
मैं एक छात्र के रूप में अपने कार्य केंद्र को इकट्ठा करने में सक्षम था। तार्किक रूप से पर्याप्त है, मैंने AMD कंप्यूटिंग समाधानों को प्राथमिकता दी। क्योंकि यह सस्ता कीमत / गुणवत्ता के मामले में लाभदायक। मैंने लंबे समय तक घटकों को उठाया, अंत में मुझे 40k के साथ एफएक्स -8320 और आरएक्स -656 जीबी का एक सेट मिला। पहले तो यह किट एकदम सही लग रही थी! मेरे रूममेट और मैंने थोड़ा सा मोनरो का खनन किया और मेरे सेट ने 650h / s बनाम 550h / s को i5-85xx और Nvidia 1050Ti के सेट पर दिखाया। सच है, कमरे में मेरे सेट से यह रात में थोड़ा गर्म था, लेकिन यह तब तय किया गया था जब मैंने सीपीयू के लिए एक टॉवर कूलर खरीदा था।
कहानी खत्म हो गई
सब कुछ एक परी कथा की तरह था, जब तक कि मैं कंप्यूटर दृष्टि के क्षेत्र में मशीन सीखने में दिलचस्पी नहीं ले लेता। इससे भी अधिक सटीक - जब तक कि मुझे 100x100px से अधिक के संकल्प के साथ इनपुट छवियों के साथ काम नहीं करना था (इस बिंदु तक, मेरा 8-कोर एफएक्स ब्रिस्ली कॉपी किया गया)। पहली कठिनाई भावनाओं को निर्धारित करने का कार्य था। प्रशिक्षण सेट में 4 ResNet लेयर, इनपुट इमेज 100x100 और 3000 इमेज। और अब - सीपीयू पर 150 घंटे के प्रशिक्षण के 9 घंटे।
बेशक, इस देरी के कारण, पुनरावृत्ति विकास प्रक्रिया ग्रस्त है। काम पर, हमारे पास Nvidia 1060 6GB और एक समान संरचना के लिए प्रशिक्षण था (हालांकि प्रतिगमन को वहां की वस्तुओं को स्थानीय बनाने के लिए प्रशिक्षित किया गया था), यह 3.5 मिनट के एक युग के लिए 15-20 मिनट - 8 सेकंड में उड़ गया। जब आपकी नाक के नीचे ऐसा कंट्रास्ट होता है, तो सांस लेना और भी मुश्किल हो जाता है।
खैर, यह सब के बाद मेरी पहली चाल का अनुमान है? हां, मैं अपने पड़ोसी के साथ 1050Ti सौदा करने गया था। एक अतिरिक्त शुल्क के लिए मेरे कार्ड का आदान-प्रदान करने की पेशकश के साथ, उसके लिए CUDA की बेकारता के बारे में तर्क के साथ। लेकिन सब व्यर्थ। और अब मैं अपने आरटीओ 460 को एविटो पर पोस्ट कर रहा हूं और सिटीलिंक और टेक्नोप्वाइंट की साइटों पर पोषित 1050 टीआई की समीक्षा कर रहा हूं। यहां तक कि कार्ड की सफल बिक्री की स्थिति में, मुझे एक और 10k ढूंढना होगा (मैं एक छात्र हूं, जो एक काम कर रहा है)।
गूगल
ठीक है। मैं Tensorflow के तहत Radeon का उपयोग करने के लिए Google पर जा रहा हूं। यह जानते हुए कि यह एक विदेशी काम था, मुझे कुछ भी समझदार होने की उम्मीद नहीं थी। उबंटू के तहत इकट्ठा करें, चाहे वह शुरू हो या न हो, एक ईंट प्राप्त करें - मंचों से छीनने वाले वाक्यांश।
और इसलिए मैं दूसरे तरीके से गया - मैंने Google Tensorflow AMD Radeon नहीं, बल्कि Keras AMD Radeon को चुना। यह तुरंत मुझे प्लेडएमएल के पेज पर ले जाता है । मैं इसे 15 मिनट में शुरू करता हूं (हालांकि मुझे केरस को 2.0.5 पर डाउनग्रेड करना पड़ा) और सीखने के लिए नेटवर्क सेट किया। पहला अवलोकन - युग 200 के बजाय 35 सेकंड है।
पता लगाने के लिए चढ़ो
प्लेएडएमएल के लेखक vertex.ai हैं, जो इंटेल परियोजना समूह (!) का हिस्सा है। विकास लक्ष्य अधिकतम क्रॉस-प्लेटफ़ॉर्म है। बेशक, यह उत्पाद में आत्मविश्वास जोड़ता है। उनके लेख में कहा गया है कि "पूरी तरह से अनुकूलन" के कारण प्लेडएमएल Tensorflow 1.3 + cuDNN 6 के साथ प्रतिस्पर्धी है।
हालाँकि, हम जारी रखते हैं। कुछ हद तक निम्नलिखित लेख से हमें पुस्तकालय की आंतरिक संरचना का पता चलता है। अन्य सभी रूपरेखाओं से मुख्य अंतर गणना कर्नेल की स्वचालित पीढ़ी है (टेन्सरफ्लो नोटेशन में, "कोर" एक ग्राफ में एक निश्चित ऑपरेशन करने की पूरी प्रक्रिया है)। प्लेएडएमएल में स्वचालित कर्नेल पीढ़ी के लिए, सभी टेंसरों, स्थिरांक, कदम, दृढ़ संकल्प आकार और सीमा मूल्यों के सटीक आयाम जिनके साथ आपको बाद में काम करना होगा, बहुत महत्वपूर्ण हैं। उदाहरण के लिए, यह तर्क दिया जाता है कि प्रभावी गुठली का निर्माण 1 और 32 बैचों के लिए या आकार 3x3 और 7x7 के संकल्पों के लिए अलग-अलग होता है। इस डेटा के होने के बाद, ढांचा ही विशिष्ट विशेषताओं के साथ किसी विशेष उपकरण के लिए सभी कार्यों को समानांतर और निष्पादित करने का सबसे कुशल तरीका उत्पन्न करेगा। यदि आप नए ऑपरेशन बनाते समय टेंसरफ़्लो को देखते हैं, तो हमें उनके लिए कर्नेल को भी लागू करने की आवश्यकता है - और कार्यान्वयन एकल-थ्रेडेड, बहु-थ्रेडेड या CUDA- संगत कर्नेल के लिए बहुत भिन्न हैं। यानी प्लेडएमएल स्पष्ट रूप से अधिक लचीला है।
हम और आगे बढ़ें। कार्यान्वयन स्व-लिखित भाषा टाइल में लिखा गया है। इस भाषा के निम्नलिखित मुख्य लाभ हैं - गणितीय संकेतन के लिए सिंटैक्स की निकटता (लेकिन पागल हो जाओ!)।
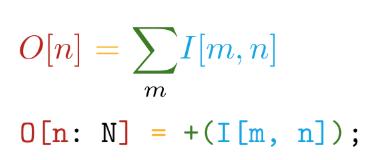
और सभी घोषित ऑपरेशनों के स्वचालित भेदभाव। उदाहरण के लिए, TensorFlow में, एक नया कस्टम ऑपरेशन बनाते समय, यह अत्यधिक अनुशंसा की जाती है कि आप ढ़ाल की गणना करने के लिए एक फ़ंक्शन लिखें। इस प्रकार, टाइल भाषा में अपने स्वयं के संचालन का निर्माण करते समय, हमें केवल यह कहने की आवश्यकता है कि हम हार्डवेयर उपकरणों के संबंध में इस पर विचार करने के लिए HOW के बारे में सोचने के बिना क्या गणना करना चाहते हैं।
इसके अतिरिक्त, DRAM के साथ काम का अनुकूलन और GPU में L1 कैश का एक एनालॉग प्रदर्शन किया जाता है। योजनाबद्ध डिवाइस को याद करें:
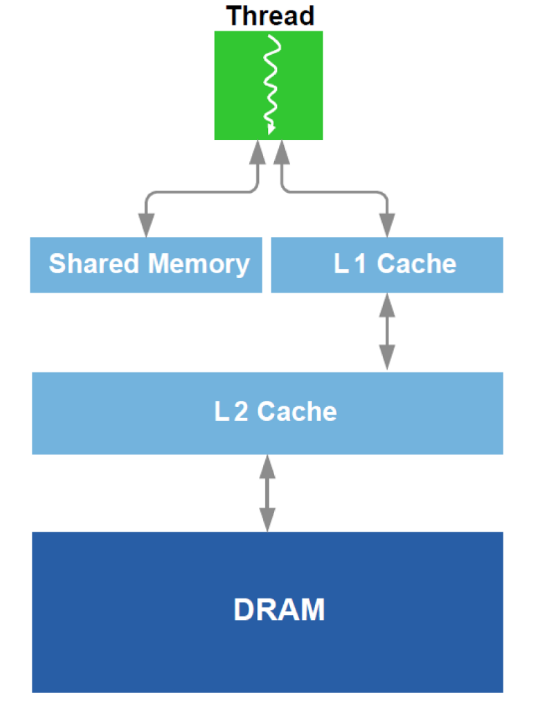
अनुकूलन के लिए, उपकरणों के बारे में सभी उपलब्ध डेटा का उपयोग किया जाता है - कैश आकार, कैश लाइन की चौड़ाई, डीआरएएम बैंडविड्थ, आदि। मुख्य विधियाँ डीआरएएम (विभिन्न क्षेत्रों को संबोधित करने से बचने का प्रयास) से बड़े पर्याप्त ब्लॉकों के एक साथ पढ़ने की सुविधा प्रदान कर रही हैं और यह प्राप्त कर रही हैं कि कैश में लोड किए गए डेटा का उपयोग कई बार किया जाता है (एक ही डेटा को कई बार लोड करने से बचने का प्रयास)।
प्रशिक्षण के पहले युग के दौरान सभी अनुकूलन होते हैं, जबकि पहले रन के समय में काफी वृद्धि होती है:
इसके अलावा, यह ध्यान देने योग्य है कि यह ढांचा ओपनसीएल से बंधा हुआ है। ओपनसीएल का मुख्य लाभ यह है कि यह विषम प्रणालियों के लिए एक मानक है और कुछ भी आपको सीपीयू पर कर्नेल को चलाने से रोकता है । हां, यह वह जगह है जहां क्रॉस-प्लेटफॉर्म प्लेडएमएल के मुख्य रहस्यों में से एक है।
निष्कर्ष
बेशक, आरएक्स 460 पर प्रशिक्षण 1060 की तुलना में अभी भी 5-6 गुना धीमा है, लेकिन आप वीडियो कार्ड की कीमत श्रेणियों की तुलना कर सकते हैं! तब मुझे एक आरएक्स 580 8 जीबी मिला (उन्होंने मुझे उधार दिया!) और युग को चलाने में लगने वाले समय को 20 सेकंड तक घटा दिया गया, जो लगभग तुलनीय है।
Vertex.ai ब्लॉग में ईमानदार ग्राफ हैं (अधिक बेहतर है):
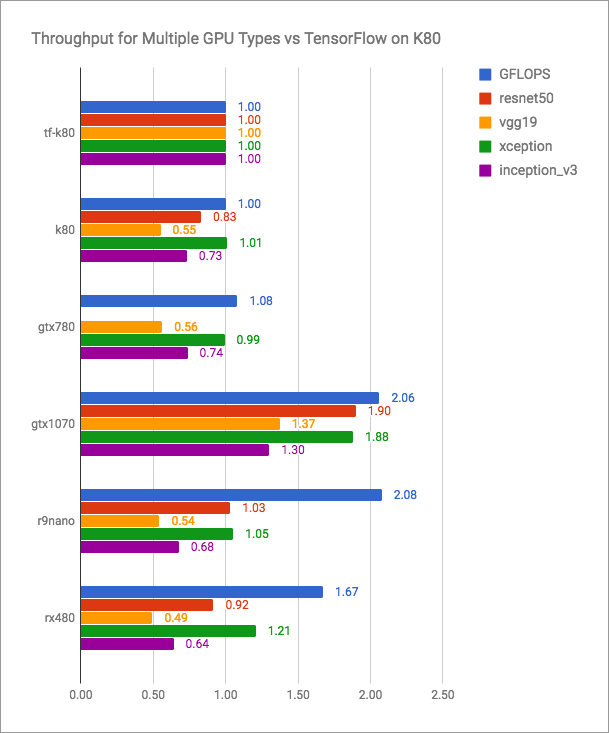
यह देखा जा सकता है कि प्लेएडएमएल Tensorflow + CUDA के साथ प्रतिस्पर्धी है, लेकिन निश्चित रूप से वर्तमान संस्करणों के लिए तेज़ नहीं है। लेकिन प्लेएडएमएल डेवलपर्स शायद ऐसी खुली लड़ाई में प्रवेश करने की योजना नहीं बनाते हैं। उनका लक्ष्य सार्वभौमिकता, क्रॉस-प्लेटफॉर्म है।
मैं अपने प्रदर्शन माप के साथ यहां एक बहुत तुलनात्मक तालिका नहीं छोड़ूंगा:
| कम्प्यूटिंग डिवाइस | युग का समय (बैच - 16), एस |
|---|
| AMD FX-8320 tf | 200 |
| RX 460 2GB प्लेड | 35 |
| RX 580 8 GB प्लेड | 20 |
| 1060 6GB TF | 8 |
| 1060 6GB प्लेड | 10 |
| इंटेल i7-2600 tf | 185 |
| इंटेल i7-2600 प्लेड | 240 |
| जीटी 640 प्लेड | 46 |
नवीनतम वर्टेक्स.आई ब्लॉग पोस्ट और रिपॉजिटरी के नवीनतम संस्करण मई 2018 दिनांकित हैं। ऐसा लगता है कि यदि इस उपकरण के डेवलपर्स नए संस्करणों को जारी करना बंद नहीं करते हैं और अधिक से अधिक लोग जो एनवीडिया से नाराज हैं, वे प्लेडएमएल से परिचित हैं, तो वे वर्टेक्स के बारे में बात करेंगे।
अपने radeons को उजागर!