 तीसरी पीढ़ी का टेंसर प्रोसेसरGoogle Tensor Processor
तीसरी पीढ़ी का टेंसर प्रोसेसरGoogle Tensor Processor एक विशेष प्रयोजन एकीकृत परिपथ (
ASIC ) है, जो मशीन द्वारा सीखने के कार्यों को करने के लिए Google द्वारा जमीन से विकसित किया गया है। वह कई प्रमुख Google उत्पादों पर काम करता है, जिसमें अनुवाद, फोटो, खोज सहायक और जीमेल शामिल हैं। क्लाउड टीपीयू उन सभी डेवलपर्स और डेटा वैज्ञानिकों को स्केलबिलिटी और उपयोग में आसानी का लाभ देता है जो Google क्लाउड में अत्याधुनिक मशीन लर्निंग मॉडल लॉन्च करते हैं। Google नेक्स्ट '18 पर, हमने घोषणा की कि क्लाउड टीपीयू वी 2 अब सभी उपयोगकर्ताओं के लिए उपलब्ध है, जिसमें
नि: शुल्क परीक्षण खाते शामिल हैं , और क्लाउड टीपीयू वी 3 अल्फा परीक्षण के लिए उपलब्ध है।

लेकिन कई लोग पूछते हैं - सीपीयू, जीपीयू और टीपीयू में क्या अंतर है? हमने एक
डेमो साइट बनाई जहां प्रस्तुति और एनीमेशन स्थित हैं जो इस प्रश्न का उत्तर देते हैं। इस पोस्ट में, मैं इस साइट की सामग्री की कुछ विशेषताओं पर ध्यान देना चाहूंगा।
तंत्रिका नेटवर्क कैसे काम करते हैं?
सीपीयू, जीपीयू और टीपीयू की तुलना करना शुरू करने से पहले, आइए देखें कि मशीन लर्निंग के लिए किस तरह की गणना आवश्यक है - और विशेष रूप से, तंत्रिका नेटवर्क के लिए।
उदाहरण के लिए, कल्पना करें कि हम हस्तलिखित संख्याओं को पहचानने के लिए एकल-परत तंत्रिका नेटवर्क का उपयोग करते हैं, जैसा कि निम्नलिखित चित्र में दिखाया गया है:
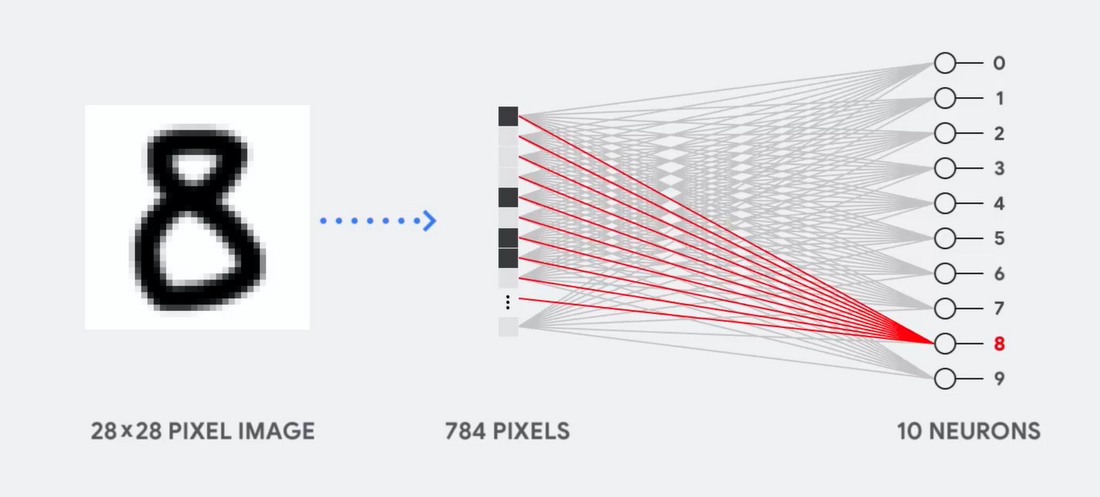
यदि चित्र ग्रे स्केल में 28x28 पिक्सेल का ग्रिड है, तो इसे 784 मान (माप) के वेक्टर में परिवर्तित किया जा सकता है। एक न्यूरॉन जो संख्या 8 को पहचानता है, इन मूल्यों को लेता है और उन्हें पैरामीटर मान (आरेख में लाल रेखाओं) से गुणा करता है।
पैरामीटर एक फिल्टर के रूप में काम करता है, डेटा की विशेषताओं को निकालता है जो छवि और आकार 8 की समानता को दर्शाता है:

तंत्रिका नेटवर्क द्वारा डेटा के वर्गीकरण का यह सबसे सरल स्पष्टीकरण है। उनके अनुरूप मापदंडों के साथ डेटा का गुणन (अंकों का रंग) और उनका जोड़ (दाईं ओर बिंदुओं का योग)। उच्चतम परिणाम दर्ज किए गए डेटा और संबंधित पैरामीटर के बीच सबसे अच्छा मैच इंगित करता है, जो कि, सबसे अधिक संभावना है, सही उत्तर होगा।
सीधे शब्दों में कहें, तो तंत्रिका नेटवर्क को डेटा और मापदंडों के कई गुणा और परिवर्धन करने की आवश्यकता है। अक्सर हम उन्हें
मैट्रिक्स गुणा के रूप में व्यवस्थित करते हैं, जिसे आप स्कूल में बीजगणित में सामना कर सकते हैं। इसलिए, समस्या यह है कि जितनी जल्दी हो सके बड़ी संख्या में मैट्रिक्स गुणा करना, जितना संभव हो उतना कम ऊर्जा खर्च करना।
सीपीयू कैसे काम करता है?
सीपीयू इस कार्य को कैसे करता है? सीपीयू
वॉन न्यूमैन आर्किटेक्चर पर आधारित एक सामान्य-प्रयोजन प्रोसेसर है। इसका मतलब है कि CPU सॉफ्टवेयर और मेमोरी के साथ काम करता है:
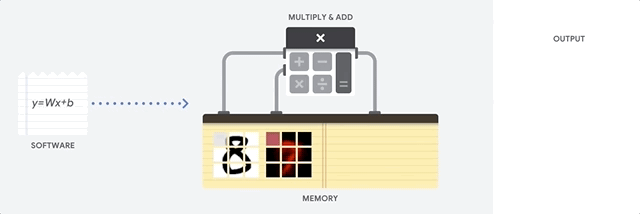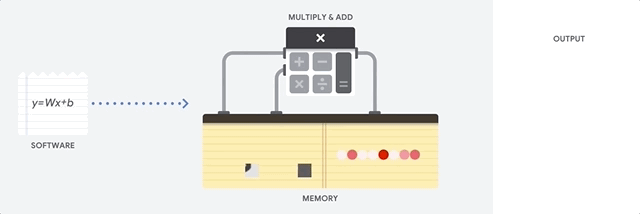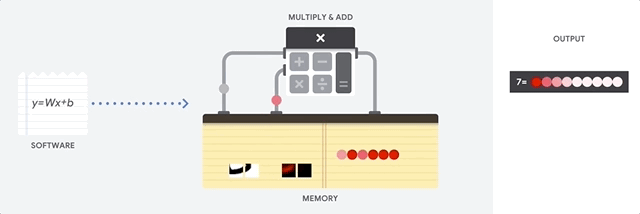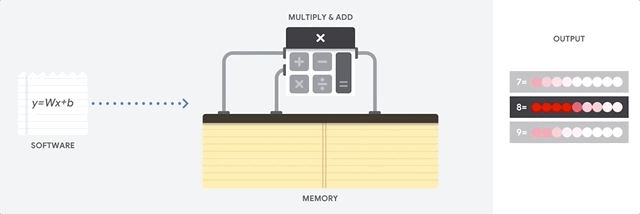
CPU का मुख्य लाभ लचीलापन है। वॉन न्यूमैन वास्तुकला के लिए धन्यवाद, आप लाखों विभिन्न प्रयोजनों के लिए पूरी तरह से अलग सॉफ्टवेयर डाउनलोड कर सकते हैं। सीपीयू का उपयोग शब्द प्रसंस्करण, रॉकेट इंजन नियंत्रण, बैंक लेनदेन, एक न्यूरल नेटवर्क का उपयोग करके छवि वर्गीकरण के लिए किया जा सकता है।
लेकिन चूंकि सीपीयू इतना लचीला है, इसलिए उपकरण को पहले से पता नहीं होता है कि सॉफ्टवेयर से अगला निर्देश पढ़ने तक अगला ऑपरेशन क्या होगा। सीपीयू को सीपीयू (तथाकथित रजिस्टरों, या
एल 1 कैश ) के अंदर स्थित मेमोरी में प्रत्येक गणना के परिणामों को संग्रहीत करने की आवश्यकता होती है। इस स्मृति तक पहुंच सीपीयू वास्तुकला का एक शून्य बन जाता है, जिसे वॉन न्यूमैन वास्तुकला अड़चन के रूप में जाना जाता है। और यद्यपि तंत्रिका नेटवर्क के लिए भारी मात्रा में गणना भविष्य के कदमों का अनुमान लगाती है, प्रत्येक CPU (ALU, एक घटक जो मल्टीप्लायरों और योजक को नियंत्रित करता है) के
अंकगणितीय तर्क उपकरण को क्रमिक रूप से निष्पादित करता है, हर बार स्मृति तक पहुंचता है, जो समग्र थ्रूपुट को सीमित करता है और ऊर्जा की एक महत्वपूर्ण मात्रा का उपभोग करता है। ।
GPU कैसे काम करता है
CPU की तुलना में थ्रूपुट को बढ़ाने के लिए, GPU एक सरल रणनीति का उपयोग करता है: प्रोसेसर में हजारों ALU को एकीकृत क्यों नहीं किया जाता है? आधुनिक GPU में प्रोसेसर पर लगभग 2500 - 5000 ALU होते हैं, जो एक बार में हजारों गुणा और परिवर्धन करने के लिए संभव बनाता है।

इस तरह की वास्तुकला बड़े पैमाने पर समानांतरकरण की आवश्यकता वाले अनुप्रयोगों के साथ अच्छी तरह से काम करती है, जैसे कि, उदाहरण के लिए, तंत्रिका नेटवर्क में मैट्रिक्स गुणन। डीप लर्निंग (जीओ) के विशिष्ट प्रशिक्षण भार के साथ, इस मामले में सीपीयू की तुलना में परिमाण के एक क्रम से थ्रूपुट बढ़ता है। इसलिए, आज जीपीओ जीओ के लिए सबसे लोकप्रिय प्रोसेसर आर्किटेक्चर है।
लेकिन GPU अभी भी एक सामान्य-उद्देश्य वाला प्रोसेसर बना हुआ है, जिसे एक लाख विभिन्न अनुप्रयोगों और सॉफ्टवेयर का समर्थन करना चाहिए। और यह हमें वॉन न्यूमैन आर्किटेक्चर की अड़चन की मूलभूत समस्या को वापस लाता है। हजारों एएलयू, जीपीयू में प्रत्येक गणना के लिए, मध्यवर्ती गणना परिणामों को पढ़ने और सहेजने के लिए रजिस्टरों या साझा मेमोरी को संदर्भित करना आवश्यक है। क्योंकि GPU अपने ALU के हजारों पर अधिक समानांतर कंप्यूटिंग करता है, यह भी मेमोरी एक्सेस पर आनुपातिक रूप से अधिक ऊर्जा खर्च करता है और एक बड़ा क्षेत्र लेता है।
TPU कैसे काम करता है?
जब हमने Google में TPU विकसित किया, तो हमने एक विशिष्ट कार्य के लिए डिज़ाइन किया गया एक आर्किटेक्चर बनाया। सामान्य-प्रयोजन प्रोसेसर विकसित करने के बजाय, हमने एक मैट्रिक्स प्रोसेसर विकसित किया जो तंत्रिका नेटवर्क के साथ काम करने के लिए विशेष है। टीपीयू एक शब्द प्रोसेसर के साथ काम करने, रॉकेट इंजन को नियंत्रित करने या बैंकिंग लेनदेन करने में सक्षम नहीं होगा, लेकिन यह एक अविश्वसनीय गति से तंत्रिका नेटवर्क के लिए कई गुणा और परिवर्धन की प्रक्रिया कर सकता है, जबकि बहुत कम ऊर्जा की खपत और एक छोटी भौतिक मात्रा में फिटिंग।
मुख्य चीज जो उसे ऐसा करने की अनुमति देती है वह वॉन न्यूमैन वास्तुकला की अड़चन का कट्टरपंथी उन्मूलन है। चूंकि टीपीयू का मुख्य कार्य मैट्रिक्स प्रसंस्करण है, सर्किट डेवलपर्स सभी आवश्यक गणना चरणों से परिचित थे। इसलिए, वे हजारों गुणक और योजक रखने में सक्षम थे, और एक बड़े भौतिक मैट्रिक्स का निर्माण करते हुए, उन्हें भौतिक रूप से जोड़ते थे। इसे
पाइपलाइन्ड ऐरे आर्किटेक्चर कहा जाता है। क्लाउड टीपीयू वी 2 के मामले में, 128 x 128 के दो पाइपलाइन सरणियों का उपयोग किया जाता है, जो कुल मिलाकर एक प्रोसेसर पर 16-बिट फ्लोटिंग-पॉइंट मानों के लिए 32,768 ALU देता है।
आइए देखें कि एक पाइपलाइन नेटवर्क एक तंत्रिका नेटवर्क के लिए गणना कैसे करता है। सबसे पहले, टीपीयू मापदंडों को मेमोरी से मल्टीप्लायरों और योजक के मैट्रिक्स में लोड करता है।

तब टीपीयू मेमोरी से डेटा लोड करता है। प्रत्येक गुणन के पूरा होने पर, परिणाम निम्नलिखित कारकों को प्रेषित किया जाता है, जबकि परिवर्धन करते हुए। इसलिए, आउटपुट डेटा और मापदंडों के सभी गुणा का योग होगा। वॉल्यूमेट्रिक कंप्यूटिंग और डेटा ट्रांसफर की प्रक्रिया के दौरान, मेमोरी तक पहुंच पूरी तरह से अनावश्यक है।
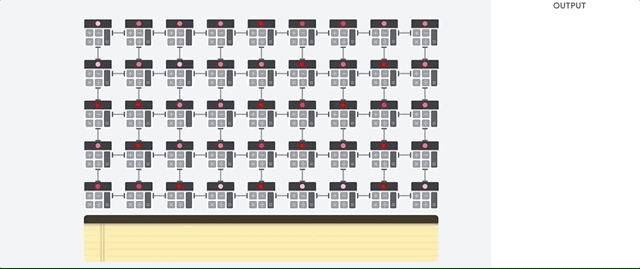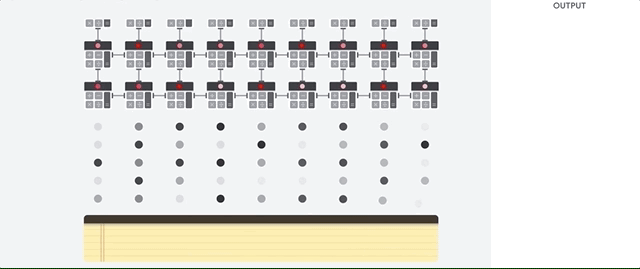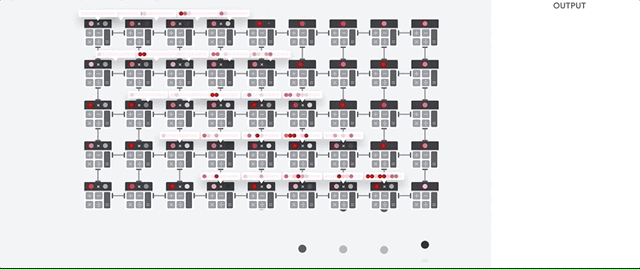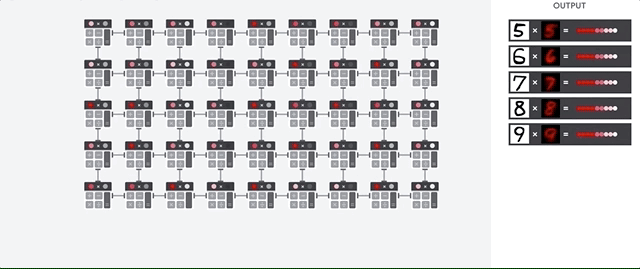
इसलिए, टीपीयू तंत्रिका नेटवर्क की गणना करते समय अधिक थ्रूपुट प्रदर्शित करता है, बहुत कम ऊर्जा की खपत करता है और कम जगह लेता है।
फायदा: 5 गुना कम लागत
टीपीयू वास्तुकला के लाभ क्या हैं? लागत। यहाँ अगस्त 2018 के लिए क्लाउड टीपीयू v2 की लागत, लेखन के समय है:
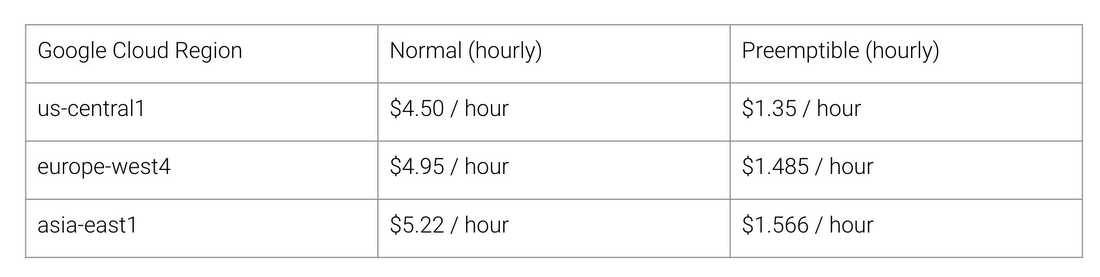
Google क्लाउड के विभिन्न क्षेत्रों के लिए सामान्य और TPU कार्य की लागत
स्टैनफोर्ड विश्वविद्यालय
डीएएनबेंच परीक्षणों का एक सेट वितरित कर रहा है जो गहन शिक्षण प्रणालियों के प्रदर्शन को मापता है। वहां आप कार्यों, मॉडलों और कंप्यूटिंग प्लेटफार्मों के विभिन्न संयोजनों, साथ ही संबंधित परीक्षण परिणामों को देख सकते हैं।
अप्रैल 2018 में प्रतियोगिता के अंत में, TPU के अलावा अन्य आर्किटेक्चर के साथ प्रोसेसर पर न्यूनतम प्रशिक्षण लागत $ 72.40 (
स्पॉट इंस्टैंस पर ImageNet पर 93% सटीकता के साथ ResNet-50 के प्रशिक्षण के
लिए ) थी। क्लाउड टीपीयू वी 2 के साथ, यह प्रशिक्षण $ 12.87 के लिए किया जा सकता है। यह लागत का 1/5 से कम है। यह विशेष रूप से तंत्रिका नेटवर्क के लिए डिज़ाइन की गई वास्तुकला की शक्ति है।