हाय, हब्र, इस लेख में मैं इग्नाइट लाइब्रेरी के बारे में बात करूंगा, जिसके साथ आप PyTorch ढांचे का उपयोग करके आसानी से तंत्रिका नेटवर्क को प्रशिक्षित और परीक्षण कर सकते हैं।
इग्नाइट के साथ , आप नेटवर्क को केवल कुछ लाइनों में प्रशिक्षित करने के लिए साइकिल लिख सकते हैं, बॉक्स से मानक मैट्रिक्स गणना जोड़ सकते हैं, मॉडल को बचा सकते हैं, आदि। ठीक है, उन लोगों के लिए जो टीएफ से पियरटेक के लिए चले गए हैं, हम कह सकते हैं कि प्रज्वलित पुस्तकालय पायर के लिए केरस है।
यह लेख विस्तार से आगणन का उपयोग करके एक वर्गीकरण कार्य के लिए एक तंत्रिका नेटवर्क के प्रशिक्षण का एक उदाहरण विस्तार से जांच करेगा ।

PyTorch में अधिक आग जोड़ें
मैं इस बारे में बात करने में समय बर्बाद नहीं करूंगा कि पाइरॉच फ्रेमवर्क कितना अच्छा है। जो कोई पहले से ही इसका इस्तेमाल कर चुका है, वह समझता है कि मैं क्या लिख रहा हूं। लेकिन, अपने सभी फायदों के साथ, यह अभी भी प्रशिक्षण, परीक्षण, तंत्रिका नेटवर्क के परीक्षण के लिए चक्र लिखने के मामले में निम्न स्तर का है।
अगर हम PyTorch ढांचे का उपयोग करने के आधिकारिक उदाहरणों को देखते हैं, तो हम एपोच द्वारा और ग्रिड प्रशिक्षण कोड में निर्धारित प्रशिक्षण के बैचों द्वारा कम से कम दो चक्रों को देखेंगे:
for epoch in range(1, epochs + 1): for batch_idx, (data, target) in enumerate(train_loader):
आग्नेय पुस्तकालय का मुख्य विचार इन लूपों को एक ही वर्ग में बदलना है, जबकि उपयोगकर्ता इन हैंडलर का उपयोग करके इन लूपों के साथ बातचीत करने की अनुमति देता है।
नतीजतन, मानक गहन शिक्षण कार्यों के मामले में, हम कोड की लाइनों की संख्या पर बहुत बचत कर सकते हैं। कम लाइनें - कम त्रुटियां!
उदाहरण के लिए, तुलना के लिए, बाईं ओर प्रज्वलन का उपयोग करते हुए प्रशिक्षण और मॉडल सत्यापन के लिए कोड है, और दाईं ओर शुद्ध Pyoror है:
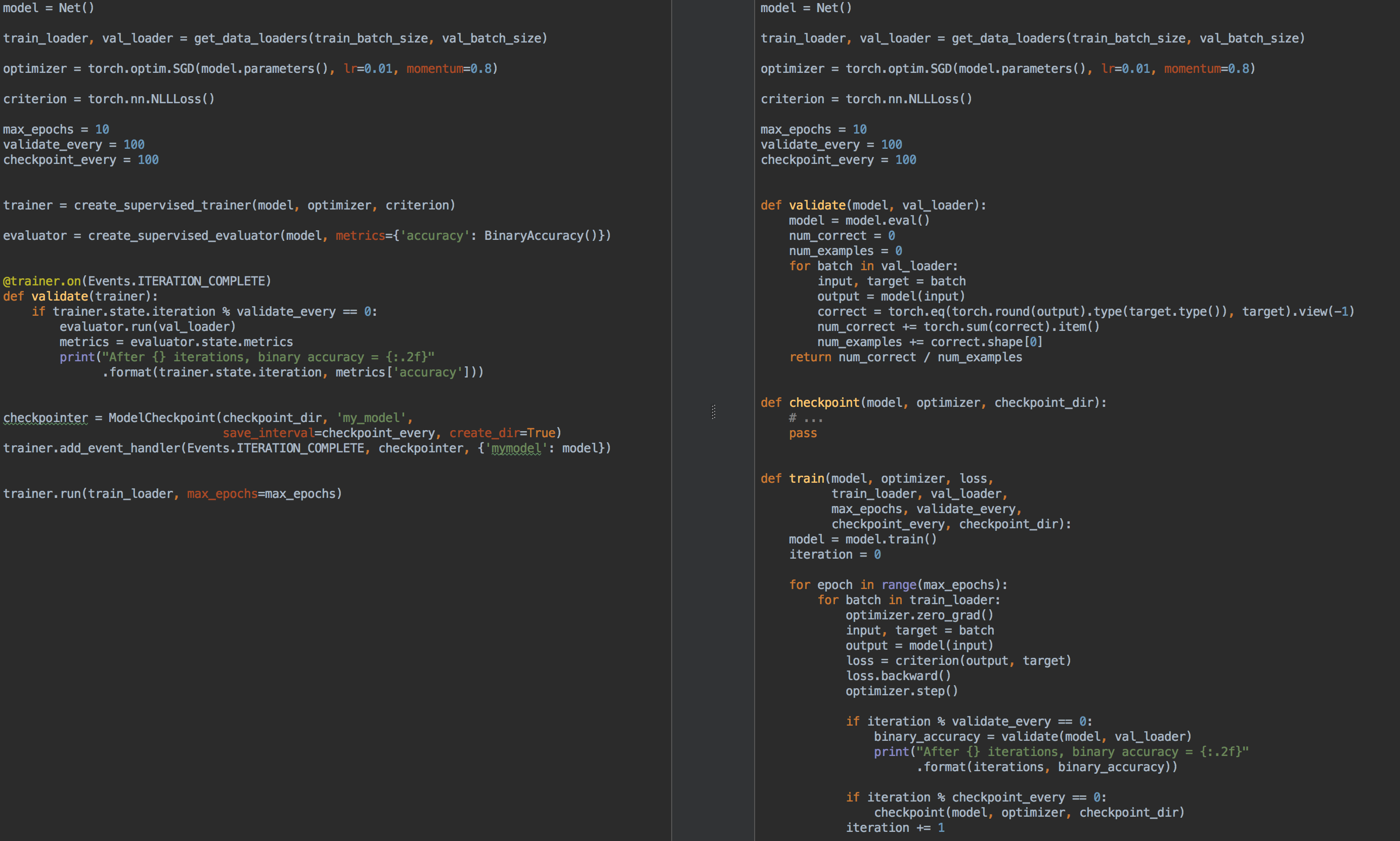
तो फिर, क्या प्रज्वलित के लिए अच्छा है ?
- अब आपको प्रत्येक कार्य छोरों के
for epoch in range(n_epochs) for batch in data_loader और for batch in data_loader लिए लिखने की आवश्यकता नहीं है। - आपको बेहतर फैक्टर कोड बनाने की अनुमति देता है
- आप बॉक्स से बाहर बुनियादी मैट्रिक्स की गणना करने की अनुमति देता है
- प्रकार के "बन्स" प्रदान करता है
- प्रशिक्षण के दौरान नवीनतम और सर्वश्रेष्ठ मॉडल (भी आशावादी और सीखने की दर अनुसूचक) को बचाते हुए,
- जल्दी सीखना बंद करो
- आदि
- आसानी से विज़ुअलाइज़ेशन टूल के साथ एकीकृत होता है: टेंसोरबोर्ड, विज़डम, ...
एक अर्थ में, जैसा कि पहले ही उल्लेख किया गया है, प्रज्वलित पुस्तकालय की तुलना प्रशिक्षण और परीक्षण नेटवर्क के लिए सभी प्रसिद्ध केर और इसके एपीआई के साथ की जा सकती है। इसके अलावा, पहली नज़र में प्रज्वलित पुस्तकालय, tnt पुस्तकालय के समान है, क्योंकि शुरू में दोनों पुस्तकालयों में सामान्य लक्ष्य थे और उनके कार्यान्वयन के लिए समान विचार थे।
तो, प्रकाश:
pip install pytorch-ignite
या
conda install ignite -c pytorch
अगला, एक विशिष्ट उदाहरण के साथ, हम खुद को इग्नाइट लाइब्रेरी एपीआई के साथ परिचित करेंगे।
आग्नेय के साथ वर्गीकरण कार्य
लेख के इस भाग में, हम प्रज्वलित पुस्तकालय का उपयोग करके वर्गीकरण समस्या के लिए एक तंत्रिका नेटवर्क के प्रशिक्षण के एक स्कूल उदाहरण पर विचार करेंगे।
तो, आइए एक सरल डेटासेट लें जिसमें केगल के साथ फलों के चित्र हैं । कार्य प्रत्येक फल चित्र के साथ संबंधित वर्ग को जोड़ना है।
इग्नाइट का उपयोग करने से पहले, आइए मुख्य घटकों को परिभाषित करें:
डेटा स्ट्रीम
- प्रशिक्षण नमूना बैचर लोडर,
train_loader - चेकआउट बैच डाउनलोडर,
val_loader
मॉडल:
- मशाल से छोटे निचोड़ने का ग्रिड ले
torchvision
अनुकूलन एल्गोरिथम:
नुकसान समारोह:
कोड from pathlib import Path import numpy as np import torch from torch.utils.data import Dataset, DataLoader from torch.utils.data.dataset import Subset from torchvision.datasets import ImageFolder from torchvision.transforms import Compose, RandomResizedCrop, RandomVerticalFlip, RandomHorizontalFlip from torchvision.transforms import ColorJitter, ToTensor, Normalize FRUIT360_PATH = Path(".").resolve().parent / "input" / "fruits-360_dataset" / "fruits-360" device = "cuda" train_transform = Compose([ RandomHorizontalFlip(), RandomResizedCrop(size=32), ColorJitter(brightness=0.12), ToTensor(), Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) ]) val_transform = Compose([ RandomResizedCrop(size=32), ToTensor(), Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) ]) batch_size = 128 num_workers = 8 train_dataset = ImageFolder((FRUIT360_PATH /"Training").as_posix(), transform=train_transform, target_transform=None) val_dataset = ImageFolder((FRUIT360_PATH /"Test").as_posix(), transform=val_transform, target_transform=None) train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers, drop_last=True, pin_memory="cuda" in device) val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers, drop_last=False, pin_memory="cuda" in device)
import torch.nn as nn from torchvision.models.squeezenet import squeezenet1_1 model = squeezenet1_1(pretrained=False, num_classes=81) model.classifier[-1] = nn.AdaptiveAvgPool2d(1) model = model.to(device)
import torch.nn as nn from torch.optim import SGD optimizer = SGD(model.parameters(), lr=0.01, momentum=0.5) criterion = nn.CrossEntropyLoss()
तो अब प्रज्वलित होने का समय है:
from ignite.engine import Engine, _prepare_batch def process_function(engine, batch): model.train() optimizer.zero_grad() x, y = _prepare_batch(batch, device=device) y_pred = model(x) loss = criterion(y_pred, y) loss.backward() optimizer.step() return loss.item() trainer = Engine(process_function)
आइए देखें कि इस कोड का क्या अर्थ है।
इंजन का Engine
ignite.engine.Engine लाइब्रेरी लाइब्रेरी फ्रेमवर्क है, और इस क्लास का उद्देश्य trainer :
trainer = Engine(process_function)
यह एक बैच के प्रसंस्करण के लिए इनपुट फंक्शन process_function साथ परिभाषित किया गया है और प्रशिक्षण नमूने के लिए पास लागू करने के लिए कार्य करता है। ignite.engine.Engine क्लास के अंदर, निम्न होता है:
while epoch < max_epochs:
वापस करने के लिए process_function फ़ंक्शन:
def process_function(engine, batch): model.train() optimizer.zero_grad() x, y = _prepare_batch(batch, device=device) y_pred = model(x) loss = criterion(y_pred, y) loss.backward() optimizer.step() return loss.item()
हम देखते हैं कि फ़ंक्शन के अंदर, हम हमेशा की तरह, मॉडल प्रशिक्षण के मामले में, y_pred भविष्यवाणियों की गणना करते हैं, हानि फ़ंक्शन, loss और ग्रेडिएंट्स की गणना करते हैं। उत्तरार्द्ध आपको मॉडल वजन अपडेट करने की अनुमति देता है: optimizer.step() ।
सामान्य तौर पर, process_function फ़ंक्शन के कोड पर कोई प्रतिबंध नहीं है। हम केवल यह नोट करते हैं कि इनपुट के रूप में दो तर्क हैं: Engine ऑब्जेक्ट (हमारे मामले में, trainer ) और डेटा लोडर से बैच। इसलिए, उदाहरण के लिए, एक तंत्रिका नेटवर्क का परीक्षण करने के लिए, हम ignite.engine.Engine वर्ग की एक अन्य वस्तु को परिभाषित कर सकते हैं, जिसमें इनपुट फ़ंक्शन केवल भविष्यवाणियों की गणना करता है, और एक बार परीक्षण नमूने के माध्यम से एक पास लागू करता है। इसके बारे में बाद में पढ़ें।
तो, उपरोक्त कोड केवल प्रशिक्षण शुरू किए बिना आवश्यक वस्तुओं को परिभाषित करता है। मूल रूप से, एक न्यूनतम उदाहरण में, आप विधि को कॉल कर सकते हैं:
trainer.run(train_loader, max_epochs=10)
और यह कोड "चुपचाप" (मध्यवर्ती परिणामों के किसी भी व्युत्पत्ति के बिना) मॉडल को प्रशिक्षित करने के लिए पर्याप्त है।
एक नोटयह भी ध्यान दें कि इस प्रकार के कार्यों के लिए लाइब्रेरी में trainer ऑब्जेक्ट बनाने के लिए एक सुविधाजनक तरीका है:
from ignite.engine import create_supervised_trainer trainer = create_supervised_trainer(model, optimizer, criterion, device)
बेशक, व्यवहार में, उपरोक्त उदाहरण थोड़ा ब्याज का है, इसलिए "कोच" के लिए निम्नलिखित विकल्प जोड़ें।
- प्रत्येक 50 पुनरावृत्तियों को नुकसान फ़ंक्शन का प्रदर्शन
- एक निर्धारित मॉडल के साथ प्रशिक्षण सेट पर मैट्रिक्स की गणना की शुरुआत
- प्रत्येक युग के बाद परीक्षण नमूने पर मैट्रिक्स की गणना की शुरुआत
- प्रत्येक युग के बाद मॉडल मापदंडों को सहेजना
- तीन सर्वश्रेष्ठ मॉडलों का संरक्षण
- युग के आधार पर सीखने की गति में बदलाव (सीखने की दर निर्धारण)
- प्रारंभिक रोक प्रशिक्षण (प्रारंभिक रोक)
इवेंट्स एंड इवेंट हैंडलर
"ट्रेनर" के लिए उपरोक्त विकल्पों को जोड़ने के लिए, इग्नाइट लाइब्रेरी एक इवेंट सिस्टम और कस्टम इवेंट हैंडलर के लॉन्च की सुविधा प्रदान करता है। इस प्रकार, उपयोगकर्ता प्रत्येक चरण में Engine वर्ग की एक वस्तु को नियंत्रित कर सकता है:
- इंजन शुरू / पूरा हुआ
- युग शुरू हुआ / समाप्त हुआ
- बैच पुनरावृत्ति शुरू / समाप्त हो गया
और हर घटना पर अपना कोड चलाएं।
हानि फ़ंक्शन मान प्रदर्शित करता है
ऐसा करने के लिए, बस उस फ़ंक्शन को निर्धारित करें जिसमें आउटपुट स्क्रीन पर प्रदर्शित होगा, और इसे "ट्रेनर" में जोड़ें:
from ignite.engine import Events log_interval = 50 @trainer.on(Events.ITERATION_COMPLETED) def log_training_loss(engine): iteration = (engine.state.iteration - 1) % len(train_loader) + 1 if iteration % log_interval == 0: print("Epoch[{}] Iteration[{}/{}] Loss: {:.4f}" .format(engine.state.epoch, iteration, len(train_loader), engine.state.output))
इवेंट हैंडलर जोड़ने के वास्तव में दो तरीके हैं: add_event_handler माध्यम से, या डेकोरेटर के माध्यम से। ऊपर जैसा इस प्रकार किया जा सकता है:
from ignite.engine import Events log_interval = 50 def log_training_loss(engine):
ध्यान दें कि किसी भी तर्क को इवेंट हैंडलिंग फ़ंक्शन में पास किया जा सकता है। सामान्य तौर पर, ऐसा फ़ंक्शन इस तरह दिखेगा:
def custom_handler(engine, *args, **kwargs): pass trainer.add_event_handler(Events.ITERATION_COMPLETED, custom_handler, *args, **kwargs)
तो, आइए एक युग पर प्रशिक्षण शुरू करें और देखें कि क्या होता है:
output = trainer.run(train_loader, max_epochs=1)
Epoch[1] Iteration[50/322] Loss: 4.3459 Epoch[1] Iteration[100/322] Loss: 4.2801 Epoch[1] Iteration[150/322] Loss: 4.2294 Epoch[1] Iteration[200/322] Loss: 4.1467 Epoch[1] Iteration[250/322] Loss: 3.8607 Epoch[1] Iteration[300/322] Loss: 3.6688
बुरा नहीं है! आगे चलते हैं।
प्रशिक्षण और परीक्षण नमूनों पर मैट्रिक्स की गणना शुरू करना
आइए निम्नलिखित मीट्रिक की गणना करें: प्रशिक्षण की ओर से प्रत्येक युग के बाद औसत सटीकता, औसत पूर्णता और संपूर्ण परीक्षण नमूना। ध्यान दें कि हम प्रशिक्षण के प्रत्येक युग के बाद प्रशिक्षण नमूने के हिस्से पर मैट्रिक्स की गणना करेंगे, और प्रशिक्षण के दौरान नहीं। इस प्रकार, दक्षता का माप अधिक सटीक होगा, क्योंकि गणना के दौरान मॉडल नहीं बदलता है।
इसलिए, हम मैट्रिक्स को परिभाषित करते हैं:
from ignite.metrics import Loss, CategoricalAccuracy, Precision, Recall metrics = { 'avg_loss': Loss(criterion), 'avg_accuracy': CategoricalAccuracy(), 'avg_precision': Precision(average=True), 'avg_recall': Recall(average=True) }
अगला, हम ignite.engine.create_supervised_evaluator का उपयोग करके मॉडल का मूल्यांकन करने के लिए दो इंजन ignite.engine.create_supervised_evaluator :
from ignite.engine import create_supervised_evaluator
हम मॉडल को बचाने और जल्दी सीखने (इन सभी के बारे में नीचे) को रोकने के लिए उनमें से एक में अतिरिक्त इवेंट हैंडलर संलग्न करने के लिए दो इंजन बना रहे हैं।
आइए इस बात का भी ध्यान रखें कि मॉडल के मूल्यांकन के लिए इंजन को कैसे परिभाषित किया गया है, अर्थात् इनपुट फ़ंक्शन प्रक्रिया_फंक्शन को एक बैच को कैसे संसाधित किया जाता है:
def create_supervised_evaluator(model, metrics={}, device=None): if device: model.to(device) def _inference(engine, batch): model.eval() with torch.no_grad(): x, y = _prepare_batch(batch, device=device) y_pred = model(x) return y_pred, y engine = Engine(_inference) for name, metric in metrics.items(): metric.attach(engine, name) return engine
हम आगे भी जारी रहे। आइए हम यादृच्छिक रूप से प्रशिक्षण नमूने के उस भाग का चयन करें, जिस पर हम मैट्रिक्स की गणना करेंगे:
import numpy as np from torch.utils.data.dataset import Subset indices = np.arange(len(train_dataset)) random_indices = np.random.permutation(indices)[:len(val_dataset)] train_subset = Subset(train_dataset, indices=random_indices) train_eval_loader = DataLoader(train_subset, batch_size=batch_size, shuffle=True, num_workers=num_workers, drop_last=True, pin_memory="cuda" in device)
अगला, आइए निर्धारित करें कि प्रशिक्षण में हम किस बिंदु पर मैट्रिक्स की गणना शुरू करेंगे और स्क्रीन पर आउटपुट करेंगे:
@trainer.on(Events.EPOCH_COMPLETED) def compute_and_display_offline_train_metrics(engine): epoch = engine.state.epoch print("Compute train metrics...") metrics = train_evaluator.run(train_eval_loader).metrics print("Training Results - Epoch: {} Average Loss: {:.4f} | Accuracy: {:.4f} | Precision: {:.4f} | Recall: {:.4f}" .format(engine.state.epoch, metrics['avg_loss'], metrics['avg_accuracy'], metrics['avg_precision'], metrics['avg_recall'])) @trainer.on(Events.EPOCH_COMPLETED) def compute_and_display_val_metrics(engine): epoch = engine.state.epoch print("Compute validation metrics...") metrics = val_evaluator.run(val_loader).metrics print("Validation Results - Epoch: {} Average Loss: {:.4f} | Accuracy: {:.4f} | Precision: {:.4f} | Recall: {:.4f}" .format(engine.state.epoch, metrics['avg_loss'], metrics['avg_accuracy'], metrics['avg_precision'], metrics['avg_recall']))
तुम दौड़ सकते हो!
output = trainer.run(train_loader, max_epochs=1)
हम स्क्रीन पर आते हैं
Epoch[1] Iteration[50/322] Loss: 3.5112 Epoch[1] Iteration[100/322] Loss: 2.9840 Epoch[1] Iteration[150/322] Loss: 2.8807 Epoch[1] Iteration[200/322] Loss: 2.9285 Epoch[1] Iteration[250/322] Loss: 2.5026 Epoch[1] Iteration[300/322] Loss: 2.1944 Compute train metrics... Training Results - Epoch: 1 Average Loss: 2.1018 | Accuracy: 0.3699 | Precision: 0.3981 | Recall: 0.3686 Compute validation metrics... Validation Results - Epoch: 1 Average Loss: 2.0519 | Accuracy: 0.3850 | Precision: 0.3578 | Recall: 0.3845
पहले से बेहतर!
कुछ विवरण
आइए पिछले कोड को थोड़ा देखें। पाठक ने कोड की निम्नलिखित पंक्ति देखी होगी:
metrics = train_evaluator.run(train_eval_loader).metrics
और संभवत: train_evaluator.run(train_eval_loader) से प्राप्त ऑब्जेक्ट के प्रकार के बारे में एक सवाल था, जिसमें metrics विशेषता है।
वास्तव में, Engine वर्ग में एक संरचना होती है जिसे state (टाइप State ) कहा जाता है ताकि ईवेंट हैंडलर के बीच डेटा स्थानांतरित किया जा सके। इस state विशेषता में वर्तमान युग, पुनरावृत्ति, युगों की संख्या आदि के बारे में बुनियादी जानकारी है। इसका उपयोग मेट्रिक्स की गणना के परिणामों सहित किसी भी उपयोगकर्ता डेटा को स्थानांतरित करने के लिए भी किया जा सकता है।
state = train_evaluator.run(train_eval_loader) metrics = state.metrics
प्रशिक्षण के दौरान मैट्रिक्स की गणना
यदि कार्य में एक बड़ा प्रशिक्षण सेट है और प्रत्येक प्रशिक्षण युग के बाद मैट्रिक्स की गणना करना महंगा है, लेकिन फिर भी प्रशिक्षण के दौरान कुछ मेट्रिक्स परिवर्तन देखना चाहते हैं, तो आप बॉक्स से निम्नलिखित RunningAverage इवेंट हैंडलर का उपयोग कर सकते हैं। उदाहरण के लिए, हम वर्गीकरण की सटीकता की गणना और प्रदर्शन करना चाहते हैं:
acc_metric = RunningAverage(CategoryAccuracy(...), alpha=0.98) acc_metric.attach(trainer, 'running_avg_accuracy') @trainer.on(Events.ITERATION_COMPLETED) def log_running_avg_metrics(engine): print("running avg accuracy:", engine.state.metrics['running_avg_accuracy'])
RunningAverage कार्यक्षमता का उपयोग करने के लिए, आपको स्रोतों से आग लगाने की आवश्यकता है:
pip install git+https:
सीखने की दर निर्धारण
प्रज्वलित का उपयोग करके सीखने की गति को बदलने के कई तरीके हैं। इसके बाद, प्रत्येक युग की शुरुआत में lr_scheduler.step() फ़ंक्शन को कॉल करके सबसे सरल विधि पर विचार करें।
from torch.optim.lr_scheduler import ExponentialLR lr_scheduler = ExponentialLR(optimizer, gamma=0.8) @trainer.on(Events.EPOCH_STARTED) def update_lr_scheduler(engine): lr_scheduler.step()
प्रशिक्षण के दौरान सर्वश्रेष्ठ मॉडल और अन्य मापदंडों को सहेजना
प्रशिक्षण के दौरान, डिस्क पर सर्वश्रेष्ठ मॉडल के वजन को रिकॉर्ड करना बहुत अच्छा होगा, साथ ही समय-समय पर मॉडल की ऊंचाई, ऑप्टिमाइज़र पैरामीटर और सीखने की गति को बदलने के लिए मापदंडों को बचाने के लिए। अंतिम बचाए गए राज्य से सीखने को फिर से शुरू करने के लिए उत्तरार्द्ध उपयोगी हो सकता है।
इग्नाइट में इसके लिए एक विशेष ModelCheckpoint क्लास है। तो, चलिए एक ModelCheckpoint इवेंट ModelCheckpoint बनाते हैं और टेस्ट सेट में सटीकता के मामले में सबसे अच्छे मॉडल को बचाते हैं। इस मामले में, हम एक score_function फ़ंक्शन को परिभाषित करते हैं जो इवेंट हैंडलर को सटीकता मूल्य देता है और यह तय करता है कि मॉडल को सहेजना है या नहीं:
from ignite.handlers import ModelCheckpoint def score_function(engine): val_avg_accuracy = engine.state.metrics['avg_accuracy'] return val_avg_accuracy best_model_saver = ModelCheckpoint("best_models", filename_prefix="model", score_name="val_accuracy", score_function=score_function, n_saved=3, save_as_state_dict=True, create_dir=True)
अब प्रत्येक 1000 पुनरावृत्तियों को सीखने की स्थिति बनाए रखने के लिए एक और ModelCheckpoint ईवेंट ModelCheckpoint बनाएं:
training_saver = ModelCheckpoint("checkpoint", filename_prefix="checkpoint", save_interval=1000, n_saved=1, save_as_state_dict=True, create_dir=True) to_save = {"model": model, "optimizer": optimizer, "lr_scheduler": lr_scheduler} trainer.add_event_handler(Events.ITERATION_COMPLETED, training_saver, to_save)
तो, लगभग सब कुछ तैयार है, अंतिम तत्व जोड़ें:
प्रारंभिक रोक प्रशिक्षण (प्रारंभिक रोक)
आइए एक और ईवेंट हैंडलर जोड़ें जो 10 युगों में मॉडल की गुणवत्ता में सुधार नहीं होने पर सीखना बंद कर देगा। हम फिर से स्कोर_फंक्शन score_function का उपयोग करके मॉडल की गुणवत्ता का मूल्यांकन करेंगे।
from ignite.handlers import EarlyStopping early_stopping = EarlyStopping(patience=10, score_function=score_function, trainer=trainer) val_evaluator.add_event_handler(Events.EPOCH_COMPLETED, early_stopping)
प्रशिक्षण शुरू करें
प्रशिक्षण शुरू करने के लिए, हमारे लिए run() विधि को कॉल करना पर्याप्त है। हम 10 युगों के लिए मॉडल को प्रशिक्षित करेंगे:
max_epochs = 10 output = trainer.run(train_loader, max_epochs=max_epochs)
स्क्रीन आउटपुट Learning rate: 0.01 Epoch[1] Iteration[50/322] Loss: 2.7984 Epoch[1] Iteration[100/322] Loss: 1.9736 Epoch[1] Iteration[150/322] Loss: 4.3419 Epoch[1] Iteration[200/322] Loss: 2.0261 Epoch[1] Iteration[250/322] Loss: 2.1724 Epoch[1] Iteration[300/322] Loss: 2.1599 Compute train metrics... Training Results - Epoch: 1 Average Loss: 1.5363 | Accuracy: 0.5177 | Precision: 0.5477 | Recall: 0.5178 Compute validation metrics... Validation Results - Epoch: 1 Average Loss: 1.5116 | Accuracy: 0.5139 | Precision: 0.5400 | Recall: 0.5140 Learning rate: 0.008 Epoch[2] Iteration[50/322] Loss: 1.4076 Epoch[2] Iteration[100/322] Loss: 1.4892 Epoch[2] Iteration[150/322] Loss: 1.2485 Epoch[2] Iteration[200/322] Loss: 1.6511 Epoch[2] Iteration[250/322] Loss: 3.3376 Epoch[2] Iteration[300/322] Loss: 1.3299 Compute train metrics... Training Results - Epoch: 2 Average Loss: 3.2686 | Accuracy: 0.1977 | Precision: 0.1792 | Recall: 0.1942 Compute validation metrics... Validation Results - Epoch: 2 Average Loss: 3.2772 | Accuracy: 0.1962 | Precision: 0.1628 | Recall: 0.1918 Learning rate: 0.006400000000000001 Epoch[3] Iteration[50/322] Loss: 0.9016 Epoch[3] Iteration[100/322] Loss: 1.2006 Epoch[3] Iteration[150/322] Loss: 0.8892 Epoch[3] Iteration[200/322] Loss: 0.8141 Epoch[3] Iteration[250/322] Loss: 1.4005 Epoch[3] Iteration[300/322] Loss: 0.8888 Compute train metrics... Training Results - Epoch: 3 Average Loss: 0.7368 | Accuracy: 0.7554 | Precision: 0.7818 | Recall: 0.7554 Compute validation metrics... Validation Results - Epoch: 3 Average Loss: 0.7177 | Accuracy: 0.7623 | Precision: 0.7863 | Recall: 0.7611 Learning rate: 0.005120000000000001 Epoch[4] Iteration[50/322] Loss: 0.8490 Epoch[4] Iteration[100/322] Loss: 0.8493 Epoch[4] Iteration[150/322] Loss: 0.8100 Epoch[4] Iteration[200/322] Loss: 0.9165 Epoch[4] Iteration[250/322] Loss: 0.9370 Epoch[4] Iteration[300/322] Loss: 0.6548 Compute train metrics... Training Results - Epoch: 4 Average Loss: 0.7047 | Accuracy: 0.7713 | Precision: 0.8040 | Recall: 0.7728 Compute validation metrics... Validation Results - Epoch: 4 Average Loss: 0.6737 | Accuracy: 0.7778 | Precision: 0.7955 | Recall: 0.7806 Learning rate: 0.004096000000000001 Epoch[5] Iteration[50/322] Loss: 0.6965 Epoch[5] Iteration[100/322] Loss: 0.6196 Epoch[5] Iteration[150/322] Loss: 0.6194 Epoch[5] Iteration[200/322] Loss: 0.3986 Epoch[5] Iteration[250/322] Loss: 0.6032 Epoch[5] Iteration[300/322] Loss: 0.7152 Compute train metrics... Training Results - Epoch: 5 Average Loss: 0.5049 | Accuracy: 0.8282 | Precision: 0.8393 | Recall: 0.8314 Compute validation metrics... Validation Results - Epoch: 5 Average Loss: 0.5084 | Accuracy: 0.8304 | Precision: 0.8386 | Recall: 0.8328 Learning rate: 0.0032768000000000007 Epoch[6] Iteration[50/322] Loss: 0.4433 Epoch[6] Iteration[100/322] Loss: 0.4764 Epoch[6] Iteration[150/322] Loss: 0.5578 Epoch[6] Iteration[200/322] Loss: 0.3684 Epoch[6] Iteration[250/322] Loss: 0.4847 Epoch[6] Iteration[300/322] Loss: 0.3811 Compute train metrics... Training Results - Epoch: 6 Average Loss: 0.4383 | Accuracy: 0.8474 | Precision: 0.8618 | Recall: 0.8495 Compute validation metrics... Validation Results - Epoch: 6 Average Loss: 0.4419 | Accuracy: 0.8446 | Precision: 0.8532 | Recall: 0.8442 Learning rate: 0.002621440000000001 Epoch[7] Iteration[50/322] Loss: 0.4447 Epoch[7] Iteration[100/322] Loss: 0.4602 Epoch[7] Iteration[150/322] Loss: 0.5345 Epoch[7] Iteration[200/322] Loss: 0.3973 Epoch[7] Iteration[250/322] Loss: 0.5023 Epoch[7] Iteration[300/322] Loss: 0.5303 Compute train metrics... Training Results - Epoch: 7 Average Loss: 0.4305 | Accuracy: 0.8579 | Precision: 0.8691 | Recall: 0.8596 Compute validation metrics... Validation Results - Epoch: 7 Average Loss: 0.4262 | Accuracy: 0.8590 | Precision: 0.8685 | Recall: 0.8606 Learning rate: 0.002097152000000001 Epoch[8] Iteration[50/322] Loss: 0.4867 Epoch[8] Iteration[100/322] Loss: 0.3090 Epoch[8] Iteration[150/322] Loss: 0.3721 Epoch[8] Iteration[200/322] Loss: 0.4559 Epoch[8] Iteration[250/322] Loss: 0.3958 Epoch[8] Iteration[300/322] Loss: 0.4222 Compute train metrics... Training Results - Epoch: 8 Average Loss: 0.3432 | Accuracy: 0.8818 | Precision: 0.8895 | Recall: 0.8817 Compute validation metrics... Validation Results - Epoch: 8 Average Loss: 0.3644 | Accuracy: 0.8713 | Precision: 0.8784 | Recall: 0.8707 Learning rate: 0.001677721600000001 Epoch[9] Iteration[50/322] Loss: 0.3557 Epoch[9] Iteration[100/322] Loss: 0.3692 Epoch[9] Iteration[150/322] Loss: 0.3510 Epoch[9] Iteration[200/322] Loss: 0.3446 Epoch[9] Iteration[250/322] Loss: 0.3966 Epoch[9] Iteration[300/322] Loss: 0.3451 Compute train metrics... Training Results - Epoch: 9 Average Loss: 0.3315 | Accuracy: 0.8954 | Precision: 0.9001 | Recall: 0.8982 Compute validation metrics... Validation Results - Epoch: 9 Average Loss: 0.3559 | Accuracy: 0.8818 | Precision: 0.8876 | Recall: 0.8847 Learning rate: 0.0013421772800000006 Epoch[10] Iteration[50/322] Loss: 0.3340 Epoch[10] Iteration[100/322] Loss: 0.3370 Epoch[10] Iteration[150/322] Loss: 0.3694 Epoch[10] Iteration[200/322] Loss: 0.3409 Epoch[10] Iteration[250/322] Loss: 0.4420 Epoch[10] Iteration[300/322] Loss: 0.2770 Compute train metrics... Training Results - Epoch: 10 Average Loss: 0.3246 | Accuracy: 0.8921 | Precision: 0.8988 | Recall: 0.8925 Compute validation metrics... Validation Results - Epoch: 10 Average Loss: 0.3536 | Accuracy: 0.8731 | Precision: 0.8785 | Recall: 0.8722
अब डिस्क पर सहेजे गए मॉडल और मापदंडों की जाँच करें:
ls best_models/ model_best_model_10_val_accuracy=0.8730994.pth model_best_model_8_val_accuracy=0.8712978.pth model_best_model_9_val_accuracy=0.8818188.pth
और
ls checkpoint/ checkpoint_lr_scheduler_3000.pth checkpoint_optimizer_3000.pth checkpoint_model_3000.pth
एक प्रशिक्षित मॉडल द्वारा भविष्यवाणियों
सबसे पहले, एक परीक्षण डेटा लोडर बनाएं (उदाहरण के लिए, एक सत्यापन नमूना लें) ताकि डेटा बैच में चित्र और उनके सूचकांक शामिल हों:
class TestDataset(Dataset): def __init__(self, ds): self.ds = ds def __len__(self): return len(self.ds) def __getitem__(self, index): return self.ds[index][0], index test_dataset = TestDataset(val_dataset) test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=num_workers, drop_last=False, pin_memory="cuda" in device)
इग्नाइट का उपयोग करते हुए , हम परीक्षण डेटा के लिए एक नया पूर्वानुमान इंजन बनाएंगे। ऐसा करने के लिए, हम फ़ंक्शन inference_update को परिभाषित करते inference_update , जो छवि की भविष्यवाणी और सूचकांक का परिणाम देता है। सटीकता बढ़ाने के लिए, हम जाने-माने ट्रिक "टेस्ट टाइम एनगठन" (TTA) का भी उपयोग करेंगे।
import torch.nn.functional as F from ignite._utils import convert_tensor def _prepare_batch(batch): x, index = batch x = convert_tensor(x, device=device) return x, index def inference_update(engine, batch): x, indices = _prepare_batch(batch) y_pred = model(x) y_pred = F.softmax(y_pred, dim=1) return {"y_pred": convert_tensor(y_pred, device='cpu'), "indices": indices} model.eval() inferencer = Engine(inference_update)
अगला, ईवेंट हैंडलर बनाएं जो भविष्यवाणियों के चरण के बारे में सूचित करेंगे और भविष्यवाणियों को एक समर्पित सरणी में सहेजेंगे:
@inferencer.on(Events.EPOCH_COMPLETED) def log_tta(engine): print("TTA {} / {}".format(engine.state.epoch, n_tta)) n_tta = 3 num_classes = 81 n_samples = len(val_dataset) # y_probas_tta = np.zeros((n_samples, num_classes, n_tta), dtype=np.float32) @inferencer.on(Events.ITERATION_COMPLETED) def save_results(engine): output = engine.state.output tta_index = engine.state.epoch - 1 start_index = ((engine.state.iteration - 1) % len(test_loader)) * batch_size end_index = min(start_index + batch_size, n_samples) batch_y_probas = output['y_pred'].detach().numpy() y_probas_tta[start_index:end_index, :, tta_index] = batch_y_probas
प्रक्रिया शुरू करने से पहले, आइए सबसे अच्छा मॉडल डाउनलोड करें:
model = squeezenet1_1(pretrained=False, num_classes=64) model.classifier[-1] = nn.AdaptiveAvgPool2d(1) model = model.to(device) model_state_dict = torch.load("best_models/model_best_model_10_val_accuracy=0.8730994.pth") model.load_state_dict(model_state_dict)
हम लॉन्च करते हैं:
inferencer.run(test_loader, max_epochs=n_tta) > TTA 1 / 3 > TTA 2 / 3 > TTA 3 / 3
अगला, मानक तरीके से, हम TTA भविष्यवाणियों का औसत लेते हैं और उच्चतम संभावना वाले वर्ग सूचकांक की गणना करते हैं:
y_probas = np.mean(y_probas_tta, axis=-1) y_preds = np.argmax(y_probas, axis=-1)
और अब हम भविष्यवाणियों के अनुसार एक बार फिर से मॉडल की सटीकता की गणना कर सकते हैं:
from sklearn.metrics import accuracy_score y_test_true = [y for _, y in val_dataset] accuracy_score(y_test_true, y_preds) > 0.9310369676443035
, , . , , , ignite .
.
github
- fast neural transfer
- reinforcement learning
- dcgan
निष्कर्ष
, ignite Facebook (. ). 0.1.0, API (Engine, State, Events, Metric, ...) . , , , pull request- github .
आपका ध्यान के लिए धन्यवाद!