एक साल पहले, हमने अपने एजेंट को क्लाइंट सर्वर पर स्मार्ट डिस्क विशेषताओं से मैट्रिक्स का एक संग्रह जोड़ा। उस समय, हमने उन्हें इंटरफ़ेस में नहीं जोड़ा और उन्हें ग्राहकों को दिखाया। तथ्य यह है कि हम मैट्रिक्स को स्मार्टक्टेल के माध्यम से नहीं लेते हैं, लेकिन हम कोड से सीधे ioctl खींचते हैं ताकि क्लाइंट सर्वर पर स्मार्टमोनटूल स्थापित किए बिना यह कार्यक्षमता काम करे।
एजेंट सभी उपलब्ध विशेषताओं को नहीं हटाता है, लेकिन केवल हमारी राय में सबसे महत्वपूर्ण है और कम से कम विक्रेता-विशिष्ट वाले (अन्यथा, आपको स्मार्टमोनोलस के समान डिस्क आधार बनाए रखना होगा)।
अब, हाथ अंततः इस बात की जाँच करने के लिए पहुँच गए हैं कि हमने वहाँ क्या फिल्माया है। और यह विशेषता "मीडिया वियरआउट संकेतक" के साथ शुरू करने का निर्णय लिया गया था, जो शेष एसएसडी रिकॉर्डिंग संसाधन का प्रतिशत दर्शाता है। कटौती के तहत चित्रों में कुछ कहानियों के बारे में कि कैसे यह संसाधन वास्तविक जीवन में सर्वर पर खर्च किया जाता है।
क्या कोई मारे गए एसएसडी हैं?
यह माना जाता है कि पुराने की तुलना में नए, अधिक उत्पादक ssds अधिक बार जारी किए जाते हैं जो मारे जाने के लिए प्रबंधन करते हैं। इसलिए, पहली बात यह है कि रिकॉर्डिंग संसाधन डिस्क के संदर्भ में सबसे अधिक मारे गए को देखना दिलचस्प था। सभी ग्राहकों के सभी ssd के लिए न्यूनतम मूल्य 1% है।
हमने तुरंत इस बारे में क्लाइंट को लिखा, यह हेटनर में एक डेडिक निकला। होस्टिंग समर्थन तुरंत ssd की जगह:

यह देखना बहुत दिलचस्प होगा कि ऑपरेटिंग सिस्टम के दृष्टिकोण से स्थिति कैसी दिखती है जब ssd एक रिकॉर्ड सर्विसिंग बंद कर देता है (हम अब इस तरह के मैट्रिक्स को देखने के लिए जानबूझकर नकली sdd का अवसर तलाश रहे हैं :)
एसएसडी कितनी तेजी से मारे जाते हैं?
चूंकि हमने एक साल पहले मेट्रिक्स इकट्ठा करना शुरू कर दिया था, और हम मेट्रिक्स नहीं हटा रहे हैं, इसलिए समय पर इस मीट्रिक को देखना संभव है। दुर्भाग्य से, उच्चतम प्रवाह दर वाला सर्वर केवल 2 महीने पहले ओकेमीटर से जुड़ा था।

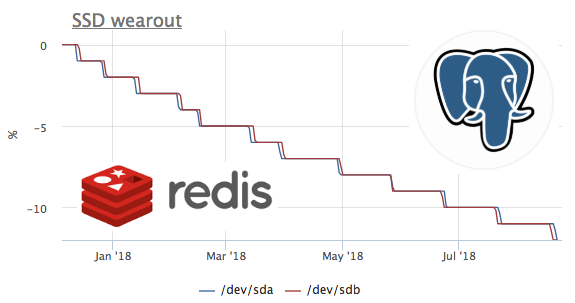
इस ग्राफ़ में, हम देखते हैं कि कैसे 2 महीने में उन्होंने 8% रिकॉर्डिंग संसाधन को जला दिया। यही है, एक ही रिकॉर्डिंग प्रोफ़ाइल के साथ, ये ssd 100 / (8/2) = 25 महीने के लिए पर्याप्त होगा। मुझे बहुत कम या कुछ पता नहीं है, लेकिन देखते हैं कि वहाँ किस तरह का भार है?

हम देखते हैं कि केवल ceph डिस्क के साथ काम करता है, लेकिन हम समझते हैं कि ceph केवल एक परत है। इस मामले में, ceph क्लाइंट कई नोड्स पर kubernetes क्लस्टर के लिए एक भंडार के रूप में कार्य करता है, देखते हैं कि k8s के अंदर क्या सबसे डिस्क लिखता है:

पूर्ण मान इस तथ्य के कारण सबसे अधिक संभावना से मेल नहीं खाता है कि सीफ़एच क्लस्टर में काम कर रहा है और डेटा प्रतिकृति के कारण रेडिस से रिकॉर्ड बढ़ रहा है। लेकिन लोड प्रोफ़ाइल आपको आत्मविश्वास से यह कहने की अनुमति देता है कि रिकॉर्ड बिल्कुल रेडिस शुरू करता है। आइए देखें कि मूली पर क्या होता है:

यहां आप देख सकते हैं कि औसतन प्रति सेकंड 100 से कम अनुरोध निष्पादित किए जाते हैं, जो डेटा को बदल सकते हैं। याद रखें कि रेडिस में डिस्क पर डेटा लिखने के 2 तरीके हैं :
- RDB - डिस्क पर पूरे डेटाबेस के आवधिक स्नैपशॉट, जब रेडिस शुरू करते हैं, तो हम अंतिम डंप को मेमोरी में पढ़ते हैं, और हम डंप के बीच डेटा खो देते हैं
- AOF - हम सभी परिवर्तनों का एक लॉग लिखते हैं, शुरुआत में रेडिस इस लॉग को खो देता है और सभी डेटा मेमोरी में प्रकट होता है, हम केवल इस लॉग के fsync के बीच डेटा खो देते हैं
जैसा कि सभी को पहले से ही इस मामले में अनुमान है, RDB का उपयोग 1 मिनट की डंप आवृत्ति के साथ किया जाता है:

SSD + RAID
हमारी टिप्पणियों के अनुसार, एसएसडी की उपस्थिति के साथ सर्वरों के डिस्क सबसिस्टम के तीन मुख्य कॉन्फ़िगरेशन हैं:
- सर्वर में 2 SSD छापे -1 में एकत्र किया और सब कुछ वहाँ रहता है
- सर्वर में ssd से HDD + raid-10 है, यह आमतौर पर क्लासिक RDBMSs (सिस्टम, वाल और HDD पर डेटा का हिस्सा है, और एसएसडी पर पढ़ने के संदर्भ में सबसे डेटा) के लिए उपयोग किया जाता है
- सर्वर में एक फ्री-स्टैंडिंग SSD (JBOD) होता है, जिसे आमतौर पर nosql प्रकार के कैसेंड्रा के लिए उपयोग किया जाता है
अगर ssd को raid-1 में एकत्र किया जाता है, तो रिकॉर्डिंग दोनों डिस्क पर जाती है, इसलिए पहनने पर समान गति होती है:
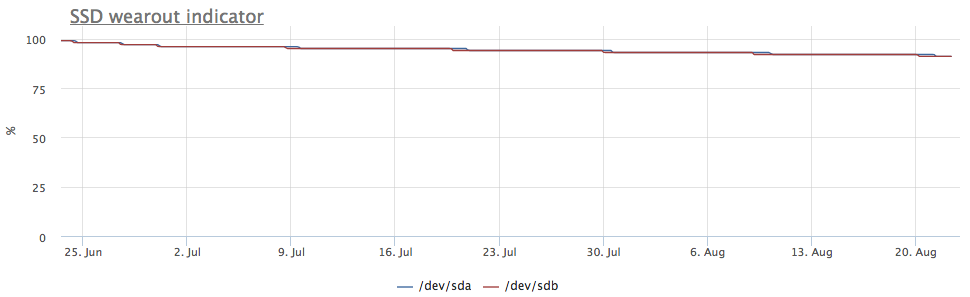
लेकिन सर्वर ने मेरी आंख को पकड़ लिया, जिसमें चित्र अलग है:

इस स्थिति में, केवल mdraid विभाजन माउंट किए जाते हैं (सभी छापे -1 सरणियाँ):

रिकॉर्डिंग मेट्रिक्स यह भी दिखाते हैं कि / dev / sda पर अधिक प्रविष्टियाँ हैं:

यह पता चला है कि / dev / sda पर विभाजन में से एक का उपयोग स्वैप के रूप में किया जाता है, और इस सर्वर पर i / o स्वैप काफी ध्यान देने योग्य है:

SSD और PostgreSQL का मूल्यह्रास
दरअसल, मैं Postgres में विभिन्न लेखन भार पर ssd पहनने की दर देखना चाहता था, लेकिन एक नियम के रूप में, वे लोड किए गए ssd डेटाबेस पर बहुत सावधानी से उपयोग किए जाते हैं और बड़े पैमाने पर रिकॉर्डिंग एचडीडी में जाती है। एक उपयुक्त मामले की खोज करते हुए, मैं एक बहुत ही रोचक सर्वर पर आया:

3 महीने के लिए छापे -1 में दो ssd का पहनना 4% था, लेकिन वाल रिकॉर्डिंग की गति को देखते हुए, यह पोस्टग्रास 100 Kb / s से कम लिखता है:
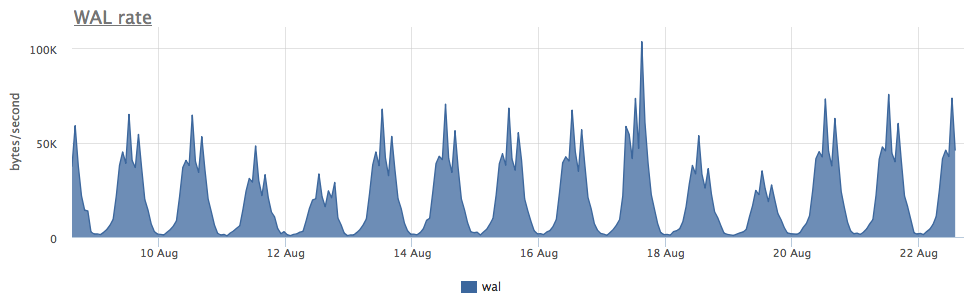
यह पता चला कि पोस्टग्रेज सक्रिय रूप से अस्थायी फ़ाइलों का उपयोग करता है, जिसके साथ काम करने से डिस्क में लेखन की एक निरंतर धारा बनती है:

चूंकि निदान के साथ postgresql बहुत अच्छा है, हम कर सकते हैं, अनुरोध तक, पता करें कि वास्तव में हमें क्या तय करना है:

जैसा कि आप यहां देख सकते हैं, यह विशेष रूप से सेलेक्ट अस्थायी फ़ाइलों का एक समूह बनाता है। सामान्य तौर पर, SELECT पोस्टग्रेट्स में, कभी-कभी वे बिना किसी अस्थायी फ़ाइलों के एक रिकॉर्ड बनाते हैं - यहाँ हमने पहले ही इस बारे में बात की है।
कुल मिलाकर
- Redis + RDB द्वारा डिस्क बनाने के लिए लिखने की मात्रा डेटाबेस में संशोधनों की संख्या पर निर्भर नहीं करती है, लेकिन डेटाबेस के आकार पर + डंप अंतराल (और सामान्य तौर पर, यह उन डेटा स्टोरों में लेखन प्रवर्धन का उच्चतम स्तर है जो मुझे पता है)
- Ssd पर सक्रिय रूप से उपयोग किया गया स्वैप खराब है, लेकिन यदि आपको sdd पहनने के लिए घिसने (छापे -1 विश्वसनीयता के लिए) को जोड़ने की आवश्यकता है, तो यह एक विकल्प हो सकता है :)
- वाल और डेटाफाइल्स के अलावा, डेटाबेस अभी भी डिस्क पर सभी प्रकार के अस्थायी डेटा लिख सकते हैं।
हम okmeter.io में मानते हैं कि समस्या के कारण की तह तक जाने के लिए, इंजीनियर को बुनियादी ढांचे की सभी परतों के बारे में बहुत सारे मेट्रिक्स की आवश्यकता होती है। हम मदद करने की पूरी कोशिश कर रहे हैं :)