पिछले लेख में, हमने RabbitMQ में प्रयुक्त पैटर्न और टोपोलॉजी को देखा। इस भाग में, हम काफ्का की ओर रुख करेंगे और अपने मतभेदों के बारे में कुछ विचार प्राप्त करने के लिए रैबिटएमक्यू के साथ इसकी तुलना करेंगे। यह ध्यान में रखना चाहिए कि इवेंट-ओरिएंटेड एप्लिकेशन आर्किटेक्चर की तुलना डाटा प्रोसेसिंग पाइपलाइनों के बजाय की जाएगी, हालांकि इस मामले में इन दोनों अवधारणाओं के बीच की रेखा धुंधली होगी। सामान्य तौर पर, यह एक स्पष्ट पृथक्करण की तुलना में अधिक स्पेक्ट्रम है। हमारी तुलना बस इवेंट-संचालित अनुप्रयोगों से संबंधित इस स्पेक्ट्रम के हिस्से पर ध्यान केंद्रित करेगी।

सबसे पहला अंतर जो दिमाग में आता है वह यह है कि रैबिटएमक्यू द्वारा काफ्का में डेड-लेटर संदेशों के साथ काम करने के लिए उपयोग किए जाने वाले संदेश पुनर्प्रयास और स्नूज़ तंत्र अर्थहीन हैं। RabMMQ में, संदेश अस्थायी होते हैं, वे प्रसारित होते हैं और गायब हो जाते हैं। इसलिए, उन्हें फिर से जोड़ना एक बिल्कुल वास्तविक उपयोग का मामला है। और काफ्का में, पत्रिका केंद्र चरण लेती है। कतार में संदेश भेजकर वितरण की समस्याओं को हल करने का कोई मतलब नहीं है और केवल पत्रिका को परेशान करता है। फ़ायदों में से एक पत्रिका के विभाजन के दौरान संदेशों के स्पष्ट वितरण की गारंटी है, दोहराया संदेश एक अच्छी तरह से संगठित योजना को भ्रमित करते हैं। RabbitMQ में, आप पहले से ही उस संदेश को कतार में भेज सकते हैं जिसके साथ एक प्राप्तकर्ता काम करता है, और कफका मंच पर सभी प्राप्तकर्ताओं के लिए एक पत्रिका है। डिलीवरी में देरी और संदेश वितरण में समस्याएं पत्रिका के संचालन के लिए बहुत नुकसान नहीं पहुंचाती हैं, लेकिन काफ्का में अंतर्निहित विलंब तंत्र शामिल नहीं हैं।
संदेश योजनाओं पर अनुभाग में कफका मंच पर संदेशों को फिर से कैसे वितरित किया जाए, इस पर चर्चा की जाएगी।
दूसरा बड़ा अंतर जो संभावित मैसेजिंग स्कीमों को प्रभावित करता है वह यह है कि रैबिटएमक्यू मैसेज काफ्का की तुलना में बहुत कम स्टोर करता है। जब एक संदेश पहले से ही प्राप्तकर्ता को RabbitMQ में दिया गया है, तो उसे उसके अस्तित्व का पता लगाए बिना हटा दिया जाता है। कफ़्का में, हर संदेश को तब तक लॉग में रखा जाता है जब तक कि वह साफ़ न हो जाए। क्लीनअप की आवृत्ति उपलब्ध डेटा की मात्रा, डिस्क स्थान की मात्रा पर निर्भर करती है जिसे आप उनके लिए आवंटित करने की योजना बनाते हैं, और संदेश योजनाएं जो आप प्रदान करना चाहते हैं। आप उस समय विंडो का उपयोग कर सकते हैं जिस पर हम संदेशों को एक निश्चित अवधि के लिए संग्रहीत करते हैं: पिछले कुछ दिन / सप्ताह / महीने।
इस तरह, काफ्का प्राप्तकर्ता को पिछले संदेशों को फिर से देखने या पुनः प्राप्त करने की अनुमति देता है। यह संदेश भेजने के लिए एक तकनीक की तरह दिखता है, हालांकि यह RabbitMQ के समान काम नहीं करता है।
यदि RabbitMQ संदेश ले जाता है और जटिल रूटिंग स्कीम बनाने के लिए शक्तिशाली तत्व प्रदान करता है, तो काफ्का सिस्टम की वर्तमान और पिछली स्थिति को बचाता है। यह प्लेटफॉर्म विश्वसनीय ऐतिहासिक डेटा के स्रोत के रूप में इस्तेमाल किया जा सकता है क्योंकि RabbitMQ नहीं कर सकता।
काफ्का मंच पर उदाहरण संदेश योजना
RabbitMQ और Kafka दोनों का उपयोग करने का सबसे सरल उदाहरण "प्रकाशक-ग्राहक" योजना के अनुसार सूचना का प्रसार है। एक या अधिक प्रकाशक विभाजन लॉग में संदेश जोड़ते हैं, और ये संदेश ग्राहकों के एक या अधिक समूहों द्वारा प्राप्त किए जाते हैं।

चित्र 1. कई प्रकाशक विभाजन लॉग में संदेश भेजते हैं, और प्राप्तकर्ताओं के कई समूह उन्हें प्राप्त करते हैं।
यदि आप इस बारे में विवरण में नहीं जाते हैं कि प्रकाशक जर्नल के आवश्यक अनुभागों को संदेश कैसे भेजता है, और प्राप्तकर्ता समूह आपस में कैसे समन्वित होते हैं, तो यह योजना RabbitQQ में उपयोग किए जाने वाले फैनआउट टोपोलॉजी (कांटेक्ट एक्सचेंज) से अलग नहीं है।
पिछले लेख में, सभी RabbitMQ संदेश योजनाओं और टोपोलॉजी पर चर्चा की गई थी। शायद किसी समय आपने सोचा था कि "मुझे इन सभी कठिनाइयों की आवश्यकता नहीं है, मैं सिर्फ कतार में संदेश भेजना और प्राप्त करना चाहता हूं", और यह तथ्य कि आप पत्रिका को पिछले पदों पर वापस ला सकते हैं, काफ्का के स्पष्ट लाभों के बारे में बात की थी।
जो लोग कतारबद्ध प्रणालियों की पारंपरिक विशेषताओं के लिए उपयोग किए जाते हैं, उनके लिए घड़ी को पीछे ले जाने और अतीत में ईवेंट लॉग को दोबारा जोड़ने की संभावना का तथ्य आश्चर्यजनक है। यह संपत्ति (कतार के बजाय लॉग का उपयोग करके उपलब्ध) विफलताओं से उबरने के लिए बहुत उपयोगी है। मैं (अंग्रेजी लेख के लेखक) ने 4 साल पहले अपने मौजूदा क्लाइंट के लिए सर्वर सिस्टम सपोर्ट ग्रुप के तकनीकी प्रबंधक के रूप में काम करना शुरू किया था। हमारे पास 50 से अधिक एप्लिकेशन थे जिन्हें MSMQ के माध्यम से व्यावसायिक घटनाओं के बारे में वास्तविक समय की जानकारी प्राप्त हुई, और सामान्य बात यह थी कि जब आवेदन में कोई त्रुटि हुई, तो सिस्टम ने अगले दिन ही इसका पता लगा लिया। दुर्भाग्य से, अक्सर संदेश एक परिणाम के रूप में गायब हो गए, लेकिन आमतौर पर हम तीसरे डेटा सिस्टम से प्रारंभिक डेटा प्राप्त करने में सक्षम थे और आगे के संदेशों को केवल "ग्राहक" को समस्या हुई थी। इससे हमें प्राप्तकर्ताओं के लिए एक मैसेजिंग इन्फ्रास्ट्रक्चर बनाने की आवश्यकता हुई। और अगर हमारे पास काफ़्का प्लेटफ़ॉर्म था, तो इस तरह के काम को करना ज्यादा मुश्किल नहीं होगा क्योंकि लिंक के लिए अंतिम प्राप्त संदेश के स्थान को बदलने के लिए जिसमें त्रुटि हुई थी।
इवेंट-ओरिएंटेड एप्लिकेशन और सिस्टम्स में डेटा इंटीग्रेशन
यह योजना कई मायनों में घटनाओं को उत्पन्न करने का एक साधन है, हालांकि एक भी आवेदन से संबंधित नहीं है। इवेंट पीढ़ी के दो स्तर हैं: सॉफ्टवेयर और सिस्टम। वर्तमान योजना बाद से जुड़ी हुई है।
कार्यक्रम स्तर की इवेंट जनरेशन
अनुप्रयोग इवेंट स्टोर में संग्रहीत परिवर्तन ईवेंट के एक अपरिवर्तनीय अनुक्रम के माध्यम से अपने स्वयं के राज्य का प्रबंधन करता है। आवेदन की वर्तमान स्थिति प्राप्त करने के लिए, आपको सही क्रम में इसकी घटनाओं को खेलना या संयोजित करना चाहिए। आमतौर पर ऐसे मॉडल में, CQRS काफ्का मॉडल को इस प्रणाली के रूप में इस्तेमाल किया जा सकता है।
सिस्टम स्तर पर अनुप्रयोगों के बीच सहभागिता।
एप्लिकेशन या सेवाएं किसी भी तरह से अपने राज्य का प्रबंधन कर सकती हैं, जो उनके डेवलपर प्रबंधन करना चाहते हैं, उदाहरण के लिए, एक नियमित संबंधपरक डेटाबेस में।
लेकिन अनुप्रयोगों को अक्सर एक-दूसरे के बारे में डेटा की आवश्यकता होती है, यह सबऑप्टिमल आर्किटेक्चर की ओर जाता है, उदाहरण के लिए, सामान्य डेटाबेस, इकाई सीमाओं का धुंधला होना या असुविधाजनक रीस्ट एपीआई।
मैं (अंग्रेजी लेख के लेखक) ने पॉडकास्ट " सॉफ्टवेयर इंजीनियरिंग डेली " को सुना, जो सामाजिक नेटवर्क पर सेवा प्रोफाइल के लिए एक घटना-उन्मुख परिदृश्य का वर्णन करता है। सिस्टम में कई संबंधित सेवाएं हैं, जैसे कि खोज, सामाजिक ग्राफ़ की एक प्रणाली, एक सिफारिश इंजन, आदि, इन सभी को उपयोगकर्ता प्रोफ़ाइल की स्थिति में बदलाव के बारे में जानने की आवश्यकता है। जब मैंने (अंग्रेजी लेख के लेखक) ने हवाई परिवहन से संबंधित प्रणाली के लिए वास्तुकला के एक वास्तुकार के रूप में काम किया था, तो हमारे पास संबंधित छोटी सेवाओं के असंख्य के साथ दो बड़े सॉफ्टवेयर सिस्टम थे। समर्थन सेवाओं के लिए आदेश और उड़ान डेटा की आवश्यकता होती है। हर बार एक ऑर्डर बनाया या बदला गया, जब एक उड़ान में देरी या रद्द हो गई, तो इन सेवाओं को सक्रिय करना पड़ा।
इसे घटनाओं को उत्पन्न करने के लिए एक तकनीक की आवश्यकता थी। लेकिन पहले, आइए कुछ सामान्य समस्याओं को देखें जो बड़े सॉफ़्टवेयर सिस्टम में उत्पन्न होती हैं, और देखें कि कैसे घटनाओं की पीढ़ी उन्हें हल कर सकती है।
एक बड़ी एकीकृत कॉर्पोरेट प्रणाली आमतौर पर संगठनात्मक रूप से विकसित होती है; नई प्रौद्योगिकियों और नए आर्किटेक्चर के लिए पलायन किया जाता है, जो सिस्टम के 100% को प्रभावित नहीं कर सकता है। डेटा को संस्था के विभिन्न हिस्सों में वितरित किया जाता है, अनुप्रयोग सार्वजनिक उपयोग के लिए डेटाबेस का खुलासा करते हैं ताकि एकीकरण जितनी जल्दी हो सके, और कोई भी निश्चितता के साथ भविष्यवाणी नहीं कर सकता है कि सिस्टम के सभी तत्व कैसे बातचीत करेंगे।
रैंडम डेटा वितरण
डेटा को विभिन्न स्थानों में वितरित किया जाता है और विभिन्न स्थानों पर प्रबंधित किया जाता है, इसलिए इसे समझना कठिन है:
- व्यवसाय प्रक्रियाओं में डेटा कैसे चलता है;
- सिस्टम के एक भाग में परिवर्तन अन्य भागों को कैसे प्रभावित कर सकते हैं;
- डेटा संघर्षों के साथ क्या करना है जो इस तथ्य के कारण उत्पन्न होते हैं कि डेटा की कई प्रतियां हैं जो धीरे-धीरे फैलती हैं।
यदि डोमेन संस्थाओं की कोई स्पष्ट सीमाएं नहीं हैं, तो परिवर्तन महंगा और जोखिम भरा होगा, क्योंकि वे एक साथ कई प्रणालियों को प्रभावित करते हैं।
केंद्रीकृत वितरित डेटाबेस
सार्वजनिक रूप से खुला डेटाबेस कई समस्याएं पैदा कर सकता है:
- यह प्रत्येक एप्लिकेशन के लिए अलग से पर्याप्त रूप से अनुकूलित नहीं है। सबसे अधिक संभावना है, इस डेटाबेस में एप्लिकेशन के लिए एक अत्यधिक पूर्ण डेटा सेट है, इसके अलावा, इसे इस तरह से सामान्यीकृत किया जाता है कि उन्हें प्राप्त करने के लिए अनुप्रयोगों को बहुत जटिल प्रश्नों को चलाना होगा।
- एक सामान्य डेटाबेस का उपयोग करते हुए, अनुप्रयोग एक दूसरे के काम को प्रभावित कर सकते हैं।
- डेटाबेस की तार्किक संरचना में परिवर्तन के लिए बड़े पैमाने पर समन्वय और डेटा माइग्रेशन पर काम करने की आवश्यकता होती है, और इस पूरी प्रक्रिया की अवधि के लिए व्यक्तिगत सेवाओं के विकास को रोक दिया जाएगा।
- कोई भी भंडारण संरचना को बदलना नहीं चाहता है। जिन परिवर्तनों का सभी को इंतजार है, वे बहुत दर्दनाक हैं।
असुविधाजनक REST API का उपयोग करना
दूसरी ओर REST एपीआई के माध्यम से अन्य प्रणालियों से डेटा प्राप्त करना सुविधा और अलगाव जोड़ता है, लेकिन फिर भी हमेशा सफल नहीं हो सकता है। इस तरह के प्रत्येक इंटरफ़ेस की अपनी विशेष शैली और अपने स्वयं के सम्मेलन हो सकते हैं। आवश्यक डेटा प्राप्त करना बहुत सारे HTTP अनुरोधों की आवश्यकता हो सकती है और काफी जटिल हो सकती है।
हम एपीआई केंद्रितता की ओर अधिक से अधिक बढ़ रहे हैं, और ऐसे आर्किटेक्चर कई फायदे प्रदान करते हैं, खासकर जब सेवाएं स्वयं हमारे नियंत्रण से बाहर हैं। इस समय एक एपीआई बनाने के लिए बहुत सारे सुविधाजनक तरीके हैं कि हमें उतना कोड नहीं लिखना है जितना हमें पहले चाहिए था। फिर भी, यह केवल उपलब्ध उपकरण नहीं है, और सिस्टम की आंतरिक वास्तुकला के लिए विकल्प हैं।
एक घटना भंडार के रूप में काफ्का
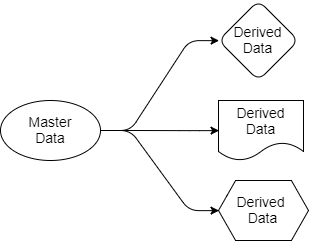
हम एक उदाहरण देते हैं। एक प्रणाली है जो एक रिलेशनल डेटाबेस में आरक्षण का प्रबंधन करती है। सिस्टम अपनी विशेषताओं को प्रभावी ढंग से प्रबंधित करने और सभी को खुश करने के लिए डेटाबेस द्वारा पेश की गई परमाणुता, स्थिरता, अलगाव और स्थायित्व की सभी गारंटी का उपयोग करता है। टीमों और अनुरोधों में जिम्मेदारी का विभाजन, घटनाओं की पीढ़ी, माइक्रोसर्विस अनुपस्थित हैं, सामान्य तौर पर, एक पारंपरिक रूप से निर्मित मोनोलिथ। लेकिन आरक्षण से संबंधित समर्थन सेवाओं (संभवतः माइक्रोसर्विस) के असंख्य हैं: पुश नोटिफिकेशन, ई-मेल वितरण, धोखाधड़ी-रोधी प्रणाली, वफादारी कार्यक्रम, बिलिंग, रद्दीकरण प्रणाली, आदि। सूची आगे बढ़ती है। इन सभी सेवाओं के लिए आरक्षण विवरण की आवश्यकता होती है, और उन्हें प्राप्त करने के कई तरीके हैं। ये सेवाएं स्वयं डेटा का उत्पादन करती हैं जो अन्य अनुप्रयोगों के लिए उपयोगी हो सकता है।

चित्रा 2. विभिन्न प्रकार के डेटा एकीकरण।
काफ्का पर आधारित वैकल्पिक वास्तुकला। हर बार जब आप एक नया आरक्षण करते हैं या पिछले आरक्षण को बदलते हैं, तो सिस्टम इस आरक्षण की वर्तमान स्थिति के बारे में पूरा डाटा कफका को भेजता है। पत्रिका को समेकित करके, आप संदेशों को छोटा कर सकते हैं ताकि नवीनतम बुकिंग स्थिति के बारे में केवल जानकारी इसमें बची रहे। इस मामले में, जर्नल का आकार नियंत्रण में होगा।
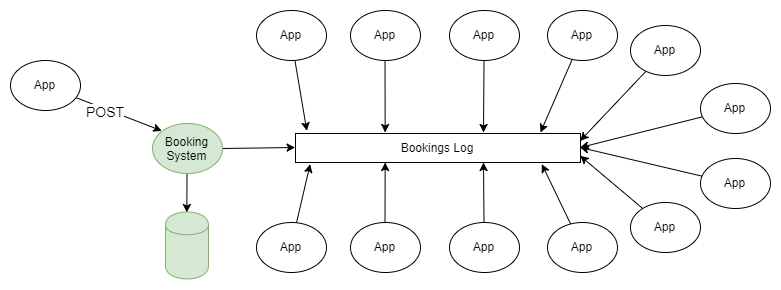
चित्रा 3. घटना पीढ़ी के लिए आधार के रूप में कफका-आधारित डेटा एकीकरण
उन सभी अनुप्रयोगों के लिए जिनके लिए यह आवश्यक है, यह जानकारी सत्य का स्रोत और डेटा का एकमात्र स्रोत है। अचानक, हम काफ़्का विषयों से / से डेटा भेजने और प्राप्त करने के लिए निर्भरता और प्रौद्योगिकियों के एक एकीकृत नेटवर्क से आगे बढ़ रहे हैं।
एक घटना भंडार के रूप में काफ्का:
- यदि डिस्क स्थान के साथ कोई समस्या नहीं है, तो काफ्का घटनाओं के पूरे इतिहास को संग्रहीत कर सकता है, अर्थात, एक नया एप्लिकेशन तैनात किया जा सकता है और जर्नल से सभी आवश्यक जानकारी डाउनलोड कर सकता है। घटनाओं के रिकॉर्ड जो ऑब्जेक्ट की विशेषताओं को पूरी तरह से दर्शाते हैं, लॉग को संकलित करके संकुचित किया जा सकता है, जो इस दृष्टिकोण को कई परिदृश्यों के लिए अधिक न्यायसंगत बना देगा।
- क्या होगा अगर घटनाओं को सही क्रम में खेला जाना चाहिए? जब तक घटनाओं के रिकॉर्ड को सही ढंग से वितरित नहीं किया जाता है, तब तक आप उनके प्लेबैक का क्रम निर्धारित कर सकते हैं और फ़िल्टर, रूपांतरण उपकरण आदि को लागू कर सकते हैं, ताकि डेटा प्लेबैक हमेशा आवश्यक जानकारी पर समाप्त हो जाए। डेटा वितरण की संभावना के आधार पर, सही क्रम में उनकी अत्यधिक समानांतर प्रसंस्करण सुनिश्चित करना संभव है।
- डेटा मॉडल में बदलाव की आवश्यकता हो सकती है। एक नया फ़िल्टर / ट्रांसफ़ॉर्म फ़ंक्शन बनाते समय, पिछले एक सप्ताह में सभी घटनाओं या घटनाओं के रिकॉर्ड को खेलना आवश्यक हो सकता है।
संदेश आपके संगठन के अनुप्रयोगों से न केवल कफ़्का में आ सकते हैं, जो उनकी विशेषताओं (या इन परिवर्तनों के परिणामों) में सभी परिवर्तनों के बारे में संदेश भेजते हैं, लेकिन आपके सिस्टम के साथ एकीकृत तृतीय-पक्ष सेवाओं से भी। यह निम्नलिखित तरीकों से होता है:
- समय-समय पर निर्यात, स्थानांतरण, तृतीय-पक्ष सेवाओं से प्राप्त डेटा का आयात, और काफ्का के लिए उनका डाउनलोड।
- कफका में तृतीय-पक्ष सेवाओं से डेटा डाउनलोड करना।
- CSV और तृतीय-पक्ष सेवाओं से अपलोड किए गए अन्य प्रारूपों का डेटा काफ्का पर अपलोड किया गया है।
आइए उन सवालों पर लौटते हैं, जिन्हें हमने पहले माना था। काफ्का आधारित वास्तुकला डेटा वितरण को सरल करता है। हम जानते हैं कि सत्य का स्रोत कहां है, हम जानते हैं कि इसके डेटा के स्रोत कहां हैं, और सभी लक्ष्य अनुप्रयोग इस डेटा से प्राप्त प्रतियों के साथ काम करते हैं। डेटा प्रेषक से प्राप्तकर्ता तक जाता है। स्रोत डेटा केवल प्रेषक का है, लेकिन अन्य अपने अनुमानों के साथ काम करने के लिए स्वतंत्र हैं। वे अन्य स्रोतों से डेटा के साथ उन्हें फ़िल्टर कर सकते हैं, बदल सकते हैं, उन्हें पूरक कर सकते हैं, उन्हें अपने डेटाबेस में सहेज सकते हैं।
अंजीर 4. स्रोत और आउटपुट डेटा
प्रत्येक एप्लिकेशन जिसे आरक्षण और उड़ान डेटा की आवश्यकता होती है, वह इसे स्वयं प्राप्त करेगा, क्योंकि यह कफ़्का के उन वर्गों को "सब्सक्राइब" किया गया है जिनमें यह डेटा है। इस एप्लिकेशन के लिए, वे SQL, Cypher, JSON, या किसी अन्य क्वेरी भाषा का उपयोग कर सकते हैं। एक एप्लिकेशन इसके सिस्टम में डेटा को सहेज सकता है क्योंकि यह फिट दिखता है। अन्य अनुप्रयोगों के संचालन को प्रभावित किए बिना डेटा वितरण योजना को बदला जा सकता है।
सवाल उठ सकता है: यह सब RabbitMQ का उपयोग क्यों नहीं किया जा सकता है? इसका उत्तर यह है कि RabbitMQ का उपयोग वास्तविक समय में घटनाओं को संसाधित करने के लिए किया जा सकता है, लेकिन घटनाओं को उत्पन्न करने के लिए आधार के रूप में नहीं। RabbitMQ केवल उन घटनाओं का जवाब देने के लिए एक पूर्ण समाधान है जो अभी हो रही हैं। जब एक नया एप्लिकेशन जोड़ा जाता है जिसे इस एप्लिकेशन के कार्यों के लिए अनुकूलित प्रारूप में प्रस्तुत किए गए आरक्षण डेटा के अपने हिस्से की आवश्यकता होती है, तो RabbitMQ मदद करने में सक्षम नहीं होगा। RabbitMQ के साथ, हम साझा डेटाबेस या REST API पर लौटते हैं।
दूसरे, जिस क्रम में घटनाओं को संसाधित किया जाता है वह महत्वपूर्ण है। यदि आप RabbitMQ के साथ काम करते हैं, जब आप कतार में दूसरे प्राप्तकर्ता को जोड़ते हैं, तो आदेश के अनुपालन की गारंटी खो जाती है। इस प्रकार, संदेश भेजने का सही क्रम केवल एक प्राप्तकर्ता के लिए मनाया जाता है, लेकिन यह, ज़ाहिर है, पर्याप्त नहीं है।
कफका, इसके विपरीत, इस एप्लिकेशन को डेटा की अपनी प्रति बनाने और डेटा को अद्यतित रखने के लिए आवश्यक सभी डेटा प्रदान कर सकता है, जबकि काफ्का उस क्रम का अनुसरण करता है जिसमें संदेश भेजे जाते हैं।
अब वापस एपीआई-केंद्रित आर्किटेक्चर पर। क्या ये इंटरफेस हमेशा सबसे अच्छा विकल्प होगा? जब आप रीड-ओनली डेटा एक्सेस खोलना चाहते हैं, तो मैं आर्किटेक्चर उत्सर्जित करने वाली घटना को प्राथमिकता दूंगा। यह कैस्केडिंग विफलताओं को रोकने और अन्य सेवाओं पर निर्भरता की संख्या में वृद्धि के साथ जुड़े जीवनकाल को छोटा करेगा। सिस्टम के भीतर डेटा के रचनात्मक और कुशल संगठन के लिए अधिक अवसर होंगे। लेकिन कभी-कभी आपको अपने सिस्टम और किसी अन्य सिस्टम में डेटा को सिंक्रनाइज़ करने की आवश्यकता होती है, और ऐसी स्थिति में, एपीआई-केंद्रित सिस्टम उपयोगी होंगे। कई उन्हें अन्य अतुल्यकालिक तरीकों के लिए पसंद करते हैं। मुझे लगता है कि यह स्वाद का मामला है।
उच्च ट्रैफ़िक और इवेंट प्रोसेसिंग संवेदनशील अनुप्रयोग।
बहुत समय पहले नहीं, एक समस्या रैबिटबैंक के रिसीवर में से एक के साथ उत्पन्न हुई थी, जिन्होंने तृतीय-पक्ष सेवा से कतारबद्ध फाइलें प्राप्त की थीं। कुल फ़ाइल आकार बड़ा था, और इस तरह के डेटा की मात्रा प्राप्त करने के लिए एप्लिकेशन को विशेष रूप से कॉन्फ़िगर किया गया था। समस्या यह थी कि डेटा असंगत रूप से आया था, इससे बहुत सारी समस्याएं पैदा हुईं।
इसके अलावा, कभी-कभी इस तथ्य में एक समस्या थी कि कभी-कभी दो फाइलें एक ही गंतव्य के लिए अभिप्रेत थीं, और उनके आगमन का समय कई सेकंड से भिन्न था। वे दोनों प्रसंस्करण से गुजरे और उन्हें एक सर्वर पर अपलोड करना पड़ा। और सर्वर पर दूसरा संदेश दर्ज होने के बाद, इसके बाद पहला संदेश दूसरा ओवरराइट करता है। इस प्रकार, अमान्य डेटा को सहेजने के साथ सब कुछ समाप्त हो गया। RabbitMQ ने अपनी भूमिका को पूरा किया और सही क्रम में संदेश भेजे, लेकिन सभी एक ही, सब कुछ आवेदन में ही गलत क्रम में समाप्त हो गया।
इस समस्या को मौजूदा रिकॉर्ड्स से टाइमस्टैम्प पढ़कर और संदेश के पुराने होने पर प्रतिक्रिया की कमी से हल किया गया था। इसके अलावा, डेटा एक्सचेंज के दौरान सुसंगत हैशिंग लगाया गया था, और कतार को विभाजित किया गया था, जैसा कि काफ्का प्लेटफॉर्म पर समान विभाजन के साथ।
विभाजन के हिस्से के रूप में, काफ्का उस क्रम में संदेश संग्रहीत करता है जिसमें उन्हें भेजा गया था। संदेश आदेश केवल विभाजन के भीतर ही मौजूद है। ऊपर के उदाहरण में, काफ्का का उपयोग करते हुए, हमें वांछित विभाजन का चयन करने के लिए गंतव्य के आईडी पर हैश फ़ंक्शन को लागू करना था। हमें विभाजन का एक सेट बनाना था, उनमें से अधिक से अधिक ग्राहक होना चाहिए। संदेश प्रसंस्करण के आदेश को इस तथ्य के कारण प्राप्त किया जाना चाहिए था कि प्रत्येक विभाजन केवल एक प्राप्तकर्ता के लिए है। सरल और प्रभावी।
रैबिटएमक्यू की तुलना में काफ्का में हैशिंग के उपयोग से संदेश विभाजन से जुड़े कुछ फायदे हैं। RabbitMQ प्लेटफ़ॉर्म पर कुछ भी नहीं है जो संगत हैशिंग का उपयोग करके डेटा एक्सचेंज के हिस्से के रूप में उत्पन्न होने वाली एक ही कतार के भीतर प्राप्तकर्ता संघर्ष को रोक देगा। RabbitMQ प्राप्तकर्ता को समन्वित करने में मदद नहीं करता है ताकि पूरी कतार से केवल एक प्राप्तकर्ता संदेश का उपयोग करता है। Kafka प्राप्तकर्ता समूहों और एक समन्वयक नोड के उपयोग के माध्यम से यह सब प्रदान करता है। यह आपको यह सुनिश्चित करने की अनुमति देता है कि संदेश का उपयोग करने के लिए अनुभाग में केवल एक प्राप्तकर्ता की गारंटी है, और यह कि डेटा प्रोसेसिंग ऑर्डर की गारंटी है।
डेटा स्थानीयता
विभाजन के दौरान डेटा वितरित करने के लिए हैश फ़ंक्शन का उपयोग करते हुए, काफ्का डेटा स्थानीयता प्रदान करता है। उदाहरण के लिए, आईडी 1001 वाले उपयोगकर्ता के संदेशों को हमेशा प्राप्तकर्ता के पास जाना चाहिए। चूंकि उपयोगकर्ता 1001 की घटनाएं हमेशा प्राप्तकर्ता 3 तक जाती हैं, प्राप्तकर्ता 3 प्रभावी रूप से कुछ ऑपरेशन कर सकता है जो बाहरी डेटाबेस या अन्य प्रणालियों को प्राप्त करने के लिए नियमित रूप से अधिक कठिन होगा। डेटा। हम डेटा पढ़ सकते हैं, एकत्रीकरण कर सकते हैं, आदि। सीधे प्राप्तकर्ता की मेमोरी में जानकारी के साथ। यह वह स्थान है जहां इवेंट-ओरिएंटेड एप्लिकेशन और डेटा स्ट्रीमिंग गठबंधन करना शुरू करते हैं।
कफका डेटा स्थानीयता कैसे प्रदान करता है? शुरू करने के लिए, यह ध्यान रखना महत्वपूर्ण है कि काफ्का विभाजन की संख्या को बढ़ाने और कम करने की अनुमति नहीं देता है। सबसे पहले, आप विभाजन की संख्या को कम नहीं कर सकते हैं: यदि 10 हैं, तो आप संख्या को 9 तक नहीं घटा सकते हैं। लेकिन, दूसरी ओर, यह आवश्यक नहीं है। प्रत्येक प्राप्तकर्ता 1 या कई विभाजनों का उपयोग कर सकता है, इसलिए, उनकी संख्या को कम करना शायद ही आवश्यक है। काफ्का पर अतिरिक्त विभाजनों के निर्माण से पुनर्संतुलन के समय में देरी होती है, इसलिए हम चोटी के भार को ध्यान में रखते हुए विभाजन की संख्या को मापने की कोशिश करते हैं।
लेकिन अगर हमें अभी भी बड़े पैमाने पर विभाजन और प्राप्तकर्ताओं की संख्या बढ़ाने की आवश्यकता है, तो हमें केवल एक बार अप्रत्यक्ष लागतों की आवश्यकता होगी यदि पुनर्संतुलन आवश्यक है। यह ध्यान दिया जाना चाहिए कि जब पुराने डेटा को स्केलिंग उसी पार्टीशन में रहती है जहां यह था। लेकिन नए आने वाले संदेशों को पहले से ही अलग तरह से रूट किया जाएगा, और नए संदेश प्राप्त करने के लिए नए विभाजन शुरू होंगे। उपयोगकर्ता 1001 के संदेश अब प्राप्तकर्ता 4 पर जा सकते हैं (क्योंकि उपयोगकर्ता 1001 के बारे में डेटा अब दो खंडों में है)।
इसके अलावा हम दोनों प्रणालियों में वितरण संदेशों के वितरण शब्दार्थों की तुलना और तुलना करेंगे। पुनर्संतुलन और विभाजन का विषय एक अलग लेख के योग्य है, जिसकी चर्चा हम अगले भाग में करेंगे।