अत्यधिक विविधीकरण के खतरों पर
लेख को जारी रखने के लिए, हम उपयोगी स्टॉक चयन उपकरण बनाएंगे। उसके बाद, हम एक सरल रीबैलेंसिंग करेंगे और तकनीकी संकेतकों की अनूठी शर्तों को जोड़ेंगे, जो कि लोकप्रिय सेवाओं में अक्सर कमी होती है। और फिर व्यक्तिगत परिसंपत्तियों और विभिन्न विभागों पर रिटर्न की तुलना करें।
इस सब में हम पंडों का उपयोग करते हैं और चक्रों की संख्या को कम करते हैं। समय श्रृंखला समूह और रेखांकन आकर्षित करें। आइए बहु-सूचकांकों और उनके व्यवहार से परिचित हों। और यह सब Python 3.6 में Jupyter में।
यदि आप कुछ अच्छा करना चाहते हैं, तो स्वयं करें।
फर्डिनेंड पोर्श
वर्णित टूल आपको पोर्टफोलियो के लिए इष्टतम संपत्ति का चयन करने और सलाहकारों द्वारा लगाए गए टूल को बाहर करने की अनुमति देगा। लेकिन हम केवल बड़ी तस्वीर देखेंगे - खाते की तरलता, पदों की भर्ती के लिए समय, ब्रोकर कमीशन और एक शेयर की लागत के बिना। सामान्य तौर पर, बड़े दलालों के मासिक या वार्षिक पुनर्संतुलन के साथ यह महत्वहीन लागत होगी। हालांकि, आवेदन करने से पहले, संभावित त्रुटियों को खत्म करने के लिए, चुने गए रणनीति को इवेंट-संचालित बैकटेस्टर में जांचना चाहिए, उदाहरण के लिए, क्वांटोपियन (क्यूपी)।
क्यूपी में तुरंत क्यों नहीं? समय। वहां, सबसे सरल परीक्षण लगभग 5 मिनट तक रहता है। और वर्तमान समाधान आपको एक मिनट में अद्वितीय स्थितियों के साथ सैकड़ों विभिन्न रणनीतियों की जांच करने की अनुमति देगा।
कच्चा डेटा लोड हो रहा है
डेटा लोड करने के लिए, इस
आलेख में वर्णित विधि लें। मैं दैनिक कीमतों को स्टोर करने के लिए PostgreSQL का उपयोग करता हूं, लेकिन अब यह मुफ्त स्रोतों से भरा है, जहां से आप आवश्यक डेटाफ़्रेम बना सकते हैं।
डेटाबेस से मूल्य इतिहास डाउनलोड करने का कोड रिपॉजिटरी में उपलब्ध है। लिंक लेख के अंत में होगा।
DataFrame संरचना
मूल्य इतिहास के साथ काम करते समय, सुविधाजनक समूहीकरण और सभी डेटा तक पहुंच के लिए, सबसे अच्छा समाधान तारीख और टिकर के साथ एक बहु-सूचकांक (मल्टीइंडेक्स) का उपयोग करना है।
df = df.set_index(['dt', 'symbol'], drop=False).sort_index() df.tail(len(df.index.levels[1]) * 2)
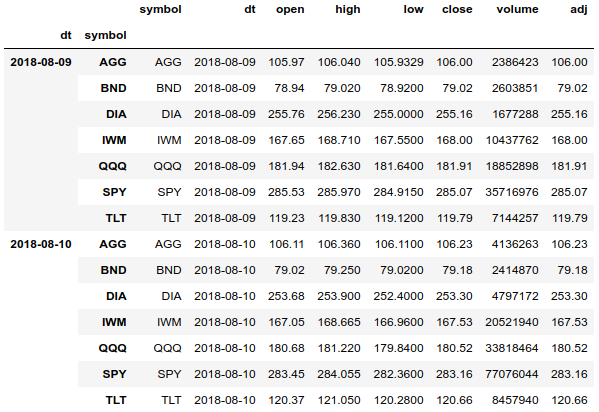
एक मल्टी-इंडेक्स का उपयोग करके, हम आसानी से सभी परिसंपत्तियों के लिए पूरे मूल्य इतिहास तक पहुंच सकते हैं और सरणी को तिथि और परिसंपत्ति द्वारा अलग-अलग समूह कर सकते हैं। हम एक संपत्ति के लिए मूल्य इतिहास भी प्राप्त कर सकते हैं।
यहां इस बात का उदाहरण दिया गया है कि आप सप्ताह, महीने, और वर्ष के आधार पर इतिहास को आसानी से कैसे समझ सकते हैं। और पंडों बलों द्वारा रेखांकन पर यह सब दिखाने के लिए:
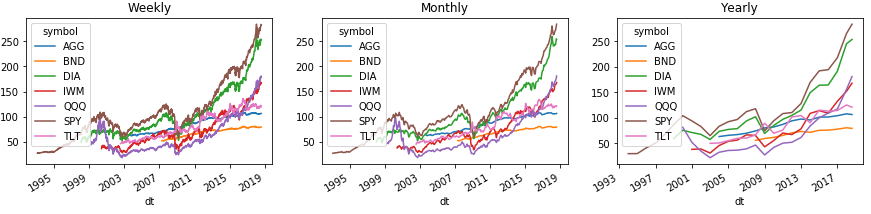
चार्ट किंवदंती के साथ क्षेत्र को सही ढंग से प्रदर्शित करने के लिए, हम श्रृंखला () (अनस्टैक (1) कमांड का उपयोग करते हुए स्तंभों के ऊपर सूचकांक स्तर को दूसरे स्तर पर टिकर के साथ स्थानांतरित करते हैं। DataFrame () के साथ, ऐसी संख्या काम नहीं करेगी, लेकिन समाधान नीचे है।
जब मानक अवधि के अनुसार समूहीकरण किया जाता है, तो पंडास सूचकांक में समूह की नवीनतम कैलेंडर तिथि का उपयोग करता है, जो अक्सर वास्तविक तिथियों से भिन्न होता है। इसे ठीक करने के लिए, इंडेक्स को अपडेट करें।
monthly = df.groupby([pd.Grouper(freq='M', level=0), level_values(1)]).agg(agg_rules) \ .set_index(['dt', 'symbol'], drop=False)
एक विशिष्ट संपत्ति का मूल्य इतिहास प्राप्त करने का एक उदाहरण (हम सभी तिथियां, QQQ टिकर और सभी कॉलम लेते हैं):
monthly.loc[(slice(None), ['QQQ']), :]
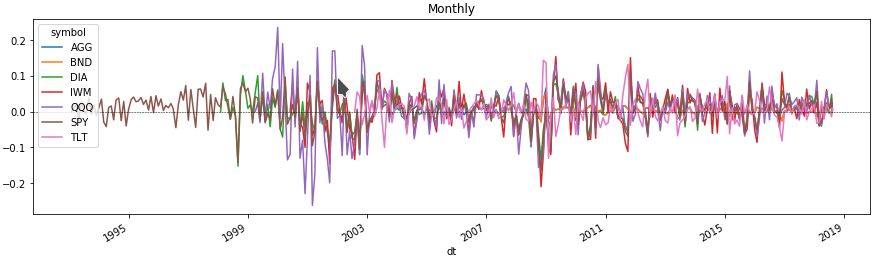
मासिक संपत्ति की अस्थिरता
अब हम चार्ट पर कुछ पंक्तियों को देख सकते हैं कि हमारे लिए ब्याज की अवधि के लिए प्रत्येक संपत्ति की कीमत में बदलाव। ऐसा करने के लिए, हम एक परिसंपत्ति टिकर के साथ बहु-सूचकांक स्तर द्वारा डेटाफ्रेम को समूहीकृत करके मूल्य परिवर्तनों का प्रतिशत प्राप्त करते हैं।
monthly = df.groupby([pd.Grouper(freq='M', level=0), level_values(1)]).agg( agg_rules).set_index(['dt', 'symbol'], drop=False)
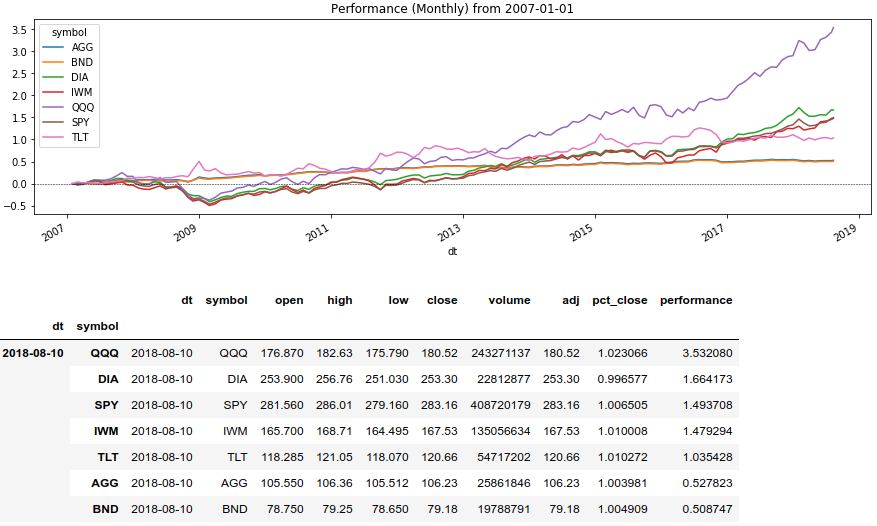
एसेट रिटर्न की तुलना करें
अब हम श्रृंखला ()) रोलिंग () विंडो विधि का उपयोग करेंगे और एक निश्चित अवधि के लिए परिसंपत्तियों पर रिटर्न प्रदर्शित करेंगे:
पायथन कोड rolling_prod = lambda x: x.rolling(len(x), min_periods=1).apply(np.prod)
पोर्टफोलियो रीबैलेंसिंग के तरीके
तो हम सबसे स्वादिष्ट हो गए। उदाहरणों में, हम कई परिसंपत्तियों के बीच पूर्व निर्धारित शेयरों को पूंजी के आवंटन में पोर्टफोलियो के परिणामों को देखेंगे। और अद्वितीय शर्तें भी जोड़ें जिनके तहत हम पूंजी के वितरण के समय कुछ संपत्तियों को छोड़ देंगे। यदि कोई उपयुक्त संपत्ति नहीं है, तो हम मानते हैं कि दलाल के पास कैश में पूंजी है।
पुनर्संतुलन के लिए पंडों के तरीकों का उपयोग करने के लिए, हमें एक डेटाफ़्रेम में समूहीकृत डेटा के साथ वितरण शेयरों और असंतुलन की स्थितियों को संग्रहीत करने की आवश्यकता है। अब रिबैलेंसिंग फंक्शन्स पर विचार करें जिसे हम डेटाफ़्रेम () लागू करेंगे। लागू करें () विधि:
क्रम में:
- rebalance_simple सबसे सरल कार्य है जो शेयरों में प्रत्येक परिसंपत्ति की लाभप्रदता को वितरित करेगा।
- rebalance_sma एक ऐसा कार्य है जो उन परिसंपत्तियों के बीच पूंजी का वितरण करता है जिनकी चलती औसत प्रतिपूर्ति के समय 200 दिनों की तुलना में 50 दिन अधिक होती है।
- rebalance_rsi - एक ऐसा फ़ंक्शन जो परिसंपत्तियों के बीच पूंजी वितरित करता है जिसके लिए 100 दिनों के लिए आरएसआई संकेतक का मूल्य 50 से ऊपर है।
- rebalance_custom सबसे धीमा और सबसे सार्वभौमिक फ़ंक्शन है, जहां हम रिबैलेंसिंग के समय दैनिक संपत्ति मूल्य इतिहास से संकेतक मूल्यों की गणना करेंगे। यहां आप किसी भी स्थिति और डेटा का उपयोग कर सकते हैं। यहां तक कि हर बार बाहरी स्रोतों से डाउनलोड करें। लेकिन आप एक चक्र के बिना नहीं कर सकते।
- ड्राडाउन - सहायक फ़ंक्शन, पोर्टफोलियो में अधिकतम गिरावट दिखा रहा है।
रिबैलेंसिंग फंक्शंस में, हमें एसेट्स द्वारा टूटी तारीख के लिए सभी डेटा की एक सरणी की आवश्यकता होती है। डेटाफ्रेम () लागू करें () विधि, जिसके द्वारा हम पोर्टफोलियो के परिणामों की गणना करेंगे, हमारे फ़ंक्शन के लिए एक सरणी पास करेंगे, जहां कॉलम पंक्ति सूचकांक बन जाएगा। और अगर हम एक बहु-सूचकांक बनाते हैं, जहां टिकर शून्य स्तर होगा, तो एक बहु-सूचकांक हमारे पास आएगा। हम इस बहु-सूचकांक को दो-आयामी सरणी में विस्तारित कर सकते हैं और प्रत्येक पंक्ति पर संबंधित संपत्ति का डेटा प्राप्त कर सकते हैं।

पोर्टफोलियो रिबैलेंसिंग
अब आवश्यक शर्तों को तैयार करना और चक्र में प्रत्येक पोर्टफोलियो के लिए एक गणना करना पर्याप्त है। सबसे पहले, हम दैनिक मूल्य इतिहास पर संकेतक की गणना करते हैं:
अब हम उपरोक्त वर्णित विधियों का उपयोग करके वांछित पुनर्वित्त अवधि के लिए कहानी का समूह बनाएंगे। उसी समय, हम भविष्य की तलाश को बाहर करने के लिए अवधि की शुरुआत में संकेतक के मूल्यों को ले लेंगे।
हम विभागों की संरचना का वर्णन करते हैं और वांछित पुनर्संतुलन का संकेत देते हैं। हम एक चक्र में विभागों की गणना करेंगे, क्योंकि हमें अद्वितीय शेयरों और शर्तों को निर्दिष्ट करने की आवश्यकता है:
इस बार हमें असंतुलन फ़ंक्शन में वांछित बहु-सूचकांक प्राप्त करने के लिए कॉलम और पंक्ति सूचकांकों के साथ एक चाल करने की आवश्यकता है। हम इसे DataFrame ()। Stack ()। Unstack ([1, 2]) क्रम में कॉल करके प्राप्त करेंगे। यह कोड कॉलम को लोअरकेस मल्टी-इंडेक्स में स्थानांतरित करेगा, और फिर वांछित क्रम में टिकर और कॉलम के साथ मल्टी-इंडेक्स को वापस करेगा।
चार्ट के लिए तैयार ब्रीफकेस
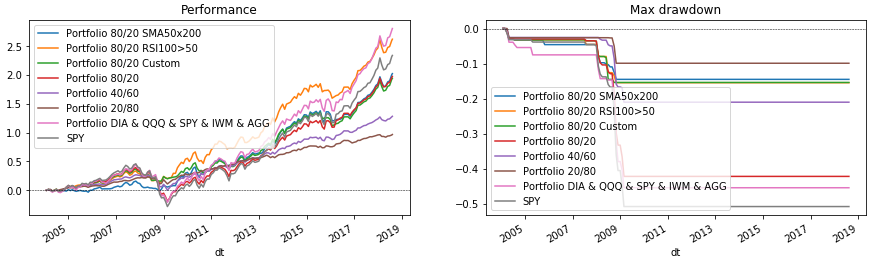
अब यह सब कुछ आकर्षित करता है। ऐसा करने के लिए, पोर्टफोलियो चक्र को फिर से चलाएं, जो चार्ट पर डेटा प्रदर्शित करता है। अंत में हम एसपीवाई को एक बेंचमार्क के रूप में तुलना के लिए तैयार करेंगे।
पायथन कोड fig = plt.figure(figsize=(15, 4), facecolor='white') ax_perf = fig.add_subplot(121) ax_dd = fig.add_subplot(122) for p in portfolios: p['performance'].rename(p['name']).plot(ax=ax_perf, legend=True, title='Performance') p['drawdown'].rename(p['name']).plot(ax=ax_dd, legend=True, title='Max drawdown')
निष्कर्ष
माना गया कोड आपको विभिन्न पोर्टफोलियो संरचनाओं और रीबैलेंसिंग स्थितियों का चयन करने की अनुमति देता है। इसकी मदद से, आप जल्दी से जांच कर सकते हैं कि क्या उदाहरण के लिए, यह एक पोर्टफोलियो में सोने (जीएलडी) या उभरते बाजारों (ईईएम) के लायक है। इसे स्वयं आज़माएं, संकेतक के लिए अपनी शर्तों को जोड़ें या पहले से वर्णित मापदंडों का चयन करें। (लेकिन उत्तरजीवी की गलती को याद रखें और पिछले डेटा के लिए फिटिंग भविष्य में उम्मीदों पर खरा नहीं उतर सकती।) और फिर तय करें कि आप किसके साथ अपने पोर्टफोलियो पर भरोसा करते हैं - पायथन या वित्तीय सलाहकार?
रिपोजिटरी:
rebalance.portfolio