नमस्ते, गार्ड। आज की पोस्ट इस बारे में होगी कि मशीन लर्निंग के लिए TensorFlow का उपयोग करने और अपने लक्ष्य को प्राप्त करने के लिए विभिन्न प्रकार के विकल्पों में से किस तरह से खो जाना चाहिए। लेख को इस तरह से डिज़ाइन किया गया है कि पाठक मशीन सीखने के सिद्धांतों की मूल बातें जानता है, लेकिन अभी तक इसे अपने हाथों से करने की कोशिश नहीं की है। नतीजतन, हमें एंड्रॉइड पर एक काम करने वाला डेमो मिलता है, जो काफी उच्च सटीकता के साथ कुछ को पहचानता है। लेकिन पहले बातें पहले।

नवीनतम सामग्रियों को देखने के बाद, यह तय किया गया कि टेन्सरफ़्लो को संलग्न किया जाए , जो अब उच्च गति प्राप्त कर रहा है, और अंग्रेजी और रूसी में लेख इस में खुदाई नहीं करने और यह पता लगाने के लिए पर्याप्त है कि क्या है।
कार्यालय में दो सप्ताह, लेखों और कई पूर्व नमूनों का अध्ययन करना। साइट, मुझे एहसास हुआ कि मुझे कुछ भी समझ नहीं आया है Tensorflow का उपयोग कैसे किया जा सकता है, इस पर बहुत अधिक जानकारी और विकल्प। मेरा सिर पहले से ही सूज गया है कि वे अलग-अलग समाधानों की पेशकश करते हैं और उनके साथ क्या करना है, जैसा कि मेरे कार्य पर लागू होता है।

तब मैंने सबसे सरल और सबसे अधिक तैयार किए गए विकल्पों में से सब कुछ आज़माने का फैसला किया (जिसमें मुझे ग्रेड में एक निर्भरता दर्ज करने और कोड की कुछ पंक्तियों को जोड़ने की आवश्यकता थी) अधिक जटिल लोगों के लिए (जिसमें मुझे स्वयं ग्राफ मॉडल बनाने और प्रशिक्षित करना होगा और उन्हें मोबाइल में उपयोग करना सीखना होगा। परिशिष्ट)।
अंत में, मुझे एक जटिल संस्करण का उपयोग करना पड़ा, जिस पर नीचे और अधिक विस्तार से चर्चा की जाएगी। इस बीच, मैंने आपके लिए सरल विकल्पों की एक सूची तैयार की है जो समान रूप से प्रभावी हैं, बस हर एक अपने उद्देश्य के अनुरूप है।

उपयोग करने का सबसे आसान समाधान - कोड की कुछ पंक्तियाँ जिनका आप उपयोग कर सकते हैं:
- पाठ पहचान (पाठ, लैटिन वर्ण)
- चेहरा पहचानना (चेहरे, भावनाएं)
- बारकोड स्कैनिंग (बारकोड, qr कोड)
- छवि लेबलिंग (छवि में वस्तुओं की एक सीमित संख्या)
- ऐतिहासिक पहचान (आकर्षण)
यह थोड़ा और अधिक जटिल है। इस समाधान के साथ, आप अपने खुद के TensorFlow Lite मॉडल का भी उपयोग कर सकते हैं, लेकिन इस प्रारूप में परिवर्तित होने से कठिनाइयाँ होती हैं, इसलिए इस आइटम को आज़माया नहीं गया है।
जैसा कि इस वंश के निर्माता लिखते हैं, इन कार्यों का उपयोग करके अधिकांश कार्यों को हल किया जा सकता है। लेकिन अगर यह आपके कार्य पर लागू नहीं होता है, तो आपको कस्टम मॉडल का उपयोग करना होगा।

छवियों का उपयोग करके अपने कस्टम मॉडल बनाने और प्रशिक्षण के लिए एक बहुत सुविधाजनक उपकरण।
पेशेवरों से - एक मुफ्त संस्करण है जो आपको एक परियोजना रखने की अनुमति देता है।
विपक्ष की - मुक्त संस्करण "आने वाली" छवियों की संख्या को 3,000 तक सीमित करता है। कोशिश करना और सटीकता का औसत दर्जे का नेटवर्क बनाना - यही काफी है। अधिक सटीक कार्यों के लिए, आपको और अधिक की आवश्यकता है।
उपयोगकर्ता को जो कुछ भी आवश्यक है, वह चिह्नित छवियों को जोड़ना है (उदाहरण के लिए - छवि 1 "रेसून" है, छवि 2 "सूरज" है), भविष्य के उपयोग के लिए ग्राफ को प्रशिक्षित और निर्यात करें।
Microsoft की देखभाल का अपना नमूना भी है , जिसके साथ आप अपने प्राप्त ग्राफ़ को आज़मा सकते हैं।
उन लोगों के लिए जो पहले से ही "विषय में" हैं - ग्राफ पहले से ही जमे हुए राज्य में उत्पन्न होता है, अर्थात। आपको इसके साथ कुछ भी करने / परिवर्तित करने की आवश्यकता नहीं है।
यह समाधान अच्छा है जब आपके पास प्रशिक्षण में विभिन्न वर्गों का एक बड़ा नमूना और (ध्यान) बहुत है। क्योंकि अन्यथा व्यवहार में कई गलत परिभाषाएँ होंगी। उदाहरण के लिए, आपने रैकून और सूर्य पर प्रशिक्षण दिया, और यदि कोई व्यक्ति प्रवेश द्वार पर है, तो वह समान संभावना के साथ इस तरह की प्रणाली को एक या दूसरे के रूप में परिभाषित कर सकता है। हालांकि वास्तव में - न तो कोई और न ही।
3. मैन्युअल रूप से एक मॉडल बनाना

जब आपको छवि पहचान के लिए मॉडल को ठीक से ट्यून करने की आवश्यकता होती है, तो इनपुट छवि चयन के साथ और अधिक जटिल जोड़-तोड़ खेलने में आते हैं।
उदाहरण के लिए, हम इनपुट नमूने की मात्रा (पिछले पैराग्राफ में) पर प्रतिबंध नहीं लगाना चाहते हैं, या हम खुद को युग और अन्य प्रशिक्षण मापदंडों की संख्या निर्धारित करके मॉडल को अधिक सटीक रूप से प्रशिक्षित करना चाहते हैं।
इस दृष्टिकोण में, तेंसोरफ्लो से कई उदाहरण हैं जो प्रक्रिया और अंतिम परिणाम का वर्णन करते हैं।
यहाँ कुछ उदाहरण हैं:
यह एक उदाहरण देता है कि छवियों के खुले इमेजनेट डेटाबेस के आधार पर रंग प्रकारों का एक वर्गीकरण कैसे बनाया जाए - चित्र तैयार करें, और फिर मॉडल को प्रशिक्षित करें। इसके अलावा थोड़ा सा उल्लेख है कि आप एक दिलचस्प उपकरण के साथ कैसे काम कर सकते हैं - टेंसोरबोर्ड। अपने सरलतम कार्यों में से - यह आपके तैयार मॉडल की संरचना को स्पष्ट रूप से प्रदर्शित करता है, साथ ही साथ कई तरीकों से सीखने की प्रक्रिया भी करता है।
कवियों 2 के लिए कोडलैब टेंसरफ़्लो - रंग वर्गीकरण के साथ काम जारी रखा। यह दिखाता है कि यदि आपके पास ग्राफ़ फ़ाइलें और उसके लेबल (जो पिछले कोडलैब में प्राप्त किए गए थे), आप एंड्रॉइड पर एप्लिकेशन कैसे चला सकते हैं। कोडलैब के बिंदुओं में से एक "सामान्य" ग्राफ प्रारूप ".pb" से टेंसोरफ्लो लाइट प्रारूप में रूपांतरण है (जिसमें अंतिम ग्राफ़ फ़ाइल आकार को कम करने के लिए कुछ फ़ाइल अनुकूलन शामिल हैं, क्योंकि मोबाइल उपकरणों को इसकी आवश्यकता होती है)।
लिखावट मान्यता MNIST ।
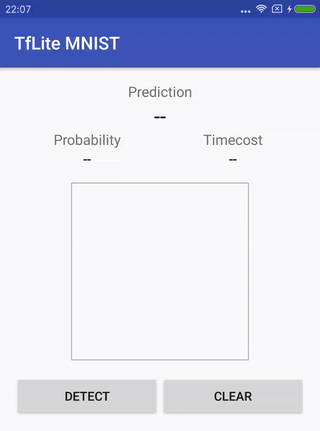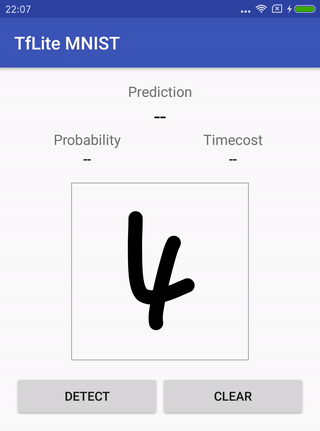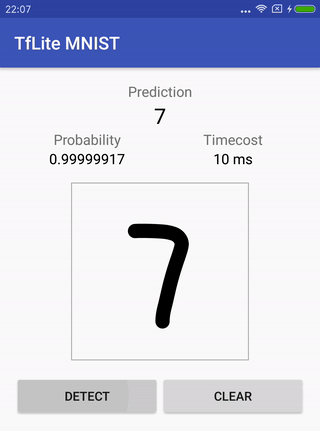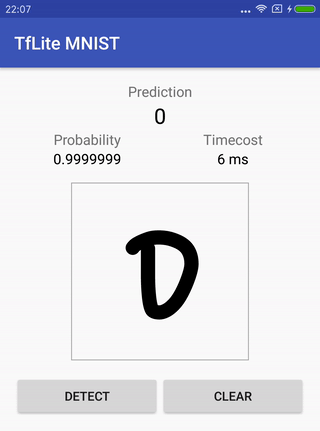
शलजम में मूल मॉडल होता है (जो इस कार्य के लिए पहले से ही तैयार किया गया है), इसे कैसे प्रशिक्षित किया जाए, इसे रूपांतरित करने के लिए निर्देश, और यह कैसे काम करता है, यह जांचने के लिए अंत में एंड्रॉइड के लिए प्रोजेक्ट कैसे चलाएं
इन उदाहरणों के आधार पर, आप यह पता लगा सकते हैं कि टेन्सरफ़्लो में कस्टम मॉडल के साथ कैसे काम किया जाए और या तो अपना खुद का बनाने की कोशिश करें या एक पूर्व-प्रशिक्षित मॉडल लें, जिसे गिथब पर इकट्ठा किया जाए:
Tensorflow से मॉडल
"पूर्व-प्रशिक्षित" मॉडल की बात करना। उन का उपयोग करते समय दिलचस्प बारीकियों:
- उनकी संरचना पहले से ही एक विशिष्ट कार्य के लिए तैयार है।
- वे पहले से ही बड़े नमूना आकारों में प्रशिक्षित हैं।
इसलिए, यदि आपका नमूना अपर्याप्त रूप से भरा हुआ है, तो आप एक पूर्व-प्रशिक्षित मॉडल ले सकते हैं जो आपके कार्य के दायरे के करीब है। इस मॉडल का उपयोग करते हुए, अपने स्वयं के प्रशिक्षण नियमों को जोड़ने से, आपको एक बेहतर परिणाम मिलेगा, जिससे आप मॉडल को खरोंच से प्रशिक्षित करने का प्रयास करेंगे।
4. ऑब्जेक्ट डिटेक्शन एपीआई + मैनुअल मॉडल निर्माण
हालांकि, पिछले सभी पैराग्राफ ने वांछित परिणाम नहीं दिया था। शुरुआत से ही यह समझना मुश्किल था कि क्या किया जाना चाहिए और किस दृष्टिकोण के साथ। तब ऑब्जेक्ट डिटेक्शन एपीआई पर एक अच्छा लेख पाया गया, जो बताता है कि एक छवि पर कई श्रेणियों को कैसे खोजना है, साथ ही एक ही श्रेणी के कई उदाहरण भी हैं। इस नमूने पर काम करने की प्रक्रिया में, कस्टम वस्तुओं को पहचानने पर स्रोत लेख और वीडियो ट्यूटोरियल अधिक सुविधाजनक हो गए हैं (लिंक अंत में होंगे)।
लेकिन पिकाचु मान्यता पर एक लेख के बिना काम पूरा नहीं हो सकता था - क्योंकि वहां एक बहुत ही महत्वपूर्ण बारीकियों को इंगित किया गया था, जो किसी कारण से एक गाइड या उदाहरण में कहीं भी उल्लेख नहीं किया गया है। और इसके बिना, किए गए सभी कार्य व्यर्थ होंगे।
तो, अब अंत में क्या अभी भी किया जाना था और बाहर के रास्ते पर क्या हुआ।
- सबसे पहले, Tensorflow स्थापना का आटा। जो इसे स्थापित नहीं कर सकता, या एक मॉडल बनाने, प्रशिक्षित करने के लिए मानक स्क्रिप्ट का उपयोग कर सकता है - बस रोगी और Google रहें। लगभग हर समस्या पहले से ही गितिब पर या स्टैकओवरफ़्लो पर मुद्दों में लिखी गई है।
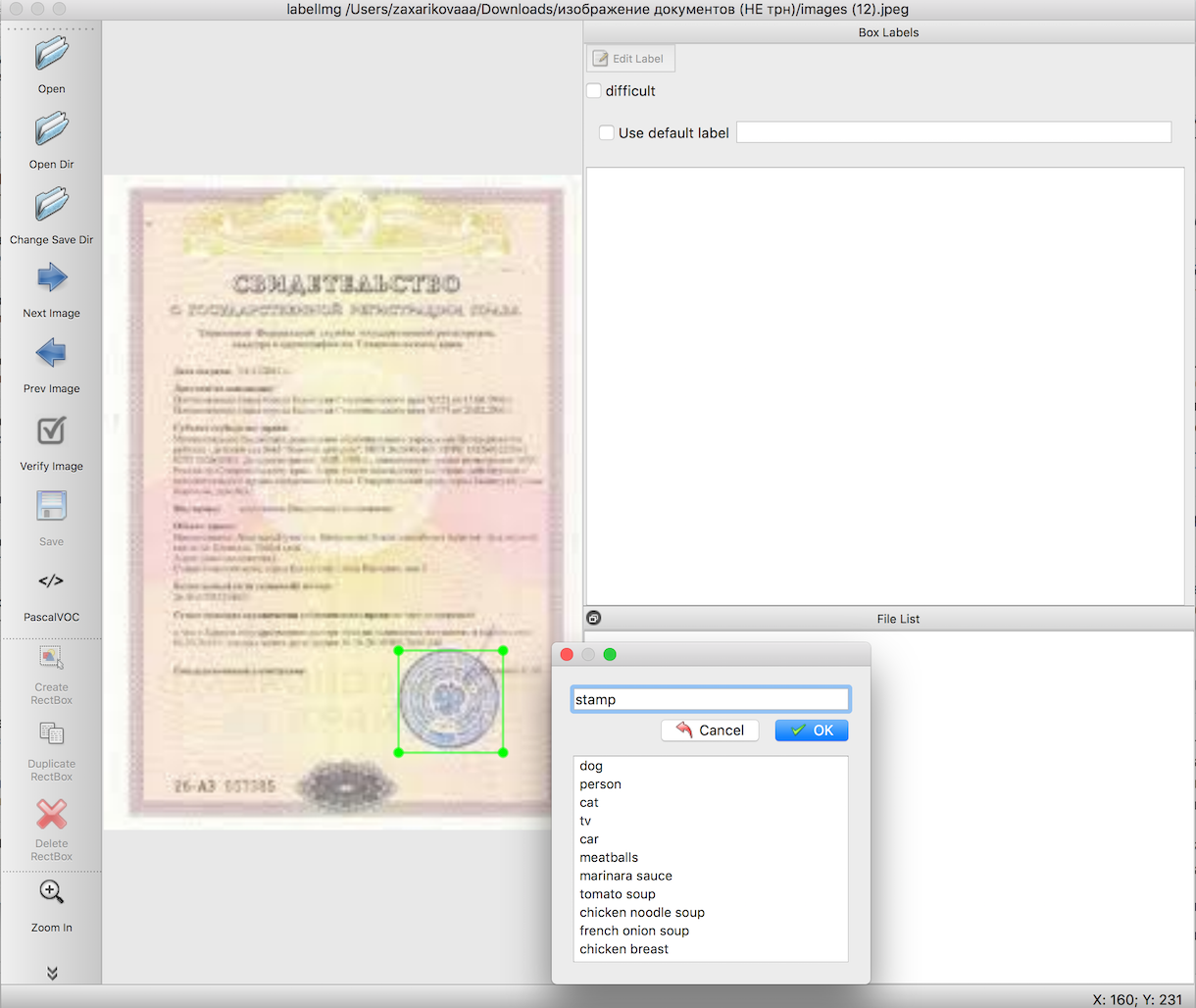
ऑब्जेक्ट मान्यता के निर्देशों के अनुसार, हमें मॉडल को प्रशिक्षित करने से पहले एक इनपुट नमूना तैयार करना होगा। इन लेखों में विस्तार से वर्णन किया गया है कि यह कैसे करना है एक सुविधाजनक उपकरण का उपयोग करके - labelImg। यहां एकमात्र कठिनाई यह है कि हमें जिन वस्तुओं की आवश्यकता है, उनकी सीमाओं को उजागर करने पर एक बहुत लंबा और सावधानीपूर्वक काम करना है। इस मामले में, दस्तावेजों की छवियों पर टिकटें।
अगला चरण, तैयार लिपियों का उपयोग करते हुए, हम चरण 2 से डेटा को पहले csv फ़ाइलों में निर्यात करते हैं, फिर TFRecords - Tensorflow input data format में। यहां कोई कठिनाई पैदा नहीं होनी चाहिए।
एक पूर्व-प्रशिक्षित मॉडल का विकल्प, जिसके आधार पर हम ग्राफ को पूर्व-प्रशिक्षित करेंगे, साथ ही प्रशिक्षण भी। यह वह जगह है जहां सबसे बड़ी संख्या में अज्ञात त्रुटियां हो सकती हैं, जिसका कारण काम के लिए आवश्यक अनइंस्टॉल (या कुटिल रूप से स्थापित) पैकेज हैं। लेकिन आप सफल होंगे, निराशा न करें, परिणाम इसके लायक है।

'Pb' प्रारूप में प्रशिक्षण के बाद प्राप्त फ़ाइल को निर्यात करें। बस अंतिम फ़ाइल 'ckpt' चुनें और इसे निर्यात करें।
एंड्रॉइड पर काम का एक उदाहरण चल रहा है।
Tensorflow github -
TF डिटेक्ट से आधिकारिक वस्तु मान्यता नमूना डाउनलोड करना। वहां अपना मॉडल डालें और लेबल लगाएं। लेकिन। कुछ नहीं चलेगा।

यह वह जगह है जहां सभी कामों में सबसे बड़ा गैग बस हुआ, अजीब तरह से पर्याप्त - अच्छी तरह से, टेंसरफ्लो के नमूने किसी भी तरह से काम नहीं करना चाहते थे। सब कुछ गिर गया है। केवल अपने लेख के साथ शक्तिशाली पिकाचु सब कुछ लाने में मदद करने में कामयाब रहा।
Label.txt फ़ाइल में पहली पंक्ति शिलालेख "???" होना चाहिए, क्योंकि ऑब्जेक्ट डिटेक्शन एपीआई में डिफ़ॉल्ट रूप से, ऑब्जेक्ट्स की आईडी संख्या हमेशा की तरह 0 से शुरू नहीं होती है, लेकिन 1. इस तथ्य के कारण कि शून्य वर्ग आरक्षित है, जादू के सवालों का संकेत दिया जाना चाहिए। यानी आपकी टैग फ़ाइल कुछ इस तरह दिखाई देगी:
??? stamp
और फिर - नमूना चलाएं और वस्तुओं की मान्यता और विश्वास का स्तर देखें जिसके साथ इसे प्राप्त किया गया था।
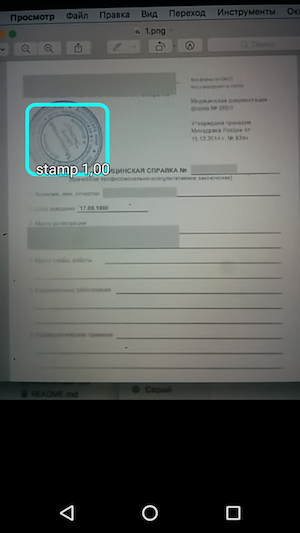
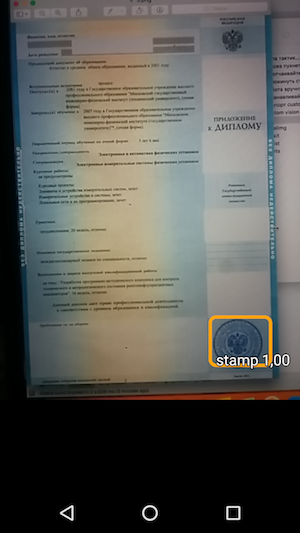
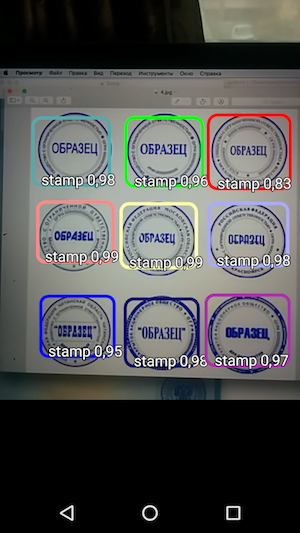
इस प्रकार, परिणाम एक सरल अनुप्रयोग है, जब आप कैमरे पर मंडराते हैं, तो दस्तावेज़ पर स्टैम्प सीमा को पहचानता है और मान्यता सटीकता के साथ उन्हें इंगित करता है।
और अगर हम उस समय को छोड़ दें जो सही दृष्टिकोण की खोज में लगा था और इसे लॉन्च करने की कोशिश कर रहा था, तो, पूरे पर, काम बहुत जल्दी हो गया और वास्तव में जटिल नहीं था। बस आपको काम शुरू करने से पहले बारीकियों को जानना होगा।
पहले से ही एक अतिरिक्त अनुभाग के रूप में (यहां आप पहले से ही लेख को बंद कर सकते हैं यदि आप जानकारी से थक गए हैं), मैं कुछ जीवन हैक्स लिखना चाहूंगा जिन्होंने इस सब के साथ काम करने में मदद की।
बहुत बार टेंसरफ्लो स्क्रिप्ट काम नहीं करती थी क्योंकि वे गलत निर्देशिकाओं से चलाई जाती थीं। इसके अलावा, यह अलग-अलग पीसी पर अलग था: कुछ को काम के लिए tensroflowmodels/models/research निर्देशिका से चलाने की आवश्यकता थी, और कुछ को tensroflowmodels/models/research/object-detection से गहरे स्तर की आवश्यकता थी
याद रखें कि प्रत्येक खुले टर्मिनल के लिए आपको कमांड का उपयोग करके फिर से पथ निर्यात करने की आवश्यकता है
export PYTHONPATH=/ /tensroflowmodels/models/research/slim:$PYTHONPATH
यदि आप अपने स्वयं के ग्राफ का उपयोग नहीं कर रहे हैं और इसके बारे में जानकारी प्राप्त करना चाहते हैं (उदाहरण के लिए, " input_node_name ", जो काम करते समय भविष्य में आवश्यक है), रूट फ़ोल्डर से दो कमांड चलाएं:
bazel build tensorflow/tools/graph_transforms:summarize_graph bazel-bin/tensorflow/tools/graph_transforms/summarize_graph --in_graph="/ /frozen_inference_graph.pb"
जहाँ " / /frozen_inference_graph.pb " उस ग्राफ़ के लिए पथ है जिसके बारे में आप जानना चाहते हैं
ग्राफ के बारे में जानकारी देखने के लिए, आप Tensorboard का उपयोग कर सकते हैं।
python import_pb_to_tensorboard.py --model_dir=output/frozen_inference_graph.pb --log_dir=training
जहाँ आपको ग्राफ़ ( model_dir ) और प्रशिक्षण के दौरान प्राप्त फ़ाइलों के लिए पथ ( model_dir ) निर्दिष्ट करना होगा। फिर बस ब्राउज़र में लोकलहोस्ट खोलें और देखें कि आपकी क्या रुचि है।
और अंतिम भाग - ऑब्जेक्ट डिटेक्शन एपीआई निर्देशों में अजगर लिपियों के साथ काम करने पर - कमांड और सुझावों के साथ नीचे एक छोटी सी चीट शीट आपके लिए तैयार की गई है।
धोखा की चादरलेबलिमग से सीएसवी को निर्यात करें (ऑब्जेक्ट_डाइट डायरेक्टरी से)
python xml_to_csv.py
इसके अलावा, नीचे सूचीबद्ध सभी चरणों को एक ही टेन्सरफ़्लो फ़ोल्डर (" tensroflowmodels/models/research/object-detection " या एक स्तर ऊपर - जो आप कैसे जाते हैं, उसके आधार पर) से किया जाना चाहिए। काम शुरू करने से पहले इनपुट चयन, TFRecords, और अन्य फ़ाइलों की छवियों को इस निर्देशिका के अंदर कॉपी किया जाना चाहिए।
Csv से tfrecord में निर्यात करें
python generate_tfrecord.py --csv_input=data/train_labels.csv --output_path=data/train.record python generate_tfrecord.py --csv_input=data/test_labels.csv --output_path=data/test.record
* फ़ाइल में ही पथ में 'ट्रेन' और 'परीक्षण' लाइनों को बदलना न भूलें (जनरेट_टर्फेर्डहोम), साथ ही
class_text_to_int फ़ंक्शन में मान्यता प्राप्त कक्षाओं का नाम (जो pbtxt फ़ाइल में डुप्लिकेट होना चाहिए जिसे आप ग्राफ़ को प्रशिक्षित करने से पहले बनाएंगे)।
ट्रेनिंग
python legacy/train.py —logtostderr --train_dir=training/ --pipeline_config_path=training/ssd_mobilenet_v1_coco.config
** प्रशिक्षण से पहले, फ़ाइल को " training/object-detection.pbtxt training/ssd_mobilenet_v1_coco.config " चेक करना न भूलें - सभी मान्यता प्राप्त कक्षाएं होनी चाहिए और फ़ाइल " training/ssd_mobilenet_v1_coco.config " होनी चाहिए - वहां आपको अपनी कक्षाओं की संख्या में पैरामीटर " num_classes " को बदलने की आवश्यकता है।
निर्यात मॉडल को पी.बी.
python export_inference_graph.py \ --input_type=image_tensor \ --pipeline_config_path=training/pipeline.config \ --trained_checkpoint_prefix=training/model.ckpt-110 \ --output_directory=output
इस विषय में आपकी रुचि के लिए धन्यवाद!
संदर्भ
- वस्तु मान्यता पर मूल लेख
- अंग्रेजी में वस्तुओं की मान्यता पर लेख के लिए वीडियो का एक चक्र
- मूल लेख में उपयोग किए गए स्क्रिप्ट का सेट