जब मेरा पहला बेटा केवल दो था, तो वह पहले से ही कारों से प्यार करता था, सभी जानता था और मॉडल (यहां तक कि मैं, अपने दोस्तों के लिए धन्यवाद), छवि के एक छोटे हिस्से द्वारा उन्हें पहचान सकता था। सभी ने कहा: प्रतिभा। हालाँकि उन्होंने इस ज्ञान की पूर्ण निरर्थकता पर ध्यान दिया। और बेटे, इस बीच, उनके साथ सोए, उन्हें लुढ़का, उन्हें एक पंक्ति या एक वर्ग में बिल्कुल व्यवस्थित किया।

जब वह 4 साल का था, तब उसने गिनती करना सीखा, और 5 साल में वह पहले से ही गुणा कर सकता था और 1000 के भीतर जोड़ सकता था। हमने यहां तक कि मैथ वर्कआउट भी खेला (गेम एंड्रॉइड पर इस तरह है - मुझे काम के बाद सबवे में गणना करना पसंद था), और कुछ बिंदु पर वह मेरे लिए शुरू हुआ बस वही करो। और अपने खाली समय में, वह एक मिलियन तक गिना गया, जो चारों ओर जम गया। एक जीनियस! उन्होंने कहा, लेकिन हमें संदेह था कि यह बिल्कुल भी नहीं था।
वैसे, बाजार में, उसने अपनी मां की अच्छी तरह से मदद की - उसने कैलकुलेटर पर विक्रेताओं की तुलना में तेजी से कुल राशि की गणना की।
इसके अलावा, वह कभी कोर्ट पर नहीं खेलता था, साथियों के साथ संवाद नहीं करता था, बगीचे में बच्चों और शिक्षकों के साथ बहुत अच्छी तरह से नहीं मिलता था। सामान्य तौर पर, मैं थोड़ा आरक्षित बच्चा था।
अगला चरण भूगोल था - हमने संख्याओं के प्यार को कहीं और चैनल करने की कोशिश की, और हमारे बेटे को एक पुराने सोवियत एटलस को सौंप दिया। उन्होंने एक महीने तक इसमें डुबकी लगाई, और उसके बाद हमसे शैली में अजीब सवाल पूछना शुरू किया:
- पिताजी, आपको क्या लगता है कि किस देश में एक बड़ा क्षेत्र है: पाकिस्तान या मोजाम्बिक?
"शायद मोजाम्बिक," मैंने जवाब दिया।
- यहाँ यह है! पाकिस्तान का क्षेत्रफल 2,350 किमी 2 जितना है, ”बेटे ने खुशी से जवाब दिया।

उसी समय, वह इन देशों में रहने वाले लोगों में पूरी तरह से दिलचस्पी नहीं ले रहा था, न ही उनकी भाषाएं, न ही कपड़े, न ही लोक संगीत। केवल नंगे नंबर: क्षेत्र, जनसंख्या, खनिज भंडार की मात्रा, आदि।
सभी ने फिर से प्रशंसा की। उन्होंने कहा, "मैं अपने वर्षों से अधिक स्मार्ट हूं", लेकिन फिर से मैं चिंतित था, क्योंकि मैं समझ गया कि यह पूरी तरह से बेकार ज्ञान था, जीवन के अनुभव से बंधा नहीं था, और जिसे विकसित करना जारी रखना मुश्किल था। मुझे जो कुछ मिला, उसका सबसे अच्छा अनुप्रयोग यह गणना करने का एक प्रस्ताव था कि पार्किंग में कितनी कारें फिट होती हैं, अगर कुछ विशेष देश को डामर (पहाड़ी इलाके को ध्यान में रखते हुए) के साथ रोल किया गया था, लेकिन जल्दी से कम हो गया, क्योंकि इससे नरसंहार की बू आती है।
दिलचस्प बात यह है कि इस क्षण तक कारों का विषय पूरी तरह से गायब हो गया, बेटे को अपने विशाल संग्रह से अपनी पसंदीदा कारों का नाम भी याद नहीं था, जिसे हमने रुचि के नुकसान के साथ बाहर करना शुरू कर दिया था। और फिर वह धीरे-धीरे अपने दिमाग में गिनना शुरू कर दिया और जल्द ही देशों के क्षेत्र को भूल गया। उसी समय, उन्होंने साथियों के साथ अधिक संवाद करना शुरू किया, अधिक संपर्क बन गया। जीनियस पास हो गया, दोस्तों ने प्रशंसा करना बंद कर दिया, बेटा गणित और सटीक विज्ञान के लिए एक अच्छे छात्र के साथ सिर्फ एक अच्छा छात्र बन गया।
दोहराव - सीखने की माँ
ऐसा लगता है, यह सब क्यों होगा। यह कई बच्चों में देखा जाता है। उनके माता-पिता सभी को घोषणा करते हैं कि उनके बच्चे प्रतिभाशाली हैं, दादी उत्साही हैं और बच्चों को उनके "ज्ञान" के लिए प्रशंसा करते हैं। और फिर साधारण साधारण होशियार बच्चे उनसे बड़े हो जाते हैं, मां के बेटे के दोस्त से ज्यादा चमकीले नहीं।
तंत्रिका नेटवर्क का अध्ययन करते हुए, मैं एक समान घटना के साथ आया, और यह मुझे लगता है कि इस सादृश्य से कुछ निष्कर्ष निकाले जा सकते हैं। मैं जीवविज्ञानी या न्यूरोसाइंटिस्ट नहीं हूं। आगे सभी - मेरा अनुमान विशेष रूप से वैज्ञानिक होने का दावा किए बिना। मुझे पेशेवरों पर टिप्पणी करने में खुशी होगी।
जब मैंने यह समझने की कोशिश की कि मेरे बेटे ने मुझसे अधिक तेजी से गिनती करने के लिए कितनी दृढ़ता से सीखा था (उन्होंने 20.4 सेकंड में मैथ वर्कआउट में स्तर पार कर लिया, जबकि मेरा रिकॉर्ड 21.9 था), मुझे एहसास हुआ कि वह बिल्कुल भी नहीं गिना था। उन्होंने याद दिलाया कि जब 55 + 17 दिखाई देते हैं, तो आपको 72 दबाने की आवश्यकता होती है। 45 + 38 में आपको 83 पर क्लिक करने की आवश्यकता होती है, और इसी तरह। सबसे पहले, उन्होंने निश्चित रूप से गिना, लेकिन गति में तेजी उस समय आई जब वे सभी संयोजनों को याद रखने में सक्षम थे। और जल्दी से पर्याप्त, वह ठोस शिलालेख नहीं, बल्कि प्रतीकों के संयोजन को याद करने लगा। यह वही है जो स्कूल में पढ़ाया जाता है, गुणन तालिका का अध्ययन करना - पत्राचार तालिका को याद रखें MxN -> पी।
यह पता चला कि इनपुट और आउटपुट के बीच एक संबंध के रूप में वह अधिकांश जानकारी को ठीक-ठीक समझता है, और यह कि हम जवाब पाने के लिए स्क्रॉल करने के लिए जिस सामान्य सामान्य एल्गोरिथ्म का उपयोग करते हैं, वह दो अंकों की संख्याओं की गणना के लिए एक बहुत ही अच्छी तरह से तीक्ष्ण अत्यधिक विशिष्ट एल्गोरिदम को कम नहीं करता है। उन्होंने थोड़ा उत्कृष्ट कार्य किया, लेकिन बहुत धीमा। यानी जो सबको सुपर कूल लग रहा था वह वास्तव में एक विशिष्ट कार्य के लिए एक अच्छी तरह से प्रशिक्षित तंत्रिका नेटवर्क द्वारा अनुकरण किया गया था।
अतिरिक्त ज्ञान
कुछ बच्चों को यह याद रखने की क्षमता क्यों होती है, जबकि कुछ को नहीं?
बच्चे के हितों के क्षेत्र की कल्पना करें (यहां हम किसी भी माप के बिना गुणात्मक रूप से मुद्दे पर पहुंचते हैं)। बाईं ओर एक साधारण बच्चे के हितों का क्षेत्र है, और दाईं ओर एक "उपहार" बच्चे के हितों का क्षेत्र है। जैसा कि अपेक्षित था, मुख्य रुचि उन क्षेत्रों में केंद्रित है जिनमें विशेष झुकाव हैं। लेकिन रोजमर्रा की चीजों और साथियों के साथ संवाद पर, ध्यान अब पर्याप्त नहीं है। वह इस ज्ञान को सतही मानते हैं।
 |  |
| एक साधारण बच्चे के 5 साल के बच्चे | 5 साल के "शानदार" बच्चे के हित |
ऐसे बच्चों में, मस्तिष्क केवल चयनित विषयों पर प्रशिक्षण का विश्लेषण और संचालन करता है। प्रशिक्षण के माध्यम से, मस्तिष्क में एक तंत्रिका नेटवर्क को आने वाले डेटा को सफलतापूर्वक वर्गीकृत करना सीखना चाहिए। लेकिन मस्तिष्क के कई, कई न्यूरॉन्स होते हैं। ऐसे सरल कार्यों के साथ सामान्य काम के लिए आवश्यक से अधिक मजबूत। आमतौर पर, जीवन में, बच्चे कई अलग-अलग समस्याओं को हल करते हैं, लेकिन यहां सभी समान संसाधनों को कार्यों की एक संकीर्ण सीमा तक फेंक दिया जाता है। और इस मोड में प्रशिक्षण आसानी से एमएल पेशेवरों को ओवरफिटिंग कहते हैं। नेटवर्क, गुणांक (न्यूरॉन्स) की एक बहुतायत का उपयोग करते हुए, इस तरह से प्रशिक्षित किया गया था कि यह हमेशा सही उत्तर देता है (लेकिन यह मध्यवर्ती इनपुट डेटा पर पूर्ण बकवास दे सकता है, लेकिन कोई भी इसे नहीं देखता है)। इस प्रकार, प्रशिक्षण ने इस तथ्य को जन्म नहीं दिया कि मस्तिष्क ने मुख्य विशेषताओं को एकल किया और उन्हें याद किया, लेकिन इस तथ्य से कि उसने पहले से ज्ञात डेटा (जैसा कि दाईं ओर की तस्वीर में है) पर सटीक परिणाम उत्पन्न करने के लिए बहुत सारे गुणांक समायोजित किए। इसके अलावा, अन्य विषयों पर, मस्तिष्क ने ऐसा सीखा, इसलिए खराब प्रशिक्षण प्राप्त किया (जैसा कि बाईं तरफ की तस्वीर में है)।
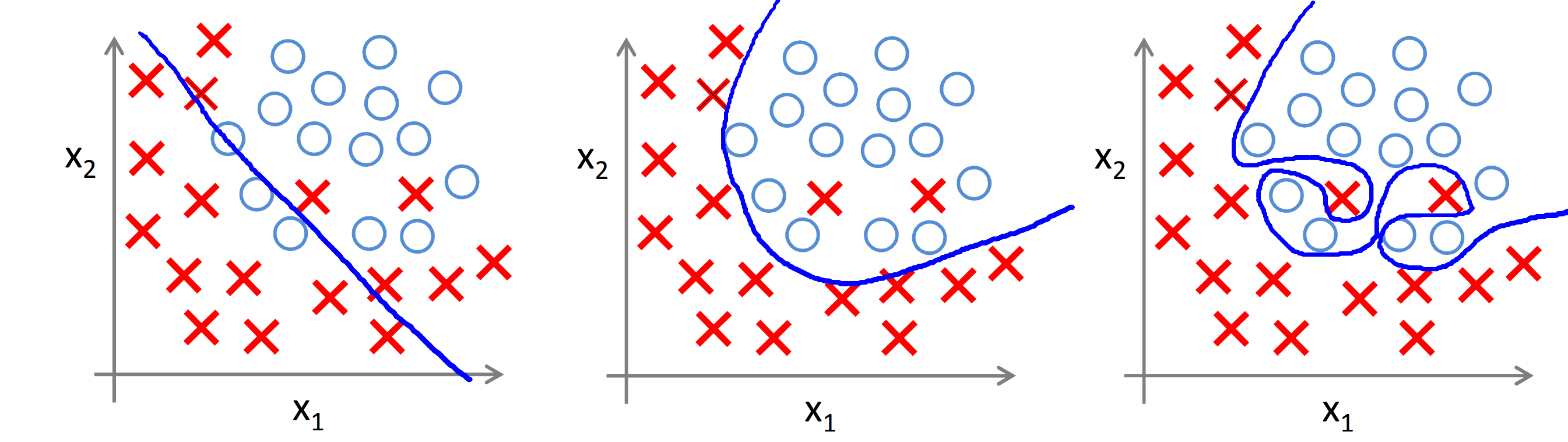
अंडरफ़िटिंग और ओवरफ़िटिंग क्या है?जो विषय में नहीं हैं, उनके लिए मैं आपको बहुत संक्षेप में बताऊंगा। एक तंत्रिका नेटवर्क को प्रशिक्षित करते समय, कार्य एक निश्चित संख्या में मापदंडों (न्यूरॉन्स के बीच संचार भार) का चयन करना है ताकि नेटवर्क, प्रशिक्षण डेटा (प्रशिक्षण नमूना) का जवाब दे, यथासंभव बारीकी से और सटीक रूप से उत्तर दे।
यदि बहुत कम ऐसे पैरामीटर हैं, तो नेटवर्क नमूने के विवरण को ध्यान में नहीं रख पाएगा, जिससे बहुत ही मोटा और औसत जवाब मिलेगा जो प्रशिक्षण नमूने में भी अच्छी तरह से काम नहीं करता है। जैसे ऊपर की बाईं तस्वीर में। यह अंडरफुटिंग है।
पर्याप्त संख्या में मापदंडों के साथ, नेटवर्क एक अच्छा परिणाम देगा, प्रशिक्षण डेटा में मजबूत विचलन "निगल"। ऐसा नेटवर्क न केवल प्रशिक्षण सेट, बल्कि अन्य मध्यवर्ती मूल्यों के लिए भी अच्छी तरह से प्रतिक्रिया देगा। जैसे ऊपर चित्र में है।
लेकिन अगर नेटवर्क को बहुत अधिक कॉन्फ़िगर करने योग्य पैरामीटर दिए जाते हैं, तो उसे मजबूत विचलन और उतार-चढ़ाव (त्रुटियों के कारण होने वाले सहित) को पुन: पेश करने के लिए प्रशिक्षित किया जाता है, जो प्रशिक्षण सेट से इनपुट डेटा का जवाब पाने की कोशिश करते समय पूरी तरह से बकवास हो सकता है। जैसे ऊपर दी गई सही तस्वीर में। यह ओवरफिटिंग है।
एक सरल उदाहरण है।

कल्पना करें कि आपके पास कई डॉट्स (नीले घेरे) हैं। आपको एक चिकनी वक्र खींचने की आवश्यकता है जो आपको अन्य बिंदुओं की स्थिति का अनुमान लगाने की अनुमति देता है। यदि हम लेते हैं, उदाहरण के लिए, एक बहुपद, तो छोटी डिग्री (3 या 4 तक) के लिए, हमारी चिकनी वक्र काफी सटीक (नीली वक्र) होगी। इस स्थिति में, नीला वक्र प्रारंभिक बिंदुओं (नीला बिंदु) से नहीं गुजर सकता है।
हालांकि, यदि गुणांक (और इसलिए बहुपद की डिग्री) की संख्या बढ़ जाती है, तो नीले बिंदुओं के पारित होने की सटीकता बढ़ जाएगी (या यहां तक कि 100% हिट होगी), लेकिन इन बिंदुओं के बीच का व्यवहार अप्रत्याशित हो जाएगा (देखें कि लाल वक्र में उतार-चढ़ाव कैसे होता है)।
यह मुझे लगता है कि यह एक विशिष्ट विषय (निर्धारण) के लिए बच्चे का झुकाव है और शेष विषयों के लिए पूरी उपेक्षा है, जो इस तथ्य की ओर ले जाता है कि प्रशिक्षण के दौरान भी बहुत सारे विषयों के लिए "कारक" दिए जाते हैं।
यह देखते हुए कि नेटवर्क विशिष्ट इनपुट डेटा के लिए कॉन्फ़िगर किया गया है और "सुविधाओं" को आवंटित नहीं किया है, लेकिन इनपुट डेटा को बेवकूफ़ रूप से "याद" किया जाता है, इसे थोड़ा अलग इनपुट डेटा के साथ उपयोग नहीं किया जा सकता है। ऐसे नेटवर्क की प्रयोज्यता बहुत संकीर्ण है। उम्र के साथ, क्षितिज व्यापक हो जाता है, ध्यान केंद्रित हो जाता है, और एक ही कार्य के लिए कई न्यूरॉन्स को मोड़ने का कोई अवसर नहीं है - वे बच्चे के लिए अधिक आवश्यक नए कार्यों में उपयोग करना शुरू करते हैं। उस ओवरफिट नेटवर्क के ढहने की "सेटिंग", बच्चा "सामान्य" हो जाता है, प्रतिभा गायब हो जाती है।
बेशक, अगर किसी बच्चे के पास एक कौशल है जो अपने आप में उपयोगी है और इसे विकसित किया जा सकता है (उदाहरण के लिए, संगीत या खेल), तो उसके "प्रतिभाशाली" को लंबे समय तक बनाए रखा जा सकता है, और यहां तक कि इन कौशल को पेशेवर स्तर पर लाया जा सकता है। लेकिन ज्यादातर मामलों में यह काम नहीं करता है, और पिछले कौशल से और एक ट्रेस 8-10 साल की उम्र तक नहीं रहेगा।
निष्कर्ष
- क्या आपके पास एक शानदार बच्चा है? यह गुजर जाएगा;)
- क्षितिज और "प्रतिभा" संबंधित चीजें हैं, और वे सीखने के तंत्र के माध्यम से सटीक रूप से जुड़े हुए हैं
- यह दृश्यमान "जीनियस" - सबसे अधिक संभावना नहीं है, लेकिन किसी विशेष कार्य पर बहुत अधिक मस्तिष्क प्रशिक्षण के प्रभाव को समझने के बिना - यह सिर्फ इतना है कि सभी संसाधन इस कार्य के लिए समर्पित थे
- बच्चे के संकीर्ण हितों को सही करते समय, उसकी प्रतिभा गायब हो जाती है
- यदि आपका बच्चा "सरल" है और साथियों की तुलना में थोड़ा अधिक आरक्षित है, तो आपको इन समान कौशलों को सावधानीपूर्वक विकसित करने की आवश्यकता है, एक ही समय में अपने क्षितिज को सक्रिय रूप से विकसित करना है, और इन "शांत" पर ध्यान केंद्रित नहीं करना चाहिए, लेकिन आमतौर पर बेकार कौशल