पिछले लेख में, मैंने इस बारे में बात की थी कि कैसे, राजस्व पूर्वानुमान के उद्देश्य से, लोगों ने एक बड़ी और जटिल एक्सेल फाइल बनाई ( आप यहाँ पढ़ सकते हैं )। हमने इस शर्म में हस्तक्षेप करने का फैसला किया और पूर्वानुमान मॉडल को फिर से बनाने का प्रस्ताव दिया ताकि कम त्रुटियों, आसान संचालन और ट्यूनिंग में एक लचीलापन हो।
वर्णित मॉडल में मुख्य समस्याएं क्या हैं:
- डेटा, मॉडल और विचारों को एक इकाई में मिलाया जाता है। इस वजह से, कम से कम एक तत्व में परिवर्तन इस पूरे मोनोलिथ को नष्ट कर देता है।
- मैनुअल प्रोसेसिंग के लिए अत्यधिक गणना, जो बड़ी मात्रा में त्रुटियों और टाइपोस को जन्म देती है।
हमने क्या सुझाव दिया:
- प्रारंभिक मॉडल में, प्रारंभिक डेटा जिस पर इसे बनाया गया था, वह कहीं दिखाई नहीं दिया। हमने इस डेटा को एक्सेल फ़ाइल में 2 सामान्य शीट के प्रारूप में 2 अलग-अलग शीट (बिक्री और ग्राहकों की संख्या) में दर्ज करने का प्रस्ताव दिया। सौभाग्य से, महीने के हिसाब से हमारे एकत्रीकरण में बिक्री का आंकड़ा लाखों नहीं बल्कि हजारों लाइनों का है। हमने डेटाबेस से सीधे पावर क्वेरी का उपयोग करके यह डेटा प्राप्त करने के लिए भी कॉन्फ़िगर किया है।
- हमने एक मॉडलिंग शीट बनाई, जिसमें 3 ब्लॉक शामिल हैं:
- राजस्व धुरी तालिका
- ग्राहकों की संख्या का सारांश तालिका
- औसत जांच की निपटान तालिका
प्रत्येक पिवट टेबल विभागों और इकाइयों द्वारा वर्तमान सिमुलेशन के लिए आवश्यक विवरण में अवधियों (महीनों) पर स्रोत डेटा पर निर्मित एक पिवट टेबल है।

- सिमुलेशन शीट में, हमने ऐतिहासिक समय श्रृंखला के आधार पर सरल पूर्वानुमान मॉडल बनाए। हमने ग्राहकों की संख्या और औसत बिल को बढ़ाया, और कुल पूर्वानुमान राजस्व को इन मूल्यों के उत्पाद के रूप में माना गया। डेटा की समीक्षा करने के बाद, हम 3 पूर्वानुमान मॉडल के साथ आए: पिछले समय के लिए औसतन, घातीय ट्रिपल स्मूदी और शून्यकरण (जब हमें 0 पूर्वानुमान की आवश्यकता होती है)।

- औसत रसीद (तथ्य) और राजस्व (पूर्वानुमान) की गणना कोशिकाओं को संदर्भित करके नहीं, बल्कि वीएलआर और ऑफ़सेट मार्किंग का उपयोग करके की जाती है, जो गणना को प्रारंभिक डेटा में बदलाव के लिए प्रतिरोधी बनाता है।
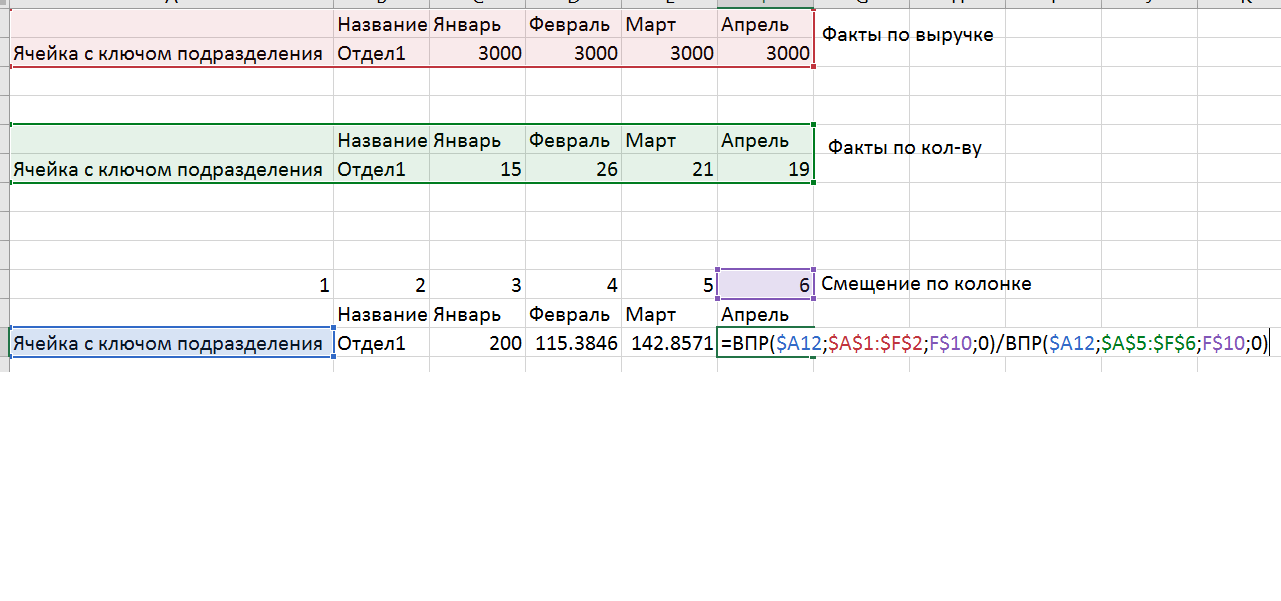
- यह स्पष्ट है कि अब मॉडल उपयोगकर्ता द्वारा पठनीय नहीं है, क्योंकि इसके कई अर्थ हैं। ऐसा करने के लिए, हमने इकाइयों की अलग-अलग शीट का निर्माण किया। प्रत्येक शीट में एक सेल होता है जो यह चुनता है कि इस शीट में कौन सा डेटा संक्षेप में होना चाहिए। VLOOKUP के आधार पर, हम मॉडल शीट से डेटा को शीट में खींचते हैं।
- इकाइयों द्वारा 30 शीट्स का निर्माण एक विशेष प्रक्रिया के अनुसार किया गया था। सबसे पहले, पहली शीट बनाई जाती है, इकाइयों में से एक, जिसमें विभागों के सभी संभावित नाम शामिल हैं। यदि इकाई में कोई विभाग नहीं है, तो सूत्र उन्हें वापस 0 पर खींचते हैं। सभी 30 इकाइयों को बनाने के लिए, हम डुप्लिकेट बनाते हैं और नियंत्रण कक्ष में नाम बदलते हैं (इसका उपयोग VLOOKUP कुंजी उत्पन्न करने के लिए किया जाता है) और हमारे पास प्रस्तुति के रूप में आवश्यक डेटा है। VLOOKUP एक कुंजी के रूप में 1 से अधिक सेल का उपयोग कर सकता है, यदि आप ट्रिक का उपयोग करते हैं: कॉन्टेक्ट का उपयोग करके उन कोशिकाओं को संयोजित करें जिनकी आपको आवश्यकता है (CLIP फ़ंक्शन या & सिंबल)।
- प्रस्तुति प्रपत्र में एक तत्व जोड़ा गया है जो आपको मॉडल को नियंत्रित करने की अनुमति देता है: औसत चेक और संख्या के अनुमानित मूल्यों के लिए एक सरल गुणक। यह तत्व एक विशेष तकनीकी शीट पर एकत्र किया गया है जो INDIRECT फ़ंक्शन का उपयोग करता है, जो आपको उत्पन्न लिंक का उपयोग करने की अनुमति देता है। इस तकनीकी शीट से, इन सभी सुधारों को VLOOKUP का उपयोग करके मॉडल शीट में स्थानांतरित किया जाता है।

- सामान्यीकरण पत्रक अब प्रस्तुति पत्रक का एक योग नहीं हैं, लेकिन अन्य सभी शीटों की तरह ही निर्मित होते हैं - एक मॉडल के साथ शीट पर डेटा को संक्षेप में। नतीजतन, प्रतिनिधित्व शुद्ध प्रतिनिधित्व हैं और आपस में कोई निर्भरता नहीं है।
हमें क्या मिला:
- यह हमेशा स्पष्ट होता है कि हमें कौन सा अंक डेटा मिला (क्योंकि पावर क्वेरी क्वेरी बच गई थी)।
- हम मॉडल को तोड़े बिना डेटा बदल सकते हैं।
- संरचना और पदानुक्रम में परिवर्तन के लिए मामूली संशोधनों की आवश्यकता होगी (आपको केवल प्रस्तुति की 1 शीट में नाम बदलने की आवश्यकता है और फिर इसे डुप्लिकेट करें)।
- हमने संभावित त्रुटियों की संख्या को काफी कम कर दिया है, क्योंकि अधिकांश डेटा फ़ार्मुलों, लिंक और कुंजियों का उपयोग करके भरा जाता है।
- ग्राहक को एक इंटरैक्टिव पूर्वानुमान प्राप्त हुआ, जिसमें वह स्वयं मूल्यों को बदल सकता है और तुरंत एक पूर्वानुमान प्राप्त कर सकता है।
- हम एक साथ उन आवश्यकताओं को संतुष्ट करने में सक्षम थे, जिनकी हमें वार्षिक और मासिक दोनों स्थितियों में डेटा की आवश्यकता है।
- अगले बजट अवधि में इस्तेमाल किया जा सकता है।
- यदि आप हमें अनुपयुक्त लगते हैं तो आप पूर्वानुमान के मॉडल को बदल सकते हैं।
हमने एक्सेल में रहने का फैसला क्यों किया, और इसे कुछ अन्य तकनीकों पर फिर से नहीं किया?
- हमें वर्तमान कर्मचारियों के संचालन में इस फ़ाइल को छोड़ने की आवश्यकता थी। एक्सेल के भीतर, हमारे लिए यह दिखाना आसान है कि यह सब कैसे काम करता है और वे क्या तय कर सकते हैं।
- एक्सेल कार्य और अन्य समाधानों के साथ मुकाबला करता है - शानदार संस्थाएं।
- ग्राहक इस फॉर्म का आदी है और कुछ श्रम लागतों को "पीछे हटाना" है जो हम बर्दाश्त नहीं कर सकते।
हमें कितना समय लगा: लगभग 5 कार्य दिवस, जहाँ 1 व्यक्ति ने दिन में 2-4 घंटे बिताए, और दिन के अंत में हमने परिणामों की समीक्षा की।