
शुभ दिन।
वास्तविक अभ्यास में, आप अक्सर ऐसे कार्यों का सामना करते हैं जो जटिल एमएल एल्गोरिदम से दूर हैं, लेकिन साथ ही साथ व्यवसाय के लिए कम महत्वपूर्ण और जरूरी नहीं है।
आइए उनमें से एक के बारे में बात करते हैं।
टास्क डिस्ट्रीब्यूटिंग (सीलिंग, रैसप्लिटोवैट - बिजनेस का शब्दजाल अटूट है) के साथ कुछ और विस्तृत ग्रैन्युलैरिटी की मेज पर एग्रीगेट (एग्रीगेट वैल्यूज) के साथ कुछ टारगेट टेबल का डेटा होता है।
उदाहरण के लिए, वाणिज्यिक विभाग को ब्रांड स्तर पर सहमत वार्षिक योजना को तोड़ने की जरूरत है - उत्पादों के बारे में विस्तार से, विपणक के लिए देश द्वारा वार्षिक विपणन बजट को तोड़ने के लिए, वित्तीय जिम्मेदारी केंद्रों द्वारा सामान्य व्यवसाय व्यय को तोड़ने के लिए योजना और आर्थिक विभाग। आदि
यदि आपको लगता है कि इस तरह के कार्य पहले से ही क्षितिज पर आपके सामने उभर रहे हैं या पहले से ही उन कार्यों का इलाज कर रहे हैं जो इस तरह के कार्यों से पीड़ित हैं, तो मैं एक बिल्ली के लिए पूछता हूं।
एक वास्तविक उदाहरण पर विचार करें:
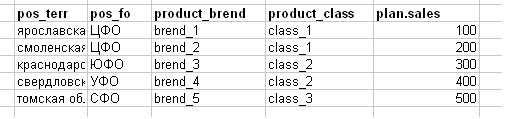
वे बिक्री योजना को एक कार्य के रूप में नीचे चित्र के रूप में कम करते हैं (मैंने जानबूझकर उदाहरण को सरलीकृत किया, वास्तविकता में - एक 100-200 एमबी एक्सेल बैनर)।
शीर्षक स्पष्टीकरण:
- आउटलेट का pos_terr- क्षेत्र (क्षेत्र)
- pos_fo - आउटलेट का संघीय जिला (उदाहरण के लिए, केंद्रीय संघीय जिला-केंद्रीय संघीय जिला)
- product_brend - उत्पाद ब्रांड
- product_class - उत्पाद वर्ग
- plan.sales किसी भी चीज़ की बिक्री योजना है।
और वे पूछते हैं, उदाहरण के लिए, उनकी मेगा-टेबल को तोड़ने के लिए (हमारे बच्चों के उदाहरण के ढांचे में, यह निश्चित रूप से अधिक विनम्र है) - बिक्री चैनल के लिए। इस सवाल के अनुसार - किस तर्क को तोड़ना है, मुझे जवाब मिलता है: "लेकिन इस तरह की 4 वीं तिमाही के लिए वास्तविक बिक्री के आंकड़ों को लें और योजना के प्रत्येक पंक्ति के लिए% में चैनलों के वास्तविक शेयरों को प्राप्त करें और योजना की रेखा के इन हिस्सों से विभाजित करें"।
वास्तव में, इस तरह के कार्यों में यह सबसे लगातार उत्तर है ...
अब तक, सब कुछ काफी सरल लगता है।
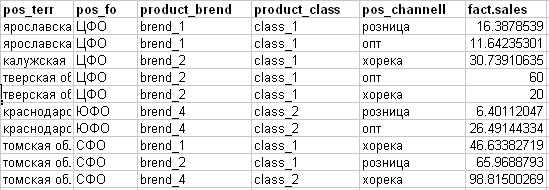
मुझे यह तथ्य मिलता है (नीचे दी गई तस्वीर देखें):
- pos_channell - बिक्री चैनल (योजना के लिए लक्ष्य विशेषता)
- fact.sales - किसी चीज़ की वास्तविक बिक्री।
योजना की पहली पंक्ति के उदाहरण पर "देखा" के लिए प्राप्त दृष्टिकोण के आधार पर, हम इस तथ्य के आधार पर इसे नीचे तोड़ देंगे:

हालांकि, अगर हम इस तथ्य की तुलना पूरी प्लेट के लिए योजना के साथ करते हैं कि क्या यह समझने के लिए कि क्या योजना की सभी पंक्तियों को शेयरों में पर्याप्त रूप से "काटा" जा सकता है, तो हमें निम्नलिखित चित्र मिलते हैं: (हरे रंग की - योजना रेखा के सभी गुण इस तथ्य से मेल खाते हैं, पीली कोशिकाएं मेल नहीं खाती थीं)।
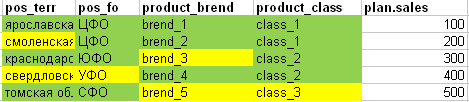
- योजना की पहली पंक्ति में, सभी क्षेत्र पूरी तरह से तथ्य में पाए जाते हैं।
- योजना की दूसरी पंक्ति में, संबंधित क्षेत्र वास्तव में नहीं मिला था
- योजना की तीसरी पंक्ति ब्रांड के तथ्य में पर्याप्त नहीं है
- योजना की चौथी पंक्ति क्षेत्र और संघीय जिले के तथ्य में पर्याप्त नहीं है
- योजना की 5 वीं पंक्ति में वास्तव में ब्रांड और वर्ग का अभाव है।
जैसा कि पैनिकोवस्की ने कहा: "शूरा को देखा, देखा - वे सोने के हैं ..."

मैं व्यवसाय ग्राहक के पास जाता हूं और दूसरी पंक्ति के उदाहरण पर स्पष्ट करता हूं कि वह ऐसी स्थितियों के लिए किस तरह का दृष्टिकोण देखता है?
मुझे उत्तर मिलता है: "ऐसे मामलों के लिए जब स्मोलेंस्क क्षेत्र में ब्रांड नंबर 2 के लिए चैनलों की हिस्सेदारी की गणना करना संभव नहीं है (इस तथ्य को ध्यान में रखते हुए कि हमारे पास केंद्रीय संघीय जिला-केंद्रीय संघीय जिले में स्मोलेंस्क क्षेत्र है) - पूरे केंद्रीय संघीय जिले के भीतर चैनल संरचना के अनुसार इस लाइन को तोड़ दें!"
यह है कि, {स्मोलेंस्क क्षेत्र + brand_2} के लिए हम केंद्रीय संघीय जिले के स्तर पर तथ्य को एकत्र करते हैं और स्मोलेंस्क क्षेत्र को कुछ इस तरह से तोड़ते हैं:

वापस जा रहे हैं और जो मैंने सुना है उसे पचाने के लिए, मैं एक अधिक सार्वभौमिक अनुमान के लिए सामान्यीकरण करने की कोशिश करता हूं:
यदि तथ्य तालिका के विस्तार के वर्तमान स्तर पर कोई डेटा नहीं है, तो लक्ष्य फ़ील्ड (बिक्री चैनल) के लिए शेयरों की गणना करने से पहले, हम ऊपर दिए गए पदानुक्रम विशेषता तक तथ्य तालिका को एकत्र करते हैं।
यही है, यदि क्षेत्र के लिए नहीं है, तो हम इस तथ्य को एक उच्च स्तरीय स्तर तक एकत्रित करते हैं - योजना में उसी केंद्रीय संघीय जिले के लिए शेयर। यदि ब्रांड के लिए नहीं है, तो ऊपर पदानुक्रम में एक उत्पाद वर्ग है - तदनुसार हम उसी वर्ग और इसी तरह के शेयरों को फिर से साझा करते हैं।
यानी हम युग्मन फ़ील्ड पर योजना और तथ्य को जोड़ते हैं, जिसके लिए हम वास्तव में शेयरों पर विचार करते हैं और शेष अप्रतिबंधित योजना के अनुसार प्रत्येक पुनरावृत्ति में, हम क्रमिक रूप से युग्मन फ़ील्ड की संरचना को कम करते हैं।
एक निश्चित डेटा वितरण पैटर्न यहाँ पहले से ही है:
- हम योजना को वास्तव में संबंधित क्षेत्रों के पूर्ण संयोग के आधार पर वितरित करते हैं
- हमें एक टूटी हुई योजना मिलती है (हम इसे मध्यवर्ती परिणाम में जमा करते हैं) और एक अटूट योजना (सभी लाइनों से मेल नहीं खाती)
- हम एक अटूट योजना लेते हैं और इसे वास्तव में उच्च श्रेणी के स्तर तक विभाजित करते हैं (यानी, हम इन 2 तालिकाओं के युग्मन के एक निश्चित क्षेत्र को छोड़ देते हैं और शेयरों की गणना के लिए इस क्षेत्र के बिना तथ्य को एकत्रित करते हैं)
- हमें एक टूटी हुई योजना मिलती है (हम इसे मध्यवर्ती परिणाम में जोड़ते हैं) और एक अटूट योजना (सभी लाइनों से मेल नहीं खाती)
- और हम उन्हीं चरणों को दोहराते हैं जब तक कि कोई "अनसुलझी" योजना न हो।
सामान्य तौर पर, कोई भी हमें केवल पदानुक्रम के भीतर अड़चन क्षेत्रों को हटाने के लिए बाध्य नहीं करता है। उदाहरण के लिए, हमने पहले ही अड़चन वाले क्षेत्रों से ब्रांड और क्षेत्र को हटा दिया है और शेष योजना को वितरित किया है: product_class (ब्रांड के ऊपर पदानुक्रम) + Fed.krug (क्षेत्र के ऊपर पदानुक्रम)। और फिर भी योजना का कुछ असंतुलित संतुलन बना रहा।
इसके अलावा, हम युग्मन क्षेत्रों से या तो उत्पाद वर्ग या संघीय जिले से हटा सकते हैं, जैसा कि वे अब एक दूसरे के पदानुक्रम में एम्बेडेड नहीं हैं।
यह देखते हुए कि इस तरह की तालिकाओं में दर्जनों और खेतों की पंक्तियाँ हैं - अपने हाथों से इस तरह के हेरफेर करने वाले एक मिलियन तक - कार्य सबसे सुखद नहीं है।
और इस तरह के कार्य दिए गए प्रत्येक वर्ष के अंत में नियमित रूप से मेरे पास आते हैं (निदेशक मंडल पर अगले वर्ष के लिए बजट को मंजूरी देते हुए), आपको इस प्रक्रिया को किसी प्रकार के लचीले सार्वभौमिक टेम्पलेट में बदलना था।
और चूंकि अधिकांश समय मैं आर के माध्यम से डेटा के साथ काम करता हूं - कार्यान्वयन तदनुसार उस पर समान है।
शुरुआत करने के लिए, हमें एक सार्वभौमिक मैजिक फंक्शन लिखना होगा, जिसमें एक ब्रेकडाउन (हमारे उदाहरण में, एक प्लान) के लिए बेस टेबल (बेसटैब) और शेयर (शेयरटैब) की गणना के लिए एक टेबल होगी, जिसके आधार पर हम डेटा (हमारे उदाहरण में) देखेंगे। एक तथ्य यह है)। लेकिन फ़ंक्शन को यह भी समझना चाहिए कि इन वस्तुओं के साथ क्या करने की आवश्यकता है, इसलिए फ़ंक्शन युग्मन फ़ील्ड्स (मर्ज.वियर्स) के नामों के वेक्टर को भी स्वीकार करेगा - i.e. वे फ़ील्ड जिन्हें दोनों तालिकाओं में समान रूप से नाम दिया गया है और हमें इन क्षेत्रों के साथ एक तालिका को दूसरे से कनेक्ट करने की अनुमति देगा जहां यह काम करता है (यानी राइट जॉइन)। साथ ही, फ़ंक्शन को यह समझना चाहिए कि बेस टेबल के किस कॉलम को वितरण (basetab.value) में लिया जाना चाहिए और शेयर (sharetab.value) को गिनने के लिए किस फ़ील्ड पर आधारित होना चाहिए। खैर, और सबसे महत्वपूर्ण बात - परिणामी फ़ील्ड (शेयरटैबटार्ग्वार्स) के लिए क्या लेना है, हमारे मामले में, हम इस तथ्य से बिक्री चैनल के माध्यम से योजना का विस्तार करना चाहते हैं।
वैसे, यह वैरिएबल शेयरटैब। टारगेटवार मेरी बहुवचन में यादृच्छिक नहीं है - यह एक क्षेत्र नहीं बल्कि फ़ील्ड नामों का एक वेक्टर हो सकता है, ऐसे मामलों के लिए जब आपको साझा तालिका से आधार तालिका में एक फ़ील्ड नहीं जोड़ने की आवश्यकता होती है, लेकिन कई बार एक बार (उदाहरण के लिए, तथ्य के आधार पर, आप योजना को विभाजित नहीं कर सकते हैं। केवल बिक्री चैनल के माध्यम से, बल्कि ब्रांड में शामिल उत्पादों के नाम से भी)।
हां, और एक और शर्त :) मेरा कार्य 2 स्क्रीन पर किसी भी बहु-मंजिला इमारत के बिना यथासंभव स्थानीय और पठनीय होना चाहिए (मुझे वास्तव में बड़े कार्य पसंद नहीं हैं)।
अंतिम स्थिति में, लोकप्रिय dplyr पैकेज जितना संभव हो उतना आराम से फिट होता है, और यह विचार करते हुए कि इसके पाइपलाइन ऑपरेटरों को उन क्षेत्रों के शाब्दिक नामों को समझना चाहिए जिन्हें फ़ंक्शन में कम किया गया है,
स्टैंडआर्ट मूल्यांकन बिना नहीं
था ।
यहाँ यह बच्चा है (आंतरिक टिप्पणियों की गिनती नहीं):
fn_distr <- function(sharetab, sharetab.value, sharetab.targetvars, basetab, basetab.value, merge.vrs,level.txt=NA) { # sharetab - = # sharetab.value - - # sharetab.targetvars - - # basetab - = # basetab.value - # merge.vrs - 2- # level.txt - . ( merge.vrs) require(dplyr) sharetab.value <- as.name(sharetab.value) basetab.value <- as.name(basetab.value) if(is.na(level.txt )){level.txt <- paste0(merge.vrs,collapse = ",")} result <- sharetab %>% group_by(.dots = c(merge.vrs, sharetab.targetvars)) %>% summarise(sharetab.sum = sum(!!sharetab.value)) %>% ungroup %>% group_by(.dots = merge.vrs) %>% mutate(sharetab.share = sharetab.sum / sum(sharetab.sum)) %>% ungroup %>% right_join(y = basetab, by = merge.vrs) %>% mutate(distributed.result = !!basetab.value * sharetab.share, level = level.txt) %>% select(-sharetab.sum,-sharetab.share) return(result) }
आउटपुट पर, फ़ंक्शन को योजना + तथ्य की उन पंक्तियों के साथ दो तालिकाओं के संघ के डेटा को वापस करना चाहिए + जहां युग्मन फ़ील्ड के वर्तमान संस्करण पर योजना को विभाजित करना संभव था, और योजना की मूल पंक्तियों के साथ (और खाली तथ्य) उन लाइनों में जहां योजना वर्तमान पुनरावृत्ति पर विभाजित नहीं की जा सकती थी।
यही है, पहली पुनरावृत्ति (यारोस्लाव क्षेत्र के लिए योजना की पहली पंक्ति को तोड़ने) के बाद फ़ंक्शन द्वारा लौटा परिणाम इस तरह दिखेगा:
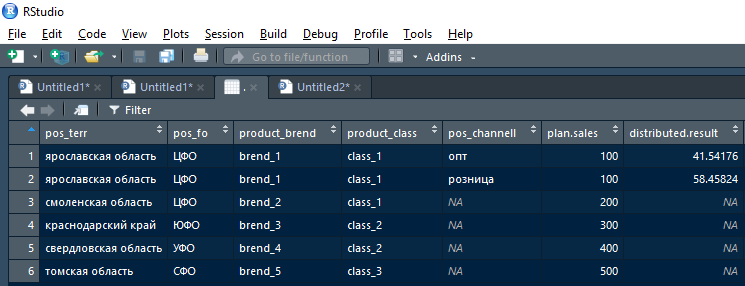
इसके अलावा, इस परिणाम को गैर-रिक्त वितरित द्वारा प्राप्त किया जा सकता है। परिणाम संचयी परिणाम में और खाली (एनए) द्वारा वितरित किया जाता है। संपूर्ण - अगले विशिष्ट पुनरावृत्ति को भेजें, लेकिन उच्चतर पदानुक्रम स्तर पर शेयरों द्वारा टूट गया।
सभी आकर्षण और सभी सुविधा यह है कि काम एक ही प्रकार के ब्लॉक और एक सार्वभौमिक फ़ंक्शन के साथ चलता है, सभी को प्रत्येक चरण (पुनरावृत्ति) की आवश्यकता होती है, वेक्टर मर्ज को सही करने के लिए। यह देखते हैं कि जादू आपके लिए यह सब थकाऊ काम कैसे करता है:

हां, मैं लगभग एक छोटी सी बारीकियों को भूल गया: अगर कुछ गलत हो जाता है और बहुत ही अंत में हमें एक टूटी हुई योजना मिलती है कि कुल मिलाकर टूटने से पहले योजना के बराबर नहीं होगा - यह ट्रैक करना मुश्किल होगा जिस पर चलना सब कुछ गलत हो गया।
इसलिए, हम एक चेकसम के साथ प्रत्येक पुनरावृत्ति की आपूर्ति करते हैं:
(_)-(___ )-(___.)=0
अब हम अपने उदाहरण को वितरण टेम्पलेट के माध्यम से चलाने की कोशिश करते हैं और देखते हैं कि हमें आउटपुट में क्या मिलता है।
सबसे पहले, स्रोत डेटा प्राप्त करें:
library(dplyr) plan <- data_frame(pos_terr = c(" ", " ", " ", " ", " "), pos_fo = c("", "", "", "", ""), product_brend = c("brend_1", "brend_2", "brend_3", "brend_4", "brend_5"), product_class = c("class_1", "class_1", "class_2", "class_2", "class_3"), plan.sales = c(100, 200, 300, 400, 500)) fact <- data_frame(pos_terr = c(" ", " ", " ", " ", " "," ", " ", " ", " ", " "), pos_fo = c("", "","","", "", "", "", "", "", ""), product_brend = c("brend_1", "brend_1", "brend_2", "brend_2","brend_2", "brend_4", "brend_4", "brend_1", "brend_2", "brend_4"), product_class = c("class_1", "class_1", "class_1","class_1","class_1", "class_2", "class_2", "class_1", "class_1", "class_2"), pos_channell = c("", "", "","", "", "", "", "", "", ""), fact.sales = c(16.38, 11.64, 30.73,60, 20, 6.40, 26.49, 46.63, 65.96, 98.81)) </soure> ( ) . <source> plan.remain <- plan result.total <- data_frame()
1. हम वितरित द्वारा आतंक, एफडी (संघीय जिला), ब्रांड, वर्ग merge.fields <- c("pos_terr","pos_fo","product_brend", "product_class") result.current <- fn_distr(sharetab = fact,sharetab.value = "fact.sales",sharetab.targetvars = "pos_channell", basetab = plan.remain,basetab.value = "plan.sales",merge.vrs = merge.fields) result.total <- result.current %>% filter(!is.na(distributed.result)) %>% select(-plan.sales) %>% bind_rows(result.total) # - plan.remain <- result.current %>% filter(is.na(distributed.result)) %>% select(colnames(plan)) # = cat(" :",sum(plan.remain$plan.sales)+sum(result.total$distributed.result)-sum(plan$plan.sales),"\n", " :",nrow(plan.remain)," ")
 2. हम pho, ब्रांड, क्लास द्वारा वितरित करते हैं (अर्थात, हम वास्तव में इस क्षेत्र को छोड़ देते हैं)
2. हम pho, ब्रांड, क्लास द्वारा वितरित करते हैं (अर्थात, हम वास्तव में इस क्षेत्र को छोड़ देते हैं)पहले ब्लॉक से एकमात्र अंतर यह है कि इसमें मर्ज को हटाकर उन्हें थोड़ा मर्ज कर दिया जाता है
merge.fields <- c("pos_fo","product_brend", "product_class") result.current <- fn_distr(sharetab = fact,sharetab.value = "fact.sales",sharetab.targetvars = "pos_channell", basetab = plan.remain,basetab.value = "plan.sales",merge.vrs = merge.fields) result.total <- result.current %>% filter(!is.na(distributed.result)) %>% select(-plan.sales) %>% bind_rows(result.total) plan.remain <- result.current %>% filter(is.na(distributed.result)) %>% select(colnames(plan)) cat(" :",sum(plan.remain$plan.sales)+sum(result.total$distributed.result)-sum(plan$plan.sales),"\n", " :",nrow(plan.remain)," ")
3. pho, वर्ग द्वारा वितरित करें merge.fields <- c("pos_fo", "product_class") result.current <- fn_distr(sharetab = fact,sharetab.value = "fact.sales",sharetab.targetvars = "pos_channell", basetab = plan.remain,basetab.value = "plan.sales",merge.vrs = merge.fields) result.total <- result.current %>% filter(!is.na(distributed.result)) %>% select(-plan.sales) %>% bind_rows(result.total) plan.remain <- result.current %>% filter(is.na(distributed.result)) %>% select(colnames(plan)) cat(" :",sum(plan.remain$plan.sales)+sum(result.total$distributed.result)-sum(plan$plan.sales),"\n", " :",nrow(plan.remain)," ")
4. वर्ग द्वारा वितरित merge.fields <- c( "product_class") result.current <- fn_distr(sharetab = fact,sharetab.value = "fact.sales",sharetab.targetvars = "pos_channell", basetab = plan.remain,basetab.value = "plan.sales",merge.vrs = merge.fields) result.total <- result.current %>% filter(!is.na(distributed.result)) %>% select(-plan.sales) %>% bind_rows(result.total) plan.remain <- result.current %>% filter(is.na(distributed.result)) %>% select(colnames(plan)) cat(" :",sum(plan.remain$plan.sales)+sum(result.total$distributed.result)-sum(plan$plan.sales),"\n", " :",nrow(plan.remain)," ")
 5. एफडी द्वारा वितरित करें
5. एफडी द्वारा वितरित करें merge.fields <- c( "pos_fo") result.current <- fn_distr(sharetab = fact,sharetab.value = "fact.sales",sharetab.targetvars = "pos_channell", basetab = plan.remain,basetab.value = "plan.sales",merge.vrs = merge.fields) result.total <- result.current %>% filter(!is.na(distributed.result)) %>% select(-plan.sales) %>% bind_rows(result.total) plan.remain <- result.current %>% filter(is.na(distributed.result)) %>% select(colnames(plan)) cat(" :",sum(plan.remain$plan.sales)+sum(result.total$distributed.result)-sum(plan$plan.sales),"\n", " :",nrow(plan.remain)," ")
जैसा कि आप देख सकते हैं, कोई "अन-आरा" योजना नहीं बची है और वितरित योजना का अंकगणित मूल के बराबर है।

और यहां बिक्री चैनलों के साथ परिणाम (सही कॉलम में, फ़ंक्शन प्रदर्शित करता है कि युग्मन / एकत्रीकरण किन क्षेत्रों के लिए था, ताकि बाद में हम समझ सकें कि यह वितरण कहां से आया है):

बस इतना ही। लेख बहुत छोटा नहीं था, लेकिन कोड की तुलना में अधिक व्याख्यात्मक पाठ है।
मुझे उम्मीद है कि इस लचीले दृष्टिकोण से न केवल मेरे लिए समय और नसों की बचत होगी :-)
आपका ध्यान के लिए धन्यवाद।