यह नोट JPoint 2018 सम्मेलन से मेरी रिपोर्ट "अक्षम कोड का उपयोग करके प्रदर्शन को कैसे बर्बाद करें" का एक लिखित संस्करण है। आप सम्मेलन पृष्ठ पर वीडियो और स्लाइड देख सकते हैं। अनुसूची में, रिपोर्ट को स्मूथी के एक आक्रामक ग्लास के साथ चिह्नित किया जाता है, इसलिए सुपर जटिल कुछ भी नहीं होगा, शुरुआती लोगों के लिए यह अधिक संभावना है।
रिपोर्ट का विषय:
- इसमें अड़चनों को खोजने के लिए कोड को कैसे देखें
- आम एंटीपार्टर्न
- गैर-स्पष्ट रेक
- रेक बायपास
किनारे पर, उन्होंने रिपोर्ट में कुछ गलतियाँ / चूक बताई हैं, उन्हें यहाँ नोट किया गया है। टिप्पणियाँ भी स्वागत है।
प्रदर्शन पर प्रभाव
एक उपयोगकर्ता वर्ग है:
class User { String name; int age; }
हमें वस्तुओं की एक दूसरे से तुलना करने की आवश्यकता है, इसलिए हम equals और hashCode विधियों की घोषणा करते हैं:
import lombok.EqualsAndHashCode; @EqualsAndHashCode class User { String name; int age; }
कोड व्यावहारिक है, सवाल अलग है: क्या इस कोड का प्रदर्शन सबसे अच्छा होगा? इसका उत्तर देने के लिए, आइए Object::equals की विशेषताओं को याद करते हैं Object::equals विधि: यह केवल तभी सकारात्मक परिणाम देता है जब तुलना किए जा रहे सभी फ़ील्ड समान हों, अन्यथा परिणाम नकारात्मक होगा। दूसरे शब्दों में, एक अंतर पहले से ही एक नकारात्मक परिणाम के लिए पर्याप्त है।
@EqualsAndHashCode लिए जनरेट किए गए कोड को देखने के @EqualsAndHashCode हम कुछ इस तरह देखेंगे:
public boolean equals(Object that) {
खेतों की जाँच करने का क्रम उनकी घोषणा के क्रम से मेल खाता है, जो हमारे मामले में सबसे अच्छा समाधान नहीं है, क्योंकि equals उपयोग करने वाली वस्तुओं की तुलना करना सरल प्रकारों की तुलना में "कठिन" है।
ठीक है, आइए आइडिया का उपयोग करके equals/hashCode विधियों को बनाने की कोशिश करते हैं:
@Override public boolean equals(Object o) { if (this == o) { return true; } if (o == null || getClass() != o.getClass()) { return false; } User that = (User) o; return age == that.age && Objects.equals(name, that.name); }
एक आइडिया स्मार्ट कोड बनाता है जो विभिन्न प्रकार के डेटा की तुलना करने की जटिलता को जानता है। खैर, हम @EqualsAndHashCode को @EqualsAndHashCode और हम स्पष्ट रूप से equals/hashCode @EqualsAndHashCode लिखेंगे। अब देखते हैं कि जब क्लास बढ़ती है तो क्या होता है:
class User { List<T> props; String name; int age; }
equals/hashCode :
@Override public boolean equals(Object o) { if (this == o) { return true; } if (o == null || getClass() != o.getClass()) { return false; } User that = (User) o; return age == that.age && Objects.equals(props, that.props)
स्ट्रिंग्स की तुलना करने से पहले सूची की तुलना की जाती है, जो स्ट्रिंग्स अलग होने पर कोई मतलब नहीं है। पहली नज़र में, बहुत अंतर नहीं है, क्योंकि समान लंबाई के तारों की तुलना संकेतों द्वारा की जाती है (यानी, स्ट्रिंग की लंबाई के साथ तुलना समय बढ़ता है):
एक अशुद्धि थीjava.lang.String::equals विधि घुसपैठ है , इसलिए निष्पादन पर तुलना पर कोई संकेत नहीं है।
अब दो ArrayList (सबसे अधिक इस्तेमाल की जाने वाली सूची कार्यान्वयन के रूप में) की तुलना करने पर विचार करें। ArrayList , हम यह जानकर आश्चर्यचकित हैं कि इसमें equals का अपना कार्यान्वयन नहीं है, लेकिन एक अंतर्निहित कार्यान्वयन का उपयोग करता है:
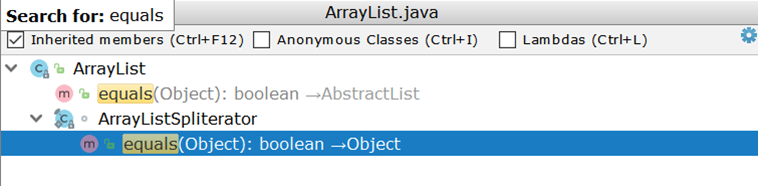
यहाँ महत्वपूर्ण है दो पुनरावृत्तियों का निर्माण और उनके माध्यम से जोड़ीदार मार्ग। मान लें कि दो ArrayList :
- 1 से 99 तक एक संख्या में
- 1 से 100 तक दूसरी संख्या में
आदर्श रूप से, यह दो सूचियों के आकार की तुलना करने के लिए पर्याप्त होगा और यदि वे मेल नहीं खाते हैं, तो तुरंत एक नकारात्मक परिणाम लौटाते हैं (जैसा कि AbstractSet करता है), वास्तव में, 99 तुलनाएं की जाएंगी और केवल सौवें पर यह स्पष्ट हो जाएगा कि सूचियां अलग हैं।
कोटलीनियों के साथ क्या है?
data class User(val name: String, val age: Int);
यहाँ सब कुछ लोम्बोक जैसा है - तुलना क्रम घोषणा के क्रम से मेल खाता है:
public boolean equals(Object o) { if (this == o) { return true; } if (o instanceof User) { User u = (User) o; if (Intrinsics.areEqual(name, u.name) && age == u.age) {
वर्कअराउंड के रूप में, आप मैन्युअल रूप से फ़ील्ड घोषणाओं को व्यवस्थित कर सकते हैं।
आइए कार्य को जटिल करते हैं
void check(Dto dto) { SomeEntity entity = jpaRepository.findOne(dto.getId()); boolean valid = dto.isValid(); if (valid && entity.hasGoodRating()) {
कोड में डेटाबेस तक पहुंच शामिल है, यहां तक कि जब तीर द्वारा इंगित शर्तों की जांच करने का परिणाम अग्रिम में अनुमानित है। यदि valid चर का मान गलत है, तो if ब्लॉक में कोड कभी निष्पादित नहीं होगा, जिसका अर्थ है कि आप अनुरोध के बिना कर सकते हैं:
void check(Dto dto) { boolean valid = dto.isValid(); if (valid && hasGoodRating(dto)) {
किनारे से ध्यान देंजब इकाई JpaRepository::findOne से वापस लौटाया जा सकता है तो निरर्थक हो सकता है JpaRepository::findOne पहले JpaRepository::findOne ही पहले स्तर के कैश में है - फिर कोई अनुरोध नहीं होगा।
स्पष्ट शाखा के बिना एक समान उदाहरण:
boolean checkChild(Dto dto) { Long id = dto.getId(); Entity entity = jpaRepository.findOne(id); return dto.isValid() && entity.hasChild(); }
एक त्वरित वापसी आपको अनुरोध में देरी करने की अनुमति देता है:
boolean checkChild(Dto dto) { if (!dto.isValid()) { return false; } return jpaRepository.findOne(dto.getId()).hasChild(); }
एक स्पष्ट रूप से स्पष्ट जोड़ जो रिपोर्ट में दिखाई नहीं दियाकल्पना करें कि एक निश्चित चेक एक समान इकाई का उपयोग करता है:
@Entity class ParentEntity { @ManyToOne(fetch = LAZY) @JoinColumn(name = "CHILD_ID") private ChildEntity child; @Enumerated(EnumType.String) private SomeType type;
यदि चेक एक ही इकाई का उपयोग करता है, तो आपको यह सुनिश्चित करना चाहिए कि पहले से लोड किए गए फ़ील्ड में कॉल के बाद "आलसी" बाल संस्थाओं / संग्रह को कॉल किया जाता है। पहली नज़र में, एक अतिरिक्त अनुरोध का समग्र चित्र पर महत्वपूर्ण प्रभाव नहीं पड़ेगा, लेकिन जब कोई कार्य लूप में किया जाता है तो सब कुछ बदल सकता है।
निष्कर्ष: व्यक्तिगत कार्यों की बढ़ती जटिलता के क्रम में कार्यों / चेकों की श्रृंखला का आदेश दिया जाना चाहिए, शायद उनमें से कुछ को प्रदर्शन नहीं करना होगा।
चक्र और थोक प्रसंस्करण
निम्नलिखित उदाहरण को विशेष स्पष्टीकरण की आवश्यकता नहीं है:
@Transactional void enrollStudents(Set<Long> ids) { for (Long id : ids) { Student student = jpaRepository.findOne(id);
कई डेटाबेस प्रश्नों के कारण, कोड धीमा है।
टिप्पणीप्रदर्शन तब और भी अधिक डूब सकता है, जब किसी लेनदेन के बाहर enrollStudents विधि निष्पादित की जाती है: तो osdjrJpaRepository::findOne प्रत्येक कॉल osdjrJpaRepository::findOne को एक नए लेन-देन ( SimpleJpaRepository देखें) में निष्पादित किया जाएगा, जिसका अर्थ है कि डेटाबेस से कनेक्शन प्राप्त करना और वापस करना, साथ ही साथ प्रथम स्तर कैश बनाना और फ्लशिंग करना।
ठीक:
@Transactional void enrollStudents(Set<Long> ids) { if (ids.isEmpty()) { return; } for (Student student : jpaRepository.findAll(ids)) { enroll(student); } }
चलो चाबियों के संग्रह के लिए रनटाइम (माइक्रोसेकंड में) को मापें (10 और 100 टुकड़े) बेंचमार्क
टिप्पणीयदि आप Oracle का उपयोग करते हैं और findAll लिए 1000 से अधिक कुंजियाँ पास findAll , तो आपको अपवाद ORA-01795: maximum number of expressions in a list is 1000 findAll मिलेगा ORA-01795: maximum number of expressions in a list is 1000 ।
इसके अलावा, एक भारी (कई कुंजियों के साथ) -सीरीज in प्रदर्शन करना एन प्रश्नों से भी बदतर हो सकता है। यह सब विशिष्ट अनुप्रयोग पर निर्भर करता है, इसलिए चक्र के बड़े पैमाने पर प्रसंस्करण के लिए यांत्रिक प्रतिस्थापन प्रदर्शन को नीचा कर सकता है।
एक ही विषय पर एक अधिक जटिल उदाहरण
for (Long id : ids) { Region region = jpaRepository.findOne(id); if (region == null) {
इस स्थिति में, हम लूप को JpaRepository::findAll प्रतिस्थापित नहीं कर सकते, JpaRepository::findAll यह तर्क को तोड़ देगा: JpaRepository::findAll से प्राप्त सभी मान JpaRepository::findAll null नहीं होगा और if ब्लॉक काम नहीं करेगा।
तथ्य यह है कि प्रत्येक डेटाबेस कुंजी के लिए हमें इस कठिनाई को हल करने में मदद करेगा
वास्तविक मूल्य या उसकी अनुपस्थिति या तो देता है। यानी एक अर्थ में, एक डेटाबेस एक शब्दकोश है। बॉक्स से जावा हमें डिक्शनरी का तैयार किया हुआ कार्यान्वयन देता है - HashMap - जिसके शीर्ष पर हम डेटाबेस को बदलने के लिए तर्क का निर्माण करेंगे:
Map<Long, Region> regionMap = jpaRepository.findAll(ids) .stream() .collect(Collectors.toMap(Region::getId, Function.identity())); for (Long id : ids) { Region region = map.get(id); if (region == null) { region = new Region(); region.setId(id); } use(region); }
उल्टा उदाहरण
यह कोड हमेशा संस्थाओं की सूची को बचाने के लिए एक नया लेनदेन बनाता है। एक नए लेनदेन को खोलने वाले तरीके से कई कॉल करने के साथ शुरू होता है:
समाधान: Saver::save लागू करें Saver::save संपूर्ण डेटा सेट के लिए तुरंत विधि Saver::save :
@Transactional public void audit(List<AuditDto> inserts) { List<AuditEntity> bulk = inserts .map(this::toEntities) .flatMap(List::stream)
बहुत सारे लेन-देन एक में विलय हो जाते हैं, जो एक ठोस वृद्धि (माइक्रोसेकंड में समय) देता है: बेंचमार्क
कई लेन-देन के साथ एक उदाहरण को औपचारिक बनाना मुश्किल है, जिसे JpaRepository::findOne कॉल करने के बारे में नहीं कहा जा सकता है JpaRepository::findOne एक लूप में।
दृष्टिकोण न केवल डेटाबेस पर लागू होता है, इसलिए टैगिर लानी वलेव आगे बढ़ गए। और अगर पहले हमने ऐसा लिखा था:
List<Long> list = new ArrayList<>(); for (Long id : items) { list.add(id); }
और सब कुछ ठीक था, अब "आइडिया" खुद को सही करने का सुझाव देता है:
List<Long> list = new ArrayList<>(); list.addAll(items);
लेकिन यहां तक कि यह विकल्प हमेशा इसे संतुष्ट नहीं करता है, क्योंकि आप इसे और भी छोटा और तेज बना सकते हैं:
List<Long> list = new ArrayList<>(items);
तुलना (एनएस में समय)ArrayList के लिए, यह सुधार ध्यान देने योग्य वृद्धि देता है:
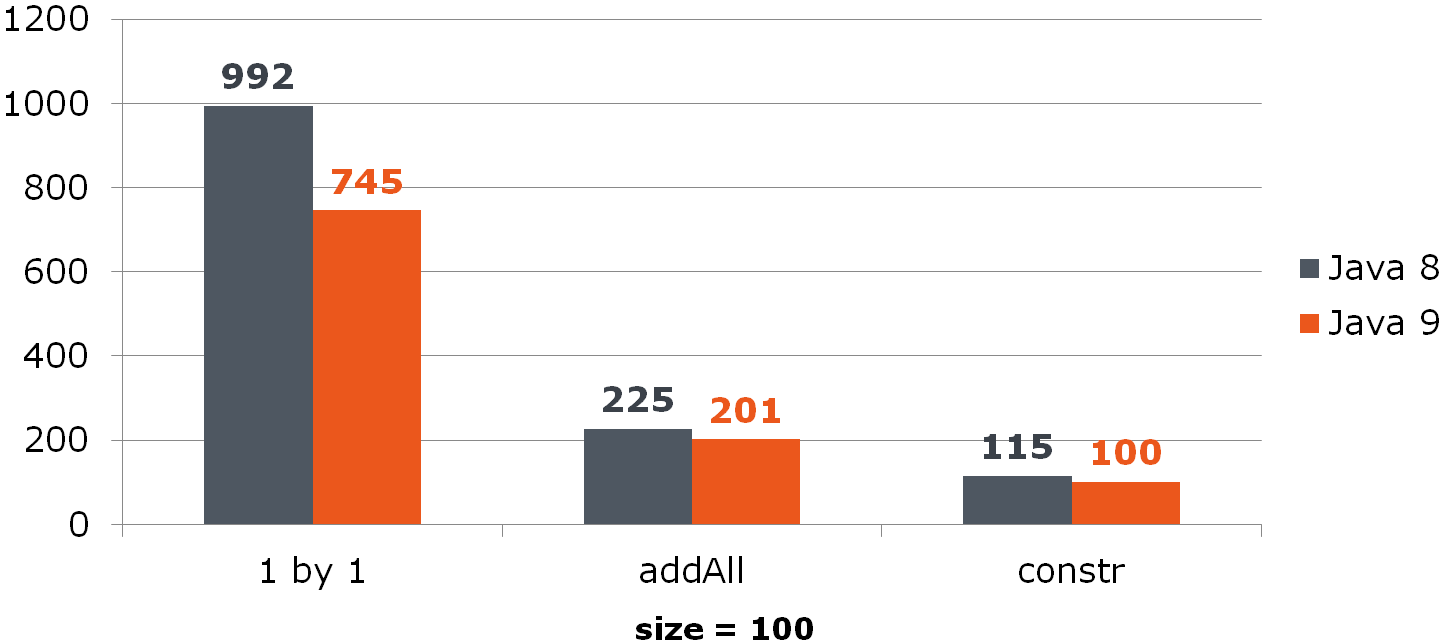
हैशसेट के लिए, यह इतना रसदार नहीं है:

बेंचमार्क
ArrayList से हटाना
for (int i = from; i < to; i++) { list.remove(from); }
समस्या List::remove विधि लागू करने में है:
public E remove(int index) { Objects.checkIndex(index, size); modCount++; E oldValue = elementData(index); int numMoved = size - index - 1; if (numMoved > 0) { System.arraycopy(array, index + 1, array, index, numMoved);
समाधान:
list.subList(from, to).clear();
लेकिन क्या होगा यदि स्रोत कोड में दूरस्थ मूल्य का उपयोग किया जाता है?
for (int i = from; i < to; i++) { E removed = list.remove(from); use(removed); }
अब आपको पहले साफ की गई सूची से गुजरना होगा:
List<String> removed = list.subList(from, to); removed.forEach(this::use); removed.clear();
यदि आप वास्तव में चक्र में हटाना चाहते हैं, तो सूची से गुजरने की दिशा में बदलाव से दर्द को कम करने में मदद मिलेगी। इसका अर्थ सेल की सफाई के बाद कम संख्या में तत्वों को स्थानांतरित करना है:
सभी तीन तरीकों की तुलना करें (कॉलम के तहत 100 आइटम की सूची से 100% हटाए गए आइटम हैं):
वैसे, क्या किसी ने विसंगति को नोटिस किया?
देखने के लिए
यदि हम अंत से चल रहे सभी डेटा को हटा देते हैं, तो अंतिम तत्व हमेशा हटा दिया जाता है और कोई बदलाव नहीं होता है:
बेंचमार्क
निष्कर्ष: सिंगल ऑपरेशंस की तुलना में मास ऑपरेशन अक्सर तेज होते हैं।
स्कोप और प्रदर्शन
इस कोड को किसी विशेष स्पष्टीकरण की आवश्यकता नहीं है:
void leaveForTheSecondYear() { List<Student> naughty = repository.findNaughty(); List<Student> underAchieving = repository.findUnderAchieving();
हम गुंजाइश को संकीर्ण करते हैं, जो शून्य से 1 क्वेरी देता है:
void leaveForTheSecondYear() { List<Student> naughty = repository.findNaughty(); if (Settings.leaveBothCategories()) { List<Student> underAchieving = repository.findUnderAchieving();
और यहां चौकस पाठक को पूछना चाहिए: स्थैतिक विश्लेषण के बारे में क्या? सतह पर पड़े सुधार के बारे में आइडिया ने हमें क्यों नहीं बताया?
तथ्य यह है कि स्थिर विश्लेषण की संभावनाएं सीमित हैं: यदि विधि जटिल है (विशेष रूप से डेटाबेस के साथ बातचीत) और सामान्य स्थिति को प्रभावित करती है, तो इसके निष्पादन को स्थानांतरित करने से आवेदन टूट सकता है। स्थैतिक विश्लेषक बहुत सरल निष्पादन की रिपोर्ट करने में सक्षम है, जिसके हस्तांतरण का कहना है कि ब्लॉक के अंदर कुछ भी नहीं टूटेगा।
आप एक ersatz के रूप में चर हाइलाइटिंग का उपयोग कर सकते हैं, लेकिन फिर से, इसे सावधानी से उपयोग करें, क्योंकि दुष्प्रभाव हमेशा संभव हैं। आप स्टेटिक तरीकों को इंगित करने के लिए जेटब्रिंस-एनोटेशन लाइब्रेरी से उपलब्ध एनोटेशन @org.jetbrains.annotations.Contract(pure = true) उपयोग कर सकते हैं:
निष्कर्ष: अधिक बार नहीं, अधिक काम केवल प्रदर्शन को खराब करता है।
सबसे असामान्य उदाहरण
@Service public class RemoteService { private ContractCounter contractCounter; @Transactional(readOnly = true)
यह कार्यान्वयन लेन-देन की आवश्यकता होने पर भी लेनदेन खोलता है (विधि से त्वरित रिटर्न -1)।
आपको बस ContractCounter::countContracts अंदर की लेन-देन को दूर करना होगा, जहाँ इसकी आवश्यकता है, और इसे "बाहरी" विधि से हटा दें।
मामले के लिए निष्पादन समय की तुलना करें जब -1 (ns) लौटाया जाता है: मेमोरी खपत (बाइट्स) की तुलना करें: बेंचमार्क
निष्कर्ष: नियंत्रकों और "बाहरी" दिखने वाली सेवाओं को लेन-देन से मुक्त करने की आवश्यकता है (यह उनकी जिम्मेदारी नहीं है) और इनपुट डेटा सत्यापन के पूरे तर्क, जिसे डेटाबेस और लेन-देन के घटकों तक पहुंच की आवश्यकता नहीं है, को वहां से हटा दिया जाना चाहिए।
परिवर्तित दिनांक / समय स्ट्रिंग के लिए
शाश्वत कार्यों में से एक तारीख / समय को एक स्ट्रिंग में बदल रहा है। G8 से पहले, हमने यह किया:
SimpleDateFormat formatter = new SimpleDateFormat("dd.MM.yyyy"); String dateAsStr = formatter.format(date);
JDK 8 की रिलीज़ के साथ, हमें LocalDate/LocalDateTime मिला और, तदनुसार, DateTimeFormatter
DateTimeFormatter formatter = ofPattern("dd.MM.yyyy"); String dateAsStr = formatter.format(localDate);
आइए इसके प्रदर्शन को मापें:
Date date = new Date(); LocalDate localDate = LocalDate.now(); SimpleDateFormat sdf = new SimpleDateFormat("dd.MM.yyyy"); DateTimeFormatter dtf = DateTimeFormatter.ofPattern("dd.MM.yyyy"); @Benchmark public String simpleDateFormat() { return sdf.format(date); } @Benchmark public String dateTimeFormatter() { return dtf.format(localDate); }
प्रश्न: मान लीजिए कि हमारी सेवा को बाहर से डेटा प्राप्त होता है और हम java.util.Date मना नहीं कर सकते। क्या यह हमारे लिए फायदेमंद होगा कि Date को LocalDate परिवर्तित करें यदि बाद वाला तेजी से स्ट्रिंग में परिवर्तित हो जाए? आइए गिनती:
@Benchmark public String measureDateConverted(Data data) { LocalDate localDate = toLocalDate(data.date); return data.dateTimeFormatter.format(localDate); } private LocalDate toLocalDate(Date date) { return date.toInstant().atZone(ZoneId.systemDefault()).toLocalDate(); }
इस प्रकार, "नौ" का उपयोग करते समय रूपांतरण Date -> LocalDate फायदेमंद है। G8 में, रूपांतरण की लागत DateTimeFormatter -a के सभी लाभों को DateTimeFormatter करेगी।
बेंचमार्क
निष्कर्ष: नए समाधानों का लाभ उठाएं।
एक और "आठ"
इस कोड में, हम स्पष्ट अतिरेक देखते हैं:
Iterator<Long> iterator = items
हम इसे हटा देते हैं:
Iterator<Long> iterator = items
आइए देखें कि प्रदर्शन में कितना सुधार हुआ है: कमाल है ना? मैंने ऊपर तर्क दिया है कि अतिरिक्त कार्य प्रदर्शन को कम करता है। लेकिन यहां हम अतिरिक्त को हटा देते हैं - और (अचानक) यह खराब हो जाता है। यह समझने के लिए कि क्या हो रहा है, दो पुनरावृत्तियों को लें और उन्हें एक आवर्धक कांच के नीचे देखें:
पता चलता है Iterator iterator1 = items.stream().collect(toList()).iterator(); Iterator iterator2 = items.stream().iterator();

पहला पुनरावृत्त नियमित ArrayList$Itr ।
इसके माध्यम से मार्ग सरल है: public boolean hasNext() { return cursor != size; } public E next() { checkForComodification(); int i = cursor; if (i >= size) { throw new NoSuchElementException(); } Object[] elementData = ArrayList.this.elementData; if (i >= elementData.length) { throw new ConcurrentModificationException(); } cursor = i + 1; return (E) elementData[lastRet = i]; }
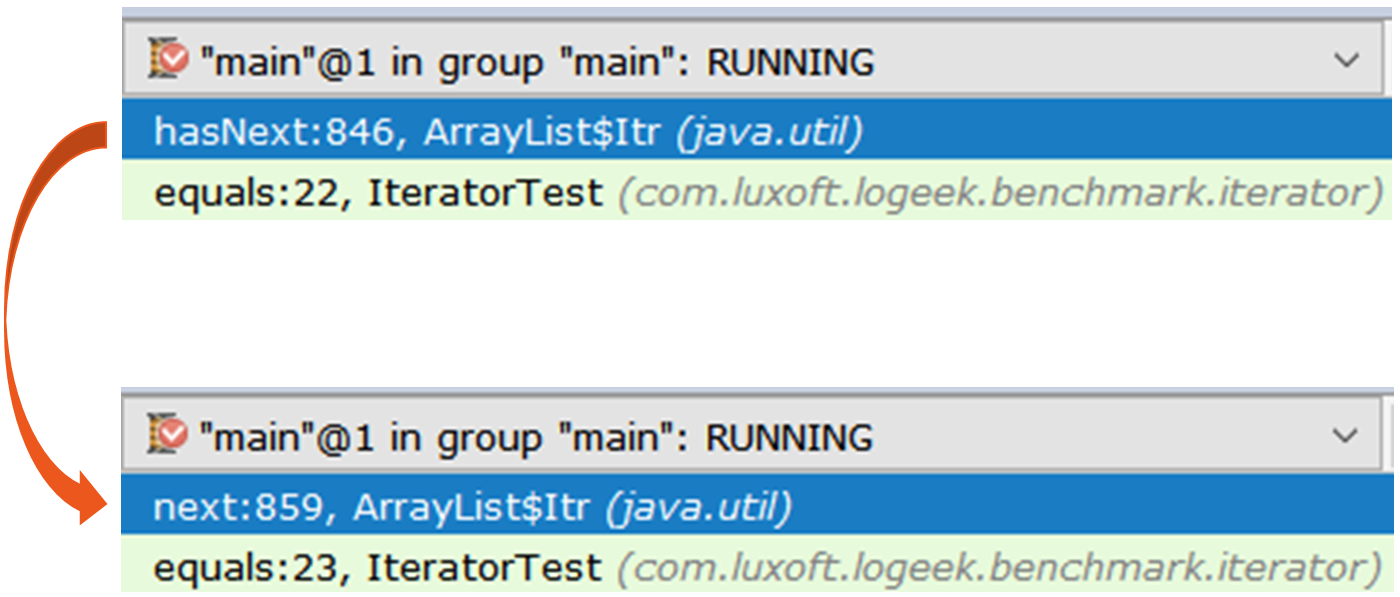
दूसरा अधिक दिलचस्प है, यह Spliterators$Adapter , जो ArrayList$ArrayListSpliterator पर आधारित है।
वहां से गुजरना ज्यादा मुश्किल है आइए async-profiler के माध्यम से पुनरावृति पुनरावृत्ति को देखें:
15.64% juArrayList$ArrayListSpliterator.tryAdvance 10.67% jusSpinedBuffer.clear 9.86% juSpliterators$1Adapter.hasNext 8.81% jusStreamSpliterators$AbstractWrappingSpliterator.fillBuffer 6.01% oojiBlackhole.consume 5.71% jusReferencePipeline$3$1.accept 5.57% jusSpinedBuffer.accept 5.06% cllbir.IteratorFromStreamBenchmark.iteratorFromStream 4.80% jlLong.valueOf 4.53% cllbiIteratorFromStreamBenchmark$$Lambda$8.885721577.apply
यह देखा जा सकता है कि अधिकांश समय इट्रेटर से गुजरने में व्यतीत होता है, हालांकि और बड़े से, हमें इसकी आवश्यकता नहीं है, क्योंकि खोज इस तरह से की जा सकती है:
items .stream() .map(Long::valueOf) .forEach(bh::consume);
Stream::forEach स्पष्ट रूप से एक विजेता है, लेकिन यह अजीब है: यह अभी भी ArrayListSpliterator पर आधारित है, लेकिन इसके उपयोग में काफी सुधार हुआ है।
आइए प्रोफाइल देखें: 29.04% oojiBlackhole.consume 22.92% juArrayList$ArrayListSpliterator.forEachRemaining 14.47% jusReferencePipeline$3$1.accept 8.79% jlLong.valueOf 5.37% cllbiIteratorFromStreamBenchmark$$Lambda$9.617691115.accept 4.84% cllbiIteratorFromStreamBenchmark$$Lambda$8.1964917002.apply 4.43% jusForEachOps$ForEachOp$OfRef.accept 4.17% jusSink$ChainedReference.end 1.27% jlInteger.longValue 0.53% jusReferencePipeline.map
इस प्रोफाइल में, ज्यादातर समय Blackhole अंदर के मूल्यों को "निगलने" में बिताया जाता है। एक इटरेटर की तुलना में, समय का एक बड़ा हिस्सा सीधे जावा कोड के निष्पादन पर खर्च किया जाता है। यह माना जा सकता है कि कारण कचरा संग्रह का कम विशिष्ट भार है, इसकी तुलना इट्रेटर ब्रूट बल से की जाती है। की जाँच करें:
forEach:·gc.alloc.rate.norm 100 avgt 30 216,001 ± 0,002 B/op iteratorFromStream:·gc.alloc.rate.norm 100 avgt 30 416,004 ± 0,006 B/op
वास्तव में, Stream::forEach स्मृति की आधी खपत प्रदान करता है।
यह तेज क्यों है?ब्लैक होल में शुरू से ही कॉल की श्रृंखला इस तरह दिखती है:
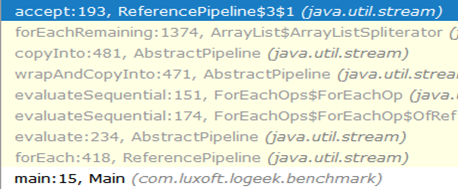
जैसा कि आप देख सकते हैं, ArrayListSpliterator::tryAdvance चेन से गायब हो गया, और ArrayListSpliterator::forEachRemaining दिखाई दी:
उच्च गति ArrayListSpliterator::forEachRemaining 1 विधि कॉल में संपूर्ण सरणी के माध्यम से पास का उपयोग करके प्राप्त किया जाता है। इटरेटर का उपयोग करते समय, मार्ग एक तत्व तक सीमित है, इसलिए हम हमेशा ArrayListSpliterator::tryAdvance खिलाफ आराम ArrayListSpliterator::tryAdvance ।
ArrayListSpliterator::forEachRemaining में पूरे सरणी तक पहुंच है और अतिरिक्त कॉल के बिना एक गिनती चक्र के साथ इस पर ArrayListSpliterator::forEachRemaining करता है।
महत्वपूर्ण सूचनाकृपया ध्यान दें कि यांत्रिक प्रतिस्थापन
Iterator<Long> iterator = items .stream() .map(Long::valueOf) .collect(toList()) .iterator(); while (iterator.hasNext()) { bh.consume(iterator.next()); }
पर
items .stream() .map(Long::valueOf) .forEach(bh::consume);
यह हमेशा समतुल्य नहीं होता है, क्योंकि पहले मामले में हम स्ट्रीम को प्रभावित किए बिना पास के लिए डेटा की एक प्रति का उपयोग करते हैं, और दूसरे मामले में डेटा को सीधे स्ट्रीम से लिया जाता है।
बेंचमार्क
निष्कर्ष: जब डेटा के जटिल अभ्यावेदन के साथ काम करते हैं, तो इस तथ्य के लिए तैयार रहें कि "लोहे" के नियम (अतिरिक्त कार्य हानि) काम करना बंद कर दें। ऊपर दिए गए उदाहरण से पता चलता है कि प्रतीत होता है कि बहुत ही शानदार मध्यवर्ती सूची गणना के तेजी से कार्यान्वयन का लाभ देती है।
दो टोटके
StackTraceElement[] trace = th.getStackTrace(); StackTraceElement[] newTrace = Arrays .asList(trace) .subList(0, depth) .toArray(new StackTraceElement[newDepth]);
पहली चीज जो आपकी आंख को पकड़ती है, वह सड़ा हुआ "सुधार" है, अर्थात्, नॉनजरो की लंबाई की एक सरणी को Collection::toArray गुजरना। यह बहुत विस्तार से बताता है कि यह हानिकारक क्यों है।
दूसरी समस्या इतनी स्पष्ट नहीं है, और इसकी समझ के लिए हम समीक्षक और इतिहासकार के काम के बीच समानता ला सकते हैं।
इस बारे में रॉबिन कॉलिंगवुड लिखते हैं: . :
1)
2)
3)
, :
StackTraceElement[] trace = th.getStackTrace(); StackTraceElement[] newTrace = Arrays.copyOf(trace, depth);
List<T> list = getList(); Set<T> set = getSet(); return list.stream().allMatch(set::contains);
, , :
List<T> list = getList(); Set<T> set = getSet(); return set.containsAll(list);
:
interface FileNameLoader { String[] loadFileNames(); }
:
private FileNameLoader loader; void load() { for (String str : asList(loader.loadFileNames())) {
, forEach , :
private FileNameLoader loader; void load() { for (String str : loader.loadFileNames()) {
: :
, , , . , : "" ( ), "" ( ), .
→
→