1 बिलियन फ्रेम प्रति सेकंड से अधिक की गति पर, यह यकीनन दुनिया में 8-बिट कंसोल क्लस्टर का सबसे तेज है।
 वितरित टेट्रिस (1989)
वितरित टेट्रिस (1989)ऐसे कंप्यूटर का निर्माण कैसे करें?
विधि
एक मुट्ठी भर सिलिकॉन लें, सुदृढीकरण प्रशिक्षण लागू करें, सुपर कंप्यूटर के साथ अनुभव करें, कंप्यूटर आर्किटेक्चर के लिए एक जुनून, पसीना और आँसू जोड़ें, इसे उबालने तक 1000 घंटे हिलाएं - और वॉयला।
किसी को ऐसे कंप्यूटर की आवश्यकता क्यों होगी?
संक्षेप में: कृत्रिम बुद्धिमत्ता को बढ़ाने की ओर बढ़ना।
 प्रयोगों के लिए उपयोग किए जाने वाले 48 आईबीएम न्यूरल कंप्यूटर बोर्डों में से एक
प्रयोगों के लिए उपयोग किए जाने वाले 48 आईबीएम न्यूरल कंप्यूटर बोर्डों में से एकऔर यहां एक अधिक विस्तृत संस्करण है
2016 वष। गहन शिक्षा सर्वव्यापी है। छवि मान्यता को दृढ़ तंत्रिका नेटवर्क के लिए एक सुलझा हुआ कार्य माना जा सकता है, और मेरी शोध रुचियां स्मृति और प्रबलित शिक्षण के साथ तंत्रिका नेटवर्क के लिए प्रयासरत हैं।
विशेष रूप से, Google डीपमाइंड के लेखकों के काम में यह दिखाया गया था कि डीप क्यू-न्यूरल नेटवर्क द्वारा समर्थित एक सरल शिक्षण का उपयोग करके, अटारी 2600 (होम गेम कंसोल, 1977 में जारी किया गया) के लिए किसी व्यक्ति के स्तर तक पहुंचना या यहां तक कि इसे विभिन्न खेलों में पार करना संभव है। और यह सब गेमप्ले देखने के दौरान होता है। इसने मेरा ध्यान खींचा।
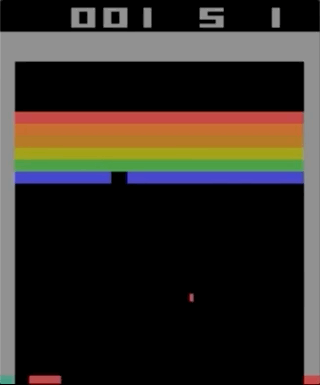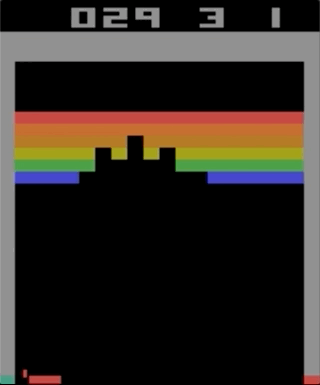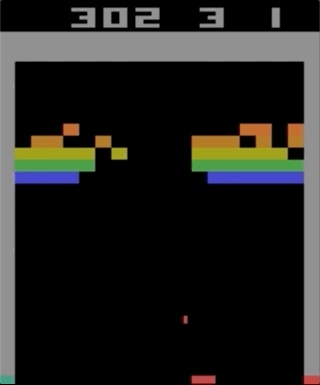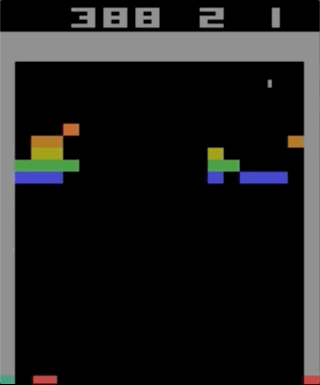 अटारी 2600, ब्रेकआउट के साथ खेलों में से एक। मशीन को एक सरल सुदृढीकरण सीखने के एल्गोरिथ्म का उपयोग करके प्रशिक्षित किया गया था। लाखों पुनरावृत्तियों के बाद, कंप्यूटर ने मनुष्यों की तुलना में बेहतर खेलना शुरू कर दिया।
अटारी 2600, ब्रेकआउट के साथ खेलों में से एक। मशीन को एक सरल सुदृढीकरण सीखने के एल्गोरिथ्म का उपयोग करके प्रशिक्षित किया गया था। लाखों पुनरावृत्तियों के बाद, कंप्यूटर ने मनुष्यों की तुलना में बेहतर खेलना शुरू कर दिया।मैंने अटारी 2600 खेलों के साथ प्रयोग करना शुरू किया। हालांकि, प्रभावशाली, को जटिल नहीं कहा जा सकता। कठिनाई को आपके कार्यों (जॉयस्टिक) और आपके परिणामों (अंक) के अनुसार कठिनाई की डिग्री से निर्धारित किया जा सकता है। समस्या तब प्रकट होती है जब प्रभाव को लंबे समय तक प्रतीक्षा करने की आवश्यकता होती है।
 एक उदाहरण के रूप में अधिक जटिल गेम का उपयोग करके समस्या का चित्रण। लेफ्ट - ब्रेकआउट (ATARI 2600) [लेखक से गलती हुई थी, यह एक पोंग गेम / लगभग है। ट्रांस।] बहुत तेज़ प्रतिक्रिया और तेज़ प्रतिक्रिया के साथ। राइट - मारियो लैंड (निंटेंडो गेम बॉय) कार्रवाई के प्रभावों पर तत्काल जानकारी प्रदान नहीं करता है; अप्रासंगिक टिप्पणियों के लंबे समय तक दो महत्वपूर्ण घटनाओं के बीच प्रकट हो सकता है।
एक उदाहरण के रूप में अधिक जटिल गेम का उपयोग करके समस्या का चित्रण। लेफ्ट - ब्रेकआउट (ATARI 2600) [लेखक से गलती हुई थी, यह एक पोंग गेम / लगभग है। ट्रांस।] बहुत तेज़ प्रतिक्रिया और तेज़ प्रतिक्रिया के साथ। राइट - मारियो लैंड (निंटेंडो गेम बॉय) कार्रवाई के प्रभावों पर तत्काल जानकारी प्रदान नहीं करता है; अप्रासंगिक टिप्पणियों के लंबे समय तक दो महत्वपूर्ण घटनाओं के बीच प्रकट हो सकता है।अधिगम को अधिक प्रभावी बनाने के लिए, व्यक्ति सरल खेलों से कुछ ज्ञान को स्थानांतरित करने के प्रयासों की कल्पना कर सकता है। यह कार्य अब अनसुलझा है, और अनुसंधान के लिए एक सक्रिय विषय है। OpenAI से हाल ही में प्रकाशित एक
कार्य बस उसी को मापने की कोशिश कर रहा है।
ज्ञान को स्थानांतरित करने की क्षमता केवल प्रशिक्षण को गति नहीं देगी - मेरा मानना है कि बुनियादी ज्ञान की अनुपस्थिति में कुछ सीखने की समस्याओं को बिल्कुल भी हल नहीं किया जा सकता है। हमें डेटा दक्षता चाहिए। खेल राजकुमार फारस की ले लो:

इसमें कोई स्पष्ट बिंदु नहीं हैं।
खेल को पूरा करने में 60 मिनट लगते हैं।

क्या यह वही दृष्टिकोण लागू करना संभव है जो अटारी 2600 पर काम लिखते समय उपयोग किया गया था? कितनी संभावना है कि आप यादृच्छिक कुंजी दबाकर अंत तक पहुंच सकते हैं?
इस प्रश्न ने मुझे समुदाय में योगदान करने के लिए प्रेरित किया, जो इस समस्या को हल करने की कोशिश में शामिल हैं। वास्तव में, हमारे पास चिकन और अंडे का कार्य है - हमें एक बेहतर एल्गोरिथ्म की आवश्यकता है जो हमें एक संदेश प्रसारित करने की अनुमति देगा, हालांकि, इसके लिए अनुसंधान की आवश्यकता होती है, और प्रयोग समय लेने वाले होते हैं, क्योंकि हमारे पास अधिक कुशल एल्गोरिदम नहीं है।
 ज्ञान हस्तांतरण का एक उदाहरण: कल्पना करें कि हमने पहली बार एक साधारण गेम खेलना सीखा, जैसे कि बाईं ओर। फिर हम ऐसी अवधारणाओं को "रेस", "कार", "ट्रैक", "जीत" के रूप में सहेजते हैं और रंग या त्रि-आयामी मॉडल सीखते हैं। हमारा तर्क है कि खेलों के बीच सामान्य अवधारणाओं को "आगे बढ़ाया" जा सकता है। खेलों की समानता उनके बीच स्थानांतरित ज्ञान की संख्या से निर्धारित की जा सकती है। उदाहरण के लिए, टेट्रिस और एफ 1 गेम समान नहीं होंगे।
ज्ञान हस्तांतरण का एक उदाहरण: कल्पना करें कि हमने पहली बार एक साधारण गेम खेलना सीखा, जैसे कि बाईं ओर। फिर हम ऐसी अवधारणाओं को "रेस", "कार", "ट्रैक", "जीत" के रूप में सहेजते हैं और रंग या त्रि-आयामी मॉडल सीखते हैं। हमारा तर्क है कि खेलों के बीच सामान्य अवधारणाओं को "आगे बढ़ाया" जा सकता है। खेलों की समानता उनके बीच स्थानांतरित ज्ञान की संख्या से निर्धारित की जा सकती है। उदाहरण के लिए, टेट्रिस और एफ 1 गेम समान नहीं होंगे।इसलिए, मैंने दूसरे आदर्श दृष्टिकोण का उपयोग करने का फैसला किया, प्रारंभिक मंदी से बचते हुए, नाटकीय रूप से सिस्टम को तेज किया। मेरे लक्ष्य थे:
- त्वरित वातावरण (कल्पना करें कि राजकुमार फारस को 100 गुना तेजी से पूरा किया जा सकता है) और एक साथ 100,000 खेलों का शुभारंभ।
- अनुसंधान के लिए अधिक उपयुक्त वातावरण (हम कार्यों पर ध्यान केंद्रित करते हैं, लेकिन प्रारंभिक गणना पर नहीं, हमारे पास विभिन्न खेलों तक पहुंच है)।
प्रारंभ में, मैंने सोचा था कि प्रदर्शन की अड़चन किसी तरह एमुलेटर कोड की जटिलता पर निर्भर हो सकती है (उदाहरण के लिए, स्टेला कोड बेस बड़ा है, और यह C ++ एब्स्ट्रैक्ट पर निर्भर करता है - एमुलेटर के लिए सबसे अच्छा विकल्प नहीं)।
कंसोल

कुल मिलाकर, मैंने कई प्लेटफार्मों पर काम किया, जो पहले कभी बनाए गए खेलों (पोंग गेम के साथ) में से एक के साथ शुरू हुआ था - आर्केड स्पेस इनवेस्टर्स, अटारी 2600, एनईएस और गेम बॉय। और यह सब C में लिखा गया था।
मैं प्रति सेकंड 2000-3000 की अधिकतम फ्रेम दर तक पहुंचने में कामयाब रहा। प्रयोगों के परिणाम प्राप्त करने के लिए, हमें लाखों या अरबों फ़्रेमों की आवश्यकता है, इसलिए यह अंतर बहुत बड़ा था।
 FPGA में काम कर रहे अंतरिक्ष आक्रमणकारियों - कम गति डिबगिंग मोड। FPGA काउंटर घड़ी चक्र की संख्या को दर्शाता है जो बीत चुके हैं।
FPGA में काम कर रहे अंतरिक्ष आक्रमणकारियों - कम गति डिबगिंग मोड। FPGA काउंटर घड़ी चक्र की संख्या को दर्शाता है जो बीत चुके हैं।और फिर मैंने सोचा - क्या होगा अगर हम लोहे के साथ सही वातावरण में तेजी ला सकते हैं। उदाहरण के लिए, मूल अंतरिक्ष आक्रमणकारियों 1 मेगाहर्ट्ज की आवृत्ति के साथ 8080 सीपीयू में चले गए। मैं 3 गीगाहर्ट्ज़ एक्सॉन प्रोसेसर पर 8080 40 मेगाहर्ट्ज सीपीयू का अनुकरण करने में कामयाब रहा। बुरा नहीं है, लेकिन मैंने FPGA के अंदर यह सब डालने के बाद, आवृत्ति 400 मेगाहर्ट्ज तक बढ़ गई। इसका मतलब था कि एक स्ट्रीम से 24,000 FPS - 30 GHz Xeon के बराबर! क्या मैंने उल्लेख किया है कि आप एक औसत FPGA में 100 8080 प्रोसेसर रटना कर सकते हैं? इससे पहले से ही 2.4 मिलियन FPS की पैदावार होती है।
 100 मेगाहर्ट्ज हार्डवेयर त्वरण के साथ अंतरिक्ष आक्रमणकारियों, पूर्ण गति का एक चौथाई
100 मेगाहर्ट्ज हार्डवेयर त्वरण के साथ अंतरिक्ष आक्रमणकारियों, पूर्ण गति का एक चौथाई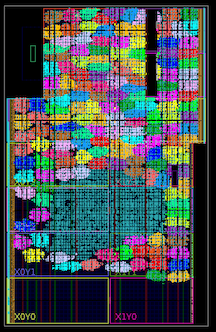 Xilinx Kintex 7045 FPGA के अंदर सौ से अधिक कोर (चमकीले रंगों से संकेत मिलता है; बीच में नीला स्थान प्रदर्शन के लिए सामान्य तर्क है)।
Xilinx Kintex 7045 FPGA के अंदर सौ से अधिक कोर (चमकीले रंगों से संकेत मिलता है; बीच में नीला स्थान प्रदर्शन के लिए सामान्य तर्क है)। असमान निष्पादन पथ
असमान निष्पादन पथआप पूछ सकते हैं, GPU के बारे में क्या? संक्षेप में, हमें
MIMD की तरह समरूपता की आवश्यकता है,
SIMD की नहीं। एक छात्र के रूप में, मैंने कुछ समय के लिए एक जीपीयू पर मोंटे कार्लो वृक्ष खोज को
लागू करने पर काम किया (ऐसी खोज का उपयोग अल्फ़ा में किया गया था)।
उस समय, मैंने ऐसे कोड को निष्पादित करने के लिए SIMD (IBM Cell, Xeon Phi, AVX CPU) के सिद्धांत पर काम करने वाले GPU और हार्डवेयर के अन्य टुकड़ों को पाने के लिए अनगिनत घंटे बिताए। कुछ साल पहले, मैंने सोचना शुरू किया कि सुदृढीकरण प्रशिक्षण से संबंधित समस्याओं को हल करने के लिए विशेष रूप से तैयार किए गए हार्डवेयर को स्वतंत्र रूप से विकसित करने में सक्षम होना अच्छा होगा।
 MIMD संगामिति
MIMD संगामितिATARI 2600, NES या गेम बॉय?
8080 में, मैंने अंतरिक्ष आक्रमणकारियों, एनईएस, 2600 और गेम बॉय को लागू किया। और यहां उनके बारे में कुछ तथ्य और उनमें से प्रत्येक के लाभ हैं।
 एनईएस पचमन
एनईएस पचमनअंतरिक्ष आक्रमणकारी सिर्फ एक वार्म-अप थे। हम उन्हें काम पर लाने में कामयाब रहे, लेकिन यह केवल एक खेल था, इसलिए परिणाम बहुत उपयोगी नहीं था।
अटारी 2600 वास्तव में सुदृढीकरण सीखने के अनुसंधान में मानक है। MOS 6507 प्रोसेसर प्रसिद्ध 6502 का एक सरलीकृत संस्करण है, इसका डिज़ाइन 8080 की तुलना में अधिक सुरुचिपूर्ण और अधिक कुशल है। मैंने 2600 को केवल खेल और उनके ग्राफिक्स से संबंधित कुछ प्रतिबंधों के कारण नहीं चुना।
मैंने एनईएस (निंटेंडो एंटरटेनमेंट सिस्टम) को भी लागू किया है, यह सीपीयू को 2600 के साथ साझा करता है। गेम 2600 से बहुत बेहतर हैं। लेकिन दोनों कंसोल एक अति जटिल ग्राफिक्स प्रोसेसिंग पाइप लाइन और कई कारतूस प्रारूपों से ग्रस्त हैं जिन्हें समर्थन देने की आवश्यकता है।
इस बीच, मैंने निन्टेंडो गेम बॉय को फिर से खोज लिया। और यही मैं ढूंढ रहा था।
गेम बॉय इतना कूल क्यों है?
 गेम बॉय कलर के लिए 1049 क्लासिक गेम्स और 576 गेम्स
गेम बॉय कलर के लिए 1049 क्लासिक गेम्स और 576 गेम्सकुल मिलाकर, 1000 से अधिक खेल, एक बहुत बड़ी विविधता, उच्च गुणवत्ता, उनमें से कुछ काफी जटिल (राजकुमार) हैं, ज्ञान और प्रशिक्षण के हस्तांतरण पर अनुसंधान के लिए खेलों को समूहीकृत और सौंपा जा सकता है (उदाहरण के लिए, टेट्रिस, रेसिंग गेम्स, मारियो) के विकल्प हैं। फारस के खेल को हल करने के लिए, आपको कुछ अन्य समान गेम से ज्ञान स्थानांतरित करने की आवश्यकता हो सकती है जिसमें अंक स्पष्ट रूप से इंगित किए जाते हैं (राजकुमार में यह नहीं है)।
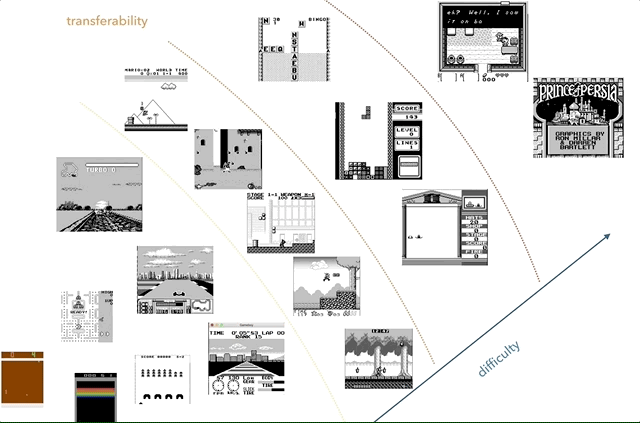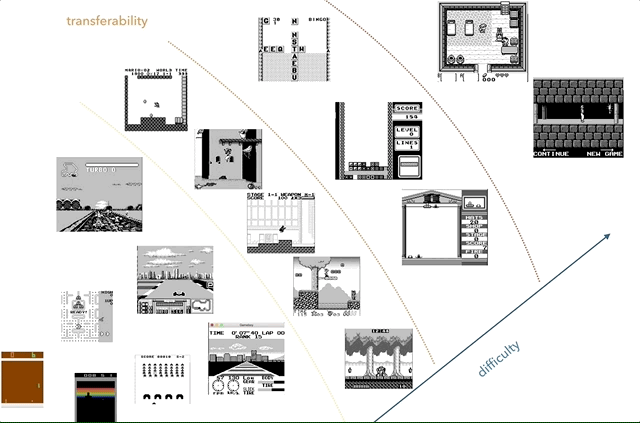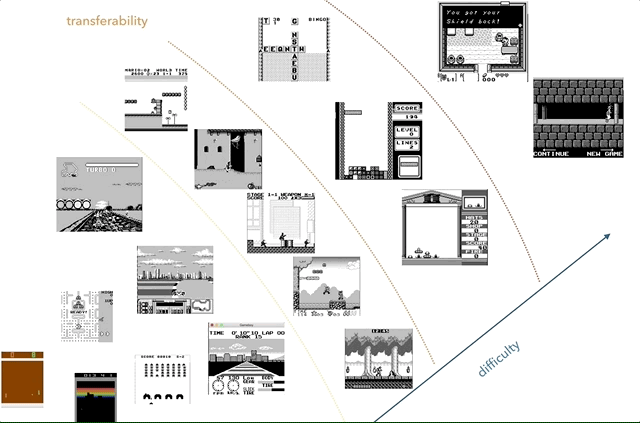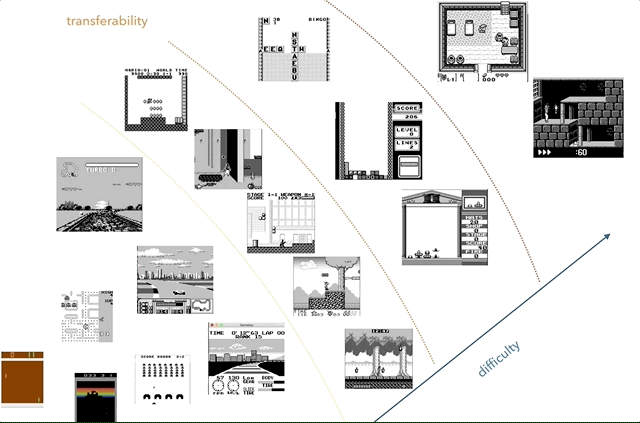 निन्टेंडो गेम बॉय मेरा पसंदीदा ज्ञान अंतरण अनुसंधान मंच है। ग्राफ़ पर, मैंने जटिलता (व्यक्तिपरक) और समानता (कॉन्सेप्ट जैसे रेसिंग, जम्पिंग, शूटिंग, विभिन्न खेलों जैसे टेट्रिस? किसी को HATRIS खेला है?) के अनुसार खेलों को समूह बनाने की कोशिश की।
निन्टेंडो गेम बॉय मेरा पसंदीदा ज्ञान अंतरण अनुसंधान मंच है। ग्राफ़ पर, मैंने जटिलता (व्यक्तिपरक) और समानता (कॉन्सेप्ट जैसे रेसिंग, जम्पिंग, शूटिंग, विभिन्न खेलों जैसे टेट्रिस? किसी को HATRIS खेला है?) के अनुसार खेलों को समूह बनाने की कोशिश की।क्लासिक गेम बॉय में एक बहुत ही सरल स्क्रीन (160x144, 2-बिट रंग) है, इसलिए प्रीप्रोसेसिंग सरल हो जाता है, और आप महत्वपूर्ण चीजों पर ध्यान केंद्रित कर सकते हैं। 2600 में, यहां तक कि साधारण खेलों में भी कई रंग होते हैं। इसके अलावा, गेम ब्वॉय ऑब्जेक्ट पर बेहतर प्रदर्शन किया जाता है, बिना पलक झपकाए और बिना अधिकतम दो लगातार फ्रेम लेने की आवश्यकता के बिना।

एनईएस या 2600 की तरह कोई पागल मेमोरी लेआउट नहीं है। अधिकांश गेम 2-3 मैपर के साथ काम करने के लिए बनाए जा सकते हैं।
कॉम्पैक्ट कोड - मैं सी के 700 से अधिक लाइनों में सी में पूरे एमुलेटर को फिट करने में कामयाब रहा, और मेरा वेरिलॉग कार्यान्वयन 500 लाइनों में फिट बैठता है।
अंतरिक्ष आक्रमणकारियों का वही सरल संस्करण है जैसा कि आर्केड में है।
और यहाँ वह मेरा 1989 का डॉट-मैट्रिक्स गेम बॉय और FPGA संस्करण है जो 4K स्क्रीन पर एचडीएमआई के माध्यम से काम करता है।

और यहाँ क्या मेरा पुराना गेम बॉय नहीं हो सकता है:
 लोहे के साथ त्वरित टेट्रिस - वास्तविक समय में स्क्रीन से रिकॉर्डिंग, गति अधिकतम का 1/4 है।
लोहे के साथ त्वरित टेट्रिस - वास्तविक समय में स्क्रीन से रिकॉर्डिंग, गति अधिकतम का 1/4 है।क्या इसका कोई वास्तविक लाभ है?
हाँ है। अब तक, मैंने सरल परिस्थितियों में प्रणाली का परीक्षण किया है, नियमों के एक बाहरी नेटवर्क के साथ जो व्यक्तिगत गेम बॉयज़ के साथ बातचीत करता है। अधिक विशेष रूप से, मैंने A3C (एडवांटेज एक्टर क्रिटिक) एल्गोरिथ्म का उपयोग किया, और मैं इसे एक अलग पोस्ट में वर्णित करने की योजना बना रहा हूं। मेरे सहकर्मी ने इसे FPGA के दृढ़ नेटवर्क से जोड़ा, और यह काम करता है।
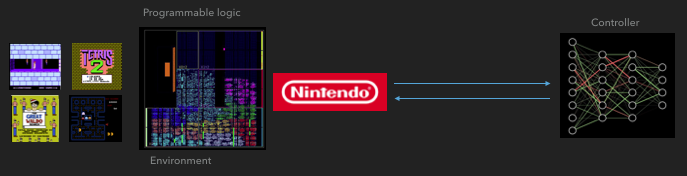 एफजीपीए एक तंत्रिका नेटवर्क के साथ कैसे संचार करता है
एफजीपीए एक तंत्रिका नेटवर्क के साथ कैसे संचार करता है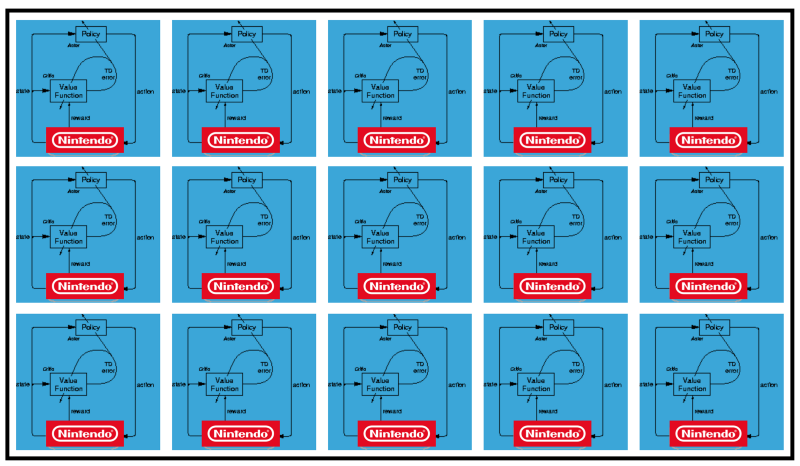 वितरित A3C
वितरित A3C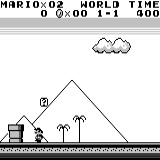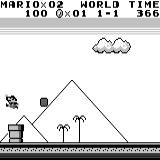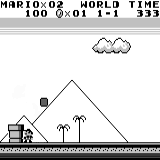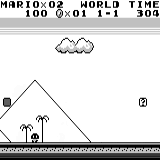 मारियो भूमि: प्रारंभिक स्थिति। एक यादृच्छिक कीस्ट्रोक हमें दूर नहीं ले जाएगा। ऊपरी दायां कोना शेष समय दिखाता है। अगर हम भाग्यशाली हैं, तो हम जल्द ही खेल को छूने के बाद खेल को समाप्त कर देंगे। यदि नहीं, तो "खोने" में 400 सेकंड लगेंगे।
मारियो भूमि: प्रारंभिक स्थिति। एक यादृच्छिक कीस्ट्रोक हमें दूर नहीं ले जाएगा। ऊपरी दायां कोना शेष समय दिखाता है। अगर हम भाग्यशाली हैं, तो हम जल्द ही खेल को छूने के बाद खेल को समाप्त कर देंगे। यदि नहीं, तो "खोने" में 400 सेकंड लगेंगे।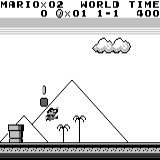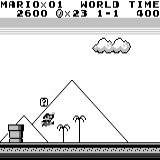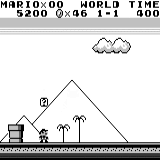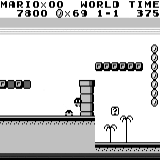 मारियो भूमि: एक घंटे के खेल के बाद, मारियो ने एक पाइप में रेंगते हुए दौड़ना, कूदना और यहां तक कि एक गुप्त कमरा खोलना भी सीखा।
मारियो भूमि: एक घंटे के खेल के बाद, मारियो ने एक पाइप में रेंगते हुए दौड़ना, कूदना और यहां तक कि एक गुप्त कमरा खोलना भी सीखा। पीएसी मैन: लगभग एक घंटे के प्रशिक्षण के बाद, तंत्रिका नेटवर्क पूरे खेल को एक बार पूरा करने में सक्षम था (सभी बिंदुओं को खाया)।
पीएसी मैन: लगभग एक घंटे के प्रशिक्षण के बाद, तंत्रिका नेटवर्क पूरे खेल को एक बार पूरा करने में सक्षम था (सभी बिंदुओं को खाया)।निष्कर्ष
मैं यह सोचना चाहूंगा कि अगला दशक वह दौर होगा जब सुपरकंप्यूटिंग और एआई एक-दूसरे को खोजेंगे। मैं ऐसा हार्डवेयर रखना चाहूंगा जो मुझे वांछित AI एल्गोरिथ्म के अनुकूल होने के लिए एक निश्चित स्तर तक खुद को स्थापित करने की अनुमति देता है।
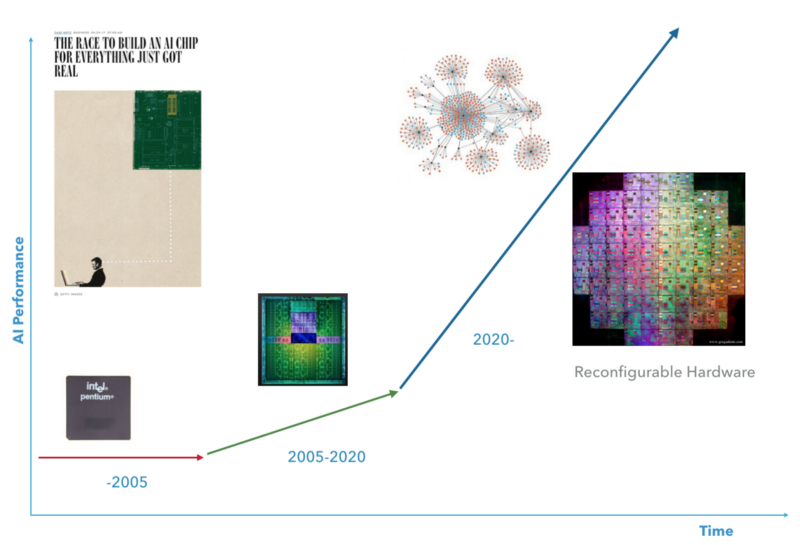 अगले दशकसी। में गेम बॉय के लिए कोड
अगले दशकसी। में गेम बॉय के लिए कोडडिबगिंग
लोग अक्सर मुझसे पूछते हैं: सबसे मुश्किल क्या था? यह बात है - पूरी परियोजना काफी दर्दनाक थी। शुरुआत के लिए, गेम बॉय के लिए कोई विनिर्देश नहीं है। हमने जो कुछ भी सीखा, वह रिवर्स इंजीनियरिंग के लिए धन्यवाद मिला, अर्थात्, हमने एक मध्यवर्ती कार्य, जैसे कि एक खेल शुरू किया, और देखा कि यह कैसे किया जाता है। यह मानक सॉफ़्टवेयर डिबगिंग से बहुत अलग है, क्योंकि यहां हम प्रोग्राम चलाने वाले हार्डवेयर को डीबग करते हैं। मुझे इसे पूरा करने के लिए विभिन्न तरीकों के साथ आना पड़ा। और मैंने इस बारे में बात की कि किसी प्रक्रिया की निगरानी करना कितना मुश्किल है जब वह 100 मेगाहर्ट्ज की आवृत्ति पर चलती है? ओह, और वहां कोई प्रिंटफ नहीं है।
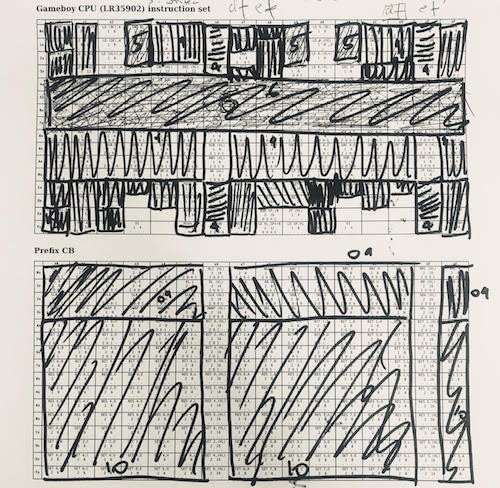 सीपीयू को लागू करने के लिए एक दृष्टिकोण उनके कार्यों पर निर्देशों को समूहित करना है। 6502 के साथ यह बहुत आसान है। LR35092 सभी "यादृच्छिक" बकवास का एक बहुत crammed और कई अपवाद हैं। सीपीयू गेम बॉय के साथ काम करते समय मैंने इस टेबल का इस्तेमाल किया। मैंने एक लालची रणनीति का उपयोग किया - मैंने निर्देशों का सबसे बड़ा टुकड़ा लिया, उन्हें लागू किया और उन्हें हटा दिया, फिर उन्हें दोहराया। निर्देशों का 1/4 ALU है, 1/4 रजिस्टर लोडिंग है, जिसे काफी जल्दी लागू किया जा सकता है। स्पेक्ट्रम के दूसरी तरफ सभी प्रकार की अलग-अलग चीजें हैं, जैसे "एचएल से एसपी को एक संकेत के साथ अपलोड करें", जिसे अलग से संसाधित किया जाना था।
सीपीयू को लागू करने के लिए एक दृष्टिकोण उनके कार्यों पर निर्देशों को समूहित करना है। 6502 के साथ यह बहुत आसान है। LR35092 सभी "यादृच्छिक" बकवास का एक बहुत crammed और कई अपवाद हैं। सीपीयू गेम बॉय के साथ काम करते समय मैंने इस टेबल का इस्तेमाल किया। मैंने एक लालची रणनीति का उपयोग किया - मैंने निर्देशों का सबसे बड़ा टुकड़ा लिया, उन्हें लागू किया और उन्हें हटा दिया, फिर उन्हें दोहराया। निर्देशों का 1/4 ALU है, 1/4 रजिस्टर लोडिंग है, जिसे काफी जल्दी लागू किया जा सकता है। स्पेक्ट्रम के दूसरी तरफ सभी प्रकार की अलग-अलग चीजें हैं, जैसे "एचएल से एसपी को एक संकेत के साथ अपलोड करें", जिसे अलग से संसाधित किया जाना था। डिबगिंग: उस कोड को हार्डवेयर पर चलाएं जिसे आप डिबग कर रहे हैं, अपने कार्यान्वयन और अतिरिक्त जानकारी का एक लॉग लिखें (यहां दाईं ओर मेरे सी-एमुलेटर के साथ बाईं ओर वेरिलॉग कोड की तुलना दर्शायी गई है)। फिर विसंगतियों (नीला) को खोजने के लिए लॉग के लिए अलग-अलग रन करें। स्वचालन का उपयोग करने का एक कारण यह है कि कई मामलों में मुझे लाखों निष्पादन चक्रों के बाद समस्याएं मिलीं जब एक एकल सीपीयू ध्वज ने स्नोबॉल प्रभाव पैदा किया। मैंने कई तरीकों की कोशिश की, और यह सबसे प्रभावी निकला।
डिबगिंग: उस कोड को हार्डवेयर पर चलाएं जिसे आप डिबग कर रहे हैं, अपने कार्यान्वयन और अतिरिक्त जानकारी का एक लॉग लिखें (यहां दाईं ओर मेरे सी-एमुलेटर के साथ बाईं ओर वेरिलॉग कोड की तुलना दर्शायी गई है)। फिर विसंगतियों (नीला) को खोजने के लिए लॉग के लिए अलग-अलग रन करें। स्वचालन का उपयोग करने का एक कारण यह है कि कई मामलों में मुझे लाखों निष्पादन चक्रों के बाद समस्याएं मिलीं जब एक एकल सीपीयू ध्वज ने स्नोबॉल प्रभाव पैदा किया। मैंने कई तरीकों की कोशिश की, और यह सबसे प्रभावी निकला। आपको बहुत सारी कॉफी की आवश्यकता होगी!
आपको बहुत सारी कॉफी की आवश्यकता होगी! ये किताबें 40 साल पुरानी हैं। यह उनके माध्यम से अफवाह और उस समय उन उपयोगकर्ताओं की आंखों के माध्यम से कंप्यूटर की दुनिया को देखने के लिए अद्भुत था - मुझे भविष्य से मेहमान की तरह महसूस हुआ।
ये किताबें 40 साल पुरानी हैं। यह उनके माध्यम से अफवाह और उस समय उन उपयोगकर्ताओं की आंखों के माध्यम से कंप्यूटर की दुनिया को देखने के लिए अद्भुत था - मुझे भविष्य से मेहमान की तरह महसूस हुआ।OpenAI अनुसंधान अनुरोध
पहले मैं मेमोरी के संदर्भ में गेम के साथ काम करना चाहता था, जैसा कि ओपनएआई के एक
पोस्ट में वर्णित है।
आश्चर्यजनक रूप से, स्मृति राज्यों का प्रतिनिधित्व करने वाले इनपुट पर अच्छी तरह से काम करने के लिए क्यू-लर्निंग प्राप्त करना अप्रत्याशित रूप से कठिन था।
इस परियोजना के पास समाधान नहीं हो सकता है। यह पता लगाना अप्रत्याशित होगा कि क्यू-सीखना अटारी में मेमोरी के साथ काम करने में कभी सफल नहीं होगा, लेकिन संभावना है कि यह कार्य काफी मुश्किल होगा।
यह देखते हुए कि अटारी पर खेल केवल 128 बी मेमोरी का उपयोग करते थे, फुल स्क्रीन फ्रेम के बजाय इन 128 बी को संसाधित करना बहुत आकर्षक लग रहा था। मुझे मिश्रित परिणाम मिले, इसलिए मैंने इसका पता लगाना शुरू कर दिया।
और यद्यपि मैं यह साबित नहीं कर सकता कि स्मृति से सीखना असंभव है, मैं यह दिखा सकता हूं कि स्मृति की पूर्ण स्थिति को प्रतिबिंबित करने वाली धारणा गलत है। अटारी 2600 सीपीयू (6507) मेमोरी के 128 बी का उपयोग करता है, लेकिन यह अभी भी एक अलग सर्किट (टीआईए, टीवी के लिए एडॉप्टर, एक जीपीयू जैसा कुछ) पर रहने वाले अतिरिक्त रजिस्टरों तक पहुंचता है। इन रजिस्टरों का उपयोग वस्तुओं (रैकेट, रॉकेट, बॉल, टकराव) के बारे में जानकारी संग्रहीत करने और संसाधित करने के लिए किया जाता है। दूसरे शब्दों में, वे दुर्गम होंगे यदि हम केवल स्मृति पर विचार करते हैं। NES और गेम बॉय में अतिरिक्त रजिस्टर भी हैं जो स्क्रीन और स्क्रॉल को नियंत्रित करने के लिए उपयोग किए जाते हैं। केवल एक स्मृति खेल की पूर्ण स्थिति को प्रतिबिंबित नहीं करती है।
केवल 8080 सीधे वीडियो मेमोरी में डेटा संग्रहीत करता है, जो आपको गेम की पूर्ण स्थिति को निकालने की अनुमति देता है। अन्य मामलों में, रैम के बाहर "जीपीयू" रजिस्टर सीपीयू और स्क्रीन बफर के बीच जुड़े हुए हैं।
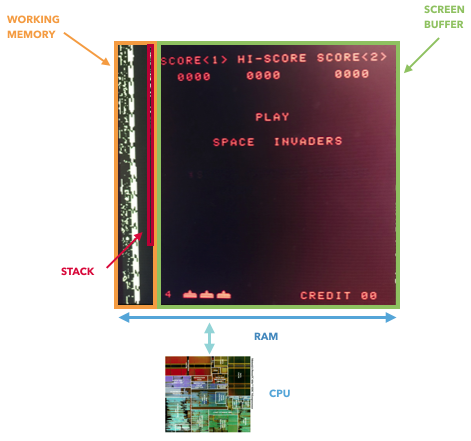
एक दिलचस्प तथ्य: यदि आप जीपीयू के इतिहास पर शोध करते हैं, तो 8080 पहला "ग्राफिक्स एक्सीलेटर" हो सकता है - इसमें एक बाहरी बदलाव रजिस्टर होता है जो आपको एक ही आदेश के साथ अंतरिक्ष आक्रमणकारियों को स्थानांतरित करने की अनुमति देता है, जो सीपीयू को लोड करता है।

EOF