लेख के सह-लेखक: माइक चेंग
Google क्लाउड प्लेटफ़ॉर्म में अब अपने पोर्टफोलियो में वर्चुअल मशीन चित्र हैं, जो विशेष रूप से डीप लर्निंग में शामिल लोगों के लिए डिज़ाइन किए गए हैं। आज हम इस बारे में बात करते हैं कि ये चित्र क्या दर्शाते हैं, वे डेवलपर्स और शोधकर्ताओं को क्या फायदे देते हैं, और निश्चित रूप से, उनके आधार पर एक वर्चुअल मशीन कैसे बनाई जाए।
गीतात्मक विषयांतर: लेखन के समय, उत्पाद अभी भी बीटा में था, क्रमशः, कोई SLAs उस पर लागू नहीं होता है।
यह किस प्रकार का जानवर है, Google से डीप लर्निंग के लिए आभासी मशीनों की छवियां?
Google से डीप लर्निंग के लिए वर्चुअल मशीन छवियां डेबियन 9 छवियां हैं, जो बॉक्स के ठीक बाहर है, जिसमें दीप लर्निंग की जरूरत है। वर्तमान में, TensorFlow, PyTorch और सामान्य-उद्देश्य छवियों के साथ छवियों के संस्करण हैं। प्रत्येक संस्करण केवल-सीपीयू और जीपीयू इंस्टेंस के लिए संस्करण में मौजूद है। यह समझने के लिए कि आपको किस छवि की आवश्यकता है, मैंने एक छोटा सा धोखा पत्र दिया:
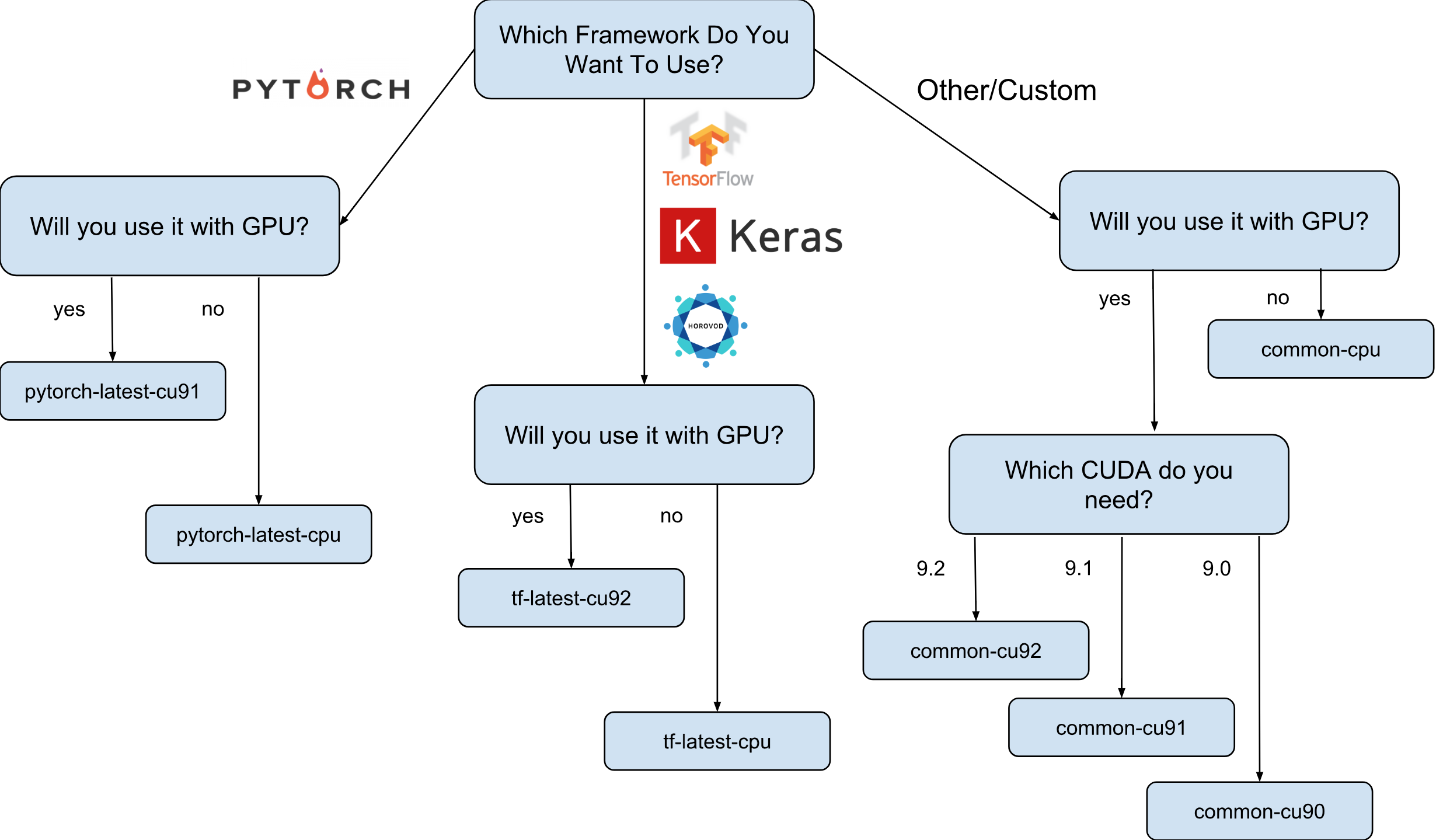
जैसा कि चीट शीट पर दिखाया गया है, 8 अलग-अलग छवि वाले परिवार हैं। जैसा कि पहले ही उल्लेख किया गया है, वे सभी डेबियन 9 पर आधारित हैं।
क्या वास्तव में छवियों पर पूर्वस्थापित है?
सभी छवियों में निम्न पूर्व-स्थापित पैकेजों के साथ पायथन 2.7 / 3.5 है:
- numpy
- sklearn
- scipy
- पांडा
- nltk
- तकिया
- बृहस्पति वातावरण (लैब और नोटबुक)
- और भी बहुत कुछ।
एनवीडिया से कॉन्फ़िगर किया गया स्टैक (केवल GPU छवियों में):
- कुडा 9. *
- CuDNN 7.1
- एनसीसीएल 2. *
- नवीनतम एनवीडिया चालक
सूची लगातार अपडेट की जाती है, इसलिए आधिकारिक पेज पर बने रहें।
और इन चित्रों की वास्तव में आवश्यकता क्यों है?
मान लीजिए कि आपको केरस (टेंसोरफ्लो के साथ) का उपयोग करके एक तंत्रिका नेटवर्क मॉडल को प्रशिक्षित करने की आवश्यकता है। सीखने की गति आपके लिए महत्वपूर्ण है और आप GPU का उपयोग करने का निर्णय लेते हैं। GPU का उपयोग करने के लिए, आपको एनवीडिया स्टैक (Nvidia ड्राइवर + CUDA + CuDNN + NCCL) को स्थापित और कॉन्फ़िगर करना होगा। न केवल यह प्रक्रिया अपने आप में काफी जटिल है (विशेषकर यदि आप एक सिस्टम इंजीनियर नहीं हैं, बल्कि एक शोधकर्ता हैं), तो यह इस तथ्य से अधिक जटिल है कि आपको TensorFlow पुस्तकालय के अपने संस्करण की द्विआधारी निर्भरता को ध्यान में रखना होगा। उदाहरण के लिए, आधिकारिक TensorFlow 1.9 वितरण CUDA 9.0 के साथ संकलित किया गया है और यह काम नहीं करेगा यदि आपके पास CUDA 9.1 या 9.2 के साथ एक स्टैक है। इस स्टैक को स्थापित करना एक "मजेदार" प्रक्रिया हो सकती है, मुझे लगता है कि कोई भी इसके साथ बहस नहीं कर सकता है (विशेषकर जो लोग ऐसा करते हैं)।
अब मान लीजिए कि कई रातों की नींद के बाद सब कुछ सेट और काम कर रहा है। प्रश्न: यह कॉन्फ़िगरेशन, जिसे आप कॉन्फ़िगर करने में सक्षम थे, क्या यह आपके हार्डवेयर के लिए सबसे इष्टतम है? उदाहरण के लिए, क्या यह सच है कि स्थापित CUDA 9.0 और आधिकारिक TensorFlow 1.9 बाइनरी पैकेज एक स्काईलेक प्रोसेसर और एक वोल्टा वी 100 जीपीयू के साथ एक उदाहरण पर सबसे तेज गति दिखाते हैं?
CUDA के अन्य संस्करणों के साथ परीक्षण के बिना उत्तर देना लगभग असंभव है। सुनिश्चित करने के लिए उत्तर देने के लिए, आपको मैन्युअल रूप से TensorFlow को अलग-अलग कॉन्फ़िगरेशन में पुनर्निर्माण करने और अपने परीक्षण चलाने की आवश्यकता है। यह सब उस महंगे हार्डवेयर पर किया जाना चाहिए, जिस पर बाद में मॉडल को प्रशिक्षित करने की योजना है। खैर, और बहुत आखिरी, इन सभी मापों को फेंक दिया जा सकता है जैसे ही TensorFlow या Nvidia स्टैक का नया संस्करण जारी किया जाता है। यह सुरक्षित रूप से कहा जा सकता है कि अधिकांश शोधकर्ता बस ऐसा नहीं करेंगे और बस मानक TensorFlow विधानसभा का उपयोग करेंगे, जिसमें अधिकतम गति नहीं होगी।
यह वह जगह है जहां Google से दीप लर्निंग की छवियां दृश्य पर दिखाई देती हैं। उदाहरण के लिए, TensorFlow के साथ छवियों की अपनी TensorFlow असेंबली है, जो Google क्लाउड इंजन पर उपलब्ध हार्डवेयर के लिए अनुकूलित है। उन्हें एनवीडिया स्टैक के एक अलग कॉन्फ़िगरेशन के साथ परीक्षण किया जाता है और उस पर आधारित होता है जिसने उच्चतम प्रदर्शन दिखाया (स्पॉइलर: यह हमेशा सबसे नया नहीं होता है)। अच्छी तरह से और सबसे महत्वपूर्ण बात - अनुसंधान के लिए आपको जो कुछ भी चाहिए वह पहले से ही पहले से स्थापित है!
मैं किसी एक चित्र के आधार पर एक उदाहरण कैसे बना सकता हूं?
इन चित्रों के आधार पर एक नया उदाहरण बनाने के लिए दो विकल्प हैं:
- Google क्लाउड मार्केटप्लेस वेब UI का उपयोग करना
- Gcloud का उपयोग करना
चूंकि मैं टर्मिनल और सीएलआई उपयोगिताओं का बहुत बड़ा प्रशंसक हूं, इस लेख में मैं इस विकल्प के बारे में बात करूंगा। इसके अलावा, यदि आप यूआई पसंद करते हैं, तो वेब यूआई का उपयोग करके एक उदाहरण बनाने के तरीके का वर्णन करने वाला एक अच्छा दस्तावेज है ।
जारी रखने से पहले, स्थापित करें (यदि आपने पहले से स्थापित नहीं किया है) gcloud टूल । वैकल्पिक रूप से, आप Google क्लाउड शेल का उपयोग कर सकते हैं, लेकिन ध्यान रखें कि वर्तमान में Google क्लाउड शेल में WebPreview फ़ंक्शन समर्थित नहीं है और इसलिए आप वहां Jupyter Lab या नोटबुक का उपयोग नहीं कर सकते हैं।
अगला कदम एक छवि परिवार का चयन करना है। मैं अपने आप को एक बार फिर छवियों की एक परिवार की पसंद के साथ चीट शीट लाने की अनुमति दूंगा।
उदाहरण के लिए, हम मानते हैं कि आपकी पसंद tf-latest-cu92 पर गिरी थी, और हम इसे बाद में पाठ में उपयोग करेंगे।
रुको, लेकिन क्या होगा अगर मुझे "नवीनतम" के बजाय टेंसोरफ्लो के एक विशिष्ट संस्करण की आवश्यकता है?
मान लीजिए कि हमारे पास एक प्रोजेक्ट है जिसमें TensorFlow 1.8 की आवश्यकता है, लेकिन एक ही समय में 1.9 पहले ही जारी कर दिया गया है और tf-latest परिवार में चित्र पहले से ही 1.9 हैं। इस मामले के लिए, हमारे पास छवियों का एक परिवार है, जिसमें हमेशा फ्रेमवर्क का एक विशिष्ट संस्करण होता है (हमारे मामले में, tf-1-8-cpu और tf-1-8-cu92)। इन छवि परिवारों को अपडेट किया जाएगा, लेकिन TensorFlow का संस्करण उनमें नहीं बदलेगा।
चूंकि यह केवल बीटा रिलीज़ है, अब हम केवल TensorFlow 1.8 / 1.9 और PyTorch 0.4 का समर्थन करते हैं। हम भविष्य के रिलीज का समर्थन करने की योजना बना रहे हैं, लेकिन हम मौजूदा स्तर पर स्पष्ट रूप से इस सवाल का जवाब नहीं दे सकते कि पुराने संस्करणों का समर्थन कब तक किया जाएगा।
क्या होगा यदि मैं एक क्लस्टर बनाना चाहता हूं या उसी छवि का उपयोग करना चाहता हूं?
वास्तव में, ऐसे कई मामले हो सकते हैं, जब एक ही छवि का बार-बार उपयोग करना आवश्यक होता है (चित्रों के परिवार के बजाय)। सख्ती से बोलना, सीधे छवियों का उपयोग करना लगभग हमेशा पसंदीदा विकल्प होता है। ठीक है, उदाहरण के लिए, यदि आप कई उदाहरणों के साथ एक क्लस्टर चलाते हैं, तो उस स्थिति में आपकी लिपियों में सीधे छवि वाले परिवारों को निर्दिष्ट करने की अनुशंसा नहीं की जाती है, क्योंकि यदि स्क्रिप्ट के चालू होने पर परिवार अपडेट किया जाता है, तो संभावना है कि विभिन्न छवियों के लिए अलग-अलग क्लस्टर इंस्टेंसेस बनाए जाएंगे (और पुस्तकालयों के विभिन्न संस्करण हो सकते हैं!)। ऐसे मामलों में, पहले उनके परिवार की छवि के लिए एक विशिष्ट नाम प्राप्त करना बेहतर होता है, और उसके बाद ही किसी विशिष्ट नाम का उपयोग करें।
यदि आप इस विषय में रुचि रखते हैं, तो आप मेरे लेख "छवि परिवारों का सही उपयोग कैसे करें" देख सकते हैं।
आप एक साधारण आदेश के साथ परिवार में अंतिम छवि का नाम देख सकते हैं:
gcloud compute images describe-from-family tf-latest-cu92 \ --project deeplearning-platform-release
मान लीजिए कि किसी विशेष छवि का नाम tf-latest-cu92-1529452792 है, तो आप पहले से ही इसे कहीं भी उपयोग कर सकते हैं:
हमारा पहला उदाहरण बनाने के लिए समय!
छवियों के परिवार से एक उदाहरण बनाने के लिए, बस एक साधारण कमांड चलाएं:
export IMAGE_FAMILY="tf-latest-cu92"
यदि आप छवि नाम का उपयोग करते हैं, न कि छवि परिवार का, तो आपको "- छवि-परिवार = $ IMAGE_FAMILY" को "- छवि = $ छवि-नाम" से बदलना होगा।
यदि आप GPU के साथ एक उदाहरण का उपयोग कर रहे हैं, तो आपको निम्नलिखित परिस्थितियों पर ध्यान देने की आवश्यकता है:
आपको सही ज़ोन का चयन करने की आवश्यकता है । यदि आप किसी विशिष्ट GPU के साथ एक उदाहरण बनाते हैं, तो आपको यह सुनिश्चित करने की आवश्यकता है कि इस प्रकार का GPU उस क्षेत्र में उपलब्ध है जिसमें आप उदाहरण बनाते हैं। यहाँ आप GPU के प्रकारों के पत्राचार पा सकते हैं। जैसा कि आप देख सकते हैं, us-west1-b एकमात्र क्षेत्र है जिसमें सभी 3 प्रकार के जीपीयू (K80 / P100 / V100) हैं।
सुनिश्चित करें कि आपके पास GPU के साथ एक उदाहरण बनाने के लिए पर्याप्त कोटा है । यहां तक कि अगर आपने सही क्षेत्र चुना है, तो इसका मतलब यह नहीं है कि आपके पास इस क्षेत्र में GPU के साथ एक उदाहरण बनाने के लिए कोटा है। डिफ़ॉल्ट रूप से, GPU कोटा सभी क्षेत्रों में शून्य पर सेट है, इसलिए GPU के साथ एक आवृत्ति बनाने के सभी प्रयास विफल हो जाएंगे। कोटा कैसे बढ़ाया जाए इसका एक अच्छा विवरण यहां पाया जा सकता है ।
सुनिश्चित करें कि आपके अनुरोध को पूरा करने के लिए क्षेत्र में पर्याप्त GPU हैं । यहां तक कि अगर आपने सही क्षेत्र चुना है और आपके पास इस क्षेत्र में GPU के लिए एक कोटा है, तो इसका मतलब यह नहीं है कि इस क्षेत्र में आपके लिए एक GPU का हित है। दुर्भाग्य से, मुझे नहीं पता है कि आप GPU की उपलब्धता की जांच कैसे कर सकते हैं, उदाहरण के लिए एक प्रयास के अलावा और देखें कि क्या होता है =)
GPU की सही संख्या चुनें (GPU के प्रकार के आधार पर) । तथ्य यह है कि हमारी टीम में "एक्सीलरेटर" ध्वज टाइप करने के लिए उपलब्ध GPU के प्रकार और संख्या के लिए जिम्मेदार है: i.e. "- त्वरक = 'टाइप = एनविडिया-टेस्ला-वी 100, काउंट = 8'" आठ उपलब्ध एनवीडिया टेस्ला वी 100 (वोल्टा) जीपीयू के साथ एक उदाहरण बनाएगा। प्रत्येक प्रकार के जीपीयू में गणना मूल्यों की एक मान्य सूची है। यहां हर प्रकार के GPU के लिए सूची दी गई है:
- nvidia-tesla-k80, मायने रखता है: 1, 2, 4, 8
- एनवीडिया-टेस्ला-पी 100, में मायने रखता है: 1, 2, 4
- एनवीडिया-टेस्ला-वी 100, में मायने रखता है: 1, 8
आप जिस समय इंस्टेंस लॉन्च करते हैं, उस समय अपनी ओर से एनवीडिया ड्राइवर को स्थापित करने के लिए Google क्लाउड को अनुमति दें । Nvidia का ड्राइवर एक होना चाहिए। इस लेख के दायरे से परे कारणों के लिए, छवियों में एक पूर्व-स्थापित एनवीडिया चालक नहीं है। हालाँकि, आप Google क्लाउड को पहली बार आपके द्वारा इंस्टेंस लॉन्च करने पर इसे स्थापित करने का अधिकार दे सकते हैं। यह "- मेटाडेटा = 'स्थापित-एनवीडिया-चालक = सत्य'" ध्वज को जोड़कर किया जाता है। यदि आप इस ध्वज को निर्दिष्ट नहीं करते हैं, तो पहली बार जब आप एसएसएच के माध्यम से कनेक्ट होते हैं, तो आपको ड्राइवर स्थापित करने के लिए प्रेरित किया जाएगा।
दुर्भाग्य से, ड्राइवर स्थापना प्रक्रिया पहले बूट में समय लेती है, क्योंकि इसे इस ड्राइवर को डाउनलोड करने और स्थापित करने की आवश्यकता होती है (और यह भी उदाहरण को रिबूट करने की आवश्यकता होती है)। कुल में, यह 5 मिनट से अधिक नहीं लेना चाहिए। हम थोड़ा बाद में बात करेंगे कि आप पहले बूट समय को कैसे कम कर सकते हैं।
SSH के माध्यम से एक उदाहरण से कनेक्ट करें
यह शलजम की तुलना में सरल है और इसे एक कमांड के साथ किया जा सकता है:
gcloud compute ssh $INSTANCE_NAME
gcloud एक प्रमुख जोड़ी बनाएगा और स्वचालित रूप से उन्हें नए बनाए गए इंस्टेंस पर अपलोड करेगा, साथ ही उस पर अपना उपयोगकर्ता भी बनाएगा। यदि आप इस प्रक्रिया को और भी सरल बनाना चाहते हैं, तो आप एक फ़ंक्शन का उपयोग कर सकते हैं जो इसे भी सरल करता है:
function gssh() { gcloud compute ssh $@ } gssh $INSTANCE_NAME
वैसे, आप यहाँ मेरे सभी gcloud bash फ़ंक्शन पा सकते हैं। खैर, इससे पहले कि हम यह सवाल करें कि ये छवियां कितनी तेज़ हैं, या उनके साथ क्या किया जा सकता है, मुझे लॉन्चिंग गति के साथ समस्या को स्पष्ट करने दें।
मैं पहली शुरुआत के समय को कैसे कम कर सकता हूं?
तकनीकी तौर पर, बहुत पहले लॉन्च का समय कुछ भी नहीं है। लेकिन आप कर सकते हैं:
- एक K80 के साथ सबसे सस्ता n1-standard-1 उदाहरण बनाएं;
- पहले डाउनलोड पूरा होने तक प्रतीक्षा करें;
- सत्यापित करें कि Nvidia ड्राइवर स्थापित है (यह "nvidia-smi" चलाकर किया जा सकता है);
- उदाहरण रोकें
- एक बंद उदाहरण से अपनी खुद की छवि बनाएं
- लाभ - आपकी व्युत्पन्न छवि से बनाए गए सभी उदाहरणों में 15 सेकंड का लॉन्च समय होगा।
इसलिए, इस सूची से हम पहले से ही जानते हैं कि एक नया उदाहरण कैसे बनाया जाए और उससे कैसे जुड़ा जाए, हम यह भी जानते हैं कि ऑपरेट करने के लिए ड्राइवरों की जांच कैसे करें। यह केवल इस बारे में बात करने के लिए बनी हुई है कि कैसे उदाहरण को रोकें और उससे एक छवि बनाएं।
उदाहरण को रोकने के लिए, निम्न कमांड चलाएँ:
function ginstance_stop() { gcloud compute instances stop - quiet $@ } ginstance_stop $INSTANCE_NAME
और यहाँ छवि बनाने की आज्ञा है:
export IMAGE_NAME="my-awesome-image" export IMAGE_FAMILY="family1" gcloud compute images create $IMAGE_NAME \ --source-disk $INSTANCE_NAME \ --source-disk-zone $ZONE \ --family $IMAGE_FAMILY
बधाई हो, अब आपके पास स्थापित एनवीडिया ड्राइवरों के साथ अपनी छवि है।
कैसे जुपिटर लैब के बारे में?
एक बार जब आपका उदाहरण चल रहा होता है, तो अगला तार्किक कदम सीधे व्यापार के लिए नीचे उतरने के लिए जुपिटर लैब शुरू करना होगा :) नई छवियों के साथ, यह बहुत सरल है। उदाहरण पेश किए जाने के बाद से ही ज्यूपिटर लैब चल रही है। आपको बस उस उदाहरण से कनेक्ट करना होगा और उस पोर्ट को अग्रेषित करना होगा जिस पर जुपिटर लैब सुन रहा है। और यह पोर्ट 8080 है। यह निम्नलिखित कमांड के साथ किया जाता है:
gssh $INSTANCE_NAME -- -L 8080:localhost:8080
सब कुछ तैयार है, अब आप अपना पसंदीदा ब्राउज़र खोल सकते हैं और http: // localhost: 8080 पर जा सकते हैं
छवियों से TensorFlow कितना तेज है?
एक बहुत ही महत्वपूर्ण सवाल है, क्योंकि मॉडल को प्रशिक्षित करने की गति वास्तविक पैसा है। हालांकि, इस सवाल का पूरा जवाब सबसे लंबा होगा जो पहले से ही इस लेख में लिखा गया है। तो आपको अगले लेख का इंतज़ार करना होगा :)
इस बीच, मैं आपको अपने छोटे से निजी प्रयोग में प्राप्त कुछ नंबरों से लाड़ कर दूंगा। तो, इमेजनेट पर प्रशिक्षण की गति 6100 चित्र प्रति सेकंड (रेसनेट -50 नेटवर्क) थी। मेरे व्यक्तिगत बजट ने मुझे मॉडल को पूरी तरह से प्रशिक्षण पूरा करने की अनुमति नहीं दी, हालांकि, इस गति से, मुझे लगता है कि 5% की 75% सटीकता को थोड़ा-थोड़ा करके हासिल करना संभव है।
सहायता कहां से प्राप्त करें?
यदि आपको नई छवियों पर कोई जानकारी चाहिए, तो आप निम्न कर सकते हैं:
- स्टैकओवरफ़्लो पर एक प्रश्न पूछें, टैग google-dl-platform के साथ;
- सार्वजनिक Google समूह को लिखें;
- मुझे मेल या ट्विटर पर लिख सकते हैं।
आपकी प्रतिक्रिया बहुत महत्वपूर्ण है, अगर आपको छवियों के बारे में कुछ कहना है, तो कृपया मुझे किसी भी तरह से आपके लिए सुविधाजनक महसूस करने के लिए स्वतंत्र महसूस करें या इस लेख के तहत एक टिप्पणी छोड़ दें।