
हाल ही में, फ़िशिंग साइबर अपराधियों के लिए धन या जानकारी चुराने का सबसे आसान और लोकप्रिय तरीका रहा है। उदाहरण के लिए, आपको दूर जाने की आवश्यकता नहीं है। पिछले साल, प्रमुख रूसी उद्यमों को एक अभूतपूर्व पैमाने पर हमले का सामना करना पड़ा - हमलावरों ने बड़े पैमाने पर नकली संसाधनों को पंजीकृत किया, उनकी ओर से अनुबंध समाप्त करने के लिए उर्वरक और पेट्रो रसायन निर्माताओं की साइटों की सटीक प्रतियां। इस तरह के हमले से औसत क्षति 1.5 मिलियन रूबल से है, कंपनी द्वारा नुकसान की प्रतिष्ठा का उल्लेख नहीं करना। इस लेख में, हम HTML के बजाय संसाधन विश्लेषण (सीएसएस, जेएस छवियों, आदि) का उपयोग करके फ़िशिंग साइटों का प्रभावी ढंग से पता लगाने के बारे में बात करेंगे और इन समस्याओं को कैसे हल कर सकते हैं।
पावेल स्लिपेनचुक, मशीन लर्निंग सिस्टम आर्किटेक्ट, ग्रुप-आईबी
फ़िशिंग महामारी
ग्रुप-आईबी के अनुसार, विभिन्न बैंकों के 900 से अधिक ग्राहक हर दिन रूस में अकेले वित्तीय फ़िशिंग के शिकार हो जाते हैं - यह आंकड़ा मैलवेयर के शिकार लोगों की दैनिक संख्या का 3 गुना है। एक उपयोगकर्ता पर एक फ़िशिंग हमले से नुकसान 2,000 से 50,000 रूबल तक भिन्न होता है। जालसाज केवल एक कंपनी या बैंक की वेबसाइट, उनके लोगो और कंपनी के रंग, सामग्री, संपर्क विवरण की प्रतिलिपि नहीं बनाते हैं, एक समान डोमेन नाम पंजीकृत करते हैं, वे अभी भी सामाजिक नेटवर्क और खोज इंजन में अपने संसाधनों का सक्रिय रूप से विज्ञापन करते हैं। उदाहरण के लिए, वे अनुरोध के लिए खोज परिणामों के शीर्ष पर अपने फ़िशिंग साइटों के लिंक लाने का प्रयास करते हैं "कार्ड में धन स्थानांतरित करें"। कार्ड से कार्ड में स्थानांतरित करने या मोबाइल ऑपरेटरों की सेवाओं के लिए तत्काल भुगतान के साथ पैसे चोरी करने के लिए अक्सर, नकली साइटें ठीक से बनाई जाती हैं।
फ़िशिंग (संलग्न। फ़िशिंग, मछली पकड़ने से - मछली पकड़ना, मछली पकड़ना) इंटरनेट धोखाधड़ी का एक रूप है, जिसका उद्देश्य पीड़ित को धोखेबाज़ को गोपनीय जानकारी प्रदान करना है। सबसे अधिक बार, वे पैसे चोरी करने के लिए बैंक अकाउंट एक्सेस पासवर्ड चुराते हैं, सोशल मीडिया अकाउंट (पैसा निकालने या पीड़ित की ओर से स्पैम भेजने के लिए), सशुल्क सेवाओं के लिए साइन अप करते हैं, मेल भेजते हैं या कंप्यूटर को संक्रमित करते हैं, जिससे यह बॉटनेट में एक लिंक बन जाता है।
हमले के तरीकों से, उपयोगकर्ताओं और कंपनियों पर लक्षित फ़िशिंग के 2 प्रकार हैं:
- फ़िशिंग साइटें जो पीड़ित के मूल संसाधन (बैंक, एयरलाइंस, ऑनलाइन स्टोर, उद्यम, सरकारी एजेंसियों, आदि) की नकल करती हैं।
- फ़िशिंग मेलिंग, ई-मेल, एसएमएस, सामाजिक नेटवर्क में संदेश आदि।
व्यक्तियों पर अक्सर उपयोगकर्ताओं द्वारा हमला किया जाता है, और आपराधिक व्यवसाय के इस क्षेत्र में प्रवेश करने की सीमा इतनी कम है कि न्यूनतम "निवेश" और बुनियादी ज्ञान इसे लागू करने के लिए पर्याप्त हैं। इस प्रकार की धोखाधड़ी का प्रसार फ़िशिंग किट, फ़िशिंग साइट बिल्डर कार्यक्रमों द्वारा भी किया जाता है, जिन्हें हैकर मंचों पर डार्कनेट में स्वतंत्र रूप से खरीदा जा सकता है।
कंपनियों या बैंकों पर हमले अलग हैं। वे तकनीकी रूप से अधिक समझदार हमलावरों द्वारा किए जाते हैं। एक नियम के रूप में, बड़े औद्योगिक उद्यमों, ऑनलाइन स्टोर, एयरलाइंस और सबसे अधिक बार बैंकों को पीड़ितों के रूप में चुना जाता है। ज्यादातर मामलों में, फ़िशिंग एक संक्रमित फ़ाइल के साथ एक ईमेल भेजने के लिए नीचे आती है। इस तरह के एक हमले के सफल होने के लिए, समूह के "कर्मचारियों" को दुर्भावनापूर्ण कोड लिखने में विशेषज्ञ होने चाहिए, और प्रोग्रामर को अपनी गतिविधियों को स्वचालित करने के लिए, और ऐसे लोग जो पीड़ित पर प्राथमिक बुद्धिमत्ता का संचालन कर सकते हैं और उसकी कमजोरियों का पता लगा सकते हैं।
रूस में, हमारे अनुमानों के अनुसार, वित्तीय संस्थानों के उद्देश्य से फ़िशिंग में 15 आपराधिक समूह लगे हुए हैं। क्षति की मात्रा हमेशा छोटी होती है (बैंकिंग ट्रोजन से दस गुना कम), लेकिन पीड़ितों की संख्या जो वे अपनी साइटों को लुभाते हैं, हर दिन हजारों का अनुमान है। वित्तीय फ़िशिंग साइटों पर लगभग 10-15% आगंतुक अपना डेटा स्वयं दर्ज करते हैं।
जब कोई फ़िशिंग पृष्ठ दिखाई देता है, तो बिल घंटों और कभी-कभी मिनटों के लिए भी चला जाता है, क्योंकि उपयोगकर्ता गंभीर वित्तीय खर्च करते हैं, और कंपनियों के मामले में, साथ ही साथ प्रतिष्ठित क्षति भी। उदाहरण के लिए, कुछ सफल फ़िशिंग पृष्ठ एक दिन से भी कम समय के लिए उपलब्ध थे, लेकिन 1,000,000 रूबल से राशियों को नुकसान पहुंचाने में सक्षम थे।
इस लेख में, हम पहले प्रकार के फ़िशिंग: फ़िशिंग साइटों पर ध्यान केन्द्रित करेंगे। फ़िशिंग के "संदिग्ध" होने वाले संसाधनों को विभिन्न तकनीकी साधनों का उपयोग करके आसानी से पता लगाया जा सकता है: हनीपोट्स, क्रॉलर, आदि, हालांकि, यह सुनिश्चित करना समस्याग्रस्त है कि वे वास्तव में फ़िशिंग हैं और हमला किए गए ब्रांड की पहचान करना है। आइए जानें कि इस समस्या को कैसे हल किया जाए।
पकड़ने fishey
यदि कोई ब्रांड अपनी प्रतिष्ठा की निगरानी नहीं करता है, तो यह एक आसान लक्ष्य बन जाता है। अपराधियों से अपनी नकली साइटों को पंजीकृत करने के तुरंत बाद पहल को जब्त करना आवश्यक है। व्यवहार में, फ़िशिंग पृष्ठ की खोज को 4 चरणों में विभाजित किया गया है:
- फ़िशिंग स्कैन (क्रॉलर, हनीपोट्स, आदि) के लिए कई संदिग्ध पतों (URL) का गठन।
- कई फ़िशिंग पतों का गठन।
- गतिविधि के क्षेत्र द्वारा पहले से ही पहचाने गए फ़िशिंग पतों का वर्गीकरण और प्रौद्योगिकी पर हमला, उदाहरण के लिए, "RBS :: Sberbank Online" या "RBS :: Alfa-Bank"।
- दाता पृष्ठ के लिए खोजें।
पैराग्राफ 2 और 3 का कार्यान्वयन डेटा साइंस के विशेषज्ञों के कंधों पर पड़ता है।
उसके बाद, आप फ़िशिंग पेज को ब्लॉक करने के लिए पहले से ही सक्रिय कदम उठा सकते हैं। विशेष रूप से:
- हमारे भागीदारों के समूह-आईबी उत्पादों और उत्पादों को ब्लैकलिस्ट करें;
- फ़िशिंग URL को हटाने के अनुरोध के साथ डोमेन ज़ोन के मालिक को स्वचालित रूप से या मैन्युअल रूप से पत्र भेजें;
- हमला किए गए ब्रांड की सुरक्षा सेवा को पत्र भेजें;
- आदि

HTML विश्लेषण के तरीके
संदिग्ध फ़िशिंग पतों की जांच करने और एक प्रभावित ब्रांड को स्वचालित रूप से पहचानने के कार्यों का क्लासिक समाधान HTML स्रोत पृष्ठों को पार्स करने के विभिन्न तरीके हैं। सबसे सरल बात नियमित अभिव्यक्ति लिख रही है। यह मजेदार है, लेकिन यह चाल अभी भी काम करती है। और आज, अधिकांश नौसिखिए फिशर केवल मूल साइट से सामग्री की प्रतिलिपि बनाते हैं।
इसके अलावा, बहुत प्रभावी एंटी-फ़िशिंग सिस्टम फ़िशिंग किट शोधकर्ताओं द्वारा विकसित किए जा सकते हैं। लेकिन इस मामले में, आपको HTML पृष्ठ की जांच करने की आवश्यकता है। इसके अलावा, ये समाधान सार्वभौमिक नहीं हैं - उनके विकास के लिए खुद "व्हेल" के आधार की आवश्यकता होती है। कुछ फ़िशिंग किट शोधकर्ता को ज्ञात नहीं हो सकती हैं। और, ज़ाहिर है, प्रत्येक नए "व्हेल" का विश्लेषण एक बल्कि श्रमसाध्य और महंगी प्रक्रिया है।
एचटीएमएल पेज विश्लेषण के आधार पर सभी फ़िशिंग डिटेक्शन सिस्टम HTML ओफ़्फ़ैक्शन के बाद काम करना बंद कर देते हैं। और कई मामलों में यह केवल HTML पृष्ठ के फ्रेम को बदलने के लिए पर्याप्त है।
ग्रुप-आईबी के अनुसार, इस समय ऐसी फ़िशिंग साइटों का 10% से अधिक नहीं है, लेकिन यहां तक कि लापता व्यक्ति को पीड़ित को बहुत अधिक खर्च करना पड़ सकता है।
इस प्रकार, लॉक को बायपास करने के लिए एक फ़िशर के लिए, यह केवल HTML फ्रेमवर्क को बदलने के लिए पर्याप्त है, कम बार - एचटीएमएल पृष्ठ को बाधित करने के लिए (मार्कअप और / या जेएस के माध्यम से सामग्री को लोड करने के लिए)।
समस्या का बयान। संसाधन आधारित विधि
फ़िशिंग पृष्ठों का पता लगाने के लिए उपयोग किए जाने वाले संसाधनों के विश्लेषण के आधार पर तरीके बहुत अधिक प्रभावी और सार्वभौमिक हैं। एक संसाधन वह फ़ाइल है जिसे वेब पेज (सभी चित्र, कैस्केडिंग स्टाइल शीट (सीएसएस), जेएस फाइलें, फोंट, आदि) प्रदान करते समय अपलोड किया जाता है।
इस मामले में, आप एक द्विदलीय ग्राफ बना सकते हैं, जहां कुछ कोने फ़िशिंग के संदेह वाले पते होंगे, जबकि अन्य उनके साथ जुड़े संसाधन होंगे।
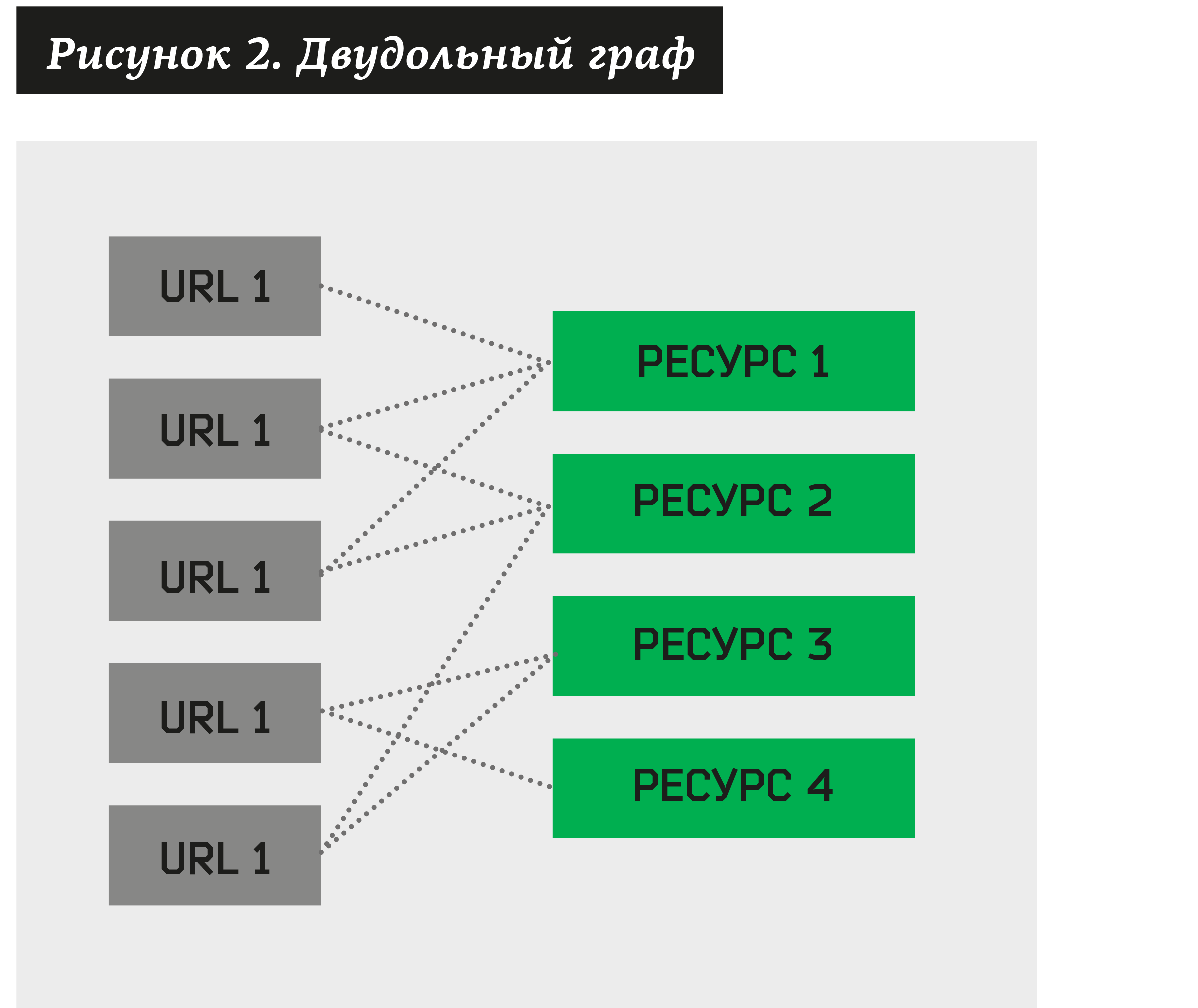
क्लस्टरिंग का कार्य उठता है - ऐसे संसाधनों का एक संग्रह खोजने के लिए जो विभिन्न URL की एक बड़ी संख्या के मालिक हैं। इस तरह के एक एल्गोरिथ्म का निर्माण करके, हम किसी भी द्विदलीय ग्राफ को समूहों में विघटित कर सकते हैं।
परिकल्पना वह है, जो वास्तविक डेटा पर आधारित है, काफी हद तक संभावना के साथ यह कहा जा सकता है कि क्लस्टर में URL का संग्रह है जो एक ही ब्रांड से संबंधित है और एक फ़िशिंग किट द्वारा उत्पन्न होता है। फिर, इस परिकल्पना का परीक्षण करने के लिए, प्रत्येक ऐसे क्लस्टर को CERT (सूचना सुरक्षा हादसा प्रतिक्रिया केंद्र) को मैन्युअल सत्यापन के लिए भेजा जा सकता है। विश्लेषक, बदले में, क्लस्टर की स्थिति देगा: +1 ("स्वीकृत") या -1 (अस्वीकृत)। एक विश्लेषक सभी अनुमोदित क्लस्टरों पर एक अटैक किए गए ब्रांड को भी असाइन करेगा। यह "मैनुअल काम" समाप्त होता है - बाकी प्रक्रिया स्वचालित है। औसतन, एक समूह ने 152 फ़िशिंग पतों (जून 2018 के अनुसार डेटा) के लिए एक अनुमोदित समूह खातों, और कभी-कभी 500-1000 पतों के समूहों को पार किया है! विश्लेषक क्लस्टर को मंजूरी देने या खंडन करने के लिए लगभग 1 मिनट खर्च करता है।
फिर, सभी खारिज किए गए क्लस्टर सिस्टम से हटा दिए जाते हैं, और थोड़ी देर के बाद उनके सभी पते और संसाधन फिर से क्लस्टर एल्गोरिथ्म के इनपुट को खिलाए जाते हैं। नतीजतन, हमें नए क्लस्टर मिलते हैं। और फिर से हम उन्हें सत्यापन आदि के लिए भेजते हैं।
इस प्रकार, प्रत्येक नए प्राप्त पते के लिए, सिस्टम को निम्नलिखित करना चाहिए:
- साइट के लिए कई संसाधन निकालें।
- कम से कम एक पहले से स्वीकृत क्लस्टर के लिए जाँच करें।
- यदि URL किसी भी क्लस्टर से संबंधित है, तो स्वचालित रूप से ब्रांड नाम निकालें और इसके लिए एक क्रिया करें (ग्राहक को सूचित करें, संसाधन हटाएं, आदि)।
- यदि कोई क्लस्टर संसाधनों के लिए असाइन नहीं किया जा सकता है, तो पते और संसाधनों को द्विदलीय ग्राफ में जोड़ें। भविष्य में, यह URL और संसाधन नए समूहों के गठन में भाग लेंगे।
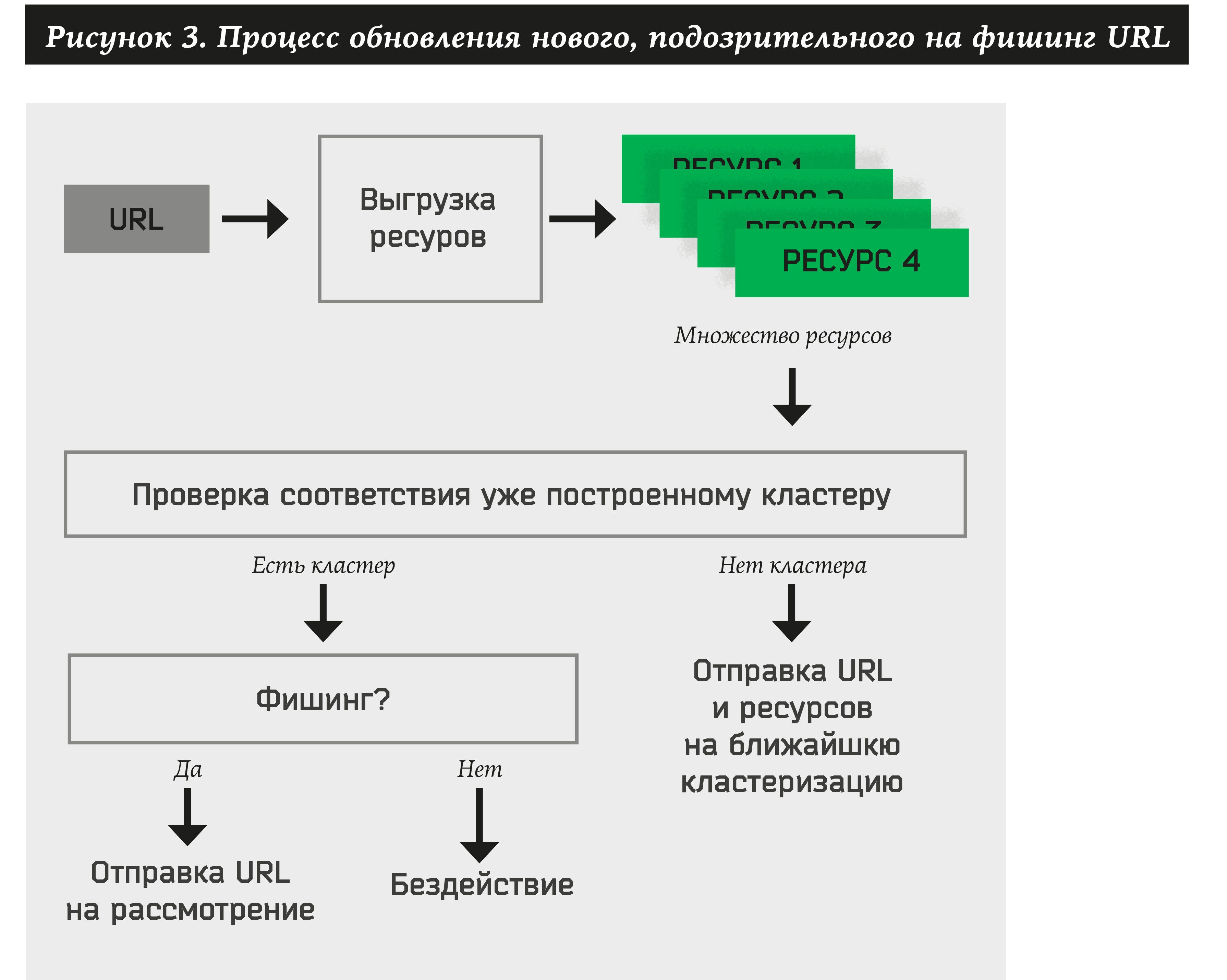
सरल संसाधन क्लस्टरिंग एल्गोरिथम
सबसे महत्वपूर्ण बारीकियों में से एक है कि सूचना सुरक्षा में एक डेटा विज्ञान विशेषज्ञ को ध्यान में रखना चाहिए तथ्य यह है कि एक व्यक्ति उसका प्रतिद्वंद्वी है। इस कारण से, विश्लेषण के लिए स्थितियां और डेटा बहुत जल्दी बदल जाते हैं! एक समाधान जो 2-3 महीने बाद उल्लेखनीय रूप से समस्या को ठीक करता है, सिद्धांत रूप में काम करना बंद कर सकता है। इसलिए, यदि संभव हो तो सार्वभौमिक (अनाड़ी) तंत्र या तो बनाना महत्वपूर्ण है, या सबसे अधिक लचीली प्रणाली जो जल्दी विकसित हो सकती है। सूचना सुरक्षा में डेटा विज्ञान विशेषज्ञ एक बार और सभी के लिए समस्या का समाधान नहीं कर सकता है।
बड़ी संख्या में सुविधाओं के कारण मानक क्लस्टरिंग विधियां काम नहीं करती हैं। प्रत्येक संसाधन को बूलियन विशेषता के रूप में दर्शाया जा सकता है। हालांकि, व्यवहार में, हम प्रतिदिन 5,000 वेबसाइट पते से प्राप्त करते हैं, और उनमें से प्रत्येक में औसतन 17.2 संसाधन (जून 2018 के लिए डेटा) हैं। आयामीता का अभिशाप डेटा को मेमोरी में लोड करने की अनुमति नहीं देता है, बहुत कम किसी भी क्लस्टरिंग एल्गोरिदम का निर्माण करता है।
एक अन्य विचार विभिन्न सहयोगी फ़िल्टरिंग एल्गोरिदम का उपयोग करके समूहों में क्लस्टर करने का प्रयास करना है। इस मामले में, एक और विशेषता बनाने के लिए आवश्यक था - किसी विशेष ब्रांड से संबंधित। कार्य इस तथ्य पर कम हो जाएगा कि सिस्टम को शेष URL के लिए इस संकेत की उपस्थिति या अनुपस्थिति की भविष्यवाणी करनी चाहिए। विधि ने सकारात्मक परिणाम दिए, लेकिन दो कमियां थीं:
- प्रत्येक ब्रांड के लिए सहयोगी फ़िल्टरिंग के लिए अपनी विशेषता बनाना आवश्यक था;
- प्रशिक्षण नमूने की आवश्यकता है।
हाल ही में, अधिक से अधिक कंपनियां इंटरनेट पर अपने ब्रांड की रक्षा करना चाहती हैं और फ़िशिंग साइटों का पता लगाने को स्वचालित करने के लिए कह रही हैं। संरक्षण में लिया गया प्रत्येक नया ब्रांड एक नई विशेषता जोड़ देगा। और प्रत्येक नए ब्रांड के लिए एक प्रशिक्षण नमूना बनाने के लिए एक अतिरिक्त मैनुअल काम और समय है।
हमने इस समस्या का हल ढूंढना शुरू किया। और उन्हें एक बहुत ही सरल और प्रभावी तरीका मिला।
शुरू करने के लिए, हम निम्नलिखित एल्गोरिथ्म का उपयोग करके संसाधन जोड़े बनाएंगे:
- सभी प्रकार के संसाधनों को लें (हम उन्हें निरूपित करते हैं a) जिसके लिए कम से कम N1 पते हैं, हम इस संबंध को # (a)। N1 के रूप में दर्शाते हैं।
- हम सभी प्रकार के संसाधन जोड़े (a1, a2) बनाते हैं और केवल उन्हीं का चयन करते हैं जिनके लिए कम से कम N2 पते होंगे, अर्थात। # (ए 1, ए 2) a एन 2।
फिर हम इसी तरह के जोड़े पर विचार करते हैं जिसमें पिछले पैराग्राफ में प्राप्त जोड़े हैं। परिणामस्वरूप, हमें चार मिलते हैं: (a1, a2) + (a3, a4) → (a1, a2, a3, a4)। इसके अलावा, अगर कम से कम एक तत्व जोड़े में से एक में मौजूद है, तो चौकों के बजाय हमें त्रिक मिलते हैं: (ए, ए 2) + (ए, ए 3) → (ए 1, ए 2, ए 3)। परिणामी सेट में से, हम केवल उन चार और त्रिगुणों को छोड़ते हैं जो कम से कम N3 पते के अनुरूप हैं। और इसी तरह…
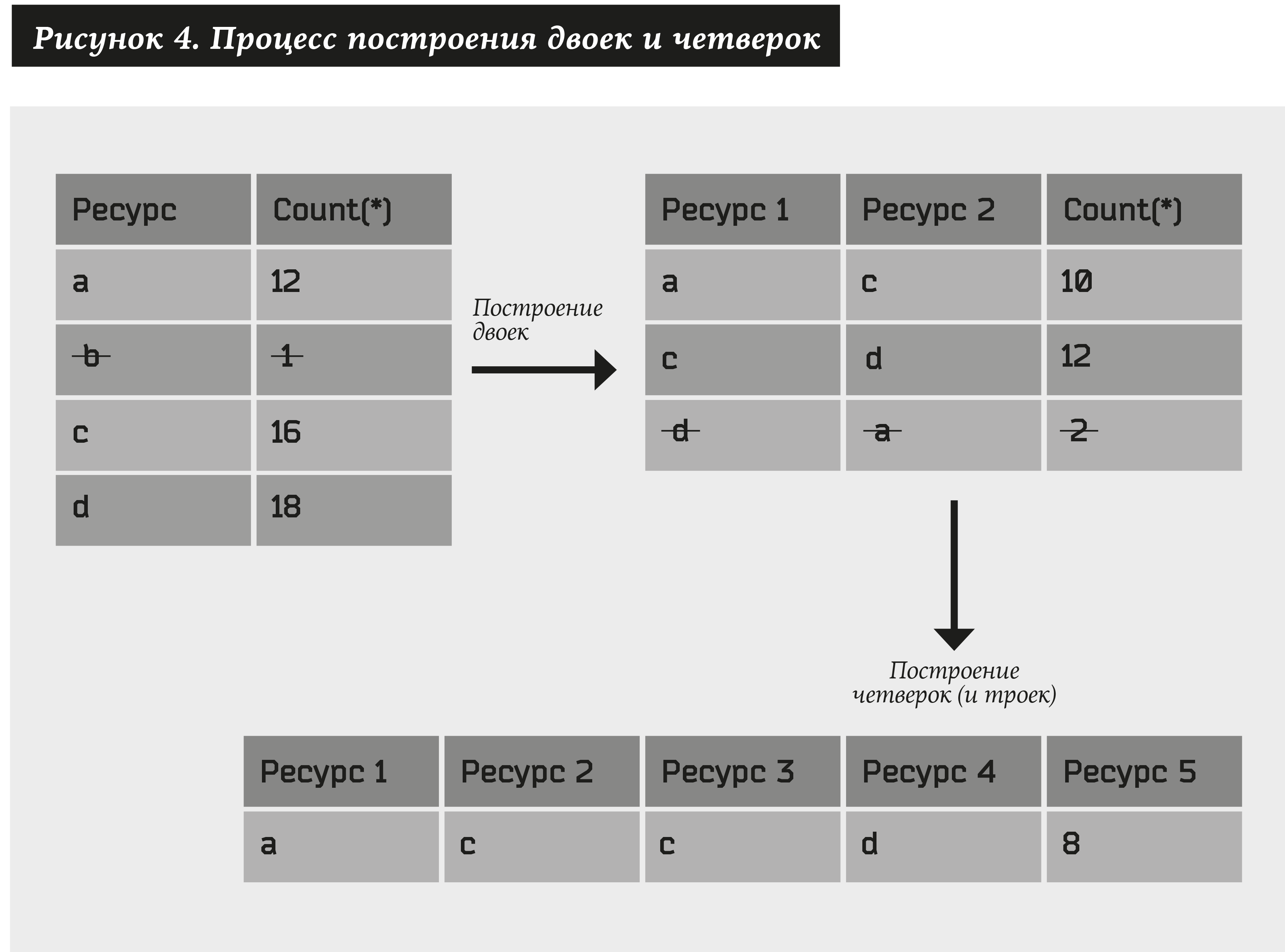
आप मनमानी लंबाई के कई संसाधन प्राप्त कर सकते हैं। U. N1, N2 ... NU के चरणों की संख्या को सीमित करें सिस्टम पैरामीटर।
मान N1, N2 ... NU एल्गोरिथ्म के पैरामीटर हैं, वे मैन्युअल रूप से सेट किए गए हैं। सामान्य मामले में, हमारे पास CL2 अलग-अलग जोड़े हैं, जहां एल संसाधनों की संख्या है, अर्थात। जोड़े बनाने की कठिनाई O (L2) होगी। फिर प्रत्येक जोड़ी से एक क्वाड बनाया जाता है। और सिद्धांत रूप में, हमें संभवतः O (L4) मिलता है। हालांकि, व्यवहार में, इस तरह के जोड़े बहुत छोटे होते हैं, और बड़ी संख्या में पते के साथ, O (L2log L) निर्भरता को अनुभवपूर्वक प्राप्त किया गया था। इसके अलावा, बाद के कदम (चौकों में मुड़, चौगुनी आठवें में, आदि) नगण्य हैं।
यह ध्यान दिया जाना चाहिए कि एल गैर-संकुल URL की संख्या है। सभी URL जिन्हें पहले से ही स्वीकृत किसी क्लस्टर के लिए जिम्मेदार ठहराया जा सकता है, वे क्लस्टरिंग के लिए चयन में नहीं आते हैं।
आउटपुट पर, आप संसाधनों के सबसे बड़े संभावित सेटों से मिलकर कई क्लस्टर बना सकते हैं। उदाहरण के लिए, यदि कोई मौजूद है (a1, a2, a4, a5) नी की सीमाओं को संतुष्ट करता है, तो एक को क्लस्टर (a1, a2, a3) और a4 (a5) के सेट से हटा देना चाहिए।
फिर, प्रत्येक प्राप्त क्लस्टर को मैनुअल सत्यापन के लिए भेजा जाता है, जहां सीईआरटी विश्लेषक इसे स्थिति प्रदान करता है: +1 ("अनुमोदित") या -1 ("अस्वीकृत"), और यह भी इंगित करता है कि क्लस्टर में आने वाले URL फ़िशिंग या वैध साइट हैं या नहीं।
जब आप एक नया संसाधन जोड़ते हैं, तो URL की संख्या कम हो सकती है, वही रहें, लेकिन कभी भी न बढ़ें। इसलिए, किसी भी संसाधन के लिए a1 ... a संबंध साकार है:
# (a1) (# (a1, a2) a # (a1, a2, a3) ≥ ... ≥ # (a1, a2, ..., aN)।
इसलिए, मापदंडों को निर्धारित करना बुद्धिमानी है:
एन 1 ≥ एन 2 3 एन 3 ≥ ...। एनयू।
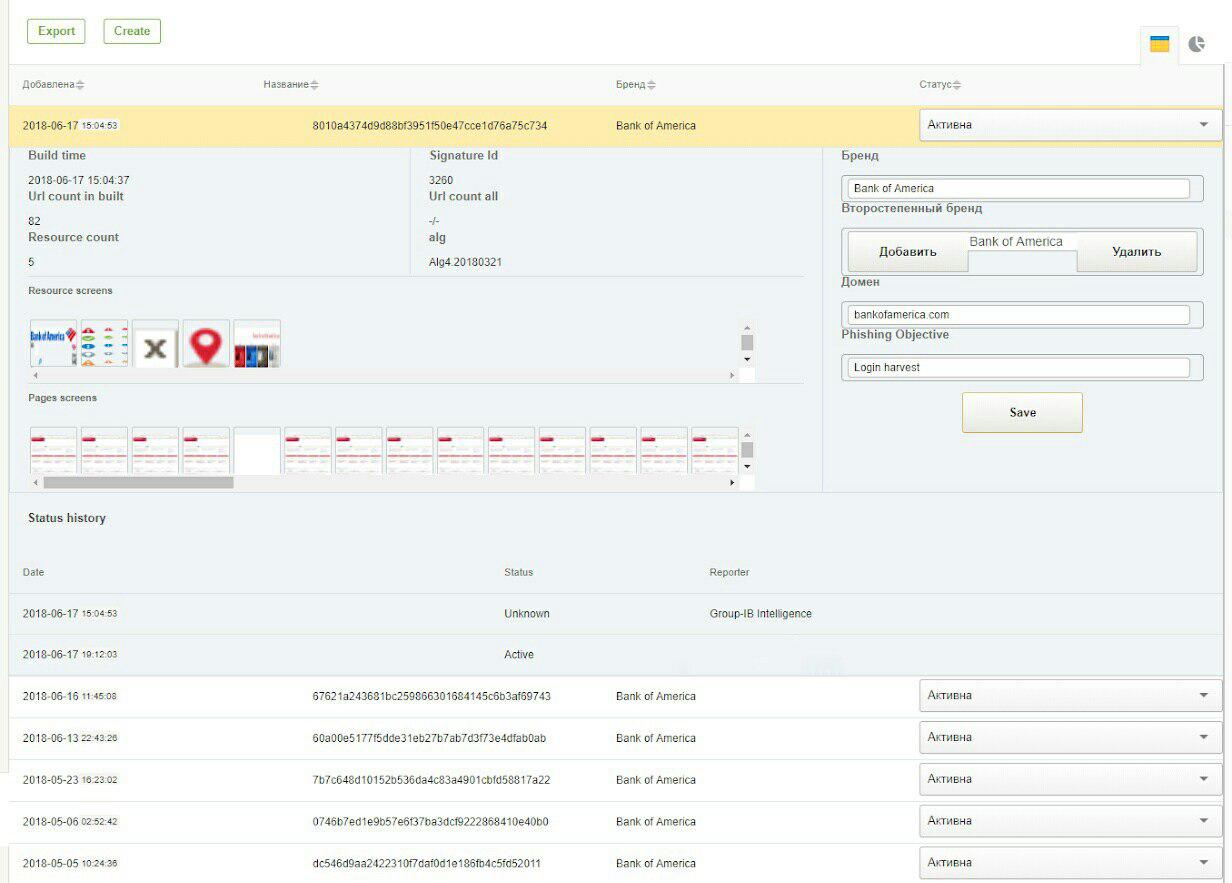
आउटपुट पर, हम सत्यापन के लिए सभी प्रकार के समूह देते हैं। अंजीर में। लेख की शुरुआत में 1 वास्तविक क्लस्टर प्रस्तुत करता है जिसके लिए सभी संसाधन चित्र हैं।
व्यवहार में एल्गोरिथ्म का उपयोग करना
ध्यान दें कि अब आपको फ़िशिंग किट का पता लगाने की आवश्यकता नहीं है! सिस्टम स्वचालित रूप से क्लस्टर करता है और आवश्यक फ़िशिंग पृष्ठ पाता है।
हर दिन, सिस्टम 5,000 फ़िशिंग पृष्ठों से प्राप्त करता है और प्रति दिन कुल 3 से 25 नए क्लस्टर बनाता है। प्रत्येक क्लस्टर के लिए, संसाधनों की एक सूची अपलोड की जाती है, कई स्क्रीनशॉट बनाए जाते हैं। यह क्लस्टर पुष्टि या खंडन के लिए CERT एनालिटिक्स को भेजा जाता है।
स्टार्टअप पर, एल्गोरिथ्म की सटीकता कम थी - केवल 5%। हालांकि, 3 महीने के बाद, सिस्टम ने 50 से 85% तक सटीकता रखी। वास्तव में, सटीकता मायने नहीं रखती है! मुख्य बात यह है कि विश्लेषकों के पास समूहों को देखने का समय है। इसलिए, यदि सिस्टम, उदाहरण के लिए, प्रति दिन लगभग 10,000 क्लस्टर उत्पन्न करता है और आपके पास केवल एक विश्लेषक है, तो आपको सिस्टम मापदंडों को बदलना होगा। यदि प्रति दिन 200 से अधिक नहीं, तो यह एक व्यक्ति के लिए संभव है। जैसा कि अभ्यास से पता चलता है, औसतन दृश्य विश्लेषण में लगभग 1 मिनट लगता है।
प्रणाली की पूर्णता लगभग 82% है। शेष 18% या तो फ़िशिंग के अनूठे मामले हैं (इसलिए, उन्हें समूहीकृत नहीं किया जा सकता है), या फ़िशिंग, जिसके पास संसाधनों की एक छोटी राशि है (समूह द्वारा कुछ भी नहीं है), या फ़िशिंग पृष्ठ जो पैरामीटर N1, N2 ... NU की सीमाओं से परे चले गए।
एक महत्वपूर्ण बिंदु: कितनी बार ताजे, अपरिवर्तित URL पर एक नया क्लस्टर शुरू करना है? हम हर 15 मिनट में ऐसा करते हैं। इसके अलावा, डेटा की मात्रा के आधार पर, क्लस्टरिंग समय में 10-15 मिनट लगते हैं। इसका मतलब यह है कि फ़िशिंग URL की उपस्थिति के बाद 30 मिनट के समय में अंतराल है।
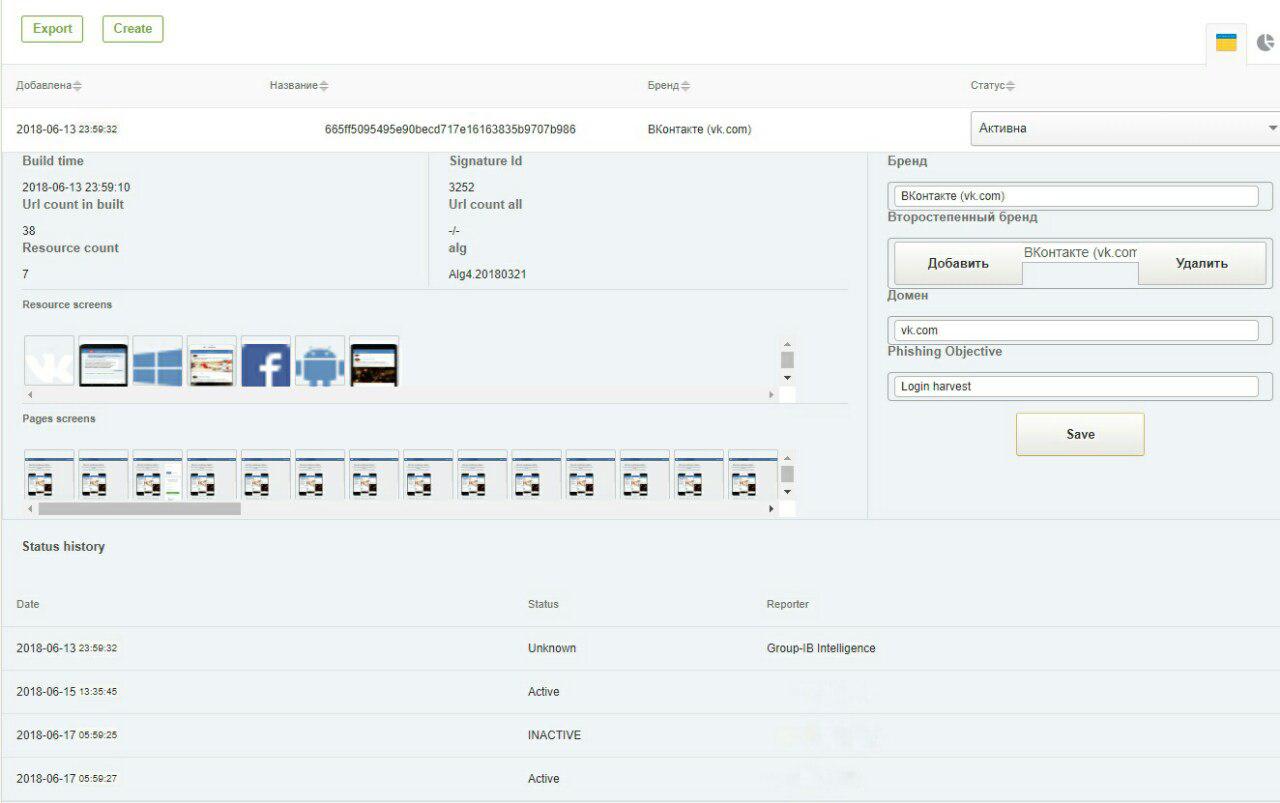
नीचे GUI सिस्टम से 2 स्क्रीनशॉट हैं: VKontakte और बैंक ऑफ अमेरिका सोशल नेटवर्क पर फ़िशिंग का पता लगाने के लिए हस्ताक्षर।
जब एल्गोरिथ्म काम नहीं करता है
जैसा कि ऊपर उल्लेख किया गया है, एल्गोरिथ्म सिद्धांत रूप में काम नहीं करता है यदि पैरामीटर एन 1, एन 2, एन 3 ... एनयू द्वारा निर्दिष्ट सीमाएं नहीं पहुंचती हैं, या आवश्यक क्लस्टर बनाने के लिए संसाधनों की संख्या बहुत कम है।
एक फ़िशर प्रत्येक फ़िशिंग साइट के लिए अद्वितीय संसाधन बनाकर एल्गोरिथ्म को बायपास कर सकता है। उदाहरण के लिए, प्रत्येक छवि में आप एक पिक्सेल को बदल सकते हैं, और लोड किए गए जेएस और सीएसएस पुस्तकालयों में आपत्ति का उपयोग करते हैं। इस मामले में, प्रत्येक प्रकार के लोड किए गए दस्तावेज़ों के लिए एक तुलनीय हैश एल्गोरिथम (अवधारणात्मक हैश) विकसित करना आवश्यक है। हालाँकि, ये समस्याएँ इस आलेख के दायरे से परे हैं।
यह सब एक साथ रखना
हम अपने मॉड्यूल को क्लासिक HTML रेग्युलर, थ्रेट इंटेलिजेंस (साइबर इंटेलिजेंस सिस्टम) से प्राप्त डेटा से जोड़ते हैं, और हमें 99.4% की पूर्णता मिलती है। बेशक, यह डेटा पर पूर्णता है जो पहले से ही थ्रेट इंटेलिजेंस द्वारा फ़िशिंग संदिग्ध के रूप में वर्गीकृत किया गया है।
सभी संभावित डेटा की पूर्णता को कोई नहीं जानता है, क्योंकि सिद्धांत में पूरे डार्कनेट को कवर करना असंभव है, हालांकि, गार्टनर, आईडीसी और फॉरेस्टर रिपोर्टों के अनुसार, ग्रुप-आईबी अपनी क्षमताओं में थ्रेट इंटेलिजेंस समाधान के प्रमुख अंतरराष्ट्रीय प्रदाताओं में से एक है।
अवर्गीकृत फ़िशिंग पृष्ठों के बारे में क्या? एक दिन में लगभग 25-50। उन्हें मैन्युअल रूप से जांचा जा सकता है। कुल मिलाकर, किसी भी कार्य में हमेशा मैनुअल श्रम होता है जो सूचना सुरक्षा के क्षेत्र में डेटा विज्ञान के लिए काफी मुश्किल है, और 100 प्रतिशत स्वचालन के किसी भी आरोप एक विपणन कल्पना है। डेटा वैज्ञानिक विशेषज्ञ का कार्य परिमाण के 2–3 आदेशों द्वारा मैन्युअल श्रम को कम करना है, जिससे विश्लेषक का कार्य यथासंभव प्रभावी हो सके।
JETINFO पर प्रकाशित लेख