Guess.js के पूर्वानुमान
मॉडल के लिए सुधारों के साथ प्रयोग करते हुए, मैंने गहन शिक्षण को करीब से देखना शुरू किया: आवर्तक तंत्रिका नेटवर्क (RNN), विशेष रूप से LSTM में, क्षेत्र में उनके
"अनुचित प्रभाव" के कारण जहां Guess.js काम करता है। उसी समय, मैंने कन्वेन्शनल न्यूरल नेटवर्क (CNNs) के साथ खेलना शुरू कर दिया, जिसका उपयोग अक्सर समय श्रृंखला के लिए भी किया जाता है। सीएनएन आमतौर पर छवियों को वर्गीकृत करने, पहचानने और पता लगाने के लिए उपयोग किया जाता है।
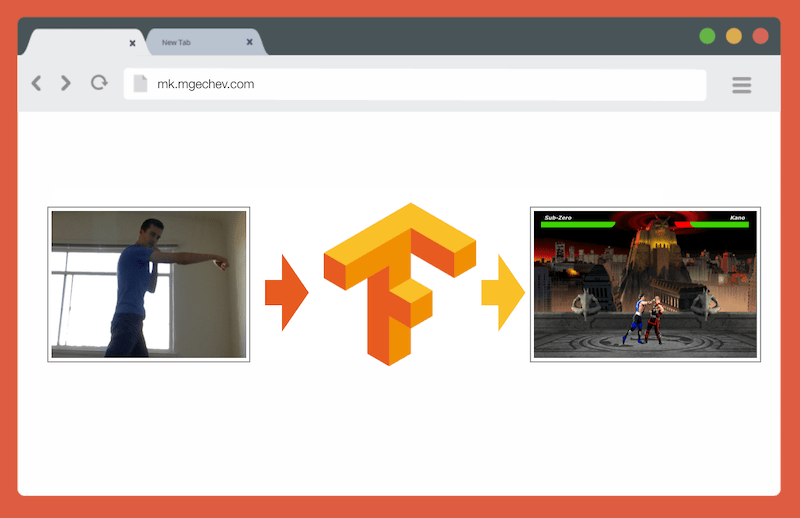 TensorFlow.js के साथ MK.js का प्रबंधन करना
TensorFlow.js के साथ MK.js का प्रबंधन करनाइस लेख और MK.js का स्रोत कोड मेरे GitHub पर है । मैंने एक प्रशिक्षण डाटासेट पोस्ट नहीं किया है, लेकिन आप अपना स्वयं का निर्माण कर सकते हैं और नीचे वर्णित मॉडल को प्रशिक्षित कर सकते हैं!
CNN के साथ खेलने के बाद, मुझे एक
प्रयोग याद आया जो मैंने कई साल पहले किया था जब ब्राउज़र डेवलपर्स ने
getUserMedia API जारी किया था। इसमें, उपयोगकर्ता का कैमरा नश्वर कॉम्बैट 3 के छोटे जावास्क्रिप्ट क्लोन को चलाने के लिए एक नियंत्रक के रूप में कार्य करता है। आप उस गेम
को गिटहब रिपॉजिटरी में पा सकते हैं। प्रयोग के भाग के रूप में, मैंने एक बुनियादी पोजिशनिंग एल्गोरिथ्म लागू किया जो छवि को निम्न वर्गों में वर्गीकृत करता है:
- बाएँ या दाएँ पंच
- बाएँ या दाएँ किक
- बाएँ और दाएँ कदम
- बैठने
- उपरोक्त में से कोई नहीं
एल्गोरिथ्म इतना सरल है कि मैं इसे कुछ वाक्यों में समझा सकता हूं:
एल्गोरिथ्म पृष्ठभूमि की तस्वीरें। जैसे ही उपयोगकर्ता फ़्रेम में दिखाई देता है, एल्गोरिथ्म उपयोगकर्ता के साथ पृष्ठभूमि और वर्तमान फ्रेम के बीच अंतर की गणना करता है। तो यह उपयोगकर्ता के आंकड़े की स्थिति निर्धारित करता है। अगला कदम उपयोगकर्ता के शरीर को काले रंग में सफेद में प्रदर्शित करना है। उसके बाद, ऊर्ध्वाधर और क्षैतिज हिस्टोग्राम बनाए जाते हैं, प्रत्येक पिक्सेल के लिए मानों को जोड़ते हैं। इस गणना के आधार पर, एल्गोरिथ्म शरीर की वर्तमान स्थिति को निर्धारित करता है।
वीडियो दिखाता है कि कार्यक्रम कैसे काम करता है।
GitHub स्रोत कोड।
यद्यपि छोटे एमके क्लोन ने सफलतापूर्वक काम किया, एल्गोरिथ्म परिपूर्ण से बहुत दूर है। एक पृष्ठभूमि के साथ एक फ्रेम की आवश्यकता है। उचित संचालन के लिए, कार्यक्रम के निष्पादन के दौरान पृष्ठभूमि समान रंग होनी चाहिए। इस तरह की सीमा का मतलब है कि प्रकाश, छाया और अन्य चीजों में परिवर्तन हस्तक्षेप करेगा और एक गलत परिणाम देगा। अंत में, एल्गोरिथ्म कार्रवाई को नहीं पहचानता है; वह केवल नए फ्रेम को पूर्वनिर्धारित सेट से शरीर की स्थिति के रूप में वर्गीकृत करता है।
अब, वेब एपीआई में प्रगति के लिए धन्यवाद, अर्थात् WebGL, मैंने TensorFlow.js को लागू करके इस कार्य पर लौटने का फैसला किया।
परिचय
इस लेख में, मैं TensorFlow.js और MobileNet का उपयोग करके शरीर की स्थिति को वर्गीकृत करने के लिए एक एल्गोरिथ्म बनाने में अपना अनुभव साझा करूंगा। निम्नलिखित विषयों पर विचार करें:
- छवि वर्गीकरण के लिए प्रशिक्षण डेटा का संग्रह
- इमेग के साथ डेटा ऑगमेंटेशन
- मोबाइलनेट के साथ लर्निंग ट्रांसफर
- बाइनरी वर्गीकरण और एन-प्राथमिक वर्गीकरण
- TodeorFlow.js छवि वर्गीकरण मॉडल को Node.js में प्रशिक्षित करना और एक ब्राउज़र में इसका उपयोग करना
- LSTM के साथ क्रियाओं को वर्गीकृत करने के बारे में कुछ शब्द
इस लेख में, हम फ्रेम के अनुक्रम द्वारा कार्यों को पहचानने के विपरीत, एक फ्रेम के आधार पर शरीर की स्थिति का निर्धारण करने के लिए समस्या को कम करेंगे। हम एक शिक्षक के साथ गहन सीखने का एक मॉडल विकसित करेंगे, जो उपयोगकर्ता के वेब कैमरा से छवि के आधार पर, एक व्यक्ति के आंदोलनों को निर्धारित करता है: किक, पैर, या इनमें से कोई भी नहीं।
लेख के अंत तक, हम
MK.js खेलने के लिए एक मॉडल बनाने में सक्षम
होंगे :

लेख की बेहतर समझ के लिए, पाठक को प्रोग्रामिंग और जावास्क्रिप्ट की मूलभूत अवधारणाओं से परिचित होना चाहिए। गहरी सीखने की एक बुनियादी समझ भी उपयोगी है, लेकिन आवश्यक नहीं है।
डेटा संग्रह
गहन शिक्षण मॉडल की सटीकता डेटा की गुणवत्ता पर अत्यधिक निर्भर है। हमें उत्पादन के रूप में एक व्यापक डेटा सेट एकत्र करने का प्रयास करने की आवश्यकता है।
हमारे मॉडल को छिद्रों और किक को पहचानने में सक्षम होना चाहिए। इसका मतलब है कि हमें तीन श्रेणियों की छवियां एकत्र करनी चाहिए:
इस प्रयोग में, दो स्वयंसेवकों (
@lili_vs और
@gsamokovarov ) ने मुझे तस्वीरें एकत्र करने में मदद की। हमने अपने मैकबुक प्रो पर 5 क्विक वीडियो रिकॉर्ड किए, जिनमें से प्रत्येक में 2-4 किक और 2-4 किक शामिल थे।
तब हम वीडियो से अलग-अलग फ्रेम निकालने के लिए ffmpeg का उपयोग करते हैं और उन्हें
jpg चित्र के रूप में सहेजते हैं:
ffmpeg -i video.mov $filename%03d.jpgउपरोक्त कमांड को निष्पादित करने के लिए, आपको पहले कंप्यूटर पर
ffmpeg स्थापित करना होगा ।
यदि हम मॉडल को प्रशिक्षित करना चाहते हैं, तो हमें इनपुट डेटा और संबंधित आउटपुट डेटा प्रदान करना होगा, लेकिन इस स्तर पर हमारे पास केवल तीन लोगों की छवियों का एक समूह है। डेटा की संरचना करने के लिए, आपको तीन श्रेणियों में फ्रेम को वर्गीकृत करने की आवश्यकता है: घूंसे, किक और अन्य। प्रत्येक श्रेणी के लिए, एक अलग निर्देशिका बनाई जाती है, जहां सभी संबंधित छवियों को स्थानांतरित किया जाता है।
इस प्रकार, प्रत्येक निर्देशिका में नीचे की तरह लगभग 200 छवियां होनी चाहिए:

कृपया ध्यान दें कि दूसरों की निर्देशिका में बहुत अधिक छवियां होंगी, क्योंकि अपेक्षाकृत कुछ फ़्रेमों में घूंसे और किक की तस्वीरें होती हैं, और शेष फ़्रेमों में लोग चलते हैं, चारों ओर मुड़ते हैं या वीडियो को नियंत्रित करते हैं। यदि हमारे पास एक वर्ग की बहुत अधिक छवियां हैं, तो हम इस विशेष वर्ग के प्रति पक्षपाती मॉडल को पढ़ाने का जोखिम उठाते हैं। इस मामले में, जब किसी छवि को एक प्रभाव के साथ वर्गीकृत किया जाता है, तो तंत्रिका नेटवर्क अभी भी "अन्य" वर्ग का निर्धारण कर सकता है। इस पूर्वाग्रह को कम करने के लिए, आप दूसरों की निर्देशिका से कुछ तस्वीरें निकाल सकते हैं और प्रत्येक श्रेणी से समान संख्या में छवियों पर मॉडल को प्रशिक्षित कर सकते हैं।
सुविधा के लिए, हम
1 से
190 तक कैटलॉग की संख्याओं को असाइन करते हैं, इसलिए पहली छवि
1.jpg , दूसरी
2.jpg , आदि होगी।
यदि हम एक ही वातावरण में समान लोगों के साथ ली गई केवल 600 तस्वीरों में मॉडल को प्रशिक्षित करते हैं, तो हम बहुत उच्च स्तर की सटीकता हासिल नहीं करेंगे। हमारे डेटा का अधिकतम लाभ उठाने के लिए, डेटा संवर्द्धन का उपयोग करके कुछ अतिरिक्त नमूने उत्पन्न करना सर्वोत्तम है।
डेटा ऑगमेंटेशन
डेटा ऑगमेंटेशन एक ऐसी तकनीक है जो मौजूदा सेट से नए बिंदुओं को संश्लेषित करके डेटा बिंदुओं की संख्या बढ़ाती है। आमतौर पर, प्रशिक्षण सेट के आकार और विविधता को बढ़ाने के लिए वृद्धि का उपयोग किया जाता है। हम नई छवियों को बनाने वाले परिवर्तनों की पाइपलाइन में मूल छवियों को स्थानांतरित करते हैं। आप परिवर्तनों को बहुत आक्रामक तरीके से नहीं कर सकते हैं: केवल दूसरे हाथ के घूंसे एक पंच से उत्पन्न होने चाहिए।
स्वीकार्य परिवर्तन रोटेशन, रंग उलटा, धुंधला आदि हैं। डेटा वृद्धि के लिए उत्कृष्ट खुला स्रोत उपकरण हैं। जावास्क्रिप्ट में इस लेख को लिखने के समय, बहुत अधिक विकल्प नहीं थे, इसलिए मैंने पायथन में लागू पुस्तकालय -
इमोगुग का उपयोग किया । इसमें संवर्धितों का एक समूह है जिसे संभावित रूप से लागू किया जा सकता है।
इस प्रयोग के लिए डेटा वृद्धि तर्क यहाँ दिया गया है:
np.random.seed(44) ia.seed(44) def main(): for i in range(1, 191): draw_single_sequential_images(str(i), "others", "others-aug") for i in range(1, 191): draw_single_sequential_images(str(i), "hits", "hits-aug") for i in range(1, 191): draw_single_sequential_images(str(i), "kicks", "kicks-aug") def draw_single_sequential_images(filename, path, aug_path): image = misc.imresize(ndimage.imread(path + "/" + filename + ".jpg"), (56, 100)) sometimes = lambda aug: iaa.Sometimes(0.5, aug) seq = iaa.Sequential( [ iaa.Fliplr(0.5),
यह स्क्रिप्ट लूप के
for तीन
for साथ
main विधि का उपयोग करती है - प्रत्येक छवि श्रेणी के लिए। प्रत्येक पुनरावृत्ति में, प्रत्येक लूप में, हम
draw_single_sequential_images विधि कहते हैं: पहला तर्क फ़ाइल का नाम है, दूसरा पथ है, तीसरा वह निर्देशिका है जहां परिणाम को सहेजना है।
उसके बाद, हम डिस्क से छवि को पढ़ते हैं और इसमें परिवर्तनों की एक श्रृंखला लागू करते हैं। मैंने उपरोक्त कोड स्निपेट में अधिकांश परिवर्तनों का दस्तावेजीकरण किया है, इसलिए हम इसे नहीं दोहराएंगे।
प्रत्येक छवि के लिए, 16 अन्य चित्र बनाए जाते हैं। यहाँ एक उदाहरण है कि वे कैसे दिखते हैं:

कृपया ध्यान दें कि उपरोक्त स्क्रिप्ट में हम छवियों को
100x56 पिक्सेल तक
100x56 करते हैं। हम डेटा की मात्रा को कम करने के लिए ऐसा करते हैं और तदनुसार, प्रशिक्षण और मूल्यांकन के दौरान हमारे मॉडल की गणना की संख्या।
मॉडल बिल्डिंग
अब वर्गीकरण के लिए एक मॉडल बनाएं!
चूंकि हम छवियों के साथ काम कर रहे हैं, इसलिए हम एक संवेदी तंत्रिका नेटवर्क (CNN) का उपयोग करते हैं। यह नेटवर्क आर्किटेक्चर छवि पहचान, वस्तु पहचान और वर्गीकरण के लिए उपयुक्त माना जाता है।
लर्निंग ट्रांसफर
नीचे दी गई छवि लोकप्रिय सीएनएन वीजीजी -16 दिखाती है, जिसका उपयोग छवियों को वर्गीकृत करने के लिए किया जाता है।
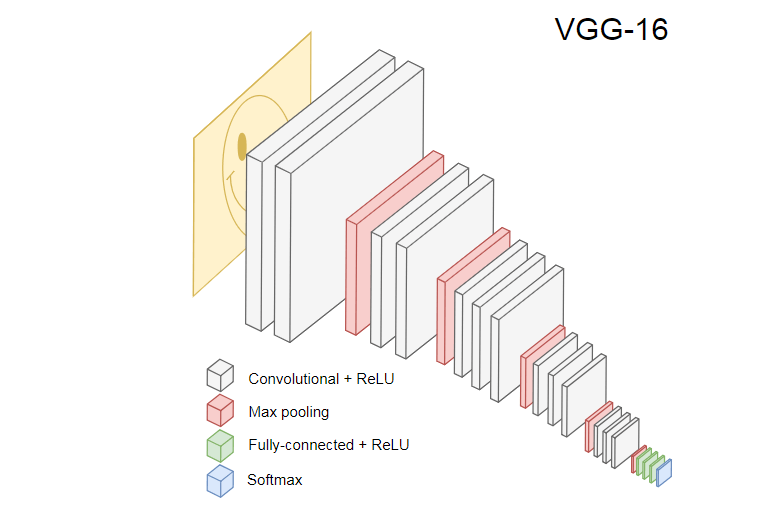
VGG-16 न्यूरल नेटवर्क 1000 छवि वर्गों को पहचानता है। इसमें 16 लेयर्स हैं (पूलिंग और आउटपुट लेयर्स की गिनती नहीं)। इस तरह के एक बहुपरत नेटवर्क को अभ्यास में प्रशिक्षित करना मुश्किल है। इसके लिए एक बड़े डेटा सेट और कई घंटों के प्रशिक्षण की आवश्यकता होगी।
प्रशिक्षित सीएनएन की छिपी परतें प्रशिक्षण सेट से छवियों के विभिन्न तत्वों को पहचानती हैं, जो किनारों से शुरू होकर अधिक जटिल तत्वों, जैसे आकार, व्यक्तिगत वस्तुओं और इतने पर चलती हैं। छवियों के एक बड़े सेट को पहचानने के लिए वीजीजी -16 की शैली में प्रशिक्षित सीएनएन में छिपी हुई परतें होनी चाहिए जिन्होंने प्रशिक्षण सेट से बहुत सारी विशेषताएं सीखी हैं। ऐसी विशेषताएं अधिकांश छवियों के लिए सामान्य होंगी और तदनुसार, विभिन्न कार्यों में पुन: उपयोग किया जाएगा।
लर्निंग ट्रांसफर आपको मौजूदा और प्रशिक्षित नेटवर्क का पुन: उपयोग करने की अनुमति देता है। हम मौजूदा नेटवर्क की किसी भी लेयर से आउटपुट ले सकते हैं और इसे नए न्यूरल नेटवर्क में इनपुट के रूप में ट्रांसफर कर सकते हैं। इस प्रकार, नए बनाए गए तंत्रिका नेटवर्क को पढ़ाकर, समय के साथ उच्च स्तर की नई विशेषताओं को पहचानना और उन कक्षाओं से छवियों को सही ढंग से वर्गीकृत करना सिखाया जा सकता है जो मूल मॉडल ने पहले कभी नहीं देखा था।
हमारे उद्देश्यों के लिए,
@ टेनसफ़्लो-मॉडल / मोबिलनेट पैकेज से मोबाइलनेट न्यूरल नेटवर्क
लें । मोबाइलनेट वीजीजी -16 की तरह ही शक्तिशाली है, लेकिन यह बहुत छोटा है, जो प्रत्यक्ष वितरण को गति देता है, अर्थात, नेटवर्क प्रसार (आगे का प्रसार), और ब्राउज़र में डाउनलोड समय को कम करता है। MobileNet
ILSVRC-2012-CLS छवि वर्गीकरण
डेटासेट पर प्रशिक्षित।
सीखने के हस्तांतरण के साथ एक मॉडल विकसित करते समय, हमारे पास दो विकल्प होते हैं:
- स्रोत मॉडल की किस परत से आउटपुट लक्ष्य मॉडल के लिए इनपुट के रूप में उपयोग करना है।
- लक्ष्य मॉडल से कितनी परतें हैं जिन्हें हम प्रशिक्षित करने जा रहे हैं, यदि कोई हो।
पहला बिंदु बहुत महत्वपूर्ण है। चयनित परत के आधार पर, हमें अपने तंत्रिका नेटवर्क के इनपुट के रूप में अमूर्त के निचले या उच्च स्तर पर सुविधाएँ मिलेंगी।
हम MobileNet की किसी भी परत को प्रशिक्षित नहीं करने जा रहे हैं। हम
global_average_pooling2d_1 से आउटपुट का
global_average_pooling2d_1 और इसे हमारे छोटे मॉडल के इनपुट के रूप में पास करते हैं। मैंने इस विशेष परत को क्यों चुना? अनुभव। मैंने कुछ परीक्षण किए, और यह परत काफी अच्छी तरह से काम करती है।
मॉडल की परिभाषा
प्रारंभिक कार्य छवि को तीन वर्गों में वर्गीकृत करना था: हाथ, पैर और अन्य आंदोलनों। पहले, चलो छोटी समस्या को हल करें: हम यह निर्धारित करेंगे कि फ्रेम में हाथ की हड़ताल है या नहीं। यह एक विशिष्ट बाइनरी वर्गीकरण समस्या है। इस उद्देश्य के लिए, हम निम्नलिखित मॉडल को परिभाषित कर सकते हैं:
import * as tf from '@tensorflow/tfjs'; const model = tf.sequential(); model.add(tf.layers.inputLayer({ inputShape: [1024] })); model.add(tf.layers.dense({ units: 1024, activation: 'relu' })); model.add(tf.layers.dense({ units: 1, activation: 'sigmoid' })); model.compile({ optimizer: tf.train.adam(1e-6), loss: tf.losses.sigmoidCrossEntropy, metrics: ['accuracy'] });
ऐसा कोड एक साधारण मॉडल,
1024 इकाइयों और
ReLU सक्रियण के साथ एक परत, साथ ही साथ एक आउटपुट इकाई को परिभाषित करता है जो
ReLU सक्रियण
sigmoid से गुजरता
sigmoid । उत्तरार्द्ध
0 से
1 तक की संख्या देता है, जो इस फ्रेम में हाथ की हड़ताल की संभावना पर निर्भर करता है।
मैंने दूसरे स्तर के लिए
1024 इकाइयों और
1e-6 की प्रशिक्षण गति क्यों
1e-6 ? खैर, मैंने कई अलग-अलग विकल्पों की कोशिश की और देखा कि ऐसे विकल्प सबसे अच्छे हैं। स्पीयर मेथड सबसे अच्छा तरीका नहीं लगता है, लेकिन बहुत हद तक यह है कि डीप लर्निंग के काम में हाइपरपैरेट सेटिंग्स - मॉडल की हमारी समझ के आधार पर, हम ऑर्थोगोनल मापदंडों को अपडेट करने के लिए अंतर्ज्ञान का उपयोग करते हैं और मॉडल काम कैसे करते हैं, यह सत्यापित करता है।
compile विधि प्रशिक्षण और मूल्यांकन के लिए मॉडल तैयार करते हुए, परतों को एक साथ संकलित करती है। यहां हम घोषणा करते हैं कि हम
adam ऑप्टिमाइज़ेशन एल्गोरिदम का उपयोग करना चाहते हैं। हम यह भी घोषणा करते हैं कि हम क्रॉस एन्ट्रापी से नुकसान (हानि) की गणना करेंगे, और संकेत देंगे कि हम मॉडल की सटीकता का मूल्यांकन करना चाहते हैं। TensorFlow.js तब सूत्र का उपयोग करके सटीकता की गणना करता है:
Accuracy = (True Positives + True Negatives) / (Positives + Negatives)यदि आप मूल MobileNet मॉडल से प्रशिक्षण स्थानांतरित करते हैं, तो आपको पहले इसे डाउनलोड करना होगा। चूंकि यह हमारे मॉडल को एक ब्राउज़र में 3,000 से अधिक छवियों पर प्रशिक्षित करने के लिए व्यावहारिक नहीं है, हम Node.js का उपयोग करेंगे और फ़ाइल से तंत्रिका नेटवर्क को लोड करेंगे।
मोबाइलनेट
यहाँ डाउनलोड
करें । कैटलॉग में फ़ाइल
model.json , जिसमें मॉडल की
model.json होती हैं - परतें, सक्रियता आदि। शेष फ़ाइलों में मॉडल पैरामीटर हैं। आप इस कोड का उपयोग करके मॉडल को फ़ाइल से लोड कर सकते हैं:
export const loadModel = async () => { const mn = new mobilenet.MobileNet(1, 1); mn.path = `file://PATH/TO/model.json`; await mn.load(); return (input): tf.Tensor1D => mn.infer(input, 'global_average_pooling2d_1') .reshape([1024]); };
ध्यान दें कि
loadModel विधि में
loadModel हम एक फ़ंक्शन लौटाते हैं जो इनपुट के रूप में एक आयामी टेंसर को स्वीकार करता है और
mn.infer(input, Layer) ।
infer विधि में एक तनु और एक परत होती है। परत निर्धारित करती है कि हम किस छिपी हुई परत से आउटपुट चाहते हैं। यदि आप
model.json खोलते हैं और
global_aiture_pooling2d_1 की global_average_pooling2d_1 , तो आपको परतों में से एक पर ऐसा नाम मिलेगा।
अब आपको मॉडल को प्रशिक्षित करने के लिए एक डेटा सेट बनाने की आवश्यकता है। ऐसा करने के लिए, हमें सभी छवियों को मोबाइलनेट में अवर विधि के माध्यम से पास करना चाहिए और उन्हें लेबल असाइन करना चाहिए: स्ट्रोक के साथ छवियों के लिए
1 और स्ट्रोक के बिना छवियों के लिए
0 :
const punches = require('fs') .readdirSync(Punches) .filter(f => f.endsWith('.jpg')) .map(f => `${Punches}/${f}`); const others = require('fs') .readdirSync(Others) .filter(f => f.endsWith('.jpg')) .map(f => `${Others}/${f}`); const ys = tf.tensor1d( new Array(punches.length).fill(1) .concat(new Array(others.length).fill(0))); const xs: tf.Tensor2D = tf.stack( punches .map((path: string) => mobileNet(readInput(path))) .concat(others.map((path: string) => mobileNet(readInput(path)))) ) as tf.Tensor2D;
उपरोक्त कोड में, हमने पहली बार हिट्स के साथ और बिना निर्देशिकाओं में फ़ाइलों को पढ़ा। फिर हम आउटपुट लेबल्स वाले एक आयामी टेंसर को निर्धारित करते हैं। यदि हमारे पास स्ट्रोक और
m अन्य छवियों के साथ
n चित्र हैं, तो टेंसर में 1 के मान के साथ
n तत्व और 0 के मान के साथ
m तत्व होंगे।
xs हम व्यक्तिगत छवियों के लिए
infer विधि को कॉल करने
infer परिणामों को
infer करते
infer । ध्यान दें कि प्रत्येक छवि के लिए, हम
readInput विधि कहते हैं। यहाँ इसका कार्यान्वयन है:
export const readInput = img => imageToInput(readImage(img), TotalChannels); const readImage = path => jpeg.decode(fs.readFileSync(path), true); const imageToInput = image => { const values = serializeImage(image); return tf.tensor3d(values, [image.height, image.width, 3], 'int32'); }; const serializeImage = image => { const totalPixels = image.width * image.height; const result = new Int32Array(totalPixels * 3); for (let i = 0; i < totalPixels; i++) { result[i * 3 + 0] = image.data[i * 4 + 0]; result[i * 3 + 1] = image.data[i * 4 + 1]; result[i * 3 + 2] = image.data[i * 4 + 2]; } return result; };
readInput पहले
readImage फ़ंक्शन को कॉल करता है, और उसके बाद अपनी कॉल को
imageToInput को
imageToInput ।
readImage फ़ंक्शन डिस्क से एक छवि पढ़ता है और फिर जेपीजी
-जेएस पैकेज का उपयोग करके बफर से jpg को डिकोड करता है।
imageToInput हम छवि को त्रि-आयामी टेंसर में परिवर्तित करते हैं।
नतीजतन, प्रत्येक
i से
0 लिए
TotalImages ys[i] 1 बराबर होना चाहिए यदि
xs[i] एक हिट के साथ छवि से मेल खाती है, और
0 अन्यथा।
मॉडल प्रशिक्षण
अब मॉडल प्रशिक्षण के लिए तैयार है!
fit विधि को बुलाओ:
await model.fit(xs, ys, { epochs: Epochs, batchSize: parseInt(((punches.length + others.length) * BatchSize).toFixed(0)), callbacks: { onBatchEnd: async (_, logs) => { console.log('Cost: %s, accuracy: %s', logs.loss.toFixed(5), logs.acc.toFixed(5)); await tf.nextFrame(); } } });
उपरोक्त कोड तीन तर्कों के साथ
fit है:
xs , ys और कॉन्फ़िगरेशन ऑब्जेक्ट। कॉन्फ़िगरेशन ऑब्जेक्ट में, हम सेट करते हैं कि मॉडल, पैकेट का आकार कितने मिटाता है, और प्रत्येक पैकेट को संसाधित करने के बाद TensorFlow.js द्वारा कॉलबैक को प्रशिक्षित किया जाएगा।
एक युग में मॉडल के प्रशिक्षण के लिए पैकेट का आकार
xs और
ys निर्धारित करता है। प्रत्येक युग के लिए, TensorFlow.js
xs का एक उपसमूह और
ys से संबंधित तत्वों का चयन करेगा, एक प्रत्यक्ष वितरण करता है,
sigmoid सक्रियण के साथ परत का आउटपुट प्राप्त करता है, और फिर, नुकसान के आधार पर,
adam एल्गोरिथ्म का उपयोग करके अनुकूलन का प्रदर्शन करता है।
प्रशिक्षण स्क्रिप्ट शुरू करने के बाद, आप नीचे दिए गए परिणाम के समान देखेंगे:
लागत: 0.84212, सटीकता: 1.00000
eta = 0.3> ---------- acc = 1.00 loss = 0.84 लागत: 0.79740, सटीकता: 1.00000
एटा = 0.2 => --------- एसीसी = 1.00 हानि = 0.80 लागत: 0.81533, सटीकता: 1.00000
एटा = 0.2 ==> -------- एसीसी = 1.00 हानि = 0.82 लागत: 0.64303, सटीकता: 0.50000
एटा = 0.2 ===> ------- एसीसी = 0.50 हानि = 0.64 लागत: 0.51377, सटीकता: 0.00000
एटा = 0.2 ====> ------ एसीसी = 0.00 नुकसान = 0.51 लागत: 0.46473, सटीकता: 0.50000
एटा = 0.1 =====> ----- एसीसी = 0.50 हानि = 0.46 लागत: 0.50872, सटीकता: 0.00000
एटा = 0.1 ======> ---- एसीसी = 0.00 हानि = 0.51 लागत: 0.62556, सटीकता: 1.00000
एटा = 0.1 =======> --- एसीसी = 1.00 हानि = 0.63 लागत: 0.65133, सटीकता: 0.50000
एटा = 0.1 ========> - एसीसी = 0.50 हानि = 0.65 लागत: 0.63824, सटीकता: 0.50000
एटा = 0.0 ===========>
293ms 14675us / कदम - एसीसी = 0.60 नुकसान = 0.65
युग 3/50
लागत: 0.44661, सटीकता: 1.00000
eta = 0.3> ---------- acc = 1.00 loss = 0.45 लागत: 0.78060, सटीकता: 1.00000
एटा = 0.3 => --------- एसीसी = 1.00 हानि = 0.78 लागत: 0.79208, सटीकता: 1.00000
एटा = 0.3 ==> -------- एसीसी = 1.00 हानि = 0.79 लागत: 0.49072, सटीकता: 0.50000
एटा = 0.2 ===> ------- एसीसी = 0.50 हानि = 0.49 लागत: 0.62232, सटीकता: 1.00000
एटा = 0.2 ====> ------ acc = 1.00 हानि = 0.62 लागत: 0.82899, सटीकता: 1.00000
एटा = 0.2 =====> ----- एसीसी = 1.00 हानि = 0.83 लागत: 0.67629, सटीकता: 0.50000
एटा = 0.1 ======> ---- एसीसी = 0.50 हानि = 0.68 लागत: 0.62621, सटीकता: 0.50000
एटा = 0.1 =======> --- एसीसी = 0.50 हानि = 0.63 लागत: 0.46077, सटीकता: 1.00000
एटा = 0.1 ========> - acc = 1.00 हानि = 0.46 लागत: 0.62076, सटीकता: 1.00000
एटा = 0.0 ===========>
304ms 15221us / कदम - एसीसी = 0.85 नुकसान = 0.63
ध्यान दें कि समय के साथ सटीकता कैसे बढ़ती है और नुकसान घटता है।
मेरे डेटा सेट पर, प्रशिक्षण के बाद के मॉडल में 92% की सटीकता दिखाई दी। ध्यान रखें कि प्रशिक्षण डेटा के छोटे सेट के कारण सटीकता बहुत अधिक नहीं हो सकती है।
ब्राउज़र में मॉडल चलाना
पिछले अनुभाग में, हमने द्विआधारी वर्गीकरण मॉडल को प्रशिक्षित किया। अब इसे ब्राउजर में चलाएं और
MK.js से कनेक्ट करें!
const video = document.getElementById('cam'); const Layer = 'global_average_pooling2d_1'; const mobilenetInfer = m => (p): tf.Tensor<tf.Rank> => m.infer(p, Layer); const canvas = document.getElementById('canvas'); const scale = document.getElementById('crop'); const ImageSize = { Width: 100, Height: 56 }; navigator.mediaDevices .getUserMedia({ video: true, audio: false }) .then(stream => { video.srcObject = stream; });
उपरोक्त कोड में कई घोषणाएँ हैं:
video HTML5 videoLayer MobileNet,mobilenetInfer — , MobileNet . MobileNetcanvas HTML5 canvas ,scale — canvas ,
उसके बाद, हम उपयोगकर्ता के कैमरे से वीडियो स्ट्रीम प्राप्त करते हैं और इसे तत्व के स्रोत के रूप में सेट करते हैं video।अगला कदम एक ग्रेस्केल फिल्टर को लागू करना है canvasजो अपनी सामग्री को स्वीकार करता है और परिवर्तित करता है : const grayscale = (canvas: HTMLCanvasElement) => { const imageData = canvas.getContext('2d').getImageData(0, 0, canvas.width, canvas.height); const data = imageData.data; for (let i = 0; i < data.length; i += 4) { const avg = (data[i] + data[i + 1] + data[i + 2]) / 3; data[i] = avg; data[i + 1] = avg; data[i + 2] = avg; } canvas.getContext('2d').putImageData(imageData, 0, 0); };
अगले चरण के रूप में, हम मॉडल को MK.js से जोड़ेंगे: let mobilenet: (p: any) => tf.Tensor<tf.Rank>; tf.loadModel('http://localhost:5000/model.json').then(model => { mobileNet .load() .then((mn: any) => mobilenet = mobilenetInfer(mn)) .then(startInterval(mobilenet, model)); });
उपरोक्त कोड में, हम पहले उस मॉडल को लोड करते हैं जिसे हमने ऊपर प्रशिक्षित किया था, और फिर MobileNet डाउनलोड करें। हम mobilenetInferछिपे हुए नेटवर्क परत से आउटपुट की गणना करने का तरीका प्राप्त करने के लिए मोबाइलनेट पास करते हैं । उसके बाद, हम विधि startIntervalको दो नेटवर्क के साथ तर्क के रूप में कहते हैं। const startInterval = (mobilenet, model) => () => { setInterval(() => { canvas.getContext('2d').drawImage(video, 0, 0); grayscale(scale .getContext('2d') .drawImage( canvas, 0, 0, canvas.width, canvas.width / (ImageSize.Width / ImageSize.Height), 0, 0, ImageSize.Width, ImageSize.Height )); const [punching] = Array.from(( model.predict(mobilenet(tf.fromPixels(scale))) as tf.Tensor1D) .dataSync() as Float32Array); const detect = (window as any).Detect; if (punching >= 0.4) detect && detect.onPunch(); }, 100); };
सबसे दिलचस्प हिस्सा विधि में शुरू होता है startInterval! सबसे पहले, हम एक अंतराल चलाते हैं जहां हर कोई 100msएक अनाम फ़ंक्शन कहता है। इसमें, canvasवर्तमान फ्रेम के साथ वीडियो को इसके शीर्ष पर पहले गाया जाता है । फिर हम फ्रेम आकार को कम करते हैं 100x56और इसे एक ग्रेस्केल फ़िल्टर लागू करते हैं।अगला कदम फ्रेम को मोबाइलनेट में स्थानांतरित करना है, वांछित छिपी परत से आउटपुट प्राप्त करना और इसे predictहमारे मॉडल की विधि के इनपुट के रूप में स्थानांतरित करना है । जो एक तत्व के साथ एक टेंसर लौटाता है। का उपयोग करते हुए, dataSyncहम टेंसर से मूल्य प्राप्त करते हैं और इसे एक स्थिर को असाइन करते हैं punching।अंत में, हम जांचते हैं: यदि एक हाथ की हड़ताल की संभावना अधिक हो जाती है 0.4, तो हम onPunchवैश्विक ऑब्जेक्ट विधि कहते हैं Detect। MK.js तीन तरीकों के साथ एक वैश्विक वस्तु प्रदान करता है:onKick, onPunchऔर onStandजो हम किसी एक वर्ण को नियंत्रित करने के लिए उपयोग कर सकते हैं।हो गया!
यहाँ परिणाम है!
एन-वर्गीकरण के साथ किक और आर्म रिकग्निशन
अगले भाग में, हम एक चालाक मॉडल बनाएंगे: एक तंत्रिका नेटवर्क जो घूंसे, किक और अन्य छवियों को पहचानता है। इस बार, प्रशिक्षण सेट तैयार करके शुरू करें: const punches = require('fs') .readdirSync(Punches) .filter(f => f.endsWith('.jpg')) .map(f => `${Punches}/${f}`); const kicks = require('fs') .readdirSync(Kicks) .filter(f => f.endsWith('.jpg')) .map(f => `${Kicks}/${f}`); const others = require('fs') .readdirSync(Others) .filter(f => f.endsWith('.jpg')) .map(f => `${Others}/${f}`); const ys = tf.tensor2d( new Array(punches.length) .fill([1, 0, 0]) .concat(new Array(kicks.length).fill([0, 1, 0])) .concat(new Array(others.length).fill([0, 0, 1])), [punches.length + kicks.length + others.length, 3] ); const xs: tf.Tensor2D = tf.stack( punches .map((path: string) => mobileNet(readInput(path))) .concat(kicks.map((path: string) => mobileNet(readInput(path)))) .concat(others.map((path: string) => mobileNet(readInput(path)))) ) as tf.Tensor2D;
पहले की तरह, हम पहले हाथ, पैर और अन्य छवियों द्वारा छिद्रों की छवियों के साथ कैटलॉग पढ़ते हैं। इसके बाद, पिछली बार के विपरीत, हम दो आयामी टेंसर के रूप में अपेक्षित परिणाम बनाते हैं, न कि एक-आयामी। हम पूछना चाहते हैं तो एन एक पंच के साथ छवियों, मीटर एक किक के साथ छवियों और k अन्य छवियों, टेंसर ysहो जाएगा nमूल्य के तत्वों [1, 0, 0], mमूल्य के साथ तत्वों [0, 1, 0]और kमूल्य के साथ आइटम [0, 0, 1]। तत्वोंका एक वेक्टर nजिसमें n - 1एक मान के साथ तत्व होते हैं और एक मूल्य के साथ 0एक तत्व होता है 1, हम एक एकात्मक वेक्टर (एक-गर्म वेक्टर) कहते हैं।उसके बाद, हम इनपुट टेंसर बनाते हैंxsMobileNet से प्रत्येक छवि के आउटपुट को स्टैक करना।यहां आपको मॉडल की परिभाषा को अपडेट करना होगा: const model = tf.sequential(); model.add(tf.layers.inputLayer({ inputShape: [1024] })); model.add(tf.layers.dense({ units: 1024, activation: 'relu' })); model.add(tf.layers.dense({ units: 3, activation: 'softmax' })); await model.compile({ optimizer: tf.train.adam(1e-6), loss: tf.losses.sigmoidCrossEntropy, metrics: ['accuracy'] });
पिछले मॉडल से केवल दो अंतर हैं:- आउटपुट लेयर में इकाइयों की संख्या
- आउटपुट लेयर में सक्रियता
आउटपुट परत में तीन इकाइयाँ हैं, क्योंकि हमारे पास छवियों की तीन अलग-अलग श्रेणियां हैं:इन तीन इकाइयों पर सक्रियण शुरू हो जाता है softmax, जो तीन मानों के साथ अपने मापदंडों को एक टेनॉर में परिवर्तित करता है। आउटपुट लेयर के लिए तीन यूनिट क्यों? तीन वर्गों के लिए तीन मानों में से प्रत्येक दो बिट्स द्वारा दर्शाया जा सकता: 00, 01, 10। बनाए गए टेंसर के मानों का योग softmax1 है, अर्थात हमें कभी भी 00 नहीं मिलेगा, इसलिए हम किसी एक वर्ग की छवियों को वर्गीकृत नहीं कर पाएंगे। उम्रसे अधिक मॉडल के प्रशिक्षण के बाद 500, मैंने लगभग 92% की सटीकता हासिल की! यह बुरा नहीं है, लेकिन यह मत भूलो कि प्रशिक्षण एक छोटे डेटा सेट पर आयोजित किया गया था।अगला कदम एक ब्राउज़र में मॉडल को चलाना है! चूंकि तर्क द्विआधारी वर्गीकरण के लिए मॉडल को चलाने के समान है, अंतिम चरण पर एक नज़र डालें, जहां मॉडल के उत्पादन के आधार पर कार्रवाई का चयन किया जाता है: const [punch, kick, nothing] = Array.from((model.predict( mobilenet(tf.fromPixels(scaled)) ) as tf.Tensor1D).dataSync() as Float32Array); const detect = (window as any).Detect; if (nothing >= 0.4) return; if (kick > punch && kick >= 0.35) { detect.onKick(); return; } if (punch > kick && punch >= 0.35) detect.onPunch();
पहले हम मोबाइलनेट को भूरे रंग के रंगों में कम फ्रेम के साथ कहते हैं, फिर हम अपने प्रशिक्षित मॉडल के परिणाम को स्थानांतरित करते हैं। मॉडल एक-आयामी टेंसर लौटाता है, जिसे हम Float32Arrayc में बदलते हैं dataSync। अगले चरण में हम Array.fromटाइप किए गए सरणी को जावास्क्रिप्ट सरणी में डालने के लिए उपयोग करते हैं । फिर हम उन संभावनाओं को निकालते हैं जो एक हाथ, एक किक या कुछ भी नहीं है जो फ्रेम पर मौजूद है।यदि तीसरे परिणाम की संभावना अधिक हो जाती है 0.4, तो हम वापस लौट आते हैं। अन्यथा, यदि किक की संभावना अधिक होती है 0.32, तो हम एमके को एक किक कमांड भेजते हैं। यदि एक किक की संभावना अधिक है 0.32और एक किक की संभावना से अधिक है, तो हम एक किक की कार्रवाई भेजते हैं।सामान्य तौर पर, यह सब है! परिणाम नीचे दिखाया गया है:
कार्रवाई मान्यता
यदि आप उन लोगों के बारे में डेटा का एक बड़ा और विविध सेट एकत्र करते हैं जो अपने हाथों और पैरों से मारते हैं, तो आप एक मॉडल का निर्माण कर सकते हैं जो व्यक्तिगत फ्रेम पर बहुत अच्छा काम करता है। लेकिन क्या इतना ही काफी है? क्या होगा अगर हम आगे भी जाना चाहते हैं और दो अलग-अलग प्रकार के किक को भेद करते हैं: एक मोड़ से और एक पीठ (बैक किक) से।जैसा कि नीचे के फ़्रेम में देखा जा सकता है, एक निश्चित कोण से एक निश्चित समय पर, दोनों स्ट्रोक समान दिखते हैं:
 लेकिन यदि आप प्रदर्शन को देखते हैं, तो चालें पूरी तरह से अलग हैं:
लेकिन यदि आप प्रदर्शन को देखते हैं, तो चालें पूरी तरह से अलग हैं: आप फ्रेम के अनुक्रम का विश्लेषण करने के लिए एक तंत्रिका नेटवर्क को कैसे प्रशिक्षित कर सकते हैं, और केवल एक फ्रेम नहीं?इस प्रयोजन के लिए, हम तंत्रिका नेटवर्क के एक और वर्ग का पता लगा सकते हैं, जिसे आवर्तक तंत्रिका नेटवर्क (RNN) कहा जाता है। उदाहरण के लिए, RNN समय श्रृंखला के साथ काम करने के लिए महान हैं:
आप फ्रेम के अनुक्रम का विश्लेषण करने के लिए एक तंत्रिका नेटवर्क को कैसे प्रशिक्षित कर सकते हैं, और केवल एक फ्रेम नहीं?इस प्रयोजन के लिए, हम तंत्रिका नेटवर्क के एक और वर्ग का पता लगा सकते हैं, जिसे आवर्तक तंत्रिका नेटवर्क (RNN) कहा जाता है। उदाहरण के लिए, RNN समय श्रृंखला के साथ काम करने के लिए महान हैं:- प्राकृतिक भाषा प्रसंस्करण (एनएलपी), जहां प्रत्येक शब्द पिछले और बाद में निर्भर करता है
- अपने ब्राउज़िंग इतिहास के आधार पर अगले पृष्ठ की भविष्यवाणी करें
- फ़्रेम मान्यता
इस तरह के एक मॉडल को लागू करना इस लेख के दायरे से परे है, लेकिन आइए एक उदाहरण वास्तुकला पर गौर करें कि यह कैसे एक साथ काम करेगा।आरएनएन की शक्ति
नीचे दिए गए आरेख क्रियाओं की पहचान का मॉडल दिखाता है: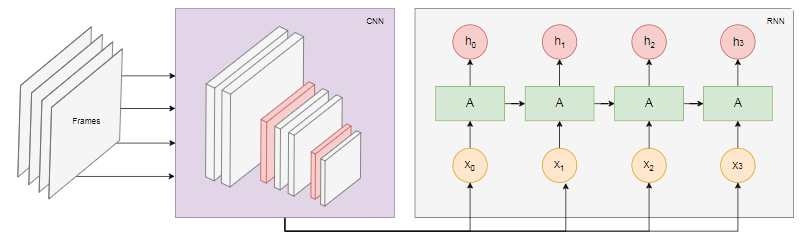 हम
हम nवीडियो से अंतिम फ्रेम लेते हैं और उन्हें सीएनएन में स्थानांतरित करते हैं। प्रत्येक फ्रेम के लिए सीएनएन आउटपुट को इनपुट आरएनएन के रूप में प्रेषित किया जाता है। एक आवर्तक तंत्रिका नेटवर्क व्यक्तिगत फ़्रेमों के बीच संबंधों को निर्धारित करेगा और पहचानेगा कि वे किस क्रिया के अनुरूप हैं।निष्कर्ष
इस लेख में, हमने एक छवि वर्गीकरण मॉडल विकसित किया। इस उद्देश्य के लिए, हमने एक डेटा सेट एकत्र किया: हमने वीडियो फ्रेम निकाले और मैन्युअल रूप से उन्हें तीन श्रेणियों में विभाजित किया। तब डेटा को इमेग का उपयोग करके जोड़कर संवर्धित किया गया था ।उसके बाद, हमने समझाया कि लर्निंग ट्रांसफर क्या है और अपने स्वयं के प्रयोजनों के लिए @ टेंसोरफ़्लो-मॉडल / मोबिलनेट पैकेज से प्रशिक्षित मोबाइलनेट मॉडल का उपयोग किया जाता है । हमने Node.js प्रक्रिया में एक फ़ाइल से MobileNet डाउनलोड किया और एक अतिरिक्त घने परत को प्रशिक्षित किया, जहां डेटा को छिपे हुए MobileNet परत से फीड किया गया था। प्रशिक्षण के बाद, हमने 90% से अधिक की सटीकता हासिल की!एक ब्राउज़र में इस मॉडल का उपयोग करने के लिए, हमने इसे मोबाइलनेट के साथ डाउनलोड किया और उपयोगकर्ता के वेब कैमरा से हर 100 एमएस में फ़्रेम को वर्गीकृत करना शुरू किया। हमने मॉडल को खेल से जोड़ाMK.js और वर्णों को नियंत्रित करने के लिए मॉडल आउटपुट का उपयोग किया।अंत में, हमने देखा कि कार्यों को पहचानने के लिए एक आवर्तक तंत्रिका नेटवर्क के साथ संयोजन करके मॉडल को कैसे बेहतर बनाया जाए।मुझे आशा है कि आपने इस छोटे से प्रोजेक्ट का आनंद लिया जो मैंने नहीं किया था!