उच्च लोड स्थितियों के तहत, संबंधपरक डेटाबेस को अनुकूलित करने की जटिलता परिमाण के एक क्रम से बढ़ जाती है, क्योंकि इससे भी अधिक शक्तिशाली हार्डवेयर खरीदना महंगा है और एक लंबी डेटाबेस परिवर्तन प्रक्रिया और डेटा माइग्रेशन के लिए रात में आवेदन को बंद करने का कोई तरीका नहीं है।
हमने हाल ही में इस बारे में बात की कि हमने
अपने आवेदन के लिए PHP कोड को कैसे
अनुकूलित किया । अब लेख की बारी आई है कि कैसे हमने एक भी अनुरोध खोए बिना, सबसे अधिक लोड किए गए और महत्वपूर्ण डेटाबेस की आंतरिक संरचना को पूरी तरह से बदल दिया।
रोगी
उपयोगकर्ता DataBase, या UDB, एक ऐसी सेवा है जो लगभग किसी भी अनुरोध को शुरू करती है। यह कई समस्याओं को हल करता है: सबसे पहले, यह मूल उपयोगकर्ता डेटा का केंद्रीय भंडार है जिसके लिए प्राधिकरण लेता है (उदाहरण के लिए, ईमेल, user_id या facebook_id)। इस डेटा को संग्रहीत करने के अलावा, सेवा विशिष्टता नियंत्रण प्रदान करती है (ताकि एक ही ईमेल वाले दो उपयोगकर्ता, facebook_id, आदि सिस्टम में पंजीकृत न हो सकें)। और एक ही सेवा के बारे में जानकारी देता है कि हजारों में से किस शार्क में अन्य सभी उपयोगकर्ता डेटा हैं।
2018 के अंत में, यूडीबी 800 मिलियन से अधिक उपयोगकर्ताओं से डेटा संग्रहीत करता है, जो डिस्क स्थान के 1 टीबी पर कब्जा करता है। यह सब हमारे प्रत्येक डेटा सेंटर में मास्टर-स्लेव MySQL सर्वरों के जोड़े द्वारा परोसा जाता है। कुल में, वे प्रति सेकंड 140,000 से अधिक अनुरोधों को संसाधित करते हैं।
यूडीबी के गिरने का मतलब है कि सभी अटैचमेंट की दुर्गमता, क्योंकि कोड उस शार्क को नहीं खोज पाएगा, जिस पर उपयोगकर्ता का डेटा निहित है। इसलिए, विश्वसनीयता और उपलब्धता के लिए इस पर भारी मांगें रखी जाती हैं।
इस विशिष्टता के कारण, भंडारण संरचना में परिवर्तन करना बहुत महंगा है, इसलिए हमने 2013 में UDB डिजाइन को बहुत गंभीरता से लिया। हालांकि, समय के साथ, आवश्यकताओं के साथ-साथ लोड प्रोफाइल भी बदलते हैं। सिस्टम को नई आवश्यकताओं और लोड स्तरों के अनुकूल बनाने के प्रयास में, कई छोटे और सरल बदलाव किए गए थे, लेकिन, दुर्भाग्य से, ऐसे बदलाव सबसे प्रभावी हैं। और वह दिन आ गया, जब अगली हैक या महंगे हार्डवेयर की खरीद के बजाय, यह विश्व स्तर पर अनुकूलन करने के लिए समझदार था। आगे हम इस मार्ग के मुख्य चरणों पर विचार करेंगे।
गैर-आक्रामक अनुकूलन
डेटा माइग्रेशन प्रक्रिया की जटिलता के कारण एक बड़े और लोड किए गए डेटाबेस की संरचना में कोई भी बदलाव काफी महंगा है। इसलिए, सबसे पहले, आपको उन सभी अनुकूलन विकल्पों को समाप्त करना चाहिए जो डेटा संरचना को प्रभावित नहीं करते हैं, लेकिन कोड और SQL प्रश्नों तक सीमित हैं। शायद यह कुछ वर्षों के लिए अत्यधिक कार्यभार की समस्या को स्थगित करने के लिए पर्याप्त होगा, जो आपको इस समय व्यवसाय के लिए कुछ और महत्वपूर्ण करने की अनुमति देगा।
आप अपने सिस्टम को जितना बेहतर समझेंगे, आपके लिए उतनी ही आशाओं के लिए दृष्टिकोण ढूंढना आसान होगा। सुनिश्चित करें कि आप सभी मीट्रिक एकत्र करते हैं जो आपकी सहायता कर सकते हैं। यह न केवल सीपीयू उपयोग और रैम उपयोग या किसी विशिष्ट डेटाबेस के मेट्रिक्स जैसे सिस्टम मेट्रिक्स के बारे में है, बल्कि एक ऐसे एप्लिकेशन के अनुप्रयोग-स्तरीय मैट्रिक्स के बारे में भी है जो एक अनुकूलित डेटाबेस से जुड़ा है। विभिन्न प्रकार के कार्यों में प्रति सेकंड कितने अनुरोध हैं? उनकी प्रतिक्रिया का समय क्या है? इनपुट और आउटपुट का आकार क्या है? यह इन मैट्रिक्स पर है कि आप अनुकूलन की सफलता का न्याय कर सकते हैं। यह संभावना नहीं है कि आपको अनुकूलन की आवश्यकता है जो डेटाबेस सर्वर पर सीपीयू के उपयोग को थोड़ा कम करेगा, लेकिन साथ ही साथ आपके आवेदन की प्रतिक्रिया समय को दस गुना बढ़ा देगा।

UDB के लिए अतिरिक्त एप्लिकेशन-स्तरीय मैट्रिक्स एकत्र करना शुरू करने के बाद, हम यह समझने में सक्षम थे कि कौन से प्रदर्शन किए गए संचालन में से 80% लोड का निर्माण करते हैं और अध्ययन के लिए पहले उम्मीदवार हैं, और जिनका उपयोग कम या बिल्कुल नहीं किया जाता है।
सबसे लगातार संचालन का एक विस्तृत विश्लेषण (कुछ मानदंडों को पूरा करने वाले उपयोगकर्ताओं को पुनः प्राप्त करना) से पता चला है कि इस तथ्य के बावजूद कि डेटाबेस से सभी उपलब्ध उपयोगकर्ता डेटा का अनुरोध किया जाता है, वास्तव में 95% मामलों में आवेदन केवल user_id का उपयोग करता है। बस इस मामले को एक अलग एपीआई विधि में अलग करके, जो तालिका से केवल एक कॉलम निकालता है, हम डेटाबेस के सर्वर से लगभग 5% सीपीयू लोड को हटाने के लिए कवरिंग इंडेक्स के उपयोग से लाभ उठा सकते थे।
एक और लगातार ऑपरेशन के विश्लेषण से पता चला है कि इस तथ्य के बावजूद कि यह प्रत्येक HTTP अनुरोध के लिए किया जाता है, वास्तव में, यह जो डेटा प्राप्त करता है वह अत्यंत दुर्लभ है। हमने एक आलसी मॉडल के इस अनुरोध का अनुवाद किया।
ऑप्टिमाइज़ेशन प्रोजेक्ट के मामले में मीट्रिक का मुख्य लक्ष्य अपने डेटाबेस को बेहतर ढंग से समझना और सबसे तेज़ टुकड़ों को ढूंढना है। यह बहुत अधिक समय बिताने के लिए कोई मतलब नहीं है और प्रश्नों को अनुकूलित करने का प्रयास करता है जो आपके लोड प्रोफ़ाइल का 1% से कम बनाते हैं। यदि आपके पास मेट्रिक्स नहीं हैं जो आपको अपने लोड की प्रोफ़ाइल को समझने की अनुमति देता है, तो उन्हें इकट्ठा करें। कोड पक्ष पर इस तरह की अनुकूलन के साथ, हमने उपभोग किए गए डेटाबेस के 80% से लगभग 15% सीपीयू उपयोग को हटाने में कामयाब रहे।
परीक्षण के विचार
यदि आप इसकी संरचना को बदलकर किसी लोड किए गए डेटाबेस का अनुकूलन करने जा रहे हैं, तो आपको परीक्षण बेंच पर अपने विचारों की जांच शुरू कर देनी चाहिए, क्योंकि यहां तक कि सिद्धांत में बहुत आशाजनक दिखने वाले व्यवहार में सकारात्मक प्रभाव नहीं हो सकता है (और कभी-कभी उनका नकारात्मक प्रभाव भी हो सकता है)। और आप उत्पादन पर एक लंबे डेटा माइग्रेशन के बाद ही इस बारे में जानना चाहते हैं।
उत्पादन कॉन्फ़िगरेशन के लिए आपका स्टैंड कॉन्फ़िगरेशन जितना अधिक होगा, आपको परिणाम उतने अधिक विश्वसनीय होंगे। स्टैंड का सही लोड सुनिश्चित करने के लिए एक महत्वपूर्ण बिंदु है। यादृच्छिक या समान क्वेरी चलाने से गलत परिणाम हो सकते हैं। सबसे अच्छा विकल्प उत्पादन से वास्तविक अनुरोधों का उपयोग करना है। UDB के लिए, हमने हर दसवें एपीआई रीड रिक्वेस्ट (मापदंडों सहित) को एक फाइल में सिर्फ JSON लॉग के रूप में लॉग इन किया। एक दिन के लिए, हमने 700 मिलियन अनुरोधों से आकार में 65 जीबी का लॉग एकत्र किया।
हमने रिकॉर्ड का परीक्षण नहीं किया, क्योंकि पढ़ने के अनुरोधों की संख्या की तुलना में, यह बहुत छोटा है और हमारे भार को प्रभावित नहीं करता है। हालाँकि, आपके मामले में ऐसा नहीं हो सकता है। यदि आप लिखित अनुरोधों के साथ परीक्षण बेंच को लोड करना चाहते हैं, तो आपको प्रत्येक अनुरोध को इकट्ठा करना होगा, क्योंकि लेखन अनुरोधों को छोड़ देने से परीक्षण बेंच पर स्थिरता की त्रुटियां हो सकती हैं।
अगला कदम स्टैंड पर लॉग को सही ढंग से खोना है। हमने अपने
स्क्रिप्ट क्लाउड से लॉन्च किए गए 400 PHP श्रमिकों का उपयोग किया, जो कि तेजी से कतार से एकत्रित लॉग को पढ़ते हैं और क्रमिक रूप से अनुरोधों को निष्पादित करते हैं। इस मामले में, कतार एक अन्य स्क्रिप्ट के साथ एक कड़ाई से परिभाषित गति से भरी हुई है। विचारों का परीक्षण करने के लिए, हमने x10 की गति का उपयोग किया, जिसने इस तथ्य से गुणा किया कि हमने उत्पादन से हर दसवें अनुरोध को इकट्ठा किया, उत्पादन में आरपीएस की समान संख्या दी।
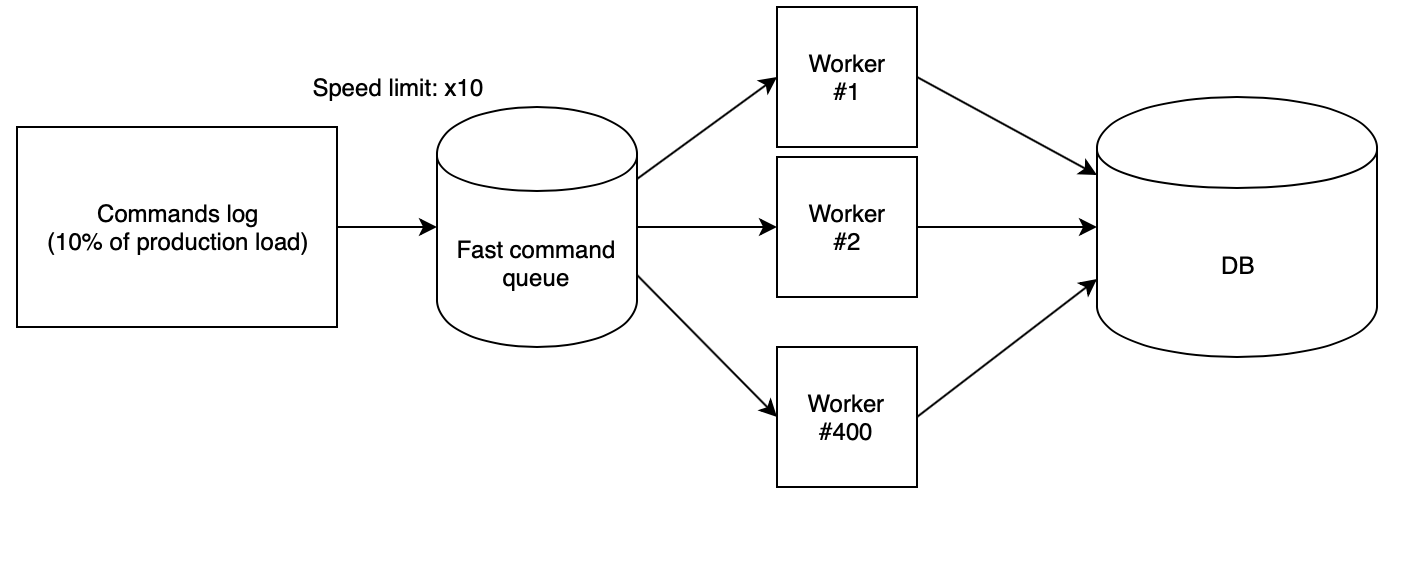
इन गुणांक के साथ, यह पता चलता है कि परीक्षण बेंच पर सभी लोड ड्रॉप के साथ उत्पादन दिन केवल ढाई घंटे में उड़ जाता है।
इसलिए, उदाहरण के लिए, हम जो पहले परीक्षण x5 की गति (उत्पादन से लोड का 50%) की गति से भागते थे, क्वेरी लॉग पर आधे दिन के लिए इस तरह दिखता था:
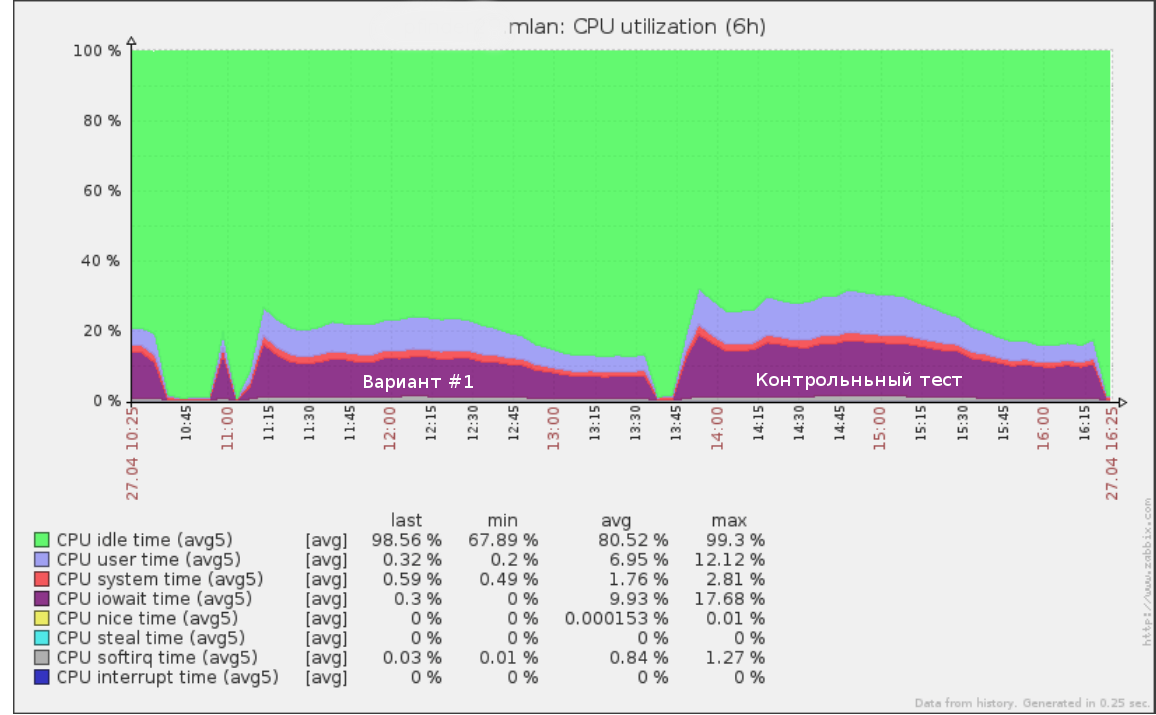
एक ही उपकरण का उपयोग विफलता परीक्षण करने के लिए किया जा सकता है: गति में वृद्धि (और इसलिए आरपीएस) जब तक कि स्टैंड पर आधार नीचा होना शुरू नहीं हो जाता। यह आपको एक स्पष्ट समझ देगा कि आपका डेटाबेस कितना अधिक लोड का सामना कर सकता है।
नए डेटा स्कीमा का परीक्षण करने के बाद, मूल डेटाबेस संरचना पर नियंत्रण परीक्षण करना भी महत्वपूर्ण है। यदि इसके परिणाम और उत्पादन पर वर्तमान प्रदर्शन बहुत अलग हैं, तो आपको पहले कारणों को समझना चाहिए। शायद परीक्षण सर्वर गलत तरीके से कॉन्फ़िगर किया गया है और आप लोड परीक्षण डेटा पर भरोसा नहीं कर सकते।
यह भी सुनिश्चित करने के लायक है कि नया कोड सही तरीके से काम कर रहा है। यह उन सवालों के प्रदर्शन का परीक्षण करने के लिए बहुत कम समझ में आता है जो काम नहीं करते हैं। आपको एकीकरण परीक्षणों द्वारा अच्छी तरह से सेवा दी जाएगी जो यह देखने के लिए जांचें कि क्या पुराने और नए एपीआई समान एपीआई कॉल पर समान मान लौटाते हैं।
सभी विचारों पर परिणाम प्राप्त करने के बाद, यह केवल कीमत और गुणवत्ता के बीच सबसे अच्छा संतुलन के साथ विकल्प चुनने और उत्पादन के लिए एक नई योजना शुरू करने के लिए बनी हुई है।
स्कीमा बदल जाते हैं
सबसे पहले, मैं ध्यान देता हूं कि सेवा के संचालन को रोकने के बिना डेटा योजना को बदलना हमेशा काफी मुश्किल, महंगा और जोखिम भरा होता है। इसलिए, यदि आपके पास संरचना को बदलते समय अपने आवेदन को रोकने का अवसर है - बस इसे करें। यूडीबी के मामले में, दुर्भाग्य से, हम इसे बर्दाश्त नहीं कर सके।
एक सर्किट को बदलने की जटिलता को प्रभावित करने वाला दूसरा कारक परिवर्तन का नियोजित पैमाने है। यदि तालिकाओं के सभी प्रस्तावित परिवर्तन सिर्फ एक परिवर्तन से परे नहीं जाते हैं (उदाहरण के लिए, नए अनुक्रमित या स्तंभों की एक जोड़ी को जोड़ते हुए), तो आप उन्हें विशिष्ट प्रक्रियाओं जैसे कि
पीटी-ऑनलाइन-स्कीमा-परिवर्तन और
गॉ-ओस्ट के लिए
3gp प्रोसेसर या एक वैकल्पिक दास के साथ क्रैंक कर सकते हैं, उनके स्थान बदलकर। ।
हमारे मामले में, एक उत्कृष्ट तालिका एक विशाल तालिका में ऊर्ध्वाधर कॉलमिंग में दिखाई देती थी जो अन्य कॉलम और इंडेक्स और डेटा के साथ एक दर्जन छोटे होते थे। विशिष्ट उपकरणों के साथ ऐसा रूपांतरण अब संभव नहीं है। तो क्या करें?
हमने निम्नलिखित एल्गोरिथम लागू किया:
- हम एक ऐसे राज्य को प्राप्त करते हैं जहां पुरानी और नई दोनों योजनाएं वर्तमान डेटा के साथ मौजूद हैं। रिकॉर्डिंग दोनों में जाती है, और एक ही समय में दोनों संस्करणों में डेटा संगतता की गारंटी है। हम इस मद पर नीचे विस्तार से विचार करेंगे।
- लोड को नियंत्रित करते हुए धीरे-धीरे पूरे रीडिंग को एक नए सर्किट में स्विच करें।
- पुरानी योजना में रिकॉर्डिंग बंद करें और इसे हटा दें।
इस दृष्टिकोण के मुख्य लाभ:
- सुरक्षा: अंतिम चरण तक तत्काल रोलबैक की संभावना है (बस पुरानी योजना पर वापस स्विच करें, अगर कुछ गलत हो गया है);
- डेटा माइग्रेशन के दौरान पूर्ण लोड नियंत्रण;
- पुराने सर्किट की बड़ी तालिका में कोई भारी परिवर्तन की आवश्यकता नहीं है।
हालांकि, इसके नुकसान भी हैं:
- माइग्रेशन प्रक्रिया के दौरान स्कीमा के दोनों संस्करणों को डिस्क पर रखने की आवश्यकता है (यह एक समस्या हो सकती है यदि आपके पास थोड़ी जगह है और माइग्रेट की जा रही तालिका बहुत बड़ी है);
- माइग्रेशन प्रक्रिया का समर्थन करने के लिए बहुत सारे अस्थायी कोड, जो पूरा होने पर कट जाएंगे;
- समानांतर में दो योजनाओं से पढ़कर कैश को धोना संभव है; एक डर था कि पुराने और नए संस्करण रैम के लिए प्रतिस्पर्धा करेंगे, जिससे सेवा का ह्रास हो सकता है (वास्तव में, यह वास्तव में एक अतिरिक्त भार पैदा करता है, हालांकि, चूंकि माइग्रेशन को ऑफ-पीक किया गया था, इससे हमारे लिए समस्याएं पैदा नहीं हुईं)।
इस एल्गोरिथ्म में मुख्य कठिनाई पहला बिंदु है। हम इस पर विस्तार से विचार करेंगे।
सिंक बदलें
स्थैतिक डेटा का स्थानांतरण विशेष रूप से मुश्किल नहीं है। हालाँकि, क्या होगा यदि आप डेटाबेस को माइग्रेट करते समय पूरी रिकॉर्डिंग को रोक नहीं सकते हैं?
नई योजना के सिंक्रोनाइज़ेशन को प्राप्त करने के लिए कई विकल्प हैं: लॉग इन रोलिंग के साथ माइग्रेशन और बेतरतीब रिकॉर्डिंग माइग्रेशन।
निम्नलिखित परिवर्तनों के लॉग को वापस खेलकर एक डेटा स्नैपशॉट माइग्रेट करना
प्रत्येक डेटा अपडेट लेनदेन एक विशेष तालिका में एप्लिकेशन स्तर पर ट्रिगर के माध्यम से लॉग इन किया जाता है, या प्रतिकृति बिनलॉग का उपयोग लॉग के रूप में किया जाता है। आपके पास ऐसा लॉग होने के बाद, आप लेन-देन खोल सकते हैं और लॉग में स्थिति को याद करते हुए, एक डेटा स्नैपशॉट माइग्रेट कर सकते हैं। फिर यह नई योजना पर एकत्रित लॉग को लागू करना शुरू करना है। इसी तरह, उदाहरण के लिए, लोकप्रिय MySQL
Percona XtraBackup बैकअप टूल काम करता है ।
नई योजना के वर्तमान रिकॉर्ड में लॉग के साथ पकड़े जाने के बाद, सबसे महत्वपूर्ण चरण शुरू होता है: आपको अभी भी पुरानी स्कीम में थोड़े समय के लिए रिकॉर्डिंग रोकनी होगी और यह सुनिश्चित करना होगा कि पूरी उपलब्ध लॉग नई स्कीम पर लागू हो, जिसका अर्थ है कि योजनाओं के बीच डेटा सुसंगत है। आवेदन स्तर पर, दोनों स्रोतों में एक बार रिकॉर्डिंग सक्षम करें।
इस दृष्टिकोण का मुख्य नुकसान यह है कि आपको किसी तरह ऑपरेशन लॉग को स्टोर करने की आवश्यकता होगी, जो अपने आप में जटिल स्विचिंग प्रक्रिया में एक लोड बना सकता है, साथ ही साथ रिकॉर्ड को तोड़ने की संभावना में अगर किसी कारण से सर्किट असंगत हो जाते हैं।
निष्प्राण रिकॉर्ड
इस दृष्टिकोण का मुख्य विचार नई योजना को लिखना शुरू करना है, जिसमें परिवर्तन पूरी तरह से सिंक्रनाइज़ होने से पहले पुराने के साथ समानांतर में लिखना है, और फिर शेष डेटा के प्रवास को पूरा करना है। इसी तरह, आमतौर पर नए कॉलम बड़े टेबल में भरे जाते हैं।
सिंक्रोनस रिकॉर्डिंग को डेटाबेस ट्रिगर्स और सोर्स कोड दोनों पर लागू किया जा सकता है। मैं आपको कोड में यह ठीक करने की सलाह देता हूं, क्योंकि किसी भी मामले में, आपको अंततः कोड लिखना होगा जो नई योजना के लिए डेटा लिखेंगे, और कोड पक्ष पर माइग्रेशन का कार्यान्वयन आपको अधिक नियंत्रण प्रदान करेगा।
विचार करने के लिए एक महत्वपूर्ण बिंदु यह है कि जब तक प्रवास पूरा नहीं होगा, नई योजना असंगत स्थिति में होगी। इस वजह से, एक परिदृश्य संभव है जब एक नई तालिका को अपडेट करने से डेटाबेस निरंतर (विदेशी कुंजी या एक अद्वितीय सूचकांक) का उल्लंघन होता है, जबकि वर्तमान योजना के दृष्टिकोण से, लेनदेन पूरी तरह से सही है और इसे बाहर किया जाना चाहिए।
यह स्थिति माइग्रेशन प्रक्रिया के कारण अच्छे लेनदेन का रोलबैक कर सकती है। इस समस्या को हल करने का सबसे आसान तरीका है कि आप किसी नई योजना में डेटा लिखने के लिए सभी अनुरोधों में IGNORE संशोधक को शामिल करें या इस तरह के लेनदेन के रोलबैक को रोकें और नई योजना को लिखे बिना संस्करण को चलाएं।
हमारे मामले में सुखद रिकॉर्डिंग के माध्यम से तुल्यकालन एल्गोरिथ्म इस प्रकार है:
- हम संगतता मोड (IGNORE) में पुराने एक में रिकॉर्डिंग के समानांतर एक नई योजना में रिकॉर्डिंग सक्षम करते हैं।
- हम एक स्क्रिप्ट चलाते हैं जो धीरे-धीरे नई योजना को बायपास करती है और असंगत डेटा को कैप्चर करती है। उसके बाद, दोनों तालिकाओं में डेटा को सिंक्रनाइज़ किया जाना चाहिए, लेकिन यह खंड 1 में संभावित संघर्षों के कारण गलत है।
- हम डेटा संगतता परीक्षक शुरू करते हैं - हम लेनदेन खोलते हैं और क्रमिक रूप से उनके पत्राचार की तुलना करते हुए नई और पुरानी योजनाओं से लाइनें पढ़ते हैं।
- यदि संघर्ष हैं, तो हम समाप्त हो जाते हैं और पैराग्राफ 3 पर लौट आते हैं।
- चेकर के बाद पता चला कि दोनों योजनाओं में डेटा सिंक्रनाइज़ हैं, फिर योजनाओं के बीच कोई और विसंगतियां नहीं होनी चाहिए, जब तक कि निश्चित रूप से, हम कुछ बारीकियों से चूक गए। इसलिए, हम कुछ समय के लिए प्रतीक्षा करते हैं (उदाहरण के लिए, एक सप्ताह) और एक नियंत्रण जांच चलाते हैं। यदि वह दिखाता है कि सब कुछ ठीक है, तो कार्य सफलतापूर्वक पूरा हो गया है और आप रीडिंग का अनुवाद कर सकते हैं।
परिणाम
डेटा प्रारूप को बदलने के परिणामस्वरूप, हम मुख्य तालिका का आकार 544 जीबी से 226 जीबी तक कम करने में सक्षम थे, जिससे डिस्क पर लोड कम हो गया और रैम में फिट होने वाले उपयोगी डेटा की मात्रा बढ़ गई।
कुल मिलाकर, परियोजना की शुरुआत से, सभी वर्णित दृष्टिकोणों का उपयोग करके, हम चरम ट्रैफ़िक पर डेटाबेस सर्वर के CPU उपयोग को 80% से 35% तक कम करने में सक्षम थे। बाद के तनाव परीक्षण के परिणामों से पता चला कि लोड की वर्तमान विकास दर पर, हम मौजूदा हार्डवेयर पर कम से कम एक और तीन साल तक बने रह सकते हैं।
एक विशाल तालिका को कई में विभाजित करते हुए डेटाबेस में भविष्य के अलर्ट का संचालन करने की प्रक्रिया को सरल बनाया, और बीआई के लिए डेटा एकत्र करने वाली कुछ लिपियों में भी काफी तेजी लाई।