नोमाद I में पहली सेवा सितंबर 2016 में शुरू की गई थी। फिलहाल मैं इसे एक प्रोग्रामर के रूप में उपयोग करता हूं और दो घुमंतू समूहों के प्रशासक के रूप में समर्थन करता हूं - एक मेरी निजी परियोजनाओं के लिए "एक घर" (यूरोप में 5 अलग-अलग डेटा केंद्रों में हेट्ज़नर क्लाउड और अरूबाक्लाउड में 6 माइक्रो-वर्चुअल मशीन) और दूसरा काम करने वाला एक (लगभग 40 निजी आभासी और भौतिक सर्वर) दो डेटा केंद्रों में)।
पिछले समय में, खानाबदोश वातावरण के साथ काफी अनुभव जमा हो गया है, लेख में मैं खानाबदोश की समस्याओं और उनसे निपटने के तरीके का वर्णन करूंगा।

यमल खानाबदोश आपके सॉफ्टवेयर का कंटीन्यूअस डिलिवरी उदाहरण देता है © नेशनल जियोग्राफिक रूस
1. प्रति डेटा सेंटर में सर्वर नोड की संख्या
समाधान: एक सर्वर नोड एक डेटा सेंटर के लिए पर्याप्त है।
प्रलेखन स्पष्ट रूप से इंगित नहीं करता है कि एक डेटा सेंटर में कितने सर्वर नोड्स की आवश्यकता है। यह केवल संकेत दिया जाता है कि प्रति क्षेत्र में 3-5 नोड्स की आवश्यकता होती है, जो कि बेड़ा प्रोटोकॉल सर्वसम्मति के लिए तार्किक है।
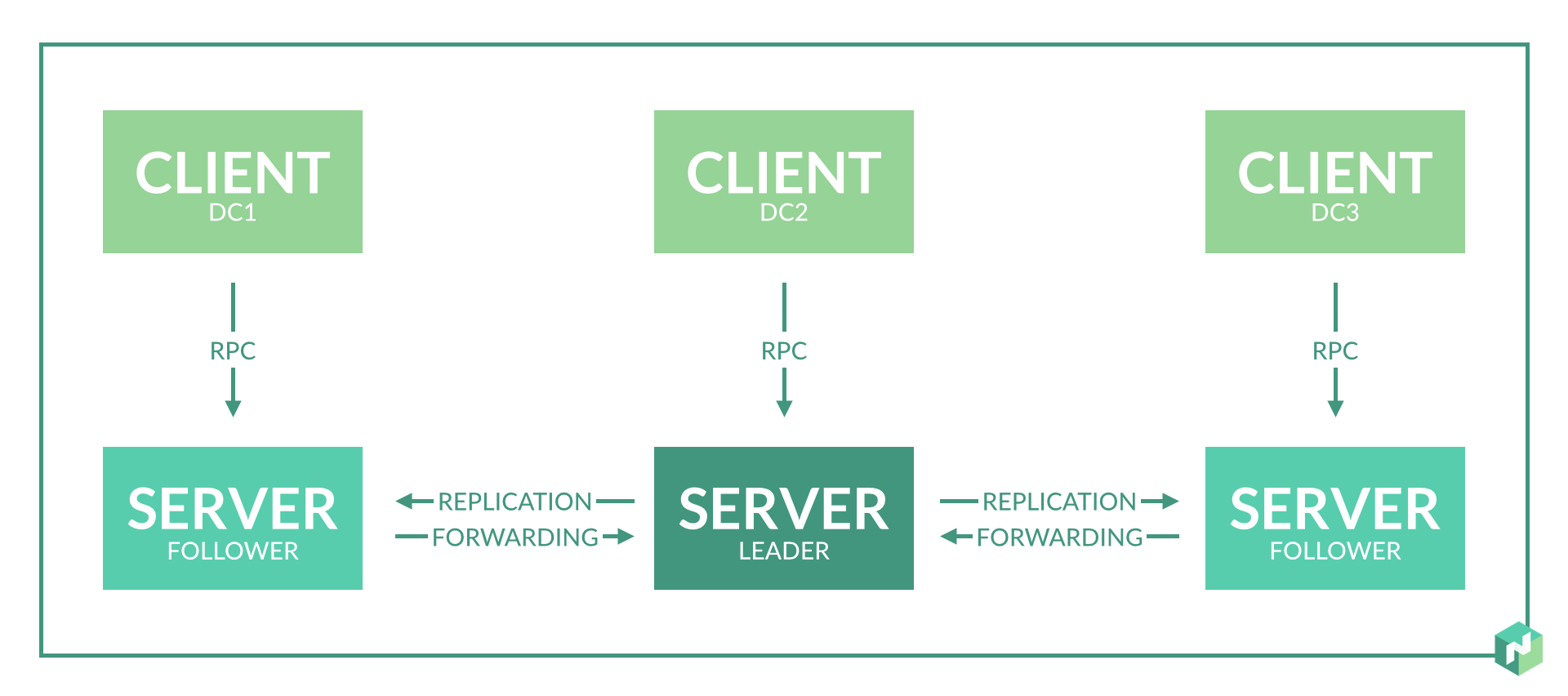
शुरुआत में, मैंने अतिरेक प्रदान करने के लिए प्रत्येक डेटा सेंटर में 2-3 सर्वर नोड्स की योजना बनाई।
उपयोग करने पर यह निकला:
- यह केवल आवश्यक नहीं है, क्योंकि डेटा केंद्र में नोड विफलता की स्थिति में, इस डेटा केंद्र में एजेंटों के लिए सर्वर नोड की भूमिका क्षेत्र में अन्य सर्वर नोड द्वारा निभाई जाएगी।
- यह समस्या 8 हल नहीं होने पर और भी बदतर हो जाती है। जब विज़ार्ड फिर से चुना जाता है, तो विसंगतियां हो सकती हैं और घुमंतू सेवाओं के कुछ हिस्से को फिर से शुरू करेगा।
2. सर्वर नोड के लिए सर्वर संसाधन
समाधान: सर्वर नोड के लिए एक छोटी वर्चुअल मशीन पर्याप्त है। एक ही सर्वर पर, इसे अन्य सेवा गैर-संसाधन-गहन सेवाओं को चलाने की अनुमति है।
खानाबदोश डेमॉन की मेमोरी खपत रनिंग कार्यों की संख्या पर निर्भर करती है। सीपीयू की खपत - कार्यों की संख्या और क्षेत्र में सर्वरों / एजेंटों की संख्या के आधार पर (रैखिक नहीं)।
हमारे मामले में: 300 चल रहे कार्यों के लिए, मेमोरी खपत वर्तमान मास्टर नोड के लिए लगभग 500 एमबी है।
एक कार्यशील क्लस्टर में, सर्वर नोड के लिए एक वर्चुअल मशीन: 4 सीपीयू, 6 जीबी रैम।
इसके अतिरिक्त लॉन्च किया गया: कंसल, एटीडी, वॉल्ट।
3. डेटा केंद्रों की कमी पर सहमति
समाधान: हम दो भौतिक डेटा केंद्रों के लिए तीन वर्चुअल डेटा केंद्र और तीन सर्वर नोड बनाते हैं।
क्षेत्र के भीतर खानाबदोश का काम बेड़ा प्रोटोकॉल पर आधारित है। सही संचालन के लिए, आपको विभिन्न डेटा केंद्रों में स्थित कम से कम 3 सर्वर नोड की आवश्यकता होती है। यह डेटा केंद्रों में से एक के साथ नेटवर्क कनेक्टिविटी के पूर्ण नुकसान के साथ सही संचालन को सक्षम करेगा।
लेकिन हमारे पास केवल दो डेटा सेंटर हैं। हम एक समझौता करते हैं: हम एक डेटा सेंटर चुनते हैं, जिस पर हम अधिक भरोसा करते हैं, और इसमें एक अतिरिक्त सर्वर नोड बनाते हैं। हम एक अतिरिक्त वर्चुअल डेटा सेंटर की शुरुआत करके ऐसा करते हैं, जो शारीरिक रूप से एक ही डेटा सेंटर में स्थित होगा (समस्या 1 का सबपर पैरा देखें)।
वैकल्पिक समाधान: हम डेटा केंद्रों को अलग-अलग क्षेत्रों में तोड़ते हैं।
परिणामस्वरूप, डेटा सेंटर स्वतंत्र रूप से कार्य करते हैं और आम सहमति केवल एक डेटा सेंटर के भीतर की आवश्यकता होती है। एक डेटा सेंटर के अंदर, इस मामले में एक भौतिक एक में तीन वर्चुअल डेटा केंद्रों को लागू करके 3 सर्वर नोड बनाना बेहतर होता है।
यह विकल्प कार्य वितरण के लिए कम सुविधाजनक है, लेकिन डेटा केंद्रों के बीच नेटवर्क समस्याओं के मामले में सेवाओं की स्वतंत्रता की 100% गारंटी देता है।
4. एक ही सर्वर पर "सर्वर" और "एजेंट"
समाधान: यदि आपके पास सीमित संख्या में सर्वर हैं, तो मान्य है।
घुमंतू प्रलेखन का कहना है कि ऐसा करना अवांछनीय है। लेकिन अगर आपके पास सर्वर नोड्स के लिए अलग-अलग वर्चुअल मशीन आवंटित करने का अवसर नहीं है, तो आप सर्वर और एजेंट नोड्स को एक ही सर्वर पर रख सकते हैं।
एक साथ रनिंग का मतलब है क्लाइंट मोड और सर्वर मोड दोनों में नोमैड डेमॉन शुरू करना।
इससे क्या खतरा है? इस सर्वर के सीपीयू पर भारी भार के साथ, खानाबदोश सर्वर नोड काम करेगा, आम सहमति और दिल की धड़कन, सेवा पुनः लोड संभव है।
इससे बचने के लिए, हम समस्या नंबर 8 के विवरण से सीमा बढ़ाते हैं।
5. नाम स्थान का कार्यान्वयन
समाधान: शायद एक आभासी डेटा केंद्र के संगठन के माध्यम से।
कभी-कभी आपको अलग-अलग सर्वरों पर सेवाओं का हिस्सा चलाने की आवश्यकता होती है।
समाधान संसाधनों पर पहली, सरल, लेकिन अधिक मांग है। हम सभी सेवाओं को उनके उद्देश्य के अनुसार समूहों में विभाजित करते हैं: सीमा, बैकएंड, ... सर्वर में मेटा विशेषताएँ जोड़ें, सभी सेवाओं के लिए चलाने के लिए विशेषताओं को लिखें।
दूसरा उपाय सरल है। हम नए सर्वर जोड़ते हैं, उनके लिए मेटा विशेषताएँ लिखते हैं, इन लॉन्च विशेषताओं को आवश्यक सेवाओं के लिए लिखते हैं, अन्य सभी सेवाएं इस विशेषता के साथ सर्वर पर लॉन्च करने पर प्रतिबंध लगाती हैं।
तीसरा समाधान जटिल है। हम एक वर्चुअल डेटा सेंटर बनाते हैं: एक नए डेटा सेंटर के लिए कॉन्सल लॉन्च करें, इस डेटा सेंटर के लिए नोमड सर्वर नोड लॉन्च करें, इस क्षेत्र के लिए सर्वर नोड्स की संख्या को न भूलें। अब आप इस समर्पित वर्चुअल डेटा सेंटर में अलग-अलग सेवाएं चला सकते हैं।
6. तिजोरी के साथ एकीकरण
समाधान: खानाबदोश से बचें <-> तिजोरी परिपत्र निर्भरता।
लॉन्च किए गए वॉल्ट को घुमंतू पर कोई निर्भरता नहीं होनी चाहिए। घुमंतू में पंजीकृत तिजोरी का पता अधिमानतः सीधे तिजोरी को इंगित करना चाहिए, बिना बेलेंसरों (लेकिन मान्य) की परतों के। इस मामले में वॉल्ट आरक्षण डीएनएस - कंसूल डीएनएस या बाहरी के माध्यम से किया जा सकता है।
यदि वॉल्ट डेटा को नोमड कॉन्फ़िगरेशन फ़ाइलों में लिखा जाता है, तो नोमैड स्टार्टअप पर वॉल्ट तक पहुंचने की कोशिश करता है। यदि पहुंच असफल है, तो घुमंतू शुरू करने से इनकार कर देता है।
मैंने बहुत समय पहले चक्रीय निर्भरता के साथ एक गलती की थी, इसने एक बार संक्षेप में खानाबदोश क्लस्टर को पूरी तरह से नष्ट कर दिया था। घुमंतू को खानाबदोशों की परवाह किए बिना सही ढंग से लॉन्च किया गया था, लेकिन घुमंतू खुद ही घुमंतू में चल रहे बैलेंसरों के माध्यम से तिजोरी के पते को देखता था। नोमेड सर्वर नोड्स की पुन: स्थापना और रिबूटिंग ने बैलेंसर सेवाओं को फिर से शुरू किया, जिसके कारण सर्वर नोड्स को स्वयं शुरू करने में विफलता हुई।
7. महत्वपूर्ण राज्य सेवाओं का शुभारंभ
समाधान: मान्य है, लेकिन मैं नहीं।
क्या PostgreSQL, ClickHouse, Redis Cluster, RabbitMQ, MongoDB को Nomad के माध्यम से चलाना संभव है?
कल्पना करें कि आपके पास महत्वपूर्ण सेवाओं का एक सेट है, जिनमें से अधिकांश अन्य सेवाओं के लिए काम बंधा हुआ है। उदाहरण के लिए, PostgreSQL / ClickHouse में एक डेटाबेस। या Redis Cluster / MongoDB में सामान्य अल्पकालिक भंडारण। या रेडिस क्लस्टर / रैबिटएमक्यू में डेटा बस।
ये सभी सेवाएं किसी न किसी तरह से एक दोष-सहिष्णु योजना को लागू करती हैं: PostgreSQL के लिए Stolon / Patroni, Redis Cluster में इसका अपना बेड़ा कार्यान्वयन, RabbitMQ, MongoDB, ClickHouse में इसका अपना क्लस्टर कार्यान्वयन।
हां, इन सभी सेवाओं को विशिष्ट सर्वर के संदर्भ में घुमंतू के माध्यम से लॉन्च किया जा सकता है, लेकिन क्यों?
प्लस - लॉन्च में आसानी, अन्य सेवाओं की तरह एक एकल स्क्रिप्ट प्रारूप। किसी भी तरह की स्क्रिप्ट / अन्य चीज़ों से परेशान होने की आवश्यकता नहीं है।
माइनस विफलता का एक अतिरिक्त बिंदु है, जो कोई लाभ नहीं देता है। व्यक्तिगत रूप से, मैंने विभिन्न कारणों से दो बार नोमैड क्लस्टर को पूरी तरह से गिरा दिया: एक बार "घर", एक बार काम करना। यह खानाबदोश शुरू करने और ढिलाई के कारण शुरुआती दौर में था।
इसके अलावा, खानाबदोश 8 नंबर की समस्या के कारण बुरा व्यवहार करना शुरू कर देता है और सेवाओं को फिर से शुरू करता है। लेकिन अगर उस समस्या को हल कर दिया जाए, तो भी खतरा बना रहता है।
8. अस्थिर नेटवर्क में काम और सेवा को फिर से शुरू करना
समाधान: दिल की धड़कन ट्यूनिंग विकल्पों का उपयोग करें।
डिफ़ॉल्ट रूप से, घुमंतू को कॉन्फ़िगर किया गया है ताकि किसी भी अल्पकालिक नेटवर्क समस्या या सीपीयू लोड के कारण सर्वसम्मति का नुकसान हो और विज़ार्ड का फिर से चुनाव हो या एजेंट नोड को अप्राप्य चिह्नित करना। और यह सेवाओं के सहज रीबूट और उनके अन्य नोड्स में स्थानांतरण की ओर जाता है।
समस्या को ठीक करने से पहले "होम" क्लस्टर के आंकड़े: पुनः आरंभ करने से पहले कंटेनर का अधिकतम जीवनकाल लगभग 10 दिन है। यहां, यह अभी भी एक सर्वर पर एजेंट और सर्वर को चलाने और यूरोप में 5 अलग-अलग डेटा केंद्रों में रखकर बोझ है, जो सीपीयू पर एक बड़ा भार और एक कम स्थिर नेटवर्क का अर्थ है।
समस्या को ठीक करने से पहले काम कर रहे क्लस्टर के आँकड़े: पुनः आरंभ करने से पहले कंटेनर का अधिकतम जीवनकाल 2 महीने से अधिक है। घुमंतू सर्वर नोड्स के लिए अलग सर्वर और डेटा केंद्रों के बीच उत्कृष्ट नेटवर्क के कारण यहां सब कुछ अपेक्षाकृत अच्छा है।
डिफ़ॉल्ट मान
heartbeat_grace = "10s" min_heartbeat_ttl = "10s" max_heartbeats_per_second = 50.0
कोड को देखते हुए: इस कॉन्फ़िगरेशन में, हर 10 सेकंड में दिल की धड़कन बनाई जाती है। दो दिल की धड़कन के नुकसान के साथ, मास्टर का फिर से चुनाव या एजेंट नोड से सेवाओं का हस्तांतरण शुरू होता है। विवादास्पद सेटिंग्स, मेरी राय में। हम उन्हें आवेदन के आधार पर संपादित करते हैं।
यदि आपके पास कई इंस्टेंसेस में चलने वाली सभी सेवाएँ हैं और डेटा केंद्रों द्वारा वितरित की जाती हैं, तो सबसे अधिक संभावना है, यह आपके लिए सर्वर की अयोग्यता (लगभग 5 मिनट, नीचे दिए गए उदाहरण में) निर्धारित करने की लंबी अवधि के लिए कोई फर्क नहीं पड़ता है - हम दिल के अंतराल को कम करते हैं और दुर्गमता को निर्धारित करने की लंबी अवधि। यह मेरे होम क्लस्टर को स्थापित करने का एक उदाहरण है:
heartbeat_grace = "300s" min_heartbeat_ttl = "30s" max_heartbeats_per_second = 10.0
यदि आपके पास अच्छी नेटवर्क कनेक्टिविटी है, तो सर्वर नोड के लिए अलग सर्वर, और सर्वर की अयोग्यता का निर्धारण करने की अवधि महत्वपूर्ण है (एक उदाहरण में कुछ सेवा चल रही है और इसे जल्दी से स्थानांतरित करना महत्वपूर्ण है), फिर दुर्गमता निर्धारित करने की अवधि बढ़ाएं (heartbeat_grace)। वैकल्पिक रूप से, आप अधिक दिल की धड़कन (min_heartbeat_ttl को कम करके) कर सकते हैं - यह CPU पर लोड को थोड़ा बढ़ा देगा। उदाहरण कार्य क्लस्टर कॉन्फ़िगरेशन:
heartbeat_grace = "60s" min_heartbeat_ttl = "10s" max_heartbeats_per_second = 50.0
ये सेटिंग्स समस्या को पूरी तरह से ठीक करती हैं।
9. आवधिक कार्य शुरू करना
समाधान: खानाबदोश आवधिक सेवाओं का उपयोग किया जा सकता है, लेकिन समर्थन के लिए क्रोन अधिक सुविधाजनक है।
घुमंतू में समय-समय पर सेवा शुरू करने की क्षमता होती है।
एकमात्र प्लस इस कॉन्फ़िगरेशन की सादगी है।
पहला ऋण यह है कि यदि सेवा बार-बार शुरू होती है, तो यह कार्यों की सूची को लिट कर देगी। उदाहरण के लिए, हर 5 मिनट में स्टार्टअप पर, हर घंटे 12 अतिरिक्त कार्य सूची में जोड़े जाएंगे, जब तक कि जीसी घुमंतू ट्रिगर नहीं हो जाता है, जो पुराने कार्यों को हटा देगा।
दूसरा माइनस - यह स्पष्ट नहीं है कि इस तरह की सेवा की निगरानी कैसे ठीक से की जाए। कैसे समझें कि एक सेवा शुरू होती है, पूरी होती है और अंत तक अपना काम करती है?
नतीजतन, अपने लिए, मैं आवधिक कार्यों के "क्रोन" कार्यान्वयन के लिए आया:
- यह लगातार चलने वाले कंटेनर में एक नियमित क्रोन हो सकता है। क्रोन समय-समय पर एक निश्चित स्क्रिप्ट चलाता है। एक स्क्रिप्ट-हेल्थचेक को आसानी से ऐसे कंटेनर में जोड़ा जाता है, जो किसी भी ध्वज की जांच करता है जो एक रनिंग स्क्रिप्ट बनाता है।
- यह लगातार चलने वाला कंटेनर हो सकता है, लगातार चलने वाली सेवा के साथ। सेवा के अंदर एक आवधिक लॉन्च पहले ही लागू किया जा चुका है। या तो एक समान स्क्रिप्ट-हेल्थ-चेक या http-healthcheck को आसानी से ऐसी सेवा में जोड़ा जा सकता है, जो अपने "इनसाइड" द्वारा स्थिति की तुरंत जाँच करता है।
फिलहाल, मैं गो में अधिकांश समय क्रमशः लिखता हूं, मैं http हेल्थचेक के साथ दूसरा विकल्प पसंद करता हूं - गो और समय-समय पर लॉन्च, और http healthcheck'i को कोड की कुछ पंक्तियों के साथ जोड़ा जाता है।
10. निरर्थक सेवाएं प्रदान करना
समाधान: कोई सरल उपाय नहीं है। दो और मुश्किल विकल्प हैं।
घुमंतू डेवलपर्स द्वारा प्रदान की जाने वाली प्रावधान योजना चल रही सेवाओं की संख्या का समर्थन करना है। आप कहते हैं कि खानाबदोश "मुझे सेवा के 5 उदाहरण लॉन्च करें" और वह उन्हें वहां से शुरू करता है। वितरण पर कोई नियंत्रण नहीं है। उदाहरण एक ही सर्वर पर चल सकते हैं।
यदि सर्वर क्रैश हो जाता है, तो इंस्टेंसेस को अन्य सर्वरों में स्थानांतरित कर दिया जाता है। जबकि उदाहरणों को स्थानांतरित किया जा रहा है, सेवा काम नहीं करती है। यह एक बुरा आरक्षित प्रावधान विकल्प है।
हम इसे सही करते हैं:
- हम dif_hosts के माध्यम से सर्वर पर उदाहरण वितरित करते हैं।
- हम डेटा केंद्रों में उदाहरण वितरित करते हैं। दुर्भाग्य से, केवल फॉर्म सेवा 1 की सेवा की प्रतिलिपि बनाकर, उसी सामग्री के साथ सेवा 2, अलग-अलग नाम और विभिन्न डेटा केंद्रों में लॉन्च का एक संकेत है।
घुमंतू 0.9 में, एक कार्यक्षमता दिखाई देगी जो इस समस्या को ठीक करेगी: सर्वर और डेटा केंद्रों के बीच प्रतिशत अनुपात में सेवाओं को वितरित करना संभव होगा।
11. वेब यूआई घुमंतू
समाधान: अंतर्निहित यूआई भयानक है, हैशी-यूआई सुंदर है।
कंसोल क्लाइंट अधिकांश आवश्यक कार्यक्षमता करता है, लेकिन कभी-कभी आप ग्राफिक्स देखना चाहते हैं, बटन धक्का देते हैं ...
घुमंतू में एक अंतर्निहित यूआई है। यह बहुत सुविधाजनक नहीं है (कंसोल से भी बदतर)।
एकमात्र विकल्प जो मुझे पता है वह हैशी-उई ।
वास्तव में, अब मुझे व्यक्तिगत रूप से केवल "घुमंतू रन" के लिए कंसोल क्लाइंट की आवश्यकता है। और यहां तक कि यह सीआई को स्थानांतरित करने की योजना है।
12. स्मृति से ओवरस्क्रिप्शन के लिए समर्थन
हल: नहीं।
घुमंतू के वर्तमान संस्करण में, आपको सेवा के लिए एक सख्त मेमोरी सीमा निर्दिष्ट करनी होगी। यदि सीमा पार हो जाती है, तो सेवा OOM किलर द्वारा मार दी जाएगी।
ओवरस्क्रिप्शन तब होता है जब किसी सेवा के लिए सीमा "से और तक" निर्दिष्ट की जा सकती है। कुछ सेवाओं को सामान्य ऑपरेशन की तुलना में स्टार्टअप पर अधिक मेमोरी की आवश्यकता होती है। कुछ सेवाएं थोड़े समय के लिए सामान्य से अधिक मेमोरी का उपभोग कर सकती हैं।
सख्त प्रतिबंध या नरम का विकल्प चर्चा के लिए एक विषय है, लेकिन, उदाहरण के लिए, कुबेरनेट्स प्रोग्रामर को एक विकल्प बनाने की अनुमति देता है। दुर्भाग्य से, घुमंतू के वर्तमान संस्करणों में ऐसी कोई संभावना नहीं है। मैं मानता हूं कि भविष्य के संस्करणों में दिखाई देगा।
13. घुमंतू सेवाओं से सर्वर की सफाई
समाधान:
sudo systemctl stop nomad mount | fgrep alloc | awk '{print $3}' | xargs -I QQ sudo umount QQ sudo rm -rf /var/lib/nomad sudo docker ps | grep -v '(-1|-2|...)' | fgrep -v IMAGE | awk '{print $1}' | xargs -I QQ sudo docker stop QQ sudo systemctl start nomad
कभी-कभी "कुछ गलत हो जाता है।" सर्वर पर, यह एजेंट नोड को मारता है और इसे शुरू करने से इनकार करता है। या एजेंट नोड प्रतिसाद देना बंद कर देता है। या एजेंट नोड इस सर्वर पर सेवाओं को "खो देता है"।
यह कभी-कभी घुमंतू के पुराने संस्करणों के साथ हुआ, अब यह या तो नहीं होता है, या बहुत कम ही होता है।
इस मामले में क्या करना सबसे आसान है, यह देखते हुए कि नाली सर्वर वांछित परिणाम नहीं देगा? हम सर्वर को मैन्युअल रूप से साफ करते हैं:
- खानाबदोश एजेंट बंद करो।
- इसे बनाए जाने वाले माउंट पर umount बनाएं।
- सभी एजेंट डेटा हटाएं।
- हम सेवा कंटेनरों (यदि कोई हो) को फ़िल्टर करके सभी कंटेनरों को निकालते हैं।
- हम एजेंट शुरू करते हैं।
14. खानाबदोश तैनात करने का सबसे अच्छा तरीका क्या है?
समाधान: बेशक, कौंसल के माध्यम से।
इस मामले में कंसूल का मतलब किसी अतिरिक्त परत से नहीं है, बल्कि एक ऐसी सेवा है जो बुनियादी ढाँचे में व्यवस्थित रूप से फिट बैठती है, जो minuses की तुलना में अधिक प्लस देती है: DNS, KV संग्रहण, सेवाओं की खोज, सेवा की उपलब्धता की निगरानी, सूचनाओं के सुरक्षित आदान-प्रदान की क्षमता।
इसके अलावा, यह खुद को खानाबदोश के रूप में आसानी से खुलासा करता है।
15. कौन सा बेहतर है - घुमंतू या कुबेरनेट?
समाधान: इस पर निर्भर करता है ...
पहले, मुझे कभी-कभी कुबेरनेट्स के लिए एक प्रवास शुरू करने का विचार था - मैं सेवाओं की आवधिक सहज रिबूट से बहुत नाराज था (समस्या संख्या 8 देखें)। लेकिन समस्या के पूर्ण समाधान के बाद, मैं कह सकता हूं: घुमंतू मुझे इस समय सूट करता है।
दूसरी ओर: कुबेरनेट्स के पास सेवाओं का अर्ध-सहज पुन: लोड भी है - जब कुबेरनेट्स शेड्यूलर लोड के आधार पर उदाहरणों को पुनर्वितरित करता है। यह बहुत अच्छा नहीं है, लेकिन यह सबसे अधिक संभावना है कॉन्फ़िगर किया गया है।
खानाबदोश के लाभ: बुनियादी ढांचे को तैनात करना बहुत आसान है, सरल स्क्रिप्ट, अच्छा प्रलेखन, इन-कंसूल / वॉल्ट के लिए अंतर्निहित समर्थन, जो बदले में देता है: पासवर्ड स्टोरेज की समस्या का एक सरल समाधान, अंतर्निर्मित डीएनएस, आसानी से कॉन्फ़िगर किया जाने वाला सहायक।
कुबेरनेट्स के पेशेवरों: अब यह एक "वास्तविक मानक है।" लॉन्च के अच्छे विवरण और मानकीकरण के साथ अच्छे प्रलेखन, कई तैयार समाधान।
दुर्भाग्य से, मेरे पास कुबेरनेट्स में एक ही महान विशेषज्ञता नहीं है कि वह इस सवाल का जवाब दे सके - नए क्लस्टर के लिए क्या उपयोग किया जाए। नियोजित आवश्यकताओं पर निर्भर करता है।
यदि आपके पास बहुत सारे नामस्थान नियोजित (समस्या संख्या 5) या आपकी विशिष्ट सेवाएँ प्रारंभ में बहुत अधिक मेमोरी का उपभोग करती हैं, तो इसे मुक्त करना (समस्या संख्या 12) - निश्चित रूप से कुबेरनेट्स, क्योंकि घुमंतू में ये दो समस्याएं पूरी तरह से हल या असुविधाजनक नहीं हैं।