क्या स्क्रैच से आपके बोल्ड एंटरप्राइज एप्लिकेशन को फिर से लिखने के लिए विचार आपके सिर में रेंग गया? यदि खरोंच से, तो यह वाह है। कम से कम दो बार कम कोड, सही? लेकिन कुछ साल बीत जाएंगे, और यह भी बढ़ेगा, विरासत बन जाएगा ... पूरी तरह से लिखने के लिए बहुत समय और पैसा नहीं है।
शांत हो जाओ, अधिकारियों को अभी भी कुछ भी लिखने की अनुमति नहीं दी जाएगी। यह रिफलेक्टर रहता है। अपने छोटे संसाधनों को खर्च करने का सबसे अच्छा तरीका क्या है? कैसे साफ करने के लिए रिफैक्टर?
इस लेख का शीर्षक चाचा बॉब
की पुस्तक
"क्लीन आर्किटेक्चर" के संदर्भ में है, और यह JPoint पर विक्टर रेंटिया (
ट्विटर ,
वेबसाइट ) द्वारा एक अद्भुत रिपोर्ट के आधार पर बनाया गया था (बिल्ली के तहत वह पहले व्यक्ति में बोलना शुरू कर देगा, लेकिन अब के लिए परिचयात्मक एक पढ़ें)। स्मार्ट किताबें पढ़ना, यह लेख प्रतिस्थापित नहीं करता है, लेकिन इस तरह के एक संक्षिप्त विवरण के लिए बहुत अच्छी तरह से सेट किया गया है।
विचार यह है कि "स्वच्छ वास्तुकला" जैसी लोकप्रिय चीजें वास्तव में उपयोगी हैं। आश्चर्य। यदि आपको बहुत विशिष्ट समस्या को हल करने की आवश्यकता है, तो एक साधारण सुरुचिपूर्ण कोड को अतिरिक्त प्रयास और अति-इंजीनियरिंग की आवश्यकता नहीं है। शुद्ध वास्तुकला का कहना है कि आपको अपने डोमेन मॉडल को बाहरी प्रभावों से बचाने की आवश्यकता है, और आपको बताता है कि यह कैसे किया जा सकता है। माइक्रोसर्विस की मात्रा बढ़ाने के लिए एक विकासवादी दृष्टिकोण। परीक्षण जो कम डरावनी बना देते हैं। आप यह सब पहले से ही जानते हैं? या आप जानते हैं, लेकिन आप इसके बारे में सोचने से भी डरते हैं, क्योंकि यह एक डरावनी घटना है जो आपको तब करनी होगी?
कौन एक जादू विरोधी विलोपन गोली प्राप्त करना चाहता है जो झटकों को रोकने में मदद करेगा और फिर से सक्रिय करना शुरू करेगा - रिपोर्ट या बिल्ली के नीचे वीडियो रिकॉर्डिंग में आपका स्वागत है।
मेरा नाम विक्टर है, मैं रोमानिया से हूँ। औपचारिक रूप से, मैं रोमानियाई आईबीएम में एक सलाहकार, तकनीकी विशेषज्ञ और प्रमुख वास्तुकार हूं। लेकिन अगर मुझे अपनी गतिविधि की परिभाषा खुद देने के लिए कहा गया, तो मैं शुद्ध कोड का एक प्रचारक हूं। मुझे सुंदर, स्वच्छ, समर्थित कोड बनाना पसंद है - एक नियम के रूप में, मैं इस बारे में रिपोर्टों पर बात करता हूं। इससे भी अधिक, मैं शिक्षण से प्रेरित हूं: जावा ईई, स्प्रिंग, डोजो, टेस्ट ड्रिवेन डेवलपमेंट, जावा प्रदर्शन के साथ-साथ उल्लेखित प्रचारवाद के क्षेत्र में प्रशिक्षण डेवलपर्स - स्वच्छ कोड पैटर्न के सिद्धांत और उनके विकास।
यह अनुभव कि मेरा सिद्धांत आधारित है, मुख्य रूप से रोमानिया में सबसे बड़े आईबीएम ग्राहक के लिए उद्यम अनुप्रयोगों का विकास है - बैंकिंग क्षेत्र।
इस लेख की योजना इस प्रकार है:
- डेटा मॉडलिंग: डेटा संरचनाएं हमारे दुश्मन नहीं बनने चाहिए;
- तर्क का संगठन: "कोड के अपघटन, जो बहुत अधिक है" का सिद्धांत;
- "प्याज" शुद्धतम लेनदेन लिपि दर्शन वास्तुकला है;
- डेवलपर के डर से निपटने के तरीके के रूप में परीक्षण।
लेकिन पहले, हम मुख्य सिद्धांतों को याद करते हैं जो हम, डेवलपर्स के रूप में, हमेशा याद रखना चाहिए।
एकमात्र जिम्मेदारी का सिद्धांत

दूसरे शब्दों में, मात्रा बनाम गुणवत्ता। एक नियम के रूप में, आपकी कक्षा में जितनी अधिक कार्यक्षमता होती है, उतना ही यह गुणात्मक अर्थ में बदल जाता है। बड़ी कक्षाओं का विकास करना, प्रोग्रामर भ्रमित होना शुरू कर देता है, निर्भरता बनाने में गलतियां करता है, और बड़ी कोड, अन्य चीजों के साथ, डिबग करना अधिक कठिन होता है। ऐसी कक्षा को कई छोटे लोगों में तोड़ना बेहतर होता है, जिनमें से प्रत्येक कुछ उपमाओं के लिए जिम्मेदार होगा। बेहतर एक से कुछ कसकर युग्मित मॉड्यूल हैं - बड़े और धीमे। प्रतिरूपकता भी तर्क के पुन: उपयोग की अनुमति देती है।
कमजोर मॉड्यूल बाध्यकारी

बाइंडिंग की डिग्री एक माप है कि आपके मॉड्यूल एक-दूसरे के साथ कितनी निकटता से बातचीत करते हैं। यह दिखाता है कि सिस्टम में किसी एक बिंदु पर आपके द्वारा किए गए परिवर्तनों का प्रभाव कितना व्यापक रूप से फैल सकता है। बाध्यकारी जितना अधिक होगा, संशोधन करना उतना ही कठिन होगा: आप एक मॉड्यूल में कुछ बदलते हैं, और प्रभाव दूर तक फैलता है और हमेशा अपेक्षित तरीके से नहीं। इसलिए, बाध्यकारी संकेतक जितना संभव हो उतना कम होना चाहिए - यह संशोधनों के दौर से गुजरने वाले सिस्टम पर अधिक नियंत्रण प्रदान करेगा।
दोहराओ मत

आपका अपना कार्यान्वयन आज अच्छा हो सकता है, लेकिन कल इतना अच्छा नहीं होगा। अपने आप को अपनी खुद की सर्वोत्तम प्रथाओं की नकल करने की अनुमति न दें और इस तरह उन्हें एक कोड आधार में वितरित करें। आप StackOverflow से कॉपी कर सकते हैं, किताबों से - किसी भी आधिकारिक स्रोतों से (जैसा कि आप निश्चित रूप से जानते हैं) एक आदर्श (या उस के करीब) कार्यान्वयन की पेशकश करते हैं। अपने स्वयं के कार्यान्वयन में सुधार, जो एक से अधिक बार होता है, लेकिन पूरे कोड बेस में गुणा किया जाता है, बहुत थका सकता है।
सादगी और संक्षिप्तता

मेरी राय में, यह मुख्य सिद्धांत है जिसे इंजीनियरिंग और सॉफ्टवेयर विकास में देखा जाना चाहिए। "समयपूर्व अतिक्रमण बुराई की जड़ है," एडम बिएन ने कहा। दूसरे शब्दों में, बुराई की जड़ "री-इंजीनियरिंग" में है। बोली के लेखक, एडम बिएन, एक समय में विरासत अनुप्रयोगों को लेने में लगे हुए थे, और अपने कोड को पूरी तरह से फिर से लिखने के लिए, मूल आधार की तुलना में 2-3 बार एक कोड आधार प्राप्त किया। इतना अतिरिक्त कोड कहां से आता है? आखिरकार, यह एक कारण के लिए उठता है। उसकी आशंकाएं हमें जन्म देती हैं। यह हमें लगता है कि बड़ी संख्या में पैटर्न को जमा करके, अप्रत्यक्षता और अमूर्तता पैदा करके, हम अपने कोड को संरक्षण प्रदान करते हैं - कल के अज्ञात से सुरक्षा और कल की आवश्यकताएं। आखिरकार, वास्तव में, आज हमें इसकी कोई आवश्यकता नहीं है, हम यह सब केवल कुछ "भविष्य की जरूरतों" के लिए करते हैं। और यह संभव है कि ये डेटा संरचनाएं बाद में हस्तक्षेप करेंगी। सच कहूं तो, जब मेरे कुछ डेवलपर्स मेरे पास आए और कहा कि वह कुछ दिलचस्प लेकर आए हैं, जिसे प्रोडक्शन कोड में जोड़ा जा सकता है, तो मैं हमेशा एक ही तरह से जवाब देता हूं: "बॉय, यह आपके लिए उपयोगी नहीं होगा।"
बहुत सारे कोड नहीं होने चाहिए, और जो सरल होना चाहिए - उसके साथ सामान्य रूप से काम करने का एकमात्र तरीका। यह आपके डेवलपर्स के लिए एक चिंता का विषय है। आपको याद रखना चाहिए कि वे आपके सिस्टम के लिए महत्वपूर्ण आंकड़े हैं। उनकी ऊर्जा खपत को कम करने की कोशिश करें, जिससे उन जोखिमों को कम किया जा सके जिनके लिए उन्हें काम करना होगा। इसका मतलब यह नहीं है कि आपको अपना खुद का ढांचा बनाना होगा, इसके अलावा, मैं आपको ऐसा करने की सलाह नहीं दूंगा: आपके ढांचे में हमेशा कीड़े होंगे, सभी को इसका अध्ययन करने की आवश्यकता होगी, आदि। मौजूदा परिसंपत्तियों का उपयोग करना बेहतर है, जिनमें से आज एक द्रव्यमान है। ये सरल उपाय होने चाहिए। वैश्विक त्रुटि संचालकों को लिखें, पहलू तकनीक, कोड जनरेटर, स्प्रिंग या सीडीआई एक्सटेंशन लागू करें, अनुरोध / थ्रेड स्कोप्स कॉन्फ़िगर करें, फ्लाई पर बायटेकोड हेरफेर और पीढ़ी का उपयोग करें, आदि। यह सब वास्तव में सबसे महत्वपूर्ण चीज के लिए आपका योगदान होगा - आपके डेवलपर का आराम।
विशेष रूप से, मैं आपसे अनुरोध / थ्रेड क्षेत्रों के आवेदन को प्रदर्शित करना चाहूंगा। मैंने बार-बार देखा है कि यह बात अविश्वसनीय रूप से उद्यम अनुप्रयोगों को कैसे सरल बनाती है। लब्बोलुआब यह है कि यह आपको RequestContext डेटा को बचाने के लिए, लॉग इन उपयोगकर्ता के रूप में अवसर देता है। इस प्रकार, RequestContext उपयोगकर्ता डेटा को एक कॉम्पैक्ट रूप में संग्रहीत करेगा।

जैसा कि आप देख सकते हैं, कार्यान्वयन कोड की केवल कुछ पंक्तियाँ लेता है। आवश्यक एनोटेशन में अनुरोध लिखने के बाद (यदि आप स्प्रिंग या सीडीआई का उपयोग करते हैं तो यह करना मुश्किल नहीं है), आप उपयोगकर्ता को विधियों में लॉगिन करने की आवश्यकता से मुक्त कर देंगे और जो भी: संदर्भ के अंदर संग्रहित मेटाडाटा पारदर्शिता को लागू करेगा। स्कोप्ड प्रॉक्सी आपको किसी भी समय वर्तमान अनुरोध के मेटाडेटा तक पहुंचने की अनुमति देगा।
प्रतिगमन परीक्षण

डेवलपर्स अद्यतन आवश्यकताओं से डरते हैं क्योंकि वे रीफैक्टरिंग प्रक्रियाओं (कोड संशोधनों) से डरते हैं। और उनकी मदद करने का सबसे आसान तरीका प्रतिगमन परीक्षण के लिए एक विश्वसनीय परीक्षण सूट बनाना है। इसके साथ, डेवलपर के पास किसी भी समय अपने ऑपरेटिंग समय का परीक्षण करने का अवसर होगा - यह सुनिश्चित करने के लिए कि यह सिस्टम को नहीं तोड़ता है।
डेवलपर को कुछ भी तोड़ने से डरना नहीं चाहिए। आपको सब कुछ करना चाहिए ताकि रिफैक्टिंग को कुछ अच्छा माना जाए।
Refactoring विकास का एक महत्वपूर्ण पहलू है। याद रखें, ठीक उसी समय जब आपके डेवलपर्स रिफैक्टिंग से डरते हैं, तो एप्लिकेशन को लिगेसी माना जा सकता है।
व्यावसायिक तर्क कहां लागू करें?
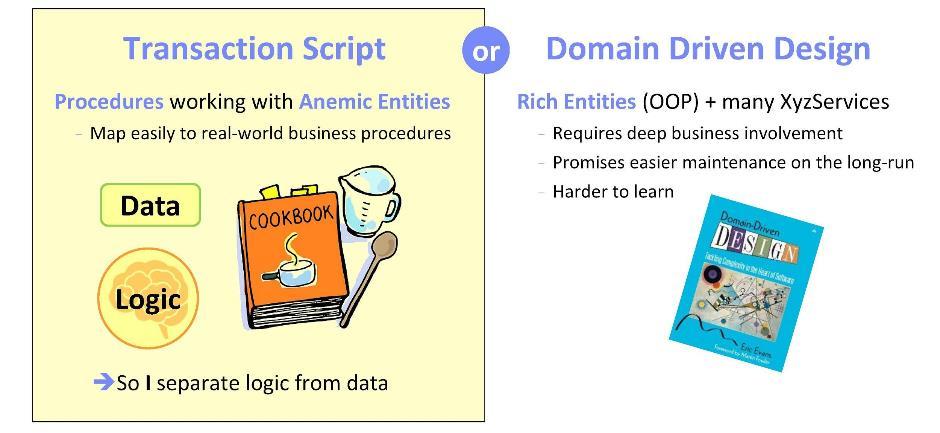
किसी भी सिस्टम (या सिस्टम घटकों) के कार्यान्वयन को शुरू करने से, हम खुद से सवाल पूछते हैं: डोमेन लॉजिक को लागू करना बेहतर है, अर्थात् हमारे आवेदन के कार्यात्मक पहलू? दो विरोधी दृष्टिकोण हैं।
पहला
लेन-देन स्क्रिप्ट दर्शन पर आधारित है। यहां, तर्क उन प्रक्रियाओं में लागू किया जाता है जो
एनीमिक संस्थाओं (यानी डेटा संरचनाओं के साथ) के साथ काम करते हैं। ऐसा दृष्टिकोण अच्छा है क्योंकि इसके कार्यान्वयन के दौरान तैयार किए गए व्यावसायिक कार्यों पर भरोसा करना संभव है। बैंकिंग क्षेत्र के लिए अनुप्रयोगों पर काम करते हुए, मैंने बार-बार सॉफ्टवेयर के लिए व्यावसायिक प्रक्रियाओं के हस्तांतरण का अवलोकन किया है। मैं कह सकता हूं कि सॉफ्टवेयर के साथ परिदृश्यों को सहसंबंधित करना वास्तव में बहुत स्वाभाविक है।
एक वैकल्पिक दृष्टिकोण
डोमेन-चालित डिजाइन के सिद्धांतों का उपयोग करना है। यहां आपको ऑब्जेक्ट-ओरिएंटेड कार्यप्रणाली के साथ विशिष्टताओं और आवश्यकताओं को सहसंबंधित करने की आवश्यकता होगी। वस्तुओं पर सावधानीपूर्वक विचार करना और अच्छी व्यावसायिक भागीदारी सुनिश्चित करना महत्वपूर्ण है। इस तरह से डिज़ाइन किए गए सिस्टम का प्लस यह है कि भविष्य में उन्हें आसानी से बनाए रखा जाता है। हालांकि, मेरे अनुभव में, इस पद्धति में महारत हासिल करना काफी कठिन है: आप इसे अध्ययन करने के छह महीने बाद पहले की तुलना में कम या ज्यादा बहादुर महसूस करेंगे।
अपने घटनाक्रम के लिए, मैंने हमेशा पहला तरीका चुना। मैं आपको आश्वस्त कर सकता हूं कि मेरे मामले में इसने पूरी तरह से काम किया।
डेटा मॉडलिंग
तथ्य
हम डेटा को कैसे मॉडल करते हैं? जैसे ही आवेदन अधिक या कम सभ्य आकार लेता है,
लगातार डेटा आवश्यक रूप से दिखाई देगा। यह उस तरह का डेटा है जिसे आपको बाकी की तुलना में लंबे समय तक संग्रहीत करने की आवश्यकता है - यह आपके सिस्टम की
डोमेन इकाइयाँ हैं । उन्हें कहां संग्रहीत करना है - चाहे डेटाबेस में, किसी फ़ाइल में या सीधे मेमोरी को प्रबंधित करने से - कोई फर्क नहीं पड़ता। महत्वपूर्ण बात यह है
कि आप उन्हें
कैसे स्टोर करेंगे - जिसमें डेटा संरचनाएं।

यह विकल्प आपको एक डेवलपर के रूप में दिया गया है, और यह केवल आप पर निर्भर करता है कि ये डेटा संरचनाएं भविष्य में कार्यात्मक आवश्यकताओं को लागू करते समय आपके लिए या आपके खिलाफ काम करेंगी। सब कुछ अच्छा होने के लिए, आपको
पुन: उपयोग किए गए डोमेन लॉजिक के दाने डालकर संस्थाओं को लागू करना होगा। कैसे विशेष रूप से? मैं एक उदाहरण का उपयोग करके कई तरीकों का प्रदर्शन करूंगा।

आइए देखें कि मैंने ग्राहक इकाई को क्या प्रदान किया है। सबसे पहले, मैंने एक
सिंथेटिक getFullName() लागू किया जो मुझे
getFullName() और lastName का
getFullName() । मैंने अपनी इकाई की स्थिति की निगरानी करने के लिए
activate() पद्धति को भी लागू किया, इस प्रकार इसे संक्षिप्त किया। इस पद्धति में, मैंने पहले, एक
सत्यापन ऑपरेशन रखा, और दूसरी बात,
मानों को स्थिति और सक्रिय
क्षेत्रों में असाइन करना , इसलिए उनके लिए व्यवस्थित करने की आवश्यकता नहीं है। मैंने ग्राहक इकाई को
isActive() और
canPlaceOrders() विधियों में भी जोड़ा है, जो अपने अंदर
canPlaceOrders() सत्यापन को लागू करते हैं। इसे प्रेडिकेटेट एनकैप्सुलेशन कहा जाता है। यदि आप जावा 8 फ़िल्टर का उपयोग करते हैं तो इस तरह की भविष्यवाणी काम में आती है: आप उन्हें फ़िल्टर करने के लिए तर्क के रूप में पास कर सकते हैं। मैं आपको इन सहायकों का उपयोग करने की सलाह देता हूं।
शायद आप किसी तरह के ओआरएम का उपयोग कर रहे हैं जैसे कि हाइबरनेट। मान लीजिए कि आपके पास दो-तरफ़ा संचार वाली दो संस्थाएँ हैं। प्रारंभ में दोनों तरफ से प्रदर्शन किया जाना चाहिए, अन्यथा, जैसा कि आप समझते हैं, भविष्य में इस डेटा तक पहुंचने पर आपको समस्याएं होंगी। लेकिन डेवलपर्स अक्सर किसी एक पार्टी से किसी ऑब्जेक्ट को इनिशियलाइज़ करना भूल जाते हैं। इन संस्थाओं को विकसित करते समय, आप विशेष तरीके प्रदान कर सकते हैं जो दो-तरफा आरंभीकरण की गारंटी देंगे।
addAddress() पर एक नज़र डालें।

जैसा कि आप देख सकते हैं, यह एक बहुत ही साधारण इकाई है। लेकिन इसके अंदर डोमेन लॉजिक निहित है। इस तरह की संस्थाओं को अल्प और सतही नहीं होना चाहिए, लेकिन तर्क से अभिभूत नहीं होना चाहिए। तर्क के साथ अतिप्रवाह अक्सर होता है: यदि आप डोमेन में सभी तर्क को लागू करने का निर्णय लेते हैं, तो प्रत्येक उपयोग-मामले के लिए यह कुछ विशिष्ट विधि को लागू करने के लिए आकर्षक होगा। एक नियम के रूप में, कई उपयोग-मामले हैं। आपको एक इकाई प्राप्त नहीं होगी, लेकिन सभी प्रकार के तर्क का एक बड़ा ढेर। यहां माप देखने की कोशिश करें: केवल
पुन :
उपयोग किए गए तर्क को डोमेन में रखा गया है और केवल
थोड़ी मात्रा में।
मूल्य वस्तुओं
संस्थाओं के अलावा, आप सबसे अधिक संभावना भी वस्तु मूल्यों की आवश्यकता होगी। यह कुछ और नहीं बल्कि डोमेन डेटा को ग्रुप करने का एक तरीका है ताकि आप बाद में इसे सिस्टम के चारों ओर एक साथ ले जा सकें।
मान ऑब्जेक्ट होना चाहिए:
- छोटा सा । मौद्रिक चर के लिए कोई
float ! डेटा प्रकारों का चयन करते समय सावधान रहें। आपकी वस्तु जितनी अधिक कॉम्पैक्ट होगी, नए डेवलपर के लिए यह पता लगाना उतना ही आसान होगा। यह आरामदायक जीवन का आधार है।
- अपरिवर्तनीय । यदि वस्तु वास्तव में अपरिवर्तनीय है, तो डेवलपर शांत हो सकता है कि आपकी वस्तु अपना मूल्य नहीं बदलेगी और निर्माण के बाद नहीं टूटेगी। यह शांत, आत्मविश्वास से भरे काम की नींव रखता है।

और यदि आप कंस्ट्रक्टर को एक
validate() विधि कॉल जोड़ते हैं, तो डेवलपर बनाई गई इकाई की वैधता के लिए शांत हो जाएगा (जब पास, कहते हैं, एक नगदी मुद्रा या नकारात्मक राशि, तो निर्माणकर्ता काम नहीं करेगा)।
एक इकाई और एक मूल्य वस्तु के बीच का अंतर
मूल्य ऑब्जेक्ट संस्थाओं से भिन्न होते हैं कि उनके पास एक निश्चित आईडी नहीं है। संस्थाओं में हमेशा किसी न किसी तालिका (या अन्य संग्रहण) की विदेशी कुंजी से जुड़े फ़ील्ड होंगे। मान ऑब्जेक्ट में ऐसे फ़ील्ड नहीं हैं। सवाल उठता है: क्या दो मूल्य वस्तुओं और दो संस्थाओं की समानता की जांच करने की प्रक्रियाएं अलग-अलग हैं? चूंकि मूल्य वस्तुओं में एक आईडी फ़ील्ड नहीं है, इसलिए यह निष्कर्ष निकालने के लिए कि ऐसी दो वस्तुएं समान हैं, आपको उनके सभी क्षेत्रों के मूल्यों की तुलना जोड़े में करनी होगी (यानी, सभी सामग्रियों की जांच करें)। संस्थाओं की तुलना करते समय, यह एक एकल तुलना करने के लिए पर्याप्त है - फ़ील्ड आईडी द्वारा। यह तुलना प्रक्रिया में है कि संस्थाओं और मूल्य वस्तुओं के बीच मुख्य अंतर निहित है।
डेटा ट्रांसफर ऑब्जेक्ट्स (DTO)

उपयोगकर्ता इंटरफ़ेस (UI) के साथ सहभागिता क्या है? आपको
उसे प्रदर्शित करने के लिए डेटा पास करना होगा। क्या आपको वास्तव में एक और संरचना की आवश्यकता होगी? तो यह है। और सभी क्योंकि उपयोगकर्ता इंटरफ़ेस आपके सभी मित्र पर नहीं है। उसके पास अपने स्वयं के अनुरोध हैं: उसे डेटा संग्रहीत करने की आवश्यकता है कि उन्हें कैसे प्रदर्शित किया जाना चाहिए। यह इतना अद्भुत है - कि यह कभी-कभी उपयोगकर्ता इंटरफेस और उनके डेवलपर्स हैं जिनकी हमें आवश्यकता होती है। फिर उन्हें पांच पंक्तियों के लिए डेटा प्राप्त करने की आवश्यकता है; तब यह उनके दिमाग में आता है कि ऑब्जेक्ट के लिए एक
isDeletable बूलियन फ़ील्ड बनाएं (ऑब्जेक्ट में सिद्धांत में ऐसा फ़ील्ड हो सकता है?) यह जानने के लिए कि डिलीट बटन सक्रिय है या नहीं। लेकिन कोई बात नहीं है। उपयोगकर्ता इंटरफ़ेस में बस अलग-अलग आवश्यकताएं हैं।
सवाल यह है कि क्या हमारी संस्थाओं को उन्हें इस्तेमाल के लिए सौंपा जा सकता है? सबसे अधिक संभावना है, वे उन्हें बदल देंगे, और हमारे लिए सबसे अवांछनीय तरीके से। इसलिए, हम उन्हें कुछ और प्रदान करेंगे -
डेटा ट्रांसफर ऑब्जेक्ट्स (डीटीओ)। वे विशेष रूप से बाहरी आवश्यकताओं और हमारे से अलग एक तर्क के अनुकूल होंगे। DTO संरचनाओं के कुछ उदाहरण हैं: फ़ॉर्म / अनुरोध (UI से आने वाला), व्यू / रिस्पॉन्स (UI में भेजा गया), SearchCriteria / SearchResult, आदि। आप एक अर्थ में, इसे एपीआई मॉडल कह सकते हैं।
पहला महत्वपूर्ण सिद्धांत: डीटीओ में कम से कम तर्क होना चाहिए।
यहाँ
CustomerDto का एक उदाहरण कार्यान्वयन है।
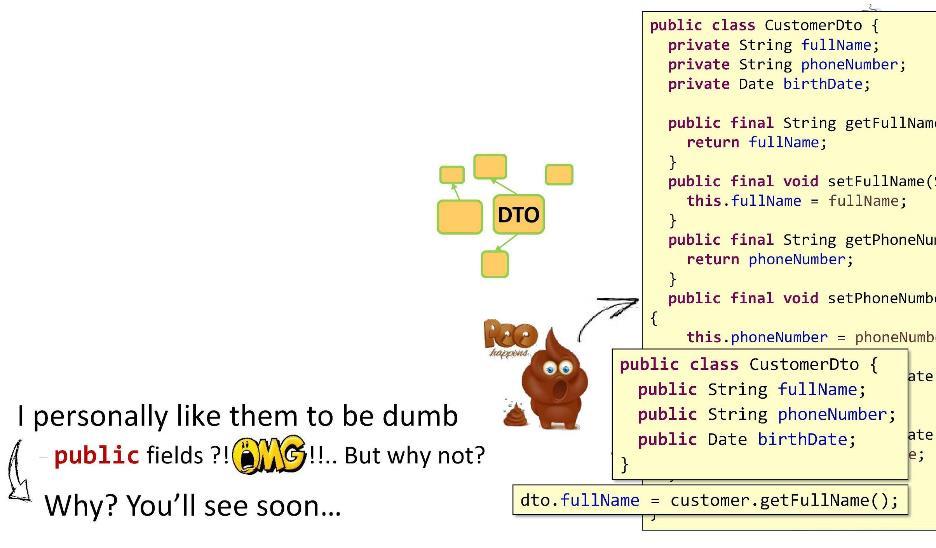
सामग्री:
निजी क्षेत्र,
सार्वजनिक गेटर्स और उनके लिए बसने वाले। सब कुछ सुपर लगता है। इसकी सारी महिमा में ओ.ओ.पी. लेकिन एक बात बुरी है: गेटर्स और सेटर के रूप में मैंने कई तरीके लागू किए हैं। डीटीओ में, जितना संभव हो उतना कम तर्क होना चाहिए। और फिर मेरा रास्ता क्या है? मैं खेतों को सार्वजनिक करता हूं! आप कहेंगे कि यह जावा 8 से विधि संदर्भों के साथ खराब काम करता है, कि सीमाएं होंगी, आदि। लेकिन यह विश्वास है या नहीं, मैंने अपने सभी प्रोजेक्ट्स (10-11 टुकड़े) ऐसे डीटीओ के साथ किए। भाई जिंदा है। अब, क्योंकि मेरे क्षेत्र सार्वजनिक हैं, मैं आसानी से
dto.fullName का मान आसानी से एक समान चिह्न लगाकर सेट कर सकता हूं। इससे अधिक सुंदर और सरल क्या हो सकता है?
तर्क संगठन
मानचित्रण
इसलिए, हमारे पास एक कार्य है: हमें अपनी संस्थाओं को डीटीओ में बदलने की आवश्यकता है। हम इस प्रकार परिवर्तन लागू करते हैं:
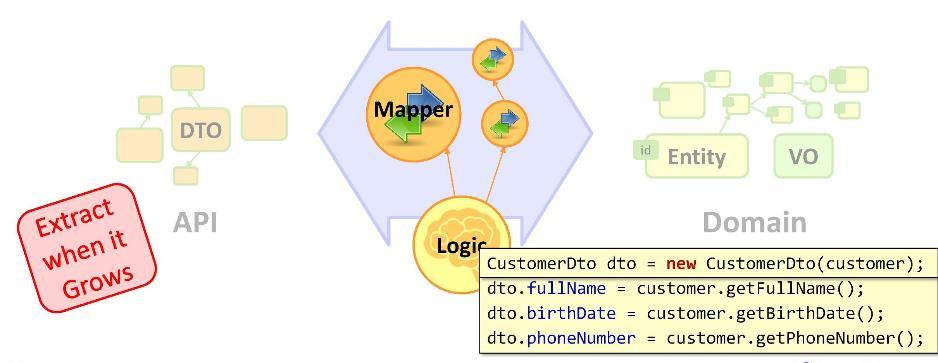
जैसा कि आप देख सकते हैं, डीटीओ घोषित करके, हम मैपिंग (मान असाइनमेंट) संचालन पर जाते हैं। क्या मुझे इतनी संख्या में नियमित असाइनमेंट लिखने के लिए एक वरिष्ठ डेवलपर होने की आवश्यकता है? कुछ के लिए, यह इतना असामान्य है कि वे चलते-चलते अपने जूते बदलना शुरू कर देते हैं: उदाहरण के लिए, प्रतिबिंब का उपयोग करके किसी प्रकार के मानचित्रण ढांचे का उपयोग करके डेटा की प्रतिलिपि बनाएँ। लेकिन वे मुख्य चीज को याद करते हैं - जो कि जल्द या बाद में, यूआई डीटीओ के साथ बातचीत करेगा, जिसके परिणामस्वरूप इकाई और डीटीओ अपने अर्थों में विचलन करते हैं।
कोई भी कह सकता है कि कंस्ट्रक्टर में मैपिंग ऑपरेशंस डालें। लेकिन यह किसी भी मानचित्रण के लिए संभव नहीं है; विशेष रूप से, डिजाइनर डेटाबेस तक नहीं पहुंच सकता है।
इस प्रकार, हम व्यापार तर्क में मानचित्रण संचालन को छोड़ने के लिए मजबूर हैं। और अगर उनके पास एक कॉम्पैक्ट उपस्थिति है, तो चिंता की कोई बात नहीं है। यदि मैपिंग कुछ पंक्तियों को नहीं लेती है, लेकिन अधिक है, तो इसे तथाकथित
मैपर में रखना बेहतर है। एक मैपर एक वर्ग है जिसे विशेष रूप से डेटा की प्रतिलिपि बनाने के लिए डिज़ाइन किया गया है। यह, सामान्य रूप से, एंटीडिल्वियन चीज और बॉयलरप्लेट है। लेकिन फिर उनके पीछे आप हमारे कई असाइनमेंट छिपा सकते हैं - कोड क्लीनर और स्लिमर बनाने के लिए।
याद रखें: एक
कोड जो बहुत बड़ा हो गया है उसे एक अलग संरचना में स्थानांतरित किया जाना चाहिए । हमारे मामले में, मैपिंग ऑपरेशन वास्तव में बहुत अधिक थे, इसलिए हमने उन्हें एक अलग वर्ग - मैपर में स्थानांतरित कर दिया।
क्या मैपर्स को डेटाबेस तक पहुंच की अनुमति देनी चाहिए? आप इसे डिफ़ॉल्ट रूप से सक्षम कर सकते हैं - यह अक्सर सादगी और व्यावहारिकता के कारणों के लिए किया जाता है। लेकिन यह आपको कुछ जोखिमों के लिए उजागर करता है।
मैं एक उदाहरण से स्पष्ट करूँगा। मौजूदा डीटीओ के आधार पर, हम
Customer इकाई बनाते हैं।
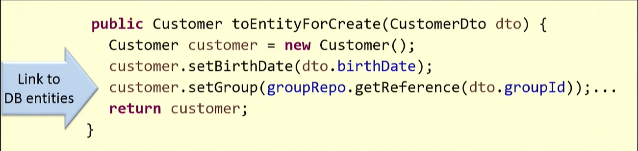
मैपिंग के लिए, हमें डेटाबेस से ग्राहक के समूह का लिंक प्राप्त करना होगा। तो मैं
getReference() विधि
getReference() हूं, और यह मुझे कुछ इकाई देता है। अनुरोध सबसे अधिक संभावना डेटाबेस में जाएगा (कुछ मामलों में ऐसा नहीं होता है, और स्टब फ़ंक्शन काम करता है)।
लेकिन मुसीबत हमें यहां नहीं, बल्कि उस विधि का इंतजार करती है जो उलटा ऑपरेशन करती है - इकाई को डीटीओ में बदलना।

एक लूप का उपयोग करके, हम मौजूदा ग्राहक से जुड़े सभी पतों के माध्यम से जाते हैं और उन्हें डीटीओ पतों में अनुवाद करते हैं। यदि आप ORM का उपयोग करते हैं, तो, शायद, जब आप
getAddresses() विधि कहते हैं, तो आलसी लोडिंग का प्रदर्शन किया जाएगा। यदि आप ORM का उपयोग नहीं करते हैं, तो यह इस माता-पिता के सभी बच्चों के लिए एक खुला अनुरोध होगा। और यहाँ आप "एन + 1 समस्या" में डूबने का जोखिम चलाते हैं। क्यों?
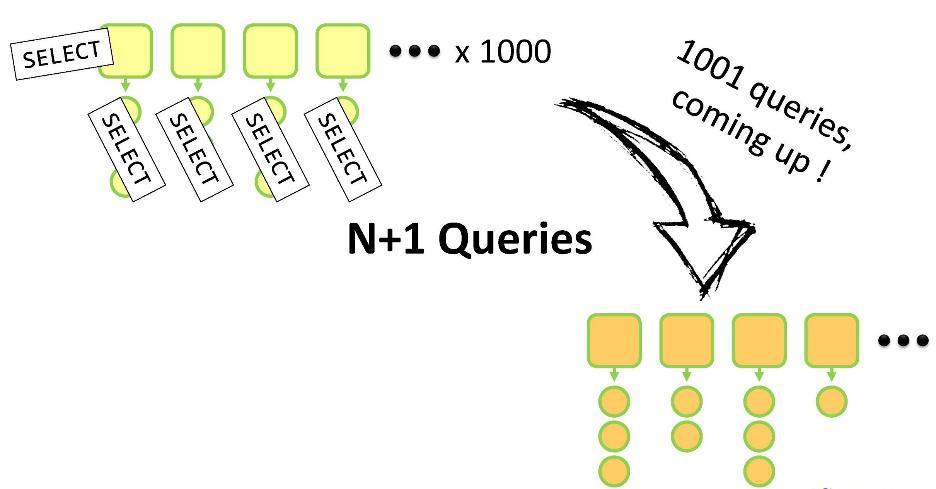
आपके पास माता-पिता का एक सेट है, जिनमें से प्रत्येक के बच्चे हैं। इस सब के लिए, आपको डीटीओ के अंदर अपना खुद का एनालॉग बनाने की जरूरत है। आपको एन पेरेंट संस्थाओं को फँसाने के लिए एक
SELECT क्वेरी का प्रदर्शन करने की आवश्यकता होगी और फिर उनमें से प्रत्येक के बच्चों के आसपास जाने के लिए एन
SELECT क्वेरीज़ की आवश्यकता होगी। कुल एन + 1 अनुरोध। 1000 मूल
Customer संस्थाओं के लिए, इस तरह के ऑपरेशन में 5-10 सेकंड लगेंगे, जो निश्चित रूप से, एक लंबा समय लेता है।
मान लीजिए कि, फिर भी, हमारे
CustomerDto() पद्धति को लूप के अंदर कहा जाता है, ग्राहक की सूची को CustomerDto सूची में परिवर्तित करता है।
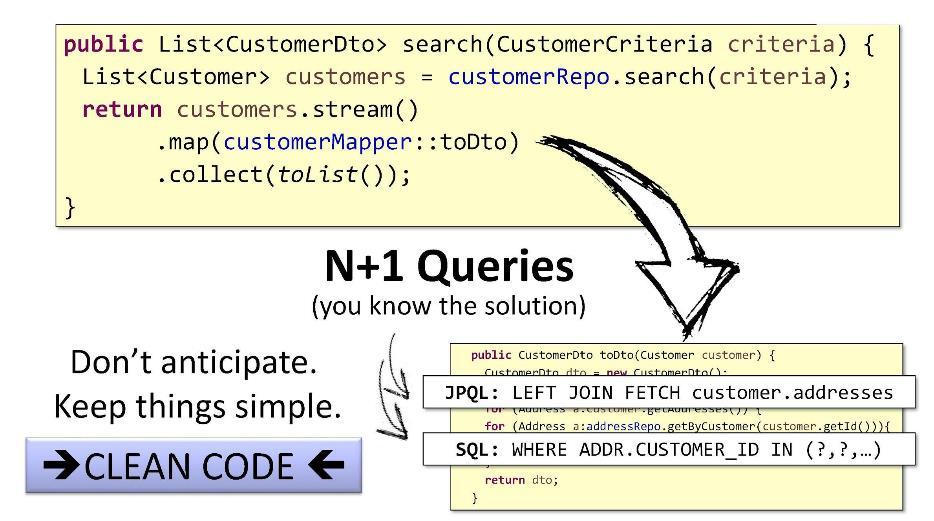
N + 1 प्रश्नों के साथ समस्या के सरल मानक समाधान हैं:
JPQL में आप
FETCH उपयोग करके ग्राहकों को पुनः प्राप्त कर सकते हैं और फिर उन्हें
JOIN का उपयोग करके कनेक्ट कर सकते हैं, और SQL में आप
IN बायपास और
WHERE उपयोग कर सकते हैं।
लेकिन मैं इसे अलग तरीके से करूंगा। आप यह जान सकते हैं कि बच्चों की सूची की अधिकतम लंबाई क्या है (यह किया जा सकता है, उदाहरण के लिए, पृष्ठ पर अंक लगाना के आधार पर)। यदि सूची में केवल 15 इकाइयां हैं, तो हमें केवल 16 प्रश्न चाहिए। 5ms के बजाय हम सब कुछ पर खर्च करेंगे, कहते हैं, 15ms - उपयोगकर्ता अंतर को नोटिस नहीं करेगा।
अनुकूलन के बारे में
मैं आपको विकास के प्रारंभिक चरण में सिस्टम प्रदर्शन पर वापस देखने की सलाह नहीं दूंगा। जैसा कि डोनाल्ड नूड ने कहा था: "समय से पहले का अनुकूलन बुराई की जड़ है।" आप प्रारंभ से अनुकूलन नहीं कर सकते। यह वही है जो बाद के लिए छोड़ दिया जाना चाहिए। और क्या विशेष रूप से महत्वपूर्ण है:
कोई धारणा नहीं - केवल माप और माप का मूल्यांकन!क्या आप सुनिश्चित हैं कि आप सक्षम हैं कि आप एक वास्तविक विशेषज्ञ हैं? खुद का मूल्यांकन करने में विनम्र रहें। यह न सोचें कि आप JVM को तब तक समझते हैं जब तक आप JIT संकलन के बारे में कम से कम एक दो पुस्तकें नहीं पढ़ लेते। ऐसा होता है कि हमारी टीम के सर्वश्रेष्ठ प्रोग्रामर मेरे पास आते हैं और कहते हैं कि
उन्हें लगता है कि
उन्होंने अधिक कुशल कार्यान्वयन पाया है। यह पता चला है कि उन्होंने फिर से कुछ का आविष्कार किया जो केवल कोड को जटिल करता है। इसलिए मैं बार-बार जवाब देता हूं: YAGNI। हमें इसकी आवश्यकता नहीं है
अक्सर, एंटरप्राइज़ अनुप्रयोगों के लिए, एल्गोरिदम के किसी भी अनुकूलन की आवश्यकता नहीं होती है। उनके लिए अड़चन, एक नियम के रूप में, संकलन नहीं है और जहां तक प्रोसेसर का संबंध नहीं है, लेकिन सभी प्रकार के इनपुट-आउटपुट संचालन। उदाहरण के लिए, एक डेटाबेस से एक लाख पंक्तियों को पढ़ना, एक फ़ाइल के लिए स्वैच्छिक लिखते हैं, सॉकेट्स के साथ बातचीत।
समय के साथ, आपको यह समझना शुरू हो जाता है कि सिस्टम में क्या अड़चनें हैं, और, माप के साथ सब कुछ को मजबूत करना, आप धीरे-धीरे अनुकूलन करना शुरू कर देंगे। अभी के लिए, कोड को यथासंभव साफ रखें। आप पाएंगे कि इस तरह के कोड को और अधिक अनुकूलित करना आसान है।
वंशानुक्रम पर रचना को प्राथमिकता दें
वापस हमारे डीटीओ के पास। मान लीजिए कि हम एक DTO को इस तरह परिभाषित करते हैं:

हमें कई वर्कफ़्लोज़ में इसकी आवश्यकता हो सकती है। लेकिन ये प्रवाह अलग-अलग हैं और, सबसे अधिक संभावना है, प्रत्येक उपयोग-केस फ़ील्ड भरने की एक अलग डिग्री मान लेगा। उदाहरण के लिए, हमें स्पष्ट रूप से डीटीओ बनाने की आवश्यकता होगी जब हमारे पास पूर्ण उपयोगकर्ता जानकारी होगी। आप अस्थायी रूप से खेतों को खाली छोड़ सकते हैं। लेकिन आप जितने अधिक क्षेत्रों की उपेक्षा करेंगे, उतना ही आप इस उपयोग के मामले के लिए एक नया सख्त डीटीओ बनाना चाहेंगे।
वैकल्पिक रूप से, आप एक अत्यधिक बड़े डीटीओ (उपलब्ध उपयोग-मामलों की संख्या में) की प्रतियां बना सकते हैं और फिर प्रत्येक प्रतिलिपि के लिए इसमें से अतिरिक्त फ़ील्ड निकाल सकते हैं। लेकिन कई प्रोग्रामर्स के लिए, उनकी बुद्धिमत्ता और साक्षरता के आधार पर, यह वास्तव में Ctrl + V को दबाने के लिए दर्द होता है। स्वयंसिद्ध कहते हैं कि कॉपी-पेस्ट बुरा है।
आप ओओपी सिद्धांत में ज्ञात
विरासत सिद्धांत का सहारा ले सकते हैं: बस एक मूल डीटीओ को परिभाषित करें और प्रत्येक उपयोग के मामले के लिए वारिस बनाएं।
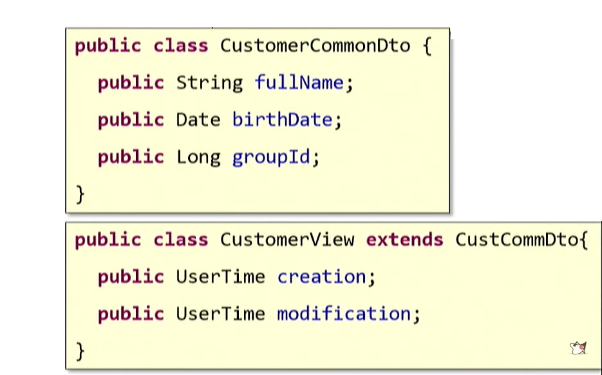
एक प्रसिद्ध सिद्धांत है: "विरासत पर रचना को प्राथमिकता दें।" पढ़िए क्या कहता है:
"विस्तार" ऐसा लगता है कि हमें स्रोत वर्ग का "विस्तार" करना चाहिए था। लेकिन अगर आप इसके बारे में सोचते हैं, तो हमने जो किया है वह "विस्तार" नहीं है। यह वास्तविक "दोहराव" है - एक ही कॉपी-पेस्ट, साइड व्यू। इसलिए, हम इनहेरिटेंस का उपयोग नहीं करेंगे।
लेकिन तब हमें क्या होना चाहिए? रचना में कैसे जाएं? इसे इस तरह करते हैं: CustomerView में एक फ़ील्ड लिखें जो अंतर्निहित DTO के ऑब्जेक्ट को इंगित करेगा।
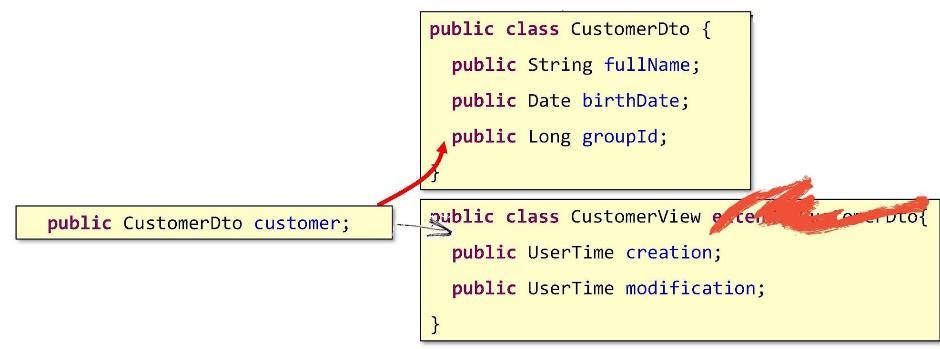
इस प्रकार, हमारे आधार संरचना के अंदर घोंसला हो जाएगा। इसी से असली रचना सामने आती है।
चाहे हम विरासत का उपयोग करें या रचना द्वारा समस्या को हल करें - ये सभी विवरण हैं, सूक्ष्मताएं जो हमारे कार्यान्वयन के दौरान गहराई से उत्पन्न हुई हैं। वे बहुत
नाजुक हैं । नाजुक का मतलब क्या है? इस कोड पर एक नज़र डालें:

जिन डेवलपर्स ने मुझे दिखाया, उनमें से अधिकांश ने तुरंत यह कह दिया कि "2" संख्या दोहराई गई है, इसलिए इसे निरंतर के रूप में बाहर निकालने की आवश्यकता है। उन्होंने ध्यान नहीं दिया कि तीनों मामलों में ड्यूस का पूरी तरह से अलग अर्थ है (या "व्यावसायिक मूल्य") और इसका दोहराव एक संयोग से ज्यादा कुछ नहीं है। एक दो को एक स्थिर में खींचना एक वैध निर्णय है, लेकिन बहुत नाजुक है। डोमेन में नाजुक तर्क की अनुमति न देने का प्रयास करें। बाहरी डेटा संरचनाओं के साथ, विशेष रूप से डीटीओ के साथ, इससे कभी भी काम न करें।
तो, विरासत को खत्म करने और बेकार होने के लिए रचना को पेश करने का काम क्यों है? ठीक है क्योंकि हम अपने लिए नहीं, बल्कि एक बाहरी ग्राहक के लिए डीटीओ बनाते हैं। और क्लाइंट एप्लिकेशन आपसे प्राप्त डीटीओ को कैसे पार्स करेगा - आप केवल अनुमान लगा सकते हैं। लेकिन जाहिर है, यह आपके कार्यान्वयन के साथ बहुत कम होगा। दूसरी ओर डेवलपर्स उन मूल और गैर-मूल डीटीओ के लिए कोई अंतर नहीं कर सकते हैं जिन्हें आपने ध्यान से सोचा है; वे शायद विरासत का उपयोग करते हैं, और शायद मूर्खतापूर्ण कॉपी-पेस्ट यह सब।
अग्रभाग

आइए आवेदन की समग्र तस्वीर पर वापस जाएं। मैं आपको सलाह दूंगा कि आप डोमेन लॉजिक के माध्यम से डोमेन लॉजिक को लागू करें, आवश्यकतानुसार
डोमेन सेवाओं के साथ facades का विस्तार करें। एक डोमेन सेवा तब बनाई जाती है जब बहुत अधिक लॉजिक सामने वाले हिस्से में जमा हो जाता है, और इसे एक अलग वर्ग में रखना अधिक सुविधाजनक होता है।
आपकी डोमेन सेवाओं के लिए आवश्यक रूप से आपके डोमेन मॉडल की भाषा (इसकी इकाइयाँ और मूल्य वस्तुएँ) होनी चाहिए। किसी भी मामले में उन्हें डीटीओ के साथ काम नहीं करना चाहिए, क्योंकि डीटीओ, जैसा कि आप याद करते हैं, ऐसी संरचनाएं हैं जो क्लाइंट साइड पर लगातार बदल रही हैं, एक डोमेन के लिए भी नाजुक हैं।
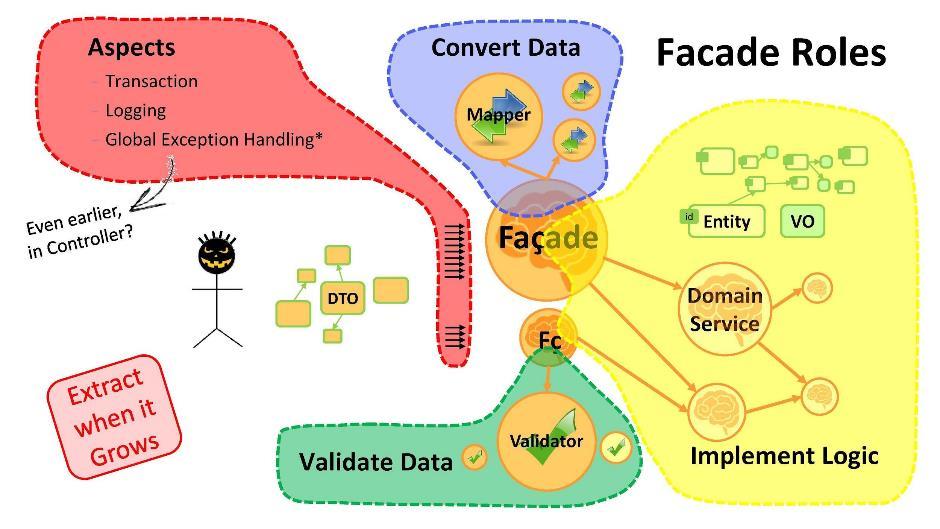
मुखौटा का उद्देश्य क्या है?
- डेटा रूपांतरण। अगर हमारे पास एक छोर से दूसरे स्थान पर डीटीओ हैं, तो एक से दूसरे में परिवर्तन करना आवश्यक है। और यह पहली बात है कि facades के लिए कर रहे हैं। यदि रूपांतरण प्रक्रिया वॉल्यूम में बढ़ी है - मैपर कक्षाओं का उपयोग करें।
- तर्क का कार्यान्वयन। मुखौटा में, आप आवेदन का मुख्य तर्क लिखना शुरू कर देंगे। जैसे ही यह बहुत हो जाता है - भागों को डोमेन सेवा में ले जाएं।
- डेटा सत्यापन। याद रखें कि उपयोगकर्ता से प्राप्त कोई भी डेटा, परिभाषा के अनुसार, गलत (त्रुटियों से युक्त) है। मुखौटा डेटा को मान्य करने की क्षमता रखता है। ये प्रक्रियाएँ, जब आयतन को पार कर लिया जाता है, आमतौर पर सत्यापनकर्ताओं के पास ले जाया जाता है।
- पहलुओं। आप आगे बढ़ सकते हैं और प्रत्येक उपयोग-केस को उसके मोहरे के माध्यम से जा सकते हैं। फिर लेन-देन, लॉगिंग, वैश्विक अपवाद हैंडलर जैसी चीजों को मुखौटा तरीकों से जोड़ना होगा। मैं ध्यान देता हूं कि किसी भी एप्लिकेशन में वैश्विक अपवाद हैंडलर होना बहुत महत्वपूर्ण है जो अन्य हैंडलर द्वारा पकड़े गए सभी त्रुटियों को पकड़ते हैं। वे आपके प्रोग्रामरों की बहुत मदद करेंगे - वे उन्हें मन की शांति और कार्रवाई की स्वतंत्रता देंगे।
बहुत सारे कोड का अपघटन
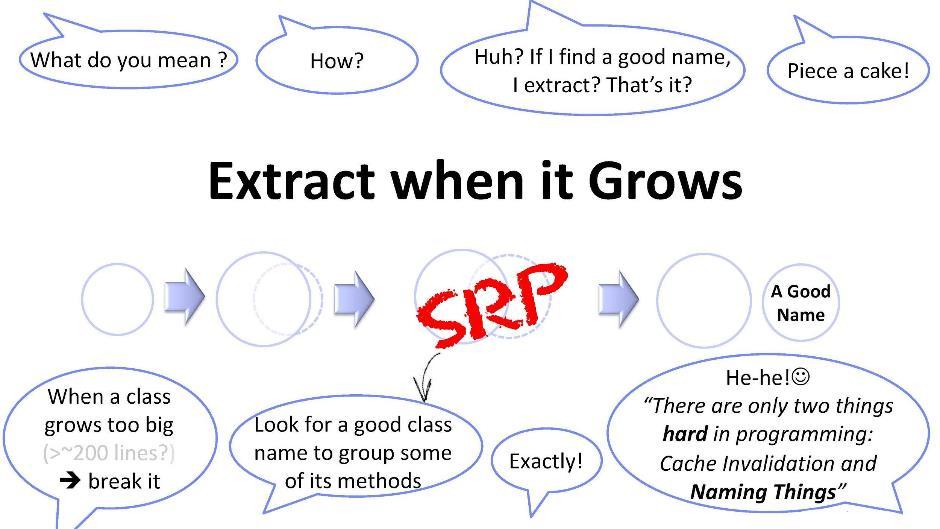
इस सिद्धांत के बारे में कुछ और शब्द। यदि कक्षा मेरे लिए कुछ आकार असुविधाजनक (जैसे, 200 लाइनें) तक पहुंच गई है, तो मुझे इसे टुकड़ों में तोड़ने की कोशिश करनी चाहिए। लेकिन एक मौजूदा से एक नए वर्ग को अलग करना हमेशा आसान नहीं होता है। हमें कुछ सार्वभौमिक तरीकों के साथ आने की जरूरत है। इन विधियों में से एक नाम की खोज करना है: आप अपनी कक्षा के तरीकों के सबसेट के लिए एक नाम खोजने की कोशिश कर रहे हैं। जैसे ही आप एक नाम खोजने के लिए प्रबंधन करते हैं, एक नया वर्ग बनाने के लिए स्वतंत्र महसूस करें। लेकिन यह इतना आसान नहीं है। प्रोग्रामिंग में, जैसा कि आप जानते हैं, केवल दो जटिल चीजें हैं: यह कैश को अमान्य कर रहा है और नामों का आविष्कार कर रहा है। इस मामले में, एक नाम का आविष्कार करना एक उप-पहचान की पहचान करना है - छिपाना और इसलिए पहले से किसी की पहचान नहीं करना।
एक उदाहरण:
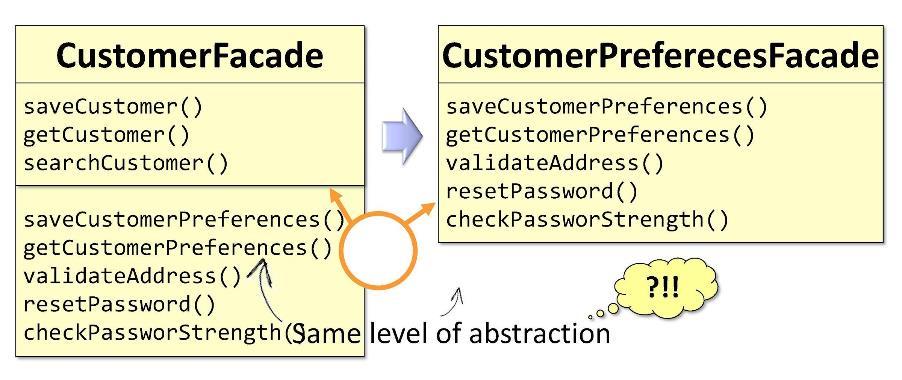
CustomerFacade के मूल पहलू में
CustomerFacade कुछ विधियाँ सीधे ग्राहक से संबंधित हैं, और कुछ ग्राहक वरीयताओं से संबंधित हैं। इसके आधार पर, मैं कक्षा को दो में विभाजित कर सकूंगा जब यह महत्वपूर्ण आकारों तक पहुँच जाएगा। मुझे दो पहलू मिलते हैं:
CustomerFacade और
CustomerPreferencesFacade । केवल बुरी बात यह है कि ये दोनों पहलू एक ही स्तर के अमूर्त हैं। अमूर्त के स्तरों से पृथक्करण का अर्थ कुछ अलग है।
एक और उदाहरण:

मान लीजिए कि हमारे सिस्टम में एक
OrderService वर्ग है जिसमें हमने एक ईमेल अधिसूचना तंत्र लागू किया है। अब हम एक
DeliveryService बना रहे हैं और उसी सूचना तंत्र का उपयोग करना चाहते हैं। कॉपी-पेस्ट को बाहर रखा गया है। आइए इसे इस तरह से करें: नए
AlertService क्लास में नोटिफिकेशन फंक्शनलिटी निकालें और इसे
DeliveryService और
OrderService लिए एक निर्भरता के रूप में लिखें। यहां, पिछले उदाहरण के विपरीत, पृथक्करण अमूर्त के स्तरों पर ठीक हुआ।
DeliveryServiceसे अधिक सार AlertService, क्योंकि यह इसे अपने वर्कफ़्लो के हिस्से के रूप में उपयोग करता है ।अमूर्तता के स्तरों से अलगाव हमेशा यह मानता है कि निकाले गए वर्ग पर निर्भरता बन जाती है , और पुन: उपयोग के लिए निष्कर्षण किया जाता है ।निष्कर्षण कार्य हमेशा आसान नहीं होता है। यह कुछ कठिनाइयों को भी पूरा कर सकता है और यूनिट परीक्षणों के कुछ पुन: निर्माण की आवश्यकता होती है। फिर भी, मेरी टिप्पणियों के अनुसार, डेवलपर्स के लिए एप्लिकेशन के विशाल अखंड कोड आधार में किसी भी कार्यक्षमता की खोज करना और भी मुश्किल है।जोड़ी प्रोग्रामिंग
 कई सलाहकार जोड़ी प्रोग्रामिंग के बारे में बात करेंगे, इस तथ्य के बारे में कि यह आज आईटी विकास की किसी भी समस्या का एक सार्वभौमिक समाधान है। इसके दौरान, प्रोग्रामर अपने तकनीकी कौशल और कार्यात्मक ज्ञान का विकास करते हैं। इसके अलावा, प्रक्रिया ही दिलचस्प है, यह टीम को एक साथ लाती है।सलाहकार के रूप में नहीं, बल्कि मानवीय रूप से बोलते हुए, सबसे महत्वपूर्ण बात यह है: जोड़ी प्रोग्रामिंग "बस कारक" में सुधार करती है। "बस कारक" का सार यह है कि सिस्टम की संरचना के बारे में अधिक से अधिक लोगों को जानकारी होनी चाहिए । इन लोगों को खोने का मतलब इस ज्ञान के आखिरी सुराग को खोना है।जोड़ी प्रोग्रामिंग रिफैक्टिंग एक कला है जिसमें अनुभव और प्रशिक्षण की आवश्यकता होती है। यह उपयोगी है, उदाहरण के लिए, आक्रामक रिफैक्टिंग का अभ्यास, हैकाथॉन का संचालन, कटौती, कोडिंग डोजोस, आदि।पेयर प्रोग्रामिंग उन मामलों में अच्छी तरह से काम करती है , जहां आपको उच्च जटिलता की समस्याओं को हल करने की आवश्यकता होती है। एक साथ काम करने की प्रक्रिया हमेशा सरल नहीं होती है। लेकिन यह आपको गारंटी देता है कि आप "पुनर्रचना" से बचेंगे - इसके विपरीत, आपको एक कार्यान्वयन मिलेगा जो निर्धारित आवश्यकताओं को न्यूनतम समानता के साथ संबोधित करता है।
कई सलाहकार जोड़ी प्रोग्रामिंग के बारे में बात करेंगे, इस तथ्य के बारे में कि यह आज आईटी विकास की किसी भी समस्या का एक सार्वभौमिक समाधान है। इसके दौरान, प्रोग्रामर अपने तकनीकी कौशल और कार्यात्मक ज्ञान का विकास करते हैं। इसके अलावा, प्रक्रिया ही दिलचस्प है, यह टीम को एक साथ लाती है।सलाहकार के रूप में नहीं, बल्कि मानवीय रूप से बोलते हुए, सबसे महत्वपूर्ण बात यह है: जोड़ी प्रोग्रामिंग "बस कारक" में सुधार करती है। "बस कारक" का सार यह है कि सिस्टम की संरचना के बारे में अधिक से अधिक लोगों को जानकारी होनी चाहिए । इन लोगों को खोने का मतलब इस ज्ञान के आखिरी सुराग को खोना है।जोड़ी प्रोग्रामिंग रिफैक्टिंग एक कला है जिसमें अनुभव और प्रशिक्षण की आवश्यकता होती है। यह उपयोगी है, उदाहरण के लिए, आक्रामक रिफैक्टिंग का अभ्यास, हैकाथॉन का संचालन, कटौती, कोडिंग डोजोस, आदि।पेयर प्रोग्रामिंग उन मामलों में अच्छी तरह से काम करती है , जहां आपको उच्च जटिलता की समस्याओं को हल करने की आवश्यकता होती है। एक साथ काम करने की प्रक्रिया हमेशा सरल नहीं होती है। लेकिन यह आपको गारंटी देता है कि आप "पुनर्रचना" से बचेंगे - इसके विपरीत, आपको एक कार्यान्वयन मिलेगा जो निर्धारित आवश्यकताओं को न्यूनतम समानता के साथ संबोधित करता है। एक सुविधाजनक कार्य प्रारूप का आयोजन टीम के लिए आपकी मुख्य जिम्मेदारियों में से एक है। आपको डेवलपर की कार्य स्थितियों का लगातार ध्यान रखना चाहिए - उन्हें पूरी तरह से आराम और रचनात्मकता की स्वतंत्रता प्रदान करें, खासकर यदि उन्हें डिजाइन वास्तुकला और इसकी जटिलता को बढ़ाने की आवश्यकता हो।
एक सुविधाजनक कार्य प्रारूप का आयोजन टीम के लिए आपकी मुख्य जिम्मेदारियों में से एक है। आपको डेवलपर की कार्य स्थितियों का लगातार ध्यान रखना चाहिए - उन्हें पूरी तरह से आराम और रचनात्मकता की स्वतंत्रता प्रदान करें, खासकर यदि उन्हें डिजाइन वास्तुकला और इसकी जटिलता को बढ़ाने की आवश्यकता हो।“मैं एक वास्तुकार हूँ। परिभाषा के अनुसार, मैं हमेशा सही हूं।
यह मूर्खता समय-समय पर सार्वजनिक रूप से या पर्दे के पीछे व्यक्त की जाती है। आज के अभ्यास में, आर्किटेक्ट जैसे कम और कम पाए जाते हैं। एजाइल के आगमन के साथ, यह भूमिका धीरे-धीरे वरिष्ठ डेवलपर्स के पास चली गई, क्योंकि आमतौर पर सभी कार्य, एक ही रास्ता या किसी अन्य, उनके चारों ओर बनाया जाता है। कार्यान्वयन का आकार धीरे-धीरे बढ़ रहा है, और इसके साथ रिफैक्टरिंग की आवश्यकता है और नई कार्यक्षमता विकसित की जा रही है।प्याज की वास्तुकला
प्याज शुद्धतम शुद्धिकरण लिपि दर्शन है। इसका निर्माण करते हुए, हमें उस कोड की सुरक्षा के लक्ष्य द्वारा निर्देशित किया जाता है जिसे हम महत्वपूर्ण मानते हैं, और इसके लिए हम इसे डोमेन मॉड्यूल में स्थानांतरित करते हैं। हमारे आवेदन में, सबसे महत्वपूर्ण डोमेन सेवाएं हैं: वे सबसे महत्वपूर्ण प्रवाह को लागू करते हैं। उन्हें डोमेन मॉड्यूल पर ले जाएं। बेशक, यह आपके सभी डोमेन ऑब्जेक्ट्स को यहां स्थानांतरित करने के लिए भी लायक है - इकाइयां और मूल्य ऑब्जेक्ट। बाकी सब कुछ जो हमने आज संकलित किया है - डीटीओ, मैपर्स, वैलिडेटर, आदि - बन जाता है, इसलिए बोलने के लिए, उपयोगकर्ता से रक्षा की पहली पंक्ति। क्योंकि उपयोगकर्ता, अफसोस, हमारा दोस्त नहीं है, और उसके लिए सिस्टम की रक्षा करना आवश्यक है।इस निर्भरता पर ध्यान दें:
हमारे आवेदन में, सबसे महत्वपूर्ण डोमेन सेवाएं हैं: वे सबसे महत्वपूर्ण प्रवाह को लागू करते हैं। उन्हें डोमेन मॉड्यूल पर ले जाएं। बेशक, यह आपके सभी डोमेन ऑब्जेक्ट्स को यहां स्थानांतरित करने के लिए भी लायक है - इकाइयां और मूल्य ऑब्जेक्ट। बाकी सब कुछ जो हमने आज संकलित किया है - डीटीओ, मैपर्स, वैलिडेटर, आदि - बन जाता है, इसलिए बोलने के लिए, उपयोगकर्ता से रक्षा की पहली पंक्ति। क्योंकि उपयोगकर्ता, अफसोस, हमारा दोस्त नहीं है, और उसके लिए सिस्टम की रक्षा करना आवश्यक है।इस निर्भरता पर ध्यान दें: एप्लिकेशन मॉड्यूल डोमेन मॉड्यूल पर निर्भर करेगा - अर्थात, अन्य तरीके से नहीं। इस तरह के कनेक्शन को पंजीकृत करने से, हम गारंटी देते हैं कि डीटीओ डोमेन मॉड्यूल के पवित्र क्षेत्र में कभी नहीं टूटेगा: वे बस डोमेन मॉड्यूल से दिखाई नहीं देते हैं और दुर्गम होते हैं। यह पता चला है कि एक अर्थ में हमने डोमेन क्षेत्र को निकाल दिया है - हमने अजनबियों तक इसकी पहुंच सीमित कर दी है।हालाँकि, डोमेन को कुछ बाहरी सेवा के साथ सहभागिता करने की आवश्यकता हो सकती है। बाहरी साधनों के साथ, क्योंकि वह अपने डीटीओ से लैस है। हमारे विकल्प क्या हैं?पहला: मॉड्यूल के अंदर दुश्मन को छोड़ दें।
एप्लिकेशन मॉड्यूल डोमेन मॉड्यूल पर निर्भर करेगा - अर्थात, अन्य तरीके से नहीं। इस तरह के कनेक्शन को पंजीकृत करने से, हम गारंटी देते हैं कि डीटीओ डोमेन मॉड्यूल के पवित्र क्षेत्र में कभी नहीं टूटेगा: वे बस डोमेन मॉड्यूल से दिखाई नहीं देते हैं और दुर्गम होते हैं। यह पता चला है कि एक अर्थ में हमने डोमेन क्षेत्र को निकाल दिया है - हमने अजनबियों तक इसकी पहुंच सीमित कर दी है।हालाँकि, डोमेन को कुछ बाहरी सेवा के साथ सहभागिता करने की आवश्यकता हो सकती है। बाहरी साधनों के साथ, क्योंकि वह अपने डीटीओ से लैस है। हमारे विकल्प क्या हैं?पहला: मॉड्यूल के अंदर दुश्मन को छोड़ दें।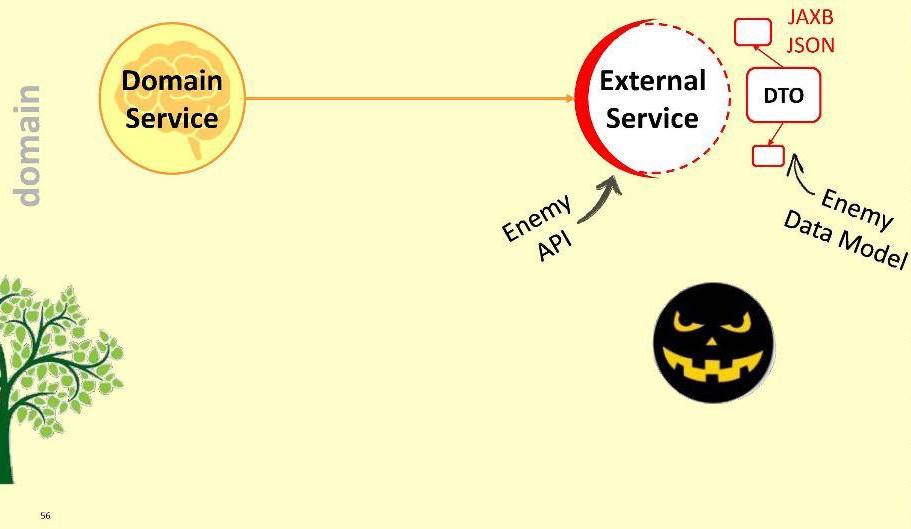 जाहिर है, यह एक बुरा विकल्प है: यह संभव है कि कल बाहरी सेवा संस्करण 2.0 में अपग्रेड न हो, और हमें अपने डोमेन को फिर से बनाना होगा। डोमेन के अंदर दुश्मन को न जाने दें!मैं एक अलग दृष्टिकोण प्रस्तावित करता हूं: हम इंटरैक्शन के लिए एक विशेष एडाप्टर बनाएंगे ।
जाहिर है, यह एक बुरा विकल्प है: यह संभव है कि कल बाहरी सेवा संस्करण 2.0 में अपग्रेड न हो, और हमें अपने डोमेन को फिर से बनाना होगा। डोमेन के अंदर दुश्मन को न जाने दें!मैं एक अलग दृष्टिकोण प्रस्तावित करता हूं: हम इंटरैक्शन के लिए एक विशेष एडाप्टर बनाएंगे ।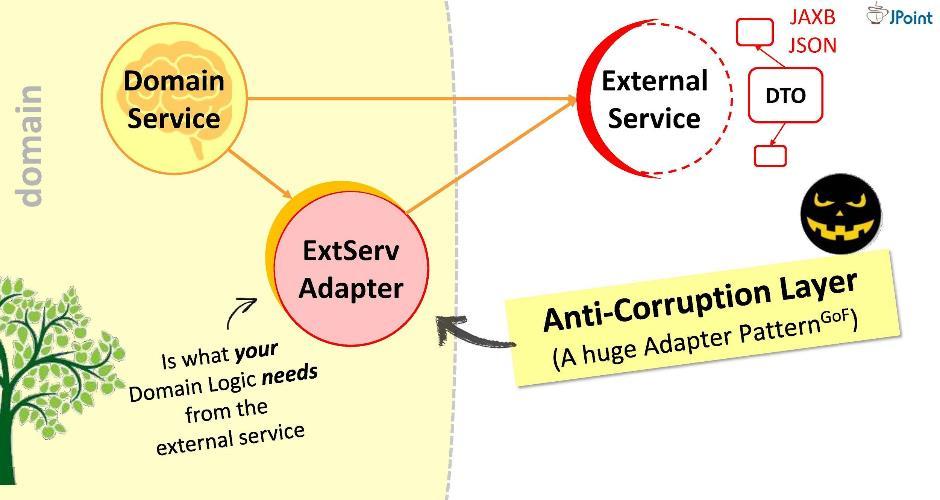 एडेप्टर एक बाहरी सेवा से डेटा प्राप्त करेगा, उस डेटा को निकालेगा जिसे हमारे डोमेन की आवश्यकता है, और इसे आवश्यक प्रकार की संरचनाओं में परिवर्तित करें। इस मामले में, विकास के दौरान हम सभी की आवश्यकता है कि डोमेन की आवश्यकताओं के साथ बाह्य सिस्टम पर कॉल को सहसंबंधित किया जाए। इसे इस तरह से एक विशाल एडाप्टर के रूप में सोचें । मैं इस परत को "भ्रष्टाचार विरोधी" कहता हूं।उदाहरण के लिए, हमें किसी डोमेन से LDAP प्रश्नों को निष्पादित करने की आवश्यकता हो सकती है। ऐसा करने के लिए, हम “एंटी-करप्शन मॉड्यूल” को लागू कर रहे हैं
एडेप्टर एक बाहरी सेवा से डेटा प्राप्त करेगा, उस डेटा को निकालेगा जिसे हमारे डोमेन की आवश्यकता है, और इसे आवश्यक प्रकार की संरचनाओं में परिवर्तित करें। इस मामले में, विकास के दौरान हम सभी की आवश्यकता है कि डोमेन की आवश्यकताओं के साथ बाह्य सिस्टम पर कॉल को सहसंबंधित किया जाए। इसे इस तरह से एक विशाल एडाप्टर के रूप में सोचें । मैं इस परत को "भ्रष्टाचार विरोधी" कहता हूं।उदाहरण के लिए, हमें किसी डोमेन से LDAP प्रश्नों को निष्पादित करने की आवश्यकता हो सकती है। ऐसा करने के लिए, हम “एंटी-करप्शन मॉड्यूल” को लागू कर रहे हैं LDAPUserServiceAdapter। एडॉप्टर में हम कर सकते हैं:
एडॉप्टर में हम कर सकते हैं:- बदसूरत एपीआई कॉल छिपाएं (हमारे मामले में, ऑब्जेक्ट सरणी लेने वाली विधि छिपाएं);
- हमारे स्वयं के कार्यान्वयन में पैक अपवाद;
- अन्य लोगों की डेटा संरचनाओं को अपने में (हमारे डोमेन ऑब्जेक्ट में) रूपांतरित करें;
- आने वाले डेटा की वैधता की जाँच करें।
यह एडॉप्टर का उद्देश्य है। अच्छा है, प्रत्येक बाहरी सिस्टम के साथ इंटरफेस पर जिसके साथ आपको बातचीत करने की आवश्यकता है, आपका एडेप्टर स्थापित होना चाहिए। इस प्रकार, डोमेन कॉल को किसी बाहरी सेवा को निर्देशित नहीं करेगा, लेकिन एडॉप्टर को। ऐसा करने के लिए, संबंधित निर्भरता डोमेन में (एडॉप्टर से या इंफ्रास्ट्रक्चर मॉड्यूल जिसमें यह स्थित है) पंजीकृत होना चाहिए। लेकिन क्या यह लत सुरक्षित है? यदि आप इसे इस तरह स्थापित करते हैं, तो एक बाहरी सेवा डीटीओ हमारे डोमेन में आ सकती है। हमें इसकी अनुमति नहीं देनी चाहिए। इसलिए, मैं आपको मॉडलिंग निर्भरता का एक और तरीका सुझाता हूं।
इस प्रकार, डोमेन कॉल को किसी बाहरी सेवा को निर्देशित नहीं करेगा, लेकिन एडॉप्टर को। ऐसा करने के लिए, संबंधित निर्भरता डोमेन में (एडॉप्टर से या इंफ्रास्ट्रक्चर मॉड्यूल जिसमें यह स्थित है) पंजीकृत होना चाहिए। लेकिन क्या यह लत सुरक्षित है? यदि आप इसे इस तरह स्थापित करते हैं, तो एक बाहरी सेवा डीटीओ हमारे डोमेन में आ सकती है। हमें इसकी अनुमति नहीं देनी चाहिए। इसलिए, मैं आपको मॉडलिंग निर्भरता का एक और तरीका सुझाता हूं।निर्भरता उलटा सिद्धांत
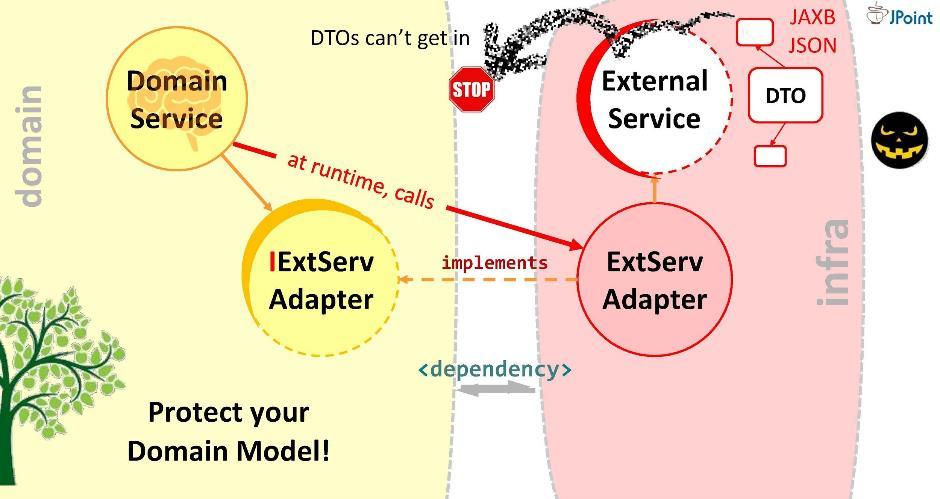 आइए एक इंटरफ़ेस बनाएं, इसमें आवश्यक विधियों के हस्ताक्षर लिखें और इसे हमारे डोमेन के अंदर रखें। एडेप्टर का कार्य इस इंटरफ़ेस को लागू करना है। यह पता चला है कि इंटरफ़ेस डोमेन के अंदर है, और एडाप्टर बाहर है, इंफ्रास्ट्रक्चर मॉड्यूल में जो इंटरफ़ेस आयात करता है। इस प्रकार, हमने विपरीत दिशा में निर्भरता की दिशा बदल दी। रन समय में, डोमेन सिस्टम इंटरफेस के माध्यम से किसी भी वर्ग को कॉल करेगा।जैसा कि आप देख सकते हैं, सिर्फ आर्किटेक्चर में इंटरफेस शुरू करने से, हम निर्भरता को तैनात करने में सक्षम थे और इस तरह से गिरने वाले विदेशी संरचनाओं और एपीआई से हमारे डोमेन को सुरक्षित किया। इस दृष्टिकोण को निर्भरता व्युत्क्रम कहा जाता है ।
आइए एक इंटरफ़ेस बनाएं, इसमें आवश्यक विधियों के हस्ताक्षर लिखें और इसे हमारे डोमेन के अंदर रखें। एडेप्टर का कार्य इस इंटरफ़ेस को लागू करना है। यह पता चला है कि इंटरफ़ेस डोमेन के अंदर है, और एडाप्टर बाहर है, इंफ्रास्ट्रक्चर मॉड्यूल में जो इंटरफ़ेस आयात करता है। इस प्रकार, हमने विपरीत दिशा में निर्भरता की दिशा बदल दी। रन समय में, डोमेन सिस्टम इंटरफेस के माध्यम से किसी भी वर्ग को कॉल करेगा।जैसा कि आप देख सकते हैं, सिर्फ आर्किटेक्चर में इंटरफेस शुरू करने से, हम निर्भरता को तैनात करने में सक्षम थे और इस तरह से गिरने वाले विदेशी संरचनाओं और एपीआई से हमारे डोमेन को सुरक्षित किया। इस दृष्टिकोण को निर्भरता व्युत्क्रम कहा जाता है ।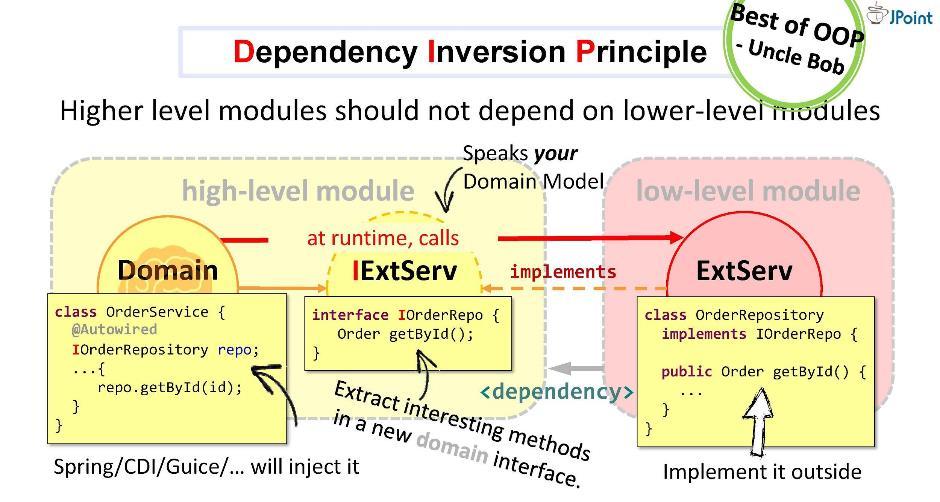 सामान्य तौर पर, निर्भरता व्युत्क्रम मानती है कि आप अपने उच्च-स्तरीय मॉड्यूल (डोमेन में) के अंदर इंटरफ़ेस में आपकी रुचि के तरीकों को रखते हैं, और इस इंटरफ़ेस को बाहर से लागू करते हैं - एक या दूसरे निम्न-स्तरीय (बुनियादी ढांचे) बदसूरत मॉड्यूल में।डोमेन मॉड्यूल के अंदर कार्यान्वित किए गए इंटरफ़ेस को डोमेन भाषा बोलनी चाहिए, अर्थात, यह उसकी संस्थाओं, उसके मापदंडों और वापसी प्रकारों पर काम करेगा। रन समय में, डोमेन किसी भी वर्ग को पॉलीमॉर्फिक कॉल के माध्यम से इंटरफ़ेस पर कॉल करेगा। निर्भरता इंजेक्शन फ्रेमवर्क (जैसे कि स्प्रिंग और सीडीआई) हमें रनटाइम में कक्षा के ठोस उदाहरण के साथ प्रदान करते हैं।लेकिन मुख्य बात यह है कि संकलन के दौरान डोमेन मॉड्यूल बाहरी मॉड्यूल की सामग्री को नहीं देखेगा। जो हमें चाहिए। किसी भी बाहरी संस्था को डोमेन में नहीं आना चाहिए। अंकल बॉब केअनुसार , नियंत्रण व्युत्क्रम का सिद्धांत (या, जैसा कि वह इसे कहते हैं, "प्लग-इन आर्किटेक्चर") संभवतः सबसे अच्छा है जो ओओपी प्रतिमान सामान्य रूप से प्रदान करता है। इस रणनीति का उपयोग किसी भी सिस्टम के साथ, तुल्यकालिक और अतुल्यकालिक कॉल और संदेशों के लिए, फ़ाइलों को भेजने के लिए, आदि के लिए एकीकरण के लिए किया जा सकता है।
सामान्य तौर पर, निर्भरता व्युत्क्रम मानती है कि आप अपने उच्च-स्तरीय मॉड्यूल (डोमेन में) के अंदर इंटरफ़ेस में आपकी रुचि के तरीकों को रखते हैं, और इस इंटरफ़ेस को बाहर से लागू करते हैं - एक या दूसरे निम्न-स्तरीय (बुनियादी ढांचे) बदसूरत मॉड्यूल में।डोमेन मॉड्यूल के अंदर कार्यान्वित किए गए इंटरफ़ेस को डोमेन भाषा बोलनी चाहिए, अर्थात, यह उसकी संस्थाओं, उसके मापदंडों और वापसी प्रकारों पर काम करेगा। रन समय में, डोमेन किसी भी वर्ग को पॉलीमॉर्फिक कॉल के माध्यम से इंटरफ़ेस पर कॉल करेगा। निर्भरता इंजेक्शन फ्रेमवर्क (जैसे कि स्प्रिंग और सीडीआई) हमें रनटाइम में कक्षा के ठोस उदाहरण के साथ प्रदान करते हैं।लेकिन मुख्य बात यह है कि संकलन के दौरान डोमेन मॉड्यूल बाहरी मॉड्यूल की सामग्री को नहीं देखेगा। जो हमें चाहिए। किसी भी बाहरी संस्था को डोमेन में नहीं आना चाहिए। अंकल बॉब केअनुसार , नियंत्रण व्युत्क्रम का सिद्धांत (या, जैसा कि वह इसे कहते हैं, "प्लग-इन आर्किटेक्चर") संभवतः सबसे अच्छा है जो ओओपी प्रतिमान सामान्य रूप से प्रदान करता है। इस रणनीति का उपयोग किसी भी सिस्टम के साथ, तुल्यकालिक और अतुल्यकालिक कॉल और संदेशों के लिए, फ़ाइलों को भेजने के लिए, आदि के लिए एकीकरण के लिए किया जा सकता है।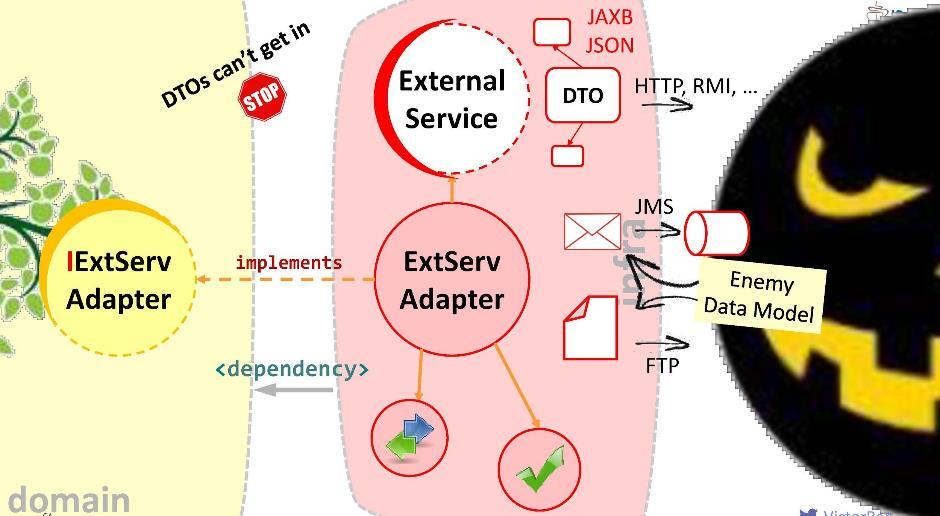
बल्ब अवलोकन
 इसलिए, हमने फैसला किया कि हम डोमेन मॉड्यूल की रक्षा करेंगे। इसके अंदर एक डोमेन सेवा, इकाइयां, मूल्य वस्तुएं हैं, और अब बाहरी सेवाओं के लिए इंटरफेस, और रिपॉजिटरी के लिए इंटरफेस (डेटाबेस के साथ बातचीत के लिए) है।संरचना इस तरह दिखती है:
इसलिए, हमने फैसला किया कि हम डोमेन मॉड्यूल की रक्षा करेंगे। इसके अंदर एक डोमेन सेवा, इकाइयां, मूल्य वस्तुएं हैं, और अब बाहरी सेवाओं के लिए इंटरफेस, और रिपॉजिटरी के लिए इंटरफेस (डेटाबेस के साथ बातचीत के लिए) है।संरचना इस तरह दिखती है: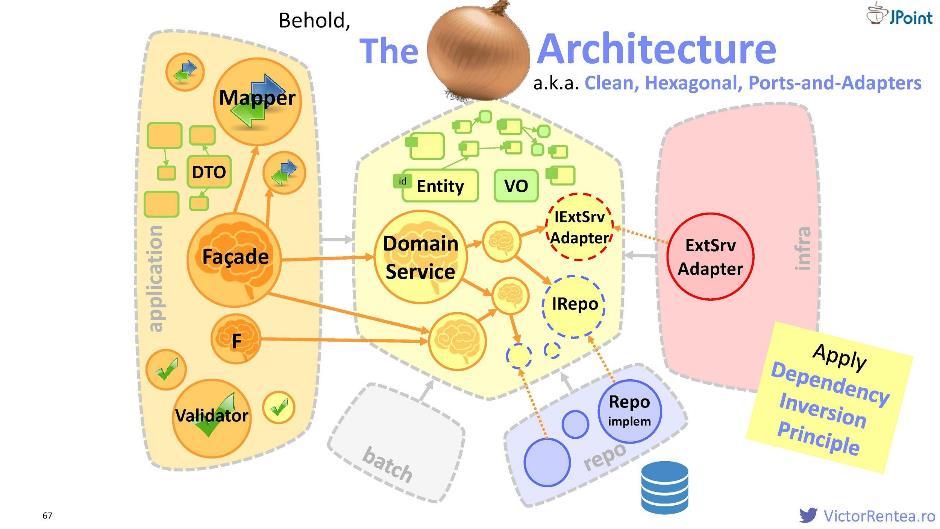 एक एप्लिकेशन मॉड्यूल, एक इन्फ्रास्ट्रक्चर मॉड्यूल (निर्भरता उलटा के माध्यम से), एक रिपॉजिटरी मॉड्यूल (हम डेटाबेस को बाहरी सिस्टम भी मानते हैं), एक बैच मॉड्यूल, और संभवतः कुछ अन्य मॉड्यूल डोमेन के लिए निर्भरता घोषित किए जाते हैं। इस वास्तुकला को "प्याज" कहा जाता है ; इसे "स्वच्छ," "हेक्सागोनल," और "पोर्ट और एडेप्टर" भी कहा जाता है।
एक एप्लिकेशन मॉड्यूल, एक इन्फ्रास्ट्रक्चर मॉड्यूल (निर्भरता उलटा के माध्यम से), एक रिपॉजिटरी मॉड्यूल (हम डेटाबेस को बाहरी सिस्टम भी मानते हैं), एक बैच मॉड्यूल, और संभवतः कुछ अन्य मॉड्यूल डोमेन के लिए निर्भरता घोषित किए जाते हैं। इस वास्तुकला को "प्याज" कहा जाता है ; इसे "स्वच्छ," "हेक्सागोनल," और "पोर्ट और एडेप्टर" भी कहा जाता है।रिपोजिटरी मॉड्यूल
मैं रिपॉजिटरी मॉड्यूल के बारे में संक्षेप में बात करूंगा। क्या इसे डोमेन से बाहर निकालना एक सवाल है। रिपॉजिटरी का काम लॉजिक क्लीनर को बनाना है, जो लगातार डेटा के साथ काम करने से हमें छिपा रहा है। पुराने स्कूल के लोगों के लिए विकल्प डेटाबेस के साथ बातचीत करने के लिए JDBC का उपयोग करना है: आप स्प्रिंग और इसके JdbcTemplate:
आप स्प्रिंग और इसके JdbcTemplate: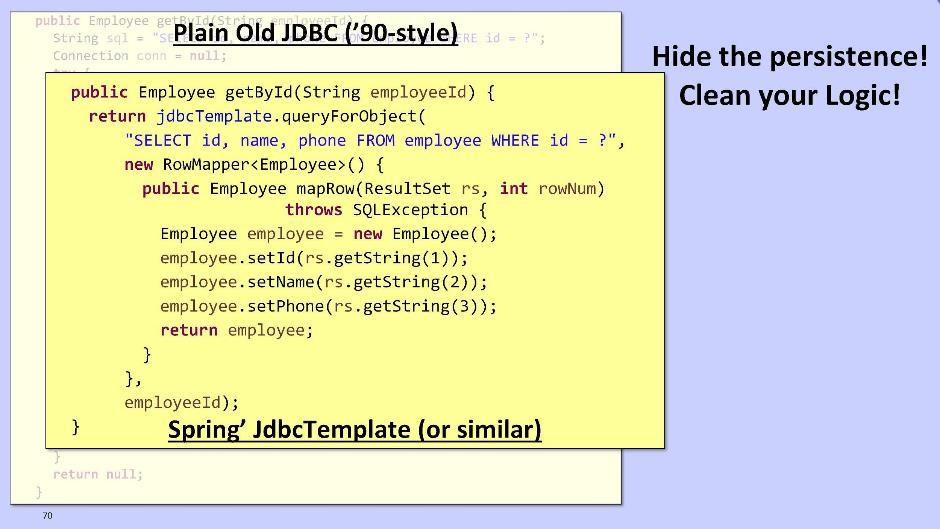 या MyBatis DataMapper का उपयोग कर सकते हैं :
या MyBatis DataMapper का उपयोग कर सकते हैं : लेकिन यह इतना जटिल और बदसूरत है कि यह आगे कुछ भी करने की इच्छा को हतोत्साहित करता है। इसलिए, मेरा सुझाव है कि जेपीए / हाइबरनेट या स्प्रिंग डेटा जेपीए का उपयोग करें। वे हमें डेटाबेस स्कीमा पर नहीं बल्कि सीधे हमारी संस्थाओं के मॉडल के आधार पर निर्मित प्रश्नों को भेजने का अवसर देंगे।JPA / हाइबरनेट के लिए कार्यान्वयन:
लेकिन यह इतना जटिल और बदसूरत है कि यह आगे कुछ भी करने की इच्छा को हतोत्साहित करता है। इसलिए, मेरा सुझाव है कि जेपीए / हाइबरनेट या स्प्रिंग डेटा जेपीए का उपयोग करें। वे हमें डेटाबेस स्कीमा पर नहीं बल्कि सीधे हमारी संस्थाओं के मॉडल के आधार पर निर्मित प्रश्नों को भेजने का अवसर देंगे।JPA / हाइबरनेट के लिए कार्यान्वयन: स्प्रिंग डेटा JPA के मामले में:
स्प्रिंग डेटा JPA के मामले में: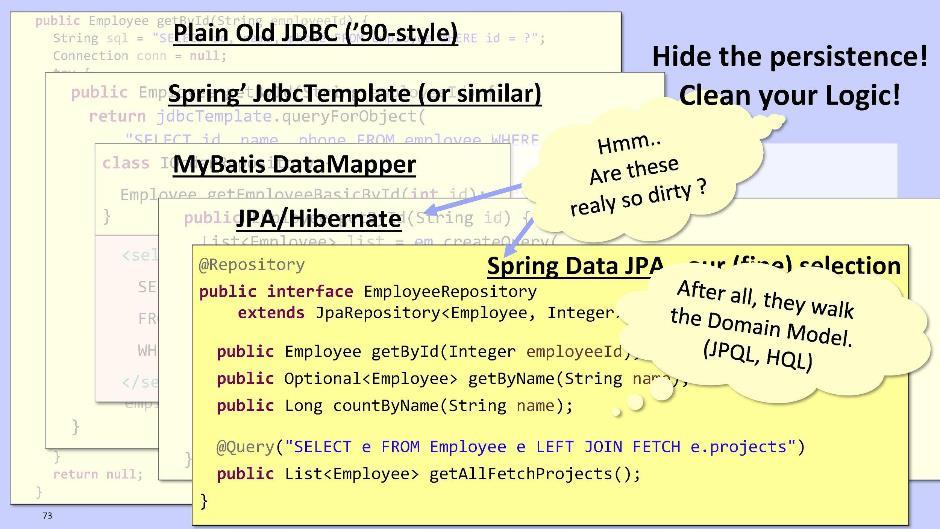 स्प्रिंग डेटा JPA स्वचालित रूप से रनटाइम पर विधियाँ उत्पन्न कर सकता है, जैसे, उदाहरण के लिए, getById (), getByName ()। यह आपको आवश्यक होने पर JPQL प्रश्नों को निष्पादित करने की अनुमति देता है - और डेटाबेस के लिए नहीं, बल्कि अपने स्वयं के इकाई मॉडल के लिए।हाइबरनेट JPA और स्प्रिंग डेटा JPA कोड वास्तव में बहुत अच्छे लगते हैं। क्या हमें इसे डोमेन से निकालने की आवश्यकता है? मेरी राय में, ऐसा और आवश्यक नहीं है। सबसे अधिक संभावना है, यदि आप इस टुकड़े को डोमेन के अंदर छोड़ देते हैं, तो कोड भी साफ हो जाएगा। इसलिए स्थिति पर कार्रवाई करें।
स्प्रिंग डेटा JPA स्वचालित रूप से रनटाइम पर विधियाँ उत्पन्न कर सकता है, जैसे, उदाहरण के लिए, getById (), getByName ()। यह आपको आवश्यक होने पर JPQL प्रश्नों को निष्पादित करने की अनुमति देता है - और डेटाबेस के लिए नहीं, बल्कि अपने स्वयं के इकाई मॉडल के लिए।हाइबरनेट JPA और स्प्रिंग डेटा JPA कोड वास्तव में बहुत अच्छे लगते हैं। क्या हमें इसे डोमेन से निकालने की आवश्यकता है? मेरी राय में, ऐसा और आवश्यक नहीं है। सबसे अधिक संभावना है, यदि आप इस टुकड़े को डोमेन के अंदर छोड़ देते हैं, तो कोड भी साफ हो जाएगा। इसलिए स्थिति पर कार्रवाई करें। यदि आप फिर भी एक रिपॉजिटरी मॉड्यूल बनाते हैं, तो निर्भरता के संगठन के लिए नियंत्रण उलटा के सिद्धांत का उसी तरह उपयोग करना बेहतर होता है। ऐसा करने के लिए, इंटरफ़ेस को डोमेन में रखें और इसे रिपॉजिटरी मॉड्यूल में लागू करें। रिपॉजिटरी लॉजिक के लिए, इसे डोमेन में ट्रांसफर करना बेहतर है। यह परीक्षण को सुविधाजनक बनाता है, क्योंकि आप डोमेन में मॉक ऑब्जेक्ट का उपयोग कर सकते हैं। वे आपको तर्क को जल्दी और बार-बार परखने की अनुमति देंगे।परंपरागत रूप से, एक डोमेन में भंडार के लिए केवल एक इकाई बनाई जाती है। वे इसे टुकड़ों में तोड़ते हैं, जब यह बहुत अधिक मात्रा में हो जाता है। याद रखें कि कक्षाएं कॉम्पैक्ट होनी चाहिए।
यदि आप फिर भी एक रिपॉजिटरी मॉड्यूल बनाते हैं, तो निर्भरता के संगठन के लिए नियंत्रण उलटा के सिद्धांत का उसी तरह उपयोग करना बेहतर होता है। ऐसा करने के लिए, इंटरफ़ेस को डोमेन में रखें और इसे रिपॉजिटरी मॉड्यूल में लागू करें। रिपॉजिटरी लॉजिक के लिए, इसे डोमेन में ट्रांसफर करना बेहतर है। यह परीक्षण को सुविधाजनक बनाता है, क्योंकि आप डोमेन में मॉक ऑब्जेक्ट का उपयोग कर सकते हैं। वे आपको तर्क को जल्दी और बार-बार परखने की अनुमति देंगे।परंपरागत रूप से, एक डोमेन में भंडार के लिए केवल एक इकाई बनाई जाती है। वे इसे टुकड़ों में तोड़ते हैं, जब यह बहुत अधिक मात्रा में हो जाता है। याद रखें कि कक्षाएं कॉम्पैक्ट होनी चाहिए।एपीआई
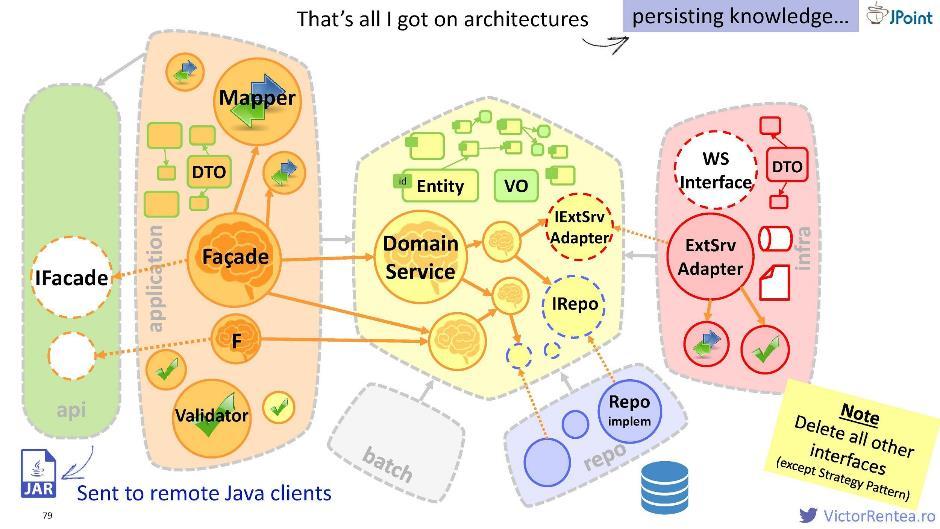 आप एक अलग मॉड्यूल बना सकते हैं, मुखौटा और डीटीओ से निकाले गए इंटरफ़ेस को रख सकते हैं जो उस पर भरोसा करते हैं, फिर इसे एक जार में पैक करें, और इस रूप में अपने जावा क्लाइंट को स्थानांतरित करें। इस फाइल के होने से, वे facades के लिए अनुरोध भेजने में सक्षम होंगे।
आप एक अलग मॉड्यूल बना सकते हैं, मुखौटा और डीटीओ से निकाले गए इंटरफ़ेस को रख सकते हैं जो उस पर भरोसा करते हैं, फिर इसे एक जार में पैक करें, और इस रूप में अपने जावा क्लाइंट को स्थानांतरित करें। इस फाइल के होने से, वे facades के लिए अनुरोध भेजने में सक्षम होंगे।व्यावहारिक बल्ब
हमारे "शत्रुओं" के अलावा, जिन्हें हम कार्यक्षमता प्रदान करते हैं, अर्थात्, ग्राहक, हमारे भी शत्रु हैं और दूसरी ओर, वे मॉड्यूल जिन पर हम स्वयं निर्भर हैं। हमें इन मॉड्यूल से खुद को बचाने की भी जरूरत है। और इसके लिए मैं आपको थोड़ा संशोधित "प्याज" प्रदान करता हूं - इसमें पूरे बुनियादी ढांचे को एक मॉड्यूल में जोड़ा जाता है।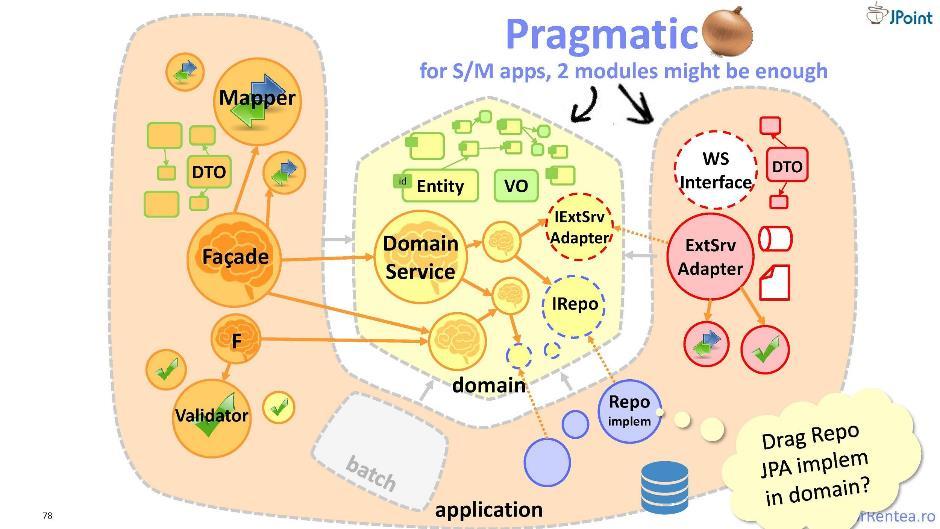 मैं इस वास्तुकला को "व्यावहारिक बल्ब" कहता हूं। यहाँ, घटकों का पृथक्करण "मेरा" और "पूर्णांक" के सिद्धांत के अनुसार किया जाता है: अलग से, जो मेरे डोमेन से संबंधित है, और अलग से, जो बाहरी सहयोगियों के साथ एकीकरण को संदर्भित करता है। इस प्रकार, केवल दो मॉड्यूल प्राप्त होते हैं: डोमेन और एप्लिकेशन। ऐसा आर्किटेक्चर बहुत अच्छा है, लेकिन केवल तब जब एप्लिकेशन मॉड्यूल छोटा हो। अन्यथा, आप पारंपरिक प्याज के लिए बेहतर वापसी करते हैं।
मैं इस वास्तुकला को "व्यावहारिक बल्ब" कहता हूं। यहाँ, घटकों का पृथक्करण "मेरा" और "पूर्णांक" के सिद्धांत के अनुसार किया जाता है: अलग से, जो मेरे डोमेन से संबंधित है, और अलग से, जो बाहरी सहयोगियों के साथ एकीकरण को संदर्भित करता है। इस प्रकार, केवल दो मॉड्यूल प्राप्त होते हैं: डोमेन और एप्लिकेशन। ऐसा आर्किटेक्चर बहुत अच्छा है, लेकिन केवल तब जब एप्लिकेशन मॉड्यूल छोटा हो। अन्यथा, आप पारंपरिक प्याज के लिए बेहतर वापसी करते हैं।परीक्षण
जैसा कि मैंने पहले कहा था, अगर हर कोई आपके आवेदन से डरता है, तो विचार करें कि इसने विरासत की रैंक को फिर से भर दिया है।  लेकिन परीक्षण अच्छे हैं। वे हमें विश्वास की भावना देते हैं जो हमें रिफैक्टिंग जारी रखने की अनुमति देता है। लेकिन दुर्भाग्य से, यह आत्मविश्वास आसानी से अनुचित हो सकता है। मैं समझाऊंगा क्यों। टीडीडी (परीक्षण के माध्यम से विकास) यह मानता है कि आप कोड के लेखक और परीक्षण मामलों के लेखक हैं: आप विनिर्देशों को पढ़ते हैं, कार्यक्षमता को लागू करते हैं और इसके लिए तुरंत एक परीक्षण सूट लिखते हैं। टेस्ट, कहते हैं, सफल होंगे। लेकिन क्या होगा अगर आप विनिर्देशों की आवश्यकताओं को गलत समझते हैं? फिर परीक्षण यह जाँचेंगे कि क्या आवश्यक नहीं है। इसलिए आपका आत्मविश्वास बेकार है। और सभी क्योंकि आपने कोड और परीक्षण अकेले लिखे थे।लेकिन इससे हमारी आंखें बंद करने की कोशिश करें। टेस्ट अभी भी आवश्यक हैं, और किसी भी मामले में वे हमें विश्वास दिलाते हैं। सभी के अधिकांश, निश्चित रूप से, हम कार्यात्मक परीक्षण प्यार करते हैं: वे किसी भी साइड इफेक्ट का मतलब नहीं है, कोई निर्भरता नहीं - केवल इनपुट और आउटपुट डेटा। एक डोमेन का परीक्षण करने के लिए, आपको नकली वस्तुओं का उपयोग करने की आवश्यकता है: वे आपको अलगाव में कक्षाओं का परीक्षण करने की अनुमति देंगे।डेटाबेस प्रश्नों के लिए, उनका परीक्षण करना अप्रिय है। ये परीक्षण नाजुक हैं, उन्हें आवश्यकता है कि आप पहले डेटाबेस में परीक्षण डेटा जोड़ें - और उसके बाद ही आप कार्यक्षमता का परीक्षण करने के लिए आगे बढ़ सकते हैं। लेकिन जैसा कि आप समझते हैं, ये परीक्षण आवश्यक भी हैं, भले ही आप जेपीए का उपयोग करें।
लेकिन परीक्षण अच्छे हैं। वे हमें विश्वास की भावना देते हैं जो हमें रिफैक्टिंग जारी रखने की अनुमति देता है। लेकिन दुर्भाग्य से, यह आत्मविश्वास आसानी से अनुचित हो सकता है। मैं समझाऊंगा क्यों। टीडीडी (परीक्षण के माध्यम से विकास) यह मानता है कि आप कोड के लेखक और परीक्षण मामलों के लेखक हैं: आप विनिर्देशों को पढ़ते हैं, कार्यक्षमता को लागू करते हैं और इसके लिए तुरंत एक परीक्षण सूट लिखते हैं। टेस्ट, कहते हैं, सफल होंगे। लेकिन क्या होगा अगर आप विनिर्देशों की आवश्यकताओं को गलत समझते हैं? फिर परीक्षण यह जाँचेंगे कि क्या आवश्यक नहीं है। इसलिए आपका आत्मविश्वास बेकार है। और सभी क्योंकि आपने कोड और परीक्षण अकेले लिखे थे।लेकिन इससे हमारी आंखें बंद करने की कोशिश करें। टेस्ट अभी भी आवश्यक हैं, और किसी भी मामले में वे हमें विश्वास दिलाते हैं। सभी के अधिकांश, निश्चित रूप से, हम कार्यात्मक परीक्षण प्यार करते हैं: वे किसी भी साइड इफेक्ट का मतलब नहीं है, कोई निर्भरता नहीं - केवल इनपुट और आउटपुट डेटा। एक डोमेन का परीक्षण करने के लिए, आपको नकली वस्तुओं का उपयोग करने की आवश्यकता है: वे आपको अलगाव में कक्षाओं का परीक्षण करने की अनुमति देंगे।डेटाबेस प्रश्नों के लिए, उनका परीक्षण करना अप्रिय है। ये परीक्षण नाजुक हैं, उन्हें आवश्यकता है कि आप पहले डेटाबेस में परीक्षण डेटा जोड़ें - और उसके बाद ही आप कार्यक्षमता का परीक्षण करने के लिए आगे बढ़ सकते हैं। लेकिन जैसा कि आप समझते हैं, ये परीक्षण आवश्यक भी हैं, भले ही आप जेपीए का उपयोग करें।यूनिट परीक्षण
 मैं कहूंगा कि इकाई परीक्षणों की शक्ति उन्हें चलाने की संभावना में नहीं है, लेकिन उन्हें लिखने की प्रक्रिया में क्या शामिल है। जब आप एक परीक्षण लिख रहे हैं, तो आप कोड के माध्यम से पुनर्विचार और काम करते हैं - कनेक्टिविटी को कम करें, इसे कक्षाओं में तोड़ दें - एक शब्द में, अगले रिफैक्टिंग को अंजाम दें। परीक्षण के तहत कोड शुद्ध कोड है; यह सरल है, इसमें कनेक्टिविटी कम हो गई है; सामान्य तौर पर, यह भी प्रलेखित है (एक अच्छी तरह से लिखित इकाई परीक्षण पूरी तरह से बताता है कि कक्षा कैसे काम करती है)। यह आश्चर्य की बात नहीं है कि इकाई परीक्षण लिखना मुश्किल है, खासकर पहले कुछ टुकड़े।
मैं कहूंगा कि इकाई परीक्षणों की शक्ति उन्हें चलाने की संभावना में नहीं है, लेकिन उन्हें लिखने की प्रक्रिया में क्या शामिल है। जब आप एक परीक्षण लिख रहे हैं, तो आप कोड के माध्यम से पुनर्विचार और काम करते हैं - कनेक्टिविटी को कम करें, इसे कक्षाओं में तोड़ दें - एक शब्द में, अगले रिफैक्टिंग को अंजाम दें। परीक्षण के तहत कोड शुद्ध कोड है; यह सरल है, इसमें कनेक्टिविटी कम हो गई है; सामान्य तौर पर, यह भी प्रलेखित है (एक अच्छी तरह से लिखित इकाई परीक्षण पूरी तरह से बताता है कि कक्षा कैसे काम करती है)। यह आश्चर्य की बात नहीं है कि इकाई परीक्षण लिखना मुश्किल है, खासकर पहले कुछ टुकड़े।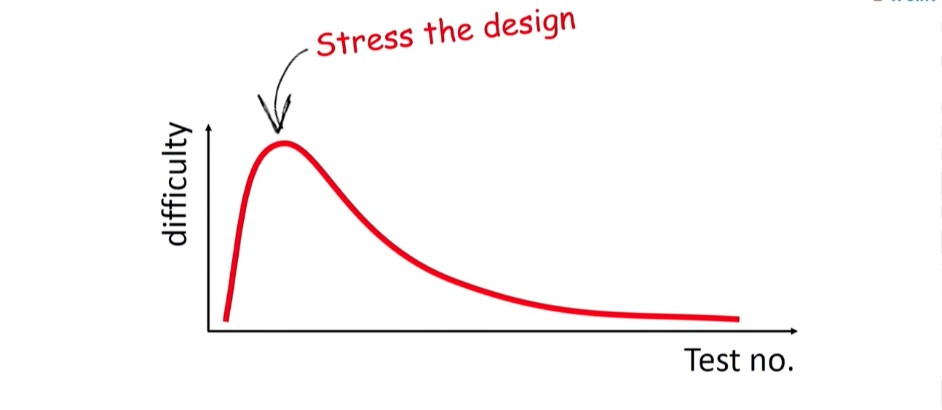 पहली इकाई परीक्षणों के चरण में, बहुत से लोग वास्तव में उन संभावनाओं से डरते हैं जो उन्हें वास्तव में कुछ का परीक्षण करना है। उन्हें इतनी मेहनत क्यों दी जाती है?क्योंकि ये परीक्षण आपकी कक्षा पर पहला बोझ हैं। यह प्रणाली के लिए पहला झटका है, जो, शायद, दिखाएगा कि यह नाजुक और भड़कीला है। लेकिन आपको यह समझने की आवश्यकता है कि ये कुछ परीक्षण आपके विकास के लिए सबसे महत्वपूर्ण हैं। वे संक्षेप में, आपके सबसे अच्छे दोस्त हैं, क्योंकि वे सब कुछ कहेंगे क्योंकि यह आपके कोड की गुणवत्ता के बारे में है। यदि आप इस चरण से डरते हैं, तो आप बहुत दूर नहीं हैं। आपको अपने सिस्टम के लिए परीक्षण चलाना चाहिए। उसके बाद, जटिलता कम हो जाएगी, परीक्षण तेजी से लिखे जाएंगे। उन्हें एक-एक करके जोड़ते हुए, आप अपने सिस्टम के लिए एक विश्वसनीय प्रतिगमन परीक्षण आधार बनाएंगे। और यह आपके डेवलपर्स के भविष्य के काम के लिए अविश्वसनीय रूप से महत्वपूर्ण है। उनके लिए रिफ्लेक्टर करना आसान होगा; वे समझेंगे कि सिस्टम को किसी भी समय परीक्षण किया जा सकता है, यही वजह है कि कोड आधार के साथ काम करना सुरक्षित है। और, मैं आपको आश्वस्त करता हूं, वे और अधिक स्वेच्छा से रिफैक्ट करने में लगे रहेंगे।
पहली इकाई परीक्षणों के चरण में, बहुत से लोग वास्तव में उन संभावनाओं से डरते हैं जो उन्हें वास्तव में कुछ का परीक्षण करना है। उन्हें इतनी मेहनत क्यों दी जाती है?क्योंकि ये परीक्षण आपकी कक्षा पर पहला बोझ हैं। यह प्रणाली के लिए पहला झटका है, जो, शायद, दिखाएगा कि यह नाजुक और भड़कीला है। लेकिन आपको यह समझने की आवश्यकता है कि ये कुछ परीक्षण आपके विकास के लिए सबसे महत्वपूर्ण हैं। वे संक्षेप में, आपके सबसे अच्छे दोस्त हैं, क्योंकि वे सब कुछ कहेंगे क्योंकि यह आपके कोड की गुणवत्ता के बारे में है। यदि आप इस चरण से डरते हैं, तो आप बहुत दूर नहीं हैं। आपको अपने सिस्टम के लिए परीक्षण चलाना चाहिए। उसके बाद, जटिलता कम हो जाएगी, परीक्षण तेजी से लिखे जाएंगे। उन्हें एक-एक करके जोड़ते हुए, आप अपने सिस्टम के लिए एक विश्वसनीय प्रतिगमन परीक्षण आधार बनाएंगे। और यह आपके डेवलपर्स के भविष्य के काम के लिए अविश्वसनीय रूप से महत्वपूर्ण है। उनके लिए रिफ्लेक्टर करना आसान होगा; वे समझेंगे कि सिस्टम को किसी भी समय परीक्षण किया जा सकता है, यही वजह है कि कोड आधार के साथ काम करना सुरक्षित है। और, मैं आपको आश्वस्त करता हूं, वे और अधिक स्वेच्छा से रिफैक्ट करने में लगे रहेंगे। आपको मेरी सलाह: अगर आपको लगता है कि आज आपके पास बहुत ताकत और ऊर्जा है, तो अपने आप को यूनिट टेस्ट लिखने के लिए समर्पित करें। और सुनिश्चित करें कि प्रत्येक एक साफ, तेज है, अपना वजन है और दूसरों को नहीं दोहराता है।
आपको मेरी सलाह: अगर आपको लगता है कि आज आपके पास बहुत ताकत और ऊर्जा है, तो अपने आप को यूनिट टेस्ट लिखने के लिए समर्पित करें। और सुनिश्चित करें कि प्रत्येक एक साफ, तेज है, अपना वजन है और दूसरों को नहीं दोहराता है।टिप्स
आज कहे गए सभी बातों को संक्षेप में, मैं आपको निम्नलिखित युक्तियों के साथ अपनाना चाहूंगा:- इसे यथासंभव लंबे समय तक सरल रखें (और इससे कोई फर्क नहीं पड़ता कि इसकी लागत क्या है) : "रीइंजीनियरिंग" और बेलेटेड ऑप्टिमाइज़ेशन से बचें, एप्लिकेशन को अधिभार न डालें;
- , , ;
- «» — ;
- , — : ;
- «», , — ;
- परीक्षणों से डरो मत : उन्हें अपने सिस्टम को गिराने का अवसर दें, उनके सभी लाभों को महसूस करें - अंत में, वे आपके दोस्त हैं क्योंकि वे ईमानदारी से समस्याओं को इंगित करने में सक्षम हैं।
इन चीजों को करके, आप अपनी टीम और खुद दोनों की मदद करेंगे। और फिर, जब उत्पाद की डिलीवरी का दिन आएगा, तो आप इसके लिए तैयार होंगे।क्या पढ़ना है?

. JPoint — , 19-20 - Joker 2018 — Java-. . .