
वाणिज्यिक (और गैर-वाणिज्यिक, भी) सेवाओं का मुख्य कार्य हमेशा उपयोगकर्ता के लिए उपलब्ध होना है। हालाँकि हर कोई क्रैश करता है, लेकिन सवाल यह है कि आईटी टीम उन्हें कम से कम करने के लिए क्या करती है। हमने बेन ट्रेनीयोर, माइक डाहलिन, विवेक राऊ और बेट्सी बेयर के एक लेख का अनुवाद किया, "सेवा विश्वसनीयता की गणना", जिसमें बताया गया है, उदाहरण के लिए, Google, क्यों 100% विश्वसनीयता संकेतक के लिए एक गलत संदर्भ बिंदु है, "चार राशियों" का नियम क्या है और कैसे, व्यवहार में, गणितीय रूप से सेवा और / या इसके महत्वपूर्ण घटकों के बड़े और छोटे परिणामों की व्यवहार्यता की भविष्यवाणी करते हैं - डाउनटाइम की अपेक्षित राशि, एक विफलता का पता लगाने में समय, और सेवा को पुनर्स्थापित करने का समय।
सेवा विश्वसनीयता की गणना
आपका सिस्टम उसके घटकों जितना ही विश्वसनीय है
बेन ट्रेनर, माइक डालिन, विवेक राऊ, बेट्सी बेयर
जैसा कि पुस्तक में वर्णित है " साइट विश्वसनीयता इंजीनियरिंग: Google में विश्वसनीयता और विश्वसनीयता " (बाद में एसआरई पुस्तक के रूप में संदर्भित), Google उत्पादों और सेवाओं का विकास आक्रामक एसएलओ (सेवा-स्तरीय उद्देश्यों, सेवा स्तर के लक्ष्यों) को बनाए रखते हुए नए कार्यों की रिहाई की उच्च गति प्राप्त कर सकता है। ) उच्च विश्वसनीयता और त्वरित प्रतिक्रिया सुनिश्चित करने के लिए। एसएलओ को यह आवश्यक है कि सेवा लगभग हमेशा अच्छी स्थिति में हो और लगभग हमेशा तेज। इसके अलावा, SLO भी किसी विशेष सेवा के लिए इस "लगभग हमेशा" के सटीक मूल्यों का संकेत देते हैं। SLO निम्नलिखित टिप्पणियों पर आधारित हैं:
सामान्य स्थिति में, किसी भी सॉफ्टवेयर सेवा या सिस्टम के लिए 100% विश्वसनीयता संकेतक के लिए गलत संदर्भ बिंदु है, क्योंकि कोई भी उपयोगकर्ता 100% और 99,999% उपलब्धता के बीच अंतर को नोटिस नहीं कर सकता है। उपयोगकर्ता और सेवा के बीच कई अन्य प्रणालियाँ हैं (उनका लैपटॉप, होम वाई-फाई, प्रदाता, बिजली आपूर्ति ...), और कुल मिलाकर ये सभी प्रणालियाँ 99.999% मामलों में उपलब्ध नहीं हैं, लेकिन बहुत कम बार। इसलिए, 99.999% और 100% के बीच का अंतर अन्य प्रणालियों की अक्षमता के कारण यादृच्छिक कारकों के कारण खो जाता है, और उपयोगकर्ता को इस तथ्य से कोई लाभ नहीं मिलता है कि हमने सिस्टम उपलब्धता के प्रतिशत के इस अंतिम अंश को प्राप्त करने में बहुत प्रयास किया। इस नियम के गंभीर अपवाद एंटी-लॉक ब्रेक और पेसमेकर हैं!
SLO SLI (सेवा-स्तरीय संकेतक) और SLAs (सेवा-स्तर समझौते) से कैसे संबंधित है, इसकी विस्तृत चर्चा के लिए, सेवा अध्याय का SRE लक्ष्य स्तर देखें। इस अध्याय में यह भी विस्तार से वर्णन किया गया है कि किसी विशेष सेवा या प्रणाली के लिए प्रासंगिक मेट्रिक्स का चयन कैसे करें, जो बदले में उस सेवा या प्रणाली के लिए उपयुक्त एसएलओ की पसंद का निर्धारण करता है।
यह लेख सेवा घटकों पर ध्यान केंद्रित करने के लिए एसएलओ विषय का विस्तार करता है। विशेष रूप से, हम यह जांच करेंगे कि महत्वपूर्ण घटकों की विश्वसनीयता किसी सेवा की विश्वसनीयता को कैसे प्रभावित करती है, साथ ही साथ सिस्टम को कैसे डिज़ाइन करें कि कैसे प्रभाव को कम किया जाए या महत्वपूर्ण घटकों की संख्या को कम किया जा सके।
Google द्वारा दी जाने वाली अधिकांश सेवाओं का लक्ष्य उपयोगकर्ताओं के लिए 99.99 प्रतिशत (कभी-कभी "चार नाइन" कहा जाता है) पहुंच प्रदान करना है। कुछ सेवाओं के लिए, उपयोगकर्ता अनुबंध में कम संख्या का संकेत दिया गया है, हालांकि, लक्ष्य 99.99% कंपनी के अंदर संग्रहीत है। यह उच्च बार उन स्थितियों में एक फायदा देता है जहां उपयोगकर्ता समझौते की शर्तों के उल्लंघन से बहुत पहले सेवा के प्रदर्शन के बारे में शिकायत करते हैं, क्योंकि SRE टीम का लक्ष्य नंबर 1 उपयोगकर्ताओं को सेवाओं से खुश करना है। कई सेवाओं के लिए, 99.99% का आंतरिक लक्ष्य मध्यम जमीन का प्रतिनिधित्व करता है, जो लागत, जटिलता और विश्वसनीयता को संतुलित करता है। कुछ अन्य लोगों के लिए, विशेष रूप से वैश्विक क्लाउड सेवाओं में, आंतरिक लक्ष्य 99.999% है।
विश्वसनीयता 99.99%: अवलोकन और निष्कर्ष
आइए 99.99% की विश्वसनीयता के साथ सेवा के डिजाइन और संचालन के बारे में कुछ महत्वपूर्ण टिप्पणियों और निष्कर्ष देखें, और फिर अभ्यास करने के लिए आगे बढ़ें।
अवलोकन # 1: कारणों की विफलता
विफलताएं दो मुख्य कारणों से होती हैं: सेवा के साथ समस्याएं और सेवा के महत्वपूर्ण घटकों के साथ समस्याएं। एक महत्वपूर्ण घटक एक घटक है जो विफलता की स्थिति में, पूरी सेवा के संचालन में एक समान विफलता का कारण बनता है।
अवलोकन संख्या 2: विश्वसनीयता का गणित
विश्वसनीयता डाउनटाइम की आवृत्ति और अवधि पर निर्भर करती है। इसके माध्यम से मापा जाता है:
- निष्क्रिय आवृत्ति, या इसका उलटा: MTTF (मतलब समय विफलता)।
- डाउनटाइम, एमटीटीआर (मरम्मत का समय)। डाउनटाइम उपयोगकर्ता के समय से निर्धारित होता है: खराबी की शुरुआत से सेवा के सामान्य संचालन की बहाली तक।
इस प्रकार, विश्वसनीयता को गणितीय रूप से उचित इकाइयों का उपयोग करके MTTF / (MTTF + MTTR) के रूप में परिभाषित किया गया है।
निष्कर्ष # 1: अतिरिक्त नौ का नियम
संयुक्त सभी महत्वपूर्ण घटकों की तुलना में एक सेवा अधिक विश्वसनीय नहीं हो सकती है। यदि आपकी सेवा 99.99% के स्तर पर उपलब्धता सुनिश्चित करने का प्रयास करती है, तो सभी महत्वपूर्ण घटकों को 99.99% से अधिक उपलब्ध होना चाहिए।
Google के अंदर, हम अंगूठे के निम्नलिखित नियम का उपयोग करते हैं: महत्वपूर्ण घटकों को आपकी सेवा की दावा की गई विश्वसनीयता की तुलना में अतिरिक्त नाइन प्रदान करना चाहिए - ऊपर दिए गए उदाहरण में, 99.999 प्रतिशत उपलब्धता - क्योंकि किसी भी सेवा में कई महत्वपूर्ण घटक होंगे, साथ ही साथ इसकी अपनी विशिष्ट समस्याएं भी होंगी। इसे "अतिरिक्त नाइन का नियम" कहा जाता है।
यदि आपके पास एक महत्वपूर्ण घटक है जो पर्याप्त नाइनस (एक अपेक्षाकृत सामान्य समस्या!) प्रदान नहीं करता है, तो आपको नकारात्मक परिणामों को कम करना चाहिए।
निष्कर्ष संख्या 2: आवृत्ति का गणित, समय का पता लगाना और वसूली का समय
एक सेवा घटनाओं की आवृत्ति और पता लगाने और पुनर्प्राप्ति के समय के उत्पाद से अधिक विश्वसनीय नहीं हो सकती है। उदाहरण के लिए, प्रत्येक वर्ष 20 मिनट के तीन कुल शट डाउन 60 मिनट की कुल अवधि तक ले जाते हैं। यहां तक कि अगर सेवा ने बाकी साल पूरी तरह से काम किया, तो 99.99 प्रतिशत विश्वसनीयता (प्रति वर्ष 53 मिनट से अधिक डाउनटाइम) असंभव नहीं होगी।
यह एक सरल गणितीय अवलोकन है, लेकिन इसे अक्सर अनदेखा किया जाता है।
निष्कर्ष नंबर 1 और नंबर 2 से निष्कर्ष
यदि आपकी सेवा पर निर्भरता के स्तर को प्राप्त नहीं किया जा सकता है, तो स्थिति को सुधारने के प्रयास किए जाने चाहिए - या तो सेवा की उपलब्धता को बढ़ाकर, या नकारात्मक परिणामों को कम करके, जैसा कि ऊपर वर्णित है। अपेक्षाओं को कम करना (यानी, घोषित विश्वसनीयता) भी एक विकल्प है, और अक्सर सबसे अधिक सच है: आप पर निर्भर सेवा के लिए यह स्पष्ट कर दें कि उसे आपकी सेवा की विश्वसनीयता में त्रुटि की भरपाई के लिए या तो अपने सिस्टम का पुनर्निर्माण करना चाहिए, या अपने स्वयं के सेवा स्तर के लक्ष्यों को कम करना चाहिए। । यदि आप स्वयं विसंगति को समाप्त नहीं करते हैं, तो सिस्टम की पर्याप्त रूप से लंबी विफलता अनिवार्य रूप से समायोजन की आवश्यकता होगी।
व्यावहारिक अनुप्रयोग
आइए 99.99% की लक्ष्य विश्वसनीयता के साथ एक सेवा का एक उदाहरण देखें और इसके दोनों घटकों की आवश्यकताओं को पूरा करें और अपनी विफलताओं के साथ काम करें।
आंकड़े
मान लें कि आपकी 99.99 प्रतिशत सेवा निम्नलिखित विशेषताओं के साथ उपलब्ध है:
- एक प्रमुख आउटेज और प्रति वर्ष तीन मामूली आउटेज। यह डरावना लगता है, लेकिन ध्यान दें कि एक 99.99% विश्वास स्तर प्रति वर्ष 20-30 मिनट बड़े पैमाने पर डाउनटाइम और कुछ छोटे आंशिक शटडाउन का मतलब है। (गणित इंगित करता है कि: ए) एक खंड की विफलता को एसएलओ के दृष्टिकोण से पूरी प्रणाली की विफलता नहीं माना जाता है, और बी) कुल विश्वसनीयता की गणना खंडों की विश्वसनीयता के योग से की जाती है।)
- 99.999% विश्वसनीयता के साथ अन्य स्वतंत्र सेवाओं के रूप में पांच महत्वपूर्ण घटक।
- पांच स्वतंत्र खंड जो एक के बाद एक असफल नहीं हो सकते।
- सभी परिवर्तन धीरे-धीरे किए जाते हैं, एक समय में एक खंड।
विश्वसनीयता की गणितीय गणना इस प्रकार होगी:
घटक आवश्यकताएँ
- वर्ष के लिए कुल त्रुटि सीमा प्रति वर्ष 525,600 मिनट का 0.01 प्रतिशत है, या 53 मिनट (सबसे खराब स्थिति में, 365 दिन के वर्ष के आधार पर)।
- महत्वपूर्ण घटकों को बंद करने के लिए आवंटित सीमा 0.001% प्रत्येक = 0.005% की सीमा के साथ पांच स्वतंत्र महत्वपूर्ण घटक हैं; प्रति वर्ष 525,600 मिनट का 0.005%, या 26 मिनट।
- आपकी सेवा की शेष त्रुटि सीमा 53-26 = 27 मिनट है।
शटडाउन रिस्पांस आवश्यकताओं
- अपेक्षित डाउनटाइम: 4 (1 पूर्ण शटडाउन और 3 शटडाउन केवल एक सेगमेंट को प्रभावित करते हैं)
- अपेक्षित परिणामों का संचयी प्रभाव: (1 × 100%) + (3 × 20%) = 1.6
- विफलता का पता लगाना और उसके बाद ठीक होना: 27 / 1.6 = 17 मिनट
- एक विफलता का पता लगाने और इसके बारे में सूचित करने के लिए निगरानी के लिए समय आवंटित: 2 मिनट
- ड्यूटी पर विशेषज्ञ को अलर्ट का विश्लेषण शुरू करने के लिए दिया गया समय: 5 मिनट। (निगरानी प्रणाली को SLO उल्लंघनों को ट्रैक करना चाहिए और हर बार सिस्टम विफल होने पर पेजर को एक संकेत भेजना चाहिए। कई Google सेवाएँ ड्यूटी पर शिफ्ट-शिफ्ट SR इंजीनियरों द्वारा समर्थित हैं जो तत्काल सवालों का जवाब देते हैं।)
- प्रतिकूल प्रभाव को कम करने के लिए शेष समय: 10 मिनट
निष्कर्ष: सेवा की विश्वसनीयता बढ़ाने के लिए लाभ
प्रस्तुत आंकड़ों को ध्यान से देखना सार्थक है, क्योंकि वे मूल बिंदु पर जोर देते हैं: सेवा की विश्वसनीयता बढ़ाने के लिए तीन मुख्य लीवर हैं।
- आउटेज की आवृत्ति कम करें - रिलीज नीतियों, परीक्षण, परियोजना संरचना के आवधिक मूल्यांकन आदि के माध्यम से।
- विभाजन, भौगोलिक अलगाव, क्रमिक गिरावट या ग्राहक अलगाव के साथ अपने औसत डाउनटाइम को कम करें।
- पुनर्प्राप्ति समय कम करना - निगरानी के साथ, एक-बटन बचाव अभियान (उदाहरण के लिए, पिछली स्थिति में वापस रोल करना या स्टैंडबाय पावर जोड़ना), परिचालन तत्परता अभ्यास, आदि।
आप दोष सहिष्णुता के कार्यान्वयन को सरल बनाने के लिए इन तीन तरीकों के बीच संतुलन बना सकते हैं। उदाहरण के लिए, अगर 17 मिनट की एमटीटीआर हासिल करना मुश्किल है, तो औसत डाउनटाइम कम करने पर ध्यान केंद्रित करें। प्रतिकूल प्रभावों को कम करने और महत्वपूर्ण घटकों के प्रभाव को कम करने के लिए रणनीतियों पर इस लेख में बाद में और अधिक विस्तार से चर्चा की गई है।
नेस्टेड घटकों के लिए स्पष्टीकरण "अतिरिक्त नीन्स के लिए नियम"
एक यादृच्छिक पाठक यह निष्कर्ष निकाल सकता है कि निर्भरता श्रृंखला में प्रत्येक अतिरिक्त लिंक के लिए अतिरिक्त नौ की आवश्यकता होती है, इसलिए द्वितीय-क्रम निर्भरता के लिए दो अतिरिक्त नौ की आवश्यकता होती है, तीसरे-क्रम निर्भरता के लिए तीन अतिरिक्त नौ की आवश्यकता होती है, आदि।
यह गलत निष्कर्ष है। यह प्रत्येक स्तर पर एक स्थिर शाखा के साथ एक पेड़ के रूप में घटकों के पदानुक्रम के एक भोले मॉडल पर आधारित है। ऐसे मॉडल में, जैसा कि अंजीर में दिखाया गया है। 1, 10 अद्वितीय प्रथम-क्रम घटक, 100 अद्वितीय द्वितीय-क्रम घटक, 1,000 अनन्य तृतीय-क्रम घटक, आदि हैं, जिसके परिणामस्वरूप कुल 1,111 अनन्य सेवाएँ हैं, भले ही आर्किटेक्चर चार परतों तक सीमित हो। इतने सारे स्वतंत्र महत्वपूर्ण घटकों के साथ अत्यधिक विश्वसनीय सेवाओं का एक पारिस्थितिकी तंत्र स्पष्ट रूप से अवास्तविक है।
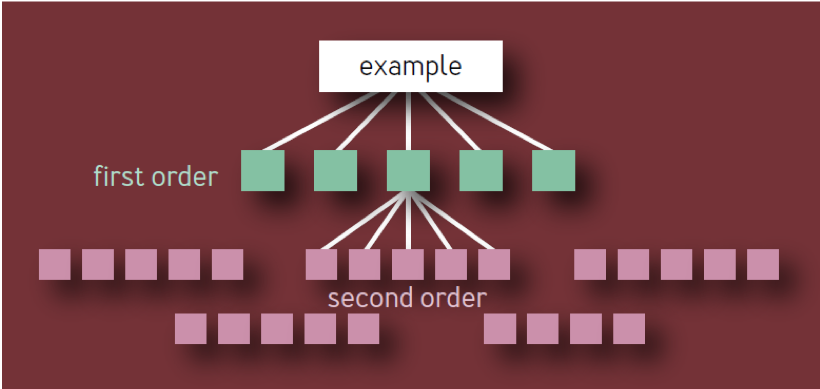
अंजीर। 1 - घटक पदानुक्रम: अमान्य मॉडल
अपने आप में एक महत्वपूर्ण घटक पूरी सेवा (या सेवा खंड) की विफलता का कारण बन सकता है, भले ही यह निर्भरता पेड़ में हो। इसलिए, यदि X के किसी दिए गए घटक को कई प्रथम-क्रम वाले घटकों की निर्भरता के रूप में प्रदर्शित किया जाता है, तो X को केवल एक बार गिना जाना चाहिए, क्योंकि इसकी विफलता अंततः एक सेवा विफलता का कारण बनेगी, चाहे कितनी भी इंटरमीडिएट सेवाएं प्रभावित हों।
नियम का एक सही पढ़ना इस प्रकार है:
- यदि किसी सेवा में एन अद्वितीय महत्वपूर्ण घटक हैं, तो उनमें से प्रत्येक इस घटक की वजह से पूरी सेवा की अविश्वसनीयता में 1 / N का योगदान देता है, चाहे वह घटकों के पदानुक्रम में कितना कम हो।
- प्रत्येक घटक को केवल एक बार गिना जाना चाहिए, भले ही वह घटक पदानुक्रम में कई बार दिखाई दे (दूसरे शब्दों में, केवल अद्वितीय घटक गिने जाते हैं)। उदाहरण के लिए, अंजीर में सेवा ए के घटकों की गणना करते समय। 2, सेवा बी को केवल एक बार माना जाना चाहिए।
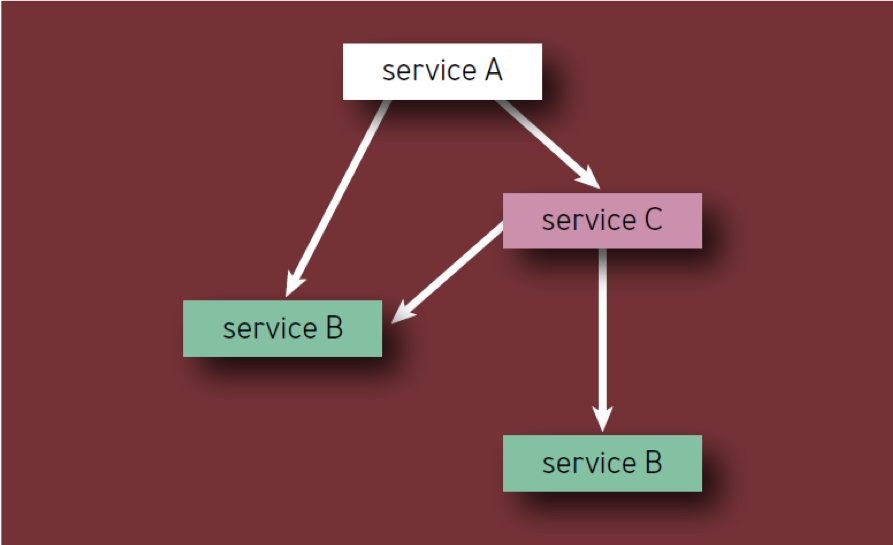
अंजीर। 2 - पदानुक्रम में घटक
उदाहरण के लिए, 0.01 प्रतिशत की त्रुटि सीमा के साथ एक काल्पनिक सेवा ए पर विचार करें। सेवा मालिक इस सीमा का आधा हिस्सा अपनी गलतियों और नुकसान के लिए, और आधा महत्वपूर्ण घटकों पर खर्च करने के लिए तैयार हैं। यदि सेवा में ऐसे घटक हैं, तो उनमें से प्रत्येक को शेष त्रुटि सीमा का 1 / एन प्राप्त होता है। विशिष्ट सेवाओं में अक्सर 5 से 10 महत्वपूर्ण घटक होते हैं, और इसलिए उनमें से प्रत्येक सेवा ए की त्रुटि सीमा के केवल दसवीं या एक बीसवीं डिग्री से इनकार कर सकता है, इसलिए, एक नियम के रूप में, सेवा के महत्वपूर्ण हिस्सों में एक अतिरिक्त नौ विश्वसनीयता होनी चाहिए।
त्रुटि सीमा
त्रुटि सीमा की अवधारणा को पुस्तक SRE में कुछ विस्तार से कवर किया गया है, लेकिन यहां इसका उल्लेख किया जाना चाहिए। Google SR इंजीनियर विश्वसनीयता और अपडेट की गति को संतुलित करने के लिए त्रुटि सीमा का उपयोग करते हैं। यह सीमा निश्चित अवधि (आमतौर पर एक महीने) के लिए सेवा के लिए विफलता का स्वीकार्य स्तर निर्धारित करती है। त्रुटि सीमा सेवा के एसएलओ से सिर्फ 1 माइनस है, इसलिए पहले से चर्चा की गई 99.99 प्रतिशत उपलब्ध सेवा में अविश्वसनीयता पर 0.01% "सीमा" है। जब तक सेवा ने एक महीने के भीतर अपनी त्रुटि सीमा का उपयोग नहीं किया, तब तक विकास टीम नए कार्यों, अपडेटों आदि को लॉन्च करने के लिए स्वतंत्र (कारण के भीतर) है।
यदि त्रुटि सीमा का उपयोग किया जाता है, तो सेवा में परिवर्तन को निलंबित कर दिया जाता है (तत्काल सुरक्षा सुधारों को छोड़कर और पहले स्थान पर उल्लंघन करने के उद्देश्य से परिवर्तन) जब तक कि सेवा त्रुटि सीमा में आरक्षित को वापस नहीं लेती है या महीने में परिवर्तन नहीं होता है। Google की कई सेवाएं SLO के लिए स्लाइडिंग विंडो विधि का उपयोग करती हैं ताकि त्रुटि सीमा धीरे-धीरे बहाल हो जाए। 99.99% से अधिक एसएलओ के साथ गंभीर सेवाओं के लिए, मासिक जीरो रीसेट के बजाय त्रैमासिक उपयोग करना उचित है, क्योंकि स्वीकार्य डाउनटाइम की संख्या छोटी है।
त्रुटि सीमाएं विभागों के बीच तनाव को खत्म करती हैं जो एसआर इंजीनियरों और उत्पाद डेवलपर्स के बीच उत्पन्न हो सकती हैं, उन्हें एक उत्पाद लॉन्च करने के लिए एक सामान्य, डेटा-आधारित जोखिम मूल्यांकन उपकरण प्रदान करता है। वे एसआर इंजीनियरों और विकास टीमों को उन तरीकों और तकनीकों को विकसित करने के लिए एक सामान्य लक्ष्य देते हैं जो उन्हें "ब्लोटिंग बजट" के बिना तेज़ी से लॉन्च करने और उत्पादों को लॉन्च करने में सक्षम बनाएंगे।
महत्वपूर्ण घटक न्यूनीकरण और शमन रणनीतियाँ
इस बिंदु पर, इस लेख में, हमने स्थापित किया है जिसे "घटक विश्वसनीयता के लिए स्वर्ण नियम" कहा जा सकता है। इसका मतलब है कि किसी भी महत्वपूर्ण घटक की विश्वसनीयता पूरे सिस्टम की विश्वसनीयता के लक्ष्य स्तर से 10 गुना अधिक होनी चाहिए ताकि सिस्टम की अविश्वसनीयता में इसका योगदान त्रुटि के स्तर पर बना रहे। यह निम्नानुसार है कि आदर्श मामले में, कार्य गैर-महत्वपूर्ण के रूप में कई घटकों को बनाने के लिए है। इसका मतलब यह है कि घटक विश्वसनीयता के निचले स्तर का पालन कर सकते हैं, जिससे डेवलपर्स को नवाचार करने और जोखिम लेने का अवसर मिलता है।
महत्वपूर्ण निर्भरता को कम करने के लिए सबसे सरल और सबसे स्पष्ट रणनीति जब भी संभव हो, तो विफलता के एकल बिंदुओं को समाप्त करना है। एक बड़ी प्रणाली किसी भी घटक के बिना स्वीकार्य रूप से संचालित करने में सक्षम होनी चाहिए जो महत्वपूर्ण निर्भरता या एसपीओएफ नहीं है।
वास्तव में, आप सबसे अधिक महत्वपूर्ण सभी निर्भरता से छुटकारा नहीं पा सकते हैं; लेकिन आप विश्वसनीयता को अनुकूलित करने के लिए कुछ सिस्टम डिज़ाइन दिशानिर्देशों का पालन कर सकते हैं। यद्यपि यह हमेशा संभव नहीं होता है, सिस्टम की उच्च विश्वसनीयता प्राप्त करने के लिए यह आसान और अधिक कुशल है यदि आप डिज़ाइन और नियोजन चरणों में विश्वसनीयता रखते हैं, और सिस्टम के काम करने के बाद नहीं और वास्तविक उपयोगकर्ताओं को प्रभावित करता है।
परियोजना संरचना मूल्यांकन
एक नई प्रणाली या सेवा की योजना बनाते समय, या किसी मौजूदा प्रणाली या सेवा को फिर से डिज़ाइन या सुधारने के दौरान, वास्तुकला या परियोजना की समीक्षा एक सामान्य बुनियादी ढांचे, साथ ही आंतरिक और बाहरी निर्भरताओं को प्रकट कर सकती है।
साझा इंफ्रास्ट्रक्चर
यदि आपकी सेवा एक साझा अवसंरचना का उपयोग करती है (उदाहरण के लिए, उपयोगकर्ताओं के लिए उपलब्ध कई उत्पादों द्वारा उपयोग की जाने वाली मुख्य डेटाबेस सेवा), तो विचार करें कि क्या इस बुनियादी ढांचे का सही उपयोग किया गया है। अतिरिक्त परियोजना प्रतिभागियों के रूप में साझा बुनियादी ढांचे के मालिकों की स्पष्ट रूप से पहचान करें। इसके अलावा, घटक अधिभार से सावधान रहें - ऐसा करने के लिए, इन घटकों के मालिकों के साथ स्टार्टअप प्रक्रिया का सावधानीपूर्वक समन्वय करें।
आंतरिक और बाहरी निर्भरता
कभी-कभी कोई उत्पाद या सेवा आपकी कंपनी के नियंत्रण से बाहर के कारकों पर निर्भर करती है - उदाहरण के लिए, सॉफ़्टवेयर लाइब्रेरी या सेवाओं और तृतीय पक्षों के डेटा से। इन कारकों की पहचान उनके उपयोग के अप्रत्याशित परिणामों को कम कर देगी।
योजना और डिजाइन सिस्टम सावधानी से
अपना सिस्टम डिज़ाइन करते समय, निम्नलिखित सिद्धांतों पर ध्यान दें:
अतिरेक और अलगाव
आप इसके कई स्वतंत्र उदाहरण बनाकर महत्वपूर्ण घटक के प्रभाव को कम करने का प्रयास कर सकते हैं। उदाहरण के लिए, यदि एक उदाहरण में डेटा संग्रहीत करना इस डेटा की 99.9 प्रतिशत उपलब्धता सुनिश्चित करता है, तो तीन व्यापक रूप से वितरित प्रतियों में तीन प्रतियां संग्रहीत करेगा, सिद्धांत रूप में, 1 की उपलब्धता स्तर - 0.013, या नौ नौ, यदि उदाहरण की विफलता शून्य सहसंबंध से स्वतंत्र है।
वास्तविक दुनिया में, सहसंबंध कभी भी शून्य नहीं होता है (रीढ़ की हड्डी के नेटवर्क की विफलताओं को देखें जो एक ही समय में कई कोशिकाओं को प्रभावित करते हैं), इसलिए वास्तविक विश्वसनीयता कभी नौ नाइन के करीब नहीं आएगी, लेकिन अब तक तीन नाइन से अधिक है।
इसी तरह, एक ही क्लस्टर में एक सर्वर पूल में आरपीसी (रिमोट प्रोसेस कॉल) भेजने से परिणाम की 99 प्रतिशत उपलब्धता हो सकती है, जबकि तीन अलग-अलग सर्वर पूल में एक साथ आरपीसी भेजने और पहली प्रतिक्रिया स्वीकार करने से उपलब्धता स्तर तक पहुंचने में मदद मिलेगी। तीन से अधिक नौ (ऊपर देखें)। यह रणनीति प्रतिक्रिया समय की देरी को भी कम कर सकती है यदि सर्वर पूल RPC प्रेषक से समतुल्य हैं। (चूंकि एक ही समय में तीन आरपीसी भेजने की लागत अधिक है, इसलिए Google अक्सर इन कॉल के लिए समय का रणनीतिक आवंटन करता है: हमारे अधिकांश सिस्टम तीसरे आरपीसी भेजने से पहले दूसरे आरपीसी और थोड़ा और समय भेजने से पहले आवंटित समय की उम्मीद करते हैं।)
रिजर्व और इसके आवेदन
सॉफ़्टवेयर के लॉन्च और पोर्टिंग को सेट करें ताकि सिस्टम काम करना जारी रखे जब अलग-अलग भाग विफल होते हैं (सुरक्षित सुरक्षित) और समस्या होने पर खुद को अलग कर लेते हैं। यहां मूल सिद्धांत यह है कि जब तक आप व्यक्ति को रिजर्व चालू करने के लिए कनेक्ट करते हैं, तब तक आप अपनी त्रुटि सीमा को पार कर सकते हैं।
asynchrony
घटकों को महत्वपूर्ण बनने से रोकने के लिए, जहाँ भी संभव हो, उन्हें अतुल्यकालिक रूप से डिज़ाइन करें। यदि कोई सेवा अपने गैर-महत्वपूर्ण भागों में से एक RPC प्रतिक्रिया की उम्मीद करती है, जो प्रतिक्रिया समय में तेज मंदी दिखाती है, तो यह मंदी मूल सेवा के प्रदर्शन को अनावश्यक रूप से खराब कर देगी। गैर-महत्वपूर्ण घटक के लिए आरपीसी को एसिंक्रोनस मोड में सेट करने से मूल घटक की प्रतिक्रिया समय इस घटक के प्रदर्शन के लिए बाध्य होने से मुक्त हो जाएगी। और यद्यपि अतुल्यकालिक कोड और सेवा के बुनियादी ढांचे को जटिल कर सकता है, फिर भी यह समझौता इसके लायक है।
संसाधन नियोजन
सुनिश्चित करें कि सभी घटकों को आपकी ज़रूरत की हर चीज़ प्रदान की जाती है। , — .
, \ .
, . . . , .
SLO. , , . , , , MTTR .
, . :
, , , . :
, : , , . — , . , , , .
, . , Google , 10 .
निष्कर्ष
, , , , . , . Google , , (. SRE, B: ).