
पिछले दिसंबर में, अल्फ़ाज़ेरो कृत्रिम बुद्धि कंपनी डीपमाइंड का उपयोग करके एक नए शतरंज इंजन की अविश्वसनीय शक्ति के बारे
में समाचारों की लहर थी। आज उन्होंने इस इंजन के एक अद्यतन संस्करण के लिए आश्चर्यजनक परिणाम जारी किए।
परिणाम फिर से कोई संदेह नहीं छोड़ते हैं कि अल्फ़ाज़ेरो दुनिया में सबसे मजबूत शतरंज इंजनों में से एक है।
अपडेटेड अल्फाज़ेरो ने एक नए मैच में स्टॉकफिश 8 को 1000 मैचों के साथ हराया, जिसमें 155 जीत, 6 हार, 839 ड्रा रहे।
अल्फ़ाज़ेरो ने स्टॉकफ़िश को खेल की एक श्रृंखला में असमान समय पर नियंत्रण के साथ मात दी, पारंपरिक इंजन को भी 10 बार की बाधा से हराया।
दीपमाइंड के अनुसार, अतिरिक्त मैचों में, नए अल्फ़ाज़ेरो ने 13 जनवरी, 2018 को स्टॉकफ़िश के "नवीनतम विकास संस्करण" को पीछे छोड़ दिया, जो लगभग समान परिणाम दिखा रहा था, जैसा कि स्टॉकफ़िश 8 के खिलाफ मैच में था।
डीपमाइंड के अनुसार, उनके मशीन लर्निंग इंजन ने भी "स्टॉकफिश वैरिएंट के खिलाफ सभी मैच जीते, जो एक मजबूत पहली पुस्तक का उपयोग करता है।" एक पहली पुस्तक को जोड़ने से स्टॉकफिश को मदद मिली, जिसने आखिरकार अल्फा ज़ीरो के काले होने पर बहुत सारे गेम जीते, लेकिन मैच जीतने के लिए पर्याप्त नहीं था।
परिणाम जर्नल साइंस
में एक लेख में प्रकाशित किए गए थे और चयनित
शतरंज मीडिया द्वारा प्रदान किए गए थे।
2018 की शुरुआत में 1000 खेलों का मैच आयोजित किया गया था। मैच में, अल्फाज़ेरो और स्टॉकफ़िश को प्रत्येक खेल के तीन घंटे दिए गए और प्रति सेकंड 15-सेकंड का लाभ दिया गया। यह समय नियंत्रण पिछले साल के मैच के परिणामों के खिलाफ सबसे बड़ी दलीलों में से एक को अप्रचलित करने की संभावना है, अर्थात् 2017 में, प्रति मिनट एक मिनट का नियंत्रण अल्फ़ाज़ेरो के लिए एक मजबूत लाभ था।
तीन घंटे के साथ-साथ 15 सेकंड की वृद्धि के साथ, इस तरह के तर्क का कोई मतलब नहीं है, क्योंकि यह किसी भी शतरंज इंजन के लिए खेलने की एक बड़ी मात्रा है। असमान समय वाले खेलों में, अल्फा-ज़ीरो 10-टू -1 के समय अनुपात के साथ भी हावी था। स्टॉकफिश ने केवल 30-टू -1 अनुपात में जीतना शुरू किया।
असमान समय के साथ खेलों में अल्फ़ाज़ेरो परिणाम बताते हैं कि यह न केवल किसी भी पारंपरिक शतरंज इंजन की तुलना में अधिक मजबूत है, बल्कि एक अधिक कुशल चाल खोज का भी उपयोग करता है। डीपमाइंड के अनुसार, अल्फाज़ेरो मोंटे कार्लो ट्री खोज का उपयोग करता है और स्टॉकफिश के लिए 60 मिलियन की तुलना में प्रति सेकंड लगभग 60,000 पदों का अध्ययन करता है।
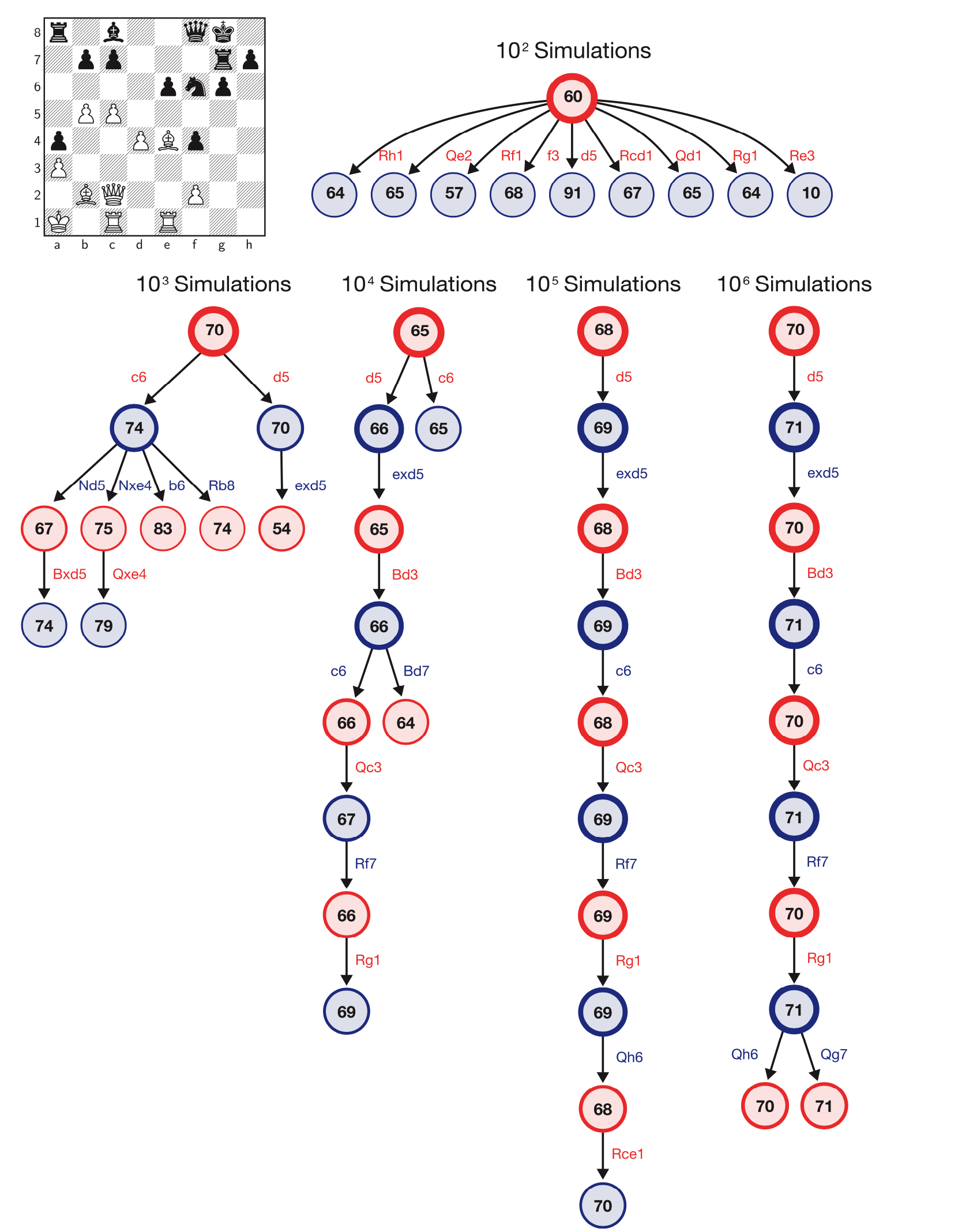 अल्फ़ाज़ेरो खोज एल्गोरिथ्म चित्रण चलता है। विज्ञान में एक लेख से दीपमिन्द की छवि।
अल्फ़ाज़ेरो खोज एल्गोरिथ्म चित्रण चलता है। विज्ञान में एक लेख से दीपमिन्द की छवि।लेख के अनुसार, अपडेटेड अल्फ़ाज़ेरो एल्गोरिथ्म तीन जटिल खेलों में समान है: शतरंज, शोगी और गो। अल्फाज़ेरो का यह संस्करण सरल प्रशिक्षण नियमों के साथ शुरू होने वाले, आत्म-प्रशिक्षण के घंटों के बाद सभी तीन खेलों के सर्वश्रेष्ठ कंप्यूटर इंजनों को हराने में सक्षम था।
DeepMind ने मैच से 210 गेम जारी किए हैं, जिन्हें आप
यहां डाउनलोड कर सकते
हैं ।
अल्फाज़ेरो के नए संस्करण ने खुद को शतरंज खेलने के लिए प्रशिक्षित किया है, खेल के नियमों के साथ शुरू करके, अपने तंत्रिका नेटवर्क को लगातार अपडेट करने के लिए मशीन सीखने के तरीकों का उपयोग कर रहा है। डीपमाइंड के अनुसार, 5,000 टीपीयू (Google टेंसर प्रोसेसर, एआई के लिए विशेष एकीकृत सर्किट) का उपयोग स्वतंत्र खेलने के लिए गेम के पहले सेट को उत्पन्न करने के लिए किया गया था, और फिर 16 टीपीयू का उपयोग तंत्रिका नेटवर्क को प्रशिक्षित करने के लिए किया गया था।
शतरंज में कुल प्रशिक्षण का समय खरोंच से नौ घंटे था। डीपमाइंड के अनुसार, नए अल्फ़ाज़ेरो को स्टॉकफिश को पार करने के लिए सिर्फ चार घंटे के प्रशिक्षण की आवश्यकता थी; नौ घंटे में, वह विश्व शतरंज चैंपियन से बहुत आगे था।
खेलों के लिए, स्टॉकफिश ने 44 प्रोसेसर का इस्तेमाल किया, जबकि अल्फाज़ेरो ने चार टीपीयू और 44 प्रोसेसर कोर के साथ एक मशीन का इस्तेमाल किया।
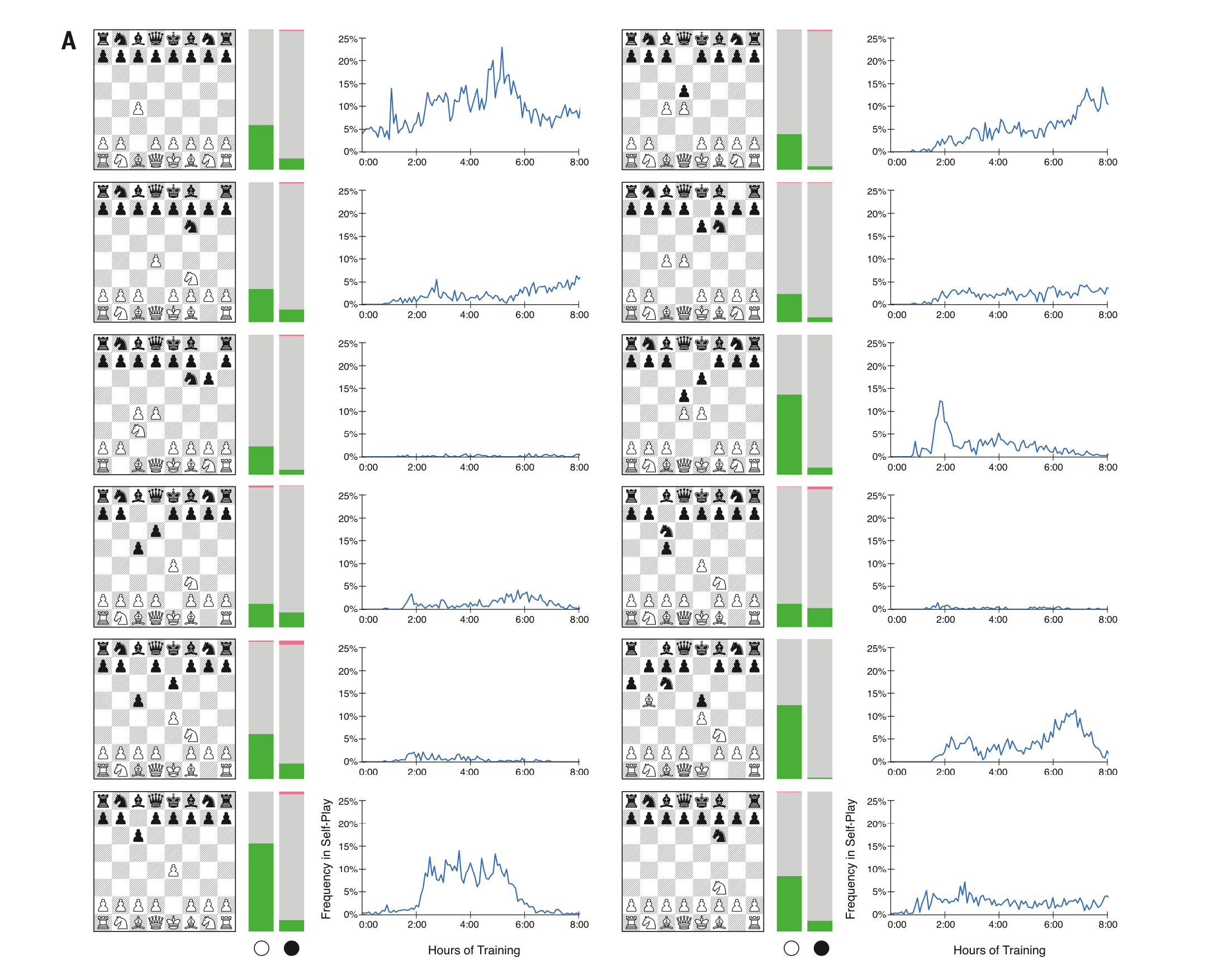 अल्फ़ाज़ेरो बनाम स्टॉकफ़िश के परिणामस्वरूप इसके सबसे लोकप्रिय डेब्यू हैं। बाईं ओर, अल्फाज़ेरो सफेद निभाता है; दाईं ओर - काला।
अल्फ़ाज़ेरो बनाम स्टॉकफ़िश के परिणामस्वरूप इसके सबसे लोकप्रिय डेब्यू हैं। बाईं ओर, अल्फाज़ेरो सफेद निभाता है; दाईं ओर - काला।दीपमिन्द ने स्वयं लेख में अपने कार्यक्रम की अनूठी खेल शैली का उल्लेख किया:
"कई खेलों में, अल्फ़ाज़ेरो ने एक दीर्घकालिक रणनीतिक लाभ के लिए टुकड़ों का बलिदान किया, यह सुझाव देते हुए कि यह पिछले शतरंज कार्यक्रमों में उपयोग किए गए नियम-आधारित रेटिंग की तुलना में अधिक प्रासंगिक स्थिति रेटिंग है," दीपमाइंड शोधकर्ताओं ने कहा।
एआई ने अल्फ़ाज़ेरो के तीन अलग-अलग खेलों में एक ही संस्करण का उपयोग करने के महत्व पर जोर दिया, इसे समग्र गेम इंटेलिजेंस में एक सफलता के रूप में बताया।
"ये परिणाम हमें कृत्रिम बुद्धिमत्ता की लंबे समय से चली आ रही महत्वाकांक्षाओं को पूरा करने के करीब लाते हैं: एक आम गेमिंग सिस्टम जो किसी भी खेल में महारत हासिल करना सीख सकता है," डीपमाइंड के शोधकर्ताओं ने कहा।