टीएल; डीआर: गिटहब: // पादरी / एएनएलसेलेटेक्स ।
एक बार, ठंड के मौसम में नहीं, लेकिन पहले से ही सर्दियों के मौसम में, और विशेष रूप से कुछ महीने पहले, एक परियोजना के लिए मैं (बिग डेटा पर आधारित कुछ भू-स्थानिक) काम कर रहा था, मुझे एक तेज़ NoSQL / की-वैल्यू स्टोरेज की आवश्यकता थी।
हम अपाचे स्पार्क का उपयोग करके स्रोत कोड की टेराबाइट्स चबाते हैं, लेकिन गणना का अंतिम परिणाम, एक हास्यास्पद राशि तक गिर गया (सिर्फ लाखों रिकॉर्ड), कहीं संग्रहीत करने की आवश्यकता है। और इस तरह से संग्रहित करना बहुत ही वांछनीय है कि यह परिणाम की प्रत्येक पंक्ति से जुड़े मेटाडेटा का उपयोग करके जल्दी से पाया और बाहर भेजा जा सके (यह एक अंक है) (लेकिन उनमें से बहुत सारे हैं)।
इस अर्थ में खड़ूपोव स्टैक के प्रारूप बहुत कम उपयोग के हैं, और लाखों रिकॉर्ड पर रिलेशनल डेटाबेस धीमा हो जाता है, और मेटाडेटा का सेट इतना तय नहीं है कि हमारे मामले में एक नियमित RDBMS - PostrereSQL की कठोर योजना में अच्छी तरह से फिट हो। नहीं, यह सामान्य रूप से JSON का समर्थन करता है, लेकिन अभी भी लाखों रिकॉर्ड पर अनुक्रमित के साथ समस्या है। सूचकांक सूज जाते हैं, तालिका को विभाजित करना आवश्यक हो जाता है, और प्रशासन के साथ इस तरह की परेशानी शुरू होती है कि नफिग-नेफिग।
ऐतिहासिक रूप से, MongoDB का उपयोग प्रोजेक्ट पर NoSQL के रूप में किया गया था, लेकिन समय के साथ, मोंगा खुद को और भी बदतर (विशेष रूप से स्थिरता के संदर्भ में) दिखाता है, इसलिए इसे धीरे-धीरे decommissioned किया गया। अधिक आधुनिक, तेज, कम छोटी गाड़ी, और आमतौर पर बेहतर विकल्प के लिए एक त्वरित खोज एयरोस्पाइक की ओर ले जाती है । कई बड़े सिर वाले लोगों के पक्ष में है, और मैंने जांच करने का फैसला किया है।
परीक्षणों से पता चला कि वास्तव में, डेटा को स्पार्क नौकरी से सीधे एक सीटी के साथ कहानी में संग्रहीत किया जाता है, और कई लाखों रिकॉर्ड में खोज मूंग की तुलना में बहुत तेज है। और वह कम मेमोरी खाती है। लेकिन यह एक "लेकिन" निकला। एयरो सोल्डर का क्लाइंट एपीआई विशुद्ध रूप से कार्यात्मक है, और घोषणात्मक नहीं है।
कहानी में रिकॉर्डिंग के लिए, यह महत्वपूर्ण नहीं है, क्योंकि सभी समान, प्रत्येक परिणामी रिकॉर्ड के सभी प्रकार के क्षेत्रों को स्थानीय स्तर पर नौकरी में ही निर्धारित किया जाना है - और संदर्भ खो नहीं है। कार्यात्मक शैली यहां जगह में है, खासकर जब से एक अलग तरीके से एक कोड लिखने से काम नहीं चलेगा। लेकिन वेब थूथन में, जो बाहरी दुनिया के लिए परिणाम अपलोड करना चाहिए, और एक साधारण स्प्रिंग वेब एप्लिकेशन है, एक उपयोगकर्ता के रूप में एक मानक SQL चयन बनाने के लिए यह अधिक तार्किक होगा, जिसमें यह AND और OR से भरा होगा - अर्थात, भविष्यवाणी करता है , - WHERE क्लॉज में।
मैं इस तरह के सिंथेटिक उदाहरण के साथ अंतर की व्याख्या करूंगा:
SELECT foo, bar, baz, qux, quux FROM namespace.set WITH (baz!='a') WHERE (foo>2 AND (bar<=3 OR foo>5) AND quux LIKE '%force%') OR NOT (qux WITHIN CAST('{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}' AS GEOJSON)
- यह पठनीय और अपेक्षाकृत स्पष्ट दोनों है जो ग्राहक को प्राप्त करने के लिए रिकॉर्ड करता है। यदि आप इस तरह के अनुरोध को सीधे लॉग में फेंकते हैं, तो आप इसे बाद में मैन्युअल रूप से डिबगिंग के लिए खींच सकते हैं। जो सभी प्रकार की अजीब स्थितियों को पार्स करते समय बहुत सुविधाजनक है।
अब एक कार्यात्मक शैली में एपीआई के लिए कॉल को देखें:
Statement reference = new Statement(); reference.setSetName("set"); reference.setNamespace("namespace"); reference.setBinNames("foo", "bar", "baz", "qux", "quux"); reference.setFillter(Filter.stringNotEqual("baz", "a")); reference.setPredExp(
यहां कोड की दीवार है, और यहां तक कि रिवर्स पोलिश नोटेशन में भी । नहीं, मैं समझता हूं कि इंजन के प्रोग्रामर के दृष्टिकोण से स्टैक मशीन कार्यान्वयन के लिए सरल और सुविधाजनक है, लेकिन क्लाइंट एप्लिकेशन से आरपीएन में भविष्यवाणी करना और लिखना ... मैं व्यक्तिगत रूप से विक्रेता के बारे में नहीं सोचना चाहता, मैं इस एपीआई के उपभोक्ता के रूप में हूं। यह सुविधाजनक था। और एक वेंडर क्लाइंट एक्सटेंशन के साथ भी भविष्यवाणी करता है (वैचारिक रूप से जावा पर्सिस्टेंस क्राइटेरिया एपीआई के समान) लिखने के लिए असुविधाजनक है। और फिर भी क्वेरी लॉग में कोई पठनीय चयन नहीं है।
सामान्य तौर पर, एसक्यूएल का आविष्कार प्राकृतिक के करीब पक्षी भाषा में मापदंड-आधारित प्रश्नों को लिखने के लिए किया गया था। तो, एक चमत्कार, क्या नरक?
रुको, कुछ सही नहीं है ... केडीपीवी पर, एरोसोलिंग के आधिकारिक दस्तावेज से एक स्क्रीनशॉट है, जिस पर SELECT पूरी तरह से वर्णित है?
हाँ, वर्णित। यह सिर्फ AQL है - यह एक तीसरी पार्टी की उपयोगिता है जो एक अंधेरी रात में पीछे के बाएं पैर से लिखी जाती है, और विक्रेता द्वारा एयरोसॉल्डिंग के पिछले संस्करण के दौरान तीन साल पहले छोड़ दी गई है। इसका क्लाइंट लाइब्रेरी से कोई लेना-देना नहीं है, हालांकि यह एक टॉड पर लिखा गया है - जिसमें शामिल है
तीन साल पहले के संस्करण में एक विधेय एपीआई नहीं था, और इसलिए AQL में विधेयकों के लिए कोई समर्थन नहीं है, और यह कि WHERE के बाद वास्तव में सूचकांक (द्वितीयक या प्राथमिक) के लिए एक कॉल है। खैर, यह है कि USE या के साथ SQL एक्सटेंशन के करीब है। यही है, आप केवल AQL स्रोतों को नहीं ले सकते, उन्हें स्पेयर पार्ट्स में अलग कर सकते हैं, और उन्हें अपने एप्लिकेशन में विधेय कॉल के लिए उपयोग कर सकते हैं।
इसके अलावा, जैसा कि मैंने कहा, यह अंधेरी रात में पीछे के बाएं पैर के साथ लिखा गया था, और ANTLR4 व्याकरण को देखना असंभव है, जिसे AQL आँसू के बिना क्वेरी के लिए पार्स करता है। खैर, मेरे स्वाद के लिए। किसी कारण के लिए, मुझे यह पसंद है जब व्याकरण की घोषित परिभाषा को ताड कोड के टुकड़ों के साथ नहीं मिलाया जाता है, और बहुत शांत नूडल्स को वहां पीसा जाता है।
खैर, सौभाग्य से, मुझे यह भी पता है कि एएनटीएलआर कैसे करें। सच है, लंबे समय तक मैंने एक चेकर नहीं उठाया था, और आखिरी बार मैंने इसे तीसरे संस्करण के तहत लिखा था। चौथा - यह बहुत अच्छा है, क्योंकि जो एक मैनुअल एएसटी दौरे लिखना चाहता है, अगर सब कुछ हमारे सामने लिखा गया था, और एक सामान्य आगंतुक है, तो चलो शुरू करें।
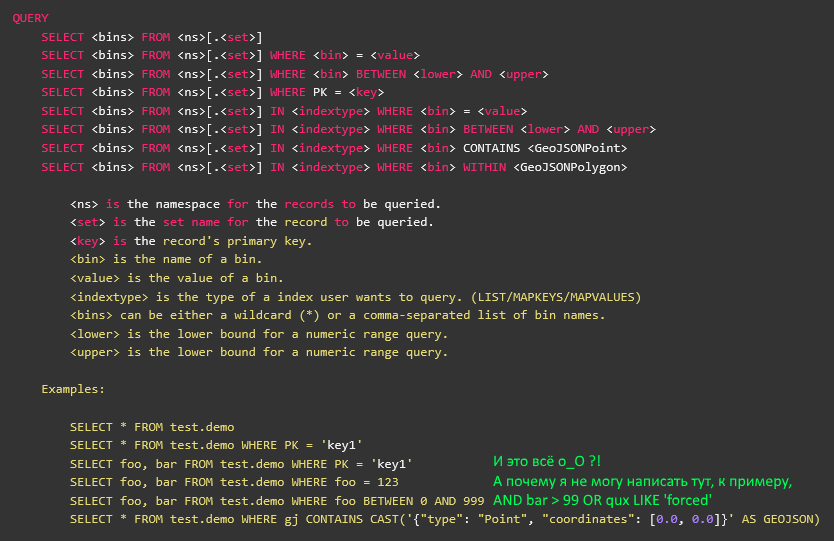
हम SQLite सिंटैक्स को एक आधार के रूप में लेते हैं, और जो कुछ भी अनावश्यक है उसे बाहर फेंकने की कोशिश करते हैं। हमें केवल चयन की आवश्यकता है, और अधिक कुछ नहीं।
grammar SQLite; simple_select_stmt : ( K_WITH K_RECURSIVE? common_table_expression ( ',' common_table_expression )* )? select_core ( K_ORDER K_BY ordering_term ( ',' ordering_term )* )? ( K_LIMIT expr ( ( K_OFFSET | ',' ) expr )? )? ; select_core : K_SELECT ( K_DISTINCT | K_ALL )? result_column ( ',' result_column )* ( K_FROM ( table_or_subquery ( ',' table_or_subquery )* | join_clause ) )? ( K_WHERE expr )? ( K_GROUP K_BY expr ( ',' expr )* ( K_HAVING expr )? )? | K_VALUES '(' expr ( ',' expr )* ')' ( ',' '(' expr ( ',' expr )* ')' )* ; expr : literal_value | BIND_PARAMETER | ( ( database_name '.' )? table_name '.' )? column_name | unary_operator expr | expr '||' expr | expr ( '*' | '/' | '%' ) expr | expr ( '+' | '-' ) expr | expr ( '<<' | '>>' | '&' | '|' ) expr | expr ( '<' | '<=' | '>' | '>=' ) expr | expr ( '=' | '==' | '!=' | '<>' | K_IS | K_IS K_NOT | K_IN | K_LIKE | K_GLOB | K_MATCH | K_REGEXP ) expr | expr K_AND expr | expr K_OR expr | function_name '(' ( K_DISTINCT? expr ( ',' expr )* | '*' )? ')' | '(' expr ')' | K_CAST '(' expr K_AS type_name ')' | expr K_COLLATE collation_name | expr K_NOT? ( K_LIKE | K_GLOB | K_REGEXP | K_MATCH ) expr ( K_ESCAPE expr )? | expr ( K_ISNULL | K_NOTNULL | K_NOT K_NULL ) | expr K_IS K_NOT? expr | expr K_NOT? K_BETWEEN expr K_AND expr | expr K_NOT? K_IN ( '(' ( select_stmt | expr ( ',' expr )* )? ')' | ( database_name '.' )? table_name ) | ( ( K_NOT )? K_EXISTS )? '(' select_stmt ')' | K_CASE expr? ( K_WHEN expr K_THEN expr )+ ( K_ELSE expr )? K_END | raise_function ;
हम्म ... सिलेक्ट के लिए बहुत ज्यादा। और यदि अतिरिक्त से छुटकारा पाना काफी आसान है, तो परिणामी वर्कअराउंड की बहुत संरचना के बारे में एक और बुरी बात है।
अंतिम लक्ष्य अपने RPN और निहित स्टैक मशीन के साथ विधेय एपीआई में अनुवाद करना है। और यहां परमाणु विस्तार किसी भी तरह से इस तरह के परिवर्तन में योगदान नहीं देता है, क्योंकि यह सामान्य विश्लेषण को बाएं से दाएं की ओर ले जाता है। हाँ, और पुनरावर्ती रूप से परिभाषित किया गया है।
यही है, हम अपने सिंथेटिक उदाहरण प्राप्त कर सकते हैं, लेकिन यह ठीक उसी तरह पढ़ा जाएगा जैसा लिखा है, बाएं से दाएं:
(foo>2 (bar<=3 foo>5) quux _ '%force%') (qux _('{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}')
ऐसे ब्रैकेट हैं जो पार्सिंग की प्राथमिकता निर्धारित करते हैं (जिसका अर्थ है कि आपको स्टैक पर आगे और पीछे लटकना होगा), और कुछ ऑपरेटर भी फ़ंक्शन कॉल की तरह व्यवहार करते हैं।
और हमें इस क्रम की आवश्यकता है:
foo 2 > bar 3 <= foo 5 > quux ".*force.*" _ qux "{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}" _
Brr, टिन, गरीब मस्तिष्क पढ़ने के लिए। लेकिन कोष्ठक के बिना, कॉल के आदेश के साथ कोई रोलबैक और गलतफहमी नहीं है। और हम एक का दूसरे में अनुवाद कैसे करते हैं?
और फिर एक गरीब दिमाग में, एक चोक होता है! - नमस्कार, यह कई से एक क्लासिक Shunting यार्ड है। प्रोफेसर। डिज्कस्ट्रा! आमतौर पर, मेरे जैसे okolobigdatovskih shamans को एल्गोरिदम की आवश्यकता नहीं है, क्योंकि हम केवल डेटा-सैटनिस्ट द्वारा पहले से ही लिखे गए प्रोटोटाइप को अजगर से टॉड में स्थानांतरित करते हैं, और फिर शुद्ध इंजीनियरिंग (== shamanistic) विधियों द्वारा प्राप्त समाधान के लंबे और थकाऊ प्रदर्शन के लिए, और वैज्ञानिक नहीं ।
लेकिन फिर अचानक एल्गोरिथ्म को जानना आवश्यक हो गया। या कम से कम इसका एक विचार है। सौभाग्य से, पिछले वर्षों में सभी विश्वविद्यालय पाठ्यक्रमों को नहीं भुलाया गया है, और चूंकि मुझे स्टैक्ड मशीनों के बारे में याद है, इसलिए मैं संबंधित एल्गोरिदम के बारे में कुछ और भी पता लगा सकता हूं।
ठीक है। शंटिंग यार्ड द्वारा धारित एक व्याकरण में, शीर्ष स्तर पर एक चयन इस तरह होगा:
select_stmt : K_SELECT ( STAR | column_name ( COMMA column_name )* ) ( K_FROM from_set )? ( (K_USE | K_WITH) index_expr )? ( K_WHERE where_expr )? ; where_expr : ( atomic_expr | OPEN_PAR | CLOSE_PAR | logic_op )+ ; logic_op : K_NOT | K_AND | K_OR ; atomic_expr : column_name ( equality_op | regex_op ) STRING_LITERAL | ( column_name | meta_name ) ( equality_op | comparison_op ) NUMERIC_LITERAL | column_name map_op iter_expr | column_name list_op iter_expr | column_name geo_op cast_expr ;
यही है, कोष्ठक के अनुरूप टोकन महत्वपूर्ण हैं, और एक पुनरावर्ती विस्तार नहीं होना चाहिए। इसके बजाय, सभी Private_expr का एक गुच्छा होगा, और सभी परिमित हैं।
कोड में टॉड पर, जो इस पेड़ के लिए आगंतुक को लागू करता है, चीजें थोड़ी अधिक नशे की लत हैं - एल्गोरिथम के साथ सख्त अनुसार, जो खुद ही लटकने वाले तर्क की प्रक्रिया करता है और कोष्ठक को संतुलित करता है। मैं कोई अंश नहीं दूंगा ( जीसी को स्वयं देखें), लेकिन मैं निम्नलिखित विचार दूंगा।
यह स्पष्ट हो जाता है कि एयरो स्पाइक के लेखक AQL में विधेय समर्थन से परेशान नहीं हुए, और तीन साल पहले इसे छोड़ दिया। क्योंकि यह कड़ाई से टाइप किया जाता है, और एयरो स्पाइक को स्कीमा-कम कहानी के रूप में प्रस्तुत किया जाता है। और इसलिए पूर्व निर्धारित योजना के बिना नंगे एसक्यूएल से एक क्वेरी लेना और लेना असंभव है। उफ़।
लेकिन हम लोग झुलसे हुए हैं, और, सबसे महत्वपूर्ण, घमंडी। हमें फ़ील्ड प्रकारों के साथ एक योजना की आवश्यकता है, इसलिए फ़ील्ड प्रकारों के साथ एक योजना होगी। इसके अलावा, क्लाइंट लाइब्रेरी में पहले से ही सभी आवश्यक परिभाषाएं हैं, उन्हें बस उठाया जाना चाहिए। हालाँकि मुझे प्रत्येक प्रकार के लिए बहुत सारे कोड लिखने थे (एक ही लिंक देखें, पंक्ति 56 से)।
अब आरंभ करें ...
final HashMap FOO_BAR_BAZ = new HashMap() {{ put("namespace.set0", new HashMap() {{ put("foo", ParticleType.INTEGER); put("bar", ParticleType.DOUBLE); put("baz", ParticleType.STRING); put("qux", ParticleType.GEOJSON); put("quux", ParticleType.STRING); put("quuux", ParticleType.LIST); put("corge", ParticleType.MAP); put("corge.uier", ParticleType.INTEGER); }}); put("namespace.set1", new HashMap() {{ put("grault", ParticleType.INTEGER); put("garply", ParticleType.STRING); }}); }}; AQLSelectEx selectEx = AQLSelectEx.forSchema(FOO_BAR_BAZ);
... और वॉयला, अब हमारे सिंथेटिक क्वेरी बस और स्पष्ट रूप से एरोसफ़ोल्डरिंग से झटके:
Statement statement = selectEx.fromString("SELECT foo,bar,baz,qux,quux FROM namespace.set WITH (baz='a') WHERE (foo>2 AND (bar <=3 OR foo>5) AND quux LIKE '%force%') OR NOT (qux WITHIN CAST('{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}' AS GEOJSON)");
और वेब थूथन से फॉर्म को स्वयं अनुरोध में परिवर्तित करने के लिए, हम वेब थूथन में बहुत पहले लिखे गए एक टन कोड को पकड़ लेते हैं ... जब यह अंत में प्रोजेक्ट को मिलता है, अन्यथा ग्राहक ने इसे अभी के लिए शेल्फ पर रख दिया है। यह शर्म की बात है, लानत है, मैंने लगभग एक सप्ताह का समय बिताया है।
मुझे आशा है कि मैंने इसे लाभ के साथ खर्च किया है, और AQLSelectEx पुस्तकालय किसी के लिए उपयोगी होगा, और दृष्टिकोण स्वयं ही थोड़ा और अधिक यथार्थवादी प्रशिक्षण सहायता होगा जो कि हेब्र से अन्य लेख ANTLR को समर्पित है।