 पाइथन में एक पूर्ण मशीन लर्निंग वॉक-थ्रू: भाग दो
पाइथन में एक पूर्ण मशीन लर्निंग वॉक-थ्रू: भाग दोमशीन लर्निंग प्रोजेक्ट के सभी हिस्सों को एक साथ रखना मुश्किल हो सकता है। लेखों की इस श्रृंखला में, हम वास्तविक डेटा का उपयोग करके मशीन सीखने की प्रक्रिया के कार्यान्वयन के सभी चरणों से गुजरेंगे, और यह पता लगाएंगे कि विभिन्न तकनीकों को एक-दूसरे के साथ कैसे जोड़ा जाता है।
पहले लेख में, हमने डेटा को साफ और संरचित किया, एक खोजपूर्ण विश्लेषण किया, मॉडल में उपयोग के लिए विशेषताओं का एक सेट एकत्र किया, और परिणामों के मूल्यांकन के लिए एक आधार रेखा निर्धारित की। इस लेख की मदद से हम सीखेंगे कि पायथन में कैसे लागू किया जाए और कई मशीन लर्निंग मॉडल की तुलना की जाए, सर्वश्रेष्ठ मॉडल का अनुकूलन करने के लिए हाइपरपरमेट्रिक ट्यूनिंग करें और एक परीक्षण डेटा सेट पर अंतिम मॉडल के प्रदर्शन का मूल्यांकन करें।
सभी प्रोजेक्ट कोड
GitHub पर है , और
यहां वर्तमान लेख से संबंधित दूसरा नोटबुक है। आप अपनी इच्छानुसार कोड का उपयोग और संशोधित कर सकते हैं!
मॉडल मूल्यांकन और चयन
मेमो: हम एक नियंत्रित प्रतिगमन कार्य पर काम कर रहे हैं,
न्यूयॉर्क में इमारतों से ऊर्जा की जानकारी का उपयोग करके एक मॉडल बनाने के लिए, जो
एक विशेष इमारत को
ऊर्जा स्टार स्कोर की भविष्यवाणी करता है। हम पूर्वानुमान की सटीकता और मॉडल की व्याख्या दोनों में रुचि रखते हैं।
आज आप
कई उपलब्ध मशीन लर्निंग मॉडल में से चुन सकते हैं, और यह बहुतायत आपको भयभीत कर सकती है। बेशक, नेटवर्क पर
तुलनात्मक समीक्षाएं हैं जो एल्गोरिथ्म चुनते समय आपको नेविगेट करने में मदद करेगी, लेकिन मैं कुछ प्रयास करना और देखना पसंद करता हूं जो बेहतर है। अधिकांश भाग के लिए, मशीन लर्निंग
सैद्धांतिक परिणामों के बजाय अनुभवजन्य पर आधारित है, और यह
अग्रिम में समझना लगभग
असंभव है कि कौन सा मॉडल अधिक सटीक है ।
आमतौर पर यह सिफारिश की जाती है कि आप सरल, व्याख्यात्मक मॉडल, जैसे रैखिक प्रतिगमन के साथ शुरू करते हैं, और यदि परिणाम असंतोषजनक हैं, तो अधिक जटिल पर आगे बढ़ें, लेकिन आमतौर पर अधिक सटीक तरीके। यह ग्राफ (बहुत वैज्ञानिक विरोधी) कुछ एल्गोरिदम की सटीकता और व्याख्या के बीच संबंध को दर्शाता है:
 व्याख्या और सटीकता ( स्रोत )।
व्याख्या और सटीकता ( स्रोत )।हम जटिलता की डिग्री के पांच मॉडल का मूल्यांकन करेंगे:
- रैखिक प्रतिगमन।
- K- निकटतम पड़ोसियों की विधि।
- "बेतरतीब जंगल।"
- धीरे-धीरे बढ़ाने वाला।
- सपोर्ट वैक्टर की विधि।
हम इन मॉडलों के सैद्धांतिक उपकरण नहीं, बल्कि उनके कार्यान्वयन पर विचार करेंगे। यदि आप सिद्धांत में रुचि रखते हैं, तो
सांख्यिकीय सीखना (मुफ्त में उपलब्ध) या
हैंड्स-ऑन मशीन लर्निंग विद स्किकिट-लर्न और टेन्सरफ्लो की जाँच करें । दोनों पुस्तकों में, सिद्धांत को पूरी तरह से समझाया गया है और क्रमशः आर और पायथन भाषाओं में उल्लिखित विधियों का उपयोग करने की प्रभावशीलता दिखाई गई है।
लापता मूल्यों में भरें
यद्यपि जब हमने डेटा को साफ़ किया, तो हमने उन स्तंभों को छोड़ दिया जिनमें आधे से अधिक मूल्य गायब हैं, फिर भी हमारे पास बहुत सारे मूल्य हैं। मशीन लर्निंग मॉडल लापता डेटा के साथ काम नहीं कर सकते हैं, इसलिए हमें उन्हें
भरने की जरूरत
है ।
सबसे पहले, हम डेटा पर विचार करते हैं और याद करते हैं कि वे कैसे दिखते हैं:
import pandas as pd import numpy as np
प्रत्येक
NaN मान डेटा में एक गुम रिकॉर्ड है।
आप उन्हें अलग-अलग तरीकों से भर सकते हैं , और हम काफी सरल औसतन प्रतिरूपण विधि का उपयोग करेंगे, जो लापता डेटा को संबंधित कॉलम के औसत मूल्यों के साथ बदल देता है।
नीचे दिए गए कोड में, हम एक औसत रणनीति के साथ एक
Scikit-Learn Imputer
Imputer बनाएंगे। फिर हम इसे प्रशिक्षण डेटा (
imputer.fit का उपयोग
imputer.fit ) पर प्रशिक्षित करते हैं, और इसे प्रशिक्षण और परीक्षण सेट में गुम मानों (
imputer.transform का उपयोग
imputer.transform ) में भरने के लिए लागू करते हैं। यही है,
परीक्षण डेटा में गायब होने वाले रिकॉर्ड को
प्रशिक्षण डेटा से संबंधित औसत मूल्य से भरा जाएगा।
हम फिलिंग करते हैं और डेटा पर मॉडल को प्रशिक्षित नहीं करते हैं, जैसा कि
परीक्षण डेटा लीक होने की समस्या से बचने के लिए होता है, जब परीक्षण डेटासेट की जानकारी प्रशिक्षण में जाती है।
अब सारे मूल्य भरे पड़े हैं, कोई अंतराल नहीं है।
फ़ीचर स्केलिंग
स्केलिंग एक विशेषता की सीमा को बदलने की सामान्य प्रक्रिया है।
यह एक आवश्यक कदम है , क्योंकि संकेतों को विभिन्न इकाइयों में मापा जाता है, जिसका अर्थ है कि वे विभिन्न श्रेणियों को कवर करते हैं। यह इस तरह के एल्गोरिदम
के समर्थन वेक्टर विधि और के-निकटतम पड़ोसी विधि के परिणामों को बहुत विकृत करता है, जो माप के बीच की दूरी को ध्यान में रखते हैं। और स्केलिंग आपको इससे बचने की अनुमति देता है। यद्यपि
रैखिक प्रतिगमन और "यादृच्छिक वन" जैसी विधियों को सुविधाओं के स्केलिंग की आवश्यकता नहीं है, लेकिन कई एल्गोरिदम की तुलना करते समय इस कदम की उपेक्षा नहीं करना बेहतर है।
हम प्रत्येक विशेषता का उपयोग 0 से 1 तक की सीमा तक करेंगे। हम विशेषता के सभी मूल्यों को लेते हैं, न्यूनतम का चयन करते हैं और इसे अधिकतम और न्यूनतम (सीमा) के बीच के अंतर से विभाजित करते हैं। इस स्केलिंग विधि को अक्सर
सामान्यीकरण कहा जाता
है, और दूसरा मुख्य तरीका मानकीकरण है ।
यह प्रक्रिया मैन्युअल रूप से लागू करना आसान है, इसलिए हम Scikit-Learn से MinMaxScaler ऑब्जेक्ट का उपयोग
MinMaxScaler । इस पद्धति का कोड अनुपलब्ध मानों को भरने के लिए कोड के समान है, केवल स्केलिंग का उपयोग चिपकाने के बजाय किया जाता है। याद रखें कि हम केवल प्रशिक्षण सेट पर मॉडल सीखते हैं, और फिर हम सभी डेटा को रूपांतरित करते हैं।
अब, प्रत्येक विशेषता का न्यूनतम मान 0 है, और अधिकतम 1. लापता मानों में भरने और विशेषताओं को स्केल करने के लिए - इन दोनों चरणों की लगभग किसी भी मशीन सीखने की प्रक्रिया में आवश्यकता होती है।
हम Scikit-Learn में मशीन लर्निंग मॉडल लागू करते हैं
सभी प्रारंभिक कार्य के बाद, मॉडल बनाने, प्रशिक्षण और चलने की प्रक्रिया अपेक्षाकृत सरल है। हम पायथन में
स्किकिट-लर्न लाइब्रेरी का उपयोग करेंगे, जो खूबसूरती से प्रलेखित है और मॉडल के निर्माण के लिए विस्तृत सिंटैक्स के साथ है। शिकिट-लर्न में एक मॉडल बनाने का तरीका सीखकर, आप सभी प्रकार के एल्गोरिदम को जल्दी से लागू कर सकते हैं।
हम ढाल बढ़ाने का उपयोग करके निर्माण, प्रशिक्षण (
.predict ) और परीक्षण (
.predict ) की प्रक्रिया का वर्णन करेंगे:
from sklearn.ensemble import GradientBoostingRegressor
बनाने, प्रशिक्षण और परीक्षण के लिए कोड की सिर्फ एक पंक्ति। अन्य मॉडल बनाने के लिए, हम एक ही वाक्यविन्यास का उपयोग करते हैं, केवल एल्गोरिथ्म का नाम बदलकर।

मॉडल का निष्पक्ष मूल्यांकन करने के लिए, हमने लक्ष्य के औसत मूल्य का उपयोग करके आधार स्तर की गणना की और 24.5 प्राप्त किया। और परिणाम बहुत बेहतर थे, इसलिए मशीन सीखने का उपयोग करके हमारी समस्या को हल किया जा सकता है।
हमारे मामले में,
ग्रेडिंग बूस्टिंग (MAE = 10.013) "यादृच्छिक वन" (10.014 एमएएच) की तुलना में थोड़ा बेहतर निकला। हालांकि इन परिणामों को पूरी तरह से ईमानदार नहीं माना जा सकता है, क्योंकि हाइपरपरमेटर्स के लिए हम ज्यादातर डिफ़ॉल्ट मानों का उपयोग करते हैं। मॉडल की प्रभावशीलता दृढ़ता से इन सेटिंग्स पर निर्भर करती है,
विशेष रूप से समर्थन वेक्टर विधि में । फिर भी, इन परिणामों के आधार पर, हम ढाल को बढ़ावा देने का चयन करेंगे और इसे अनुकूलित करना शुरू करेंगे।
हाइपरपरमेट्रिक मॉडल अनुकूलन
एक मॉडल चुनने के बाद, आप हाइपर मापदंडों को समायोजित करके कार्य को हल करने के लिए इसे अनुकूलित कर सकते हैं।
लेकिन सबसे पहले, आइए समझते हैं
कि हाइपरपरमेटर्स क्या हैं और वे साधारण मापदंडों से कैसे भिन्न हैं ?
- मॉडल के हाइपरपैरमीटर को एल्गोरिथ्म की सेटिंग्स माना जा सकता है, जिसे हम इसके प्रशिक्षण की शुरुआत से पहले सेट करते हैं। उदाहरण के लिए, हाइपरपरेट "रैंडम फ़ॉरेस्ट" में पेड़ों की संख्या है, या के-निकटतम पड़ोसियों की विधि में पड़ोसियों की संख्या है।
- मॉडल पैरामीटर - प्रशिक्षण के दौरान वह क्या सीखती है, उदाहरण के लिए, रैखिक प्रतिगमन में वजन।
हाइपरपरमीटर को नियंत्रित करके, हम मॉडल के परिणामों को प्रभावित करते हैं, इसकी
अंडर-एजुकेशन और रिट्रेनिंग के बीच संतुलन को बदलते हैं। सीखने के तहत एक ऐसी स्थिति है जहां मॉडल पर्याप्त जटिल नहीं है (यह स्वतंत्रता की बहुत कम डिग्री है) संकेतों और लक्ष्यों के पत्राचार का अध्ययन करने के लिए। एक अंडर-प्रशिक्षित मॉडल में एक
उच्च पूर्वाग्रह होता है, जिसे मॉडल को जटिल करके ठीक किया जा सकता है।
रिट्रेनिंग एक ऐसी स्थिति है जहां मॉडल अनिवार्य रूप से प्रशिक्षण डेटा को याद रखता है। मुकर गए मॉडल में एक
उच्च विचरण होता है, जिसे नियमितीकरण के माध्यम से मॉडल की जटिलता को सीमित करके समायोजित किया जा सकता है। दोनों प्रशिक्षित और मुकर्रर मॉडल अच्छी तरह से परीक्षण डेटा को सामान्य बनाने में सक्षम नहीं होंगे।
सही हाइपरपैरामीटर चुनने में कठिनाई यह है कि प्रत्येक कार्य के लिए एक अद्वितीय इष्टतम सेट होगा। इसलिए, सर्वोत्तम सेटिंग्स चुनने का एकमात्र तरीका नए डेटासेट पर विभिन्न संयोजनों का प्रयास करना है। सौभाग्य से, स्किकिट-लर्न में कई विधियां हैं जो आपको हाइपरपैरमीटर का प्रभावी ढंग से मूल्यांकन करने की अनुमति देती हैं। इसके अलावा,
टीपीओटी जैसी परियोजनाएं
जेनेटिक प्रोग्रामिंग जैसे दृष्टिकोणों का उपयोग करके
हाइपरपैरामीटर की खोज को अनुकूलित करने का प्रयास कर रही हैं। इस लेख में, हम खुद को Scikit-Learn का उपयोग करने के लिए प्रतिबंधित करते हैं।
यादृच्छिक खोज को क्रॉस-चेक करें
आइए एक हाइपरपैरेट ट्यूनिंग पद्धति को लागू करें जिसे यादृच्छिक क्रॉस-वेलिडेशन लुकअप कहा जाता है:
- रैंडम खोज - हाइपरपरमेटर्स के चयन के लिए एक तकनीक। हम ग्रिड को परिभाषित करते हैं, और फिर बेतरतीब ढंग से ग्रिड खोज के विपरीत, इसमें से विभिन्न संयोजनों का चयन करते हैं, जिसमें हम प्रत्येक संयोजन को क्रमिक रूप से आज़माते हैं। वैसे, यादृच्छिक खोज लगभग और साथ ही ग्रिड खोज का काम करती है , लेकिन बहुत तेज़ी से।
- क्रॉस-चेकिंग हाइपरपरमेटर्स के चयनित संयोजन का मूल्यांकन करने का एक तरीका है। डेटा को प्रशिक्षण और परीक्षण सेट में विभाजित करने के बजाय, जो प्रशिक्षण के लिए उपलब्ध डेटा की मात्रा को कम करता है, हम k- ब्लॉक क्रॉस सत्यापन (K- फोल्ड क्रॉस वैलिडेशन) का उपयोग करेंगे। ऐसा करने के लिए, हम प्रशिक्षण डेटा को k ब्लॉकों में विभाजित करेंगे, और फिर पुनरावृत्ति प्रक्रिया को चलाएंगे, जिसके दौरान हम पहली बार k-1 ब्लॉकों पर मॉडल को प्रशिक्षित करते हैं, और फिर k-th ब्लॉक पर सीखते हुए परिणाम की तुलना करते हैं। हम प्रक्रिया को कई बार दोहराएंगे, और अंत में हमें प्रत्येक पुनरावृत्ति के लिए औसत त्रुटि मान मिलेगा। यह अंतिम मूल्यांकन होगा।
यहाँ k = 5 पर k- ब्लॉक क्रॉस-मान्यता का एक ग्राफिक चित्रण है:

संपूर्ण क्रॉस-मान्यता रैंडम खोज प्रक्रिया इस तरह दिखाई देती है:
- हम हाइपरपरमेटर्स का एक ग्रिड सेट करते हैं।
- अनियमित रूप से हाइपरपरमेटर्स के संयोजन का चयन करें।
- इस संयोजन का उपयोग करके एक मॉडल बनाएं।
- हम k- ब्लॉक क्रॉस-वैलिडेशन का उपयोग करके मॉडल के परिणाम का मूल्यांकन करते हैं।
- हम तय करते हैं कि कौन से हाइपरपामेटर्स सबसे अच्छा परिणाम देते हैं।
बेशक, यह सब मैन्युअल रूप से नहीं किया जाता है, लेकिन रैंडिटाइज़्डसर्चवीसी का उपयोग स्किकिट-लर्न से किया जाता है!
हम एक ग्रेडिएंट बूस्ट आधारित रिग्रेशन मॉडल का उपयोग करेंगे। यह एक सामूहिक विधि है, अर्थात्, मॉडल में कई "कमजोर शिक्षार्थी" होते हैं, इस मामले में, अलग-अलग निर्णय पेड़ों से। यदि छात्र
"यादृच्छिक वन" जैसे समानांतर
एल्गोरिदम में सीखते हैं, और फिर मतदान द्वारा भविष्यवाणी परिणाम का चयन किया जाता है, तो क्रमिक बूस्टिंग जैसे
एल्गोरिदम को
बढ़ावा देने में, छात्रों को क्रमिक रूप से प्रशिक्षित किया जाता है, और उनमें से प्रत्येक पूर्ववर्तियों द्वारा की गई गलतियों पर "ध्यान केंद्रित" करता है।
हाल के वर्षों में, बूस्टिंग एल्गोरिदम लोकप्रिय हो गए हैं और अक्सर मशीन सीखने की प्रतियोगिताओं में जीत हासिल करते हैं।
ग्रेडिएंट बूस्टिंग एक कार्यान्वयन है जिसमें ग्रैडिएंट डिसेंट का उपयोग फ़ंक्शन की लागत को कम करने के लिए किया जाता है। स्किकिट-लर्न में ग्रेडिएंट बूस्टिंग के कार्यान्वयन को अन्य पुस्तकालयों में उतना प्रभावी नहीं माना जाता है, उदाहरण के लिए,
XGBoost में , लेकिन यह छोटे डेटासेट पर अच्छा काम करता है और काफी सटीक पूर्वानुमान देता है।
हाइपरपरमेट्रिक सेटिंग पर वापस जाएं
ग्रेडिएंट बूस्टिंग का उपयोग करते हुए प्रतिगमन में, कई हाइपरपरमेटर्स हैं जिन्हें कॉन्फ़िगर करने की आवश्यकता है, विवरण के लिए मैं आपको स्किकिट-लर्न प्रलेखन का संदर्भ देता हूं। हम अनुकूलित करेंगे:
loss : नुकसान समारोह का कम से कम;n_estimators : उपयोग किए गए कमजोर निर्णय पेड़ों की संख्या (निर्णय पेड़);max_depth : प्रत्येक निर्णय वृक्ष की अधिकतम गहराई;min_samples_leaf : उदाहरणों की न्यूनतम संख्या जो निर्णय वृक्ष के पत्ती नोड में होनी चाहिए;min_samples_split : निर्णय ट्री नोड को विभाजित करने के लिए आवश्यक उदाहरणों की न्यूनतम संख्या;max_features : नोड्स को अलग करने के लिए उपयोग की जाने वाली सुविधाओं की अधिकतम संख्या।
सुनिश्चित नहीं है कि अगर कोई वास्तव में समझता है कि यह सब कैसे काम करता है, और सबसे अच्छा संयोजन खोजने का एकमात्र तरीका विभिन्न विकल्पों की कोशिश करना है।
इस कोड में, हम हाइपरपैरमीटर का एक ग्रिड बनाते हैं, फिर एक
RandomizedSearchCV ऑब्जेक्ट बनाते हैं और हाइपरपैरमीटर के 25 अलग-अलग संयोजनों के लिए 4-ब्लॉक क्रॉस-वेलिडेशन का उपयोग करके खोज करते हैं:
आप ग्रिड के लिए इन परिणामों का उपयोग उन ग्रिड के लिए मापदंडों का चयन करके कर सकते हैं जो इन इष्टतम मूल्यों के करीब हैं। लेकिन आगे ट्यूनिंग से मॉडल में काफी सुधार होने की संभावना नहीं है। एक सामान्य नियम है: सुविधाओं का सक्षम निर्माण सबसे महंगी हाइपरपैरेट सेटिंग की तुलना में मॉडल की सटीकता पर बहुत अधिक प्रभाव डालेगा। यह
मशीन लर्निंग के संबंध में लाभप्रदता कम करने का
नियम है : डिजाइनिंग विशेषताएँ उच्चतम प्रतिफल देती हैं, और हाइपरपरमेट्रिक ट्यूनिंग केवल मामूली लाभ लाती है।
अन्य हाइपरपैरमीटर के मूल्यों को संरक्षित करते हुए अनुमानकों (निर्णय पेड़ों) की संख्या को बदलने के लिए, एक प्रयोग किया जा सकता है जो इस सेटिंग की भूमिका को प्रदर्शित करेगा। कार्यान्वयन
यहाँ दिया गया
है , लेकिन यहाँ परिणाम है:
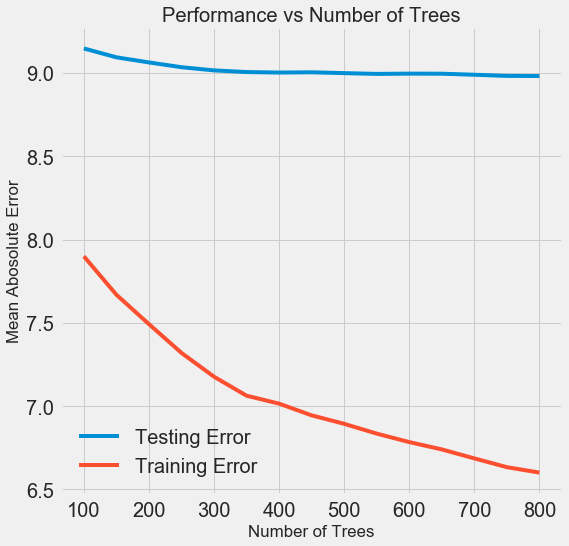
जैसे ही मॉडल द्वारा उपयोग किए जाने वाले पेड़ों की संख्या बढ़ती है, प्रशिक्षण और परीक्षण के दौरान त्रुटियों का स्तर कम हो जाता है। लेकिन सीखने की त्रुटियां बहुत तेजी से घटती हैं, और परिणामस्वरूप, मॉडल को फिर से रखा जाता है: यह प्रशिक्षण डेटा पर उत्कृष्ट परिणाम दिखाता है, लेकिन यह परीक्षण डेटा पर बदतर काम करता है।
परीक्षण डेटा पर, सटीकता हमेशा कम हो जाती है (क्योंकि मॉडल प्रशिक्षण डाटासेट के लिए सही उत्तर देखता है), लेकिन एक महत्वपूर्ण गिरावट का
संकेत देता
है ।
हाइपरपरमेटर्स का उपयोग करके प्रशिक्षण डेटा की मात्रा बढ़ाकर या
मॉडल की जटिलता को कम करके इस समस्या को हल किया जा सकता है। यहां हम हाइपरपैरामीटर पर नहीं छूएंगे, लेकिन मेरा सुझाव है कि आप हमेशा रिट्रेनिंग की समस्या पर ध्यान दें।
हमारे अंतिम मॉडल के लिए, हम 800 मूल्यांकनकर्ताओं को लेंगे, क्योंकि इससे हमें क्रॉस-वेलिडेशन में सबसे कम त्रुटि मिलेगी। अब मॉडल का परीक्षण करें!
परीक्षण डेटा का उपयोग कर आकलन
जिम्मेदार लोगों के रूप में, हमने सुनिश्चित किया कि प्रशिक्षण के दौरान किसी भी तरह से हमारे मॉडल को परीक्षण डेटा तक पहुंच प्राप्त न हो। इसलिए,
जब हम वास्तविक कार्यों में भर्ती होते हैं तो हम मॉडल गुणवत्ता
संकेतक के रूप में परीक्षण डेटा के साथ काम करते समय सटीकता का उपयोग कर सकते हैं ।
हम मॉडल परीक्षण डेटा फ़ीड करते हैं और त्रुटि की गणना करते हैं। यहाँ डिफ़ॉल्ट ढाल बूस्टिंग एल्गोरिथ्म और हमारे अनुकूलित मॉडल के परिणामों की तुलना है:
Hyperparametric ट्यूनिंग ने लगभग 10% तक मॉडल सटीकता में सुधार करने में मदद की। स्थिति के आधार पर, यह बहुत महत्वपूर्ण सुधार हो सकता है, लेकिन इसमें बहुत समय लगता है।
आप जुपिटर नोटबुक में मैजिक
%timeit टाइमिट
%timeit का उपयोग करके दोनों मॉडलों के प्रशिक्षण समय की तुलना कर सकते हैं। सबसे पहले, मॉडल की डिफ़ॉल्ट अवधि को मापें:
%%timeit -n 1 -r 5 default_model.fit(X, y) 1.09 s ± 153 ms per loop (mean ± std. dev. of 5 runs, 1 loop each)
अध्ययन के लिए एक सेकंड बहुत सभ्य है। लेकिन ट्यून्ड मॉडल इतना तेज़ नहीं है:
%%timeit -n 1 -r 5 final_model.fit(X, y) 12.1 s ± 1.33 s per loop (mean ± std. dev. of 5 runs, 1 loop each)
यह स्थिति मशीन सीखने के मूल पहलू को दर्शाती है:
यह सभी समझौता है । सटीकता और व्याख्या के बीच,
विस्थापन और फैलाव के बीच, सटीकता और संचालन समय के बीच, और इसी तरह संतुलन चुनना लगातार आवश्यक है। सही संयोजन पूरी तरह से विशिष्ट कार्य द्वारा निर्धारित किया जाता है। हमारे मामले में, सापेक्ष शब्दों में काम की अवधि में 12 गुना वृद्धि बड़ी है, लेकिन निरपेक्ष रूप से यह महत्वहीन है।
हमें अंतिम पूर्वानुमान परिणाम मिले, अब हम उनका विश्लेषण करते हैं और पता लगाते हैं कि क्या कोई ध्यान देने योग्य विचलन हैं या नहीं। बाईं ओर अनुमानित और वास्तविक मूल्यों के घनत्व का एक ग्राफ है, दाईं ओर त्रुटि का एक हिस्टोग्राम है:
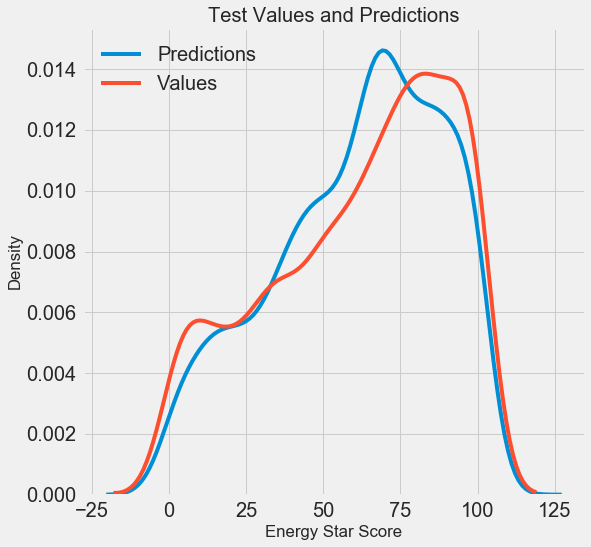

मॉडल का पूर्वानुमान वास्तविक मूल्यों के वितरण को अच्छी तरह से दोहराता है, जबकि प्रशिक्षण डेटा पर, घनत्व चोटी वास्तविक घनत्व चोटी (लगभग 100) की तुलना में औसत मूल्य (66) के करीब स्थित है। त्रुटियों का लगभग सामान्य वितरण है, हालांकि कई बड़े नकारात्मक मूल्य हैं जब मॉडल का पूर्वानुमान वास्तविक डेटा से बहुत अलग होता है। अगले लेख में, हम परिणामों की व्याख्या पर बारीकी से विचार करेंगे।
निष्कर्ष
इस लेख में, हमने मशीन लर्निंग की समस्या को हल करने के कई चरणों की जाँच की:
- लापता मूल्यों और स्केलिंग सुविधाओं में भरना।
- कई मॉडलों के परिणामों का मूल्यांकन और तुलना।
- यादृच्छिक ग्रिड खोज और क्रॉस सत्यापन का उपयोग करते हुए हाइपरपरमेट्रिक ट्यूनिंग।
- परीक्षण डेटा का उपयोग करके सर्वश्रेष्ठ मॉडल का मूल्यांकन।
परिणाम बताते हैं कि हम उपलब्ध आंकड़ों के आधार पर एनर्जी स्टार स्कोर की भविष्यवाणी करने के लिए मशीन लर्निंग का उपयोग कर सकते हैं। ग्रेडिएंट बूस्टिंग की मदद से, परीक्षण डेटा पर 9.1 की त्रुटि प्राप्त हुई। हाइपरपरमेट्रिक ट्यूनिंग परिणामों में बहुत सुधार कर सकती है, लेकिन एक महत्वपूर्ण मंदी की कीमत पर। मशीन सीखने में विचार करने के लिए यह कई ट्रेड-ऑफ में से एक है।
अगले लेख में, हम यह पता लगाने की कोशिश करेंगे कि हमारा मॉडल कैसे काम करता है। हम एनर्जी स्टार स्कोर को प्रभावित करने वाले मुख्य कारकों पर भी ध्यान देंगे। यदि हम जानते हैं कि मॉडल सटीक है, तो हम यह समझने की कोशिश करेंगे कि यह इस तरह से क्यों भविष्यवाणी करता है और यह हमें समस्या के बारे में क्या बताता है।