ANN को न्यूरॉन्स की कई परतों का उपयोग करके बनाया गया है। इन परतों की संरचना को मॉडल वास्तुकला कहा जाता है। न्यूरॉन्स अलग-अलग कम्प्यूटेशनल इकाइयाँ हैं जो इनपुट डेटा प्राप्त कर सकते हैं और इस डेटा को आगे स्थानांतरित करने के लिए यह निर्धारित करने के लिए कुछ गणितीय फ़ंक्शन लागू कर सकते हैं।
एक साधारण तीन-परत मॉडल में, पहली परत एक इनपुट परत है, उसके बाद एक छिपी हुई परत और उसके बाद एक आउटपुट परत। प्रत्येक परत में कम से कम एक न्यूरॉन होता है।
जैसा कि मॉडल की संरचना परतों और न्यूरॉन्स की संख्या में वृद्धि करके जटिल है, एएनएन समस्याओं को हल करने की क्षमता बढ़ जाती है। हालांकि, यदि किसी दिए गए कार्य के लिए मॉडल बहुत "बड़ा" है, तो इसे वांछित स्तर पर अनुकूलित नहीं किया जा सकता है। इस घटना को
ओवरफिटिंग कहा जाता
है ।
डेटा प्रोसेसिंग एल्गोरिदम की वास्तुकला, कॉन्फ़िगरेशन और चयन एएनएन के निर्माण के मुख्य घटक हैं। ये सभी घटक मॉडल के प्रदर्शन और समग्र प्रदर्शन को निर्धारित करते हैं।
मॉडल अक्सर तथाकथित
सक्रियण फ़ंक्शन द्वारा विशेषता होते हैं। इसका उपयोग एक न्यूरॉन के भारित इनपुट को अपने आउटपुट में बदलने के लिए किया जाता है (यदि एक न्यूरॉन डेटा को आगे स्थानांतरित करने का निर्णय लेता है, तो इसे इसका सक्रियण कहा जाता है)। कई अलग-अलग परिवर्तन हैं जिन्हें सक्रियण कार्यों के रूप में उपयोग किया जा सकता है।
ANN समस्याओं को हल करने का एक शक्तिशाली साधन हैं। हालाँकि, हालांकि, छोटी संख्या में न्यूरॉन्स का गणितीय मॉडल काफी सरल है, एक तंत्रिका नेटवर्क का मॉडल इसके घटक भागों की संख्या में वृद्धि के साथ काफी भ्रमित हो जाता है। इस वजह से, एएनएन के उपयोग को कभी-कभी ब्लैक बॉक्स दृष्टिकोण कहा जाता है। समस्या को हल करने के लिए ANN की पसंद पर सावधानी से विचार किया जाना चाहिए, क्योंकि कई मामलों में परिणामी अंतिम समाधान को विघटित नहीं किया जा सकता है और इसका विश्लेषण किया जा सकता है कि यह ऐसा क्यों हो गया है।

गहरी सीख
गहरा सीखने शब्द
का उपयोग तंत्रिका नेटवर्क और उनमें उपयोग किए जाने वाले एल्गोरिदम का वर्णन करने के लिए किया जाता है जो कच्चे डेटा प्राप्त करते हैं (जिसमें से कुछ उपयोगी जानकारी की आवश्यकता होती है)। यह डेटा वांछित आउटपुट प्राप्त करने के लिए तंत्रिका नेटवर्क की परतों से गुजरने के लिए संसाधित किया जाता है।
Unsupervised Learning एक ऐसा क्षेत्र है जिसमें गहरी सीखने की तकनीक बहुत अच्छा प्रदर्शन करती है। एक सही ढंग से कॉन्फ़िगर किया गया ANN इनपुट डेटा की मुख्य विशेषताओं को स्वचालित रूप से निर्धारित करने में सक्षम है (चाहे वह पाठ, चित्र या अन्य डेटा हो) और उनके प्रसंस्करण का एक उपयोगी परिणाम प्राप्त करें। गहन प्रशिक्षण के बिना, महत्वपूर्ण जानकारी की खोज अक्सर एक प्रोग्रामर के कंधों पर आती है जो उन्हें प्रसंस्करण के लिए एक प्रणाली विकसित करता है। गहन शिक्षण मॉडल, अपने दम पर, डेटा को संसाधित करने का एक तरीका खोजने में सक्षम है जो आपको उनसे उपयोगी जानकारी निकालने की अनुमति देता है। जब सिस्टम को प्रशिक्षित किया जाता है (अर्थात, यह इनपुट डेटा से उपयोगी जानकारी निकालने का बहुत ही तरीका है), मॉडल को बनाए रखने के लिए कंप्यूटिंग शक्ति, मेमोरी और ऊर्जा की आवश्यकताएं कम हो जाती हैं।
सीधे शब्दों में कहें, लर्निंग एल्गोरिदम एक विशेष कार्य करने के लिए एक कार्यक्रम "ट्रेन" के लिए विशेष रूप से तैयार डेटा का उपयोग करने की अनुमति देता है।
डीप लर्निंग का उपयोग समस्याओं की एक विस्तृत श्रृंखला को हल करने के लिए किया जाता है और इसे अभिनव AI प्रौद्योगिकियों में से एक माना जाता है। अन्य प्रकार के प्रशिक्षण भी हैं, जैसे कि
पर्यवेक्षित शिक्षण और
अर्ध-पर्यवेक्षित शिक्षण , जो डेटा प्रोसेसिंग में न्यूरल नेटवर्क को प्रशिक्षित करने के मध्यवर्ती परिणामों पर अतिरिक्त मानव नियंत्रण की शुरुआत से प्रतिष्ठित हैं (यह निर्धारित करने में मदद करता है कि क्या सही दिशा में है चलती प्रणाली)।
शैडो लर्निंग (
शैडो लर्निंग ) - एक शब्द जिसका उपयोग गहन शिक्षण के सरलीकृत रूप का वर्णन करने के लिए किया जाता है, जिसमें डेटा की प्रमुख विशेषताओं की खोज एक व्यक्ति द्वारा उनके प्रसंस्करण से पहले की जाती है और इस डेटा से संबंधित उस क्षेत्र के लिए विशिष्ट जानकारी दर्ज करती है। इस तरह के मॉडल अधिक "पारदर्शी" (परिणाम प्राप्त करने के अर्थ में) और सिस्टम के डिजाइन में निवेश किए गए समय में वृद्धि के कारण उच्च प्रदर्शन हैं।
निष्कर्ष
AI एक शक्तिशाली डेटा प्रोसेसिंग टूल है और प्रोग्रामर द्वारा लिखे गए पारंपरिक एल्गोरिदम की तुलना में तेजी से जटिल समस्याओं का समाधान पा सकता है। एएनएन और डीप लर्निंग तकनीक विभिन्न प्रकार की कई समस्याओं को हल करने में मदद कर सकते हैं। नकारात्मक पक्ष यह है कि सबसे अनुकूलित मॉडल अक्सर "ब्लैक बॉक्स" के रूप में काम करते हैं, जिससे एक या किसी अन्य समाधान को चुनने के कारणों का अध्ययन करना असंभव हो जाता है। यह तथ्य सूचना की पारदर्शिता से संबंधित नैतिक मुद्दों को जन्म दे सकता है।