डेटा विज्ञान के क्षेत्र में सबसे महत्वपूर्ण कार्यों में से एक न केवल उच्च गुणवत्ता वाले पूर्वानुमान बनाने में सक्षम मॉडल का निर्माण है, बल्कि ऐसी भविष्यवाणियों की व्याख्या करने की क्षमता भी है।
यदि हम न केवल यह जानते हैं कि ग्राहक किसी उत्पाद को खरीदने के लिए इच्छुक है, बल्कि यह भी समझे कि इसकी खरीद पर क्या प्रभाव पड़ता है, तो हम भविष्य में बिक्री दक्षता बढ़ाने के उद्देश्य से कंपनी की रणनीति बनाने में सक्षम होंगे।
या मॉडल ने भविष्यवाणी की कि रोगी जल्द ही बीमार हो जाएगा। ऐसी भविष्यवाणियों की सटीकता बहुत अधिक नहीं है, क्योंकि मॉडल से कई कारक छिपे हुए हैं, लेकिन उन कारणों की एक व्याख्या कि मॉडल ने ऐसी भविष्यवाणी क्यों की, जिससे डॉक्टर को नए लक्षणों पर ध्यान देने में मदद मिल सके। इस प्रकार, मॉडल के आवेदन की सीमाओं का विस्तार करना संभव है यदि इसकी सटीकता अपने आप में बहुत अधिक नहीं है।
इस पोस्ट में मैं
SHAP तकनीक के बारे में बात करना चाहता हूं, जो आपको विभिन्न प्रकार के मॉडल के हुड के नीचे देखने की अनुमति देता है।
यदि रैखिक मॉडल के साथ यह कम और कम स्पष्ट है, तो भविष्यवक्ता के तहत गुणांक का पूर्ण मूल्य जितना अधिक होता है, उतना ही महत्वपूर्ण यह पूर्वसूचक होता है, फिर समान ढाल बूस्टिंग की विशेषताओं के महत्व को स्पष्ट करना अधिक कठिन होता है।
ऐसे पुस्तकालय की आवश्यकता क्यों थी

स्केगरर स्टैक में, एक्सगबोस्ट, लाइट जीबीएम पैकेज में, "लकड़ी के मॉडल" के लिए सुविधाओं (सुविधा महत्व) के महत्व का आकलन करने के लिए अंतर्निहित तरीके थे:
- लाभ
यह उपाय मॉडल में प्रत्येक विशेषता के सापेक्ष योगदान को दर्शाता है। गणना के लिए, हम प्रत्येक पेड़ के माध्यम से जाते हैं, प्रत्येक ट्री नोड को देखते हैं जो फ़ीचर नोड के विभाजन की ओर जाता है और मीट्रिक (गिनी अशुद्धता, सूचना लाभ) के अनुसार मॉडल की अनिश्चितता कितनी घट जाती है।
प्रत्येक सुविधा के लिए, सभी पेड़ों पर इसके योगदान को संक्षेप में प्रस्तुत किया गया है।
- आवरण
प्रत्येक सुविधा के लिए टिप्पणियों की संख्या दिखाता है। उदाहरण के लिए, आपके पास 4 विशेषताएं हैं, 3 पेड़। मान लीजिए कि पेड़ के नोड्स में सुविधा 1 में क्रमशः 10, 5, और पेड़ों 1, 2, और 3 में 2 अवलोकन हैं। फिर, इस सुविधा के लिए, महत्व 17 (10 + 5 + 2) होगा।
- आवृत्ति
दिखाता है कि यह विशेषता पेड़ के नोड्स में कितनी बार होती है, अर्थात, प्रत्येक पेड़ में प्रत्येक सुविधा के लिए पेड़ों की कुल संख्या को नोड्स में विभाजित किया जाता है।
इन सभी दृष्टिकोणों में मुख्य समस्या यह है कि यह स्पष्ट नहीं है कि यह विशेषता मॉडल भविष्यवाणी को कैसे प्रभावित करती है। उदाहरण के लिए, हमने सीखा कि ऋण चुकाने के लिए बैंक क्लाइंट की सॉल्वेंसी का आकलन करने के लिए आय का स्तर महत्वपूर्ण है। लेकिन वास्तव में कैसे? कितना उच्च राजस्व पूर्वाग्रह मॉडल भविष्यवाणियों?
बेशक, हम आय के स्तर को बदलकर कई भविष्यवाणियां कर सकते हैं। लेकिन अन्य सुविधाओं के साथ क्या करना है? आखिरकार, हम खुद को ऐसी स्थिति में पाते हैं कि हमें अन्य विशेषताओं से
स्वतंत्र रूप से आय के प्रभाव को समझने की आवश्यकता होती है, उनके औसत मूल्य के साथ।
एक तरह का औसत बैंक ग्राहक है "शून्य में।" आय में परिवर्तन के साथ मॉडल भविष्यवाणियों को कैसे बदला जाएगा?
यहाँ
SHAP पुस्तकालय बचाव के लिए आता है।
हम SHAP का उपयोग करके सुविधाओं के महत्व की गणना करते हैं
SHAP पुस्तकालय में,
सुविधाओं के महत्व का आकलन करने के लिए
, Shapley मानों की गणना की जाती है (एक अमेरिकी गणितज्ञ के नाम से और पुस्तकालय का नाम दिया गया है)।
किसी विशेषता के महत्व का आकलन करने के लिए, इस सुविधा के
साथ और
बिना मॉडल की भविष्यवाणियों का मूल्यांकन किया
जाता है ।
थोड़ा प्रागितिहास

शेपली के अर्थ गेम थ्योरी से आते हैं।
परिदृश्य पर विचार करें: लोगों का एक समूह ताश खेलता है। उनके योगदान के अनुसार उनके बीच पुरस्कार राशि कैसे वितरित करें?
कई तरह की धारणाएँ बनाई जाती हैं:
- प्रत्येक खिलाड़ी के लिए इनाम की राशि कुल पुरस्कार पूल के बराबर है
- यदि दो खिलाड़ी खेल में समान योगदान करते हैं, तो उन्हें एक समान इनाम मिलता है।
- यदि किसी खिलाड़ी ने कोई योगदान नहीं किया है, तो उसे कोई इनाम नहीं मिलता है।
- यदि किसी खिलाड़ी ने दो गेम बिताए हैं, तो उसके कुल इनाम में प्रत्येक गेम के लिए पुरस्कार की राशि होती है
हम मॉडल की विशेषताओं को खिलाड़ियों के रूप में पेश करते हैं, और पुरस्कार पूल मॉडल की अंतिम भविष्यवाणी के रूप में।
आइए एक उदाहरण देखें।
I-th सुविधा के लिए Shapley मान की गणना करने का सूत्र:
$$ प्रदर्शन $ $ \ _ {समीकरण *} \ phi_ {i} (p) = \ sum_ {S \ subseteq N / \ {i \}} \ frac {| S |! (n - | S | -1) | !} {n!} (p (S \ cup \ {i \}) - p (S)) \ n {समीकरण *} $ $ प्रदर्शन $ $
यहां:
p (S \ cup \ {i \})p (S \ cup \ {i \}) एक मॉडल है जो i-th फीचर के साथ एक मॉडल है,
p(S) - यह i-th सुविधा के बिना मॉडल की एक भविष्यवाणी है,
एन - सुविधाओं की संख्या,
एस - i-th सुविधा के बिना सुविधाओं का एक मनमाना सेट
सुविधाओं के सभी संभव संयोजनों (सभी सुविधाओं की अनुपस्थिति सहित) पर प्रत्येक डेटा नमूने (उदाहरण के लिए, नमूना में प्रत्येक ग्राहक के लिए) के लिए आई-वें फ़ीचर के लिए Shapley मान की गणना की जाती है, फिर प्राप्त मानों को modulo के रूप में अभिव्यक्त किया जाता है और i-th सुविधा के अंतिम महत्व को प्राप्त किया जाता है।
ये गणना बेहद महंगी हैं, इसलिए, हुड के तहत, गणना के अनुकूलन के लिए विभिन्न एल्गोरिदम का उपयोग किया जाता है, अधिक विवरण के लिए, ऊपर दिए गए लिंक को देखें।
Xgboost प्रलेखन से वेनिला उदाहरण लें।
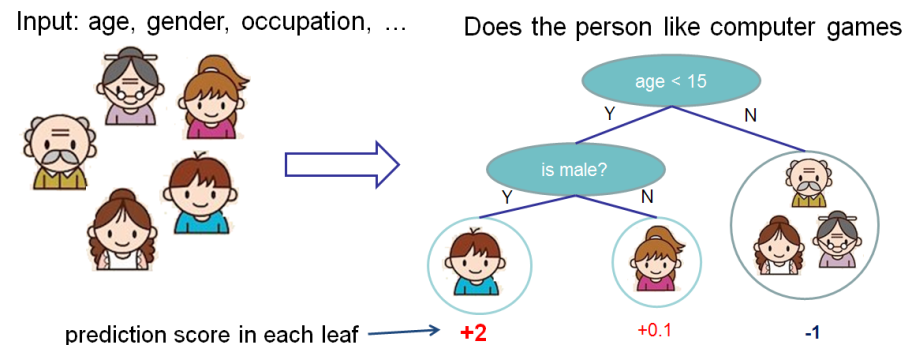
हम यह अनुमान लगाने के लिए सुविधाओं के महत्व का मूल्यांकन करना चाहते हैं कि क्या कोई व्यक्ति कंप्यूटर गेम पसंद करता है।
इस उदाहरण में, सादगी के लिए, हमारे पास दो विशेषताएं हैं: आयु (आयु) और लिंग (लिंग)। लिंग (लिंग) मान 0 और 1 लेता है।
बॉबी (पेड़ के बाएं-सबसे छोटे नोड में छोटा लड़का) को लें और फीचर उम्र (उम्र) के लिए Shapley के मूल्य की गणना करें।
हमारे पास एस सुविधाओं के दो सेट हैं:
\ {\}\ {\} - कोई सुविधाएँ नहीं
\ {लिंग \}\ {लिंग \} - केवल एक फीचर लिंग है।
स्थिति जब कोई सुविधा मान नहीं हैं
विभिन्न मॉडल उन परिस्थितियों के साथ अलग-अलग तरीके से काम करते हैं जहां डेटा नमूने के लिए कोई सुविधाएँ नहीं हैं, अर्थात सभी विशेषताओं के लिए मान NULL हैं।
इस मामले में, यह विचार करेगा कि मॉडल पेड़ों की शाखाओं पर भविष्यवाणियों को औसत करता है, अर्थात, सुविधाओं के बिना भविष्यवाणी होगी
[(2+0.1)/2+(−1)]/2=0.025 ।
यदि हम उम्र का ज्ञान जोड़ते हैं, तो मॉडल की भविष्यवाणी होगी
(2+0.1)/2=1.05 ।
नतीजतन, सुविधाओं की अनुपस्थिति के मामले के लिए Shapley का मूल्य:
\ frac {| S |! (n - | S -1)!} {n!} (p (S \ cup \ {i \}) - p (S)) = \ frac {1 (2-0) -1)!} {2!} (1.025) = 0.5125
\ frac {| S |! (n - | S -1)!} {n!} (p (S \ cup \ {i \}) - p (S)) = \ frac {1 (2-0) -1)!} {2!} (1.025) = 0.5125
वह स्थिति जब हम लिंग को जानते हैं
के लिए बॉबी
लिंग सुविधाओं की उम्र के बिना भविष्यवाणी, केवल सुविधाओं के साथ लिंग समान है
[(2+0.1)/2+(−1)]/2=0.025 । यदि हम उम्र को जानते हैं, तो भविष्यवाणी सबसे बाईं ओर का पेड़ है, अर्थात 2।
नतीजतन, इस मामले के लिए Shapley का मूल्य:
$ $ प्रदर्शन $ $ \ शुरू {समीकरण *} \ frac {| S |! (n - | S | -1 |}}} {n!} (p (S \ cup \ {i \}) - p (S) ) = \ frac {1 (2-1-1)!} {2!} (1.975) = 0.9875 \ अंत {समीकरण *} $ $ प्रदर्शन $ $
संक्षेप में प्रस्तुत करना
उम्र (उम्र) के लिए Shapley का कुल मूल्य:
$ $ प्रदर्शन $ $ \ शुरू {समीकरण *} \ phi_ {आयु बॉबी} = 0.9875 + 0.5125 = 1.5 \ अंत {समीकरण *} $ $ प्रदर्शन $ $
एक वास्तविक व्यापार उदाहरण
SHAP लाइब्रेरी में एक समृद्ध दृश्य कार्यक्षमता है जो मॉडल की पर्याप्तता का मूल्यांकन करने के लिए व्यवसाय और विश्लेषक दोनों के लिए मॉडल को आसानी से और बस समझाने में मदद करता है।
एक परियोजना में, मैंने कंपनी के कर्मचारियों के बहिर्वाह का विश्लेषण किया। एक मॉडल के रूप में, Xgboost का उपयोग किया गया था।
अजगर में कोड:
import shap shap_test = shap.TreeExplainer(best_model).shap_values(df) shap.summary_plot(shap_test, df, max_display=25, auto_size_plot=True)
सुविधाओं के महत्व का परिणामी ग्राफ:
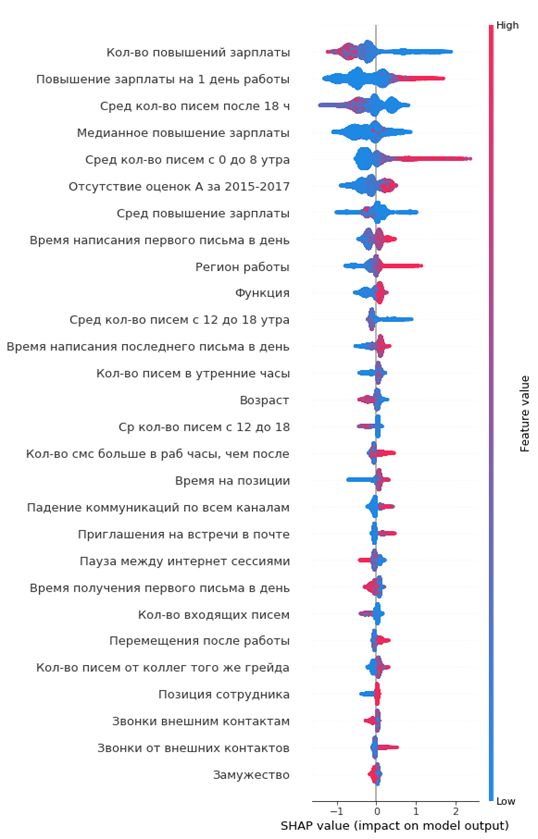
इसे कैसे पढ़ें:
- वर्टिकल लाइन के बाईं ओर स्थित मान ऋणात्मक वर्ग (0) से दाएं - धनात्मक (1) हैं
- ग्राफ पर रेखा जितनी मोटी होगी, उतने अधिक अवलोकन बिंदु
- चार्ट पर अंक जितना अधिक होगा, उसमें सुविधाओं का मूल्य उतना अधिक होगा
ग्राफ से, आप दिलचस्प निष्कर्ष निकाल सकते हैं और उनकी पर्याप्तता की जांच कर सकते हैं:
- कर्मचारी की वेतन वृद्धि जितनी कम होगी, उसके जाने की संभावना उतनी ही अधिक होगी
- कार्यालयों के क्षेत्र हैं जहाँ बहिर्वाह अधिक है
- कर्मचारी जितना छोटा होगा, उसके जाने की संभावना उतनी ही अधिक होगी
- ...
आप तुरंत निवर्तमान कर्मचारी का एक चित्र बना सकते हैं: उसे वेतन वृद्धि नहीं मिली थी, वह काफी युवा था, एक ही, एक ही स्थिति में लंबे समय तक, कोई ग्रेड वृद्धि नहीं हुई, कोई उच्च वार्षिक रेटिंग नहीं थी, उसने सहयोगियों के साथ कम संवाद करना शुरू किया।
सरल और सुविधाजनक!
आप किसी विशिष्ट कर्मचारी के लिए भविष्यवाणी की व्याख्या कर सकते हैं:

या 2 डी ग्राफ के रूप में एक विशिष्ट विशेषता पर भविष्यवाणियों की निर्भरता देखें:
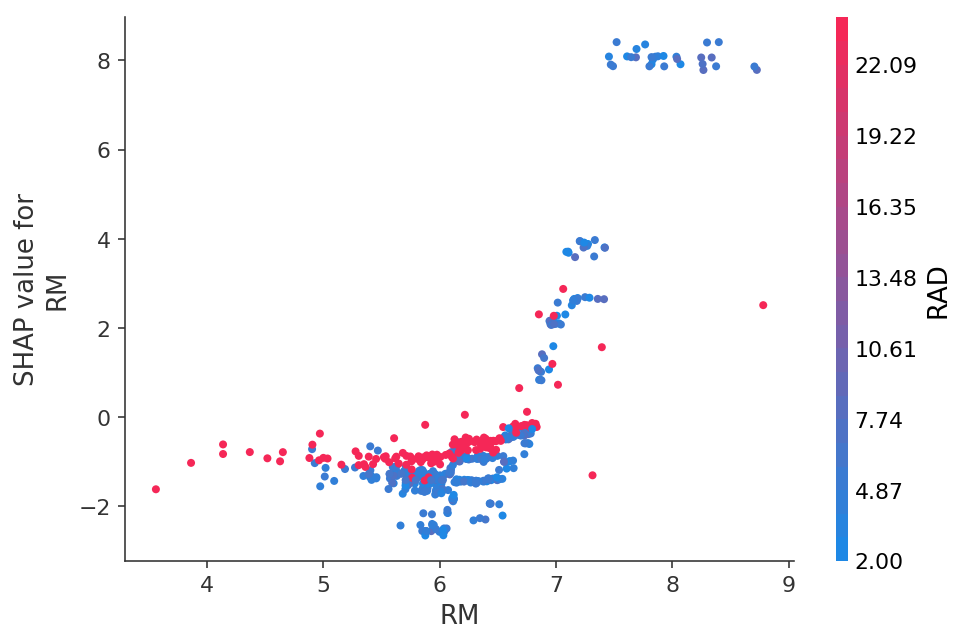
तुम भी तस्वीरों में तंत्रिका नेटवर्क की भविष्यवाणियों कल्पना कर सकते हैं:

निष्कर्ष
मैंने खुद छह महीने पहले SHAP मूल्यों के बारे में सीखा और सुविधाओं के महत्व का आकलन करने के लिए इसे पूरी तरह से बदल दिया।
मुख्य लाभ:
- सुविधाजनक दृश्य और व्याख्या
- सुविधाओं के महत्व की ईमानदार गणना
- डेटा की एक विशेष सदस्यता के लिए सुविधाओं का मूल्यांकन करने की क्षमता (उदाहरण के लिए, हमारे ग्राहक नमूना में अन्य ग्राहकों से कैसे भिन्न होते हैं) पंडों में डेटासेट के एक साधारण फिल्टर और आकार में इसके विश्लेषण के द्वारा किया जाता है, शाब्दिक रूप से कोड की एक जोड़ी