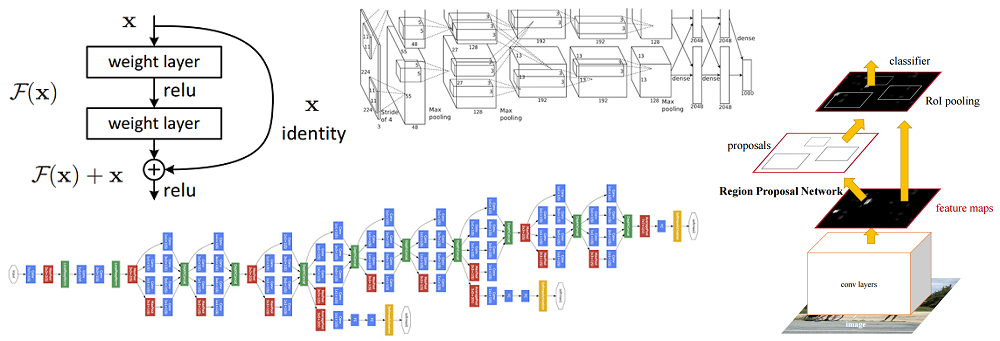
एक पिछले लेख में,
छवि वर्गीकरण के लिए तंत्रिका नेटवर्क का अवलोकन , हमने खुद को प्रासंगिक तंत्रिका नेटवर्क की मूल अवधारणाओं के साथ-साथ अंतर्निहित विचारों से परिचित कराया। इस लेख में, हम कुछ गहरे तंत्रिका नेटवर्क आर्किटेक्चर को महान प्रसंस्करण शक्ति के साथ देखेंगे - जैसे कि एलेक्सनेट, जेडएफनेट, वीजीजी, गोगेलनेट और रेसनेट - और इनमें से प्रत्येक आर्किटेक्चर के मुख्य लाभों को संक्षेप में प्रस्तुत करें। लेख की संरचना, एक ब्लॉग प्रविष्टि पर आधारित
है, जिसमें दृढ़ तंत्रिका नेटवर्क की बुनियादी अवधारणाएँ, भाग 3 हैं ।
वर्तमान में,
इमेजनेट चैलेंज मशीन मान्यता प्रणालियों और छवि वर्गीकरण के विकास के लिए मुख्य प्रोत्साहन है। अभियान डेटा के साथ काम करने की एक प्रतियोगिता है, जिसमें प्रतिभागियों को डेटा के एक बड़े सेट (एक मिलियन से अधिक चित्र) के साथ प्रदान किया जाता है। प्रतियोगिता का कार्य एक एल्गोरिथ्म विकसित करना है जो आपको आवश्यक छवियों को 1000 श्रेणियों में वस्तुओं में वर्गीकृत करने की अनुमति देता है - जैसे कुत्ते, बिल्ली, कार और अन्य - त्रुटियों की न्यूनतम संख्या के साथ।
प्रतियोगिता के आधिकारिक नियमों के अनुसार, एल्गोरिदम को प्रत्येक श्रेणी के चित्रों के लिए विश्वास के अवरोही क्रम में वस्तुओं की पाँच से अधिक श्रेणियों की सूची प्रदान करनी चाहिए। इमेज मार्किंग क्वालिटी का मूल्यांकन उस लेबल के आधार पर किया जाता है जो इमेज की जमीनी सच्चाई से सबसे अच्छी तरह मेल खाता है। विचार यह है कि एल्गोरिथ्म छवि में कई वस्तुओं की पहचान करने की अनुमति देता है और इस घटना में जुर्माना बिंदु नहीं जुटाता है कि कोई भी ज्ञात वस्तु वास्तव में छवि में मौजूद थी लेकिन जमीनी सच्चाई की संपत्ति में शामिल नहीं थी।
प्रतियोगिता के पहले वर्ष में, प्रतिभागियों को मॉडल के प्रशिक्षण के लिए पूर्व-चयनित छवि विशेषताओं के साथ प्रदान किया गया था। ये हो सकता है, उदाहरण के लिए,
सिंट एल्गोरिथ्म के संकेत वेक्टर मात्रा का उपयोग करके संसाधित किए गए हैं और शब्द बैग विधि में उपयोग के लिए या एक स्थानिक पिरामिड के रूप में प्रस्तुति के लिए उपयुक्त हैं। हालांकि, 2012 में इस क्षेत्र में एक वास्तविक सफलता मिली: टोरंटो विश्वविद्यालय के वैज्ञानिकों के एक समूह ने प्रदर्शित किया कि एक गहरा तंत्रिका नेटवर्क पहले से चयनित छवि गुणों से वैक्टर के आधार पर बनाए गए पारंपरिक मशीन लर्निंग मॉडल की तुलना में काफी बेहतर परिणाम प्राप्त कर सकता है। निम्नलिखित अनुभागों में, 2012 में प्रस्तावित पहले अभिनव वास्तुकला पर विचार किया जाएगा, साथ ही साथ आर्किटेक्चर जो 2015 तक इसके अनुयायी हैं।
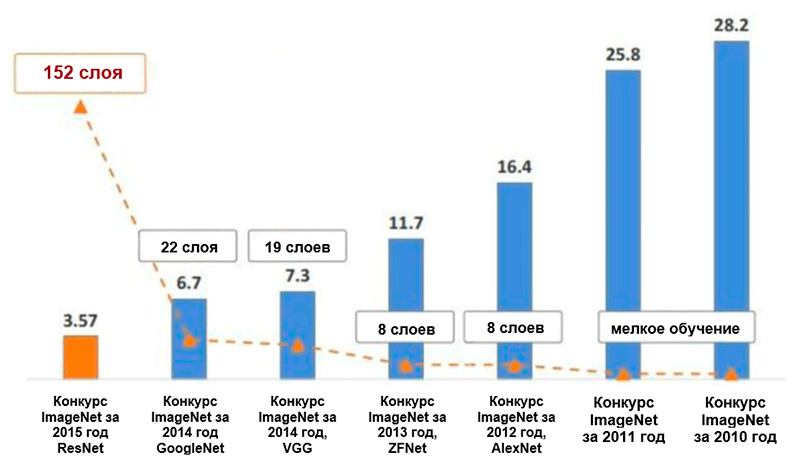 पाँच प्रमुख श्रेणियों के लिए ImageNet * छवियों के वर्गीकरण में त्रुटियों की संख्या में परिवर्तन का प्रतिशत (प्रतिशत में)। कैमिंग से ली गई छवि उनकी प्रस्तुति है, इमेज रिकग्निशन के लिए डीप अवशिष्ट लर्निंग
पाँच प्रमुख श्रेणियों के लिए ImageNet * छवियों के वर्गीकरण में त्रुटियों की संख्या में परिवर्तन का प्रतिशत (प्रतिशत में)। कैमिंग से ली गई छवि उनकी प्रस्तुति है, इमेज रिकग्निशन के लिए डीप अवशिष्ट लर्निंगAlexNet
एलेक्सनेट आर्किटेक्चर को 2012 में टोरंटो विश्वविद्यालय के वैज्ञानिकों (ए। क्रिज्व्स्की, आई। सुतस्क्वर और जे। हिंटन) के एक समूह द्वारा प्रस्तावित किया गया था। यह एक अभिनव कार्य था जिसमें लेखकों ने पहली बार (उस समय) गहरे अवक्षेपण तंत्रिका नेटवर्क का उपयोग किया था, जिसकी कुल गहराई आठ परतों (पाँच संवेदी और तीन पूरी तरह से जुड़ी हुई परतें) थी।
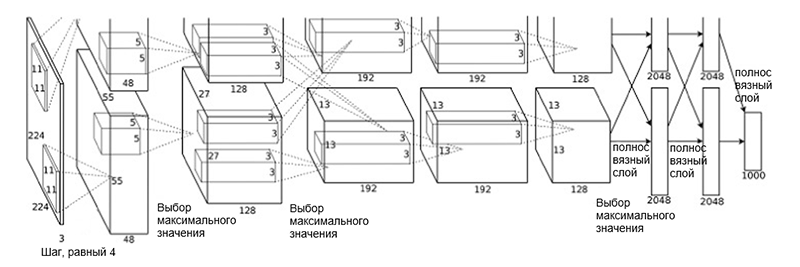 वास्तुकला एलेक्सनेट
वास्तुकला एलेक्सनेटनेटवर्क आर्किटेक्चर में निम्नलिखित परतें शामिल हैं:
- [कन्वर्सेशन लेयर + अधिकतम मूल्य चयन + सामान्यीकरण] x २
- [कन्वेंशन लेयर] x ३
- [अधिकतम मूल्य चुनना]
- [पूर्ण परत] x ३
ऐसी योजना थोड़ी अजीब लग सकती है, क्योंकि इसकी उच्च कम्प्यूटेशनल जटिलता के कारण सीखने की प्रक्रिया को दो GPU के बीच विभाजित किया गया था। जीपीयू के बीच काम के इस पृथक्करण को मॉडल को ऊर्ध्वाधर ब्लॉकों में मैन्युअल जुदाई की आवश्यकता होती है जो एक दूसरे के साथ बातचीत करते हैं।
एलेक्सनेट की वास्तुकला ने पांच प्रमुख श्रेणियों के लिए त्रुटियों की संख्या को 16.4 प्रतिशत तक घटा दिया है - पिछले उन्नत विकास की तुलना में लगभग आधा! साथ ही इस वास्तुकला के ढांचे के भीतर एक रेखीय परिशोधन इकाई (
ReLU ) के रूप में इस तरह के एक सक्रियण फ़ंक्शन को पेश किया गया था, जो वर्तमान में उद्योग मानक है। एलेक्सनेट आर्किटेक्चर और इसकी सीखने की प्रक्रिया की अन्य प्रमुख विशेषताओं का संक्षिप्त सारांश निम्नलिखित है:
- गहन डेटा वृद्धि
- अपवर्जन विधि
- अनुकूलतम पल का उपयोग कर अनुकूलन (देखें अनुकूलन गाइड "ढाल वंशानुक्रम अनुकूलन एल्गोरिदम का अवलोकन")
- सीखने की गति का मैनुअल समायोजन (सटीकता के स्थिरीकरण के साथ इस गुणांक में 10 की कमी)
- अंतिम मॉडल सात संवेदी तंत्रिका नेटवर्क का एक संग्रह है
- प्रशिक्षण दो NVIDIA * GeForce GTX * 580 ग्राफिक्स प्रोसेसर पर आयोजित किया गया था, जिनमें से प्रत्येक पर 3 जीबी वीडियो मेमोरी थी।
ZFNet
शोधकर्ताओं द्वारा प्रस्तावित
ZFNet नेटवर्क आर्किटेक्चर न्यूयॉर्क यूनिवर्सिटी के एम।
जेयलर और आर। फर्ग्यूस, एलेक्सनेट आर्किटेक्चर के लगभग समान है। उनके बीच केवल महत्वपूर्ण अंतर इस प्रकार हैं:
- फ़िल्टर का आकार और पहला कन्वेक्शन लेयर में कदम (एलेक्सनेट में, फिल्टर का साइज़ 11 × 11 है, और स्टेप 4 है; क्रमशः ZFNet में - 7 × 7 और 2,)
- स्वच्छ दृढ़ परतों (3, 4, 5) में फिल्टर की संख्या।
 ZFNet वास्तुकला
ZFNet वास्तुकलाZFNet वास्तुकला के लिए धन्यवाद, पांच प्रमुख श्रेणियों के लिए त्रुटियों की संख्या 11.4 प्रतिशत तक गिर गई। शायद इसमें मुख्य भूमिका हाइपरपरमेटर्स (आकार और फिल्टर की संख्या, पैकेट का आकार, सीखने की गति, आदि) की सटीक ट्यूनिंग द्वारा निभाई जाती है। हालांकि, यह भी संभावना है कि ZFNet वास्तुकला के विचारों का दृढ़ तंत्रिका नेटवर्क के विकास में बहुत महत्वपूर्ण योगदान है। ज़िलर और फर्गस ने कोर, वज़न और छवियों के एक छिपे हुए दृश्य को DeconvNet नामक एक दृश्य के लिए एक प्रणाली का प्रस्ताव दिया। उसके लिए, एक बेहतर समझ और दृढ़ तंत्रिका नेटवर्क के आगे विकास संभव हो गया।
वीजीजी नेट
2014 में, ऑक्सफोर्ड यूनिवर्सिटी के के। सिमोनियन और ई। ज़िसरमैन ने वीजीजी नामक एक वास्तुकला का प्रस्ताव रखा। इस संरचना का मुख्य और विशिष्ट विचार
फिल्टर को यथासंभव सरल रखना है । इसलिए, सभी कनवल्शन ऑपरेशन आकार 3 के एक फिल्टर और आकार 1 के एक चरण का उपयोग करके किए जाते हैं, और सभी सबसम्प्लिंग ऑपरेशनों का आकार 2 और आकार के एक चरण 2 का उपयोग करके किया जाता है। हालांकि, यह सब नहीं है। दृढ़ मॉड्यूल की सादगी के साथ, नेटवर्क में गहराई से काफी वृद्धि हुई है - अब इसमें 19 परतें हैं! सबसे महत्वपूर्ण विचार, जो पहले इस काम में प्रस्तावित है,
बिना सबसेंप्ले की परतों के बिना दृढ़ परतें लगाना है । अंतर्निहित विचार यह है कि इस तरह का ओवरले अभी भी पर्याप्त रूप से बड़े ग्रहणशील क्षेत्र प्रदान करता है (उदाहरण के लिए, 1 के चरणों में 3 × 3 आकार के तीन सुपरिंपोज्ड कंफर्टेबल लेयर्स में 7 × 7 के एक कंफर्टेबल लेयर के समान एक रिसेप्टिव फील्ड होता है, हालाँकि, बड़े फिल्टर वाले नेटवर्क (रेगुलराइज़र के रूप में कार्य करता है) की तुलना में मापदंडों की संख्या काफी कम है। इसके अलावा, अतिरिक्त अरेखीय परिवर्तनों को पेश करना संभव हो जाता है।
अनिवार्य रूप से, लेखकों ने प्रदर्शित किया है कि बहुत सरल भवन ब्लॉकों के साथ भी, आप ImageNet प्रतियोगिता में बेहतर गुणवत्ता वाले परिणाम प्राप्त कर सकते हैं। पांच अग्रणी श्रेणियों के लिए त्रुटियों की संख्या 7.3 प्रतिशत तक कम हो गई थी।
 वीजीजी वास्तुकला। कृपया ध्यान दें कि फिल्टर की संख्या छवि के स्थानिक आकार के विपरीत आनुपातिक है।
वीजीजी वास्तुकला। कृपया ध्यान दें कि फिल्टर की संख्या छवि के स्थानिक आकार के विपरीत आनुपातिक है।GoogLeNet
पहले, वास्तुकला का संपूर्ण विकास फिल्टर को सरल बनाने और नेटवर्क की गहराई बढ़ाने के लिए था। 2014 में, सी। सेजेडी ने, अन्य प्रतिभागियों के साथ मिलकर, एक पूरी तरह से अलग दृष्टिकोण का प्रस्ताव रखा और उस समय का सबसे जटिल वास्तुकला बनाया, जिसे GoogLeNet कहा जाता है।
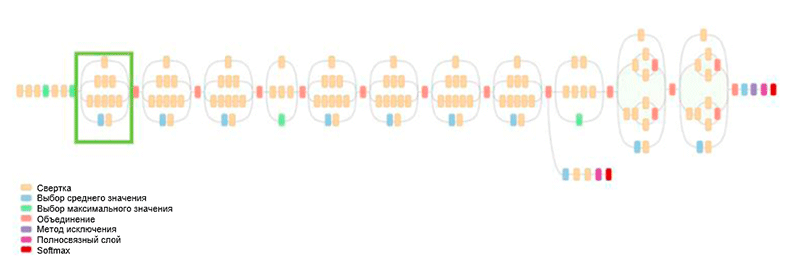 GoogLeNet वास्तुकला। यह इनसेप्शन मॉड्यूल का उपयोग करता है, आकृति में हरे रंग में हाइलाइट किया गया; नेटवर्क बिल्डिंग इन मॉड्यूल पर आधारित है
GoogLeNet वास्तुकला। यह इनसेप्शन मॉड्यूल का उपयोग करता है, आकृति में हरे रंग में हाइलाइट किया गया; नेटवर्क बिल्डिंग इन मॉड्यूल पर आधारित हैइस काम की मुख्य उपलब्धियों में से एक तथाकथित इंसेप्शन मॉड्यूल है, जिसे नीचे दिए गए आंकड़े में दिखाया गया है। अन्य आर्किटेक्चर के नेटवर्क इनपुट डेटा को क्रमिक रूप से प्रोसेस करते हैं, लेयर बाय लेयर, इन्सेप्शन मॉड्यूल का उपयोग करते हुए,
इनपुट डेटा को समानांतर में प्रोसेस किया जाता है । यह आपको आउटपुट को गति देने के साथ-साथ
मापदंडों की
कुल संख्या को कम करने की अनुमति देता है।
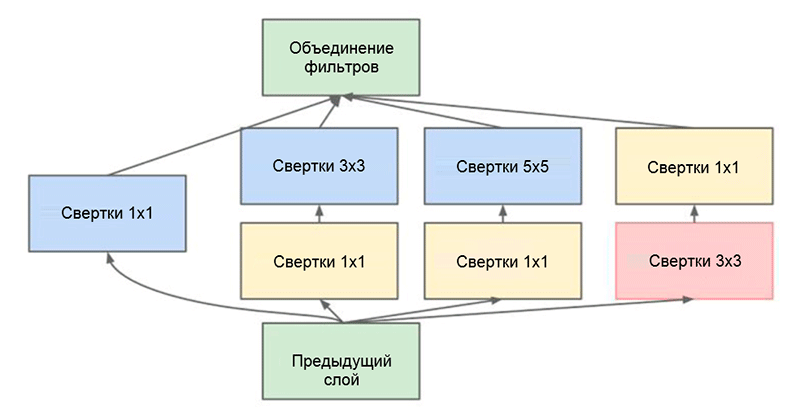 इन्सेप्शन मॉड्यूल। ध्यान दें कि मॉड्यूल कई समानांतर शाखाओं का उपयोग करता है, जो एक ही इनपुट डेटा के आधार पर विभिन्न गुणों की गणना करते हैं, और फिर परिणामों को संयोजित करते हैं
इन्सेप्शन मॉड्यूल। ध्यान दें कि मॉड्यूल कई समानांतर शाखाओं का उपयोग करता है, जो एक ही इनपुट डेटा के आधार पर विभिन्न गुणों की गणना करते हैं, और फिर परिणामों को संयोजित करते हैंइंसेप्शन मॉड्यूल में इस्तेमाल की जाने वाली एक और दिलचस्प ट्रिक है साइज़ की संकेंद्रित परतों का उपयोग करना 1 × 1. यह तब तक बेकार लग सकता है जब तक हम इस तथ्य को याद नहीं करते कि फ़िल्टर गहराई के पूरे आयाम को कवर करता है। इस प्रकार, एक 1 × 1 दृढ़ संकल्प एक संपत्ति के नक्शे के आयाम को कम करने का एक सरल तरीका है। इस तरह की दृढ़ परतों को पहली बार एम। लिन एट अल
द्वारा नेटवर्क में प्रस्तुत किया गया था। एक व्यापक और समझने योग्य विवरण ब्लॉग पोस्ट
कन्वर्सेशन [1 × 1] में भी पाया जा सकता है। ए। प्रकाश द्वारा
अंतर्ज्ञान के विपरीत उपयोगिता ।
अंततः, इस वास्तुकला ने पाँच प्रमुख श्रेणियों के लिए त्रुटियों की संख्या को आधे से भी कम कर दिया - 6.7 प्रतिशत के मान से।
ResNet
2015 में, माइक्रोसॉफ्ट रिसर्च एशिया के शोधकर्ताओं (कमिंग ही एंड अदर्स) का एक समूह एक विचार आया, जिसे वर्तमान में अधिकांश समुदाय द्वारा गहन शिक्षा के विकास में सबसे महत्वपूर्ण चरणों में से एक माना जाता है।
गहरी तंत्रिका नेटवर्क की मुख्य समस्याओं में से एक गायब हो जाने वाली ढाल की समस्या है। संक्षेप में, यह एक तकनीकी समस्या है जो ढाल गणना एल्गोरिथ्म के लिए त्रुटि वापस प्रसार विधि का उपयोग करते समय उत्पन्न होती है। त्रुटियों के पीछे प्रसार के साथ काम करते समय, एक चेन नियम का उपयोग किया जाता है। इसके अलावा, अगर ग्रेडिएंट का नेटवर्क के अंत में एक छोटा मूल्य है, तो यह नेटवर्क की शुरुआत तक पहुंचने तक असीम रूप से छोटे मूल्य ले सकता है। यह सिद्धांत में नेटवर्क सीखने की असंभवता (अधिक जानकारी के लिए, आर। कपूर द्वारा ब्लॉग प्रविष्टि देखें
एक लुप्त होती ढाल की समस्या ) सहित पूरी तरह से अलग प्रकृति की समस्याएं पैदा कर सकता है।
इस समस्या को हल करने के लिए, काइमिंग ही और उनके समूह ने निम्नलिखित विचार का प्रस्ताव दिया - नेटवर्क को स्वयं प्रदर्शन के बजाय अवशिष्ट मानचित्रण (एक तत्व जिसे इनपुट में जोड़ा जाना चाहिए) का अध्ययन करने की अनुमति देने के लिए। तकनीकी रूप से, यह आंकड़ा में दिखाए गए बाईपास कनेक्शन का उपयोग करके किया जाता है।
 अवशिष्ट ब्लॉक के योजनाबद्ध आरेख: इनपुट डेटा रूपांतरण परतों को दरकिनार करके एक छोटे कनेक्शन के माध्यम से प्रेषित होता है और परिणाम में जोड़ा जाता है। कृपया ध्यान दें कि "समान" कनेक्शन नेटवर्क में अतिरिक्त पैरामीटर नहीं जोड़ता है, इसलिए इसकी संरचना जटिल नहीं है
अवशिष्ट ब्लॉक के योजनाबद्ध आरेख: इनपुट डेटा रूपांतरण परतों को दरकिनार करके एक छोटे कनेक्शन के माध्यम से प्रेषित होता है और परिणाम में जोड़ा जाता है। कृपया ध्यान दें कि "समान" कनेक्शन नेटवर्क में अतिरिक्त पैरामीटर नहीं जोड़ता है, इसलिए इसकी संरचना जटिल नहीं हैयह विचार अत्यंत सरल है, लेकिन एक ही समय में अत्यंत प्रभावी है। यह गायब होने वाली ढाल की समस्या को हल करता है, जिससे यह ऊपरी परतों से निचले लोगों तक "समान" कनेक्शन के माध्यम से बिना किसी बदलाव के स्थानांतरित करने की अनुमति देता है। इस विचार के लिए धन्यवाद, आप बहुत गहरे, अत्यंत गहरे नेटवर्क को प्रशिक्षित कर सकते हैं।
2015 में इमेजनेट चैलेंज जीतने वाले नेटवर्क में 152 परतें थीं (लेखक 1001 परतों वाले नेटवर्क को प्रशिक्षित करने में सक्षम थे, लेकिन यह लगभग उसी परिणाम का उत्पादन करता था, इसलिए उन्होंने इसके साथ काम करना बंद कर दिया)। इसके अलावा, इस विचार ने पांच प्रमुख श्रेणियों के लिए त्रुटियों की संख्या को आधे से कम करना संभव बना दिया - 3.6 प्रतिशत के मान से। ए कारपथी
द्वारा इमेजनेट प्रतियोगिता में एक सजातीय तंत्रिका नेटवर्क के साथ प्रतिस्पर्धा करके मैंने जो कुछ भी सीखा है, उसके एक अध्ययन के अनुसार, इस कार्य के लिए मानव प्रदर्शन लगभग 5 प्रतिशत है। इसका मतलब यह है कि ResNet वास्तुकला मानव परिणामों को पार करने में सक्षम है, कम से कम इस छवि वर्गीकरण कार्य में।