नमस्कार, हेब्र! मैं आपके लिए
"चेहरे की सतह और बनावट संश्लेषण के माध्यम से गण" लेख का अनुवाद प्रस्तुत करता हूं।
जब शोधकर्ताओं के पास वास्तविक डेटा की कमी होती है, तो वे अक्सर डेटा की वृद्धि का सहारा लेते हैं, मौजूदा डेटासेट का विस्तार करने के तरीके के रूप में। विचार मौजूदा प्रशिक्षण डेटासेट को इस तरह से संशोधित करना है जैसे कि शब्दार्थ गुणों को बरकरार रखना।
मानव चेहरे की बात करें तो ऐसा कोई तुच्छ कार्य नहीं है।फेस जनरेशन विधि को इस तरह के जटिल डेटा परिवर्तनों को ध्यान में रखना चाहिए
- मुद्रा,
- प्रकाश व्यवस्था,
- गैर-कठोर विकृति
यथार्थवादी चित्र बनाते समय जो वास्तविक डेटा के आँकड़ों के अनुरूप हों।
विचार करें कि अत्याधुनिक तरीके इस समस्या को हल करने का प्रयास कैसे करते हैं।
आधुनिक पीढ़ी का सामना करने के लिए
सिंथेटिक डेटा को अधिक यथार्थवाद देने के लिए पीढ़ीगत प्रतिकूल तंत्रिका नेटवर्क (GAN) को अधिक प्रभावी दिखाया गया है। संश्लेषित डेटा को इनपुट के रूप में स्वीकार करके,
GAN ऐसे नमूने उत्पन्न करता है जो वास्तविक डेटा की तरह अधिक होते हैं । हालांकि, सिमेंटिक गुणों को बदला जा सकता है, और यहां तक कि नुकसान का कार्य, बदलते मापदंडों के लिए दंडित करना, समस्या को अंत तक हल नहीं करता है।
थ्री डी मॉर्फिबल मॉडल (3DMM) ज्यामिति और बनावट को दर्शाने और संश्लेषित करने के लिए सबसे आम तरीका है और इसे मूल रूप से तीन आयामी मानव चेहरे की पीढ़ी के संदर्भ में पेश किया गया था। इस मॉडल के अनुसार, एक मानव चेहरे की ज्यामितीय संरचना और बनावट जड़ वैक्टर के संयोजन के रूप में रैखिक रूप से अनुमानित की जा सकती है।
हाल ही में,
3DMM मॉडल को डेटा बढ़ाने के लिए
दृढ़ तंत्रिका नेटवर्क
के साथ जोड़ा गया है । हालाँकि, परिणामी नमूने बहुत चिकने और अवास्तविक हैं, जैसा कि नीचे दी गई तस्वीर में देखा जा सकता है:

3DMM का उपयोग करके प्राप्त व्यक्ति
इसके अलावा, 3DMM एक गाऊसी वितरण के आधार पर डेटा उत्पन्न करते हैं, जो शायद ही कभी डेटा के वास्तविक वितरण को दर्शाता है। उदाहरण के लिए, नीचे दो पीसीए (प्रमुख घटक विश्लेषण) वास्तविक चेहरे पर निर्मित गुणांक हैं और 3 डीएमएम का उपयोग करके संश्लेषित किया गया है। सिंथेटिक और वास्तविक वितरण के बीच अंतर आसानी से गलत डेटा की पीढ़ी को जन्म दे सकता है।
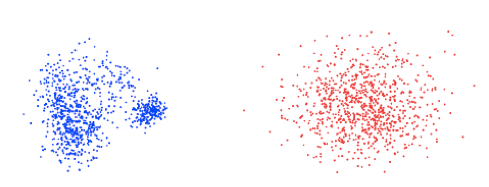
वास्तविक (बाएं) और 3DMM उत्पन्न (दाएं) व्यक्तियों के लिए पहले दो पीसीए गुणांक
अत्याधुनिक विचार
Slossberg, Shamai, और Kimmel of Technion इज़राइल इंस्टीट्यूट ऑफ टेक्नोलॉजी 3DMM और GAN के संयोजन का उपयोग करके
यथार्थवादी मानव चेहरों के संश्लेषण के लिए एक नया दृष्टिकोण प्रदान करते हैं ।
विशेष रूप से, शोधकर्ता GAN का उपयोग मानकीकृत मानव बनावट के स्थान का अनुकरण करने और प्रत्येक बनावट के लिए सर्वश्रेष्ठ 3DMM गुणांक की गणना करते हुए संबंधित फेस ज्यामितीय बनाने के लिए करते हैं। नए उच्च-रिज़ॉल्यूशन 3 डी चेहरों का उत्पादन करने के लिए उत्पन्न बनावट को उपयुक्त ज्यामिति में मैप किया जाता है।
इस तरह की वास्तुकला यथार्थवादी छवियों को उत्पन्न करती है, जबकि:
- पोज़ और लाइटिंग जैसी विशेषताओं पर नियंत्रण से पीड़ित नहीं है
- नए चेहरों की पीढ़ी में मात्रात्मक रूप से सीमित नहीं है।
आइए डेटा जनरेशन प्रक्रिया पर करीब से नज़र डालें।
डेटा जनरेशन प्रोसेस

डेटा की तैयारी
डेटा जनरेशन पाइपलाइन में चार मुख्य चरण होते हैं:
- डेटा संग्रह : शोधकर्ताओं ने विभिन्न जातीय, लिंग और आयु समूहों के 5,000 से अधिक स्कैन (फेस स्कैन) एकत्र किए हैं। प्रत्येक प्रतिभागी को तटस्थ सहित 5 विभिन्न चेहरे के भावों का चित्रण करना था।
- मार्कअप : 43 मुख्य बिंदुओं को स्वचालित रूप से माशी में जोड़ा गया, चेहरे को रेंडर करके और पूर्व-प्रशिक्षित फेस मार्किंग डिटेक्टर का उपयोग करके
- मेष की संरेखण : चिह्नित स्कैन पर ध्यान केंद्रित करते हुए प्रत्येक स्कैन की ज्यामिति के अनुसार टेम्पलेट फेस कैश की विकृति के कारण कार्यान्वित किया जाता है।
- बनावट हस्तांतरण : बनावट ब्लेंडर टूलबॉक्स में निर्मित किरण कास्टिंग तकनीक का उपयोग करके स्कैन से टेम्पलेट में स्थानांतरित किया जाता है। उसके बाद, बनावट को पूर्वनिर्धारित सार्वभौमिक परिवर्तन का उपयोग करके टेम्पलेट से द्वि-आयामी पट्टी में परिवर्तित किया जाता है

फ्लैट पंक्तिबद्ध चेहरे की बनावट
अगला चरण GAN को सिखाना है कि संरेखित बनावट के सिमुलेशन कैसे बनाएं। इस कार्य के लिए, शोधकर्ताओं ने एक सममित तंत्रिका नेटवर्क के रूप में आयोजित एक जनरेटर और भेदभाव के साथ एक प्रगतिशील जीएएन का उपयोग किया। इस तरह के कार्यान्वयन में, जनरेटर फीचर मैप के आकार को उत्तरोत्तर बढ़ाता है जब तक कि यह आउटपुट छवि के आकार तक नहीं पहुंच जाता है, जबकि विभेदक धीरे-धीरे आकार को वापस एक आउटपुट में कम कर देता है।
 गण चेहरा बनावट
गण चेहरा बनावटअंतिम चरण फेस ज्यामिति बनाना है। बनावट के लिए सही ज्यामिति गुणांक खोजने के लिए शोधकर्ताओं ने अलग-अलग तरीकों की कोशिश की। नीचे विभिन्न तरीकों की गुणात्मक और मात्रात्मक तुलना (L2 ज्यामितीय त्रुटि):

दो संश्लेषित बनावट अलग-अलग ज्यामिति पर आरोपित हैं।
अप्रत्याशित रूप से, सबसे कम वर्ग विधि सबसे अच्छे परिणाम दिखाती है। विधि की सरलता को ध्यान में रखते हुए, इसे सभी प्रयोगों के लिए चुना गया था।
परिणाम
प्रस्तावित विधि कई नए चेहरे उत्पन्न कर सकती है, और उनमें से प्रत्येक को विभिन्न अभिव्यक्तियों और प्रकाश व्यवस्था के साथ विभिन्न पोज़ में दर्शाया जा सकता है। ब्लेंड शेप मॉडल का उपयोग करके विभिन्न ज्यामिति को तटस्थ ज्यामिति में जोड़ा जाता है। परिणामी छवियां नीचे दिखाई गई हैं:



मात्रात्मक आकलन के लिए, शोधकर्ताओं ने प्रशिक्षण और उत्पन्न छवियों के वितरण के बीच की दूरी को मापने के
लिए वासेरस्टीन ट्रंकेटेड मेट्रिक (एसडब्ल्यूडी) का उपयोग किया।
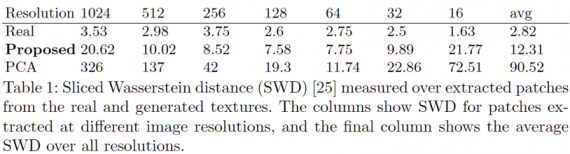
तालिका प्रदर्शित करती है कि परिणामी बनावट 3DMM का उपयोग करके प्राप्त आंकड़ों की तुलना में वास्तविक डेटा के करीब है।
निम्न प्रयोग छवियों को संश्लेषित करने की क्षमता का मूल्यांकन करता है, जो प्रशिक्षण डेटासेट से काफी भिन्न होते हैं, और पहले अनदेखी छवियों को प्राप्त करते हैं। इस प्रकार, 5% व्यक्तियों को मूल्यांकन में शामिल नहीं किया गया था। शोधकर्ताओं ने L2 को प्रशिक्षण डेटा से प्रत्येक वास्तविक व्यक्ति के बीच की दूरी और उत्पन्न समानों से सबसे अधिक मापा, और इसी तरह प्रशिक्षण डेटासेट से वास्तविक एक के लिए दूरी को मापा।
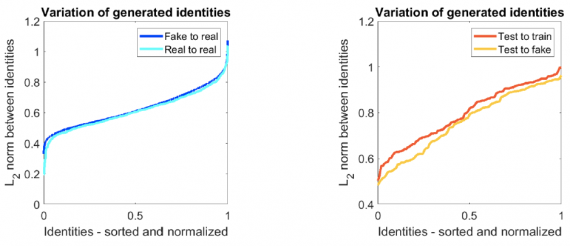
संश्लेषित और वास्तविक चेहरों के बीच की दूरी
जैसा कि रेखांकन से देखा जा सकता है, परीक्षण डेटा प्रशिक्षण वाले लोगों की तुलना में उत्पन्न छवियों के करीब है। इसके अलावा "नकली से परीक्षण" दूरी "नकली से वास्तविक" से बहुत अलग नहीं है। यह निम्नानुसार है कि प्राप्त नमूने केवल प्रशिक्षण सेट के समान संश्लेषित चेहरे नहीं हैं, बल्कि पूरी तरह से नए चेहरे हैं।
अंत में, प्रारंभिक डेटासेट उत्पन्न करने की संभावना को सत्यापित करने के लिए, एक गुणात्मक मूल्यांकन किया गया था: इस मॉडल द्वारा प्राप्त चेहरे की बनावट की तुलना L2 मीट्रिक में उनके निकटतम पड़ोसी के साथ की गई थी।

सिंथेसाइज्ड टेक्सचर (ऊपर) बनाम निकटतम वास्तविक "पड़ोसी" (नीचे)
जैसा कि आप देख सकते हैं, निकटतम वास्तविक बनावट मूल लोगों से काफी अलग हैं, जो हमें
नए चेहरे उत्पन्न करने की क्षमता के बारे में निष्कर्ष निकालने की अनुमति देता है।
परिणाम
प्रस्तावित मॉडल शायद पहला ऐसा है जो मानव चेहरे की बनावट और ज्यामिति दोनों को वास्तविक रूप से संश्लेषित करने में सक्षम है। यह चेहरे या चेहरे के पुनर्निर्माण मॉडल का पता लगाने और पहचानने के लिए उपयोगी हो सकता है। इसके अलावा, यह उन मामलों में उपयोग किया जा सकता है जहां कई अलग-अलग यथार्थवादी चेहरे की आवश्यकता होती है, उदाहरण के लिए, फिल्म उद्योग या कंप्यूटर गेम में। इसके अलावा, यह संरचना मानव चेहरे के संश्लेषण तक सीमित नहीं है, लेकिन वास्तव में वस्तुओं के अन्य वर्गों के लिए उपयोग किया जा सकता है जहां डेटा वृद्धि संभव है।
मूलअनूदित - स्टानिस्लाव लिट्विनोव।