!
«Data scientist», . , «Feature Engineering ».
— , , Machine/Deep learning , .
. , (, ), , . Jupyter Notebook.
Kaggle ( «», Data Science). ,
.
, . , , . Training Test. — Survival (/ ; 0 = No, 1 = Yes).
:
- ;
- ;
- ( );
- ;
- ;
- .
, : , . .
:
- train.csv — training set — . — survival — 0 ( )/1 ();
- test.csv — test set — . . kaggle ;
- gender_submission.csv — , kaggle.
- :
- train.csv.
- .
- .
- .
- , train.csv.
- परिवर्तन विधि निर्धारण और मॉडल।
- पाइपलाइन का उपयोग करके test.csv में समान रूपांतरण लागू करना।
- Test.csv पर मॉडल का अनुप्रयोग।
- एप्लिकेशन रिजल्ट फ़ाइल को उसी स्वरूप में सहेजना जैसे कि लिंग_सुविधा.एससीवीवी।
- परिणाम केगल प्लेटफॉर्म पर भेजा जा रहा है।
वेबिनार का व्यावहारिक हिस्सापहली बात यह है कि डाटासेट को पढ़ने और स्क्रीन पर हमारे डेटा को प्रदर्शित करने के लिए आवश्यक था:
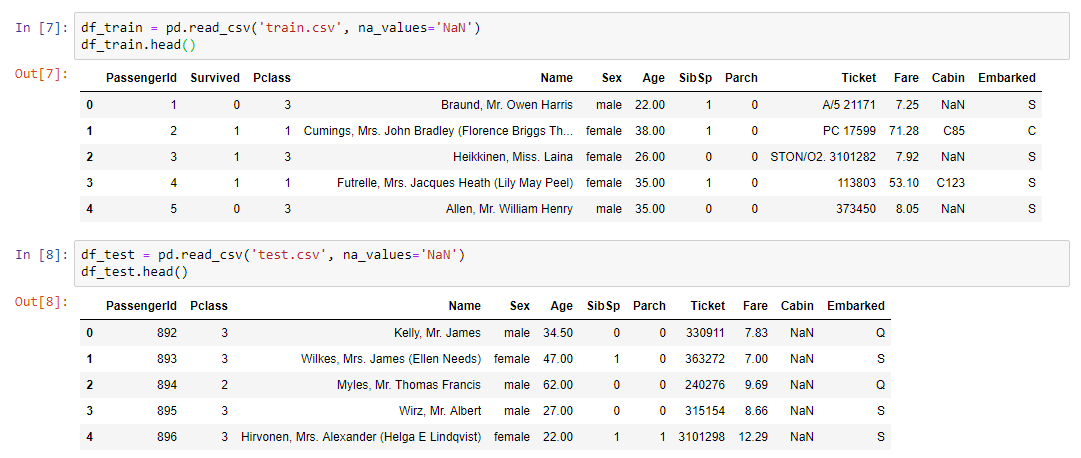
डेटा विश्लेषण के लिए, एक अल्पज्ञात, बल्कि उपयोगी प्रोफाइलिंग लाइब्रेरी का उपयोग किया गया था:
pandas_profiling.ProfileReport(df_train)प्रोफाइलिंग पर अधिकयह लाइब्रेरी वह सब कुछ करती है जो डेटा के बारे में जानकारी के बिना एक प्राथमिकताओं में किया जा सकता है। उदाहरण के लिए, डेटा पर आंकड़े प्रदर्शित करें (कितने चर और वे किस प्रकार हैं, कितनी पंक्तियाँ हैं, मान गायब हैं, आदि)। इसके अलावा, प्रत्येक चर के लिए अलग-अलग आँकड़े न्यूनतम और अधिकतम, एक वितरण ग्राफ और अन्य मापदंडों के साथ दिए गए हैं।
जैसा कि आप जानते हैं, एक अच्छा मॉडल बनाने के लिए, आपको उस प्रक्रिया में तल्लीन करने की आवश्यकता है जिसे हम अनुकरण करने की कोशिश कर रहे हैं, और यह समझ सकते हैं कि प्रमुख विशेषताएं क्या हैं। इसके अलावा, हमारे डेटा में हमेशा से ही वह सब कुछ है जिसकी आवश्यकता है, और, अधिक सटीक रूप से, लगभग कभी भी उनमें सब कुछ आवश्यक नहीं है, पूरी तरह से हमारी प्रक्रिया का निर्धारण और निर्धारण करता है। एक नियम के रूप में, हमें हमेशा कुछ को संयोजित करने की आवश्यकता होती है, शायद अतिरिक्त विशेषताएं जोड़ें जो कि डेटासेट में प्रतिनिधित्व नहीं करते हैं (उदाहरण के लिए, मौसम का पूर्वानुमान)। यह उस प्रक्रिया को समझने के लिए है जिसे हमें डेटा विश्लेषण की आवश्यकता है, जिसे प्रोफाइलिंग लाइब्रेरी का उपयोग करके किया जा सकता है।
गुम मानअगला कदम लापता मूल्यों की समस्या को हल करना है, क्योंकि ज्यादातर मामलों में डेटा पूरी तरह से भरा नहीं है।
इस समस्या के लिए निम्नलिखित समाधान उपलब्ध हैं:
- लापता मानों के साथ पंक्तियों को हटा दें (ध्यान रखें कि आप कुछ महत्वपूर्ण मूल्यों को खो सकते हैं);
- एक चिह्न हटाएं (यदि उस पर बहुत कम डेटा है तो प्रासंगिक है);
- कुछ और (औसत, औसत ...) के साथ लापता मूल्यों को बदलें।
भरण विधि का उपयोग करते हुए एक साधारण रूपांतरण का एक उदाहरण, जो माध्य चर के मूल्यों को केवल उन कोशिकाओं को प्रदान करता है जो भरे नहीं हैं:

इसके अलावा, शिक्षक ने इम्प्यूटर और पाइपलाइन का उपयोग करने के उदाहरण दिखाए।
फ़ीचर स्केलिंगमॉडल का संचालन और अंतिम निर्णय सुविधाओं के पैमाने पर निर्भर करता है। तथ्य यह है कि यह एक तथ्य नहीं है कि कोई भी विशेषता जिसमें एक बड़ा पैमाना होता है, वह उस विशेषता से अधिक महत्वपूर्ण होता है जिसका एक छोटा पैमाना होता है। यही कारण है कि मॉडल को उन विशेषताओं को प्रस्तुत करने की आवश्यकता होती है जो कि पहचान के अनुसार मापी जाती हैं, अर्थात मॉडल के लिए समान वजन होता है।
विभिन्न स्केलिंग तकनीकें हैं, हालांकि, खुले पाठ के प्रारूप ने हमें उनमें से केवल दो पर अधिक विस्तार से विचार करने की अनुमति दी है:
 फ़ीचर संयोजन
फ़ीचर संयोजनअंकगणितीय संचालन (राशि, गुणन, विभाजन) का उपयोग करके मौजूदा सुविधाओं के संयोजन आपको कोई भी सुविधा प्राप्त करने की अनुमति देते हैं जो मॉडल को अधिक कुशल बनाता है। यह हमेशा सफल नहीं होता है, और हम नहीं जानते कि कौन सा संयोजन वांछित प्रभाव देगा, लेकिन अभ्यास से पता चलता है कि यह प्रयास करने के लिए समझ में आता है। पाइप लाइन का उपयोग करके सुविधा परिवर्तनों को लागू करना सुविधाजनक है।
कोडिंगतो, हमारे पास विभिन्न प्रकार के डेटा हैं: संख्यात्मक और पाठ। वर्तमान में, बाजार के अधिकांश मॉडल पाठ डेटा के साथ काम नहीं कर सकते हैं। नतीजतन, सभी श्रेणीबद्ध संकेतों (पाठ) को एक संख्यात्मक प्रतिनिधित्व में परिवर्तित किया जाना चाहिए, जिसके लिए कोडिंग का उपयोग किया जाता है।
लेबल एन्कोडिंग । यह कई पुस्तकालयों के ढांचे के भीतर लागू किया गया एक तंत्र है जिसे कहा जा सकता है और लागू किया जा सकता है:

लेबल एन्कोडिंग प्रत्येक अद्वितीय मान के लिए एक अद्वितीय पहचानकर्ता प्रदान करता है। माइनस - हम एक निश्चित चर में ऑर्डर करने का परिचय देते हैं जो ऑर्डर नहीं किया गया था, जो अच्छा नहीं है।
OneHotEncoder। टेक्स्ट वैरिएबल के अनूठे मानों को स्तंभ के रूप में विस्तारित किया जाता है जो स्रोत डेटा में जोड़े जाते हैं, जहां प्रत्येक कॉलम 0 और 1. के रूप में एक बाइनरी वैरिएबल है। यह दृष्टिकोण लेबल एन्कोडिंग दोषों से मुक्त है, लेकिन इसका अपना माइनस है: यदि कई अनूठे मान हैं, तो हम बहुत अधिक कॉलम जोड़ते हैं और कुछ मामलों में विधि बस लागू नहीं होती है (डेटासेट बहुत बढ़ता है)।
मॉडल प्रशिक्षणउपरोक्त चरणों को करने के बाद, सभी आवश्यक कार्यों के एक सेट के साथ एक अंतिम पाइपलाइन संकलित की जाती है। अब स्रोत डेटासेट लेना और फ़िट_ट्रांसफॉर्म ऑपरेशन का उपयोग करके इस डेटा पर परिणामी पाइपलाइन लागू करना पर्याप्त है:
x_train = vec.fit_transform(df_train)नतीजतन, हमें x_train डेटासेट मिलता है, जो मॉडल में उपयोग के लिए तैयार है। केवल एक चीज यह है कि हम अपने लक्ष्य चर के मूल्य को अलग करें ताकि हम प्रशिक्षण का संचालन कर सकें।
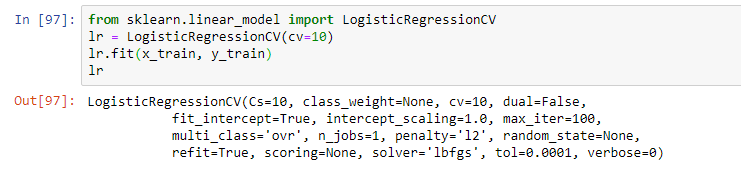
अगला, मॉडल का चयन करें। वेबिनार के हिस्से के रूप में, शिक्षक ने एक सरल लॉजिस्टिक प्रतिगमन का प्रस्ताव रखा। मॉडल को फिट ऑपरेशन का उपयोग करके प्रशिक्षित किया गया था, जिसके परिणामस्वरूप एक मॉडल कुछ मापदंडों के साथ लॉजिस्टिक रिग्रेशन के रूप में था:
हालांकि, व्यवहार में, कई मॉडल आमतौर पर उपयोग किए जाते हैं जो सबसे प्रभावी लगते हैं। और अंतिम समाधान अक्सर इन मॉडलों का एक संयोजन होता है जो स्टैकिंग तकनीकों और अन्य दृष्टिकोणों के साथ संयोजन वाले मॉडल (एक ही हाइब्रिड मॉडल के भीतर कई मॉडल का उपयोग करके) का उपयोग करता है।
प्रशिक्षण के बाद, मॉडल को कुछ मीट्रिक के ढांचे में इसकी गुणवत्ता का मूल्यांकन करते हुए, परीक्षण डेटा पर लागू किया जा सकता है। हमारे मामले में, सटीकता_सकोर के भीतर की गुणवत्ता 0.8 थी:

इसका मतलब यह है कि प्राप्त आंकड़ों पर 80% मामलों में चर की सही भविष्यवाणी की जाती है। प्रशिक्षण परिणाम प्राप्त करने के बाद, हम या तो मॉडल में सुधार कर सकते हैं (यदि सटीकता संतोषजनक नहीं है), या पूर्वानुमान के लिए सीधे आगे बढ़ें।
यह पाठ का मुख्य विषय था, लेकिन शिक्षक ने विभिन्न कार्यों में मॉडल की विशेषताओं के बारे में अधिक विस्तार से बात की और दर्शकों से सवालों के जवाब दिए। इसलिए यदि आप कुछ भी याद नहीं करना चाहते हैं, तो यदि आप इस विषय में रुचि रखते हैं तो पूर्ण वेबिनार देखें।
हमेशा की तरह, हम आपकी टिप्पणियों और प्रश्नों की प्रतीक्षा कर रहे हैं, जिन्हें आप यहां छोड़ सकते हैं या एक
खुले दिन में उनके पास जाकर
सिकंदर से पूछ सकते
हैं।