
किसी तरह, पावर बीआई में भाषाई विश्लेषण की समस्या को हल करना और उसी समय अपने
पिछले लेख के लिए उदाहरणों की तलाश में, मैंने उस समस्या को याद किया जिसे मैंने कई साल पहले एक्सेल में हल करने की कोशिश की थी: बड़ी संख्या में प्रश्नों के भाषाई विश्लेषण के लिए विश्लेषणात्मक प्रणाली में रूसी भाषा के शब्दकोश को लागू करना आवश्यक था। प्राकृतिक भाषा में। और मानक कार्यालय उपकरण का उपयोग करना वांछनीय था। अधिकांश लोग एक्सेल में इस कार्य को तुरंत कर लेंगे, और मैं एक बार उसी तरह चला गया। मैंने एक शब्दकोश के रूप में रूसी भाषा के खुले कोष (
http://opencorpora.org/ ) का उपयोग किया।
लेकिन निराशा ने मेरा इंतजार किया - शब्दकोश में 300 हजार शब्द रूपों, 5 मिलियन से अधिक प्रविष्टियाँ शामिल थीं, और एक्सेल के लिए यह सिद्धांत रूप में, एक असंभव राशि है। यहां तक कि अगर आप "बस" 1 मिलियन लाइनों को धक्का देते हैं, तो केवल एक बहुत ही रोगी व्यक्ति जो कभी भी जल्दी में नहीं होगा, उनके साथ या भगवान, मना करने के लिए किसी भी जोड़तोड़ को करने में सक्षम होगा, गणना। लेकिन इस बार मैंने कार्य के लिए अधिक उपयुक्त उपकरण निर्धारित करने का निर्णय लिया - पावर बीआई।
Power BI क्या है?
मुझे लगता है कि यह उत्पाद काफी हद तक पेशेवर समुदाय द्वारा कम करके आंका गया है। पावर बीआई व्यापार विश्लेषण उपकरण का एक सेट है जो उन उपयोगकर्ताओं के लिए बनाया गया था जो "स्तंभों में राशि को तोड़ते हैं" की तुलना में थोड़ा अधिक स्तर पर एक्सेल के मालिक हैं। यदि कोई व्यक्ति एक्सेल में मध्यम जटिलता के सूत्र लिखने में सक्षम है, तो वह एक दो शाम में पावर बीआई में मास्टर करेगा।
यह किसी प्रकार के आंतरिक प्रोग्रामिंग तर्क के साथ एक एकल उत्पाद नहीं है, लेकिन तीन घटकों की एक प्रणाली है:

- पावर क्वेरी यह एक ईटीएल है, जिसमें अपनी पूरी तरह कार्यात्मक प्रोग्रामिंग भाषा का उपयोग करके प्रश्नों को लिखना आवश्यक है - एम। निष्पक्षता में यह ध्यान दिया जाना चाहिए कि, सबसे अधिक संभावना है, एक साधारण उपयोगकर्ता को इस पर प्रोग्राम करने की संभावना नहीं है: अधिकांश फ़ंक्शन मेनू या विज़ार्ड के घटक इंटरफ़ेस में सीधे उपलब्ध हैं। M भाषा DAX क्वेरी भाषा (PowerPivot) से पूरी तरह से अलग है। हालाँकि, Microsoft उन्हें साथ लाया। यह विकास के दृष्टिकोण से कुछ समझ में आता है: ETL डेटा (जल्दी नहीं) की प्रारंभिक संतृप्ति और प्राप्त करने के लिए डिज़ाइन किया गया है, और DAX - गणना के लिए जो हमें इस डेटा (जल्दी) की कल्पना करने में मदद करता है। यही है, डेटा को निकालने और प्रारूपित करने की प्रक्रिया के लिए DAX फ्रंट एंड के लिए पावर क्वेरी के लिए बैकएंड के लिए है।
- पॉवरपिवट । XVelocity इंजन के आधार पर एक मेमोरी प्रोसेसिंग मॉड्यूल। DAX क्वेरी भाषा का उपयोग करता है, जो एक्सेल सूत्र भाषा के समान है।
- दृश्य घटक । यह उन प्रणालियों के अनुप्रयोगों के लिए बहुत उपयोगी है जहां आपको डेटा की कल्पना करने की आवश्यकता होती है: किसी कंपनी की वेबसाइट पर, या एक तकनीकी सहायता पोर्टल पर (उदाहरण के लिए, अनुरोध क्लाउड), या आंतरिक कॉर्पोरेट संसाधन पर। ऐसे उपकरण हैं जो पावर बीआई के बिना ऐसा कर सकते हैं, लेकिन उनमें से कई तब मदद नहीं करेंगे जब रिकॉर्ड की संख्या लाखों में हो और डेटा को किसी तरह एकत्र करने की आवश्यकता हो। और इस तरह के अन्य उपकरणों के साथ, पावर बीआई अपनी सादगी और स्मृति प्रसंस्करण में कम लागत के कारण प्रतिस्पर्धा करता है। यह स्पष्ट है कि यदि हम डेटा के टेराबाइट्स के बारे में बात कर रहे हैं, तो एक अलग दृष्टिकोण की आवश्यकता होगी। और ऐसे मामलों के लिए, Microsoft के पास पहले से ही कुछ है, लेकिन यह एक अलग लेख के लिए एक विषय है।
पहले चरण में सीखने की अवस्था बहुत तेजी से बढ़ती है: यदि आप एक्सेल में अच्छे हैं, तो पावर बीआई सुविधाओं का 80% एक छोटे से अध्ययन के बाद आपके लिए खुल जाएगा। यह एक बहुत शक्तिशाली उपकरण है, जिसका उपयोग करना काफी आसान है, लेकिन - एक निश्चित बिंदु तक। पूर्ण क्षमता पर इसका उपयोग करने के लिए, आपको पहले से ही M और DAX भाषाओं के अनुभव और गहन ज्ञान की आवश्यकता होगी।
Power BI डेस्कटॉप किसके लिए है?
यह किसके लिए उपयोगी हो सकता है? सबसे पहले, कोई भी व्यावसायिक उपयोगकर्ता जिन्हें बड़ी मात्रा में डेटा संसाधित करना और विश्लेषण करना पड़ता है जब एक्सेल अब सीमा तक सामना करने या करने में सक्षम नहीं है। मैं जोर देता हूं - पावर बीआई डेस्कटॉप
उपयोगकर्ताओं की एक विस्तृत श्रृंखला के लिए डिज़ाइन किया गया है
जो बहुत विविध कार्यों को हल करते हैं । उदाहरण के लिए, मेरे मामले में, यह कीवर्ड की आवृत्ति के बाद के निर्धारण के लिए 5 मिलियन पाठ प्रविष्टियों को सामान्य करने के बारे में था।
यह मांग में है जब प्रश्नावली, खोज इंजन प्रश्न, विज्ञापन, श्रुतलेख / निबंध, किसी प्रकार के सांख्यिकीय सरणियों आदि का प्रसंस्करण या वर्ग पहेली को सुलझाने के लिए ...
दिमित्री तुमाकिन के "पहचानकर्ता" पर एक
लेख में एक और मामला और कार्यान्वयन विकल्प माना जाता है। क्लासिक एक्सेल पर लागू, लेकिन मैक्रोज़ का उपयोग कर ...
पावर बीआई के इस आवेदन के लिए एक और लोकप्रिय परिदृश्य वर्तमान और पिछली अवधि के संकेतकों के अनुपात की गणना करना है। उदाहरण के लिए, हमारे पास पूर्व-एकत्रित राजस्व डेटा है, और आपको इसकी तुलना पिछली तिमाही, या वर्ष या इसी तरह की अवधि के दिनों से करनी होगी। और मैं अगले कॉलम में मूल्यों के रूप में तुलना के परिणाम को सम्मिलित करना चाहता / चाहती हूं, सूत्र नहीं। ऐसा लगता है कि एक्सेल के लिए सबसे सरल कार्य एक सरल तुलना सूत्र लिखना है और इसे कॉलम की सभी कोशिकाओं पर फैलाना है। लेकिन नहीं अगर आपके पास तालिका में कई मिलियन पंक्तियाँ हैं। डैक्स में ही यह कार्य एक्सेल की तुलना में और भी आसान है, लेकिन केवल पोस्ट-गणना की मदद से भी।
पावर बीआई का उपयोग करने के लिए कई अन्य व्यावहारिक परिदृश्य दिए जा सकते हैं, लेकिन आपको लगता है कि, पहले से ही सार समझ में आया है। बेशक, ये सभी कार्य एक प्रोग्रामर के लिए कोई समस्या नहीं हैं, जो मालिक हैं, उदाहरण के लिए, पायथन या आर, लेकिन ऐसे विशेषज्ञ एक्सेल विशेषज्ञों की तुलना में परिमाण के आदेशों के आधार पर एक छोटे हैं। एक्सेल में केवल सीमित संभावनाएं हैं, लेकिन पावर बीआई के साथ ऐसा नहीं है, जो DAX सूत्र भाषा का उपयोग करता है, जो कि एक्सेल फॉर्मूला भाषा के समान है, और मक्खी पर लाखों और लाखों रिकॉर्ड बनाने में सक्षम है। और फिर आपको रैम बढ़ाने की आवश्यकता है (कम से कम 100 तक, कम से कम 300 जीबी तक)।
हम तकनीकी सहायता प्रक्रिया अनुरोधों की मदद करते हैं
लेकिन वापस अपने काम पर। यह आवश्यक है कि कैसे तकनीकी सहायता शून्य रेखा स्वचालित रूप से उपयोगकर्ता के अनुरोधों के विषय का मूल्यांकन करेगी। इसके साथ शुरू करने के लिए, मैंने कुछ शब्द रूपों को अलग करने और सबसे महत्वपूर्ण विषयों को निर्धारित करने का फैसला किया, जो उपयोगकर्ता संदेशों में अपनी उपस्थिति की आवृत्ति से सबसे अधिक बार उठाते हैं।
स्रोत शब्दकोश एक साधारण पाठ फ़ाइल है जिसमें एक नियमित संरचना होती है और यह इस तरह दिखाई देती है:
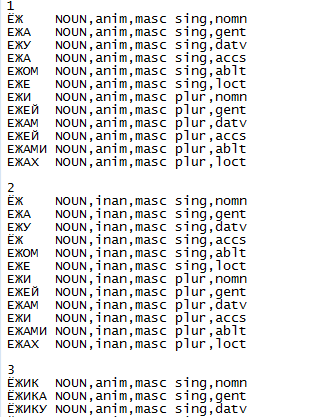
सांख्यिकीय उद्देश्यों के लिए, प्रत्येक शब्द के लिए प्रारंभिक रूप निर्धारित करना आवश्यक था: संज्ञा के लिए - नाममात्र मामले की एक संख्या, क्रियाओं के लिए - एक अनिश्चित रूप, आदि। प्रोग्रामर के लिए, यह कार्य सरल से अधिक सरल था: बाएं कॉलम में प्रत्येक शब्द के लिए, पत्राचार को उस रूप में ढूंढें, जो शब्दकोष में इस शब्द की संख्या का तुरंत अनुसरण करता है।
यह केवल औसत व्यवसाय उपयोगकर्ता है जो कि पायथन, विशेष उपकरण और विकास कौशल का मालिक नहीं है, स्व-विश्लेषिकी बीआई या इसी तरह के उपयोगकर्ता के अनुकूल उपकरणों का उपयोग किए बिना इस समस्या को हल करने में सक्षम नहीं होगा। इसके अलावा, यदि डेटा को अपनी आंतरिक आवश्यकताओं के लिए संसाधित करने की आवश्यकता है या कोई गोपनीय जानकारी नहीं है जिसे सुरक्षा की आवश्यकता है, तो इस मामले में पावर बीआई भी मुफ्त होगा *।
छिपा हुआ पाठ*) यह नि: शुल्क दर पर व्यक्तिगत उपयोग के लिए पावर बीआई डेस्कटॉप संस्करण और पावर बीआई सेवा संस्करण को संदर्भित करता है।
डेटा का विश्लेषण करने के लिए, मुझे 5 मिलियन रिकॉर्ड्स की तालिका में पावर क्वेरी में एक नए कॉलम को जोड़ने की जरूरत है, जिसे एक स्थान पर स्थानांतरित किया गया है। सबसे पहले, मैंने पावर क्वेरी का उपयोग करते हुए क्लासिक दृष्टिकोण को लागू करने का प्रयास किया, जो कि मूल पावर क्वेरी ऑनलाइन संदर्भ गाइड (पावर क्वेरी में लिखा गया) के लेखक मार्सेल बेग द्वारा पावर बीआई सामुदायिक पोर्टल पर
वर्णित है । लेख में दो अलग-अलग एल्गोरिदम प्रस्तावित हैं: एक मैट एलिंगटन, एक प्रसिद्ध गुरु और पावर बीआई ट्रेनर के विचारों से प्रेरित है, और दूसरा दृष्टिकोण एक अतिरिक्त फ़ंक्शन का उपयोग करके स्वयं मार्सेल का मूल विचार है। इस तथ्य के बावजूद कि उत्पादकता बढ़ाने के लिए मैंने स्रोत डेटा को पूरी तरह से कैश कर दिया है, दोनों दृष्टिकोणों को एक विशाल मात्रा में समय की आवश्यकता होती है - वे पहले से ही आठवें दिन चले गए थे, और प्रक्रिया पूरी नहीं हुई थी। स्रोत फ़ाइल का आकार 270 एमबी था, और संसाधित डेटा का वर्तमान आकार 17 टीबी के करीब था। मुझे यकीन है कि कुछ Power BI उपयोगकर्ताओं ने फ़ाइल स्रोत से डेटा लोड करने के लिए विंडो में ऐसे नंबर देखे हैं।
वॉल्यूम इतना सूज क्यों रहा है, यह स्पष्ट नहीं है; यहां तक कि सभी अभिलेखों का कार्टेशियन उत्पाद 16 Tb से बहुत कम है। यहाँ, आंतरिक ऑप्टिमाइज़र स्पष्ट रूप से बराबर नहीं था। और, उदाहरण के लिए, DAX- स्टूडियो पावर क्वेरी प्रश्नों को ट्रेस करने की अनुमति नहीं देता है, केवल DAX। हो सकता है कि कोई व्यक्ति पीक्यू ट्रबलशैपिंग के साथ अपने अनुभव को साझा करेगा?
पहली प्रक्रिया के पूरा होने की प्रतीक्षा किए बिना, मैंने एक अन्य मशीन पर निर्णय लिया कि एक स्व-लिखित क्वेरी के माध्यम से DAX का उपयोग करके समस्या को हल करने का प्रयास करें। अनुरोध पूरा हुआ ... लगभग 180 सेकंड में, और मेमोरी की खपत थोड़ी बढ़ गई।

DAX अनुरोध के लिए स्रोत कोड:
KeyWord =
CALCULATE(
TOPN(1;
CALCULATETABLE(
VALUES(ShiftedList[Word])
;ALLEXCEPT(ShiftedList;ShiftedList[Word Nr])
)
)//TOPN
)//CALCULATE
यही है, नए [KeyWord] कॉलम में प्रत्येक पंक्ति के लिए, [वर्ड] कॉलम का पहला मूल्य खोजा जाता है, जिसमें एक ही मूल शब्द प्रपत्र संख्या ([Word Nr] कॉलम) वाले सभी शब्दों के शब्द रूप होते हैं। जब तक स्रोत फ़ाइल का प्रारूप अपरिवर्तित रहता है, तब तक शब्दकोश के सभी बाद के रिलीज पर त्रुटियों के बिना अनुरोध पूरा होना चाहिए।
पावर क्वेरी में क्वेरी कोड, जो आवश्यक प्रारूप में स्रोत तालिका बनाता है, "स्वचालित रूप से" उत्पन्न हुआ और एक मिनट से भी कम समय में पूरा हुआ:

तीन मिनट में PowerPivot इंटरफ़ेस में कीवर्ड का एक स्तंभ बनने के बाद, Power BI इंटरफ़ेस में कोई भी शब्द फ़ॉर्म खोजने में 4 सेकंड से अधिक नहीं लगता है। इसके अलावा, आपके पसंदीदा Notepad ++ x64 में समान डेटा की एक नियंत्रण खोज में 20 सेकंड या अधिक समय लग सकता है। लेकिन यह एनपीपी के बगीचे में एक पत्थर नहीं है - पहले से चिह्नित डेटा के अनुसार पूरे डेटा सरणी की खोज करना अधिक कठिन (और लंबा) है।
वैसे, उपरोक्त डीएएक्स अनुरोध पहली बार पैदा नहीं हुआ था, और मध्यवर्ती विकल्पों ने सभी उपलब्ध मेमोरी का उपभोग किया, लंबे समय तक काम किया और डेटा त्रुटि या अप्रासंगिक परिणाम के साथ समाप्त हो गया।

नतीजतन, सहेजे गए PBIX फ़ाइल का आकार मूल पाठ शब्दकोश से 60% (112 एमबी) छोटा हो गया, लेकिन एक ही शब्दकोश के साथ ज़िप संग्रह के आकार का 4 गुना से अधिक।
पावर क्वेरी और DAX के बीच की लड़ाई पर लौटना: विभिन्न घटकों में एक ही ऑपरेशन की अवधि में अंतर बताता है कि पावर बीआई एक क्राउन नहीं है, जिसके खिलाफ कोई रिसेप्शन नहीं है। उसका अपना चरित्र और आवेदन की विशेषताएं हैं, जिसे अपने काम में ध्यान में रखा जाना चाहिए। वास्तव में, किसी भी उपकरण की तरह। और यहां तक कि मान्यता प्राप्त गुरुओं की सिफारिशों को सावधानी के साथ व्यवहार किया जाना चाहिए।
ऐसा लगता है कि नोबेल पुरस्कार विजेता रिचर्ड स्माली ने क्लार्क के पहले कानून को गलत बताते हुए कहा था: "जब विशेषज्ञ कहते हैं कि कुछ संभव है, तो वे शायद सही हैं (वे अभी पता नहीं है कि कब)। जब वे कहते हैं कि यह असंभव है, तो सबसे अधिक संभावना है कि वे गलत हैं। ”
परीक्षण मशीन के लक्षण:
प्रोसेसर: Intel Core i7 4770 @ 3.4 GHz (4 कोर)
रैम: 16 जीबी
ओएस: विंडोज 7 एंटरप्राइज SP1 x 64पावर बीआई प्रारूप में तैयार शब्दकोश
यहां से डाउनलोड किया जा सकता
है ।
और
यहाँ शब्दकोश का एक संशोधित ऑनलाइन संस्करण उपलब्ध है। आप इसके साथ अपने अवकाश पर वर्ग पहेली हल कर सकते हैं :)

... वैसे, फिर भी, कई साल पहले, एक्सेल में कार्य को हल किया गया था, हालांकि 100% नहीं। बस ग्रंथों के विश्लेषण के लिए, रूसी भाषा के पूरे कॉर्पस का उपयोग नहीं किया गया था, लेकिन आवृत्ति शब्दकोश। मूल पाठ सफाई के लिए, कई दसियों किलोबाइट के लिए
यहां उपलब्ध टॉप 100
आवृत्ति सूची में से कोई भी उपयुक्त है।
यूरी कोलमाकोव, विशेषज्ञ, समेकन और डेटा विज़ुअलाइज़ेशन सिस्टम विभाग, जेट इन्फोसिस्टम्स ( मैकको )