 हमने हाल ही में इस बारे में बात की कि हम अपने स्वयं के RFM सेगमेंटर के साथ क्यों आए , जो RFM विश्लेषण को 20 सेकंड में करने में मदद करता है , और यह दिखाया कि मार्केटिंग में इसके परिणामों का उपयोग कैसे करें।
हमने हाल ही में इस बारे में बात की कि हम अपने स्वयं के RFM सेगमेंटर के साथ क्यों आए , जो RFM विश्लेषण को 20 सेकंड में करने में मदद करता है , और यह दिखाया कि मार्केटिंग में इसके परिणामों का उपयोग कैसे करें।
अब हम बताते हैं कि इसकी व्यवस्था कैसे की जाती है।
कार्य: एक नया RFM विश्लेषण एल्गोरिदम लिखें
हम RFM विश्लेषण के लिए उपलब्ध दृष्टिकोणों से संतुष्ट नहीं थे। इसलिए, हमने अपना सेगमेंट बनाने का फैसला किया, जो:
- यह अपने आप पूरी तरह से काम करता है।
- 3 से 15 सेगमेंट में बनाता है।
- ग्राहक की गतिविधि के किसी भी क्षेत्र के लिए अनुकूलन (यह कोई फर्क नहीं पड़ता कि यह क्या है: एक फूल या बिजली उपकरण की दुकान)।
- यह उपलब्ध आंकड़ों के आधार पर खंडों की संख्या और स्थान निर्धारित करता है, न कि पूर्वनिर्धारित पैरामीटर जो सार्वभौमिक नहीं हो सकते।
- यह खंडों का चयन करता है ताकि उनके पास हमेशा उपभोक्ता हों (कुछ खंड खाली होने पर कुछ दृष्टिकोणों के विपरीत)।
समस्या को कैसे हल करें
जब हमें कार्य का एहसास हुआ, तो हमने महसूस किया कि यह मनुष्य की शक्ति से परे है, और उसने कृत्रिम बुद्धिमत्ता से मदद मांगी। उपभोक्ताओं को खंडों में विभाजित करने के लिए कार सिखाने के लिए, हमने क्लस्टरिंग विधियों का उपयोग करने का निर्णय लिया।
क्लस्टरिंग विधियों का उपयोग डेटा में एक संरचना की खोज करने और उनमें समान वस्तुओं के समूहों का चयन करने के लिए किया जाता है - बस आपको RFM विश्लेषण की क्या आवश्यकता है।
क्लस्टरिंग से तात्पर्य कक्षा के मशीन सीखने के तरीकों से है " शिक्षक के बिना सीखना ।" एक वर्ग को ऐसा कहा जाता है क्योंकि डेटा है, लेकिन कोई नहीं जानता कि इसके साथ क्या करना है, इसलिए यह एक मशीन को नहीं सिखा सकता है।
हम बाजार में इस दृष्टिकोण का उपयोग करने वाली कंपनियों को खोजने में सक्षम नहीं थे। यद्यपि उन्हें एक लेख मिला जिसमें लेखक इस विषय पर वैज्ञानिक अनुसंधान करता है। लेकिन, जैसा कि हमने अपने स्वयं के अनुभव से समझा, विज्ञान से व्यवसाय तक सभी एक कदम पर नहीं है।
स्टेज 1. डाटा प्रोसेसिंग
क्लस्टरिंग के लिए डेटा तैयार करने की आवश्यकता है।
सबसे पहले, हम उन्हें गलत मानों के लिए जाँचते हैं: नकारात्मक मान इत्यादि।
फिर हम उत्सर्जन को हटाते हैं - असामान्य विशेषताओं वाले उपभोक्ता। उनमें से कुछ हैं, लेकिन वे परिणाम को बहुत प्रभावित कर सकते हैं, और बेहतर के लिए नहीं। उन्हें अलग करने के लिए, हम एक विशेष मशीन सीखने की विधि का उपयोग करते हैं - स्थानीय आउटलाइयर फैक्टर ।

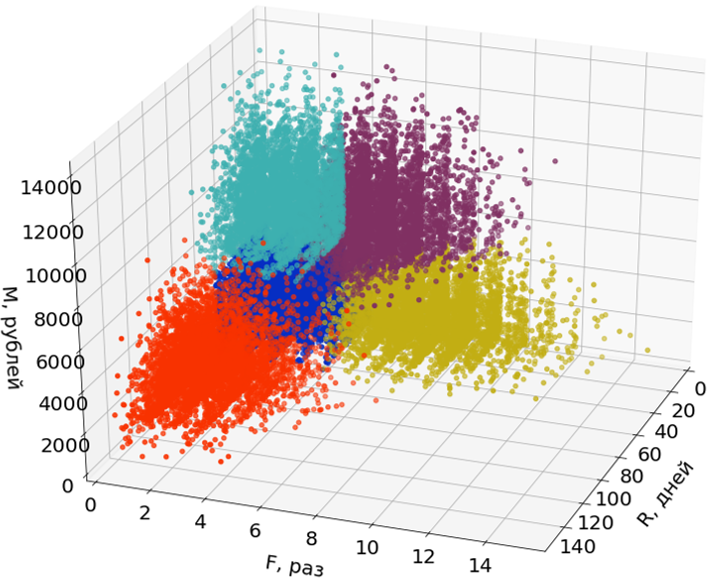
यहाँ चित्रों में मैं धारणा को सुगम बनाने के लिए तीन में से केवल दो आयामों (R और M) का उपयोग करता हूँ।
उत्सर्जन सेगमेंट के निर्माण में भाग नहीं लेते हैं, लेकिन सेगमेंट बनने के बाद उन्हें आवंटित किया जाता है।
स्टेज 2. उपभोक्ता क्लस्टरिंग
मैं शब्दावली को स्पष्ट करूंगा: समूहों द्वारा मेरा मतलब उन वस्तुओं के समूहों से है जो क्लस्टरिंग एल्गोरिदम का उपयोग करने के परिणामस्वरूप प्राप्त होते हैं, और अंतिम परिणाम के रूप में खंड, अर्थात, आरएफएम विश्लेषण का परिणाम है।
कई दर्जन क्लस्टरिंग एल्गोरिदम हैं। उनमें से कुछ के उदाहरण scikit-learn पैकेज प्रलेखन में पाए जा सकते हैं।
हमने विभिन्न संशोधनों के साथ आठ एल्गोरिदम की कोशिश की। अधिकांश के पास पर्याप्त मेमोरी नहीं थी। या उनके काम का समय अनंत तक चला गया। लगभग सभी एल्गोरिदम जो तकनीकी रूप से कार्य का सामना करने में कामयाब रहे, ने भयानक परिणाम दिए: उदाहरण के लिए, लोकप्रिय डीबीएससीएएन ने 55% वस्तुओं को शोर माना, और बाकी को 4302 समूहों में विभाजित किया।
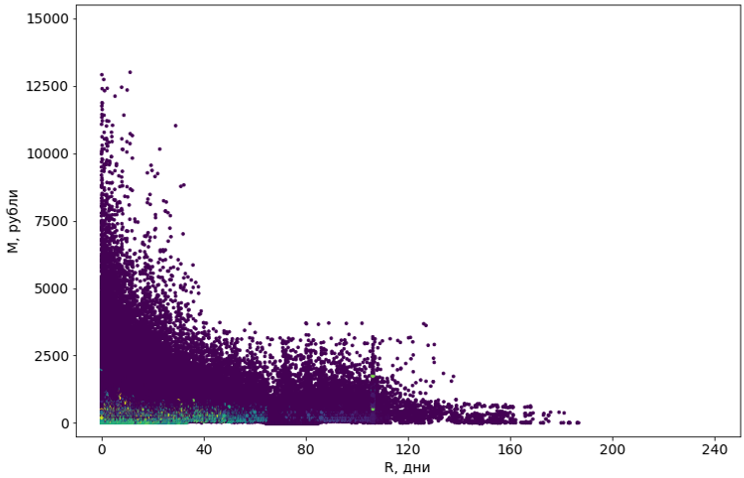
वायलेट ऑब्जेक्ट्स को "शोर" के रूप में परिभाषित किया गया है
नतीजतन, हमने के-मीन्स (के -मीन्स ) एल्गोरिथ्म को चुना क्योंकि यह बिंदुओं के समूहों के लिए नहीं दिखता है, लेकिन बस केंद्रों के आसपास बिंदुओं को समूहित करता है। जैसा कि यह निकला, यह सही निर्णय था।
लेकिन पहले, हमने कुछ समस्याओं को हल किया:
अस्थिरता। के-मीन्स सहित अधिकांश क्लस्टरिंग एल्गोरिदम के साथ यह एक ज्ञात समस्या है। अस्थिरता इस तथ्य में निहित है कि दोहराया लॉन्च के साथ, परिणाम भिन्न हो सकते हैं, क्योंकि यादृच्छिकता के एक तत्व का उपयोग किया जाता है।
इसलिए, हम कई बार क्लस्टर करते हैं, और फिर क्लस्टर करते हैं, लेकिन पहले से ही क्लस्टर के केंद्र। समूहों के अंतिम केंद्रों के रूप में, हम परिणामी समूहों के केंद्र लेते हैं (अर्थात, पहले समूहों के केंद्रों द्वारा गठित क्लस्टर)।
गुच्छों की संख्या। डेटा अलग हो सकता है, और क्लस्टर की संख्या भी अलग होनी चाहिए।
प्रत्येक ग्राहक आधार के लिए क्लस्टरों की इष्टतम संख्या जानने के लिए, हम एक अलग संख्या में क्लस्टर के साथ क्लस्टरिंग करते हैं, और उसके बाद सर्वोत्तम परिणाम का चयन करते हैं ।
स्पीड। K- साधन एल्गोरिथ्म बहुत तेज नहीं है, लेकिन स्वीकार्य (कई सौ उपभोक्ताओं के औसत आधार के लिए कुछ मिनट)। हालांकि, हम इसे कई बार चलाते हैं: सबसे पहले, स्थिरता बढ़ाने के लिए, और दूसरी बात, समूहों की संख्या का चयन करने के लिए। और ऑपरेटिंग समय बहुत बढ़ रहा है।
त्वरण के लिए, हम मिनी बैच K- मीन्स के एक संशोधन का उपयोग करते हैं। यह सभी वस्तुओं के लिए नहीं, बल्कि केवल एक छोटी सी सदस्यता के लिए क्लस्टर केंद्रों को पुनर्गणना करता है। गुणवत्ता काफी कम हो जाती है, लेकिन समय काफी कम हो जाता है।
जैसे ही हमने इन समस्याओं को हल किया, क्लस्टरिंग सफलतापूर्वक आगे बढ़ना शुरू हो गया।
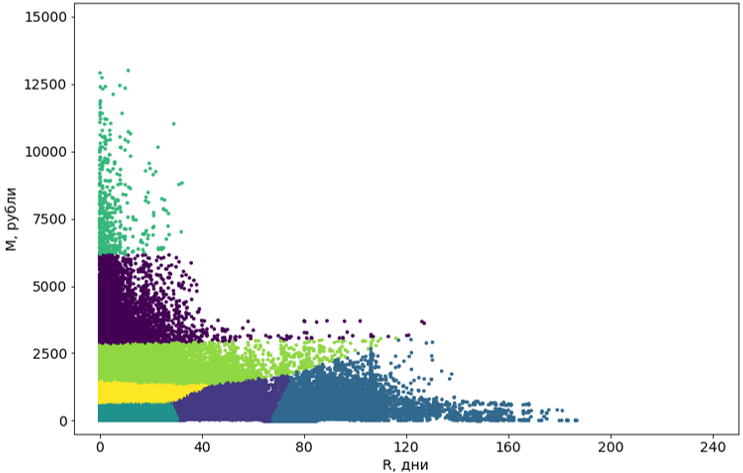
चरण 3. क्लस्टर के बाद के प्रसंस्करण
एल्गोरिथ्म का उपयोग करके प्राप्त किए गए समूहों को एक ऐसे रूप में लाया जाना चाहिए जो धारणा के लिए सुविधाजनक हो।
सबसे पहले, हम इन समूहों को घटता से आयताकार में बदलते हैं। दरअसल, यह उन्हें सेगमेंट बनाता है। खंडों की आयताकारता हमारे सिस्टम की एक आवश्यकता है और इसके अलावा, स्वयं खंडों के लिए समझ को जोड़ती है। कन्वर्ट करने के लिए, हम एक और मशीन लर्निंग एल्गोरिदम का उपयोग करते हैं - निर्णय पेड़ ।
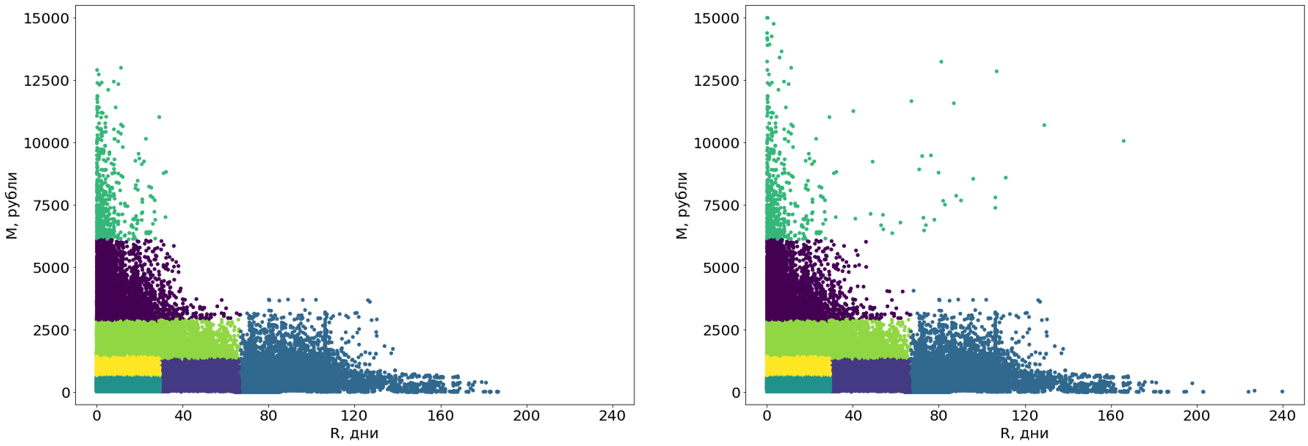
निर्णय ट्री आउटलाइयर-फ्री डेटा पर बनाया गया है, और आउटलेर को तब तैयार सेगमेंट में आवंटित किया गया है
दूसरे, हमने एक और अच्छी बात की - खंडों का वर्णन। एक विशेष एल्गोरिथ्म, एक शब्दकोश का उपयोग करते हुए, लाइव रूसी में प्रत्येक सेगमेंट का वर्णन करता है, ताकि लोगों को स्मृतिहीन संख्याओं को देखते हुए लालसा महसूस न हो।

परीक्षण के परिणाम
उत्पाद तैयार है। लेकिन इससे पहले कि आप बेचना शुरू करें इसे जांचने की जरूरत है। यही है, जांचें कि क्या आरएफएम विश्लेषण किया जाता है जैसा कि हमने इरादा किया था।
हम जानते हैं कि अगर हमने कुछ सार्थक किया है तो यह समझने का सबसे अच्छा तरीका यह है कि विश्लेषण हमारे ग्राहकों के लिए कितना उपयोगी है। और हम ऐसा करेंगे। लेकिन यह एक लंबा समय है, और परिणाम बाद में होंगे, और हम यह जानना चाहते हैं कि हमने अब सफलतापूर्वक काम कैसे पूरा किया है।
इसलिए, एक सरल और तेज़ मीट्रिक के रूप में, हमने "ऐतिहासिक नियंत्रण समूह" विधि का उपयोग किया।
ऐसा करने के लिए, हमने कई डेटाबेस लिए और उन्हें अलग-अलग बिंदुओं पर RFM विश्लेषण का उपयोग करते हुए खंडित किया: एक डेटाबेस राज्य के लिए छह महीने पहले, दूसरा एक साल पहले, आदि।
प्रत्येक आधार के लिए प्रत्येक सेगमेंटेशन के आधार पर, हमने चयनित समय से लेकर वर्तमान तक ग्राहक कार्रवाई के अपने पूर्वानुमान का निर्माण किया। फिर उन्होंने ग्राहकों के वास्तविक व्यवहार के साथ इन पूर्वानुमानों की तुलना की।

छह महीने की नियंत्रण अवधि के साथ एक ऐतिहासिक नियंत्रण समूह पर परीक्षण उदाहरण
तस्वीर में:
- कॉलम R, F और M पारंपरिक रूप से प्रत्येक अक्ष के साथ खंडों की सीमाओं को दर्शाते हैं। यह उस रूप में आधार विभाजन का परिणाम है जिसमें यह एक साल पहले था।
- स्तंभ "आकार" डेटाबेस के कुल आकार के सापेक्ष छह महीने पहले खंड के आकार को दर्शाता है।
- कॉलम "खरीद संभावना" और "राशि" अगले छह महीनों में वास्तविक उपभोक्ता व्यवहार के डेटा हैं।
- खरीद की संभावना को उस खंड से उपभोक्ताओं की संख्या के अनुपात के रूप में परिभाषित किया जाता है जिन्होंने खंड में उपभोक्ताओं की कुल संख्या के लिए खरीदारी की।
- राशि - सभी खंडों के उपभोक्ताओं द्वारा खर्च की गई राशि के सापेक्ष खंड से उपभोक्ताओं द्वारा खर्च की गई कुल राशि।
परिणाम लगातार हैं। उदाहरण के लिए, उन खंडों के ग्राहक जिनके लिए हमने वास्तव में अधिक बार खरीदी गई खरीद की उच्च आवृत्ति की भविष्यवाणी की थी।
यद्यपि हम इस तरह के परीक्षण के आधार पर एल्गोरिथ्म के सही संचालन की गारंटी नहीं दे सकते हैं, हमने तय किया कि यह सफल था।
हम क्या समझते हैं?
मशीन लर्निंग वास्तव में एक व्यापार को हल करने में मदद करने में सक्षम नहीं है, जो बहुत खराब या हल की गई समस्याओं को हल करता है।
लेकिन असली चुनौती कागेल प्रतियोगिता नहीं है। यहां, किसी दिए गए मीट्रिक में बेहतर गुणवत्ता प्राप्त करने के अलावा, आपको यह सोचने की ज़रूरत है कि एल्गोरिथ्म कितना काम करेगा, क्या यह लोगों के लिए सुविधाजनक होगा और सामान्य तौर पर, क्या आपको एमएल का उपयोग करके समस्या को हल करने की आवश्यकता है या आप एक सरल तरीके से आ सकते हैं।
और अंत में, एक औपचारिक गुणवत्ता मीट्रिक की कमी कई बार कार्य को जटिल बनाती है, क्योंकि परिणाम का सही मूल्यांकन करना मुश्किल है।