
एआई सम्मेलन में,
व्लादिमीर इवानोव vivanov879 , सीनियर प्रबलित सीखने के उपयोग के बारे में बात करेंगे
एनवीडिया में डीप लर्निंग इंजीनियर । विशेषज्ञ परीक्षण विभाग में मशीन सीखने में लगे हुए हैं: “मैं वीडियो गेम और हार्डवेयर के परीक्षण के दौरान एकत्र किए गए डेटा का विश्लेषण करता हूं। इसके लिए मैं मशीन लर्निंग और कंप्यूटर विजन का उपयोग करता हूं। काम का मुख्य हिस्सा छवि विश्लेषण, प्रशिक्षण से पहले डेटा सफाई, डेटा मार्कअप और प्राप्त समाधानों का दृश्य है। ”
आज के लेख में, व्लादिमिर बताते हैं कि स्वायत्त कारों में प्रबलित शिक्षण का उपयोग क्यों किया जाता है और इस बारे में बात की जाती है कि कैसे एक एजेंट को बदलते परिवेश में कार्य करने के लिए प्रशिक्षित किया जाता है - वीडियो गेम के उदाहरणों का उपयोग करके।
पिछले कुछ वर्षों में, मानवता ने बड़ी मात्रा में डेटा जमा किया है। कुछ डेटासेट साझा और मैन्युअल रूप से रखे गए हैं। उदाहरण के लिए, CIFAR डेटासेट, जहां प्रत्येक चित्र पर हस्ताक्षर किए जाते हैं, वह किस वर्ग का है।
ऐसे डेटासेट हैं जहां आपको केवल चित्र के रूप में नहीं, बल्कि छवि के प्रत्येक पिक्सेल के लिए एक वर्ग असाइन करने की आवश्यकता है। उदाहरण के लिए, सिटीस्केप्स में।

इन कार्यों को एकजुट करता है कि एक सीखने तंत्रिका नेटवर्क केवल डेटा में पैटर्न को याद रखने की जरूरत है। इसलिए, पर्याप्त मात्रा में डेटा के साथ, और CIFAR के मामले में यह 80 मिलियन चित्र है, तंत्रिका नेटवर्क सामान्यीकरण करना सीख रहा है। नतीजतन, वह अच्छी तरह से उन छवियों के वर्गीकरण का सामना करती है जो उसने पहले कभी नहीं देखी थीं।
लेकिन शिक्षक के साथ शिक्षण तकनीक के ढांचे के भीतर अभिनय करना, जो चित्रों को चिह्नित करने के लिए काम करता है, उन समस्याओं को हल करना असंभव है जहां हम निशान की भविष्यवाणी नहीं करना चाहते हैं, लेकिन निर्णय लेने के लिए। उदाहरण के लिए, स्वायत्त ड्राइविंग के मामले में, जहां कार्य सुरक्षित रूप से और मज़बूती से मार्ग के अंतिम बिंदु तक पहुंचना है।
वर्गीकरण की समस्याओं में, हमने शिक्षक के साथ शिक्षण तकनीक का उपयोग किया - जब प्रत्येक चित्र को एक विशिष्ट वर्ग सौंपा गया। लेकिन क्या होगा अगर हमारे पास ऐसे मार्कअप नहीं हैं, लेकिन एक एजेंट और एक वातावरण है जिसमें वह कुछ कार्य कर सकता है? उदाहरण के लिए, यह एक वीडियो गेम है, और हम नियंत्रण तीर पर क्लिक कर सकते हैं।

सुदृढीकरण प्रशिक्षण के साथ इस तरह की समस्या को हल किया जाना चाहिए। समस्या के सामान्य कथन में, हम सीखना चाहते हैं कि क्रियाओं का सही क्रम कैसे करें। यह मौलिक रूप से महत्वपूर्ण है कि एजेंट के पास बार-बार कार्रवाई करने की क्षमता है, इस प्रकार वह उस वातावरण की खोज करता है जिसमें वह है। और सही जवाब के बजाय, किसी विशेष स्थिति में क्या करना है, उसे एक सही ढंग से पूरा किए गए कार्य के लिए इनाम मिलता है। उदाहरण के लिए, एक स्वायत्त टैक्सी के मामले में, ड्राइवर को प्रत्येक यात्रा के लिए एक बोनस प्राप्त होगा।
चलो एक सरल उदाहरण पर वापस आते हैं - एक वीडियो गेम। अटारी टेबल टेनिस खेल की तरह कुछ सरल लें।
हम बाईं ओर टैबलेट को नियंत्रित करेंगे। हम दाईं ओर नियमों पर प्रोग्राम किए गए कंप्यूटर प्लेयर के खिलाफ खेलेंगे। चूंकि हम एक छवि के साथ काम कर रहे हैं, और तंत्रिका नेटवर्क छवियों से जानकारी निकालने में सबसे अधिक सफल हैं, आइए एक तस्वीर को 3x3 कर्नेल आकार के साथ तीन-परत तंत्रिका नेटवर्क के इनपुट पर लागू करें। बाहर निकलने पर, उसे दो कार्यों में से एक को चुनना होगा: बोर्ड को ऊपर या नीचे ले जाएं।
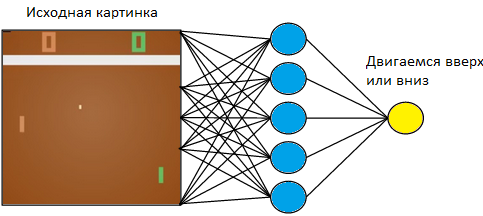
हम तंत्रिका नेटवर्क को ऐसे कार्यों के लिए प्रशिक्षित करते हैं जो जीत की ओर ले जाते हैं। प्रशिक्षण तकनीक इस प्रकार है। हम तंत्रिका नेटवर्क को टेबल टेनिस के कुछ दौर खेलने देते हैं। फिर हम खेले जाने वाले खेलों को क्रमबद्ध करना शुरू करते हैं। उन खेलों में जहां उसने जीता था, हम "ऊपर" लेबल वाली तस्वीरों को चिह्नित करते हैं जहां उसने रैकेट उठाया, और "डाउन" जहां उसने उसे उतारा। खोए हुए खेलों में, हम इसके विपरीत करते हैं। हम उन चित्रों को चिह्नित करते हैं जहां उसने बोर्ड को "ऊपर" लेबल के साथ उतारा, और जहां उसने इसे उठाया, "नीचे"। इस प्रकार, हम उस समस्या को कम कर देते हैं जो हम पहले से जानते हैं - एक शिक्षक के साथ प्रशिक्षण। हमारे पास टैग के साथ चित्रों का एक सेट है।
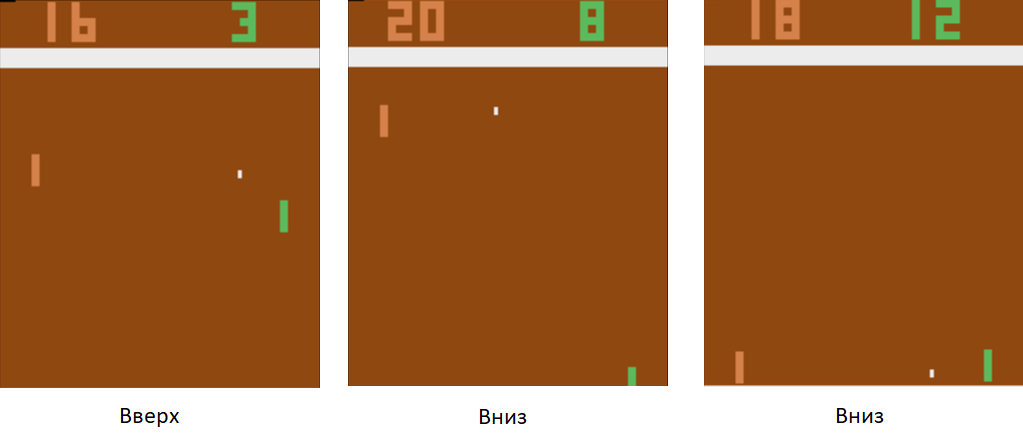
इस प्रशिक्षण तकनीक का उपयोग करके, कुछ घंटों में, हमारा एजेंट नियमों पर प्रोग्राम किए गए कंप्यूटर प्लेयर को हरा देना सीख जाएगा।
स्वायत्त ड्राइविंग के साथ क्या करना है? तथ्य यह है कि टेबल टेनिस एक बहुत ही सरल खेल है। और यह प्रति सेकंड हजारों फ्रेम का उत्पादन कर सकता है। हमारे नेटवर्क में अब केवल 3 परतें हैं। इसलिए, सीखने की प्रक्रिया तेज बिजली है। खेल डेटा की एक बड़ी मात्रा उत्पन्न करता है, और हम तुरंत इसे संसाधित करते हैं। स्वायत्त ड्राइविंग के मामले में, डेटा एकत्र करना बहुत लंबा और अधिक महंगा है। कारें महंगी हैं, और एक कार के साथ हमें प्रति सेकंड केवल 60 फ्रेम प्राप्त होंगे। इसके अलावा, त्रुटि की कीमत बढ़ जाती है। एक वीडियो गेम में, हम प्रशिक्षण के बहुत शुरुआत में गेम के बाद गेम खेल सकते थे। लेकिन हम कार को खराब नहीं कर सकते।
इस मामले में, चलो प्रशिक्षण की शुरुआत में तंत्रिका नेटवर्क की मदद करते हैं। हम कार पर कैमरा ठीक करते हैं, इसमें एक अनुभवी ड्राइवर डालते हैं और हम कैमरे से तस्वीरें रिकॉर्ड करेंगे। प्रत्येक तस्वीर के लिए, हम कार के स्टीयरिंग कोण की सदस्यता लेते हैं। हम एक अनुभवी ड्राइवर के व्यवहार की नकल करने के लिए तंत्रिका नेटवर्क को प्रशिक्षित करेंगे। इस प्रकार, हमने एक शिक्षक के साथ पहले से ही ज्ञात शिक्षण के लिए कार्य को फिर से कम कर दिया।
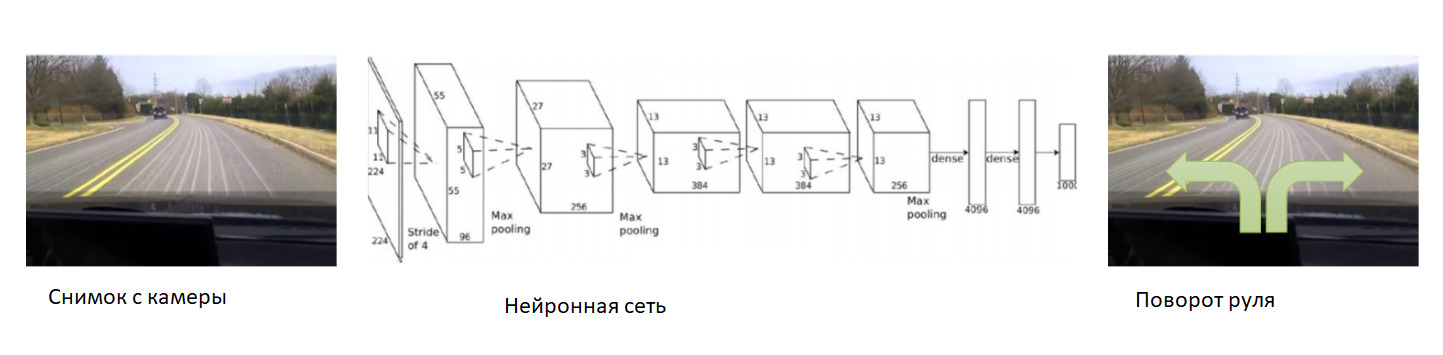
पर्याप्त रूप से बड़े और विविध डेटासेट के साथ, जिसमें विभिन्न परिदृश्य, मौसम और मौसम की स्थिति शामिल होगी, तंत्रिका नेटवर्क सीखेंगे कि कार को सही तरीके से कैसे नियंत्रित किया जाए।
हालांकि, डेटा के साथ एक समस्या थी। वे इकट्ठा करने के लिए बहुत लंबे और महंगे हैं। आइए एक सिम्युलेटर का उपयोग करें जिसमें कार आंदोलन के सभी भौतिकी को लागू किया जाएगा - उदाहरण के लिए, डीपड्राइव। हम इसे एक कार खोने के डर के बिना सीख सकते हैं।

इस सिम्युलेटर में, हमारे पास कार और दुनिया के सभी संकेतकों तक पहुंच है। इसके अलावा, सभी लोगों, कारों, उनकी गति और उनसे दूरी के बारे में चिह्नित किया गया है।

इंजीनियर के दृष्टिकोण से, इस तरह के एक सिम्युलेटर में, आप सुरक्षित रूप से नई प्रशिक्षण तकनीकों का प्रयास कर सकते हैं। एक शोधकर्ता को क्या करना चाहिए? उदाहरण के लिए, सुदृढीकरण के साथ सीखने की समस्याओं में ढाल वंश के लिए विभिन्न विकल्पों का अध्ययन। एक साधारण परिकल्पना का परीक्षण करने के लिए, मैं एक तोप से गौरैया को गोली नहीं मारना चाहता और एक जटिल आभासी दुनिया में एक एजेंट को चलाना चाहता हूं, और फिर सिमुलेशन परिणामों के लिए एक दिन के लिए प्रतीक्षा करें। इस मामले में, आइए हमारी कंप्यूटिंग शक्ति का अधिक कुशलता से उपयोग करें। एजेंटों को सरल होने दें। उदाहरण के लिए, चार-पैर वाली मकड़ी का मॉडल लें। मुजोको सिम्युलेटर में, यह इस तरह दिखता है:

हमने उसे एक निश्चित दिशा में उच्चतम संभव गति से चलाने का कार्य निर्धारित किया है - उदाहरण के लिए, दाईं ओर। एक मकड़ी के लिए मनाया मापदंडों की संख्या 39-आयामी वेक्टर है, जो उसके सभी अंगों की स्थिति और गति को रिकॉर्ड करती है। टेबल टेनिस के लिए तंत्रिका नेटवर्क के विपरीत, जहां आउटपुट में केवल एक न्यूरॉन था, आउटपुट पर आठ हैं (चूंकि इस मॉडल में मकड़ी के पास 8 जोड़ों हैं)।
ऐसे सरल मॉडल में, शिक्षण तकनीक के बारे में विभिन्न परिकल्पनाओं का परीक्षण किया जा सकता है। उदाहरण के लिए, चलिए तंत्रिका नेटवर्क के प्रकार के आधार पर, सीखने की गति की तुलना करें। इसे सिंगल-लेयर न्यूरल नेटवर्क, थ्री-लेयर न्यूरल नेटवर्क, एक कन्वेन्शनल नेटवर्क और एक आवर्तक नेटवर्क:
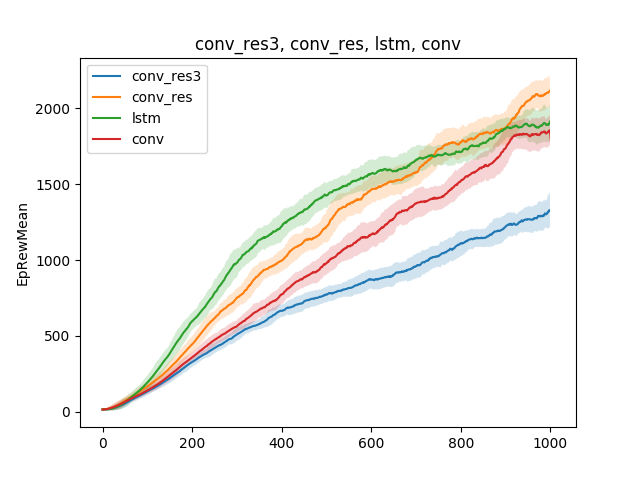
निष्कर्ष निम्नानुसार निकाला जा सकता है: चूंकि मकड़ी मॉडल और कार्य काफी सरल हैं, इसलिए विभिन्न मॉडलों के लिए प्रशिक्षण परिणाम लगभग समान हैं। एक तीन-परत नेटवर्क बहुत जटिल है, और इसलिए बदतर सीखता है।
इस तथ्य के बावजूद कि सिम्युलेटर एक साधारण मकड़ी मॉडल के साथ काम करता है, मकड़ी को दिए गए कार्य के आधार पर, प्रशिक्षण दिनों तक रह सकता है। इस मामले में, चलो एक के बजाय एक ही सतह पर कई सौ मकड़ियों को चेतन करते हैं और उन आंकड़ों से सीखते हैं जो हम सभी से प्राप्त करेंगे। इसलिए हम कई सौ बार प्रशिक्षण में तेजी लाएंगे। यहाँ फ्लेक्स इंजन का एक उदाहरण दिया गया है।
तंत्रिका नेटवर्क अनुकूलन के संदर्भ में केवल एक चीज बदल गई है डेटा संग्रह। जब हमने केवल एक मकड़ी चलाई, तो हमें क्रमिक रूप से डेटा प्राप्त हुआ। एक के बाद एक दौड़।

अब ऐसा हो सकता है कि कुछ मकड़ियां सिर्फ दौड़ शुरू कर रही हों, जबकि कुछ लंबे समय से चल रही हों।
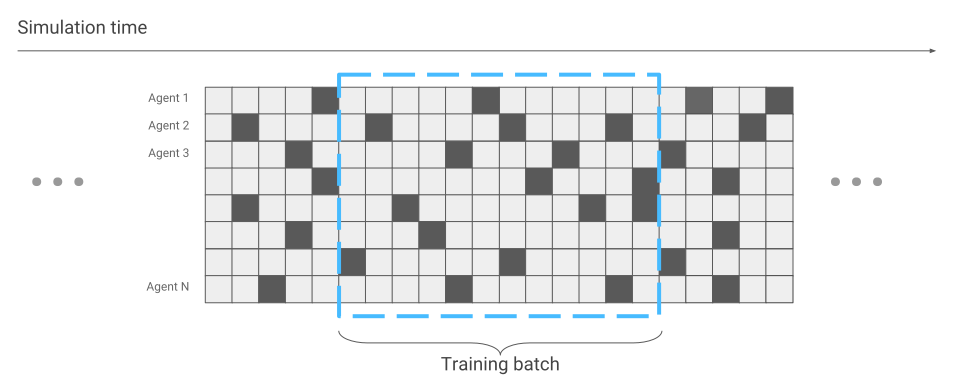
हम इसे तंत्रिका नेटवर्क अनुकूलन के दौरान ध्यान में रखेंगे। अन्यथा, सब कुछ वही रहता है। नतीजतन, सैकड़ों स्क्रीन पर एक साथ होने वाली मकड़ियों की संख्या के अनुसार, हमें सैकड़ों बार प्रशिक्षण में त्वरण मिलता है।
चूंकि हमारे पास एक प्रभावी सिम्युलेटर है, आइए अधिक जटिल समस्याओं को हल करने का प्रयास करें। उदाहरण के लिए, उबड़-खाबड़ जमीन पर दौड़ना।

चूंकि इस मामले में पर्यावरण अधिक आक्रामक हो गया है, आइए प्रशिक्षण के दौरान कार्यों को बदलें और जटिल करें। यह सीखना कठिन है, लेकिन लड़ाई में आसान है। उदाहरण के लिए, इलाके को बदलने के लिए हर कुछ मिनट। इसके अलावा, आइए बाहरी एजेंटों को एजेंट को निर्देशित करें। उदाहरण के लिए, गेंदों को उस पर फेंक दें और हवा को चालू और बंद करें। फिर एजेंट उन सतहों पर भी चलना सीखता है जो उसे कभी नहीं मिली हैं। उदाहरण के लिए, सीढ़ियाँ चढ़ें।

चूंकि हमने सिमुलेशन में भाग लेना बहुत प्रभावी ढंग से सीखा है, आइए प्रतिस्पर्धी विषयों में सुदृढीकरण प्रशिक्षण तकनीकों की जांच करें। उदाहरण के लिए, शूटिंग खेलों में। विज़्डम प्लेटफॉर्म एक ऐसी दुनिया प्रदान करता है जिसमें आप शूटिंग कर सकते हैं, हथियार जमा कर सकते हैं और स्वास्थ्य की भरपाई कर सकते हैं। इस गेम में हम एक न्यूरल नेटवर्क का भी इस्तेमाल करेंगे। केवल अब उसके पास पांच निकास होंगे: चार आंदोलन के लिए और एक शूटिंग के लिए।
प्रशिक्षण प्रभावी होने के लिए, इसे धीरे-धीरे लें। सरल से जटिल तक। इनपुट पर, तंत्रिका नेटवर्क एक छवि प्राप्त करता है, और कुछ सचेत करने के लिए शुरू करने से पहले, यह समझना चाहिए कि दुनिया में क्या शामिल है। सरल परिदृश्यों का अध्ययन करते हुए, वह यह समझना सीखेंगी कि कौन सी वस्तुएं दुनिया में निवास करती हैं और उनके साथ बातचीत कैसे करें। चलो डैश के साथ शुरू करते हैं:
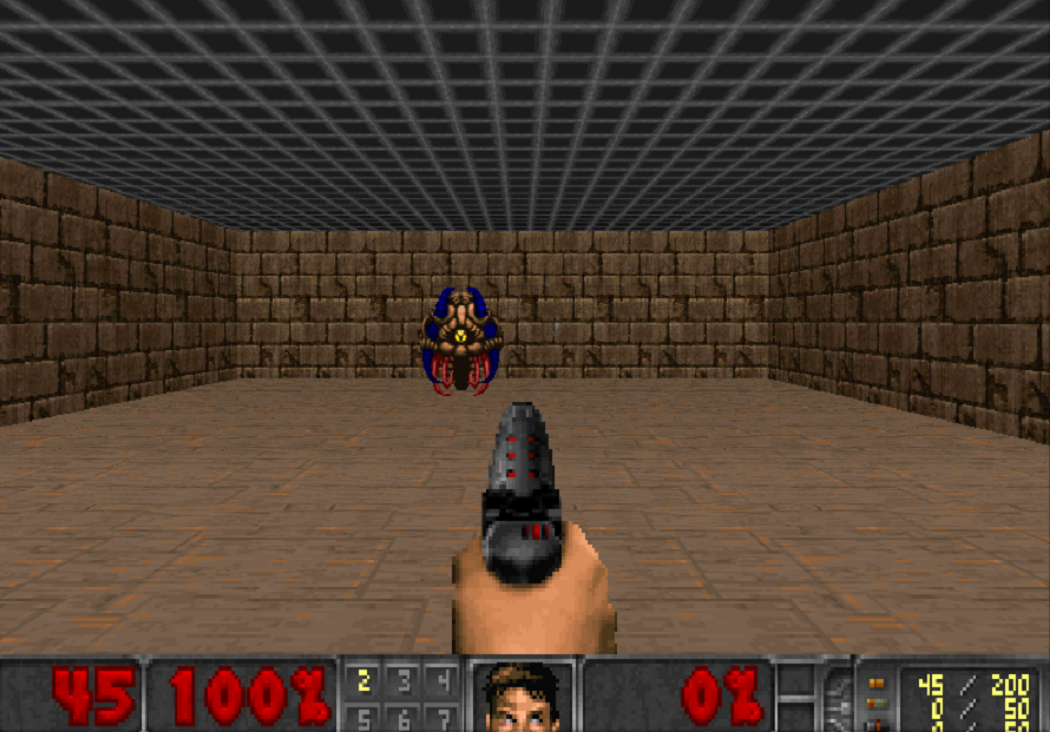
इस परिदृश्य में महारत हासिल करने पर, एजेंट समझ जाएगा कि दुश्मन हैं, और उन्हें गोली मार दी जानी चाहिए, क्योंकि आपको उनके लिए अंक मिलते हैं। फिर हम उसे एक ऐसे परिदृश्य में प्रशिक्षित करेंगे, जहां स्वास्थ्य लगातार कम हो रहा है, और आपको इसे फिर से भरने की आवश्यकता है।

यहां वह सीखेगा कि उसके पास स्वास्थ्य है और उसे फिर से भरने की आवश्यकता है, क्योंकि मृत्यु के मामले में एजेंट को नकारात्मक इनाम मिलता है। इसके अलावा, वह सीखेगा कि यदि आप विषय की ओर बढ़ते हैं, तो आप इसे एकत्र कर सकते हैं। पहले परिदृश्य में, एजेंट नहीं ले जा सका।
और अंतिम, तीसरे परिदृश्य में, चलो उसे खेल से नियमों पर प्रोग्राम किए गए बॉट के साथ शूट करने के लिए छोड़ दें ताकि वह अपने कौशल को बेहतर बना सके।

इस परिदृश्य में प्रशिक्षण के दौरान, एजेंट को मिलने वाले पुरस्कारों का सही चयन बहुत महत्वपूर्ण है। उदाहरण के लिए, यदि आप पराजित प्रतिद्वंद्वियों के लिए केवल एक इनाम देते हैं, तो संकेत बहुत कम होगा: यदि आसपास कुछ खिलाड़ी हैं, तो हम हर कुछ मिनट में अंक प्राप्त करेंगे। इसलिए, आइए उन पुरस्कारों के संयोजन का उपयोग करें जो पहले थे। एजेंट को हर उपयोगी कार्रवाई के लिए एक इनाम मिलेगा, चाहे वह स्वास्थ्य में सुधार हो, कारतूस का चयन करना या प्रतिद्वंद्वी को मारना।
नतीजतन, अच्छी तरह से चुने गए पुरस्कारों के साथ प्रशिक्षित एक एजेंट अपने अधिक कम्प्यूटेशनल रूप से विरोधियों की मांग से अधिक मजबूत है। 2016 में, इस तरह की प्रणाली ने दूसरे स्थान से बनाए गए आधे से अधिक अंकों के मार्जिन के साथ विजडम प्रतियोगिता जीती। उपविजेता टीम ने एक तंत्रिका नेटवर्क का भी उपयोग किया, केवल बड़ी संख्या में परतों और प्रशिक्षण के दौरान खेल इंजन से अतिरिक्त जानकारी के लिए। उदाहरण के लिए, एजेंट के क्षेत्र में दुश्मन हैं या नहीं, इसके बारे में जानकारी।
हमने समस्याओं को हल करने के दृष्टिकोण की जांच की है, जहां निर्णय लेना महत्वपूर्ण है। लेकिन इस दृष्टिकोण के साथ कई कार्य अनसुलझे रहेंगे। उदाहरण के लिए, खोज गेम मोंटेज़ुमा बदला।
यहां आपको पड़ोसी कमरों के दरवाजे खोलने के लिए चाबियाँ देखने की आवश्यकता है। हमें शायद ही कभी चाबियाँ मिलती हैं, और हम अक्सर कम भी कमरे खोलते हैं। विदेशी वस्तुओं से विचलित नहीं होना भी महत्वपूर्ण है। यदि आप सिस्टम को प्रशिक्षित करते हैं जैसा कि हमने पिछले कार्यों में किया था और पीटा दुश्मनों के लिए पुरस्कार देते हैं, तो यह केवल रोलिंग खोपड़ी को बार-बार खटखटाएगा और नक्शे की जांच नहीं करेगा। यदि आप रुचि रखते हैं, तो मैं एक अलग लेख में ऐसी समस्याओं को हल करने के बारे में बात कर सकता हूं।
आप 22 नवंबर को एआई सम्मेलन में व्लादिमीर इवानोव का भाषण सुन सकते हैं । कार्यक्रम की
आधिकारिक वेबसाइट पर एक विस्तृत कार्यक्रम और टिकट उपलब्ध हैं।
व्लादिमीर के साथ साक्षात्कार
यहाँ पढ़ें।