
मैं एक और शाम के दीर्घकालिक निर्माण को साझा करना चाहता हूं, जिससे पता चलता है कि आप कमजोर हार्डवेयर पर भी गेम बना सकते हैं।
आपको क्या करना है, यह कैसे तय किया गया था, और कैसे एक और पोंग क्लोन से ज्यादा कुछ करना है - कैट में आपका स्वागत है।
सावधानी: महान लेख, यातायात और कई कोड आवेषण!
संक्षेप में खेल के बारे में
मारो! - अब एवीआर पर।
वास्तव में, यह एक और शैंपू है, इसलिए एक बार फिर से मुख्य पात्र
शेपर्ड को अज्ञात लोगों द्वारा अचानक हमले से आकाशगंगा को बचाना होगा, जिससे सितारों और क्षुद्रग्रहों के क्षेत्रों के माध्यम से अंतरिक्ष के माध्यम से अपना रास्ता बनाया जा सके और साथ ही साथ प्रत्येक तारा प्रणाली को साफ किया जा सके।
Arduino से वायर लाइब्रेरी का उपयोग किए बिना पूरे खेल को C और C ++ में लिखा गया है।
खेल में चुनने के लिए 4 जहाज हैं (उत्तरार्द्ध गुजरने के बाद उपलब्ध है), प्रत्येक की अपनी विशेषताओं के साथ:
- चपलता;
- शक्ति;
- बंदूक की शक्ति।
इसे भी लागू किया गया:
- 2 डी रंग ग्राफिक्स;
- हथियारों के लिए शक्ति;
- स्तरों के अंत में मालिकों;
- क्षुद्रग्रहों (और उनके रोटेशन के एनीमेशन) के साथ स्तर;
- स्तरों पर पृष्ठभूमि का रंग परिवर्तन (और सिर्फ काली जगह नहीं);
- विभिन्न गति (गहराई के प्रभाव के लिए) में तारों की गति;
- EEPROM में स्कोरिंग और बचत;
- एक ही लगता है (शॉट्स, विस्फोट, आदि);
- समान विरोधियों का एक समुद्र।
मंच
भूत की वापसी।
मैं पहले ही स्पष्ट कर दूंगा कि इस प्लेटफॉर्म को पहली तीसरी पीढ़ी (80, शिरोमणि ) के पुराने गेम कंसोल के रूप में माना जाना चाहिए।
इसके अलावा, मूल हार्डवेयर पर हार्डवेयर संशोधन निषिद्ध हैं, जो बॉक्स के ठीक बाहर किसी अन्य समान बोर्ड पर लॉन्च सुनिश्चित करता है।
यह गेम Arduino Esplora बोर्ड के लिए लिखा गया था, लेकिन GBA या किसी अन्य प्लेटफ़ॉर्म पर स्थानांतरित करना, मुझे लगता है, मुश्किल नहीं होगा।
फिर भी, इस संसाधन पर भी इस बोर्ड को केवल एक-दो बार कवर किया गया था, और अन्य बोर्ड प्रत्येक के बड़े समुदाय के बावजूद, बिल्कुल भी उल्लेख के लायक नहीं थे:
- GameBuino META:
- Pokitto;
- makerBuino;
- Arduboy;
- UzeBox / FuzeBox;
- और कई अन्य।
शुरू करने के लिए, एस्प्लोरा पर क्या नहीं है:
- बहुत सारी मेमोरी (ROM 28kb, RAM 2.5kb);
- शक्ति (16 मेगाहर्ट्ज पर 8 बिट्स सीपीयू);
- डीएमए;
- चरित्र जनरेटर;
- आवंटित स्मृति क्षेत्र या विशेष रजिस्टर। गंतव्य (पैलेट, टाइल, पृष्ठभूमि, आदि);
- स्क्रीन की चमक को नियंत्रित करें (ओह, कचरे में बहुत सारे प्रभाव);
- पता स्थान एक्सटेंडर (मैपर);
- डिबगर (
लेकिन पूरी स्क्रीन होने पर इसकी ज़रूरत किसे है! )।
मैं इस तथ्य के साथ जारी रखूंगा कि यह है:
- हार्डवेयर SPI (F_CPU / 2 की गति से चल सकता है);
- ST7735 160x128 1.44 पर आधारित स्क्रीन ";
- एक चुटकी टाइमर (केवल 4 पीसी।);
- एक चुटकी GPIO;
- मुट्ठी भर बटन (5 पीसी। + दो-अक्ष जॉयस्टिक);
- कुछ सेंसर (प्रकाश, एक्सेलेरोमीटर, थर्मामीटर);
- पीजो बजर
जलन उत्सर्जक।
जाहिरा तौर पर वहाँ लगभग कुछ भी नहीं है। यह आश्चर्य की बात नहीं है कि कोई भी उसके साथ कुछ भी नहीं करना चाहता था, सिवाय इस समय के पोंग क्लोन और तीन गेम के एक जोड़े के लिए!
शायद तथ्य यह है कि ATmega32u4 नियंत्रक (और इस तरह) के तहत लेखन इंटेल 8051 (जो प्रकाशन के समय लगभग 40 साल पुराना है) के लिए प्रोग्रामिंग के समान है, जहां आपको भारी संख्या में शर्तों का पालन करने और विभिन्न ट्रिक्स और चालों का सहारा लेने की आवश्यकता है।
परिधीय प्रसंस्करण
सब कुछ के लिए एक!
सर्किट को देखने के बाद, यह स्पष्ट रूप से दिखाई दे रहा था कि सभी बाह्य उपकरणों को GPIO विस्तारक (74HC4067D मल्टीप्लेक्स आगे MUX) के माध्यम से जोड़ा गया है और GPIO PF4, PF5, PF6, PF7 या वरिष्ठ पोर्ट Nibble का उपयोग कर स्विच किया जाता है, और MUX आउटपुट GPIO - PF1 पर पढ़ा जाता है।
मास्क द्वारा PORTF पोर्ट पर केवल मान निर्दिष्ट करके इनपुट को स्विच करना बहुत सुविधाजनक है और नाबालिग ग्रंथियों को भूलकर कोई साधन नहीं है:
uint16_t getAnalogMux(uint8_t chMux) { MUX_PORTX = ((MUX_PORTX & 0x0F) | ((chMux<<4)&0xF0)); return readADC(); }
बटन क्लिक पोल:
#define SW_BTN_MIN_LVL 800 bool readSwitchButton(uint8_t btn) { bool state = true; if(getAnalogMux(btn) > SW_BTN_MIN_LVL) {
पोर्ट F के लिए मान निम्न हैं:
#define SW_BTN_1_MUX 0 #define SW_BTN_2_MUX 8 #define SW_BTN_3_MUX 4 #define SW_BTN_4_MUX 12
थोड़ा और जोड़कर:
#define BUTTON_A SW_BTN_4_MUX #define BUTTON_B SW_BTN_1_MUX #define BUTTON_X SW_BTN_2_MUX #define BUTTON_Y SW_BTN_3_MUX #define buttonIsPressed(a) readSwitchButton(a)
आप सही क्रॉस का सुरक्षित रूप से साक्षात्कार कर सकते हैं:
void updateBtnStates(void) { if(buttonIsPressed(BUTTON_A)) btnStates.aBtn = true; if(buttonIsPressed(BUTTON_B)) btnStates.bBtn = true; if(buttonIsPressed(BUTTON_X)) btnStates.xBtn = true; if(buttonIsPressed(BUTTON_Y)) btnStates.yBtn = true; }
कृपया ध्यान दें कि पिछली स्थिति को रीसेट नहीं किया गया है, अन्यथा आप कुंजी दबाने के तथ्य को याद कर सकते हैं (यह चटर्जी के खिलाफ एक अतिरिक्त सुरक्षा के रूप में भी काम करता है)।
SFX
एक गुलजार सा।
क्या होगा यदि यामाहा से कोई डीएसी, कोई चिप नहीं है, और ध्वनि के लिए केवल 1-बिट पीडब्लूएम आयत है?
सबसे पहले, यह इतना नहीं लगता है, लेकिन, इसके बावजूद, "पीडीएम ऑडियो" तकनीक को फिर से बनाने के लिए चालाक पीडब्लूएम का उपयोग यहां किया जाता है और इसकी मदद से आप ऐसा कर सकते हैं
।गेमबिनो से लाइब्रेरी द्वारा कुछ ऐसा ही प्रदान किया जाता है और इसकी आवश्यकता है कि पॉपिंग जनरेटर को किसी अन्य GPIO और टाइमर को Esplora (टाइमर 4 और OCR4D आउटपुट) में स्थानांतरित किया जाए। सही संचालन के लिए, टाइमर 1 का उपयोग इंटरप्ट उत्पन्न करने और नए डेटा के साथ OCR4D रजिस्टर को पुनः लोड करने के लिए भी किया जाता है।
गेमबिनो इंजन साउंड पैटर्न (ट्रैकर संगीत के रूप में) का उपयोग करता है, जो बहुत सारे स्थान बचाता है, लेकिन आपको सभी नमूनों को स्वयं करने की आवश्यकता है, तैयार किए गए पुस्तकालयों के साथ नहीं हैं।
यह उल्लेखनीय है कि यह इंजन लगभग 1/50 सेकंड या 20 फ्रेम / सेकंड की अपडेट अवधि से जुड़ा हुआ है।
ध्वनि पैटर्न पढ़ने के लिए, विकी को ऑडियो फॉर्मेट में पढ़ने के बाद, मैंने क्यूटी पर एक साधारण जीयूआई स्केच किया। यह एक ही तरीके से ध्वनि का उत्पादन नहीं करता है, लेकिन एक अनुमानित अवधारणा देता है कि पैटर्न कैसे ध्वनि करेगा और आपको इसे लोड करने, सहेजने और संपादित करने की अनुमति देता है।
ग्राफिक्स
अमर चित्रपट।
डिस्प्ले दो बाइट्स (RGB565) में रंगों को एनकोड करता है, लेकिन चूंकि इस प्रारूप में छवियां बहुत अधिक होंगी, इसलिए अंतरिक्ष को बचाने के लिए इन सभी को पैलेट द्वारा अनुक्रमित किया गया है, जिसे मैंने अपने पहले के लेखों में एक से अधिक बार वर्णित किया है।
Famicom / NES के विपरीत, छवि के लिए कोई रंग सीमाएं नहीं हैं और पैलेट में अधिक रंग उपलब्ध हैं।
खेल में प्रत्येक छवि बाइट्स की एक सरणी है जिसमें निम्न डेटा संग्रहीत है:
- चौड़ाई, ऊंचाई;
- डेटा मार्कर शुरू करें;
- शब्दकोश (यदि कोई हो, लेकिन बाद में उस पर अधिक);
- पेलोड;
- डेटा मार्कर का अंत।
उदाहरण के लिए, ऐसी तस्वीर (10 बार बढ़ाई गई):

कोड में यह इस तरह दिखेगा:
pic_t weaponLaserPic1[] PROGMEM = { 0x0f,0x07, 0x02, 0x8f,0x32,0xa2,0x05,0x8f,0x06,0x22,0x41,0xad,0x03,0x41,0x22,0x8f,0x06,0xa2,0x05, 0x8f,0x23,0xff, };
इस शैली में एक जहाज के बिना कहाँ? एक पिक्सेल अंतर के साथ सैकड़ों परीक्षण रेखाचित्रों के बाद, केवल ये जहाज खिलाड़ी के लिए बने रहे:

यह उल्लेखनीय है कि जहाजों में टाइल में लौ नहीं है (यहां यह स्पष्टता के लिए है), यह इंजन से निकास का एक एनीमेशन बनाने के लिए अलग से लगाया जाता है।
प्रत्येक जहाज के पायलटों के बारे में मत भूलना:

दुश्मन के जहाजों की भिन्नता बहुत बड़ी नहीं है, लेकिन मैं आपको याद दिला दूं, बहुत ज्यादा जगह नहीं है, इसलिए यहां तीन जहाज हैं:

हथियारों में सुधार और स्वास्थ्य को बहाल करने के रूप में विहित बोनस के बिना, खिलाड़ी लंबे समय तक नहीं रहेगा:

बेशक, बंदूकों की शक्ति में वृद्धि के साथ, उत्सर्जित गोले का प्रकार बदल जाता है:

जैसा कि शुरुआत में लिखा गया था, खेल में क्षुद्रग्रहों के साथ एक स्तर है, यह हर दूसरे मालिक के बाद आता है। यह दिलचस्प है कि विभिन्न आकारों की कई चलती और घूमती हुई वस्तुएं हैं। इसके अलावा, जब कोई खिलाड़ी उन्हें मारता है, तो वे आंशिक रूप से ढह जाते हैं, आकार में छोटे हो जाते हैं।
संकेत: बड़े क्षुद्रग्रह अधिक अंक अर्जित करते हैं।



इस सरल एनीमेशन को बनाने के लिए, 12 छोटी छवियां पर्याप्त हैं:

उन्हें प्रत्येक आकार (बड़े, मध्यम और छोटे) के लिए तीन में विभाजित किया गया है और प्रत्येक रोटेशन कोण के लिए आपको 4 और घुमाए जाने की आवश्यकता है 0, 90, 180 और 270 डिग्री। खेल में, यह एक समान अंतराल पर छवि के साथ व्यूअर को सरणी में बदलने के लिए पर्याप्त है, जिससे रोटेशन का भ्रम पैदा होता है।
void rotateAsteroid(asteroid_t &asteroid) { if(RN & 1) { asteroid.sprite.pPic = getAsteroidPic(asteroid); ++asteroid.angle; } } void moveAsteroids(void) { for(auto &asteroid : asteroids) { if(asteroid.onUse) { updateSprite(&asteroid.sprite); rotateAsteroid(asteroid); ...
यह केवल हार्डवेयर क्षमताओं की कमी के कारण किया जाता है, और एक सॉफ्टवेयर कार्यान्वयन जैसे कि अफ्फिन ट्रांसफॉर्मेशन स्वयं छवियों की तुलना में अधिक ले जाएगा और बहुत धीमी गति से होगा।
रुचि रखने वालों के लिए साटन का एक टुकड़ा।
आप प्रोटोटाइप के भाग को नोटिस कर सकते हैं और गेम पास करने के बाद केवल क्रेडिट में क्या दिखाई देता है।
सरल ग्राफिक्स के अलावा, अंतरिक्ष को बचाने के लिए और एक रेट्रो प्रभाव जोड़ने के लिए, ग्लिफ़ को कम करें और सभी ग्लिफ़्स जो 30 तक थे और एएससीआईआई के 127 बाइट्स फ़ॉन्ट से बाहर निकाल दिए गए थे।
महत्वपूर्ण!
यह मत भूलो कि एवीआर पर कब्ज और बाधा का मतलब यह बिल्कुल नहीं है कि डेटा प्रोग्राम मेमोरी में होगा, यहां आपको इसके अलावा PROGMEM का उपयोग करने की आवश्यकता है।
यह इस तथ्य के कारण है कि एवीआर कोर हार्वर्ड आर्किटेक्चर पर आधारित है, इसलिए डेटा तक पहुंचने के लिए सीपीयू के लिए विशेष एक्सेस कोड की आवश्यकता होती है।
आकाशगंगा को निचोड़ना
पैक करने का सबसे आसान तरीका RLE है।
पैक्ड डेटा का अध्ययन करने के बाद, आप देख सकते हैं कि 0x00 से 0x50 तक की रेंज में पेलोड बाइट में सबसे महत्वपूर्ण बिट का उपयोग नहीं किया जाता है। यह आपको दोहराव की शुरुआत (0x80) के लिए डेटा और स्टार्ट मार्कर को जोड़ने की अनुमति देता है, और पुनरावृत्ति की संख्या को इंगित करने के लिए अगला बाइट, जो आपको 257 की श्रृंखला (+2 इस तथ्य से पैक करने की अनुमति देता है कि दो बाइट्स का RLE केवल दो में समान बाइट्स का बेवकूफ है)।
अनपैकर कार्यान्वयन और प्रदर्शन:
void drawPico_RLE_P(uint8_t x, uint8_t y, pic_t *pPic) { uint16_t repeatColor; uint8_t tmpInd, repeatTimes; alphaReplaceColorId = getAlphaReplaceColorId(); auto tmpData = getPicSize(pPic, 0); tftSetAddrWindow(x, y, x+tmpData.u8Data1, y+tmpData.u8Data2); ++pPic;
मुख्य बात यह है कि स्क्रीन के बाहर छवि प्रदर्शित नहीं करना है, अन्यथा यह कचरा हो जाएगा, क्योंकि यहां कोई सीमा जांच नहीं है।
परीक्षण छवि ~ 39ms में अनपैक्ड है। एक ही समय में, 3040 बाइट्स पर कब्जा कर रहा है, जबकि संपीड़न के बिना यह 11,200 बाइट्स या 22,400 बाइट्स को अनुक्रमण के बिना ले जाएगा।
परीक्षण छवि (2 बार बढ़े हुए):

ऊपर की छवि में आप जिल्द देख सकते हैं, लेकिन स्क्रीन पर यह हार्डवेयर द्वारा सुचारू किया जाता है, जिससे सीआरटी के समान प्रभाव पैदा होता है और एक ही समय में संपीड़न अनुपात में काफी वृद्धि होती है।
RLE रामबाण नहीं है
हमें देजा वु के लिए इलाज किया जाता है।
जैसा कि आप जानते हैं, RLE LZ- जैसे पैकर्स के साथ अच्छी तरह से चलता है। वाईकेआई संपीड़न विधियों की एक सूची के साथ बचाव में आया था।
ध्वनि 3 डी ब्लास्ट में असंभव
इंट्रो के विश्लेषण के बारे में "गेमहट" से वीडियो था
।कई पैकर्स (LZ77, LZW, LZSS, LZO, RNC, आदि) का अध्ययन करने के बाद, मैं इस निष्कर्ष पर पहुंचा कि उनके अनपैकर्स:
- अनपैक्ड डेटा (कम से कम 64kb। और अधिक) के लिए बहुत अधिक RAM की आवश्यकता होती है;
- भारी और धीमा (प्रत्येक सबयूनिट के लिए हफ़मैन पेड़ बनाने की आवश्यकता है);
- एक छोटी खिड़की (बहुत कठोर रैम आवश्यकताओं) के साथ कम संपीड़न अनुपात है;
- लाइसेंस के साथ अस्पष्टता है।
महीनों के व्यर्थ अनुकूलन के बाद, मौजूदा पैकर को संशोधित करने का निर्णय लिया गया।
अधिकतम संपीड़न को प्राप्त करने के लिए एलजेड जैसे पैकर्स के साथ समानता से, शब्दकोश का उपयोग किया गया था, लेकिन बाइट स्तर पर - शब्दकोश में सबसे अधिक बार-बार जोड़े बाइट्स को एक बाइट पॉइंटर के साथ बदल दिया जाता है।
लेकिन एक पकड़ है: एक "शब्दकोश मार्कर" से "कितने दोहराव" के बाइट को कैसे अलग करना है?
कागज के एक टुकड़े के साथ लंबे समय तक बैठने और चमगादड़ के साथ एक जादुई खेल के बाद, यह दिखाई दिया:
- शब्दकोश में "शब्दकोश मार्कर" एक RLE मार्कर (0x80) + डेटा बाइट (0x50) + स्थिति संख्या है;
- शब्दकोश मार्कर के आकार में बाइट "कितने दोहराव" को सीमित करें - 1 (0xCF);
- शब्दकोश मान 0xff का उपयोग नहीं कर सकता (यह छवि के अंत के लिए मार्कर के लिए है)।
यह सब लागू करते हुए, हमें एक निश्चित शब्दकोश आकार मिलता है: 46 से अधिक बाइट जोड़े नहीं और 209 बाइट्स में कमी। जाहिर है, सभी छवियों को इस तरह से पैक नहीं किया जा सकता है, लेकिन वे किसी भी अधिक नहीं बन जाते हैं।
दोनों एल्गोरिदम में, पैक की गई छवि की संरचना इस प्रकार होगी:
- 1 बाइट प्रति चौड़ाई और ऊंचाई;
- शब्दकोश के आकार के लिए 1 बाइट, यह पैक्ड डेटा की शुरुआत के लिए एक मार्कर पॉइंटर है;
- शब्दकोश के 0 से 92 बाइट्स तक;
- पैक्ड डेटा के 1 से एन बाइट्स।
D (pickoPacker) पर परिणामी पैकर उपयोगिता अनुक्रमित * .png फ़ाइलों के साथ एक फ़ोल्डर में डालने और टर्मिनल (या cmd) से चलाने के लिए पर्याप्त है। यदि आपको सहायता की आवश्यकता है, तो विकल्प “-h” या “--help” के साथ चलाएं।
उपयोगिता के चलने के बाद, हमें * .h फाइलें मिलती हैं, जिनमें से सामग्री परियोजना में सही जगह पर स्थानांतरित करने के लिए सुविधाजनक है (इसलिए, कोई सुरक्षा नहीं है)।
अनपैक करने से पहले, स्क्रीन, शब्दकोश और प्रारंभिक डेटा तैयार किए जाते हैं:
void drawPico_DIC_P(uint8_t x, uint8_t y, pic_t *pPic) { auto tmpData = getPicSize(pPic, 0); tftSetAddrWindow(x, y, x+tmpData.u8Data1, y+tmpData.u8Data2); uint8_t tmpByte, unfoldPos, dictMarker; alphaReplaceColorId = getAlphaReplaceColorId(); auto pDict = &pPic[3];
डेटा का एक पढ़ा हुआ टुकड़ा एक शब्दकोश में पैक किया जा सकता है, इसलिए हम इसे चेक और अनपैक करते हैं:
inline uint8_t findPackedMark(uint8_t *ptr) { do { if(*ptr >= DICT_MARK) { return 1; } } while(*(++ptr) != PIC_DATA_END); return 0; } inline uint8_t *unpackBuf_DIC(const uint8_t *pDict) { bool swap = false; bool dictMarker = true; auto getBufferPtr = [&](uint8_t a[], uint8_t b[]) { return swap ? &a[0] : &b[0]; }; auto ptrP = getBufferPtr(buf_unpacked, buf_packed); auto ptrU = getBufferPtr(buf_packed, buf_unpacked); while(dictMarker) { if(*ptrP >= DICT_MARK) { setPicWData(ptrU) = getPicWData(pDict, *ptrP); ++ptrU; } else { *ptrU = *ptrP; } ++ptrU; ++ptrP; if(*ptrP == PIC_DATA_END) { *ptrU = *ptrP;
अब प्राप्त बफ़र से हम RLE को एक परिचित तरीके से खोलते हैं और इसे स्क्रीन पर प्रदर्शित करते हैं:
inline void printBuf_RLE(uint8_t *pData) { uint16_t repeatColor; uint8_t repeatTimes, tmpByte; while((tmpByte = *pData) != PIC_DATA_END) {
हैरानी की बात है, एल्गोरिथ्म की जगह अनपैकिंग समय को काफी प्रभावित नहीं करती है और ~ 47ms है। यह लगभग 8ms है। अब, लेकिन परीक्षण छवि केवल 1650 बाइट्स लेती है!
आखिरी उपाय तक
लगभग सब कुछ तेजी से किया जा सकता है!
हार्डवेयर एसपीआई की उपस्थिति के बावजूद, एवीआर कोर का उपयोग करते समय बहुत सिरदर्द होता है।
यह लंबे समय से ज्ञात है कि एवीआर पर एसपीआई, F_CPU / 2 की गति से चलने के अलावा, केवल 1 बाइट का डेटा रजिस्टर भी है (एक बार में 2 बाइट्स लोड करना संभव नहीं है)।
इसके अलावा, AVR पर लगभग सभी SPI कोड जो मुझे इस योजना के अनुसार मिले थे:
- एसपीडीआर डेटा डाउनलोड करें
- एक लूप में SPSR में SPIF बिट से पूछताछ करें।
जैसा कि आप देख सकते हैं, डेटा की निरंतर आपूर्ति, जैसा कि एसटीएम 32 पर किया जाता है, यहां गंध नहीं होती है। लेकिन, यहां तक कि आप ~ 3ms द्वारा दोनों unpackers के उत्पादन में तेजी ला सकते हैं!
डेटाशीट को खोलकर और "इंस्ट्रक्शन सेट क्लॉक्स" सेक्शन को देखते हुए, आप SPP के साथ बाइट ट्रांसमिट करते समय CPU लागतों की गणना कर सकते हैं:
- नए डेटा के साथ रजिस्टर लोडिंग के लिए 1 चक्र;
- प्रति बिट 2 बीट (या बाइट प्रति 16 बीट्स);
- 1 बार प्रति घड़ी लाइन जादू ("एनओपी" के बारे में थोड़ा बाद में);
- 1 घड़ी एसपीएसआर में स्थिति बिट की जांच करने के लिए (या शाखा पर 2 घड़ी);
कुल में, परीक्षण छवि (11,200 बाइट्स) के लिए एक पिक्सेल (दो बाइट्स), 38 घड़ी चक्र या ~ 425600 घड़ी चक्र प्रसारित करने के लिए खर्च किया जाना चाहिए।
यह जानते हुए कि F_CPU == 16 मेगाहर्ट्ज हम
0.0000000625 62.5 नैनोसेकेंड प्रति घड़ी चक्र (प्रोसेस0169) प्राप्त करते हैं, मूल्यों को गुणा करते हुए, हमें ~ 26 मिलीसेकंड मिलता है। सवाल यह उठता है: “जहाँ से मैंने पहले लिखा था कि अनपैकिंग का समय 39ms है। और 47ms? " सब कुछ सरल है - अनपैकर लॉजिक + इंटरप्ट हैंडलिंग।
यहाँ रुकावट आउटपुट का एक उदाहरण है:
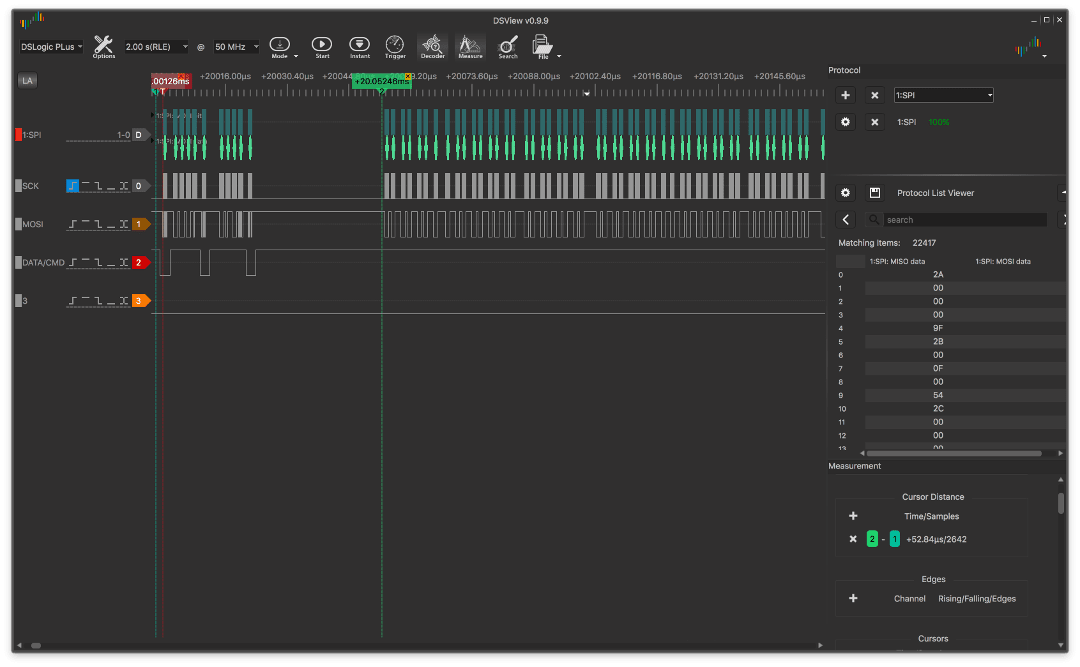
और बिना किसी रुकावट के:

ग्राफ़ दिखाते हैं कि वीआरएएम स्क्रीन में एड्रेस विंडो सेट करने और बिना किसी रुकावट के संस्करण में डेटा ट्रांसफर की शुरुआत के बीच का समय कम होता है और ट्रांसमिशन के दौरान बाइट्स के बीच लगभग कोई अंतराल नहीं होता है (ग्राफ़ एक समान है)।
दुर्भाग्य से, आप प्रत्येक छवि आउटपुट के लिए इंटरप्ट को अक्षम नहीं कर सकते, अन्यथा पूरे गेम की ध्वनि और कोर टूट जाएगी (बाद में उस पर अधिक)।
यह एक घड़ी लाइन के लिए एक निश्चित "जादू एनओपी" के बारे में ऊपर लिखा गया था। तथ्य यह है कि सीएलके को स्थिर करने और एसपीआईएफ ध्वज को सेट करने के लिए, ठीक 1 घड़ी चक्र की आवश्यकता होती है और जब तक यह झंडा पढ़ा जाता है, तब तक यह पहले से ही सेट होता है, जो कि BREQ निर्देश पर 2 बार में शाखा लगाने से बचता है।
यहाँ NOP के बिना एक उदाहरण दिया गया है:
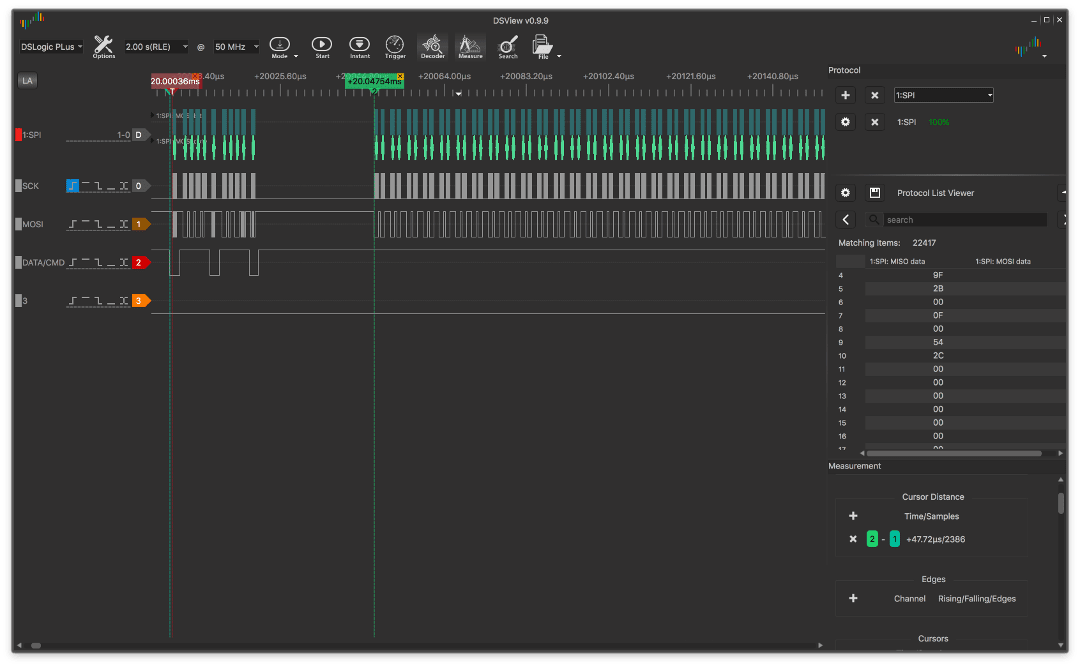
और उसके साथ:

अंतर बहुत ही कम लगता है, बस कुछ माइक्रोसेकंड, लेकिन अगर आप एक अलग पैमाने लेते हैं:
बड़े एनओपी:
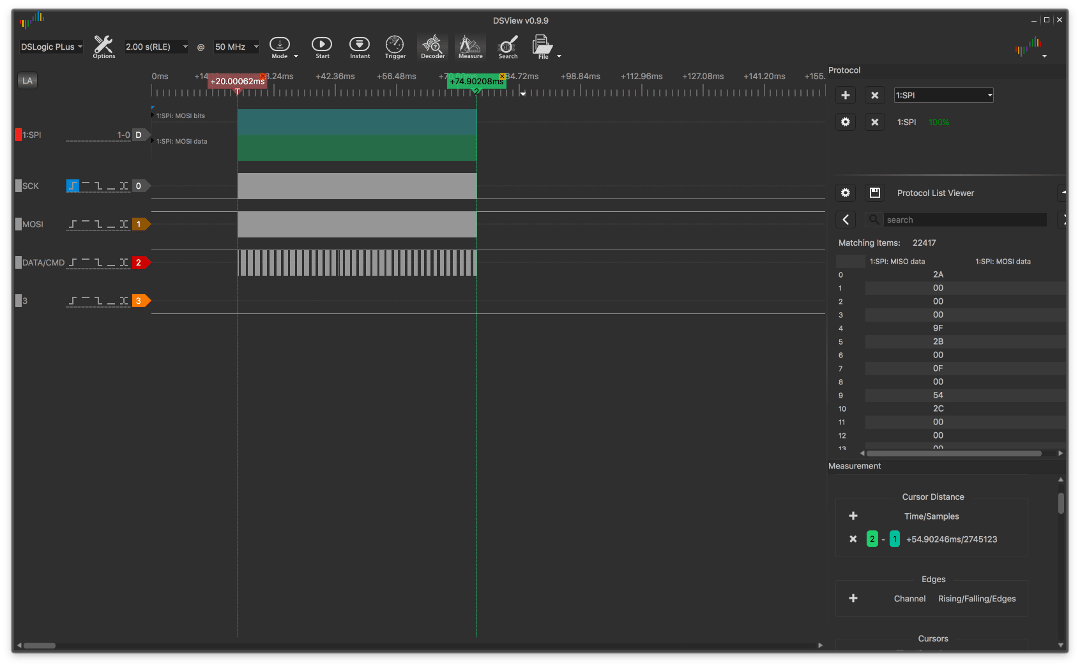
और इसके साथ बहुत बड़ा:

तब अंतर बहुत अधिक ध्यान देने योग्य हो जाता है, ~ 4.3ms तक पहुंच जाता है।
अब निम्नलिखित गंदे चाल करते हैं:
हम रजिस्टरों को लोड करने और पढ़ने के आदेश को स्वैप करते हैं और आप एसपीआईएफ ध्वज के हर दूसरे बाइट पर इंतजार नहीं कर सकते हैं, लेकिन अगले पिक्सेल के पहले बाइट को लोड करने से पहले इसे जांचें।
हम ज्ञान लागू करते हैं और "पुशकॉन्फ्रैस्ट (रिपीटक्लोर);"
#define SPDR_TX_WAIT(a) asm volatile(a); while((SPSR & (1<<SPIF)) == 0); typedef union { uint16_t val; struct { uint8_t lsb; uint8_t msb; }; } SPDR_t; ... do { #ifdef ESPLORA_OPTIMIZE SPDR_t in = {.val = repeatColor}; SPDR_TX_WAIT(""); SPDR = in.msb; SPDR_TX_WAIT("nop"); SPDR = in.lsb; #else pushColorFast(repeatColor); #endif } while(--repeatTimes); } #ifdef ESPLORA_OPTIMIZE SPDR_TX_WAIT("");
टाइमर से रुकावट के बावजूद, ऊपर की चाल का उपयोग करने से लगभग 6ms का लाभ मिलता है।

यह है कि लोहे का सरल ज्ञान आपको इसके बारे में थोड़ा और निचोड़ने और कुछ समान उत्पादन करने की अनुमति देता है:

कोलोसियम टकराव
बक्सों की लड़ाई।
शुरू करने के लिए, वस्तुओं का पूरा सेट (जहाज, गोले, क्षुद्रग्रह, बोनस) निम्नलिखित पैरामीटर के साथ संरचना (स्प्राइट) हैं:
- वर्तमान एक्स, वाई निर्देशांक;
- नए निर्देशांक X, Y;
- छवि के लिए सूचक।
चूंकि छवि चौड़ाई और ऊंचाई को संग्रहीत करती है, इसलिए इन मापदंडों को डुप्लिकेट करने की आवश्यकता नहीं है, इसके अलावा, ऐसा संगठन कई पहलुओं में तर्क को सरल करता है।
गणना स्वयं को सरल बनायी जाती है - आयताकारों के प्रतिच्छेदन के आधार पर, इसे सरल बनाया जाता है। हालांकि यह पर्याप्त सटीक नहीं है और भविष्य के संघर्षों की गणना नहीं करता है, यह पर्याप्त से अधिक है।
सत्यापन एक्स और वाई कुल्हाड़ियों पर बारी-बारी से होता है। इसके कारण, एक्स अक्ष पर चौराहे की अनुपस्थिति टकराव की गणना को कम करती है।
सबसे पहले, दूसरी आयत के बाईं ओर के साथ पहले आयत के दाईं ओर X अक्ष के सामान्य भाग के लिए जाँच की जाती है। यदि सफल हो, तो दूसरी आयत के पहले और दाएँ पक्ष के बाईं ओर के लिए एक समान जाँच की जाती है।
एक्स अक्ष के साथ चौराहों का सफलतापूर्वक पता लगाने के बाद, वाई अक्ष के साथ आयतों के ऊपरी और निचले पक्षों के लिए उसी तरह एक चेक किया जाता है।
ऊपर जितना दिखता है उससे कहीं ज्यादा आसान है:
bool checkSpriteCollision(sprite_t *pSprOne, sprite_t *pSprTwo) { auto tmpDataOne = getPicSize(pSprOne->pPic, 0); auto tmpDataTwo = getPicSize(pSprTwo->pPic, 0); uint8_t objOnePosEndX = (pSprOne->pos.Old.x + tmpDataOne.u8Data1); if(objOnePosEndX >= pSprTwo->pos.Old.x) { uint8_t objTwoPosEndX = (pSprTwo->pos.Old.x + tmpDataTwo.u8Data1); if(pSprOne->pos.Old.x >= objTwoPosEndX) { return false;
इस खेल में इसे जोड़ना बाकी है:
void checkInVadersCollision(void) { decltype(aliens[0].weapon.ray) gopher; for(auto &alien : aliens) { if(alien.alive) { if(checkSpriteCollision(&ship.sprite, &alien.sprite)) { gopher.sprite.pos.Old = alien.sprite.pos.Old; rocketEpxlosion(&gopher);
बेजियर वक्र
अंतरिक्ष की रेल।
इस शैली के साथ किसी भी अन्य खेल की तरह, दुश्मन जहाजों को घटता साथ चलना चाहिए।
नियंत्रक और इस कार्य के लिए सबसे सरल के रूप में द्विघात वक्रों को लागू करने का निर्णय लिया गया। उनके लिए तीन बिंदु पर्याप्त हैं: प्रारंभिक (P0), अंतिम (P2) और काल्पनिक (P1)। पहले दो लाइन की शुरुआत और अंत निर्दिष्ट करते हैं, अंतिम बिंदु वक्रता के प्रकार का वर्णन करता है।
घटता पर शानदार लेख।चूंकि यह एक बेजियर पैरामीट्रिक वक्र है, इसलिए इसे एक और पैरामीटर की भी आवश्यकता है - प्रारंभ और अंत बिंदुओं के बीच मध्यवर्ती बिंदुओं की संख्या।
कुल हम यहां इस तरह की संरचना प्राप्त करते हैं:
typedef struct {
इसमें, position_t निर्देशांक X और Y के दो बाइट्स की एक संरचना है।
प्रत्येक सूत्र के लिए एक बिंदु खोजना इस सूत्र (thx Wiki) का उपयोग करके गणना की जाती है:
B = ((1.0 - t) ^ 2) P0 + 2t (1.0 - t) P1 + (t ^ 2) P2:
t [> = 0 && <= 1]
एक लंबे समय के लिए, इसके कार्यान्वयन को एक निश्चित बिंदु गणित के बिना सिर पर हल किया गया था:
... float t = ((float)pItemLine->step)/((float)pLine->totalSteps); pPos->x = (1.0 - t)*(1.0 - t)*pLine->P0.x + 2*t*(1.0 - t)*pLine->P1.x + t*t*pLine->P2.x; pPos->y = (1.0 - t)*(1.0 - t)*pLine->P0.y + 2*t*(1.0 - t)*pLine->P1.y + t*t*pLine->P2.y; ...
बेशक, यह नहीं छोड़ा जा सकता है। आखिरकार, फ्लोट से छुटकारा पाने से न केवल गति में सुधार हो सकता है, बल्कि रोम को भी मुक्त किया जा सकता है, इसलिए निम्नलिखित कार्यान्वयन पाए गए:
- avrfix;
- stdfix;
- libfixmath;
- fixedptc।
पहला एक अंधेरा घोड़ा बना हुआ है, क्योंकि यह एक संकलित पुस्तकालय है और डिस्सेम्बलर के साथ गड़बड़ नहीं करना चाहता था।
जीसीसी बंडल से दूसरा उम्मीदवार भी काम नहीं करता था, क्योंकि एवीआर-जीसीसी का उपयोग नहीं किया गया था और "शॉर्ट _Accum" प्रकार अनुपलब्ध था।
तीसरा विकल्प, इस तथ्य के बावजूद कि इसमें बड़ी संख्या में चटाई है। फ़ंक्शंस, Q16.16 प्रारूप के तहत विशिष्ट बिट्स पर हार्ड-कोडित बिट ऑपरेशन है, जो क्यू और I के मूल्यों को नियंत्रित करना असंभव बनाता है।
उत्तरार्द्ध को "फिक्स्डमैथ" का एक सरलीकृत संस्करण माना जा सकता है, लेकिन मुख्य लाभ यह है कि न केवल चर के आकार को नियंत्रित करने की क्षमता है, जो डिफ़ॉल्ट रूप से प्रारूप Q24.8 के साथ 32 बिट है, बल्कि क्यू और आई के मान भी हैं।
विभिन्न सेटिंग्स पर परीक्षण के परिणाम:
| टाइप | बुद्धि | अतिरिक्त झंडे | रोम बाइट | टीएमएस। * |
|---|
| नाव | - | - | 4236 | 35 |
| fixedmath | 16.16 | - | 4796 | 119 |
| fixedmath | 16.16 | FIXMATH_NO_OVERFLOW | 4664 | 89 |
| fixedmath | 16.16 | FIXMATH_OPTIMIZE_8BIT | 5036 | 92 |
| fixedmath | 16.16 | _NO_OVERFLOW + _8BIT | 4916 | 89 |
| fixedptc | 24.8 | FIXEDPT_BITS 32 | 4420 | 64 |
| fixedptc | 9.7 | FIXEDPT_BITS 16 | 3490 | 31 |
* चेक पैटर्न पर किया गया था: "195,175,145,110,170,70,170" और कुंजी "-Os"।
यह तालिका से देखा जा सकता है कि दोनों पुस्तकालयों ने अधिक रॉम लिया और फ्लोट का उपयोग करते समय जीसीसी से संकलित कोड से खुद को बदतर दिखाया।
यह भी देखा गया है कि Q9.7 प्रारूप के लिए एक छोटे से संशोधन और 16bit के चर में कमी ने 4ms का त्वरण दिया। और ~ 50 बाइट्स पर रोम को मुक्त करना।
अपेक्षित प्रभाव सटीकता में कमी और त्रुटियों की संख्या में वृद्धि थी:

जो इस मामले में अनियंत्रित है।
संसाधनों का आवंटन
मंगलवार और गुरुवार सिर्फ एक घंटे के लिए काम करते हैं।
ज्यादातर मामलों में, सभी गणना हर फ्रेम में की जाती हैं, जो हमेशा उचित नहीं होती है, क्योंकि फ्रेम में कुछ गणना करने के लिए पर्याप्त समय नहीं हो सकता है और आपको बारी-बारी से, फ्रेम गिनने या उन्हें लंघन के साथ ट्रिक करना होगा। इसलिए मैं और आगे बढ़ गया - पूरी तरह से कर्मचारियों को छोड़ दिया।
छोटे कार्यों में सब कुछ टूटने के बाद, यह होना चाहिए: टकराव, प्रसंस्करण ध्वनि, बटन और प्रदर्शन ग्राफिक्स की गणना करना, यह उन्हें एक निश्चित अंतराल पर प्रदर्शन करने के लिए पर्याप्त है, और आंख की जड़ता और स्क्रीन के केवल भाग को अपडेट करने की क्षमता चाल करेगी।हम यह सब एक बार ओएस के साथ नहीं, बल्कि उस राज्य मशीन के साथ करते हैं, जिसे मैंने कुछ साल पहले बनाया था, या, और अधिक सरलता से, न कि क्राउड-आउट टिनीएसएम टास्क मैनेजर।मैं किसी भी RTOS के बजाय इसका उपयोग करने के कारणों को दोहराऊंगा:- कम ROM आवश्यकताओं (~ 250 बाइट्स कोर);
- कम रैम आवश्यकताएं (~ 9 बाइट्स प्रति कार्य);
- काम का सरल और समझने योग्य सिद्धांत;
- व्यवहार का निर्धारण;
- कम CPU समय बर्बाद होता है;
- लोहे तक पहुंच छोड़ देता है;
- स्वतंत्र मंच;
- C में लिखा है और C ++ में लपेटना आसान है;
मेरी अपनी बाइक चाहिए
जैसा कि मैंने एक बार वर्णन किया है, इसके लिए कार्यों को संरचनाओं के संकेत बिंदुओं में व्यवस्थित किया जाता है, जहां एक फ़ंक्शन के लिए एक संकेतक और इसके कॉल अंतराल को संग्रहीत किया जाता है। यह समूह अलग-अलग चरणों में गेम के विवरण को सरल करता है, जो आपको शाखाओं की संख्या को कम करने और कार्यों के सेट को गतिशील रूप से स्विच करने की अनुमति देता है।उदाहरण के लिए, स्टार्ट स्क्रीन के दौरान, 7 कार्य किए जाते हैं, और खेल के दौरान पहले से ही 20 कार्य होते हैं (गेम टास्क फ़ाइल में सभी कार्यों का वर्णन किया गया है)।पहले आपको अपनी सुविधा के लिए कुछ मैक्रो को परिभाषित करने की आवश्यकता है: #define T(a) a##Task #define TASK_N(a) const taskParams_t T(a) #define TASK(a,b) TASK_N(a) PROGMEM = {.pFunc=a, .timeOut=b} #define TASK_P(a) (taskParams_t*)&T(a) #define TASK_ARR_N(a) const tasksArr_t a##TasksArr[] #define TASK_ARR(a) TASK_ARR_N(a) PROGMEM #define TASK_END NULL
कार्य घोषणा वास्तव में एक संरचना का निर्माण कर रही है, अपने क्षेत्रों को आरंभ करके इसे ROM में रखती है: TASK(updateBtnStates, 25);
ऐसी प्रत्येक संरचना में 4 बाइट्स रोम (दो प्रति सूचक और दो प्रति अंतराल) होती हैं।मैक्रोज़ को एक अच्छा बोनस यह है कि यह प्रत्येक फ़ंक्शन के लिए एक से अधिक अद्वितीय संरचना बनाने के लिए काम नहीं करता है।आवश्यक कार्य घोषित करने के बाद, हम उन्हें सरणी में जोड़ते हैं और उन्हें ROM में भी डालते हैं: TASK_ARR( game ) = { TASK_P(updateBtnStates), TASK_P(playMusic), TASK_P(drawStars), TASK_P(moveShip), TASK_P(drawShip), TASK_P(checkFireButton), TASK_P(pauseMenu), TASK_P(drawPlayerWeapon), TASK_P(checkShipHealth), TASK_P(drawSomeGUI), TASK_P(checkInVaders), TASK_P(drawInVaders), TASK_P(moveInVaders), TASK_P(checkInVadersRespawn), TASK_P(checkInVadersRay), TASK_P(checkInVadersCollision), TASK_P(dropWeaponGift), TASK_END };
स्थिर स्मृति के लिए ध्वज USE_DYNAMIC_MEM को 0 पर सेट करते समय, याद रखने वाली मुख्य बात यह है कि रैम में कार्य करने वाले स्टोर पर पॉइंटर्स को इनिशियलाइज़ करना और उनमें से अधिकतम संख्या सेट करना है जिसे निष्पादित किया जाएगा: ... tasksContainer_t tasksContainer; taskFunc_t tasksArr[MAX_GAME_TASKS]; ... initTasksArr(&tasksContainer, &tasksArr[0], MAX_GAME_TASKS); …
निष्पादन के लिए कार्य निर्धारित करना: ... addTasksArray_P(gameTasksArr); …
ओवरफ्लो संरक्षण USE_MEM_PANIC ध्वज द्वारा नियंत्रित किया जाता है, यदि आप कार्यों की संख्या के बारे में सुनिश्चित हैं, तो आप इसे ROM को सहेजने के लिए अक्षम कर सकते हैं।यह केवल हैंडलर चलाने के लिए बनी हुई है: ... runTasks(); ...
अंदर एक अनंत लूप है जिसमें मूल तर्क होता है। एक बार इसके अंदर, स्टैक को "__attribute__ ((नोटरीर्न))" के लिए भी धन्यवाद दिया जाता है।लूप में, सरणी के तत्वों को वैकल्पिक रूप से स्कैन किया जाता है ताकि अंतराल समाप्त होने के बाद कार्य को कॉल करने की आवश्यकता हो।अंतराल की उलटी गिनती टाइमर 1 के आधार पर 1ms की मात्रा के साथ एक प्रणाली के रूप में की गई थी ...समय में कार्यों के सफल वितरण के बावजूद, कभी-कभी उन्हें अतिव्यापी (घबराना) किया जाता था, जिससे खेल में हर चीज और हर चीज का अल्पकालिक लुप्त होता था।यह निश्चित रूप से तय किया जाना था, लेकिन कैसे? इस बारे में कि अगली बार सबकुछ कैसे तय किया गया था, लेकिन अब स्रोत में ईस्टर अंडे को खोजने की कोशिश करें।अंत
इसलिए, बहुत सारी ट्रिक (और जिनमें से कई का मैंने वर्णन नहीं किया है) का उपयोग करते हुए, सब कुछ 24kb रोम और 1500 बाइट्स रैम में फिट होने के लिए निकला। यदि आपके कोई प्रश्न हैं, तो मुझे उनका उत्तर देने में खुशी होगी।उन लोगों के लिए जो ईस्टर अंडे की तलाश नहीं करते थे या नहीं करते थे:पक्ष के लिए खुदाई: void invadersMagicRespawn(void) { for(auto &alien : aliens) { if(!alien.alive) { alien.respawnTime = 1; } } }
उल्लेखनीय कुछ भी नहीं है, है ना?राअज़ोरवाचैइवम मैक्रो इनवेस्टर्समैजिकरस्पॉन: void action() { tftSetTextSize(1); for(;;) { tftSetCP437(RN & 1); tftSetTextColorBG((((RN % 192 + 64) & 0xFC) << 3), COLOR_BLACK); tftDrawCharInt(((RN % 26) * 6), ((RN & 15) * 8), (RN % 255)); tftPrintAt_P(32, 58, (const char *)creditP0); } } a(void) { for(auto &alien : aliens) { if(!alien.alive) { alien.respawnTime = 1; } } }
«(void)» , «action()» 10 , «disablePause();». «Matrix Falling code» . 130 ROM.
बनाने और चलाने के लिए यह फ़ोल्डर / (या लिंक) "esploraAPI" को "/ arduino / पुस्तकालयों" में डालने के लिए पर्याप्त है।संदर्भ:
PS आप देख सकते हैं और सुन सकते हैं कि जब मैं स्वीकार्य वीडियो बनाता हूं तो यह सब थोड़ा बाद में कैसे दिखता है।