मैं अपाचे सोलर फुल-टेक्स्ट सर्च प्लेटफॉर्म पर आधारित अनुप्रयोगों के विकास में अपने अनुभव के बारे में बात करना चाहता हूं।
हमारा काम संपर्क केंद्रों के लिए एक भाषण विश्लेषण प्रणाली विकसित करना था। प्रणाली दो बुनियादी प्रौद्योगिकियों पर आधारित है: भाषण मान्यता और अनुक्रमित खोज। मान्यता के लिए, हमने अपने इंजनों का उपयोग किया, और अनुक्रमण और खोज के लिए, हमने सोल्र को चुना।
क्यों सोलर? हमने अनुक्रमित खोज इंजन के अपने स्वयं के तुलनात्मक अनुसंधान का संचालन नहीं किया, लेकिन
हमारे सहयोगियों की
राय की सावधानीपूर्वक जांच की। बेशक, चुनाव एलिस्टिक्स खोज या स्फिंक्स के पक्ष में किया जा सकता है, लेकिन, जाहिर है, सोलर के पक्ष में गठित हमारी परियोजना में सितारों, हमने इसे "देखा"। पहले से ही परियोजना के दौरान, हमने निर्धारित किया कि सोल में उपलब्ध सेटिंग्स हमारे कार्यों के लिए कॉन्फ़िगर करने के लिए पर्याप्त हैं।
हमारे प्रोजेक्ट की विशेषताएं
सिस्टम को ग्राहक कॉल के विश्लेषण के लिए विकसित किया गया था, जो सेवा की गुणवत्ता की निगरानी के लिए संपर्क केंद्र में दर्ज किए जाते हैं। यह ध्वनि का विश्लेषण नहीं करता है, लेकिन संवाद की स्वचालित मान्यता के परिणामस्वरूप प्राप्त पाठ। मान्यता प्राप्त भाषण के ग्रंथ मूल रूप से उन ग्रंथों से भिन्न होते हैं जो हम नियमित रूप से वेबसाइटों या ई-मेल पर मुठभेड़ करते हैं। यहां तक कि 100% मान्यता सटीकता के साथ, मान्यता प्राप्त सहज भाषण के ग्रंथों का कोई मतलब नहीं हो सकता है।
यह दो मुख्य कारकों के कारण है। सबसे पहले, मौखिक भाषण में, अशाब्दिक और चेहरे के भाव बहुत बार उपयोग किए जाते हैं, जो पाठ में पहचाने नहीं जाते हैं, लेकिन जो कहा गया है उसे समझने के लिए महत्वपूर्ण हैं। दूसरे, भाषण में, भाषा संरचनाओं के संक्षिप्तीकरण और चूक का लगातार उपयोग किया जाता है, जिसे एक संचारी स्थिति के संदर्भ से बहाल किया जा सकता है। भाषाविज्ञान में इस घटना को एक दीर्घवृत्त कहा जाता है।
अपनी स्वयं की आंखों से देखने के लिए, इसकी सभी विशेषताओं के साथ मान्यता प्राप्त भाषण का पाठ, ध्वनि बंद होने के साथ यूट्यूब पर वीडियो के लिए स्वचालित उपशीर्षक देखें। यह इस सामग्री के बारे में है, सामग्री भाषण एनालिटिक्स सिस्टम के इनपुट पर जाती है।
जटिल क्वेरी
यद्यपि सोलर मानक
सशर्त बयानों और
समूहों का समर्थन करता है, अक्सर ये क्षमताएं विश्लेषकों के लिए सभी परिदृश्यों को लागू करने के लिए पर्याप्त नहीं हैं।
अक्सर, विश्लेषक को सोलर इंडेक्स में शामिल नहीं होने वाले मापदंडों के साथ एक क्वेरी बनाने की आवश्यकता होती है। उदाहरण के लिए, बातचीत के अंतिम 30 सेकंड में बोले गए "धन्यवाद" सभी शब्दों को खोजें। शब्द Solr द्वारा अनुक्रमित किए जाते हैं, लेकिन कोई अस्थायी शब्द स्थिति नहीं है। हम ऐसे प्रश्नों को "जटिल" कहते हैं - क्वेरी जिसमें सोलर इंडेक्स के पैरामीटर और किसी अन्य डेटा चयन पैरामीटर शामिल हैं जो सोलर इंडेक्स में शामिल नहीं हैं।
एक विश्लेषक प्रश्न कैसे बनाता है?
विश्लेषक के पास सोलर इंडेक्स की संरचना के बारे में कोई विचार नहीं है, यह उसके लिए महत्वपूर्ण है कि वह कॉल के फोनग्राम के सभी गुणों और उनके पाठ टेपों को खोजे और काटे। इसलिए, विश्लेषक के लिए "जटिल क्वेरी" की अवधारणा विशुद्ध रूप से व्यावहारिक है: प्रश्न जिसमें कई चयन पैरामीटर हैं, या प्रश्न एक पदानुक्रम में व्यवस्थित हैं।
सेट थ्योरी की भाषा में विश्लेषक की क्रियाओं के बारे में बताते हुए, हम कह सकते हैं कि प्रश्नों की सहायता से विश्लेषक अलग-अलग उप-वर्गों के बीच संबंधों की खोज करता है: चौराहों, अंतर, परिवर्धन। पदानुक्रमित प्रश्नों का उपयोग करते हुए, विश्लेषक अपनी संरचना के विस्तार के आवश्यक स्तर तक डेटा सरणी को पार्स करता है।
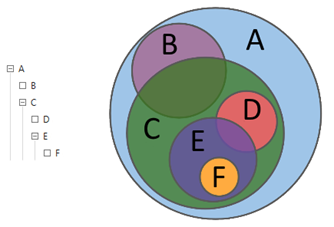 चित्रा 1. पदानुक्रमित प्रश्न
चित्रा 1. पदानुक्रमित प्रश्नचित्र 2 एक जटिल क्वेरी का एक क्लासिक उदाहरण दिखाता है जिसमें पाठ और संख्यात्मक चयन मानदंड दोनों शामिल हैं।
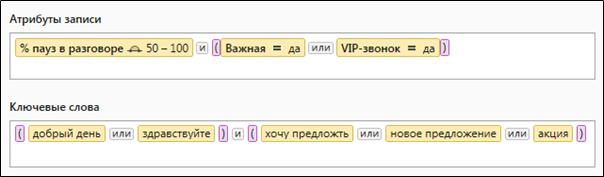 चित्रा 2. एक जटिल क्वेरी जिसमें मात्रात्मक और शाब्दिक डेटा चयन पैरामीटर हैं
चित्रा 2. एक जटिल क्वेरी जिसमें मात्रात्मक और शाब्दिक डेटा चयन पैरामीटर हैंसोल के लिए प्रश्न क्या दिखते हैं?
चित्र 1 में क्वेरी
B के उदाहरण का उपयोग करके Solr में किसी क्वेरी को निष्पादित करने के लिए सामान्य तंत्र पर विचार करें। जैसा कि हम देख सकते हैं, क्वेरी
B के पास एक पैरेंट क्वेरी
A है , दूसरे शब्दों में
B⊆A । भाषण विश्लेषिकी में, एक अनुरोध पूरा नहीं किया जा सकता है, जबकि इसके "माता-पिता" में से कम से कम एक अप्रभावित है। इस प्रकार, क्वेरी
ए को पहले निष्पादित किया जाता है, और उसके बाद ही
बी। जाहिर है,
बी में क्वेरी
ए की शर्तें होनी चाहिए
।पहली बात जो दिमाग में आती है, वह दोनों प्रश्नों की शर्तों को
AND माध्यम से संयोजित करना और इसे
query में पेस्ट करना है:
q=key:A AND key:Bहालाँकि, यदि हम केवल एक
query में सभी लगातार प्रश्नों को जोड़ते हैं, तो यह बड़ा होगा, यह प्रत्येक क्वेरी के लिए अलग होगा और इसकी संपूर्णता में गणना की जाएगी। इसके अलावा, स्थितियां क्वेरी
B के परिणामों की प्रासंगिकता को प्रभावित करेंगी, जो वांछनीय नहीं होगा।
चलिए
FilterQuery रूप में मूल प्रश्नों को जोड़ने की कोशिश करते हैं। इस स्थिति में, क्वेरी
A गैर-प्रासंगिकता से प्रभावित नहीं होगी और हम उम्मीद कर सकते हैं कि यह पहले ही पूरा हो चुका है और इसके परिणाम कैश में हैं। इस प्रकार, सोलर को केवल क्वेरी
बी की गणना करनी होगी, जबकि सोलर हमारे द्वारा आवश्यक तरीके से परिणामी चयन को छाँटेगा:
q=keyword:B &fq=keyword:Aयदि हम सोल के अनुरोध के प्रारूप पर योजनाबद्ध तरीके से विचार करते हैं, तो हम दो मुख्य संस्थाओं को अलग कर सकते हैं:
MainQuery - मुख्य क्वेरी पैरामीटर के एक सेट के साथ जो दस्तावेज़ को संतुष्ट करना चाहिए। उदाहरण के लिए, विनम्र ऑपरेटरों के लिए एक खोज अनुरोध इस तरह दिखाई देगा: text_operator: ” ” ।
इसका अर्थ है कि खोज दस्तावेज़ के text_operator फ़ील्ड में वाक्यांश “ ” होना चाहिए
FilterQuery - अतिरिक्त फ़िल्टर का एक सेट जो परिणामी चयन को सीमित करता है। FilterQuery प्रारूप FilterQuery मेल खाता है
Main और
Filter में अनुरोध को विभाजित करने से आपको निम्न की अनुमति मिलती है:
- स्पष्ट रूप से इंगित करें कि कौन से क्वेरी पैरामीटर को चयन में दस्तावेज़ की रैंक को प्रभावित करना चाहिए, और जो परिणामी चयन में केवल चयन के लिए काम करते हैं। दस्तावेज़ों के रैंक के निर्माण के लिए प्रासंगिकता की गणना तब की जाती है जब MainQuery क्वेरी के हिस्से को निष्पादित किया जाता है, और जब
FilterQuery क्वेरी के हिस्से को FilterQuery तो क्वेरी शर्तों को पूरा नहीं करने वाले दस्तावेज़ - खोज इंजन पर लोड को काफी कम कर देता है, क्योंकि
FilterQuery गणनाओं के बाद प्राप्त किए गए परिणामस्वरूप नमूना पूरी तरह से कैश हो गया है, जबकि MainQuery गणना के परिणाम केवल 50 मानों के रैंक में पहले वाले के लिए कैश में संग्रहीत किए जाते हैं
MainQuery और
FiletrQuery Solr के कार्यों पर अलग-अलग प्रभाव
FiletrQuery हैं। उदाहरण के लिए,
हाइलाइटिंग के लिए, प्रासंगिक दस्तावेज़ टुकड़े को हाइलाइट करने के लिए जिम्मेदार फ़ंक्शन, केवल
MainQuery , और
FilterQuery पैरामीटर
highlighting नहीं है। यह तर्कसंगत है, क्योंकि प्रासंगिकता की गणना
MainQuery क्वेरी के हिस्से में की
MainQuery । यह वह
highlighting परिणाम है जो "हैलो" और "सेवाओं" शब्दों के साथ ग्रंथों की वास्तविक खोज में दिखता है।
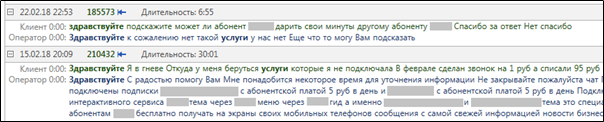 चित्रा 3. एक
चित्रा 3. एक MainQuery क्वेरी को पूरा करने के बाद प्रासंगिक शब्दों के लिए हाइलाइटिंग।
सोलर में जटिल क्वेरी
चलो एक विनम्र ऑपरेटर के उदाहरण पर वापस जाते हैं। इस उदाहरण में, हमने ऑपरेटर के भाषण में "अच्छी दोपहर" वाक्यांश की उपस्थिति से उपयुक्त कॉल का निर्धारण किया, लेकिन उस समय अंतराल को इंगित नहीं किया जिसमें बातचीत की शुरुआत या अंत के सापेक्ष कीवर्ड खोजना है।
ऐसा लगता है कि इसके लिए आवश्यक सब कुछ है - टेलीफोन वार्तालाप के पाठ प्रतिलेख में प्रत्येक शब्द के लिए टाइमस्टैम्प शामिल है, साथ ही साथ यह संवाद में कौन से प्रतिभागियों के बारे में जानकारी है। इस डेटा का उपयोग खोज में भी किया जा सकता है।
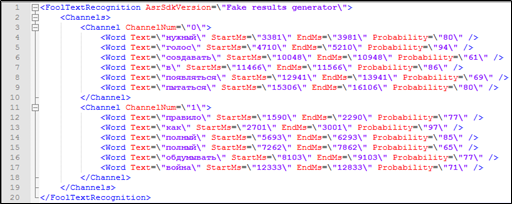 चित्रा 4. मार्कअप के साथ पाठीय एन्क्रिप्शन का एक टुकड़ा जो सोलर इंडेक्स में शामिल नहीं है: स्पीकर की संबद्धता, टाइमस्टैम्प।
चित्रा 4. मार्कअप के साथ पाठीय एन्क्रिप्शन का एक टुकड़ा जो सोलर इंडेक्स में शामिल नहीं है: स्पीकर की संबद्धता, टाइमस्टैम्प।लेकिन सोल के लिए एक खोज क्वेरी कैसे संसाधित करें, यदि गैर-अनुक्रमित पैरामीटर क्वेरी में शामिल हैं - जिस समय शब्द का उच्चारण किया जाता है?
इस समस्या को हल करने के दो स्पष्ट तरीके हैं:
- सोलर इंडेक्स में गैर-अनुक्रमित पैरामीटर जोड़ें। इसी समय, मेमोरी की खपत थोड़ी बढ़ जाएगी, लेकिन सूचकांक काफी भारी हो जाएगा
- गैर-सूचकांकीय मापदंडों द्वारा डेटा का चयन इसकी सेवा का उपयोग करके किया जाना चाहिए, और इस तरह के चयन के बाद प्राप्त दस्तावेजों के संग्रह में, सोलर इंडेक्स का उपयोग करके खोज करें। इसी समय, मेमोरी की खपत पहले मामले की तुलना में काफी अधिक होगी, लेकिन प्रदर्शन अनुमानित होगा
हमने दूसरा विकल्प चुना है। ऐसा करने के लिए, हमने एक ऐसी सेवा विकसित की है जो किसी भी तार्किक और संख्यात्मक मापदंडों वाले अनुरोधों द्वारा संग्रह की गणना करती है जो सोलर इंडेक्स में शामिल नहीं हैं। इस सेवा के काम के परिणामस्वरूप, संग्रह का वह हिस्सा जो अनुरोध को संतुष्ट नहीं करता था, एक विशेष टैग ("बच गया") के साथ चिह्नित किया गया था और फिर क्वेरी परिणामों की गणना में भाग नहीं लिया था।
कल्पना करें कि हम उस क्वेरी
B पर खोज पर प्रतिबंध लगाना चाहते हैं जिसे हम पहले से ही जानते हैं, केवल संवाद के पहले 30 सेकंड में। पहले चरण में, हम
बी को एक साधारण क्वेरी के रूप में निष्पादित करते हैं, फिर "स्क्रीन" शब्द जो चयनित सीमा से आगे जाते हैं ताकि वे सोलर इंडेक्स में न आएं, लेकिन साथ ही, हम उनसे मूल दस्तावेज़ को पुनर्स्थापित कर सकते हैं। परिणामस्वरूप दस्तावेजों को एक अलग सोलर संग्रह में रखा गया है और इस पर क्वेरी
बी की खोज फिर
से शुरू हो गई है।
यहाँ मुझे कहना होगा कि बातचीत की शुरुआत या अंत में प्रतिबंध फूल हैं, जामुन माता-पिता के अनुरोध के परिणामों पर प्रतिबंध हैं। इस तरह के अनुरोध के निष्पादन पर विचार करें।
कल्पना करें कि हमारे दस्तावेजों में संख्याओं के साथ गेंदें हैं। आइए "5" के दाईं ओर दो से अधिक गेंदों में स्थित सभी गेंदों को "6" खोजने की कोशिश करें।
आपको पहले ही पता चल गया था कि बॉल नंबर सोलर इंडेक्स में शामिल हैं, और गेंदों के बीच कोई दूरी नहीं है।
|  |
"6" और "5" गेंदों के साथ सभी दस्तावेज खोजें। MainQuery रूप में MainQuery गेंदों "5" के लिए एक क्वेरी का उपयोग करते हैं, और "6" के लिए एक क्वेरी हम FilterQuery को भेज FilterQuery । परिणामस्वरूप, सोलर खोज परिणामों में "5" गेंदों को उजागर करेगा, जो अगले चरण में हमारे जीवन को बहुत सरल करेगा। | 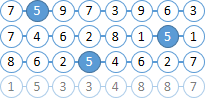 |
| हम उन सभी गेंदों को छोड़ देते हैं, जो "5" से वांछित दूरी पर हैं। प्राप्त दस्तावेजों (वांछित गेंदों के साथ दस्तावेज) को एक अलग संग्रह में रखा जाएगा। |  |
चलो परिणामस्वरूप संग्रह में गेंदों पर FilterQuery 6 "निष्पादित करें", परिणाम वह दस्तावेज है जिसकी हम FilterQuery कर रहे हैं। |  |
व्यवहार में, गेंदें 5 और 6 आमतौर पर उन प्रश्नों को छिपाती हैं जो उनके शाब्दिक प्रतिनिधित्व में कई स्क्रीन पर कब्जा कर लेते हैं। मुझे खुशी है कि हमने इस खोज को व्यर्थ नहीं किया - विश्लेषकों ने अक्सर माता-पिता के प्रतिबंधों के साथ प्रश्नों का उपयोग किया।
निष्कर्ष
हमने क्या सीखा, हमने क्या सीखा और परियोजना के परिणामस्वरूप हमने क्या हासिल किया?
हम जानते हैं कि विभिन्न प्रकार के डेटा के साथ काम करने के लिए सोलर का प्रभावी ढंग से उपयोग कैसे किया जाता है, हम सोल को उन मापदंडों के साथ प्रश्नों को संसाधित करने के लिए "सिखा" सकते हैं जो इसके खोज सूचकांक में शामिल नहीं हैं।
हमने उच्च लोड के तहत ऑपरेटिंग एक औद्योगिक वॉयस एनालिटिक्स सिस्टम विकसित किया है: विश्लेषकों के जटिल खोज प्रश्नों की गणना पांच मिलियन पाठ दस्तावेज़ों के नमूनों के लिए की जाती है। यह संभव है और अधिक है, लेकिन कोई व्यावहारिक आवश्यकता नहीं थी। विश्लेषक का सामान्य कार्य नमूना मान्यता प्राप्त फोन कॉल के लगभग 500 हजार ग्रंथों तक है, और कुल कॉल की संख्या 15 मिलियन तक पहुंच सकती है।
संपर्क केंद्रों में हमारे ग्राहकों के लिए, सिस्टम एक बहुत अलग प्रकृति के विश्लेषण के लिए अभूतपूर्व अवसर प्रदान करता है: विषयों का विश्लेषण और अनुरोधों का कारण, ग्राहकों की संतुष्टि का विश्लेषण और कई अन्य।
अब हम अपने एनालिटिक्स के नए स्रोतों को जोड़ रहे हैं - ऑपरेटरों के साथ ग्राहकों के टेक्स्ट चैट। हम संपर्क केंद्र के सभी चैनलों पर क्लाइंट कॉल की एनालिटिक्स के लिए एक एकल एप्लिकेशन को लागू करते हैं: फोन, चैट, साइटों पर फॉर्म आदि।
हमें आपके सवालों का जवाब देने में खुशी होगी।
आपका धन्यवाद
पी एस सोलर एक बहुत ही मुश्किल काम है और अच्छे परिणाम प्राप्त करने के लिए अच्छी ट्यूनिंग की आवश्यकता होती है। हम निम्नलिखित लेखों में इस क्षेत्र में अपने अनुभव के बारे में बताएंगे।