
दुर्भाग्य से इंटरनेट पर वास्तविक अनुप्रयोगों के प्रवास और पेरकोना XtraDB क्लस्टर (इसके बाद PXC) के उत्पादन संचालन के बारे में पर्याप्त जानकारी नहीं है। मैं इस स्थिति को ठीक करने की कोशिश करूंगा और अपनी कहानी के साथ अपने अनुभव के बारे में बताऊंगा। कोई चरण-दर-चरण इंस्टॉलेशन निर्देश नहीं होगा और लेख को ऑफ-डॉक्यूमेंटेशन के लिए प्रतिस्थापन के रूप में नहीं माना जाना चाहिए, लेकिन सिफारिशों के संग्रह के रूप में।
समस्या
मैं
अल्टिमेटरी डॉट कॉम पर सिस्टम एडमिनिस्ट्रेटर के रूप में काम करता हूं। चूंकि हम एक वेब सेवा प्रदान करते हैं, हमारे पास स्वाभाविक रूप से बैकएंड और एक डेटाबेस है, जो सेवा का मूल है। सेवा अपटाइम सीधे डेटाबेस के प्रदर्शन पर निर्भर करता है।
Percona MySQL 5.7 का उपयोग डेटाबेस के रूप में किया गया था। मास्टर प्रतिकृति योजना मास्टर का उपयोग करके आरक्षण लागू किया गया था। कुछ डेटा पढ़ने के लिए दासों का उपयोग किया गया था।
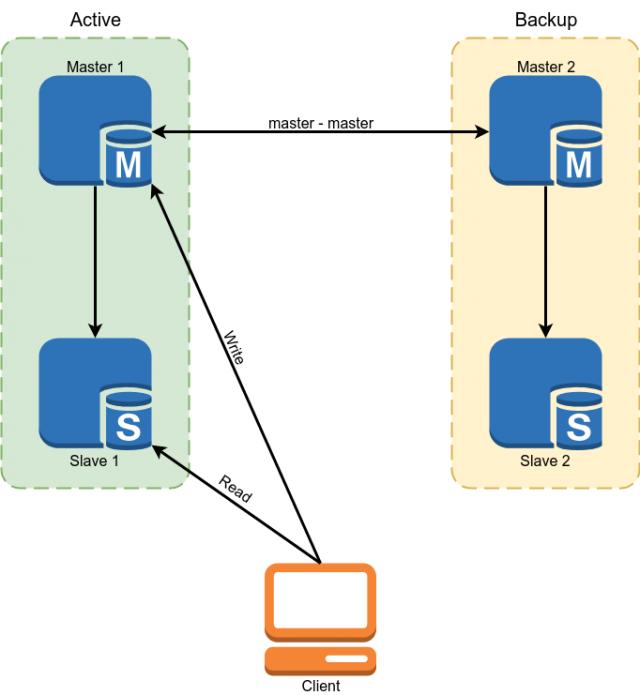
लेकिन यह योजना हमें निम्नलिखित नुकसानों के अनुकूल नहीं थी:
- इस तथ्य के कारण कि MySQL प्रतिकृति में, अतुल्यकालिक दास अनिश्चित काल तक पिछड़ सकते थे। सभी महत्वपूर्ण डेटा को मास्टर से पढ़ना पड़ता था।
- पिछले पैराग्राफ से विकास की जटिलता का अनुसरण करता है। डेवलपर डेटाबेस के लिए केवल एक अनुरोध नहीं कर सकता था, लेकिन यह सोचने के लिए बाध्य था कि क्या वह प्रत्येक विशेष मामले में दास के बैकलॉग के लिए तैयार था और यदि नहीं, तो विज़ार्ड के डेटा को पढ़ें।
- दुर्घटना की स्थिति में मैनुअल स्विचिंग। स्वचालित स्विचिंग को लागू करना इस तथ्य के कारण समस्याग्रस्त था कि MySQL वास्तुकला में विभाजित मस्तिष्क के खिलाफ अंतर्निहित सुरक्षा नहीं है। हमें खुद को एक मास्टर चुनने के जटिल तर्क के साथ एक मध्यस्थ लिखना होगा। दोनों मास्टर्स को लिखते समय, एक ही समय में टकराव पैदा हो सकता है, मास्टर प्रतिकृति को तोड़कर क्लासिक विभाजन मस्तिष्क तक ले जा सकता है।
कुछ सूखे नंबर, ताकि आप समझ सकें कि हमने क्या काम किया है:
डेटाबेस का आकार: 300 जीबी
QPS: ~ 10k
आरडब्ल्यू अनुपात: 96/4%
मास्टर सर्वर कॉन्फ़िगरेशन:
CPU: 2x E5-2620 v3
रैम: 128 जीबी
SSD: Intel Optane 905p 960 Gb
नेटवर्क: 1 जीबीपीएस
हमारे पास बहुत सारे पढ़ने के साथ एक क्लासिक ओएलटीपी लोड है, जिसे बहुत जल्दी और थोड़ी मात्रा में लेखन के साथ करने की आवश्यकता है। डेटाबेस पर लोड इस तथ्य के कारण काफी छोटा है कि रेडिस और मेमकेच्ड में कैशिंग सक्रिय रूप से उपयोग किया जाता है।
निर्णय लेना
जैसा कि आप शीर्षक से अनुमान लगा सकते हैं, हमने पीएक्ससी को चुना, लेकिन यहां मैं बताऊंगा कि हमने इसे क्यों चुना।
हमारे पास 4 विकल्प थे:
- DBMS बदलें
- MySQL ग्रुप प्रतिकृति
- मास्टर प्रतिकृति मास्टर के शीर्ष पर स्क्रिप्ट का उपयोग करके आवश्यक कार्यक्षमता को स्वयं स्क्रू करें।
- MySQL Galera क्लस्टर (या इसके कांटे, उदाहरण के लिए PXC)
डेटाबेस को बदलने के विकल्प को व्यावहारिक रूप से नहीं माना गया, क्योंकि अनुप्रयोग बड़ा है, कई स्थानों पर यह mysql कार्यक्षमता या सिंटैक्स से बंधा हुआ है, और PostgreSQL में माइग्रेशन, उदाहरण के लिए, बहुत समय और संसाधन लेगा।
दूसरा विकल्प MySQL Group Replication था। इसका एक निस्संदेह लाभ यह है कि यह MySQL की वैनिला शाखा में विकसित होता है, जिसका अर्थ है कि भविष्य में यह व्यापक हो जाएगा और सक्रिय उपयोगकर्ताओं का एक बड़ा पूल होगा।
लेकिन उसकी कुछ कमियां हैं। सबसे पहले, यह एप्लिकेशन और डेटाबेस स्कीमा पर अधिक प्रतिबंध लगाता है, जिसका अर्थ है कि माइग्रेट करना अधिक कठिन होगा। दूसरा, समूह प्रतिकृति दोष सहिष्णुता और विभाजित मस्तिष्क के मुद्दे को हल करती है, लेकिन क्लस्टर में प्रतिकृति अभी भी अतुल्यकालिक है।
हमें कई साइकिलों के लिए तीसरा विकल्प भी पसंद नहीं था, जिसे इस तरह से समस्या को हल करते समय हमें अनिवार्य रूप से लागू करना होगा।
गैलरा ने MySQL विफलता समस्या को पूरी तरह से हल करने की अनुमति दी और दासों पर डेटा की प्रासंगिकता के साथ समस्या को आंशिक रूप से हल किया। आंशिक रूप से क्योंकि प्रतिकृति अतुल्यकालिक बनाए रखी जाती है। लेन-देन स्थानीय नोड पर किए जाने के बाद, परिवर्तनों को असमान रूप से शेष नोड्स पर धकेल दिया जाता है, लेकिन क्लस्टर यह सुनिश्चित करता है कि नोड्स बहुत अधिक नहीं हैं और यदि वे अंतराल शुरू करते हैं, तो यह कृत्रिम रूप से काम को धीमा कर देता है। क्लस्टर यह सुनिश्चित करता है कि लेनदेन करने के बाद कोई भी उस नोड पर भी परस्पर विरोधी परिवर्तन नहीं कर सकता है जिसने अभी तक परिवर्तनों को दोहराया नहीं है।
माइग्रेशन के बाद, डेटाबेस ऑपरेशन स्कीम इस तरह दिखना चाहिए:
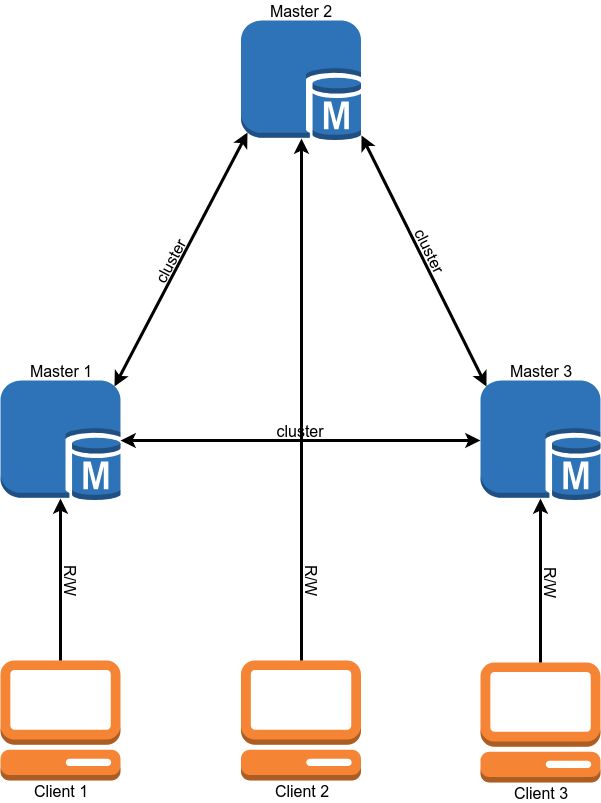
प्रवास
समाधान चुनने के बाद दूसरा आइटम क्यों माइग्रेट किया जाता है? यह सरल है - क्लस्टर में कई आवश्यकताएं हैं जो एप्लिकेशन और डेटाबेस का पालन करना चाहिए, और प्रवास से पहले हमें उन्हें पूरा करना होगा।
- सभी तालिकाओं के लिए InnoDB इंजन। MyISAM, मेमोरी और अन्य बैकएंड समर्थित नहीं हैं। यह काफी सरल रूप से तय किया गया है - हम सभी तालिकाओं को इनोबीडी में बदल देते हैं।
- ROW प्रारूप में बिनलॉग। क्लस्टर को काम करने के लिए एक बिनलॉग की आवश्यकता नहीं होती है, और यदि आपको क्लासिक दासों की आवश्यकता नहीं है, तो आप इसे बंद कर सकते हैं, लेकिन बिनलॉग प्रारूप ROW होना चाहिए।
- सभी तालिकाओं में एक प्रधान / प्रारूप कुंजी होनी चाहिए। विभिन्न नोड्स से एक ही टेबल पर सही समवर्ती लेखन के लिए यह आवश्यक है। उन तालिकाओं के लिए जिनमें एक अद्वितीय कुंजी नहीं है, आप समग्र प्राथमिक कुंजी या ऑटो वेतन वृद्धि का उपयोग कर सकते हैं।
- Not LOCK TABLES ’, OCK GET_LOCK () / RELEASE_LOCK ()’, AB FLUSH TABLES {{तालिका}} के साथ READ LOCK ’या लेन-देन के लिए अलगाव स्तर IAL SERIALABLE’ का उपयोग न करें।
- के रूप में 'क्रिएट टेबल ... एएस सिलेक्ट' प्रश्नों का उपयोग न करें वे स्कीमा और डेटा परिवर्तन को मिलाते हैं। इसे आसानी से 2 प्रश्नों में विभाजित किया जाता है, जिनमें से पहला एक तालिका बनाता है, और दूसरा डेटा से भरता है।
- 'DISCARD TABLESPACE' और 'IMPORT TABLESPACE' का प्रयोग न करें , जैसे उनकी प्रतिकृति नहीं है
- 'Innodb_autoinc_lock_mode' के विकल्प को '2' पर सेट करें। STATEMENT प्रतिकृति के साथ काम करते समय यह विकल्प डेटा को दूषित कर सकता है, लेकिन चूंकि क्लस्टर में केवल ROW प्रतिकृति की अनुमति है, इसलिए कोई समस्या नहीं होगी।
- जैसा कि 'log_output' केवल 'FILE' समर्थित है। यदि आपके पास तालिका में लॉग प्रविष्टि है, तो आपको इसे निकालना होगा।
- XA लेनदेन समर्थित नहीं हैं। यदि उनका उपयोग किया गया था, तो आपको उनके बिना कोड को फिर से लिखना होगा।
मुझे ध्यान देना चाहिए कि यदि आप चर 'pxc_strict_mode = PERMISSIVE' सेट करते हैं, तो इन सभी प्रतिबंधों को हटाया जा सकता है, लेकिन यदि आपका डेटा आपके लिए महत्वपूर्ण है, तो ऐसा न करना बेहतर है। यदि आपके पास 'pxc_strict_mode = ENFORCING' सेट है, तो MySQL आपको उपरोक्त ऑपरेशन करने या नोड को शुरू करने से रोकने की अनुमति नहीं देगा।
जब हमने डेटाबेस के लिए सभी आवश्यकताओं को पूरा कर लिया है और देव वातावरण में हमारे आवेदन के संचालन का पूरी तरह से परीक्षण किया है, तो हम अगले चरण पर आगे बढ़ सकते हैं।
क्लस्टर परिनियोजन और कॉन्फ़िगरेशन
हमारे डेटाबेस सर्वर पर कई डेटाबेस चल रहे हैं और अन्य डेटाबेस को क्लस्टर में माइग्रेट करने की आवश्यकता नहीं है। लेकिन MySQL क्लस्टर के साथ एक पैकेज क्लासिक mysql की जगह लेता है। हमारे पास इस समस्या के कई समाधान थे:
- वर्चुअलाइजेशन का उपयोग करें और VM में क्लस्टर शुरू करें। बड़े (शेष के साथ तुलना में) ओवरहेड लागत और किसी अन्य इकाई की उपस्थिति के कारण हमें यह विकल्प पसंद नहीं आया
- पैकेज के अपने संस्करण का निर्माण करें, जो एक गैर-मानक स्थान पर mysql डाल देगा। इस प्रकार, एक सर्वर पर mysql के कई संस्करण होना संभव होगा। एक अच्छा विकल्प यदि आपके पास कई सर्वर हैं, लेकिन आपके पैकेज के निरंतर समर्थन, जिसे नियमित रूप से अपडेट करने की आवश्यकता है, तो काफी समय लग सकता है।
- डॉकर का उपयोग करें।
हमने डॉकर को चुना है, लेकिन हम इसका उपयोग न्यूनतम विकल्प में करते हैं। डेटा भंडारण के लिए स्थानीय मात्रा का उपयोग किया जाता है। नेटवर्क लेटेंसी और सीपीयू लोड को कम करने के लिए '- नेट होस्ट' ऑपरेटिंग मोड का उपयोग किया जाता है।
हमें डॉकर छवि का अपना संस्करण भी बनाना था। कारण यह है कि पेरकोना से मानक छवि स्टार्टअप पर स्थिति बहाल करने का समर्थन नहीं करती है। इसका मतलब है कि हर बार उदाहरण को पुनरारंभ करने के बाद, यह तेजी से IST सिंक्रनाइज़ेशन नहीं करता है, जो केवल आवश्यक परिवर्तन अपलोड करता है, लेकिन एक धीमी एसएसटी, जो पूरी तरह से डेटाबेस को फिर से लोड करता है।
एक अन्य समस्या क्लस्टर आकार है। एक क्लस्टर में, प्रत्येक नोड पूरे डेटा सेट को संग्रहीत करता है। इसलिए, बढ़ते क्लस्टर आकार के साथ पूरी तरह से तराजू पढ़ना। रिकॉर्ड के साथ, स्थिति विपरीत है - जब प्रतिबद्ध होते हैं, तो प्रत्येक लेनदेन को सभी नोड्स पर टकराव की अनुपस्थिति के लिए मान्य किया जाता है। स्वाभाविक रूप से, अधिक नोड्स, कमिटमेंट में अधिक समय लगेगा।
यहां हमारे पास कई विकल्प हैं:
- 2 नोड्स + आर्बिटर। 2 नोड्स + आर्बिटर। परीक्षणों के लिए एक अच्छा विकल्प। दूसरे नोड की तैनाती के दौरान, मास्टर को रिकॉर्ड नहीं करना चाहिए।
- 3 नोड्स। क्लासिक संस्करण। गति और विश्वसनीयता का संतुलन। कृपया ध्यान दें कि इस कॉन्फ़िगरेशन में एक नोड को पूरे लोड को फैलाना होगा, क्योंकि तीसरे नोड को जोड़ने के समय, दूसरा दाता होगा।
- 4+ नोड्स। नोड की एक समान संख्या के साथ, विभाजन-मस्तिष्क से बचने के लिए एक मध्यस्थ जोड़ना आवश्यक है। एक विकल्प जो बहुत बड़ी मात्रा में पढ़ने के लिए अच्छी तरह से काम करता है। क्लस्टर की विश्वसनीयता भी बढ़ रही है।
हम अभी तक 3 नोड्स के साथ विकल्प पर बसे हैं।
क्लस्टर कॉन्फ़िगरेशन लगभग पूरी तरह से स्टैंडअलोन MySQL कॉन्फ़िगरेशन की प्रतिलिपि बनाता है और केवल कुछ विकल्पों में भिन्न होता है:
"Wsrep_sst_method = xtrabackup-v2" यह विकल्प नोड्स की प्रतिलिपि बनाने की विधि निर्धारित करता है। अन्य विकल्प mysqldump और rsync हैं, लेकिन वे प्रतिलिपि की अवधि के लिए नोड को रोकते हैं। मुझे गैर-xtrabackup-v2 प्रतिलिपि पद्धति का उपयोग करने का कोई कारण नहीं दिखता है।
"Gcache" क्लस्टर बिनलॉग का एक एनालॉग है। यह एक निश्चित आकार का एक परिपत्र बफर (एक फ़ाइल में) है जिसमें सभी परिवर्तन लिखे गए हैं। यदि आप क्लस्टर नोड्स में से एक को बंद करते हैं और फिर इसे वापस चालू करते हैं, तो यह Gcache (IST सिंक्रनाइज़ेशन) से लापता परिवर्तनों को पढ़ने की कोशिश करेगा। यदि इसमें नोड द्वारा आवश्यक परिवर्तन नहीं हैं, तो नोड (एसएसटी सिंक्रनाइज़ेशन) की पूरी तरह से पुनः लोडिंग की आवश्यकता होगी। Gcache का आकार इस प्रकार सेट किया गया है: wsrep_provider_options = 'gcache.size = 20G;'।
wsrep_slave_threads एक क्लस्टर में शास्त्रीय प्रतिकृति के विपरीत, समानांतर में एक ही डेटाबेस में कई "राइट सेट" लागू करना संभव है। यह विकल्प परिवर्तनों को लागू करने वाले श्रमिकों की संख्या को इंगित करता है। बेहतर है कि 1 का डिफ़ॉल्ट मान न छोड़ें, क्योंकि एक बड़े लेखन सेट के कार्यकर्ता के आवेदन के दौरान, बाकी कतार में इंतजार करेंगे और नोड प्रतिकृति पिछड़ने लगेगी। कुछ इस पैरामीटर को 2 * सीपीयू थ्रेड्स पर सेट करने की सलाह देते हैं, लेकिन मुझे लगता है कि आपको समवर्ती लिखने के संचालन की संख्या को देखना होगा जो आपके पास है।
हम मूल्य 64 पर बसे। कम मूल्य पर, क्लस्टर कभी-कभी लोड के फटने के दौरान कतार से सभी लेखन सेटों को लागू करने का प्रबंधन नहीं करता था (उदाहरण के लिए, जब भारी मुकुट शुरू करते हैं)।
wsrep_max_ws_size क्लस्टर में एकल लेन-देन
का आकार 2 GB तक सीमित है। लेकिन पीएक्ससी अवधारणा के साथ बड़े लेनदेन अच्छी तरह से फिट नहीं होते हैं। 20 एमबी के 100 लेन-देन को प्रत्येक 2 जीबी में पूरा करना बेहतर है। इसलिए, हमने पहले क्लस्टर में लेनदेन का आकार 100 एमबी तक सीमित किया, और फिर सीमा को घटाकर 50 एमबी कर दिया।
यदि आपके पास सख्त मोड सक्षम है, तो आप "
binlog_row_image " चर को "न्यूनतम" पर सेट कर सकते हैं। यह बिनलॉग में प्रविष्टियों के आकार को कई गुना कम कर देगा (पेरकोना से परीक्षण में 10 गुना)। यह डिस्क स्थान को बचाएगा और लेनदेन की अनुमति देगा जो "binlog_row_image = full" के साथ सीमा में फिट नहीं था।
एसएसटी के लिए सीमाएं। Xtrabackup के लिए, जिसका उपयोग नोड्स को भरने के लिए किया जाता है, आप नेटवर्क उपयोग, थ्रेड्स की संख्या और संपीड़न विधि पर एक सीमा निर्धारित कर सकते हैं। यह आवश्यक है ताकि जब नोड भर जाए, तो दाता सर्वर धीमा नहीं शुरू हो। ऐसा करने के लिए, "sst" अनुभाग my.cnf फ़ाइल में जोड़ा जाता है:
[sst] rlimit = 80m compressor = "pigz -3" decompressor = "pigz -dc" backup_threads = 4
हम प्रतिलिपि की गति 80 एमबी / एस तक सीमित करते हैं। हम संपीड़न के लिए पिग का उपयोग करते हैं, यह गज़िप का एक बहु-थ्रेडेड संस्करण है।
जीटीआईडी यदि आप क्लासिक दासों का उपयोग करते हैं, तो मैं क्लस्टर पर जीटीआईडी को सक्षम करने की सलाह देता हूं। यह आपको दास को फिर से लोड किए बिना क्लस्टर के किसी भी नोड से कनेक्ट करने की अनुमति देगा।
इसके अतिरिक्त, मैं 2 क्लस्टर तंत्र, उनके अर्थ और विन्यास के बारे में बात करना चाहता हूं।
प्रवाह नियंत्रण
प्रवाह नियंत्रण क्लस्टर में राइट लोड को प्रबंधित करने का एक तरीका है। यह नोड्स को प्रतिकृति में बहुत दूर जाने की अनुमति नहीं देता है। इस तरह, "लगभग तुल्यकालिक" प्रतिकृति प्राप्त की जाती है। ऑपरेशन का तंत्र काफी सरल है - जैसे ही रिसेप्शन कतार की लंबाई निर्धारित मूल्य तक पहुंचती है, यह अन्य नोड्स को संदेश "फ्लो कंट्रोल पॉज़" भेजता है, जो उन्हें तब तक नए लेनदेन के साथ रुकने के लिए कहता है जब तक कि लैगिंग नोड कतार को खत्म नहीं कर देता। ।
इस से कई चीजें निम्नलिखित हैं:
- क्लस्टर में रिकॉर्डिंग सबसे धीमे नोड की गति से होगी। (लेकिन इसे और कड़ा किया जा सकता है।)
- यदि लेनदेन करते समय आपके पास बहुत सारे संघर्ष हैं, तो आप फ्लो कंट्रोल को अधिक आक्रामक रूप से कॉन्फ़िगर कर सकते हैं, जिससे उनकी संख्या कम हो जानी चाहिए।
- एक क्लस्टर में एक नोड का अधिकतम अंतराल एक स्थिर है, लेकिन समय से नहीं, बल्कि कतार में लेनदेन की संख्या से। अंतराल समय औसत लेनदेन आकार और wsrep_slave_threads की संख्या पर निर्भर करता है।
आप इस तरह फ्लो कंट्रोल सेटिंग्स देख सकते हैं:
mysql> SHOW GLOBAL STATUS LIKE 'wsrep_flow_control_interval_%';
wsrep_flow_control_interval_low | 36
wsrep_flow_control_interval_high | 71
सबसे पहले, हम wsrep_flow_control_interval_high पैरामीटर में रुचि रखते हैं। यह कतार की लंबाई को नियंत्रित करता है, जिसके बाद FC ठहराव चालू होता है। इस पैरामीटर की गणना सूत्र द्वारा की जाती है: gcs.fc_limit * whereN (जहाँ N = क्लस्टर में n की संख्या।)।
दूसरा पैरामीटर wsrep_flow_control_interval_low है। यह कतार की लंबाई के मूल्य के लिए जिम्मेदार है, जिस पर पहुंचने पर FC बंद हो जाता है। सूत्र द्वारा परिकलित: wsrep_flow_control_interval_high * gcs.fc_factor। डिफ़ॉल्ट रूप से, gcs.fc_factor = 1।
इस प्रकार, कतार की लंबाई को बदलकर, हम प्रतिकृति अंतराल को नियंत्रित कर सकते हैं। कतार की लंबाई कम करने से एफसी ठहराव में क्लस्टर खर्च करने का समय बढ़ जाएगा, लेकिन नोड्स के अंतराल को कम कर देगा।
आप सत्र चर "
wsrep_sync_wait = 7" सेट कर सकते हैं। यह पीएक्ससी को मौजूदा कतार में सभी लिखने-सेट को लागू करने के बाद ही पढ़ने या लिखने के अनुरोधों को निष्पादित करने के लिए मजबूर करेगा। स्वाभाविक रूप से, यह अनुरोधों की विलंबता को बढ़ाएगा। विलंबता में वृद्धि सीधे कतार की लंबाई के लिए आनुपातिक है।
अधिकतम लेन-देन के आकार को कम से कम करना भी वांछनीय है, ताकि लंबे लेनदेन गलती से फिसल न जाए।
ईवीएस या ऑटो एविक्ट
यह तंत्र आपको नोड्स को बाहर निकालने की अनुमति देता है जो अस्थिर हैं (उदाहरण के लिए, पैकेट नुकसान या लंबी देरी) या जो धीरे-धीरे प्रतिक्रिया करते हैं। इसके लिए धन्यवाद, एक नोड के साथ संचार की समस्याएं पूरे क्लस्टर को नहीं लगाएंगी, लेकिन नोड को अक्षम होने दें और सामान्य मोड में काम करना जारी रखें। यह तंत्र विशेष रूप से तब उपयोगी होता है जब क्लस्टर WAN या नेटवर्क के उन हिस्सों से संचालित हो रहा है जो आपके नियंत्रण में नहीं हैं। डिफ़ॉल्ट रूप से, ईवीएस बंद है।
इसे सक्षम करने के लिए,
wsrep_provider_options पैरामीटर का विकल्प "evs.version = 1" जोड़ें। और "evs.auto_evict = 5;" (ऑपरेशन की संख्या जिसके बाद नोड बंद हो जाता है। 0 का मान ईवीएस को निष्क्रिय कर देता है।) कई पैरामीटर भी हैं जो आपको ईवीएस को ठीक करने की अनुमति देते हैं:
- evs.delayed_margin किसी नोड को प्रतिक्रिया देने के लिए समय लगता है। डिफ़ॉल्ट रूप से, 1 सेकंड।, लेकिन स्थानीय नेटवर्क पर काम करते समय, इसे 0.05-0.1 सेकंड तक घटाया जा सकता है।
- evs.inactive_check_period चेकों की अवधि। डिफ़ॉल्ट 0.5 सेकंड
वास्तव में, ईवीएस ट्रिगर होने से पहले एक नोड समस्याओं के मामले में काम कर सकता है जो कि evs.inactive_check_period * evs.auto_evict है। आप "evs.inactive_timeout" भी सेट कर सकते हैं और एक नोड जो प्रतिक्रिया नहीं देता है उसे तुरंत डिफ़ॉल्ट रूप से 15 सेकंड के लिए बाहर फेंक दिया जाएगा।
एक महत्वपूर्ण बारीकियों यह है कि संचार को बहाल करते समय यह तंत्र स्वयं नोड को वापस नहीं लौटाएगा। इसे हाथ से फिर से शुरू करना होगा।
हमने घर पर ईवीएस की स्थापना की है, लेकिन हमें इसे युद्ध में परीक्षण करने का मौका नहीं मिला है।
लोड संतुलन
क्लाइंट के लिए प्रत्येक नोड के संसाधनों का समान रूप से उपयोग करने और केवल लाइव क्लस्टर नोड्स पर अनुरोध निष्पादित करने के लिए, हमें एक लोड बैलेंसर की आवश्यकता है। पर्कोना 2 समाधान प्रदान करता है:
- ProxySQL। यह MySQL के लिए L7 प्रॉक्सी है।
- Haproxy। लेकिन हाप्रोसी को पता नहीं है कि क्लस्टर नोड की स्थिति कैसे जांचें और यह निर्धारित करें कि क्या यह अनुरोधों को निष्पादित करने के लिए तैयार है। इस समस्या को हल करने के लिए, एक अतिरिक्त पर्कनो-क्लेस्टर्कैच स्क्रिप्ट का उपयोग करने का प्रस्ताव है
सबसे पहले हम ProxySQL का उपयोग करना चाहते थे, लेकिन बेंचमार्किंग के बाद यह पता चला कि लेटेंसी ने Haproxy को लगभग 15-20% तक खो दिया है, यहां तक कि fast_forward मोड का उपयोग करते समय भी (क्वेरी पुनर्लेखन, राउटिंग और कई अन्य ProxySQL फ़ंक्शन इस मोड में काम नहीं करते हैं, अनुरोध के रूप में अनुमानित है) ।
हाप्रोसी तेज़ है, लेकिन पेरकोना स्क्रिप्ट में कुछ कमियां हैं।
सबसे पहले, यह बैश में लिखा गया है, जो इसके अनुकूलन में योगदान नहीं करता है। एक और अधिक गंभीर समस्या यह है कि यह MySQL चेक के परिणाम को कैश नहीं करता है। इस प्रकार, यदि हमारे पास 100 ग्राहक हैं, जिनमें से प्रत्येक प्रत्येक 1 सेकंड में एक बार नोड की स्थिति की जांच करता है, तो स्क्रिप्ट प्रत्येक 10 एमएस को MySQL के लिए अनुरोध करेगी। यदि किसी कारण से MySQL धीरे-धीरे काम करना शुरू कर देता है, तो सत्यापन स्क्रिप्ट बड़ी संख्या में प्रक्रियाएं बनाना शुरू कर देगा, जो निश्चित रूप से स्थिति में सुधार नहीं करेगा।
यह
एक समाधान लिखने का निर्णय लिया गया था जिसमें MySQL स्टेटस चेक और Haproxy प्रतिक्रिया एक दूसरे से संबंधित नहीं हैं। स्क्रिप्ट नियमित अंतराल पर पृष्ठभूमि में नोड की स्थिति की जांच करती है और परिणाम को कैश करती है। वेब सर्वर हाप्रोसी को कैश्ड परिणाम देता है।
हाप्रोक्सी विन्यास उदाहरणlisten db
bind 127.0.0.1:3302
mode tcp
balance first
default-server inter 200 rise 6 fall 6
option httpchk HEAD /
server node1 192.168.0.1:3302 check port 9200 id 1
server node2 192.168.0.2:3302 check port 9200 backup id 2
server node3 192.168.0.3:3302 check port 9200 backup id 3
listen db_slave
bind 127.0.0.1:4302
mode tcp
balance leastconn
default-server inter 200 rise 6 fall 6
option httpchk HEAD /
server node1 192.168.0.1:3302 check port 9200 backup
server node2 192.168.0.2:3302 check port 9200
server node3 192.168.0.3:3302 check port 9200
यह उदाहरण एकल विज़ार्ड कॉन्फ़िगरेशन दिखाता है। शेष क्लस्टर सर्वर दास के रूप में कार्य करते हैं।
निगरानी
क्लस्टर स्थिति की निगरानी करने के लिए, हमने डेटा की कल्पना करने के लिए प्रोमेथियस + मायस्कल्ड_एक्सपोर्ट और ग्राफाना का उपयोग किया। क्योंकि mysqld_exporter खुद को काफी थकाऊ बनाने के लिए मैट्रिक्स का एक गुच्छा एकत्र करता है। आप
पेरकोना से तैयार किए गए
डैशबोर्ड ले सकते हैं और उन्हें अपने लिए अनुकूलित कर सकते हैं।
बेसिक क्लस्टर मेट्रिक्स और अलर्ट इकट्ठा करने के लिए हम Zabbix का भी उपयोग करते हैं।
मुख्य क्लस्टर मीट्रिक जिसे आप मॉनिटर करना चाहते हैं:
- wsrep_cluster_status को सभी नोड्स पर प्राथमिक पर सेट किया जाना चाहिए। यदि मान "गैर-प्राथमिक" है, तो इस नोड ने क्लस्टर कोरम के साथ संपर्क खो दिया है।
- wsrep_cluster_size क्लस्टर में नोड्स की संख्या। इसमें "खोई" नोड्स भी शामिल हैं, जो क्लस्टर में होना चाहिए, लेकिन किसी कारण से उपलब्ध नहीं हैं। जब नोड को धीरे से बंद किया जाता है, तो इस चर का मूल्य कम हो जाता है।
- wsrep_local_state बताता है कि क्या नोड क्लस्टर का सक्रिय सदस्य है और जाने के लिए तैयार है।
- wsrep_evs_state एक महत्वपूर्ण पैरामीटर यदि आपके पास ऑटो एविक्शन चालू है (डिफ़ॉल्ट रूप से बंद)। यह चर इंगित करता है कि ईवीएस इस नोड को स्वस्थ मानता है।
- wsrep_evs_evict_list नोड्स की सूची जो क्लस्टर से EVS द्वारा फेंकी गई थी। एक सामान्य स्थिति में, सूची खाली होनी चाहिए।
- ईवीएस हटाने के लिए उम्मीदवारों की सूची wsrep_evs_delayed । भी खाली होना चाहिए।
मुख्य प्रदर्शन मीट्रिक:
- क्लस्टर के भीतर wsrep_evs_repl_latency दिखाता है (न्यूनतम / औसत / अधिकतम / वरिष्ठ विचलन / पैकेट आकार) संचार में देरी। यही है, यह नेटवर्क विलंबता को मापता है। बढ़ते मान नेटवर्क या क्लस्टर नोड्स को अधिभारित करने का संकेत दे सकते हैं। ईवीएस बंद होने पर भी यह मीट्रिक रिकॉर्ड किया जाता है।
- wsrep_flow_control_paused_ns नोड शुरू होने के बाद का समय (ns) में है जो इसे फ्लो कंट्रोल पॉज में खर्च करता है। आदर्श रूप से, यह 0. होना चाहिए। इस पैरामीटर की वृद्धि क्लस्टर प्रदर्शन या "wsrep_slave_threads" की कमी के साथ समस्याओं को इंगित करती है। आप यह निर्धारित कर सकते हैं कि कौन सा नोड पैरामीटर " wsrep_flow_control_sent " द्वारा धीमा हो जाता है।
- wsrep_flow_control_paused "FLUSH STATUS?" के अंतिम निष्पादन के बाद से समय का प्रतिशत, जो कि फ्लो कंट्रोल पॉज़ में खर्च किया गया नोड है। साथ ही पिछले चर, यह शून्य के लिए जाना चाहिए।
- wsrep_flow_control_status बताता है कि वर्तमान में फ़्लो कंट्रोल चल रहा है या नहीं। एफसी ठहराव आरंभ करने वाले नोड पर, इस चर का मूल्य चालू होगा।
- wsrep_local_recv_queue_avg औसत कतार की लंबाई प्राप्त करते हैं। इस पैरामीटर की वृद्धि नोड के प्रदर्शन के साथ समस्याओं को इंगित करती है।
- wsrep_local_send_queue_avg भेजें कतार की औसत लंबाई। इस पैरामीटर की वृद्धि नेटवर्क प्रदर्शन समस्याओं को इंगित करती है।
इन मापदंडों के मूल्यों पर कोई सार्वभौमिक सिफारिशें नहीं हैं। यह स्पष्ट है कि उन्हें शून्य करना चाहिए, लेकिन वास्तविक भार पर यह सबसे अधिक संभावना नहीं होगी और आपको अपने लिए यह निर्धारित करना होगा कि क्लस्टर की सामान्य स्थिति की सीमा कैसे गुजरती है।
बैकअप
क्लस्टर बैकअप व्यावहारिक रूप से स्टैंडअलोन mysql से अलग नहीं है। उत्पादन के उपयोग के लिए, हमारे पास कई विकल्प हैं।
- Xtrabackup का उपयोग करके "लाभ" नोड्स में से एक से बैकअप निकालें। सबसे आसान विकल्प है, लेकिन बैकअप क्लस्टर के दौरान प्रदर्शन को कम कर दिया जाएगा।
- प्रतिकृतियों से क्लासिक दास और बैकअप का उपयोग करें।
स्टैंडअलोन के साथ बैकअप और xtrabackup का उपयोग करके बनाए गए क्लस्टर संस्करण के साथ आपस में पोर्टेबल हैं। यही है, क्लस्टर से लिया गया बैकअप स्टैंडअलोन mysql और इसके विपरीत में तैनात किया जा सकता है। स्वाभाविक रूप से, MySQL के प्रमुख संस्करण को मेल खाना चाहिए, अधिमानतः मामूली। Mysqldump का उपयोग करके किए गए बैकअप स्वाभाविक रूप से पोर्टेबल हैं।
एकमात्र चेतावनी यह है कि बैकअप तैनात करने के बाद, आपको mysql_upgrad स्क्रिप्ट को चलाना होगा, जो कुछ सिस्टम तालिकाओं की संरचना की जांच और सही करेगा।
डेटा माइग्रेशन
अब जब हमने कॉन्फ़िगरेशन, निगरानी और अन्य चीजों का पता लगा लिया है, तो हम ठेस की ओर पलायन शुरू कर सकते हैं।
हमारी योजना में डेटा माइग्रेशन काफी सरल था, लेकिन हमने थोड़ा गड़बड़ कर दिया;)
किंवदंती - मास्टर 1 और मास्टर 2 मास्टर प्रतिकृति मास्टर द्वारा जुड़े हुए हैं। रिकॉर्डिंग केवल मास्टर के लिए जाती है 1. मास्टर 3 एक साफ सर्वर है।
हमारी प्रवासन योजना (योजना में मैं सरलता के लिए दासों के साथ संचालन को छोड़ दूंगा और केवल मास्टर सर्वर के बारे में बात करूंगा)।
प्रयास 1
- Xtrabackup का उपयोग करके मास्टर 1 से डेटाबेस बैकअप निकालें।
- 3 मास्टर करने के लिए बैकअप की प्रतिलिपि बनाएँ और क्लस्टर को एकल-नोड मोड में चलाएँ।
- मास्टर्स 3 और 1 के बीच मास्टर प्रतिकृति स्थापित करें।
- मास्टर को पढ़ने और लिखने को स्विच करें 3. एप्लिकेशन की जांच करें।
- मास्टर 2 पर, प्रतिकृति बंद करें और MySQL क्लस्टर करना शुरू करें। हम मास्टर से डेटाबेस को कॉपी करने के लिए उसका इंतजार कर रहे हैं। 3. नकल के दौरान, हमारे पास "डोनर" स्थिति में एक नोड का एक क्लस्टर था और एक अभी भी काम नहीं कर रहा नोड है। कॉपी करने के दौरान, हमें तालों का एक गुच्छा मिला और अंत में दोनों नोड्स एक त्रुटि के साथ गिर गए (मृत ताले के कारण एक नया नोड पूरा नहीं किया जा सकता है)। इस छोटे से प्रयोग ने हमें चार मिनट के डाउनटाइम की लागत दी।
- वापस पढना और लिखना १ गुरु के लिए।
प्रवासन ने इस तथ्य के कारण काम नहीं किया कि डेटाबेस पर देव वातावरण में सर्किट का परीक्षण करते समय, व्यावहारिक रूप से कोई लिखने वाला ट्रैफ़िक नहीं था, और लोड के तहत एक ही सर्किट को दोहराते समय, समस्याएं बाहर हो गईं।
हमने इन समस्याओं से बचने के लिए माइग्रेशन स्कीम को थोड़ा बदल दिया और दूसरी बार सफलतापूर्वक पुनर्प्राप्त किया;)।
प्रयास २
- हम मास्टर 3 को पुनरारंभ करते हैं ताकि यह एकल-नोड मोड में फिर से काम करे।
- हम मास्टर 2 पर फिर से क्लस्टर MySQL बढ़ाते हैं। फिलहाल, प्रतिकृति से यातायात केवल क्लस्टर में चला गया, इसलिए ताले के साथ कोई समस्या नहीं थी और क्लस्टर में दूसरा नोड सफलतापूर्वक जोड़ा गया था।
- फिर से, मास्टर को पढ़ना और लिखना स्विच करें 3. हम एप्लिकेशन के संचालन की जांच करते हैं।
- मास्टर के साथ मास्टर प्रतिकृति को अक्षम करें। मास्टर 1 पर क्लस्टर mysql चालू करें और इसके शुरू होने तक प्रतीक्षा करें। एक ही रेक पर कदम नहीं रखने के लिए, यह महत्वपूर्ण है कि आवेदन दाता नोड (विवरण के लिए, लोड संतुलन पर अनुभाग देखें) को न लिखे। तीसरा नोड शुरू करने के बाद, हमारे पास तीन नोड्स का एक पूर्ण कार्यात्मक क्लस्टर होगा।
- आप क्लस्टर के नोड्स में से एक से एक बैकअप निकाल सकते हैं और आपको आवश्यक क्लासिक दासों की संख्या बना सकते हैं।
दूसरी योजना और पहले के बीच का अंतर यह है कि हमने क्लस्टर में दूसरा नोड बढ़ाने के बाद ही ट्रैफ़िक को स्विच किया है।
इस प्रक्रिया में हमें लगभग 6 घंटे लगे।
मल्टी मास्टर
माइग्रेशन के बाद, हमारे क्लस्टर ने सिंगल-मास्टर मोड में काम किया, यानी पूरा रिकॉर्ड सर्वर में से एक में चला गया, और केवल डेटा बाकी हिस्सों से पढ़ा गया।
उत्पादन को मल्टी-मास्टर मोड में बदलने के बाद, हमें एक समस्या का सामना करना पड़ा - लेन-देन संघर्ष हमारी अपेक्षा से अधिक बार हुआ। यह विशेष रूप से प्रश्नों के साथ बुरा था जो कई रिकॉर्डों को संशोधित करता है, उदाहरण के लिए, एक तालिका में सभी रिकॉर्डों के मूल्य को अपडेट करना। क्लस्टर पर क्रमिक रूप से एक ही नोड पर सफलतापूर्वक निष्पादित किए गए लेन-देन को समानांतर में निष्पादित किया जाता है और एक लंबे समय तक लेन-देन में एक डेडलॉक त्रुटि प्राप्त होती है। मैं देरी नहीं करूंगा, आवेदन स्तर पर इसे ठीक करने के कई प्रयासों के बाद, हमने मल्टी-मास्टर के विचार को त्याग दिया।
अन्य बारीकियों
- एक क्लस्टर गुलाम हो सकता है। इस फ़ंक्शन का उपयोग करते समय, मैं उस सभी को छोड़कर सभी नोड्स को जोड़ने की सलाह देता हूं जो दास विकल्प "Skip_slave_start = 1" है। अन्यथा, प्रत्येक नया नोड मास्टर से प्रतिकृति शुरू करेगा, जो प्रतिकृति पर या तो त्रुटियों या डेटा भ्रष्टाचार का कारण होगा।
- जैसा कि मैंने कहा कि डोनर, एक नोड ठीक से ग्राहकों की सेवा नहीं कर सकता है। यह याद रखना चाहिए कि तीन नोड्स के एक क्लस्टर में, परिस्थितियां संभव हैं जब एक नोड बह गया है, दूसरा एक दाता है और ग्राहक सेवा के लिए केवल एक नोड शेष है।
निष्कर्ष
प्रवासन और कुछ ऑपरेशन के समय के बाद, हम निम्नलिखित निष्कर्ष पर आए।
- गैलेरा क्लस्टर काम करता है और काफी स्थिर है (कम से कम जब तक नोड्स या उनके असामान्य व्यवहार की कोई असामान्य बूंद नहीं हुई है)। गलती सहिष्णुता के संदर्भ में, हमें वही मिला जो हम चाहते थे।
- पर्कोना के मल्टी-मास्टर स्टेटमेंट मुख्य रूप से मार्केटिंग हैं। हां, इस मोड में क्लस्टर का उपयोग करना संभव है, लेकिन इसके लिए इस उपयोग मॉडल के लिए एप्लिकेशन के गहन परिवर्तन की आवश्यकता होगी।
- कोई तुल्यकालिक प्रतिकृति नहीं है, लेकिन अब हम नोड्स के अधिकतम अंतराल (लेनदेन में) को नियंत्रित करते हैं। 50 एमबी के अधिकतम लेन-देन के आकार की सीमा के साथ, हम नोड्स के अधिकतम अंतराल समय का सटीक अनुमान लगा सकते हैं। डेवलपर्स के लिए कोड लिखना आसान हो गया है।
- निगरानी में, हम प्रतिकृति कतार के विकास में अल्पकालिक चोटियों का निरीक्षण करते हैं। इसका कारण हमारे 1 Gbit / s नेटवर्क में है। ऐसे नेटवर्क पर एक क्लस्टर संचालित करना संभव है, लेकिन लोड के फटने के दौरान समस्याएं दिखाई देती हैं। अब हम नेटवर्क को 10 Gbit / s में अपग्रेड करने की योजना बना रहे हैं।
कुल तीन "विशलिस्ट" हमें लगभग डेढ़ प्राप्त हुए। सबसे महत्वपूर्ण आवश्यकता दोष सहिष्णुता है।
उन लोगों के लिए हमारी PXC कॉन्फ़िगरेशन फ़ाइल:
my.cnf[mysqld]
#Main
server-id = 1
datadir = /var/lib/mysql
socket = mysql.sock
port = 3302
pid-file = mysql.pid
tmpdir = /tmp
large_pages = 1
skip_slave_start = 1
read_only = 0
secure-file-priv = /tmp/
#Engine
innodb_numa_interleave = 1
innodb_flush_method = O_DIRECT
innodb_flush_log_at_trx_commit = 2
innodb_file_format = Barracuda
join_buffer_size = 1048576
tmp-table-size = 512M
max-heap-table-size = 1G
innodb_file_per_table = 1
sql_mode = "NO_ENGINE_SUBSTITUTION,NO_AUTO_CREATE_USER,ERROR_FOR_DIVISION_BY_ZERO"
default_storage_engine = InnoDB
innodb_autoinc_lock_mode = 2
#Wsrep
wsrep_provider = "/usr/lib64/galera3/libgalera_smm.so"
wsrep_cluster_address = "gcomm://192.168.0.1:4577,192.168.0.2:4577,192.168.0.3:4577"
wsrep_cluster_name = "prod"
wsrep_node_name = node1
wsrep_node_address = "192.168.0.1"
wsrep_sst_method = xtrabackup-v2
wsrep_sst_auth = "USER:PASS"
pxc_strict_mode = ENFORCING
wsrep_slave_threads = 64
wsrep_sst_receive_address = "192.168.0.1:4444"
wsrep_max_ws_size = 50M
wsrep_retry_autocommit = 2
wsrep_provider_options = "gmcast.listen_addr=tcp://192.168.0.1:4577; ist.recv_addr=192.168.0.1:4578; gcache.size=30G; pc.checksum=true; evs.version=1; evs.auto_evict=5; gcs.fc_limit=80; gcs.fc_factor=0.75; gcs.max_packet_size=64500;"
#Binlog
expire-logs-days = 4
relay-log = mysql-relay-bin
log_slave_updates = 1
binlog_format = ROW
binlog_row_image = minimal
log_bin = mysql-bin
log_bin_trust_function_creators = 1
#Replication
slave-skip-errors = OFF
relay_log_info_repository = TABLE
relay_log_recovery = ON
master_info_repository = TABLE
gtid-mode = ON
enforce-gtid-consistency = ON
#Cache
query_cache_size = 0
query_cache_type = 0
thread_cache_size = 512
table-open-cache = 4096
innodb_buffer_pool_size = 72G
innodb_buffer_pool_instances = 36
key_buffer_size = 16M
#Logging
log-error = /var/log/stdout.log
log_error_verbosity = 1
slow_query_log = 0
long_query_time = 10
log_output = FILE
innodb_monitor_enable = "all"
#Timeout
max_allowed_packet = 512M
net_read_timeout = 1200
net_write_timeout = 1200
interactive_timeout = 28800
wait_timeout = 28800
max_connections = 22000
max_connect_errors = 18446744073709551615
slave-net-timeout = 60
#Static Values
ignore_db_dir = "lost+found"
[sst]
rlimit = 80m
compressor = "pigz -3"
decompressor = "pigz -dc"
backup_threads = 8
स्रोत और उपयोगी लिंक
→
हमारी डॉकर छवि→
पर्कोना एक्स्ट्राबीडी क्लस्टर 5.7 डॉक्यूमेंटेशन→
मॉनिटरिंग क्लस्टर स्टेटस - गैलरा क्लस्टर डॉक्यूमेंटेशन→
गैलेरा स्थिति चर - गैलेरा क्लस्टर प्रलेखन