
पिछले कुछ वर्षों में, कृत्रिम बुद्धिमत्ता और मशीन लर्निंग का विषय कल्पना के दायरे से लोगों के लिए कुछ होना बंद हो गया है और दृढ़ता से रोजमर्रा की जिंदगी में प्रवेश किया है। सामाजिक नेटवर्क उन घटनाओं की यात्रा करने की पेशकश करते हैं जो हमारे लिए रुचि रखते हैं, सड़कों पर कारें बिना चालक के चारों ओर घूमना सीखती हैं, और फोन पर एक आवाज सहायक बताता है कि ट्रैफिक जाम से बचने के लिए घर छोड़ना बेहतर है और क्या आपके साथ एक छाता लेना है।
इस लेख में, हम मशीन लर्निंग टूल्स पर विचार करेंगे जो कि Apple डेवलपर्स प्रदान करते हैं, विश्लेषण करें कि कंपनी ने WWDC18 में इस क्षेत्र में क्या नया दिखाया, और यह समझने की कोशिश करें कि यह सब कैसे व्यवहार में लाना है।
मशीन सीखने
तो, मशीन लर्निंग एक प्रक्रिया है जिसके दौरान एक प्रणाली, कुछ डेटा विश्लेषण एल्गोरिदम का उपयोग करते हुए और बड़ी संख्या में उदाहरणों को संसाधित करते हुए, पैटर्न की पहचान करती है और नए डेटा की विशेषताओं का अनुमान लगाने के लिए उनका उपयोग करती है।
मशीन लर्निंग का जन्म इस सिद्धांत से हुआ था कि कंप्यूटर अपने आप सीख सकते हैं, अभी तक कुछ क्रियाओं को करने के लिए प्रोग्राम नहीं किया गया है। दूसरे शब्दों में, विशिष्ट समस्याओं को हल करने के लिए पूर्वनिर्धारित निर्देशों के साथ पारंपरिक कार्यक्रमों के विपरीत, मशीन लर्निंग सिस्टम को सीखने की अनुमति देता है कि कैसे पैटर्न को स्वतंत्र रूप से पहचानें और भविष्यवाणियां करें।
बीएनएनएस और सीएनएन
Apple काफी समय से अपने उपकरणों पर मशीन सीखने की तकनीक का उपयोग कर रहा है: मेल स्पैम ईमेल की पहचान करता है, सिरी आपको अपने सवालों के जवाब खोजने में मदद करता है, फ़ोटो छवियों में चेहरे को पहचानता है।
WWDC16 में, कंपनी ने दो न्यूरल नेटवर्क-आधारित API- बेसिक न्यूरल नेटवर्क सबरूटीन्स (BNNS) और कन्वेंशनल न्यूरल नेटवर्क्स (CNN) की शुरुआत की। बीएनएनएस एक्सीलरेट सिस्टम का हिस्सा है, जो सीपीयू पर तेजी से गणना करने का आधार है, और सीएनएन मेटल परफॉर्मेंस शेडर्स लाइब्रेरी है जो जीपीयू का उपयोग करती है। आप इन तकनीकों के बारे में अधिक जान सकते हैं, उदाहरण के लिए, यहाँ ।
कोर एमएल और तुरी क्रिएट
पिछले साल, ऐप्पल ने एक रूपरेखा की घोषणा की जो मशीन सीखने की प्रौद्योगिकियों के साथ काम करने की सुविधा प्रदान करती है - कोर एमएल। यह एक पूर्व-प्रशिक्षित डेटा मॉडल लेने और कोड के कुछ ही लाइनों में अपने आवेदन में एकीकृत करने के विचार पर आधारित है।
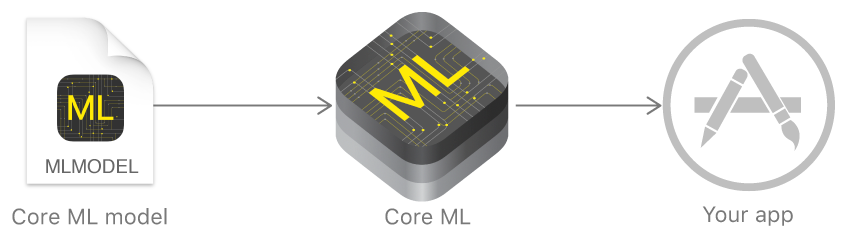
कोर एमएल का उपयोग, आप कई कार्यों को लागू कर सकते हैं:
- एक तस्वीर और वीडियो में वस्तुओं की परिभाषा;
- भविष्य कहनेवाला पाठ इनपुट;
- ट्रैकिंग और मान्यता का सामना करना;
- गति विश्लेषण;
- बारकोड परिभाषा;
- पाठ की समझ और मान्यता;
- वास्तविक समय छवि मान्यता;
- छवि शैलीीकरण;
- और भी बहुत कुछ।
कोर एमएल, बदले में, निम्न-स्तर की धातु, त्वरण और बीएनएनएस का उपयोग करता है, और इसलिए गणना के परिणाम बहुत तेज हैं।
कर्नेल तंत्रिका नेटवर्क, सामान्यीकृत रैखिक मॉडल, फीचर इंजीनियरिंग, ट्री-आधारित निर्णय लेने वाले एल्गोरिदम (ट्री एन्सेम्बल), वेक्टर मशीनों विधि, पाइपलाइन मॉडल का समर्थन करता है।
लेकिन ऐप्पल ने शुरू में मॉडल बनाने और प्रशिक्षण के लिए अपनी खुद की प्रौद्योगिकियां नहीं दिखाईं, लेकिन केवल अन्य लोकप्रिय रूपरेखाओं के लिए एक कनवर्टर बनाया: कैफ, केरस, स्किकिट-लर्न, एक्सजीबोस्ट, एलआईबीएसवीएम।
तृतीय-पक्ष टूल का उपयोग करना अक्सर सबसे आसान काम नहीं था, प्रशिक्षित मॉडल काफी बड़े थे, और प्रशिक्षण में खुद को बहुत समय लगता था।
वर्ष के अंत में, कंपनी ने टूरी क्रिएट - एक मॉडल लर्निंग फ्रेमवर्क पेश किया, जिसका मुख्य विचार बड़ी संख्या में परिदृश्यों के लिए उपयोग और समर्थन में आसानी था - छवि वर्गीकरण, वस्तुओं की परिभाषा, सिफारिश प्रणाली और कई अन्य। लेकिन तुरी क्रिएट, इसके सापेक्ष उपयोग में आसानी के बावजूद, केवल पायथन को समर्थन दिया।
एमएल बनाएं
और इस वर्ष, Apple ने Core ML 2 के अलावा, अंत में प्रशिक्षण मॉडल के लिए अपना स्वयं का उपकरण दिखाया - Apple की मूल प्रौद्योगिकियों - Xcode और Swift का उपयोग करके ML फ्रेमवर्क बनाएँ।
यह तेजी से काम करता है, और क्रिएट एमएल के साथ मॉडल मॉडल बनाना वास्तव में आसान है।
WWDC में, एक उदाहरण के रूप में Memrise एप्लिकेशन का उपयोग करके क्रिएट ML और कोर ML 2 के प्रभावशाली प्रदर्शन की घोषणा की गई थी। यदि पहले 20 मॉडल की तस्वीरों का उपयोग करके एक मॉडल को प्रशिक्षित करने में 24 घंटे लगते थे, तो क्रिएट एमएल मैकबुक प्रो पर इस समय को घटाकर 48 मिनट और iMac Pro पर 18 मिनट तक कर देता है। प्रशिक्षित मॉडल का आकार 90 एमबी से घटकर 3 एमबी हो गया।
एमएल बनाएँ आप छवियों, ग्रंथों और संरचित वस्तुओं का उपयोग करने की अनुमति देता है, उदाहरण के लिए, स्रोत डेटा के रूप में।
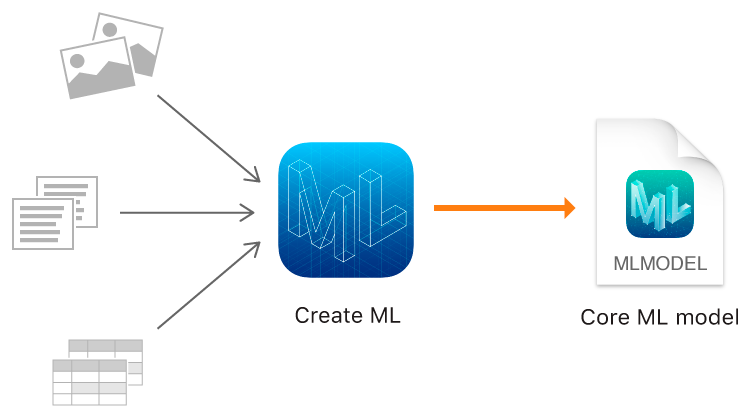
छवि वर्गीकरण
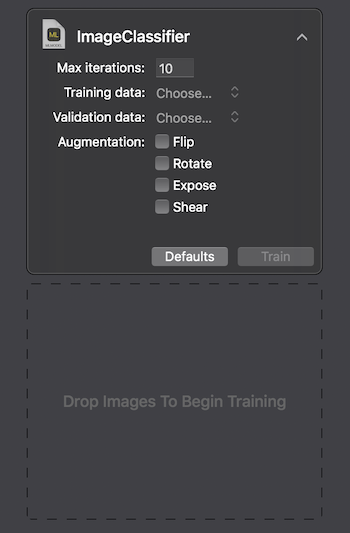
सबसे पहले, आइए देखें कि छवि वर्गीकरण कैसे काम करता है। मॉडल को प्रशिक्षित करने के लिए, हमें एक प्रारंभिक डेटा सेट की आवश्यकता होती है: हम जानवरों के फोटो के तीन समूह लेते हैं: कुत्ते, बिल्ली और पक्षी और उन्हें इसी नाम वाले फ़ोल्डर में वितरित करते हैं, जो मॉडल की श्रेणियों के नाम बन जाएंगे। प्रत्येक समूह में 1920 × 1080 पिक्सेल तक के संकल्प के साथ 100 चित्र और 1Mb तक का आकार होता है। तस्वीरों को यथासंभव अलग होना चाहिए ताकि प्रशिक्षित मॉडल ऐसे संकेतों पर भरोसा न करे जैसे कि छवि या आसपास के स्थान में रंग।
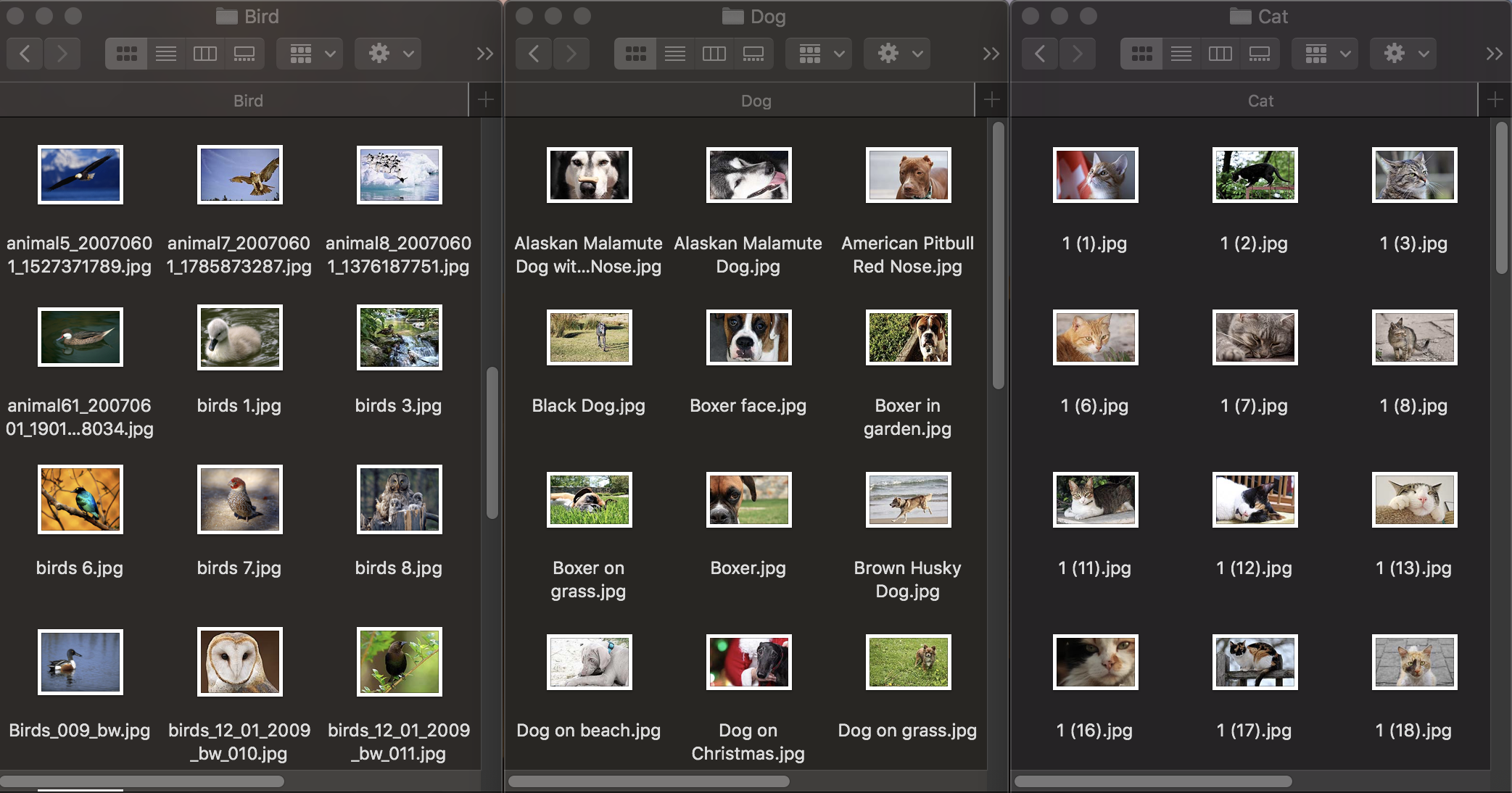
इसके अलावा, यह जांचने के लिए कि कोई प्रशिक्षित मॉडल ऑब्जेक्ट मान्यता को कितनी अच्छी तरह से संभालता है, आपको एक परीक्षण डेटा सेट - छवियों की आवश्यकता है जो मूल डेटासेट में नहीं हैं।
Apple, Create ML से बातचीत करने के दो तरीके प्रदान करता है: MacOS Playground Xcode पर UI का उपयोग करके और CreateMLUI.framework और CreateML.framework का उपयोग करके प्रोग्रामेटिक रूप से। पहली विधि का उपयोग करना, कोड की कुछ पंक्तियों को लिखना, चयनित छवियों को निर्दिष्ट क्षेत्र में स्थानांतरित करना और मॉडल के सीखते समय प्रतीक्षा करना पर्याप्त है।

अधिकतम कॉन्फ़िगरेशन में मैकबुक प्रो 2017 पर, प्रशिक्षण ने 10 पुनरावृत्तियों के लिए 29 सेकंड का समय लिया, और प्रशिक्षित मॉडल का आकार 33 एमबीबी था। यह प्रभावशाली दिखता है।
आइए यह पता लगाने की कोशिश करें कि हम ऐसे संकेतक कैसे हासिल करने में कामयाब रहे और "हुड के तहत" क्या है।
छवियों को वर्गीकृत करने का कार्य जटिल तंत्रिका नेटवर्क के सबसे लोकप्रिय उपयोगों में से एक है। सबसे पहले, यह बताने योग्य है कि वे क्या हैं।
एक व्यक्ति, एक जानवर की छवि को देखकर, किसी भी विशिष्ट विशेषताओं के आधार पर एक निश्चित वर्ग के लिए जल्दी से इसका श्रेय दे सकता है। एक तंत्रिका नेटवर्क बुनियादी विशेषताओं की खोज करके एक समान तरीके से कार्य करता है। एक इनपुट के रूप में पिक्सल्स के शुरुआती ऐरे को लेते हुए, यह क्रमिक रूप से कंडिशनल लेयर्स के समूहों के माध्यम से जानकारी को पार करता है और तेजी से जटिल अमूर्त बनाता है। प्रत्येक बाद की परत पर, वह कुछ विशेषताओं को उजागर करना सीखती है - पहले ये रेखाएं हैं, फिर रेखाओं के सेट, ज्यामितीय आकार, शरीर के कुछ हिस्सों, और इसी तरह। अंतिम परत पर हमें एक वर्ग या संभावित वर्गों के समूह का निष्कर्ष मिलता है।
क्रिएट एमएल के मामले में, तंत्रिका नेटवर्क प्रशिक्षण खरोंच से नहीं किया जाता है। फ्रेमवर्क एक विशाल डेटा सेट पर पहले से प्रशिक्षित तंत्रिका नेटवर्क का उपयोग करता है, जिसमें पहले से ही बड़ी संख्या में परतें शामिल हैं और उच्च सटीकता है।
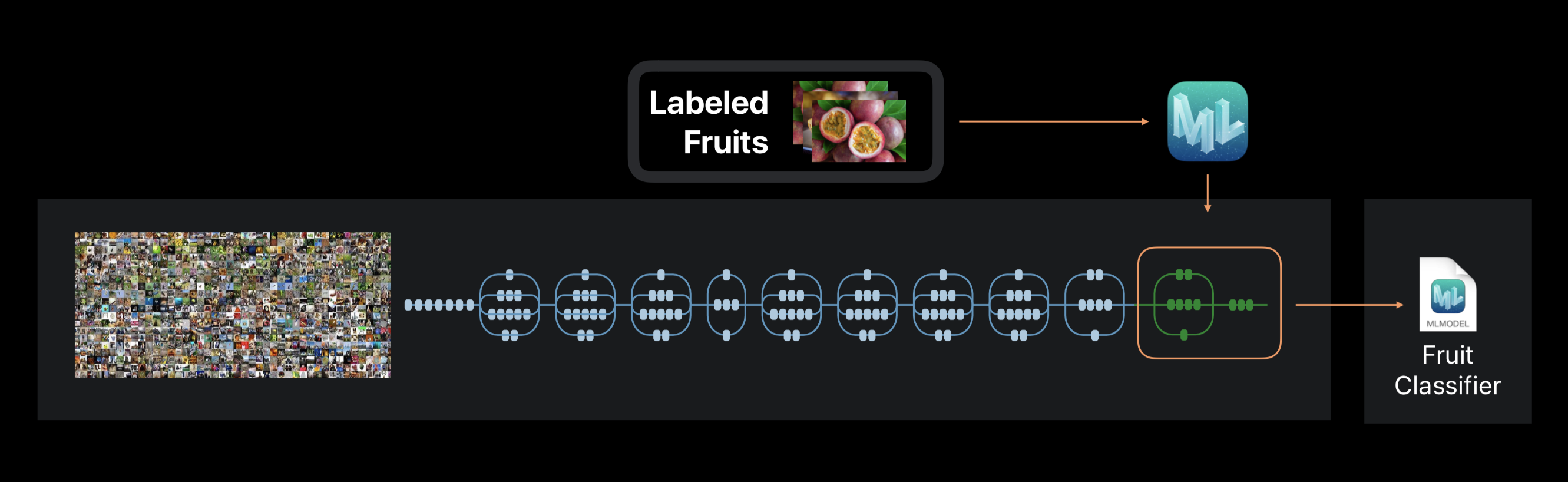
इस तकनीक को ट्रांसफर लर्निंग कहा जाता है। इसके साथ, आप पूर्व-प्रशिक्षित नेटवर्क की वास्तुकला को बदल सकते हैं ताकि यह एक नई समस्या को हल करने के लिए उपयुक्त हो। परिवर्तित नेटवर्क को तब एक नए डेटासेट पर प्रशिक्षित किया जाता है।
1000 विशिष्ट विशेषताओं के बारे में फोटो से प्रशिक्षण अर्क के दौरान एमएल बनाएं। यह वस्तुओं का आकार, बनावट का रंग, आंखों का स्थान, आकार और कई अन्य हो सकता है।
यह ध्यान दिया जाना चाहिए कि प्रारंभिक डेटा सेट जिस पर इस्तेमाल किया गया तंत्रिका नेटवर्क प्रशिक्षित है, हमारी तरह, बिल्लियों, कुत्तों और पक्षियों की तस्वीरें हो सकती हैं, लेकिन इन श्रेणियों को विशेष रूप से आवंटित नहीं किया गया है। सभी श्रेणियां एक पदानुक्रम बनाती हैं। इसलिए, इस नेटवर्क को इसके शुद्ध रूप में लागू करना असंभव है - हमारे डेटा पर इसे वापस लेना आवश्यक है।
प्रक्रिया के अंत में, हम देखते हैं कि हमारे मॉडल को कितनी पुनरावृत्तियों के बाद प्रशिक्षित और परीक्षण किया गया था। परिणामों को बेहतर बनाने के लिए, हम मूल डेटासेट में छवियों की संख्या बढ़ा सकते हैं या पुनरावृत्तियों की संख्या बदल सकते हैं।
अगला, हम परीक्षण डेटा सेट पर स्वयं मॉडल का परीक्षण कर सकते हैं। इसमें चित्र अद्वितीय होने चाहिए, अर्थात् स्रोत सेट में प्रवेश न करें।
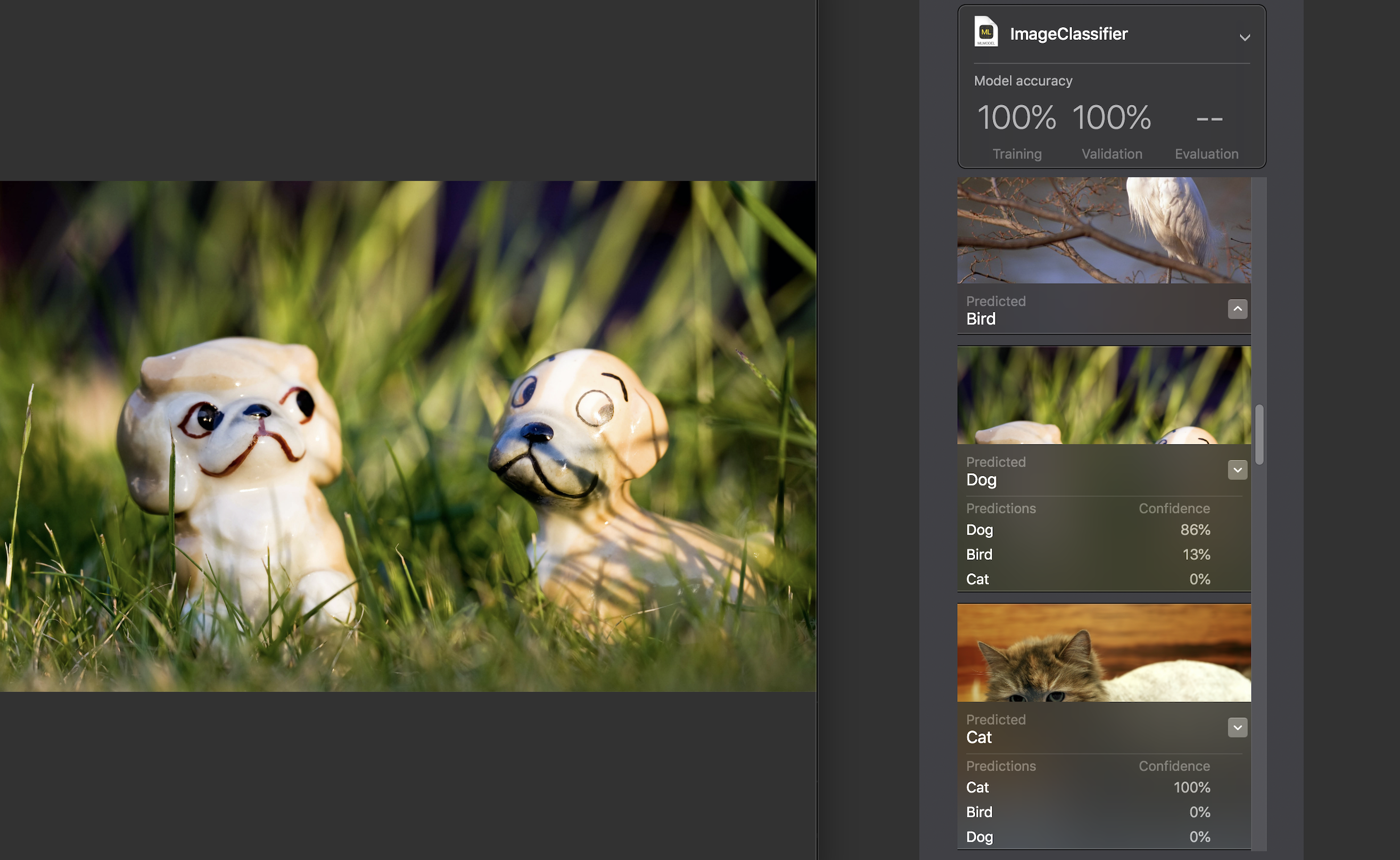
प्रत्येक छवि के लिए, एक विश्वास सूचक प्रदर्शित किया जाता है - हमारे मॉडल की सहायता से श्रेणी को कितनी सही पहचान मिली।
लगभग सभी तस्वीरों के लिए, दुर्लभ अपवादों के साथ, यह आंकड़ा 100% था। मैंने विशेष रूप से उस छवि को जोड़ा है जिसे आप परीक्षण डेटासेट के ऊपर देखते हैं, और, जैसा कि आप देख सकते हैं, इसमें एमएल बनाएँ पहचानें 86% कुत्ते और 13% पक्षी।
मॉडल प्रशिक्षण पूरा हो गया है, और हमारे लिए जो कुछ भी बचा हुआ है वह * .mlmodel फ़ाइल को सहेजना और इसे अपनी परियोजना में जोड़ना है।
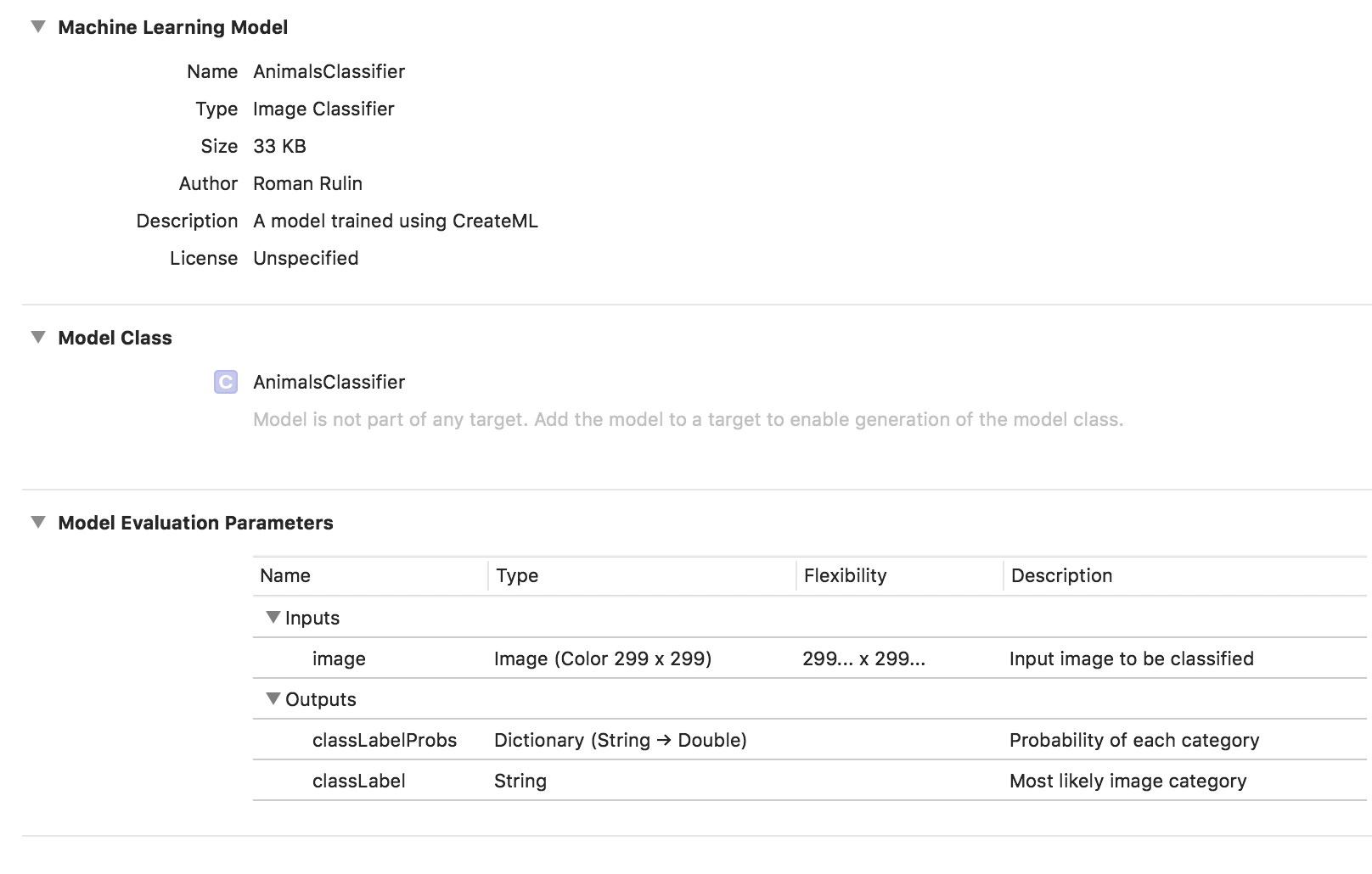
मॉडल का परीक्षण करने के लिए, मैंने विज़न फ्रेमवर्क का उपयोग करके एक सरल अनुप्रयोग लिखा। यह आपको कोर एमएल मॉडल के साथ काम करने और समस्याओं का समाधान करने की अनुमति देता है, जैसे कि छवि वर्गीकरण या ऑब्जेक्ट डिटेक्शन।
हमारा आवेदन डिवाइस के कैमरे से छवि को पहचान लेगा और वर्गीकरण में श्रेणी और प्रतिशत विश्वास प्रदर्शित करेगा।
हम विज़न के साथ काम करने और क्वेरी को कॉन्फ़िगर करने के लिए कोर एमएल मॉडल को इनिशियलाइज़ करते हैं:
func setupVision() { guard let visionModel = try? VNCoreMLModel(for: AnimalsClassifier().model) else { fatalError("Can't load VisionML model") } let request = VNCoreMLRequest(model: visionModel) { (request, error) in guard let results = request.results else { return } self.handleRequestResults(results) } requests = [request] }
एक ऐसा तरीका जोड़ें जो VNCoreMLRequest के परिणामों को संसाधित करेगा। हम केवल 70% से अधिक के आत्मविश्वास वाले संकेतक दिखाते हैं:
func handleRequestResults(_ results: [Any]) { let categoryText: String? defer { DispatchQueue.main.async { self.categoryLabel.text = categoryText } } guard let foundObject = results .compactMap({ $0 as? VNClassificationObservation }) .first(where: { $0.confidence > 0.7 }) else { categoryText = nil return } let category = categoryTitle(identifier: foundObject.identifier) let confidence = "\(round(foundObject.confidence * 100 * 100) / 100)%" categoryText = "\(category) \(confidence)" }
और अंतिम - हम प्रतिनिधि विधि जोड़ेंगे AVCaptureVideoDataOutputSampleBufferDelegate, जिसे कैमरे से हर नए फ्रेम के साथ बुलाया जाएगा और अनुरोध निष्पादित किया जाएगा:
func captureOutput( _ output: AVCaptureOutput, didOutput sampleBuffer: CMSampleBuffer, from connection: AVCaptureConnection) { guard let pixelBuffer = CMSampleBufferGetImageBuffer(sampleBuffer) else { return } var requestOptions: [VNImageOption: Any] = [:] if let cameraIntrinsicData = CMGetAttachment( sampleBuffer, key: kCMSampleBufferAttachmentKey_CameraIntrinsicMatrix, attachmentModeOut: nil) { requestOptions = [.cameraIntrinsics:cameraIntrinsicData] } let imageRequestHandler = VNImageRequestHandler( cvPixelBuffer: pixelBuffer, options: requestOptions) do { try imageRequestHandler.perform(requests) } catch { print(error) } }
आइए देखें कि मॉडल अपने कार्य को कितनी अच्छी तरह से करता है:

श्रेणी काफी उच्च सटीकता के साथ निर्धारित की जाती है, और यह विशेष रूप से आश्चर्य की बात है जब आप विचार करते हैं कि प्रशिक्षण कितनी जल्दी चला गया और मूल डाटासेट कितना छोटा था। समय-समय पर, एक अंधेरे पृष्ठभूमि के खिलाफ, मॉडल पक्षियों को प्रकट करता है, लेकिन मुझे लगता है कि मूल डेटा सेट में छवियों की संख्या में वृद्धि या आत्मविश्वास के न्यूनतम स्वीकार्य स्तर को बढ़ाकर इसे आसानी से हल किया जा सकता है।
यदि हम मॉडल को किसी अन्य श्रेणी में वर्गीकृत करने के लिए फिर से तैयार करना चाहते हैं, तो बस छवियों का एक नया समूह जोड़ें और प्रक्रिया को दोहराएं - इसमें कुछ मिनट लगेंगे।
एक प्रयोग के रूप में, मैंने एक और डेटा सेट बनाया, जिसमें मैंने विभिन्न कोणों से एक बिल्ली की तस्वीर में बिल्लियों की सभी तस्वीरों को बदल दिया, लेकिन एक ही पृष्ठभूमि पर और एक ही वातावरण में। इस मामले में, मॉडल ने लगभग हमेशा गलतियां कीं और एक खाली कमरे में श्रेणी को पहचान लिया, जाहिरा तौर पर एक प्रमुख विशेषता के रूप में रंग पर निर्भर था।
इस वर्ष केवल विज़न में पेश की गई एक और दिलचस्प विशेषता यह है कि वास्तविक समय में छवि में वस्तुओं को पहचानने की क्षमता है। यह VNRecognizedObjectObservation वर्ग द्वारा दर्शाया गया है, जो आपको किसी ऑब्जेक्ट की श्रेणी और उसके स्थान - बाउंडिंगबॉक्स को प्राप्त करने की अनुमति देता है।

अब Create ML इस कार्यक्षमता को लागू करने के लिए मॉडल बनाने की अनुमति नहीं देता है। Apple इस मामले में Turi Create का उपयोग करने का सुझाव देता है। यह प्रक्रिया ऊपर से बहुत अधिक जटिल नहीं है: आपको फोटो के साथ श्रेणी फ़ोल्डर तैयार करने की आवश्यकता है और एक फ़ाइल जिसमें प्रत्येक छवि के लिए आयत के निर्देशांक जहां ऑब्जेक्ट स्थित है, इंगित किया जाएगा।
प्राकृतिक भाषा प्रसंस्करण
अगला बनाएँ एमएल फ़ंक्शन प्राकृतिक भाषा में ग्रंथों को वर्गीकृत करने के लिए मॉडल को प्रशिक्षित करना है - उदाहरण के लिए, वाक्यों के भावनात्मक रंग को निर्धारित करने या स्पैम का पता लगाने के लिए।
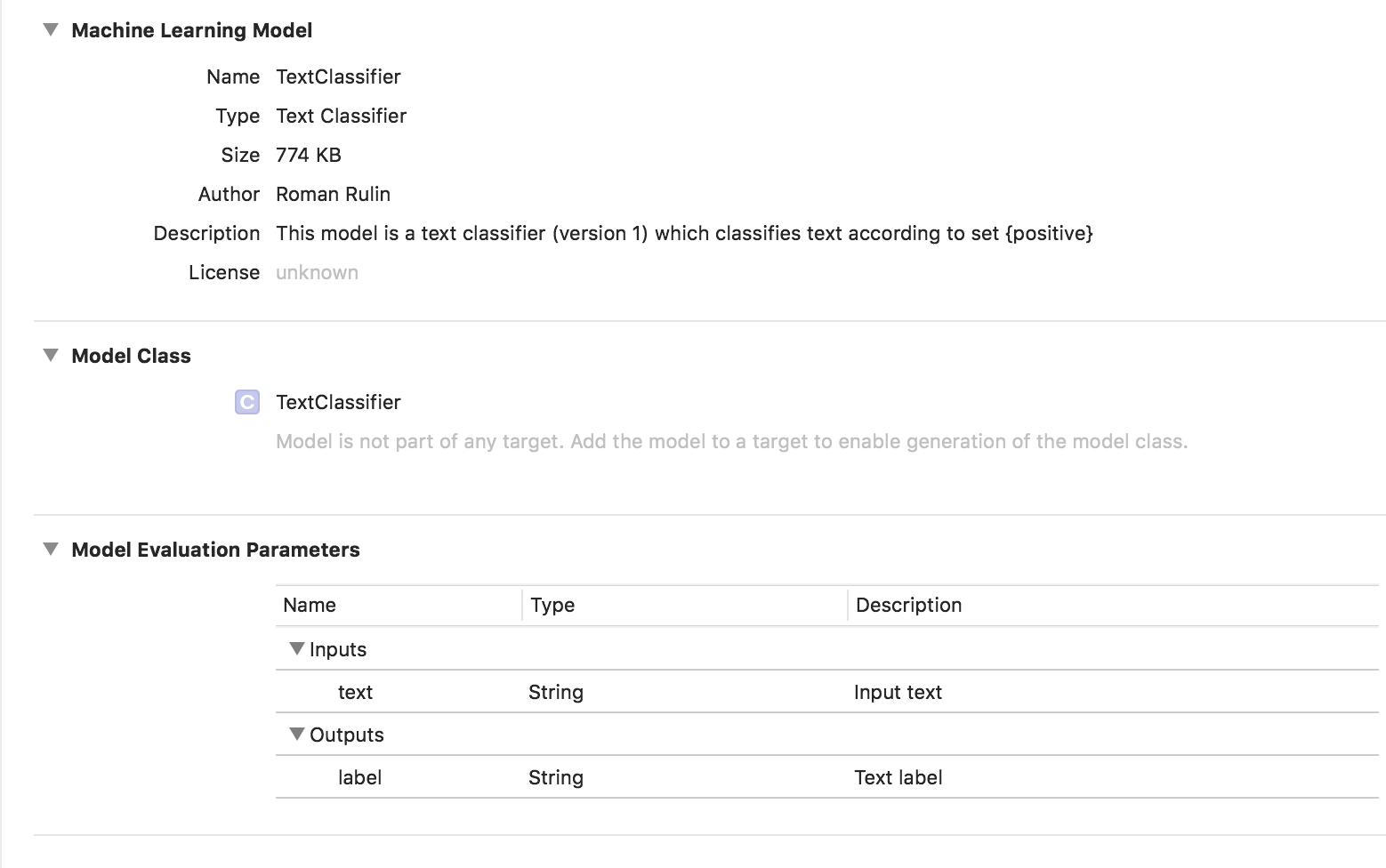
एक मॉडल बनाने के लिए, हमें मूल डेटा सेट के साथ एक तालिका एकत्र करनी चाहिए - वाक्य या पूरे ग्रंथों को एक निश्चित श्रेणी में सौंपा गया है, और MLTextClassifier ऑब्जेक्ट का उपयोग करके मॉडल को प्रशिक्षित करें:
let data = try MLDataTable(contentsOf: URL(fileURLWithPath: "/Users/CreateMLTest/texts.json")) let (trainingData, testingData) = data.randomSplit(by: 0.8, seed: 5) let textClassifier = try MLTextClassifier(trainingData: trainingData, textColumn: "text", labelColumn: "label") try textClassifier.write(to: URL(fileURLWithPath: "/Users/CreateMLTest/TextClassifier.mlmodel"))
इस मामले में, प्रशिक्षित मॉडल टेक्स्ट क्लासिफायर का प्रकार है:
सारणीबद्ध डेटा
आइए Create ML की एक और विशेषता पर करीब से नज़र डालें - संरचित डेटा (तालिकाओं) का उपयोग करके एक मॉडल को प्रशिक्षित करना।
हम एक परीक्षण एप्लिकेशन लिखेंगे जो नक्शे और अन्य निर्दिष्ट मापदंडों के आधार पर एक अपार्टमेंट की कीमत की भविष्यवाणी करता है।
इसलिए, हमारे पास मास्को में एक csv फ़ाइल के रूप में अपार्टमेंट पर सार डेटा के साथ एक तालिका है: प्रत्येक अपार्टमेंट का क्षेत्र, फर्श, कमरों की संख्या और निर्देशांक (अक्षांश और देशांतर) ज्ञात हैं। इसके अलावा, प्रत्येक अपार्टमेंट की लागत ज्ञात है। केंद्र या क्षेत्र जितना बड़ा होगा, कीमत उतनी ही अधिक होगी।
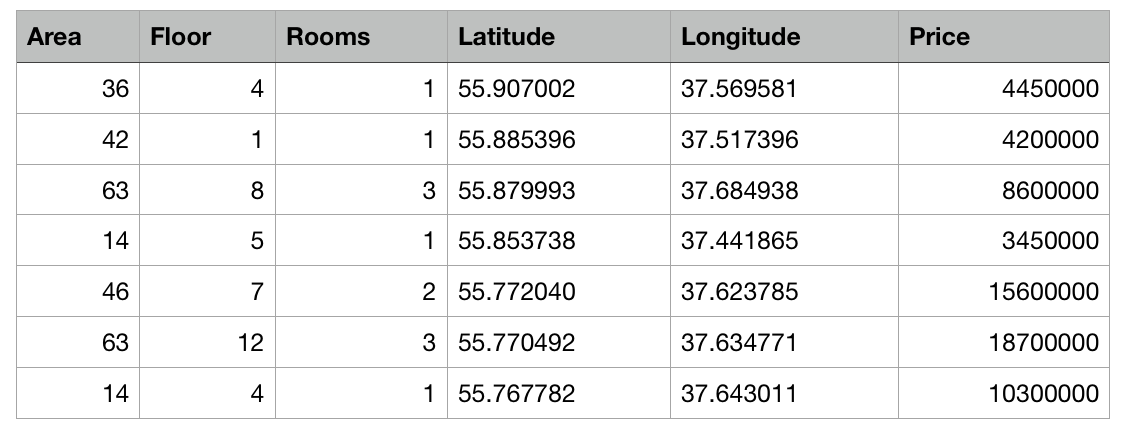
क्रिएट एमएल का काम इन विशेषताओं के आधार पर एक अपार्टमेंट की कीमत का अनुमान लगाने में सक्षम मॉडल का निर्माण करना होगा। मशीन लर्निंग में इस तरह के कार्य को प्रतिगमन कार्य कहा जाता है और एक शिक्षक के साथ सीखने का एक उत्कृष्ट उदाहरण है।
बनाएँ एमएल कई मॉडल का समर्थन करता है - रैखिक प्रतिगमन, निर्णय ट्री प्रतिगमन, ट्री क्लासिफायर, लॉजिस्टिक प्रतिगमन, रैंडम फ़ॉरेस्ट क्लासिफ़ायर, बूस्टेड ट्रीज़ प्रतिगमन, आदि।
हम MLRegressor ऑब्जेक्ट का उपयोग करेंगे, जो इनपुट डेटा के आधार पर सर्वश्रेष्ठ विकल्प का चयन करेगा।
सबसे पहले, हमारी CSV फ़ाइल की सामग्री के साथ MLDataTable ऑब्जेक्ट को इनिशियलाइज़ करें:
let trainingFile = URL(fileURLWithPath: "/Users/CreateMLTest/Apartments.csv") let apartmentsData = try MLDataTable(contentsOf: trainingFile)
हम मॉडल प्रशिक्षण और परीक्षण के लिए प्रारंभिक डेटा को 80/20 के प्रतिशत में विभाजित करते हैं:
let (trainingData, testData) = apartmentsData.randomSplit(by: 0.8, seed: 0)
हम MLRegressor मॉडल बनाते हैं, प्रशिक्षण के लिए डेटा और उस कॉलम के नाम का संकेत देते हैं, जिनके मूल्यों की हम भविष्यवाणी करना चाहते हैं। इनपुट डेटा के अध्ययन के आधार पर टास्क-स्पेसिफिक प्रकार के रेजिस्टर (लीनियर, डिसीजन ट्री, बूस्टेड ट्री या रैंडम फॉरेस्ट) को स्वतः चुना जाएगा। हम विश्लेषण के लिए फीचर कॉलम - विशिष्ट पैरामीटर कॉलम भी निर्दिष्ट कर सकते हैं, लेकिन इस उदाहरण में यह आवश्यक नहीं है, हम सभी मापदंडों का उपयोग करेंगे। अंत में, प्रशिक्षित मॉडल को बचाएं और परियोजना में जोड़ें:
let model = try MLRegressor(trainingData: apartmentsData, targetColumn: "Price") let modelPath = URL(fileURLWithPath: "/Users/CreateMLTest/ApartmentsPricer.mlmodel") try model.write(to: modelPath, metadata: nil)
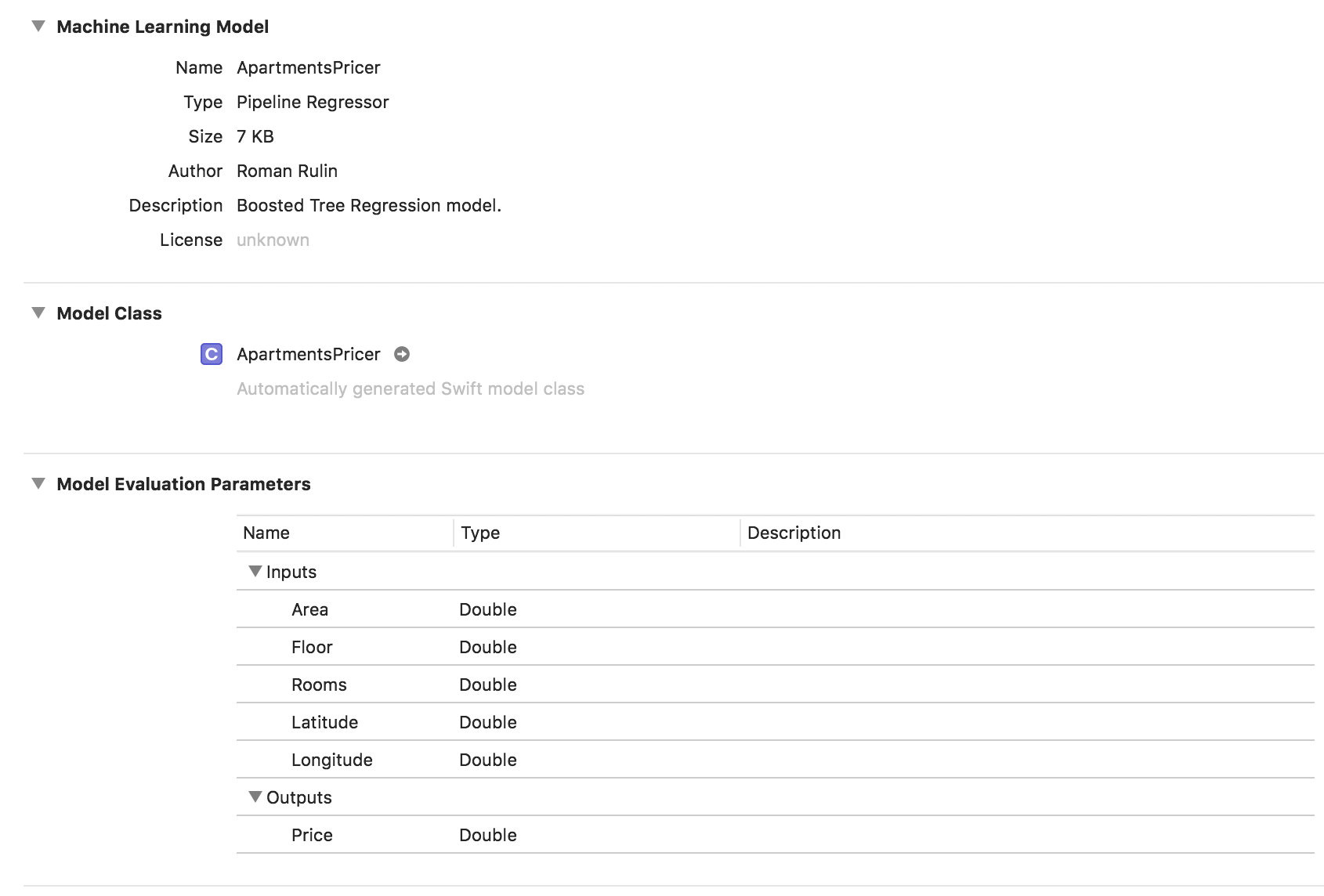
इस उदाहरण में, हम देखते हैं कि मॉडल प्रकार पहले से ही पाइपलाइन रेजिस्टर है, और विवरण फ़ील्ड में स्वचालित रूप से चयनित रेजिस्टर प्रकार - बूस्टेड ट्री रिग्रेशन मॉडल शामिल है। इनपुट और आउटपुट पैरामीटर तालिका के कॉलम के अनुरूप हैं, लेकिन उनका डेटा प्रकार डबल हो गया है।
अब परिणाम की जांच करें।
मॉडल ऑब्जेक्ट को प्रारंभ करें:
let model = ApartmentsPricer()
हम भविष्यवाणी विधि को कहते हैं, इसके लिए निर्दिष्ट पैरामीटर पास करते हैं:
let area = Double(areaSlider.value) let floor = Double(floorSlider.value) let rooms = Double(roomsSlider.value) let latitude = annotation.coordinate.latitude let longitude = annotation.coordinate.longitude let prediction = try? model.prediction( area: area, floor: floor, rooms: rooms, latitude: latitude, longitude: longitude)
हम लागत के अनुमानित मूल्य को प्रदर्शित करते हैं:
let price = prediction?.price priceLabel.text = formattedPrice(price)
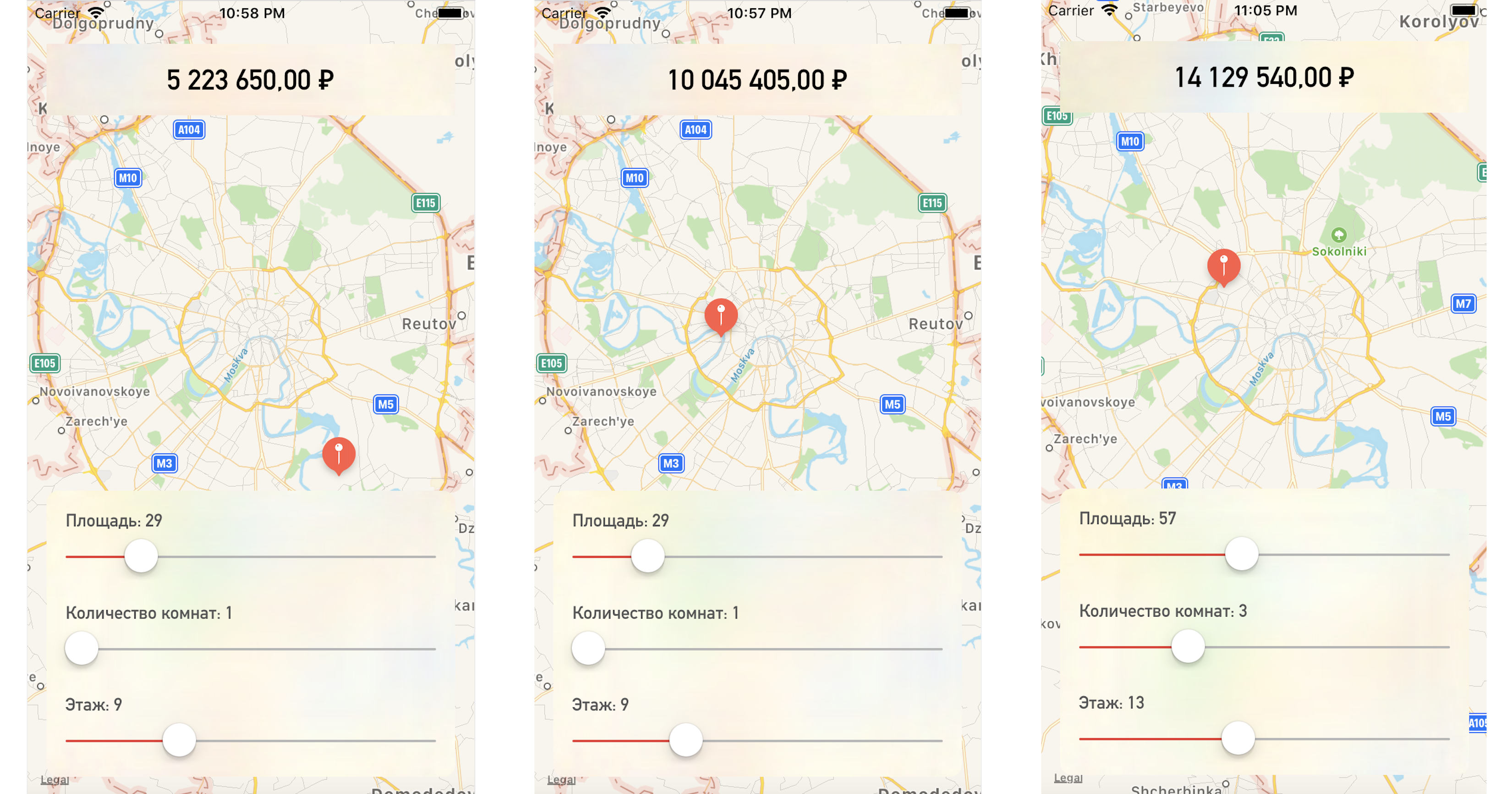
मानचित्र या पैरामीटर मानों पर एक बिंदु बदलते हुए, हमें अपार्टमेंट की कीमत हमारे परीक्षण डेटा के बहुत करीब मिलती है:
निष्कर्ष
मशीन लर्निंग प्रौद्योगिकियों के साथ काम करने के लिए बनाएँ एमएल फ्रेमवर्क अब सबसे आसान तरीकों में से एक है। यह अभी तक कुछ समस्याओं को हल करने के लिए मॉडल बनाने की अनुमति नहीं देता है: एक छवि में वस्तुओं की पहचान, एक फोटो का स्टाइलाइजेशन, इसी तरह की छवियों का निर्धारण, एक एक्सेलेरोमीटर या जाइरोस्कोप से डेटा के आधार पर शारीरिक क्रियाओं की मान्यता, जो टूरी क्रिएट करता है, उदाहरण के लिए, हैंडल।
लेकिन यह ध्यान देने योग्य है कि पिछले एक साल में Apple ने इस क्षेत्र में काफी गंभीर प्रगति की है, और, निश्चित रूप से, हम जल्द ही वर्णित तकनीकों के विकास को देखेंगे।