हर दिन, उपयोगकर्ता लाखों ऑनलाइन गतिविधियाँ करते हैं। FACETz DMP परियोजना को इस डेटा की संरचना करने और उपयोगकर्ता की प्राथमिकताओं की पहचान करने के लिए इसे खंडित करने की आवश्यकता है। लेख में, हम इस बारे में बात करेंगे कि कैसे टीम ने 600 मिलियन लोगों के दर्शकों को विभाजित किया, प्रतिदिन 5 बिलियन की घटनाओं को संसाधित किया और काफ्का और HBase का उपयोग करके आँकड़ों के साथ काम किया।
यह सामग्री स्मार्टडाटा 2017 सम्मेलन से डायरेक्चुअल के एक बड़े डेटा विशेषज्ञ अर्टिओम मारिनोव की एक
रिपोर्ट के ट्रांसक्रिप्ट पर आधारित है।
मेरा नाम अर्टिओम मारिनोव है, मैं इस बारे में बात करना चाहता हूं कि जब हमने डेटा सेंट्रिक एलायंस में काम किया तो हमने FACETz DMP प्रोजेक्ट के आर्किटेक्चर को कैसे नया स्वरूप दिया। हमने ऐसा क्यों किया, इसके कारण क्या हुआ, हम किस रास्ते पर गए और हमें किन समस्याओं का सामना करना पड़ा।
डीएमपी (डेटा मैनेजमेंट प्लेटफॉर्म) उपयोगकर्ता डेटा एकत्र करने, प्रसंस्करण और एकत्र करने के लिए एक मंच है। डेटा बहुत सी अलग-अलग चीजें हैं। प्लेटफॉर्म के लगभग 600 मिलियन उपयोगकर्ता हैं। ये लाखों कुकीज़ हैं जो इंटरनेट पर चलते हैं और विभिन्न कार्यक्रम बनाते हैं। सामान्य तौर पर, औसतन एक दिन कुछ इस तरह दिखाई देता है: हम प्रति दिन लगभग 5.5 बिलियन की घटनाओं को देखते हैं, वे किसी तरह दिन-प्रतिदिन फैलते हैं, और चरम पर वे प्रति सेकंड लगभग 100 हजार घटनाओं तक पहुंचते हैं।

घटनाएँ विभिन्न उपयोगकर्ता संकेत हैं। उदाहरण के लिए, किसी साइट की यात्रा: हम देखते हैं कि उपयोगकर्ता किस ब्राउज़र से जाता है, उसके उपयोगकर्ता-संबंधी और हम जो कुछ भी निकाल सकते हैं। कभी-कभी हम देखते हैं कि वह साइट पर कैसे और किन खोज क्वेरी के लिए आया था। यह उदाहरण के लिए, डिस्काउंट कूपन के साथ भुगतान करता है और यह ऑफ़लाइन दुनिया से विभिन्न डेटा भी हो सकता है।
हमें इस डेटा को सहेजने और उपयोगकर्ता को दर्शकों के तथाकथित समूहों में चिह्नित करने की आवश्यकता है। उदाहरण के लिए, सेगमेंट एक "महिला" हो सकती है जो "बिल्लियों से प्यार करती है" और "कार सेवा" की तलाश में है, उसके पास "तीन साल से अधिक पुरानी कार है।"
क्यों एक उपयोगकर्ता खंड? इसके लिए कई एप्लिकेशन हैं, उदाहरण के लिए, विज्ञापन। विभिन्न विज्ञापन नेटवर्क विज्ञापन सेवा एल्गोरिदम का अनुकूलन कर सकते हैं। यदि आप अपनी कार सेवा का विज्ञापन कर रहे हैं, तो आप इस तरह से एक अभियान स्थापित कर सकते हैं, जिसमें केवल वही लोग हैं जिनके पास पुरानी कार दिखाने की जानकारी है, नए लोगों के मालिकों को छोड़कर। आप साइट की सामग्री को गतिशील रूप से बदल सकते हैं, आप स्कोरिंग के लिए डेटा का उपयोग कर सकते हैं - कई एप्लिकेशन हैं।
डेटा कई पूरी तरह से अलग-अलग स्थानों से प्राप्त किया जाता है। यह प्रत्यक्ष पिक्सेल सेटिंग्स हो सकती है - यह है कि अगर ग्राहक अपने दर्शकों का विश्लेषण करना चाहता है, तो वह पिक्सेल को साइट पर डालता है, एक अदृश्य तस्वीर जो हमारे सर्वर से डाउनलोड की जाती है। लब्बोलुआब यह है कि हम इस साइट पर उपयोगकर्ता की यात्रा देखते हैं: आप इसे बचा सकते हैं, उपयोगकर्ता के चित्र का विश्लेषण और समझना शुरू कर सकते हैं, यह सभी जानकारी हमारे ग्राहक के लिए उपलब्ध है।

डेटा विभिन्न भागीदारों से प्राप्त किया जा सकता है जो बहुत अधिक डेटा देखते हैं और उन्हें विभिन्न तरीकों से विमुद्रीकृत करना चाहते हैं। भागीदार वास्तविक समय में डेटा की आपूर्ति कर सकते हैं और फ़ाइलों के रूप में आवधिक अपलोड कर सकते हैं।
मुख्य आवश्यकताएं:
- क्षैतिज मापनीयता;
- दर्शकों की मात्रा का आकलन;
- निगरानी और विकास की सुविधा;
- घटनाओं के लिए अच्छी प्रतिक्रिया दर।
सिस्टम की प्रमुख आवश्यकताओं में से एक क्षैतिज मापनीयता है। ऐसा एक क्षण है जब आप एक पोर्टल या ऑनलाइन स्टोर विकसित कर रहे हैं, तो आप अपने उपयोगकर्ताओं की संख्या का अनुमान लगा सकते हैं (यह कैसे बढ़ेगा, यह कैसे बदल जाएगा) और मोटे तौर पर समझते हैं कि संसाधनों की कितनी आवश्यकता है, और समय के साथ स्टोर कैसे रहेगा और विकसित होगा।
जब आप डीएमपी के समान एक प्लेटफ़ॉर्म विकसित करते हैं, तो आपको इस तथ्य के लिए तैयार रहना होगा कि कोई भी बड़ी साइट - सशर्त अमेज़ॅन - अपने पिक्सेल को इसमें डाल सकती है, और आपको इस पूरी साइट के ट्रैफ़िक के साथ काम करना होगा, जबकि आपको गिरना नहीं चाहिए, और संकेतक सिस्टम को किसी तरह इससे नहीं बदलना चाहिए।
यह भी एक निश्चित दर्शकों की मात्रा को समझने में सक्षम होने के लिए काफी महत्वपूर्ण है ताकि एक संभावित विज्ञापनदाता या कोई और मीडिया योजना बना सके। उदाहरण के लिए, एक व्यक्ति आपके पास आता है और आपको यह पता लगाने के लिए कहता है कि नोवोसिबिर्स्क की कितनी गर्भवती महिलाएं एक बंधक की तलाश में हैं ताकि यह आकलन किया जा सके कि यह उन्हें लक्षित करने के लिए समझ में आता है या नहीं।
विकास के दृष्टिकोण से, आपको अपने सिस्टम में होने वाली हर चीज की अच्छी तरह से निगरानी करने में सक्षम होना चाहिए, वास्तविक ट्रैफ़िक के कुछ हिस्से को डीबग करें, और इसी तरह।
सबसे महत्वपूर्ण सिस्टम आवश्यकताओं में से एक घटनाओं के लिए एक अच्छी प्रतिक्रिया दर है। जितनी तेजी से सिस्टम घटनाओं पर प्रतिक्रिया करते हैं, उतना ही बेहतर है, यह स्पष्ट है। यदि आप थिएटर टिकट की तलाश कर रहे हैं, तो यदि आप एक दिन, दो दिन या एक घंटे के बाद भी किसी प्रकार की छूट की पेशकश देखते हैं - यह अप्रासंगिक हो सकता है, क्योंकि आप पहले से ही टिकट खरीद सकते हैं या एक प्रदर्शन पर जा सकते हैं। जब आप एक ड्रिल की तलाश कर रहे हैं - आप इसे ढूंढ रहे हैं, ढूंढें, खरीदें, एक शेल्फ लटकाएं, और कुछ दिनों के बाद बमबारी शुरू होती है: "एक ड्रिल खरीदें!"।
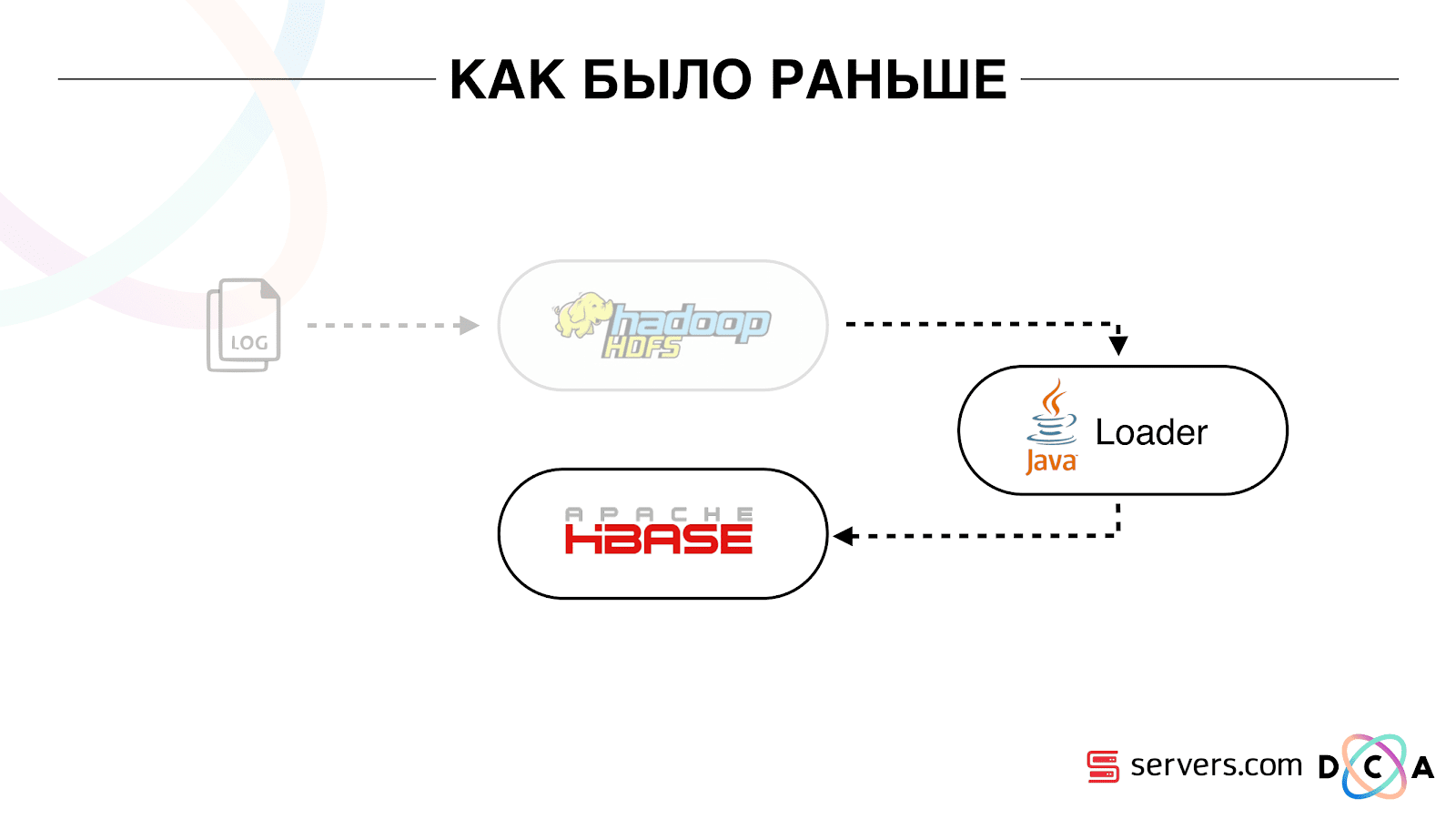
जैसा पहले था
एक पूरे के रूप में लेख रीसाइक्लिंग वास्तुकला के बारे में है। मैं आपको बताना चाहता हूं कि हमारा शुरुआती बिंदु क्या था, परिवर्तनों से पहले सब कुछ कैसे काम करता है।
हमारे पास जो भी डेटा था, चाहे वह एक डायरेक्ट डेटा स्ट्रीम हो या लॉग्स, को HDFS - डिस्ट्रिब्यूटेड फाइल स्टोरेज पर स्टोर किया गया था। फिर एक निश्चित प्रक्रिया थी जो समय-समय पर शुरू हुई थी, एचडीएफएस से सभी अप्रमाणित फाइलों को ले लिया और उन्हें एचबीएएस ("पूट अनुरोध") में डेटा संवर्धन अनुरोधों में परिवर्तित कर दिया।
हम HBase में डेटा को कैसे स्टोर करते हैं
यह एक स्तंभ समय श्रृंखला डेटाबेस है। वह एक पंक्ति कुंजी की अवधारणा है - यह वह कुंजी है जिसके तहत आप अपना डेटा संग्रहीत करते हैं। हम उपयोगकर्ता आईडी को कुंजी, उपयोगकर्ता आईडी के रूप में उपयोग करते हैं, जिसे हम पहली बार उपयोगकर्ता को देखते समय उत्पन्न करते हैं। प्रत्येक कुंजी के अंदर, डेटा को कॉलम परिवार - संस्थाओं में विभाजित किया जाता है, जिसके स्तर पर आप अपने डेटा की मेटा-जानकारी का प्रबंधन कर सकते हैं। उदाहरण के लिए, आप कॉलम परिवार "डेटा" के लिए रिकॉर्ड के एक हज़ार संस्करणों को स्टोर कर सकते हैं और उन्हें दो महीने के लिए स्टोर कर सकते हैं, और कॉलम परिवार "कच्चे" के लिए - एक वर्ष, एक विकल्प के रूप में।
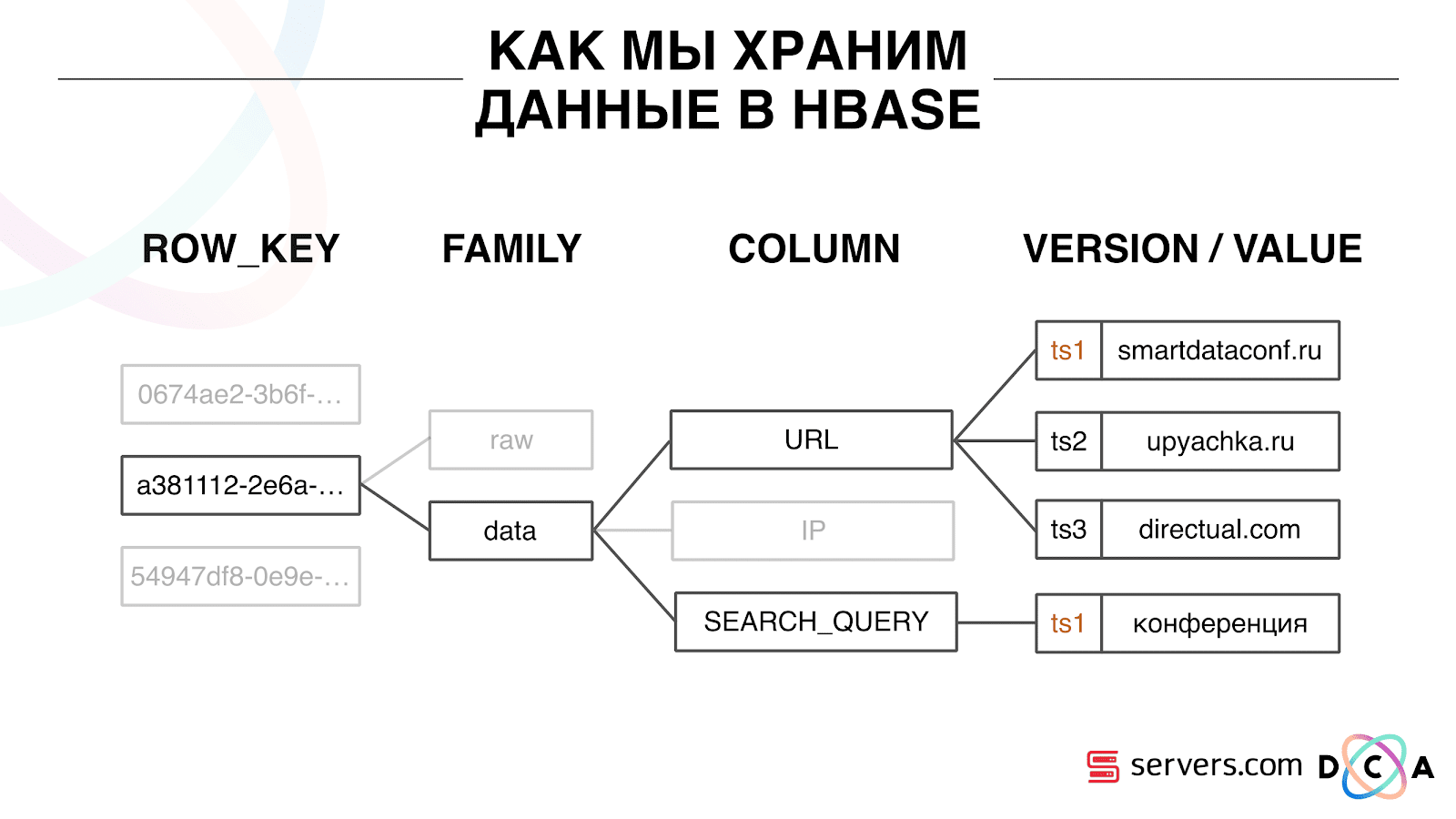
कॉलम परिवार के भीतर, कई कॉलम क्वालिफायर (इसके बाद वाले कॉलम) हैं। हम कॉलम के रूप में विभिन्न उपयोगकर्ता विशेषताओं का उपयोग करते हैं। यह वह URL हो सकता है, जिस पर वह गया था, IP पता, खोज क्वेरी। और सबसे महत्वपूर्ण बात, प्रत्येक कॉलम के अंदर बहुत सारी जानकारी संग्रहीत होती है। कॉलम URL के अंदर यह संकेत दिया जा सकता है कि उपयोगकर्ता smartdataconf.ru पर गया था, फिर कुछ अन्य साइटों पर। और टाइमस्टैम्प का उपयोग संस्करण के रूप में किया जाता है - आप उपयोगकर्ता के विज़िट का एक आदेशित इतिहास देखते हैं। हमारे मामले में, हम यह निर्धारित कर सकते हैं कि उपयोगकर्ता "कॉन्फ्रेंस" कीवर्ड के साथ स्मार्टडेटाफोन वेबसाइट पर आया था, क्योंकि उनके पास एक ही टाइमस्टैम्प है।
HBase के साथ काम करें
HBase के साथ काम करने के लिए कई विकल्प हैं। यह PUT अनुरोध (डेटा परिवर्तन के लिए अनुरोध), GET अनुरोध ("मुझे उपयोगकर्ता वास्य पर सभी डेटा दे सकता है" और ऐसा हो सकता है)। आप SCAN अनुरोध चला सकते हैं - HBase में सभी डेटा की बहु-थ्रेडेड अनुक्रमिक स्कैनिंग। हमने पहले इसका इस्तेमाल दर्शकों के सेगमेंट में मार्किंग के लिए किया था।
Analytics इंजन नामक एक कार्य था, यह दिन में एक बार चलता था और कई थ्रेड्स में HBase को स्कैन करता था। प्रत्येक उपयोगकर्ता के लिए, उसने HBase से पूरी कहानी को उठाया और विश्लेषणात्मक लिपियों के एक सेट के माध्यम से इसे चलाया।

एक विश्लेषणात्मक स्क्रिप्ट क्या है? यह किसी प्रकार का ब्लैक बॉक्स (जावा क्लास) है, जो सभी उपयोगकर्ता डेटा को इनपुट के रूप में प्राप्त करता है और सेगमेंट का एक सेट देता है जिसे वह आउटपुट के लिए उपयुक्त मानता है। हम वह सब कुछ स्क्रिप्ट को देते हैं जो हम देखते हैं - आईपी, विज़िट, यूजरएजेंट, आदि, और आउटपुट पर स्क्रिप्ट बाहर देते हैं: "यह एक महिला है, बिल्लियों से प्यार करती है, कुत्तों को पसंद नहीं करती है"।
ये डेटा भागीदारों को दिए गए थे, आंकड़ों पर विचार किया गया था। हमारे लिए यह समझना महत्वपूर्ण था कि सामान्य तौर पर कितनी महिलाएं हैं, कितने पुरुष हैं, कितने लोग बिल्लियों से प्यार करते हैं, कितनों के पास कार है या नहीं, इत्यादि।
हमने MongoDB में आंकड़े संग्रहीत किए और प्रत्येक दिन के लिए एक विशिष्ट खंड काउंटर बढ़ाकर लिखा। हमारे पास प्रत्येक दिन के लिए प्रत्येक खंड की मात्रा का एक ग्राफ था।
यह प्रणाली अपने समय के लिए अच्छी थी। यह क्षैतिज रूप से बड़े पैमाने पर बढ़ने की अनुमति देता है, दर्शकों की मात्रा का अनुमान लगाने की अनुमति देता है, लेकिन इसमें कई कमियां थीं।
लॉग को देखने के लिए सिस्टम में क्या हो रहा था, यह समझना हमेशा संभव नहीं था। जब हम पिछले हॉस्टल में थे, तो कई कारणों से यह कार्य अक्सर गिर जाता था। 20+ सर्वरों का एक Hadoop क्लस्टर था, दिन में एक बार सर्वर का एक हिस्सा दुर्घटनाग्रस्त हो गया। यह इस तथ्य के कारण था कि कार्य आंशिक रूप से गिर सकता है और डेटा की गणना नहीं कर सकता है। इसे पुनः आरंभ करने के लिए समय होना आवश्यक था, और, यह देखते हुए कि यह कई घंटों तक काम करता था, कुछ निश्चित बारीकियाँ थीं।
सबसे बुनियादी बात जो मौजूदा वास्तुकला को पूरा नहीं करती थी वह यह थी कि इस घटना के लिए प्रतिक्रिया समय बहुत लंबा था। इस विषय पर एक कहानी भी है। एक कंपनी थी जिसने क्षेत्रों में आबादी के लिए माइक्रोएलो जारी किए थे, और हमने उनके साथ भागीदारी की। उनका ग्राहक साइट पर आता है, माइक्रोक्रिडिट के लिए एक आवेदन भरता है, कंपनी को 15 मिनट में जवाब देने की आवश्यकता होती है: क्या वे ऋण देने के लिए तैयार हैं या नहीं। यदि आप तैयार हैं, तो उन्होंने तुरंत कार्ड में पैसा स्थानांतरित कर दिया।
सब कुछ अच्छा काम किया। क्लाइंट ने यह जांचने का फैसला किया कि यह आम तौर पर कैसे होता है: उन्होंने एक अलग लैपटॉप लिया, एक स्वच्छ सिस्टम स्थापित किया, इंटरनेट पर कई पृष्ठों का दौरा किया और अपनी साइट पर गए। वे देखते हैं कि एक अनुरोध है, और जवाब में हम कहते हैं कि अभी तक कोई डेटा नहीं है। ग्राहक पूछता है: "कोई डेटा क्यों नहीं है?"
हम समझाते हैं: उपयोगकर्ता द्वारा कार्रवाई करने से पहले एक निश्चित अंतराल है। डेटा HBase को भेजा जाता है, संसाधित किया जाता है, और उसके बाद ही ग्राहक को परिणाम प्राप्त होता है। ऐसा लगता है कि यदि उपयोगकर्ता ने विज्ञापन नहीं देखा - सब कुछ क्रम में है, तो कुछ भी बुरा नहीं होगा। लेकिन इस स्थिति में, अंतराल के कारण उपयोगकर्ता को ऋण नहीं दिया जा सकता है।
यह एक अलग मामला नहीं है, और यह एक रीयलटाइम सिस्टम पर स्विच करने के लिए आवश्यक था। हम उससे क्या चाहते हैं?

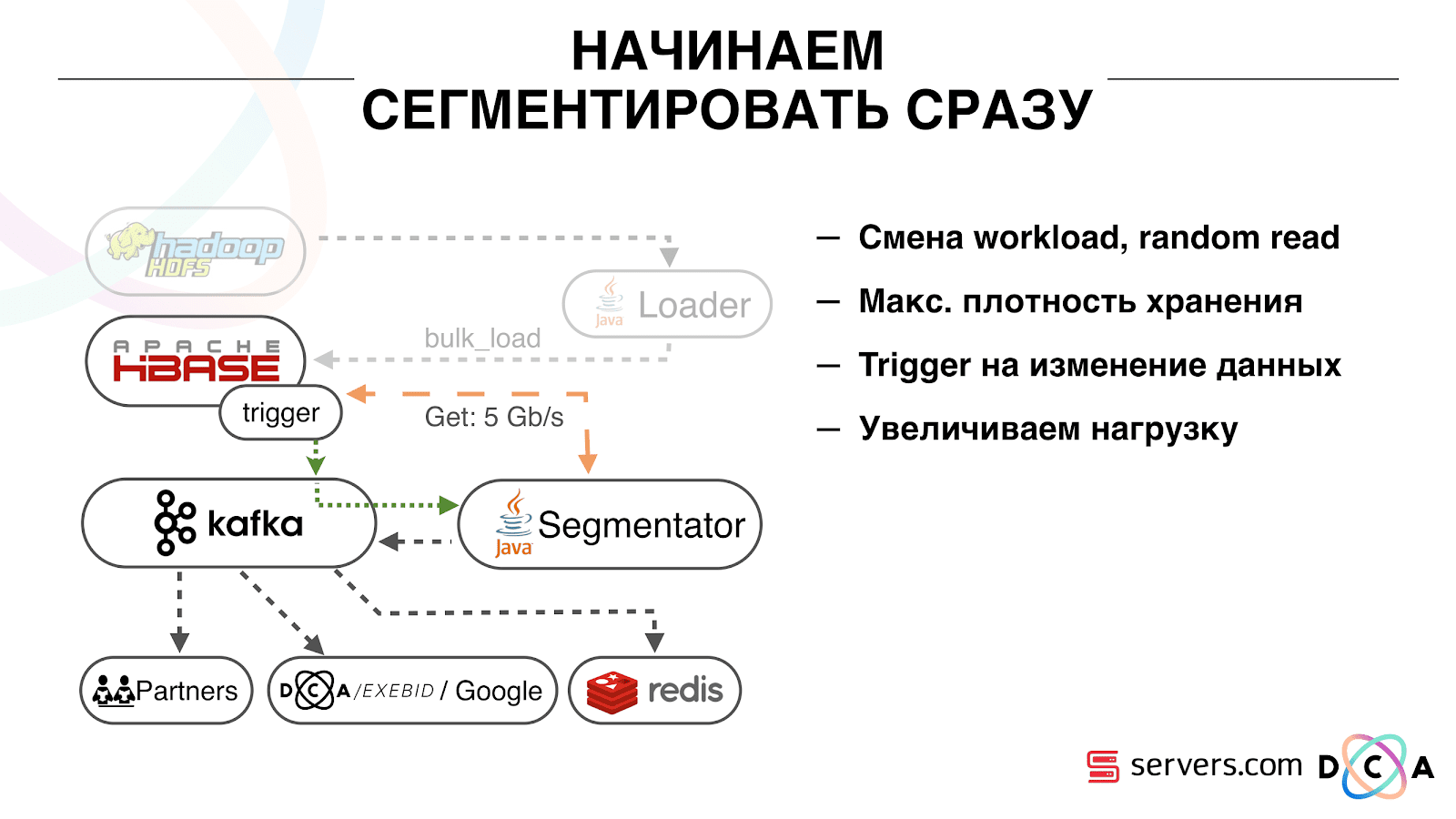
जैसे ही हम इसे देखते हैं, हम HBase को डेटा लिखना चाहते हैं। हमने एक यात्रा देखी, जो कुछ भी हम जानते हैं, उसे समृद्ध किया और भंडारण में भेज दिया। जैसे ही संग्रहण में डेटा बदल गया है, आपको तुरंत हमारे पास मौजूद विश्लेषणात्मक स्क्रिप्ट के पूरे सेट को चलाने की आवश्यकता है। हम निगरानी और विकास की सुविधा चाहते हैं, नई लिपियों को लिखने की क्षमता, उन्हें वास्तविक ट्रैफ़िक के टुकड़ों तक ले जाते हैं। हम समझना चाहते हैं कि अभी क्या व्यवस्था व्यस्त है।
पहली चीज जो हमने शुरू की थी वह दूसरी समस्या को हल कर रही है: उपयोगकर्ता को HBase में उसके बारे में डेटा बदलने के तुरंत बाद खंड दें। प्रारंभ में, हमारे पास श्रमिक-नोड्स थे (मैप-कम कार्य उन पर लॉन्च किए गए थे) HBase के रूप में एक ही स्थान पर स्थित थे। कई मामलों में, यह बहुत अच्छा था - गणना डेटा के बगल में की जाती है, कार्य काफी तेज़ी से काम करते हैं, थोड़ा ट्रैफ़िक नेटवर्क से गुजरता है। यह स्पष्ट है कि कार्य कुछ संसाधनों का उपभोग करता है, क्योंकि यह जटिल विश्लेषणात्मक स्क्रिप्ट चलाता है।
जब हम वास्तविक समय में काम करने जाते हैं, तो HBase पर भार की प्रकृति बदल जाती है। हम अनुक्रमिक वाले के बजाय यादृच्छिक रीडिंग पर चलते हैं। यह महत्वपूर्ण है कि HBase पर लोड अपेक्षित है - हम किसी को Hadoop क्लस्टर पर कार्य चलाने और HBB प्रदर्शन को खराब करने की अनुमति नहीं दे सकते।
पहली चीज जो हमने की वह थी HBase को अलग-अलग सर्वरों में स्थानांतरित करना। ब्लॉकचैच और ब्लूमफिल्टर को भी ट्विक किया। तब हमने HBase में डेटा को स्टोर करने के तरीके पर अच्छा काम किया। उन्होंने उस प्रणाली को बहुत दोबारा काम में लिया, जिसके बारे में मैंने शुरुआत में बात की थी, और डेटा को ही पुनः प्राप्त किया।

स्पष्ट से: हमने आईपी को एक स्ट्रिंग के रूप में संग्रहीत किया, और संख्याओं में लंबा हो गया। कुछ डेटा को वर्गीकृत किया गया था, शब्दावली चीजों को बाहर किया गया था, और इसी तरह। लब्बोलुआब यह है कि इस वजह से, हम HBase को लगभग दो बार हिला सकते थे - 10 टीबी से 5 टीबी तक। HBase में एक नियमित डेटाबेस में ट्रिगर के समान एक तंत्र है। यह एक सहसंयोजक तंत्र है। हमने एक सहसंसाधक लिखा, जब एक उपयोगकर्ता HBase में बदलता है, उपयोगकर्ता आईडी को काफ्का को भेजता है।
यूजर आईडी कफका में है। इसके अलावा एक निश्चित सेवा "खंड" है। यह उपयोगकर्ता पहचानकर्ताओं की धारा को पढ़ता है और उन सभी लिपियों पर चलता है जो पहले थे, HBase से डेटा का अनुरोध करते हुए। प्रक्रिया को 10% ट्रैफ़िक पर लॉन्च किया गया था, हमने देखा कि यह कैसे काम करता है। सब कुछ बहुत अच्छा था।

इसके बाद, हमने लोड बढ़ाना शुरू किया और कई समस्याओं को देखा। पहली चीज जो हमने देखी थी कि सेवा काम करती है, सेगमेंट करती है और फिर काफ्का से जुड़ जाती है, जुड़ जाती है और फिर से काम करना शुरू कर देती है। कई सेवाएं - वे एक दूसरे की मदद करते हैं। फिर अगले एक बंद हो जाता है, एक और एक सर्कल में। इसी समय, विभाजन के लिए उपयोगकर्ताओं की लाइनअप लगभग रेक नहीं किया जा रहा है।
यह काफ्का में दिल की धड़कन तंत्र की ख़ासियत के कारण था, फिर भी यह 0.8 संस्करण था। दिल की धड़कन तब होती है जब उपभोक्ता ब्रोकर को बताते हैं कि वे जीवित हैं या नहीं, हमारे मामले में, सेगमेंट रिपोर्ट करता है। निम्नलिखित हुआ: हमने डेटा का एक बड़ा पैकेट प्राप्त किया, इसे प्रसंस्करण के लिए भेजा। थोड़ी देर के लिए काम किया, जबकि यह काम किया - कोई दिल की धड़कन नहीं भेजी गई। दलालों का मानना था कि उपभोक्ता मर गया था, और इसे बंद कर दिया।
उपभोक्ता ने अंत तक काम किया, कीमती सीपीयू को बर्बाद करते हुए, यह कहने की कोशिश की कि डेटा पैक पर काम किया गया था और अगले एक को लिया जा सकता था, लेकिन उसे मना कर दिया गया क्योंकि दूसरे ने जो काम किया था, उसे छीन लिया। हमने अपनी पृष्ठभूमि को हीटबीट बनाकर इसे ठीक किया, फिर सच्चाई काफका का एक नया संस्करण आया जहां हमने इस समस्या को ठीक किया।
फिर यह सवाल उठा कि हमारे सेगमेंटर्स को किस तरह के हार्डवेयर स्थापित करने चाहिए। सेगमेंटेशन एक संसाधन गहन प्रक्रिया (सीपीयू बाउंड) है। यह महत्वपूर्ण है कि सेवा न केवल बहुत सारे सीपीयू का उपभोग करती है, बल्कि नेटवर्क को भी लोड करती है। अब यातायात 5 Gbit / sec तक पहुँचता है। सवाल था: सेवाओं को कहां रखा जाए, कई छोटे सर्वरों पर या थोड़े बड़े पर।
उस क्षण, हम पहले से ही
सर्वर पर नंगे धातु पर चले गए। हमने सर्वर से लोगों के साथ बात की, उन्होंने हमारी मदद की, इससे हमारे समाधान के काम को कम से कम महंगे सर्वरों और शक्तिशाली सीपीयू के साथ कई सस्ते लोगों पर परीक्षण करना संभव हो गया। हमने उचित विकल्प चुना, प्रति सेकंड एक घटना को संसाधित करने की इकाई लागत की गणना। वैसे, विकल्प पर्याप्त रूप से शक्तिशाली पर गिर गया और एक ही समय में बेहद सस्ती डेल R230, उन्होंने इसे लॉन्च किया - यह सब काम किया।
यह महत्वपूर्ण है कि सेगमेंट द्वारा उपयोगकर्ता को सेगमेंट में चिह्नित करने के बाद, उसके विश्लेषण का परिणाम एक निश्चित विषय सेग्मेंटेशन रिजल्ट में, काफ्का पर वापस आ जाता है।
इसके अलावा, हम अलग-अलग उपभोक्ताओं द्वारा स्वतंत्र रूप से इस डेटा से जुड़ सकते हैं जो एक-दूसरे के साथ हस्तक्षेप नहीं करेंगे। यह हमें प्रत्येक भागीदार को स्वतंत्र रूप से डेटा देने की अनुमति देता है, यह कुछ बाहरी साझेदार, आंतरिक डीएसपी, Google, आंकड़े हैं।
आंकड़ों के साथ, एक दिलचस्प बिंदु यह भी है: पहले हम MongoDB में काउंटरों के मूल्य को बढ़ा सकते थे, एक निश्चित दिन में कितने उपयोगकर्ता एक निश्चित खंड में थे। अब, ऐसा नहीं किया जा सकता क्योंकि हम किसी घटना को पूरा करने के बाद प्रत्येक उपयोगकर्ता का विश्लेषण करते हैं, अर्थात्। दिन में कई बार।
इसलिए, हमें स्ट्रीम में उपयोगकर्ताओं की अद्वितीय संख्या गिनने की समस्या को हल करना था। ऐसा करने के लिए, हमने हाइपरलॉग डेटा संरचना और रेडिस में इसके कार्यान्वयन का उपयोग किया। डेटा संरचना संभाव्य है। इसका मतलब यह है कि आप वहां उपयोगकर्ता पहचानकर्ता जोड़ सकते हैं, पहचानकर्ता स्वयं संग्रहीत नहीं होंगे, इसलिए आप हाइपरलॉगॉग अत्यंत कॉम्पैक्ट में लाखों अद्वितीय पहचानकर्ताओं को संग्रहीत कर सकते हैं, और यह प्रति कुंजी 12 किलोबाइट तक ले जाएगा।
आप स्वयं पहचानकर्ता नहीं प्राप्त कर सकते, लेकिन आप इस सेट के आकार का पता लगा सकते हैं। चूंकि डेटा संरचना संभाव्य है, इसलिए कुछ त्रुटि है। उदाहरण के लिए, यदि आपके पास एक सेगमेंट "बिल्लियों को पसंद करता है", तो एक निश्चित दिन के लिए इस सेगमेंट के आकार के लिए अनुरोध करने पर, आपको 99.2 मिलियन प्राप्त होंगे और इसका मतलब होगा "99 मिलियन से 100 मिलियन तक"।
हाइपरलॉगलॉग में भी आप कई सेटों के मिलन का आकार पा सकते हैं। मान लें कि आपके पास दो खंड हैं: "सील से प्यार करता है" और "कुत्तों से प्यार करता है"। चलो पहले 100 मिलियन, दूसरे 1 मिलियन कहते हैं। कोई भी पूछ सकता है: "वे कितने जानवरों को पसंद करते हैं?" और 1% की त्रुटि के साथ "लगभग 101 मिलियन" का उत्तर प्राप्त करें। यह गणना करना दिलचस्प होगा कि बिल्लियों और कुत्तों दोनों को एक ही समय में कितना प्यार किया जाता है, लेकिन ऐसा करना काफी मुश्किल है।

एक तरफ, आप प्रत्येक सेट के आकार का पता लगा सकते हैं, संघ के आकार का पता लगा सकते हैं, जोड़ सकते हैं, एक को दूसरे से घटा सकते हैं और चौराहा प्राप्त कर सकते हैं। लेकिन इस तथ्य के कारण कि त्रुटि का आकार अंतिम चौराहे के आकार से बड़ा हो सकता है, अंतिम परिणाम "-50 से 50 हजार तक" फॉर्म का हो सकता है।

हमने रेडिस पर डेटा लिखते समय प्रदर्शन को कैसे बढ़ाया जाए, इस पर काफी काम किया है। शुरू में, हम प्रति सेकंड 200 हजार ऑपरेशन तक पहुंचे। लेकिन जब प्रत्येक उपयोगकर्ता के 50 से अधिक खंड होते हैं - प्रत्येक उपयोगकर्ता के बारे में जानकारी दर्ज करना - 50 ऑपरेशन। यह पता चला है कि हम बैंडविड्थ में काफी सीमित हैं और इस उदाहरण में, प्रति सेकंड 4 हजार से अधिक उपयोगकर्ताओं के बारे में जानकारी नहीं लिख सकते हैं, यह हमारी जरूरत से कई गुना कम है।
हमने लुआ के माध्यम से रेडिस में एक अलग "संग्रहीत प्रक्रिया" बनाई, इसे वहां लोड किया और एक उपयोगकर्ता के खंडों की पूरी सूची के साथ इसे एक स्ट्रिंग पारित करना शुरू कर दिया। अंदर की प्रक्रिया पारित स्ट्रिंग को आवश्यक हाइपरलॉग अपडेट में कटौती करेगी और डेटा को बचाएगी, इसलिए हम प्रति सेकंड 1 मिलियन अपडेट तक पहुंच गए।
थोड़ा कट्टर: रेडिस सिंगल-थ्रेडेड है, आप इसे एक प्रोसेसर कोर, और एक नेटवर्क कार्ड को दूसरे पर पिन कर सकते हैं और एक और 15% प्रदर्शन प्राप्त कर सकते हैं, संदर्भ स्विचिंग पर बचत कर सकते हैं। इसके अतिरिक्त, महत्वपूर्ण बिंदु यह है कि आप डेटा संरचना को आसानी से बंद नहीं कर सकते, क्योंकि सेट के यूनियनों की शक्ति प्राप्त करने के संचालन का क्लस्टर नहीं किया गया है
काफ्का एक बेहतरीन उपकरण है
आप देखते हैं कि काफ्का प्रणाली में हमारा मुख्य परिवहन उपकरण है।
इसमें "विषय" का सार है। यह वह जगह है जहां आप डेटा लिखते हैं, लेकिन संक्षेप में - कतार। हमारे मामले में, कई कतारें हैं। उनमें से एक उन उपयोगकर्ताओं के पहचानकर्ता हैं जिन्हें खंड करना आवश्यक है। दूसरा विभाजन परिणाम है।
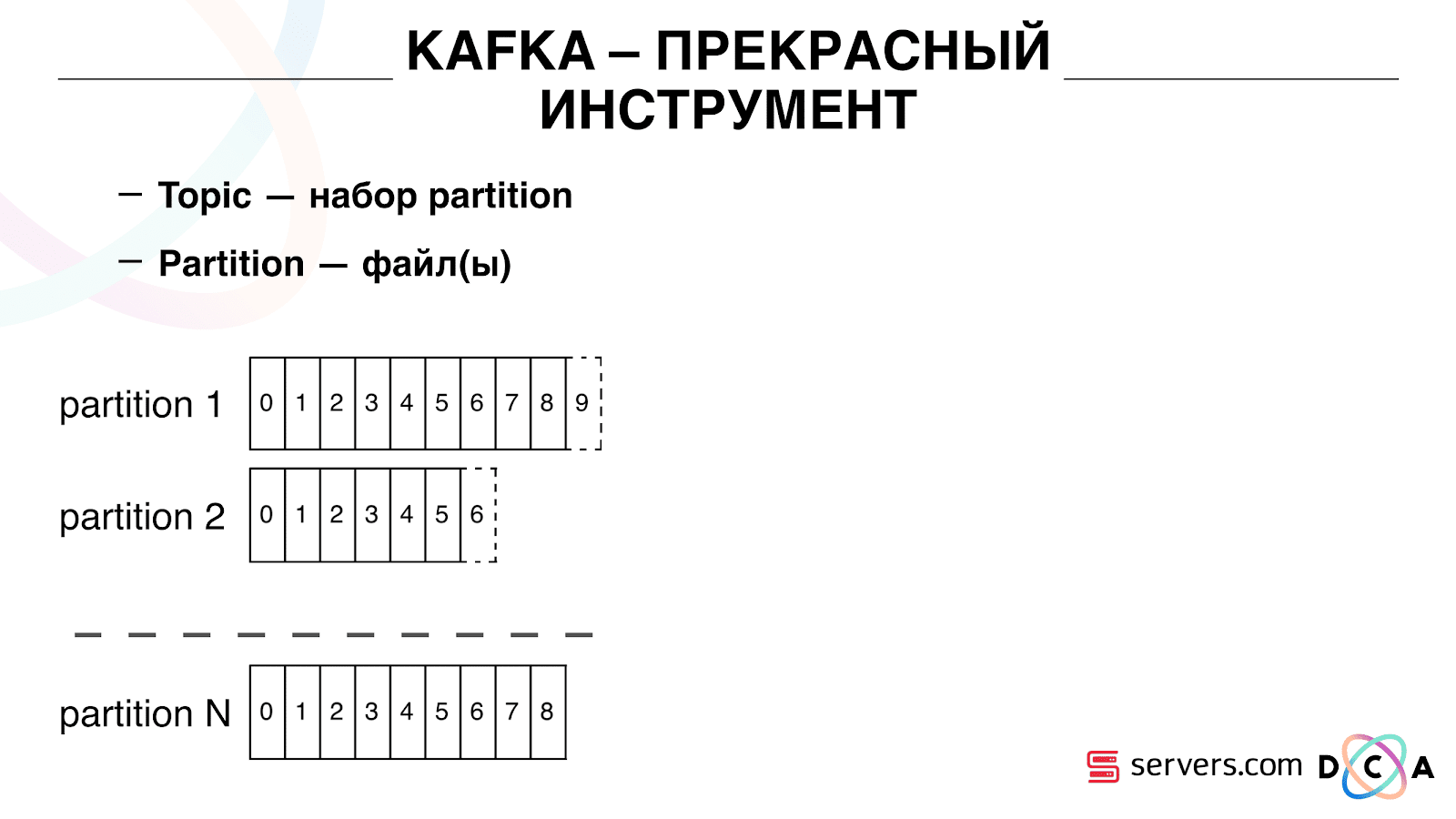
एक विषय विभाजन s का एक सेट है। इसे कुछ टुकड़ों में बांटा गया है। प्रत्येक विभाजन हार्ड ड्राइव पर एक फ़ाइल है। जब आपके निर्माता डेटा लिखते हैं, तो वे विभाजन के अंत तक पाठ के टुकड़े लिखते हैं। जब आपके उपभोक्ता डेटा पढ़ते हैं, तो वे बस इन विभाजन से पढ़ते हैं।
महत्वपूर्ण बात यह है कि आप स्वतंत्र रूप से कई उपभोक्ता समूहों को जोड़ सकते हैं, वे एक दूसरे के साथ हस्तक्षेप किए बिना डेटा का उपभोग करेंगे। यह उपभोक्ता समूह के नाम से निर्धारित होता है और निम्नानुसार हासिल किया जाता है।
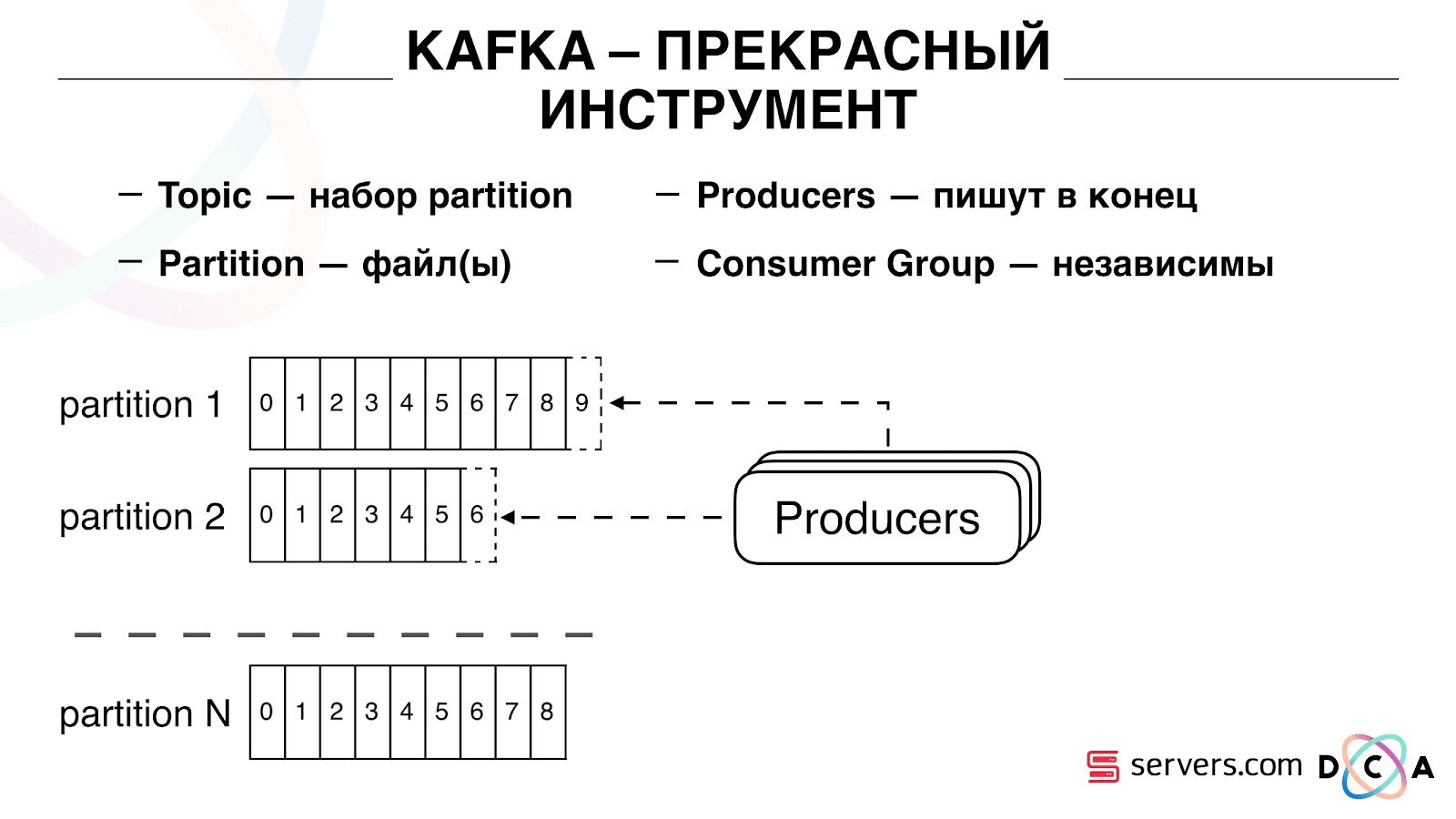
ऑफसेट जैसी कोई चीज है, वह स्थिति जहां उपभोक्ता समूह अब प्रत्येक विभाजन पर स्थित है। उदाहरण के लिए, समूह A, विभाजन 1 से सातवें संदेश को खाता है और विभाजन 2 से पांचवें को। ग्रुप बी, ए से स्वतंत्र, अन्य ऑफसेट हैं।
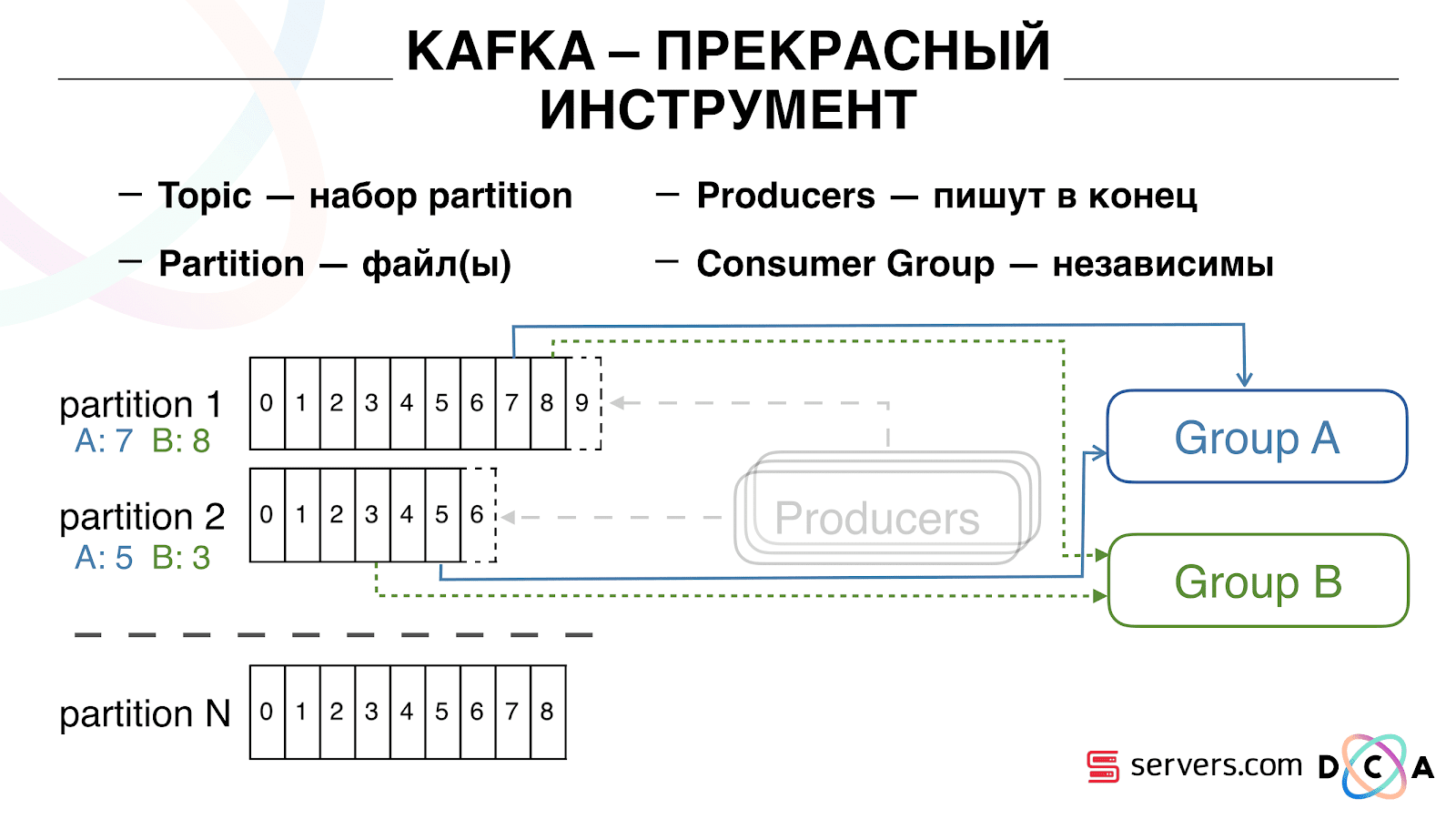 आप अपने उपभोक्ता समूह को क्षैतिज रूप से माप सकते हैं, एक अन्य प्रक्रिया या सर्वर जोड़ सकते हैं। यह विभाजन पुनर्मूल्यांकन होगा (काफ्का दलाल प्रत्येक उपभोक्ता को उपभोग के लिए एक विभाजन सूची सौंपेगा) इसका मतलब है कि पहला उपभोक्ता समूह केवल विभाजन 1 का उपभोग करना शुरू कर देगा, और दूसरा केवल विभाजन का उपभोग करता है। यदि कुछ उपभोक्ता की मृत्यु हो जाती है (उदाहरण के लिए, चूल्हा नहीं आता है), एक नया पुनर्मूल्यांकन होता है। , प्रत्येक उपभोक्ता प्रसंस्करण के लिए एक अप-टू-डेट विभाजन सूची प्राप्त करता है।
आप अपने उपभोक्ता समूह को क्षैतिज रूप से माप सकते हैं, एक अन्य प्रक्रिया या सर्वर जोड़ सकते हैं। यह विभाजन पुनर्मूल्यांकन होगा (काफ्का दलाल प्रत्येक उपभोक्ता को उपभोग के लिए एक विभाजन सूची सौंपेगा) इसका मतलब है कि पहला उपभोक्ता समूह केवल विभाजन 1 का उपभोग करना शुरू कर देगा, और दूसरा केवल विभाजन का उपभोग करता है। यदि कुछ उपभोक्ता की मृत्यु हो जाती है (उदाहरण के लिए, चूल्हा नहीं आता है), एक नया पुनर्मूल्यांकन होता है। , प्रत्येक उपभोक्ता प्रसंस्करण के लिए एक अप-टू-डेट विभाजन सूची प्राप्त करता है। यह काफी सुविधाजनक है। सबसे पहले, आप प्रत्येक उपभोक्ता समूह के लिए ऑफसेट में हेरफेर कर सकते हैं। कल्पना करें कि एक भागीदार है जिसे आप विभाजन के परिणामों के साथ इस विषय से डेटा स्थानांतरित करते हैं। वह लिखता है कि उसने बग के परिणामस्वरूप गलती से डेटा का आखिरी दिन खो दिया था। और आप, इस ग्राहक के उपभोक्ता समूह के लिए, बस एक दिन वापस रोल करें और उस पर पूरा डेटा दिन डालें। हमारा अपना उपभोक्ता समूह भी हो सकता है, उत्पादन ट्रैफ़िक से कनेक्ट हो सकता है, देखो क्या होता है, और वास्तविक डेटा पर डिबग हो सकता है।इसलिए, हमने यह हासिल कर लिया है कि हमने उपयोगकर्ताओं को बदलना शुरू कर दिया है, हम स्वतंत्र रूप से नए उपभोक्ताओं को जोड़ सकते हैं, हम आंकड़े लिखते हैं और हम इसे देख सकते हैं। अब आपको हमारे पास आने के तुरंत बाद HBase को लिखे गए डेटा को प्राप्त करने की आवश्यकता है।
यह काफी सुविधाजनक है। सबसे पहले, आप प्रत्येक उपभोक्ता समूह के लिए ऑफसेट में हेरफेर कर सकते हैं। कल्पना करें कि एक भागीदार है जिसे आप विभाजन के परिणामों के साथ इस विषय से डेटा स्थानांतरित करते हैं। वह लिखता है कि उसने बग के परिणामस्वरूप गलती से डेटा का आखिरी दिन खो दिया था। और आप, इस ग्राहक के उपभोक्ता समूह के लिए, बस एक दिन वापस रोल करें और उस पर पूरा डेटा दिन डालें। हमारा अपना उपभोक्ता समूह भी हो सकता है, उत्पादन ट्रैफ़िक से कनेक्ट हो सकता है, देखो क्या होता है, और वास्तविक डेटा पर डिबग हो सकता है।इसलिए, हमने यह हासिल कर लिया है कि हमने उपयोगकर्ताओं को बदलना शुरू कर दिया है, हम स्वतंत्र रूप से नए उपभोक्ताओं को जोड़ सकते हैं, हम आंकड़े लिखते हैं और हम इसे देख सकते हैं। अब आपको हमारे पास आने के तुरंत बाद HBase को लिखे गए डेटा को प्राप्त करने की आवश्यकता है।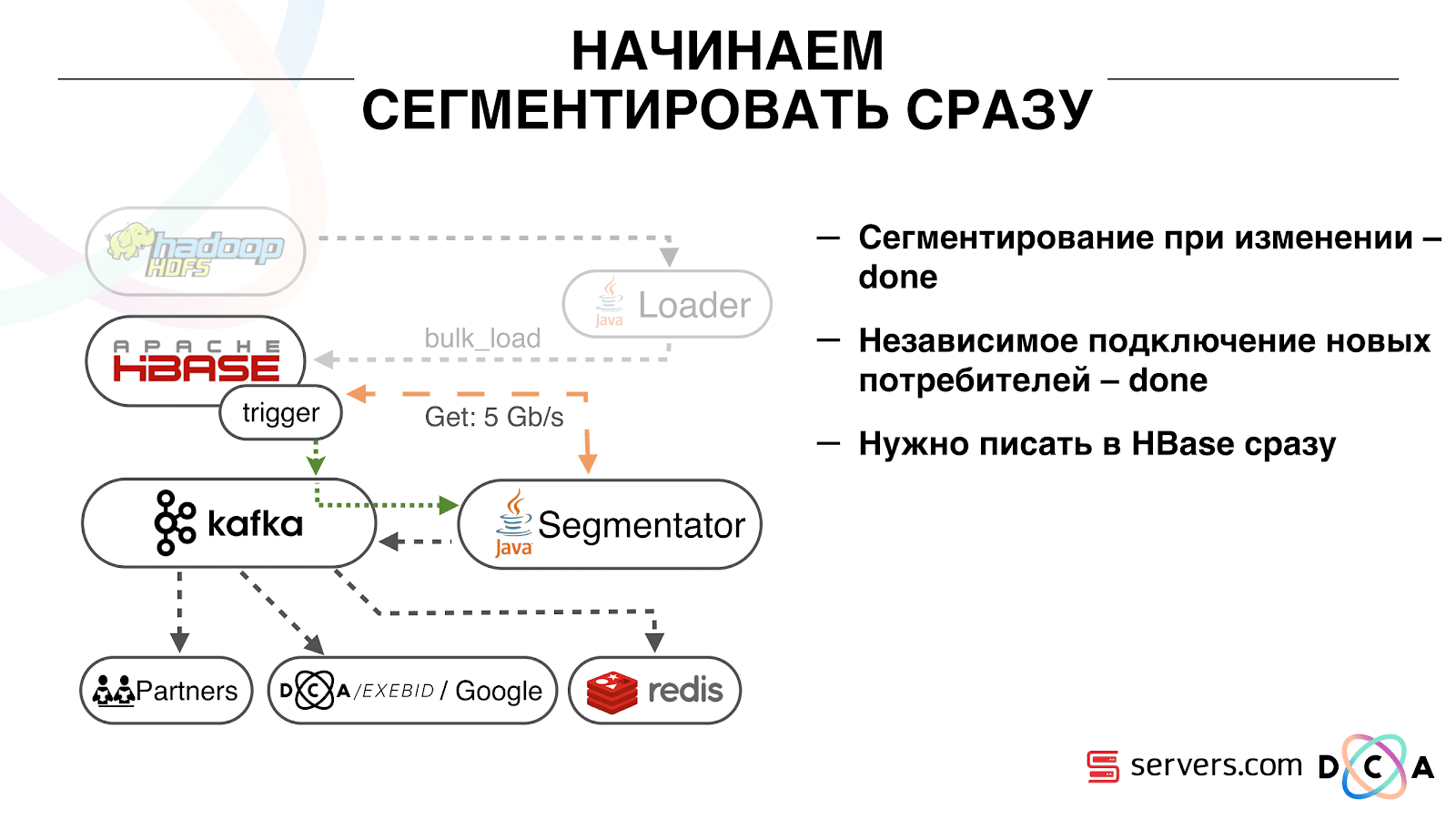 हमने यह कैसे किया। वहाँ बैच डेटा लोडिंग हुआ करती थी। एक बैच लोडर था, यह उपयोगकर्ता गतिविधि लॉग फ़ाइलों को संसाधित करता था: यदि कोई उपयोगकर्ता 10 विज़िट करता है, तो बैच 10 घटनाओं के लिए आया था, यह एक ऑपरेशन में HBase में दर्ज किया गया था। प्रति विभाजन केवल एक घटना थी। अब हम भंडारण में प्रत्येक अलग घटना लिखना चाहते हैं। हम लेखन स्ट्रीम और रीड स्ट्रीम को बहुत बढ़ा देंगे। प्रति विभाजन घटनाओं की संख्या भी बढ़ेगी।
हमने यह कैसे किया। वहाँ बैच डेटा लोडिंग हुआ करती थी। एक बैच लोडर था, यह उपयोगकर्ता गतिविधि लॉग फ़ाइलों को संसाधित करता था: यदि कोई उपयोगकर्ता 10 विज़िट करता है, तो बैच 10 घटनाओं के लिए आया था, यह एक ऑपरेशन में HBase में दर्ज किया गया था। प्रति विभाजन केवल एक घटना थी। अब हम भंडारण में प्रत्येक अलग घटना लिखना चाहते हैं। हम लेखन स्ट्रीम और रीड स्ट्रीम को बहुत बढ़ा देंगे। प्रति विभाजन घटनाओं की संख्या भी बढ़ेगी। पहली चीज जो हमने की, वह था HBase को SSD में पोर्ट करना। मानक तरीकों से, यह विशेष रूप से नहीं किया जाता है। यह एचडीएफएस का उपयोग करके किया गया था। आप कह सकते हैं कि HDFS पर एक विशिष्ट निर्देशिका डिस्क के ऐसे समूह पर होनी चाहिए। इस तथ्य के साथ एक अच्छी समस्या थी कि जब हम HBase को SSD में ले गए और इसे डब किया, तो सभी स्नैपशॉट भी वहां मिल गए और हमारे SSDs बहुत जल्दी समाप्त हो गए।यह भी हल किया गया है, हमने समय-समय पर स्नैपशॉट को एक फ़ाइल में निर्यात करना शुरू कर दिया, एक और एचडीएफएस निर्देशिका को लिखें और स्नैपशॉट के बारे में सभी मेटा-जानकारी को हटा दें। यदि आपको पुनर्स्थापित करने की आवश्यकता है - सहेजी गई फ़ाइल को ले जाएं, आयात करें और पुनर्स्थापित करें। यह ऑपरेशन बहुत ही संयोग से, सौभाग्य से है।इसके अलावा SSD पर उन्होंने राइट अहेड लॉग, राइट मेमोस्टोर, लिखो, कैश ब्लॉक को राइट ऑप्शन पर दिया। यह आपको डेटा रिकॉर्ड करते समय उन्हें तुरंत ब्लॉक कैश में डालने की अनुमति देता है। यह बहुत सुविधाजनक है क्योंकि हमारे मामले में, यदि हमने डेटा रिकॉर्ड किया है, तो इसे तुरंत पढ़ने की संभावना है। इससे कुछ फायदे भी हुए।इसके बाद, हमने अपने सभी डेटा स्रोतों को काफ्का को डेटा लिखने के लिए स्विच कर दिया। पहले से ही काफ्का से हमने एचडीएफएस में पिछड़े संगतता को बनाए रखने के लिए डेटा दर्ज किया, ताकि हमारे विश्लेषक डेटा के साथ काम कर सकें, मैपरेड कार्यों को चला सकें और उनके परिणामों का विश्लेषण कर सकें।हमने एक अलग उपभोक्ता समूह कनेक्ट किया जो HBase को डेटा लिखता है। यह वास्तव में, एक रैपर है जो काफ्का से पढ़ता है और HBase में PUTs बनाता है।
पहली चीज जो हमने की, वह था HBase को SSD में पोर्ट करना। मानक तरीकों से, यह विशेष रूप से नहीं किया जाता है। यह एचडीएफएस का उपयोग करके किया गया था। आप कह सकते हैं कि HDFS पर एक विशिष्ट निर्देशिका डिस्क के ऐसे समूह पर होनी चाहिए। इस तथ्य के साथ एक अच्छी समस्या थी कि जब हम HBase को SSD में ले गए और इसे डब किया, तो सभी स्नैपशॉट भी वहां मिल गए और हमारे SSDs बहुत जल्दी समाप्त हो गए।यह भी हल किया गया है, हमने समय-समय पर स्नैपशॉट को एक फ़ाइल में निर्यात करना शुरू कर दिया, एक और एचडीएफएस निर्देशिका को लिखें और स्नैपशॉट के बारे में सभी मेटा-जानकारी को हटा दें। यदि आपको पुनर्स्थापित करने की आवश्यकता है - सहेजी गई फ़ाइल को ले जाएं, आयात करें और पुनर्स्थापित करें। यह ऑपरेशन बहुत ही संयोग से, सौभाग्य से है।इसके अलावा SSD पर उन्होंने राइट अहेड लॉग, राइट मेमोस्टोर, लिखो, कैश ब्लॉक को राइट ऑप्शन पर दिया। यह आपको डेटा रिकॉर्ड करते समय उन्हें तुरंत ब्लॉक कैश में डालने की अनुमति देता है। यह बहुत सुविधाजनक है क्योंकि हमारे मामले में, यदि हमने डेटा रिकॉर्ड किया है, तो इसे तुरंत पढ़ने की संभावना है। इससे कुछ फायदे भी हुए।इसके बाद, हमने अपने सभी डेटा स्रोतों को काफ्का को डेटा लिखने के लिए स्विच कर दिया। पहले से ही काफ्का से हमने एचडीएफएस में पिछड़े संगतता को बनाए रखने के लिए डेटा दर्ज किया, ताकि हमारे विश्लेषक डेटा के साथ काम कर सकें, मैपरेड कार्यों को चला सकें और उनके परिणामों का विश्लेषण कर सकें।हमने एक अलग उपभोक्ता समूह कनेक्ट किया जो HBase को डेटा लिखता है। यह वास्तव में, एक रैपर है जो काफ्का से पढ़ता है और HBase में PUTs बनाता है।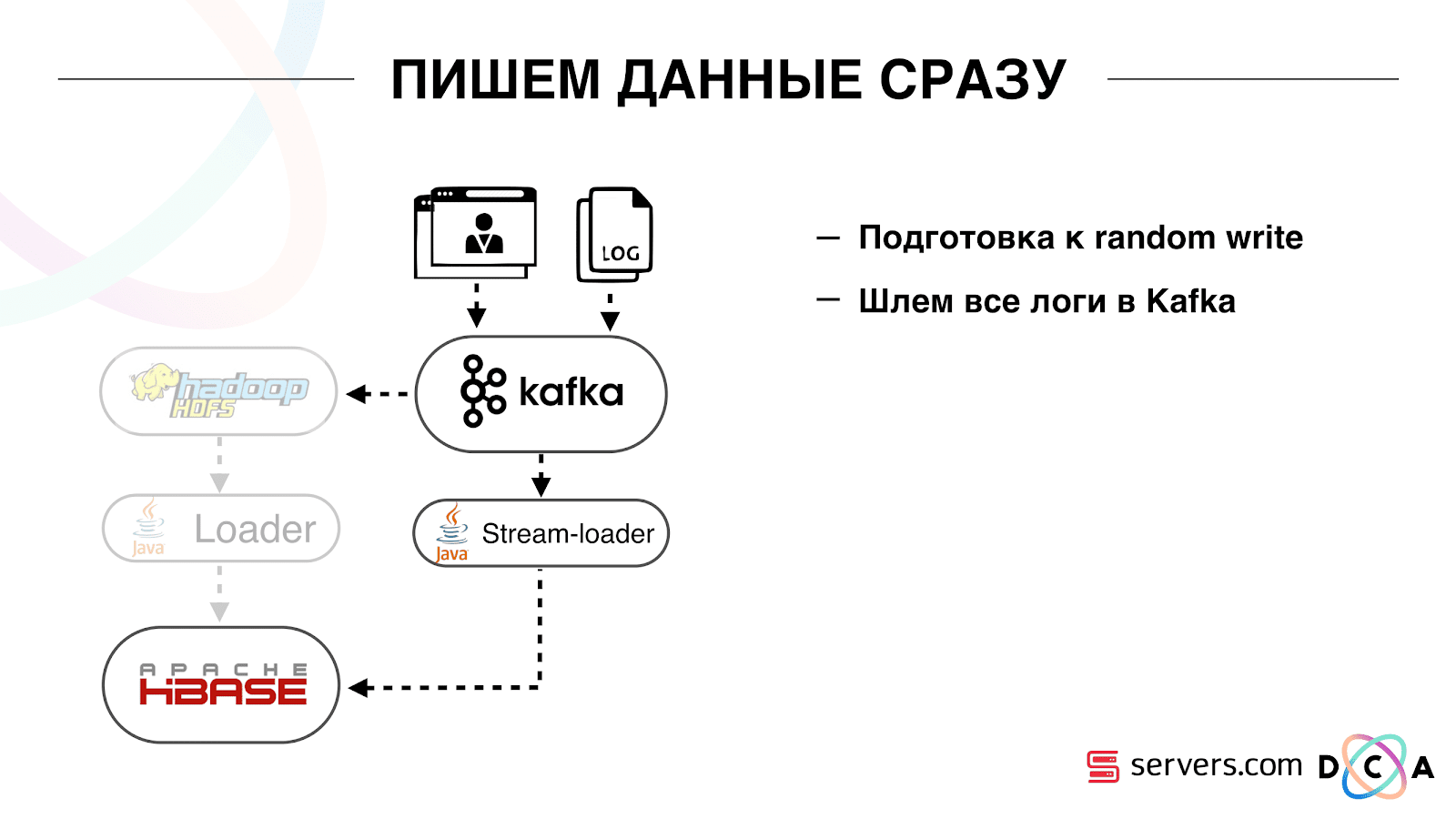 हमने दो सर्किटों को समानांतर में लॉन्च किया ताकि पिछड़े संगतता को न तोड़ें और सिस्टम के प्रदर्शन को नीचा न करें। एक नई योजना केवल कुछ प्रतिशत यातायात पर शुरू की गई थी। 10% पर, सब कुछ बहुत अच्छा था। लेकिन अधिक भार पर, सेगमेंटर्स विभाजन के प्रवाह का सामना नहीं कर सके।
हमने दो सर्किटों को समानांतर में लॉन्च किया ताकि पिछड़े संगतता को न तोड़ें और सिस्टम के प्रदर्शन को नीचा न करें। एक नई योजना केवल कुछ प्रतिशत यातायात पर शुरू की गई थी। 10% पर, सब कुछ बहुत अच्छा था। लेकिन अधिक भार पर, सेगमेंटर्स विभाजन के प्रवाह का सामना नहीं कर सके। हम मीट्रिक को "वहां से पढ़े जाने से पहले कफका में कितने संदेश देते हैं, एकत्र करते हैं।" यह एक अच्छा मीट्रिक है। प्रारंभ में, हमने मीट्रिक "कितने कच्चे संदेश अब हैं" एकत्र किया, लेकिन यह कुछ विशेष नहीं कहता है। आप देखते हैं: "मेरे पास एक लाख कच्चे संदेश हैं," तो क्या? इस मिलियन की व्याख्या करने के लिए, आपको यह जानना होगा कि सेगमेंट (उपभोक्ता) कितनी तेजी से काम कर रहा है, जो हमेशा स्पष्ट नहीं होता है।इस मीट्रिक के साथ, आप तुरंत देखते हैं कि डेटा कतार में लिखा जा रहा है, उससे लिया गया है, और आप देखते हैं कि वे संसाधित होने की कितनी उम्मीद करते हैं। हमने देखा कि हमारे पास सेगमेंट करने का समय नहीं था, और इसे पढ़ने से कई घंटे पहले संदेश कतार में था।आप बस क्षमता जोड़ सकते हैं, लेकिन यह बहुत
हम मीट्रिक को "वहां से पढ़े जाने से पहले कफका में कितने संदेश देते हैं, एकत्र करते हैं।" यह एक अच्छा मीट्रिक है। प्रारंभ में, हमने मीट्रिक "कितने कच्चे संदेश अब हैं" एकत्र किया, लेकिन यह कुछ विशेष नहीं कहता है। आप देखते हैं: "मेरे पास एक लाख कच्चे संदेश हैं," तो क्या? इस मिलियन की व्याख्या करने के लिए, आपको यह जानना होगा कि सेगमेंट (उपभोक्ता) कितनी तेजी से काम कर रहा है, जो हमेशा स्पष्ट नहीं होता है।इस मीट्रिक के साथ, आप तुरंत देखते हैं कि डेटा कतार में लिखा जा रहा है, उससे लिया गया है, और आप देखते हैं कि वे संसाधित होने की कितनी उम्मीद करते हैं। हमने देखा कि हमारे पास सेगमेंट करने का समय नहीं था, और इसे पढ़ने से कई घंटे पहले संदेश कतार में था।आप बस क्षमता जोड़ सकते हैं, लेकिन यह बहुत महंगा होगा । इसलिए, हमने अनुकूलन करने का प्रयास किया।Samomasshtabirovanie
हमारे पास HBase है। उपयोगकर्ता बदल रहा है, उसका पहचानकर्ता काफ्का में उड़ रहा है। विषय को विभाजन में विभाजित किया गया है, लक्ष्य विभाजन उपयोगकर्ता आईडी द्वारा चुना गया है। इसका मतलब यह है कि जब आप उपयोगकर्ता "वास्या" को देखते हैं - वह विभाजन 1 में जाता है। जब आप "पेट्या" को देखते हैं - विभाजन 2 को। यह सुविधाजनक है - आप यह प्राप्त कर सकते हैं कि आपको अपनी सेवा के एक उदाहरण पर एक उपभोक्ता दिखाई देगा, और दूसरा - दूसरे पर।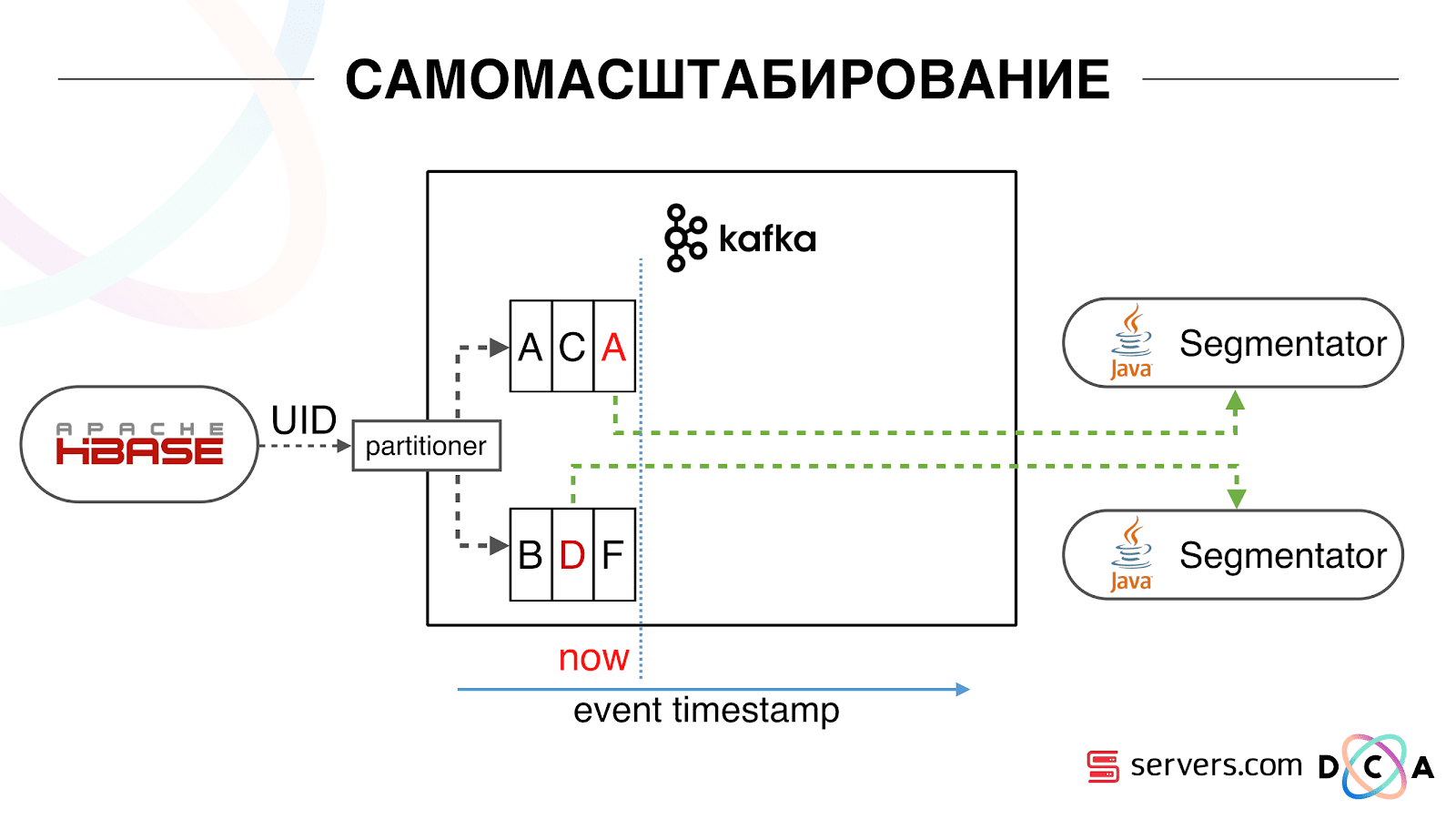 हम देखने लगे कि क्या हो रहा है। इंटरनेट पर एक विशिष्ट उपयोगकर्ता व्यवहार किसी वेबसाइट पर जाने और कई पृष्ठभूमि टैब खोलने के लिए है। दूसरे को साइट पर जाना है और लैंडिंग पृष्ठ पर पहुंचने के लिए कुछ क्लिक करना है।हम विभाजन की कतार को देखते हैं और निम्नलिखित देखते हैं: उपयोगकर्ता ए ने पृष्ठ का दौरा किया। इस उपयोगकर्ता से 5 और घटनाएं आती हैं - प्रत्येक एक पृष्ठ खोलने का संकेत देता है। हम प्रत्येक ईवेंट को उपयोगकर्ता से संसाधित करते हैं। लेकिन वास्तव में, HBase में डेटा में सभी 5 विज़िट शामिल हैं। हम पहली बार, दूसरी बार सभी 5 यात्राओं की प्रक्रिया करते हैं, और इसी तरह - हम सीपीयू संसाधनों को बर्बाद कर रहे हैं।
हम देखने लगे कि क्या हो रहा है। इंटरनेट पर एक विशिष्ट उपयोगकर्ता व्यवहार किसी वेबसाइट पर जाने और कई पृष्ठभूमि टैब खोलने के लिए है। दूसरे को साइट पर जाना है और लैंडिंग पृष्ठ पर पहुंचने के लिए कुछ क्लिक करना है।हम विभाजन की कतार को देखते हैं और निम्नलिखित देखते हैं: उपयोगकर्ता ए ने पृष्ठ का दौरा किया। इस उपयोगकर्ता से 5 और घटनाएं आती हैं - प्रत्येक एक पृष्ठ खोलने का संकेत देता है। हम प्रत्येक ईवेंट को उपयोगकर्ता से संसाधित करते हैं। लेकिन वास्तव में, HBase में डेटा में सभी 5 विज़िट शामिल हैं। हम पहली बार, दूसरी बार सभी 5 यात्राओं की प्रक्रिया करते हैं, और इसी तरह - हम सीपीयू संसाधनों को बर्बाद कर रहे हैं।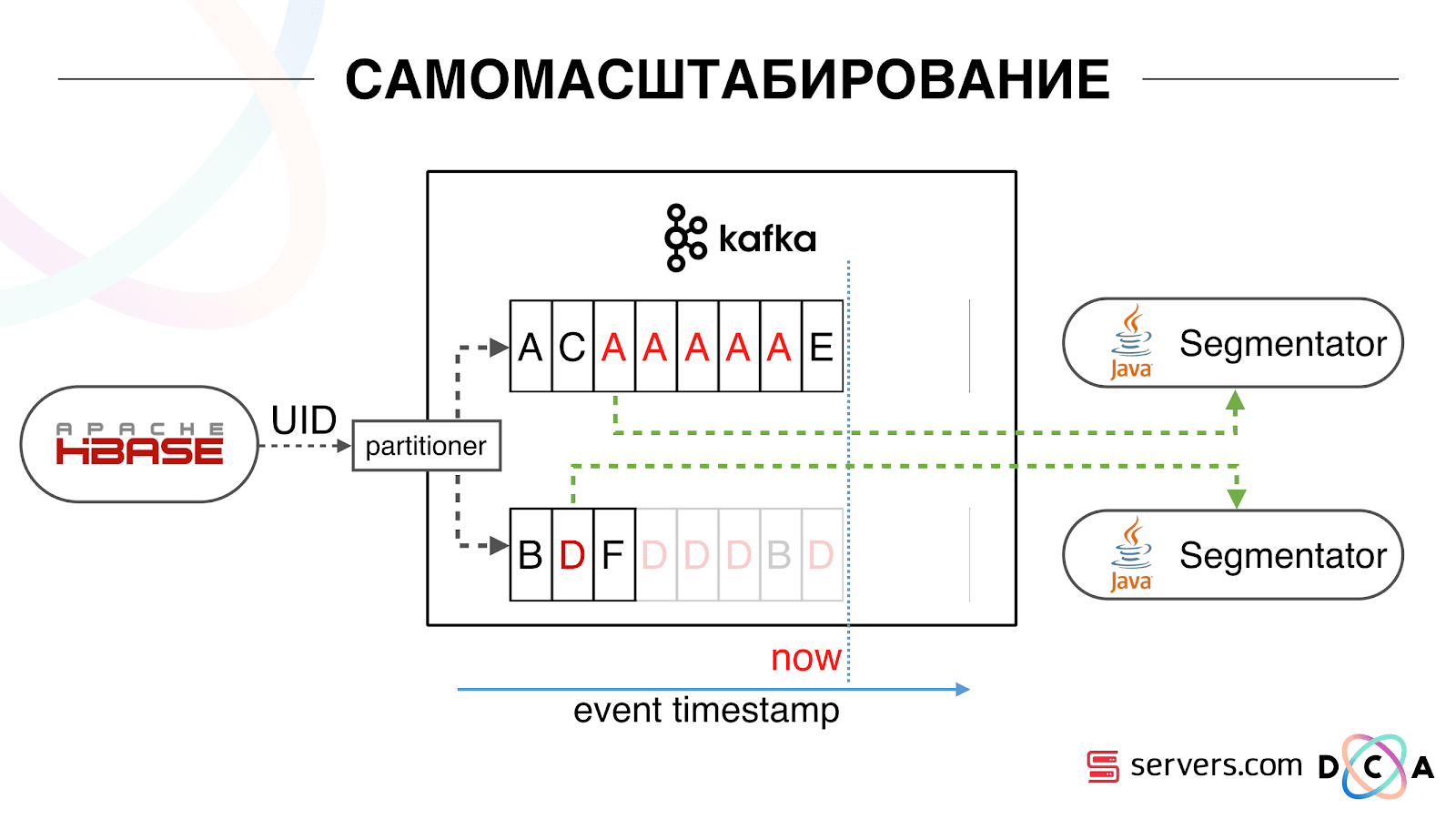 इसलिए, जब हमने पिछली बार इस उपयोगकर्ता का विश्लेषण किया था, तो हमने तारीख के साथ प्रत्येक सेगमेंट पर एक निश्चित स्थानीय कैश संग्रहीत करना शुरू किया था। यही है, हमने इसे संसाधित किया, इसके उपयोगकर्ता और कैश के लिए टाइमस्टैम्प लिखा। प्रत्येक काफ़्का संदेश में एक टाइमस्टैम्प भी होता है - हम बस इसकी तुलना करते हैं: यदि कतार में टाइमस्टैम्प अंतिम विभाजन की तारीख से कम है - हमने पहले ही इन डेटा के लिए उपयोगकर्ता का विश्लेषण किया है, और आप बस इस घटना को छोड़ सकते हैं।उपयोगकर्ता ईवेंट (रेड ए) अलग हो सकते हैं, और वे क्रम से बाहर जाते हैं। उपयोगकर्ता कई पृष्ठभूमि टैब खोल सकता है, एक पंक्ति में कई लिंक खोल सकता है, हो सकता है कि साइट में हमारे कई भागीदार एक साथ हों, जिनमें से प्रत्येक अपना डेटा भेजता है।हमारा पिक्सेल उपयोगकर्ता की यात्रा को देख सकता है, और फिर कुछ अन्य कार्रवाई कर सकता है - हम अपना हेलमेट खुद भेजेंगे। पांच ईवेंट्स आते हैं, हम पहले रेड ए को प्रोसेस कर रहे हैं। अगर इवेंट आ गया है, तो यह पहले से ही HBase में है। हम घटनाओं को देखते हैं, स्क्रिप्ट के एक सेट के माध्यम से चलाते हैं। हम निम्नलिखित घटना को देखते हैं, और वहां सभी समान घटनाएं होती हैं, क्योंकि वे पहले से ही दर्ज हैं। हम इसे फिर से चलाते हैं और तारीख के साथ कैश को बचाते हैं, इसे घटना के टाइमस्टैम्प के साथ तुलना करते हैं।
इसलिए, जब हमने पिछली बार इस उपयोगकर्ता का विश्लेषण किया था, तो हमने तारीख के साथ प्रत्येक सेगमेंट पर एक निश्चित स्थानीय कैश संग्रहीत करना शुरू किया था। यही है, हमने इसे संसाधित किया, इसके उपयोगकर्ता और कैश के लिए टाइमस्टैम्प लिखा। प्रत्येक काफ़्का संदेश में एक टाइमस्टैम्प भी होता है - हम बस इसकी तुलना करते हैं: यदि कतार में टाइमस्टैम्प अंतिम विभाजन की तारीख से कम है - हमने पहले ही इन डेटा के लिए उपयोगकर्ता का विश्लेषण किया है, और आप बस इस घटना को छोड़ सकते हैं।उपयोगकर्ता ईवेंट (रेड ए) अलग हो सकते हैं, और वे क्रम से बाहर जाते हैं। उपयोगकर्ता कई पृष्ठभूमि टैब खोल सकता है, एक पंक्ति में कई लिंक खोल सकता है, हो सकता है कि साइट में हमारे कई भागीदार एक साथ हों, जिनमें से प्रत्येक अपना डेटा भेजता है।हमारा पिक्सेल उपयोगकर्ता की यात्रा को देख सकता है, और फिर कुछ अन्य कार्रवाई कर सकता है - हम अपना हेलमेट खुद भेजेंगे। पांच ईवेंट्स आते हैं, हम पहले रेड ए को प्रोसेस कर रहे हैं। अगर इवेंट आ गया है, तो यह पहले से ही HBase में है। हम घटनाओं को देखते हैं, स्क्रिप्ट के एक सेट के माध्यम से चलाते हैं। हम निम्नलिखित घटना को देखते हैं, और वहां सभी समान घटनाएं होती हैं, क्योंकि वे पहले से ही दर्ज हैं। हम इसे फिर से चलाते हैं और तारीख के साथ कैश को बचाते हैं, इसे घटना के टाइमस्टैम्प के साथ तुलना करते हैं। इसके लिए धन्यवाद, सिस्टम ने स्व-स्केलेबिलिटी की संपत्ति प्राप्त की। वाई-एक्सिस का प्रतिशत है जो हम उपयोगकर्ता आईडी के साथ करते हैं जब वे हमारे पास आते हैं। ग्रीन - हमने जो काम किया, उसने विभाजन स्क्रिप्ट लॉन्च की। पीला - हमने ऐसा नहीं किया, क्योंकि पहले से ही वास्तव में इस डेटा खंड।
इसके लिए धन्यवाद, सिस्टम ने स्व-स्केलेबिलिटी की संपत्ति प्राप्त की। वाई-एक्सिस का प्रतिशत है जो हम उपयोगकर्ता आईडी के साथ करते हैं जब वे हमारे पास आते हैं। ग्रीन - हमने जो काम किया, उसने विभाजन स्क्रिप्ट लॉन्च की। पीला - हमने ऐसा नहीं किया, क्योंकि पहले से ही वास्तव में इस डेटा खंड।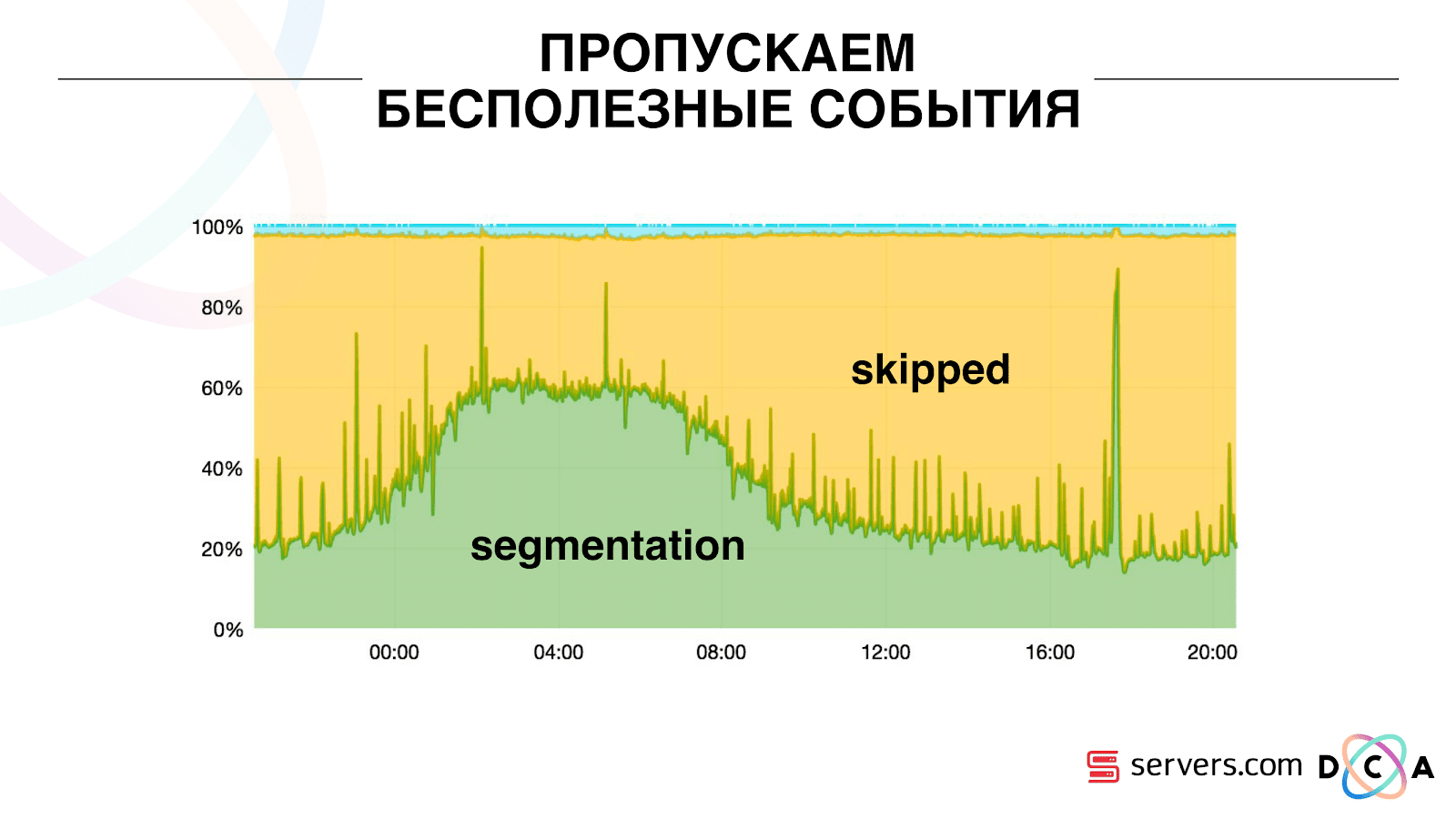 यह देखा जा सकता है कि रात में संसाधन हैं, डेटा प्रवाह कम है, और आप हर दूसरे ईवेंट को खंडित कर सकते हैं। एक छोटा संसाधन दिन, और हम घटनाओं का केवल 20% खंड करते हैं। दिन के अंत में एक कूद - साथी ने डेटा फाइलें अपलोड कीं जो हमने पहले नहीं देखी थीं, और उन्हें "ईमानदारी से" खंडित होना पड़ा।विकास को लोड करने के लिए सिस्टम ही पालन करता है। यदि हमारे पास एक बहुत बड़ा साथी है, तो हम एक ही डेटा को संसाधित करते हैं, लेकिन थोड़ा कम अक्सर। इस मामले में, शाम को सिस्टम की विशेषताओं में गिरावट होगी, विभाजन 2-3 सेकंड के लिए नहीं, बल्कि एक मिनट के लिए देरी होगी। सुबह में, सर्वर जोड़ें और वांछित परिणाम पर वापस लौटें।इस प्रकार, हमने सर्वरों पर लगभग 5 बार बचाया। अब हम 10 सर्वरों पर काम करते हैं, और इसलिए यह 50-60 होगा।शीर्ष पर छोटी नीली चीज बॉट्स है। यह विभाजन का सबसे कठिन हिस्सा है। उनके पास बड़ी संख्या में दौरे हैं, वे लोहे पर एक बहुत बड़ा भार बनाते हैं। हम प्रत्येक बॉट को एक अलग सर्वर पर देखते हैं। हम उस पर बॉट की एक काली सूची के साथ एक स्थानीय कैश एकत्र कर सकते हैं। एक साधारण एंटीफ्रॉड पेश किया: यदि उपयोगकर्ता एक निश्चित समय के लिए बहुत अधिक विज़िट करता है, तो उसके साथ कुछ गलत है, हम थोड़ी देर के लिए ब्लैकलिस्ट में जोड़ते हैं। यह थोड़ी नीली पट्टी है, लगभग 5%। उन्होंने हमें सीपीयू पर 30% की और बचत दी।इस प्रकार, हमने वह हासिल किया है जो हम प्रत्येक चरण में डेटा प्रोसेसिंग की पूरी पाइपलाइन को देखते हैं। कफका में संदेश कितना था, इसके मेट्रिक्स हम देखते हैं। शाम में, कुछ कहीं सुस्त हो गया, प्रसंस्करण समय एक मिनट तक बढ़ गया, फिर इसे जारी किया गया और सामान्य पर लौट आया।
यह देखा जा सकता है कि रात में संसाधन हैं, डेटा प्रवाह कम है, और आप हर दूसरे ईवेंट को खंडित कर सकते हैं। एक छोटा संसाधन दिन, और हम घटनाओं का केवल 20% खंड करते हैं। दिन के अंत में एक कूद - साथी ने डेटा फाइलें अपलोड कीं जो हमने पहले नहीं देखी थीं, और उन्हें "ईमानदारी से" खंडित होना पड़ा।विकास को लोड करने के लिए सिस्टम ही पालन करता है। यदि हमारे पास एक बहुत बड़ा साथी है, तो हम एक ही डेटा को संसाधित करते हैं, लेकिन थोड़ा कम अक्सर। इस मामले में, शाम को सिस्टम की विशेषताओं में गिरावट होगी, विभाजन 2-3 सेकंड के लिए नहीं, बल्कि एक मिनट के लिए देरी होगी। सुबह में, सर्वर जोड़ें और वांछित परिणाम पर वापस लौटें।इस प्रकार, हमने सर्वरों पर लगभग 5 बार बचाया। अब हम 10 सर्वरों पर काम करते हैं, और इसलिए यह 50-60 होगा।शीर्ष पर छोटी नीली चीज बॉट्स है। यह विभाजन का सबसे कठिन हिस्सा है। उनके पास बड़ी संख्या में दौरे हैं, वे लोहे पर एक बहुत बड़ा भार बनाते हैं। हम प्रत्येक बॉट को एक अलग सर्वर पर देखते हैं। हम उस पर बॉट की एक काली सूची के साथ एक स्थानीय कैश एकत्र कर सकते हैं। एक साधारण एंटीफ्रॉड पेश किया: यदि उपयोगकर्ता एक निश्चित समय के लिए बहुत अधिक विज़िट करता है, तो उसके साथ कुछ गलत है, हम थोड़ी देर के लिए ब्लैकलिस्ट में जोड़ते हैं। यह थोड़ी नीली पट्टी है, लगभग 5%। उन्होंने हमें सीपीयू पर 30% की और बचत दी।इस प्रकार, हमने वह हासिल किया है जो हम प्रत्येक चरण में डेटा प्रोसेसिंग की पूरी पाइपलाइन को देखते हैं। कफका में संदेश कितना था, इसके मेट्रिक्स हम देखते हैं। शाम में, कुछ कहीं सुस्त हो गया, प्रसंस्करण समय एक मिनट तक बढ़ गया, फिर इसे जारी किया गया और सामान्य पर लौट आया। हम मॉनिटर कर सकते हैं कि सिस्टम के साथ हमारे कार्य इसके थ्रूपुट को कैसे प्रभावित करते हैं, हम देख सकते हैं कि स्क्रिप्ट कितनी चल रही है, जहां अनुकूलन करना आवश्यक है, और कितना बचाया जा सकता है। हम खंडों के आकार, खंडों के आकार की गतिशीलता, उनके संघ और चौराहे का मूल्यांकन कर सकते हैं। यह कम या ज्यादा समान आकार के लिए किया जा सकता है।
हम मॉनिटर कर सकते हैं कि सिस्टम के साथ हमारे कार्य इसके थ्रूपुट को कैसे प्रभावित करते हैं, हम देख सकते हैं कि स्क्रिप्ट कितनी चल रही है, जहां अनुकूलन करना आवश्यक है, और कितना बचाया जा सकता है। हम खंडों के आकार, खंडों के आकार की गतिशीलता, उनके संघ और चौराहे का मूल्यांकन कर सकते हैं। यह कम या ज्यादा समान आकार के लिए किया जा सकता है।आप क्या निखारना चाहेंगे?
हमारे पास कुछ कंप्यूटिंग संसाधनों के साथ एक Hadoop क्लस्टर है। वह व्यस्त है - विश्लेषक दिन के दौरान उस पर काम करते हैं, लेकिन रात में वह व्यावहारिक रूप से स्वतंत्र है। सामान्य तौर पर, हम अपने क्लस्टर के भीतर एक अलग प्रक्रिया के रूप में सेगमेंट को कंटेनरीकृत और चला सकते हैं। हम अधिक सटीक रूप से आँकड़ों को संग्रहीत करना चाहते हैं ताकि चौराहे की मात्रा की सही गणना हो सके। हमें सीपीयू पर अनुकूलन की भी आवश्यकता है। यह सीधे निर्णय की लागत को प्रभावित करता है।संक्षेप में: कफ़्का अच्छा है, लेकिन, किसी भी अन्य तकनीक की तरह, आपको यह समझने की आवश्यकता है कि यह अंदर कैसे काम करता है और इसके साथ क्या होता है। उदाहरण के लिए, संदेश प्राथमिकता गारंटी केवल विभाजन के अंदर काम करती है। यदि आप एक संदेश भेजते हैं जो विभिन्न विभाजनों में जाता है, तो यह स्पष्ट नहीं है कि उन्हें किस क्रम में संसाधित किया जाएगा।वास्तविक डेटा बहुत महत्वपूर्ण है। यदि हमने वास्तविक ट्रैफ़िक पर परीक्षण नहीं किया है, तो सबसे अधिक संभावना है कि हम उपयोगकर्ता सत्रों के साथ बॉट की समस्याओं को नहीं देखेंगे। शून्य में कुछ विकसित करेगा, दौड़ कर लेट जाएगा। यह मॉनिटर करना महत्वपूर्ण है कि आप निगरानी के लिए क्या आवश्यक मानते हैं, और यह निगरानी करने के लिए नहीं कि आप क्या सोचते हैं।विज्ञापन का मिनट। अगर आपको स्मार्टडाटा सम्मेलन की यह रिपोर्ट पसंद आई, तो कृपया ध्यान दें कि स्मार्टडाटा 2018 15 अक्टूबर को सेंट पीटर्सबर्ग में आयोजित किया जाएगा, जो मशीन लर्निंग, विश्लेषण और डेटा प्रोसेसिंग की दुनिया में डूबे हुए लोगों के लिए एक सम्मेलन है। कार्यक्रम में बहुत सारी दिलचस्प चीजें होंगी, साइट पर पहले से ही अपने स्पीकर और रिपोर्ट हैं।