कुछ महीने पहले, Google के हमारे सहयोगियों ने प्रशंसित
खेल "क्विक, ड्रॉ!" में प्राप्त चित्रों के लिए एक क्लासिफायर बनाने के लिए कागल में एक प्रतियोगिता
आयोजित की थी! ”। टीम, जिसमें यैंडेक्स डेवलपर रोमन वालसोव ने भाग लिया, ने प्रतियोगिता में चौथा स्थान हासिल किया। जनवरी के मशीन-प्रशिक्षण सत्र में, रोमन ने अपनी टीम के विचारों, क्लासिफायर के अंतिम कार्यान्वयन और प्रतिद्वंद्वियों की दिलचस्प प्रथाओं को साझा किया।
- सभी को नमस्कार! मेरा नाम रोमा वेल्लासोव है, आज मैं आपको क्विक, ड्रॉ के बारे में बताऊंगा! डूडल रिकॉग्निशन चैलेंज।

हमारी टीम में पांच लोग थे। मैं मर्ज की समय सीमा के सामने उसके अधिकार में शामिल हो गया। हम बदकिस्मत थे, हम थोड़े से हिल गए थे, लेकिन हम पैसे से हिल गए थे, और वे सोने की स्थिति से थे। और हमने एक सम्मानजनक चौथा स्थान प्राप्त किया।
(प्रतियोगिता के दौरान, टीमों ने खुद को रेटिंग में देखा, जो प्रस्तावित डेटा सेट के एक हिस्से पर दिखाए गए परिणामों के अनुसार बनाया गया था। अंतिम रेटिंग, बदले में डेटासेट के दूसरे हिस्से पर बनाई गई थी। ऐसा इसलिए किया जाता है ताकि प्रतियोगिता के प्रतिभागी अपने एल्गोरिदम को विशिष्ट डेटा में समायोजित न करें। इसलिए, फाइनल में, जब रेटिंग के बीच स्विच करते हैं, तो पदों को थोड़ा हिलाएं (अंग्रेजी शेक अप - फेरबदल से): अन्य डेटा पर और परिणाम अलग हो सकता है। रोमन की टीम पहले शीर्ष तीन में थी। ए.यू. तिकड़ी -, पैसा, पैसा रैंकिंग क्षेत्र है के बाद से केवल पहले तीन स्थानों पुरस्कार भरोसा "शेक ए पी ए 'टीम के बाद उसी तरह अन्य टीम जीत, सोने -... एड की स्थिति) खो चौथे स्थान पर पहले से ही था ..
प्रतियोगिता इसलिए भी महत्वपूर्ण थी क्योंकि येवगेनी बाबाखानिन को उनके लिए दादी, इवान सोसिन - स्वामी, रोमन सोलोविओव ग्रैंडमास्टर बने रहे, एलेक्स परिनोव ने एक मास्टर प्राप्त किया, मैं एक विशेषज्ञ बन गया, और अब मैं पहले से ही एक मास्टर हूं।
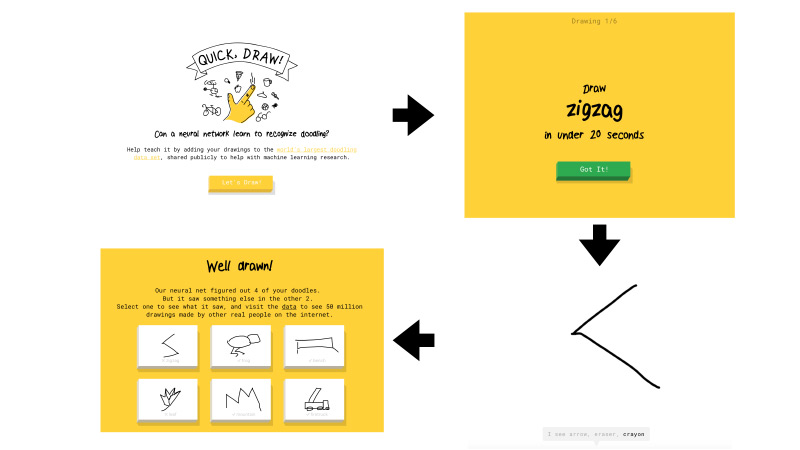
यह क्विक, ड्रा क्या है? यह Google की एक सेवा है। Google ने AI को लोकप्रिय बनाने का लक्ष्य रखा और इस सेवा के साथ यह दिखाना चाहता था कि तंत्रिका नेटवर्क कैसे काम करते हैं। आप वहां जाते हैं, लेट्स ड्रॉ पर क्लिक करते हैं, और एक नया पेज बाहर निकलता है जहाँ आपको बताया जाता है: एक ज़िगज़ैग ड्रा करें, आपके पास ऐसा करने के लिए 20 सेकंड हैं। आप उदाहरण के लिए, यहां 20 सेकंड में एक ज़िगज़ैग बनाने की कोशिश करते हैं। यदि सब कुछ आपके लिए काम करता है, तो नेटवर्क कहता है कि यह एक ज़िगज़ैग है और आप आगे बढ़ते हैं। ऐसी केवल छह तस्वीरें हैं।
यदि Google का नेटवर्क पहचान नहीं सका कि आपने क्या ड्रॉ किया है, तो एक क्रॉस को कार्य पर रखा गया था। बाद में मैं आपको बताऊंगा कि भविष्य में क्या मतलब होगा कि ड्राइंग को नेटवर्क द्वारा मान्यता प्राप्त है या नहीं।
इस सेवा ने बड़ी संख्या में उपयोगकर्ताओं को इकट्ठा किया, और उपयोगकर्ताओं द्वारा खींची गई सभी तस्वीरें लॉग की गईं।

लगभग 50 मिलियन चित्रों को एकत्र करना संभव था। इससे, हमारी प्रतियोगिता के लिए ट्रेन और परीक्षण की तारीख का गठन किया गया। वैसे, परीक्षण में डेटा की मात्रा और बोल्ड में कक्षाएं व्यर्थ नहीं हैं। मैं उनके बारे में थोड़ी देर बाद बात करूंगा।
डेटा प्रारूप इस प्रकार था। ये सिर्फ RGB इमेजेज नहीं हैं, बल्कि मोटे तौर पर कहें तो हर उस चीज का लॉग है जो यूजर ने किया था। वर्ड हमारा लक्ष्य है, देश का वह स्थान है जहां डूडल है, टाइमस्टैम्प समय है। मान्यता प्राप्त लेबल यह दर्शाता है कि Google के नेटवर्क ने चित्र को पहचाना या नहीं। और ड्राइंग खुद एक अनुक्रम है, वक्र का एक अनुमान जो उपयोगकर्ता डॉट्स के साथ खींचता है। और टाइमिंग। यह चित्र बनाने की शुरुआत से समय है।
डेटा को दो प्रारूपों में प्रस्तुत किया गया था। यह पहला प्रारूप है, और दूसरा सरल है। उन्होंने वहां से समय देखा और अंकों के एक छोटे से सेट के साथ इस सेट का अनुमान लगाया। ऐसा करने के लिए, उन्होंने
डगलस-पीकर एल्गोरिथम का उपयोग किया। आपके पास बिंदुओं का एक बड़ा समूह है जो बस एक सीधी रेखा का अनुमान लगाता है, लेकिन आप वास्तव में सिर्फ दो बिंदुओं के साथ इस रेखा का अनुमान लगा सकते हैं। यह एल्गोरिथम का विचार है।
डेटा निम्नानुसार वितरित किया गया था। सब कुछ एक समान है, लेकिन कुछ आउटलेयर हैं। जब हमने समस्या का समाधान किया, तो हमने इसे नहीं देखा। मुख्य बात यह है कि ऐसी कोई कक्षाएं नहीं थीं जो वास्तव में बहुत कम हैं, हमें भारित नमूने और डेटा ओवरसम्पलिंग नहीं करना था।

तस्वीरें कैसी दिखती थीं? यह विमान श्रेणी है और इसके उदाहरणों को मान्यता प्राप्त और गैर-मान्यता प्राप्त करार दिया जाता है। उनका अनुपात कहीं 1 से 9 था। जैसा कि आप देख सकते हैं, डेटा काफी शोर है। मैं सुझाव दूंगा कि यह एक विमान है। अगर आप पहचाने नहीं जाते हैं, तो ज्यादातर मामलों में यह सिर्फ शोर है। किसी ने भी "हवाई जहाज" लिखने की कोशिश की, लेकिन जाहिर तौर पर फ्रेंच में।
अधिकांश प्रतिभागियों ने केवल ग्रिड लिया, आरजीबी छवियों के रूप में लाइनों के इस क्रम से डेटा प्रदान किया, और उन्हें नेटवर्क में फेंक दिया। मैंने लगभग उसी तरह से पेंट किया: मैंने एक रंग पैलेट लिया, मैंने पहली पंक्ति को एक रंग के साथ चित्रित किया, जो इस पैलेट की शुरुआत में था, आखिरी एक, दूसरे के साथ, जो पैलेट के अंत में था, और उनके बीच हर जगह इस पैलेट पर हस्तक्षेप किया गया। वैसे, इससे बेहतर परिणाम दिया गया जैसे कि आप पहली ही स्लाइड में आकर्षित करते हैं - सिर्फ काला।
इवान सोसिन जैसे अन्य टीम के सदस्यों ने ड्राइंग के लिए थोड़ा अलग तरीकों की कोशिश की। एक चैनल के साथ, उन्होंने बस एक ग्रे तस्वीर खींची, दूसरे चैनल के साथ, उन्होंने प्रत्येक स्ट्रोक को शुरू से अंत तक, 32 से 255 तक, और तीसरे चैनल ने 32 से 255 तक सभी स्ट्रोक में एक ढाल आकर्षित किया।
एक और दिलचस्प बात यह है कि एलेक्स परिनोव ने कंट्रीकोड के माध्यम से नेटवर्क में जानकारी फेंक दी।
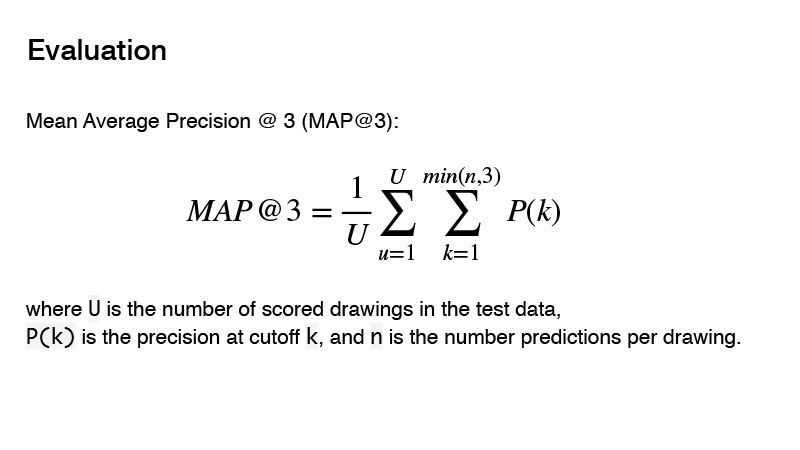
प्रतियोगिता में उपयोग की जाने वाली मीट्रिक औसत औसत परिशुद्धता है। प्रतियोगिता के लिए इस मीट्रिक का सार क्या है? आप तीन भविष्यवक्ता दे सकते हैं, और यदि ये तीन भविष्यवक्ता सही नहीं हैं, तो आपको 0. प्राप्त होता है। यदि कोई सही है, तो उसके आदेश को ध्यान में रखा जाता है। और लक्ष्य के लिए परिणाम को आपकी भविष्यवाणी के क्रम से विभाजित 1 माना जाएगा। उदाहरण के लिए, आपने तीन भविष्यवाणी की हैं, और पहले वाला सही है, तो आप 1 को 1 से विभाजित करते हैं और 1 प्राप्त करते हैं। यदि पूर्वसूचक सही है और इसका क्रम 2 है, तो 1 को 2 से विभाजित करें, आपको 0.5 मिलता है। खैर, आदि।

डेटा प्रीप्रोसेसिंग के साथ - चित्र और इतने पर कैसे आकर्षित करें - हमने थोड़ा फैसला किया। हमने किन आर्किटेक्चर का इस्तेमाल किया? हमने PNASNet, SENet जैसे बोल्ड आर्किटेक्चर का उपयोग करने की कोशिश की, और पहले से ही SE-Res-NeXt जैसे क्लासिक आर्किटेक्चर, वे तेजी से नई प्रतियोगिताओं में आ रहे हैं। रेसनेट और डेंसनेट भी थे।



हमने यह कैसे सिखाया? जितने भी मॉडल हमने लिए, हमने खुद को इमेजनेट पर पहले से प्रशिक्षित किया। यद्यपि बहुत अधिक डेटा है, 50 मिलियन छवियां, लेकिन फिर भी, यदि आप इमेजनेट पर पूर्व-प्रशिक्षित नेटवर्क लेते हैं, तो यह बेहतर परिणाम दिखाता है यदि आप इसे खरोंच से प्रशिक्षित करते हैं।
हमने किन प्रशिक्षण तकनीकों का उपयोग किया? यह वार्मिंग रिस्टार्ट्स के साथ कॉइनिंग एनलिंग है, मैं इसके बारे में थोड़ी देर बाद बात करूंगा। यह एक ऐसी तकनीक है जिसे मैं अपनी लगभग सभी अंतिम प्रतियोगिताओं में उपयोग करता हूं, और उनके साथ नेट को प्रशिक्षित करने के लिए, एक न्यूनतम न्यूनतम हासिल करने के लिए यह बहुत अच्छा है।

पठार पर अगला कम सीखने की दर। आप नेटवर्क को प्रशिक्षित करना शुरू करते हैं, कुछ विशिष्ट सीखने की दर निर्धारित करते हैं, फिर इसे सीखते हैं, फिर आपका नुकसान धीरे-धीरे कुछ विशिष्ट मूल्य में परिवर्तित हो जाता है। आप इसकी जांच करते हैं, उदाहरण के लिए, दस युगों में, हानि नहीं बदली है। आप अपने सीखने की दर को कुछ मूल्य से कम करते हैं और सीखना जारी रखते हैं। यह फिर से थोड़ा कम हो जाता है, एक निश्चित न्यूनतम पर परिवर्तित हो जाता है, और फिर से आप सीखने की दर को कम करते हैं, और इसी तरह, जब तक कि आपका नेटवर्क अंत में परिवर्तित नहीं हो जाता।
आगे की दिलचस्प तकनीक: सीखने की दर को कम न करें, बैच का आकार बढ़ाएं। उसी नाम का एक लेख है। जब आप नेटवर्क को प्रशिक्षित करते हैं, तो आपको सीखने की दर को कम करने की ज़रूरत नहीं है, आप बस बैच का आकार बढ़ा सकते हैं।
वैसे, इस तकनीक का उपयोग एलेक्स परिनोव द्वारा किया गया था। उन्होंने 408 के बराबर बैच के साथ शुरुआत की, और जब नेटवर्क उनके पठार पर आया, तो उन्होंने बस बैच का आकार दोगुना कर दिया, आदि।
वास्तव में, मुझे याद नहीं है कि बैच का आकार क्या है, लेकिन दिलचस्प बात यह है कि कागले पर ऐसी टीमें थीं, जिन्होंने एक ही तकनीक का इस्तेमाल किया था, उनके बैच का आकार लगभग 10,000 था। वैसे, गहरी शिक्षा के लिए आधुनिक रूपरेखाएँ, जैसे उदाहरण के लिए, PyTorch, आपको बहुत सरलता से ऐसा करने की अनुमति देता है। आप अपने बैच को उत्पन्न करते हैं और इसे नेटवर्क में जमा नहीं करते हैं, जैसे कि इसकी संपूर्णता में, लेकिन इसे विखंडू में विभाजित करें ताकि यह आपके वीडियो कार्ड में फिट हो जाए, ग्रेडिएंट्स की गणना करें, और पूरे बैच के लिए ढाल की गणना करने के बाद, आप तराजू को अपडेट करें।
वैसे, इस प्रतियोगिता में बड़े बैच के आकार अभी भी आए हैं, क्योंकि डेटा काफी शोर था, और एक बड़े बैच के आकार ने आपको ढाल को अधिक सटीक रूप से अनुमानित करने में मदद की।
छद्म-डबिंग का भी उपयोग किया गया था, अधिकांश भाग के लिए, इसका उपयोग रोमन सोलोविएव द्वारा किया गया था। उन्होंने परीक्षण से आधे डेटा में कहीं नमूना लिया, और ऐसे बैचों पर उन्होंने ग्रिड को प्रशिक्षित किया।
चित्रों के आकार ने एक भूमिका निभाई, लेकिन तथ्य यह है कि आपके पास बहुत अधिक डेटा है, आपको लंबे समय तक प्रशिक्षित करने की आवश्यकता है, और यदि आपका चित्र आकार काफी बड़ा है, तो आप बहुत लंबे समय तक प्रशिक्षण लेंगे। लेकिन यह आपके अंतिम क्लासिफायर की गुणवत्ता में इतना अधिक नहीं लाया, इसलिए यह कुछ ट्रेड-ऑफ का उपयोग करने के लायक था। और उन्होंने केवल बहुत बड़े आकार के नहीं चित्रों की कोशिश की।
यह सब कैसे सीखा? सबसे पहले, एक छोटे आकार की तस्वीरें ली गईं, उन पर कई युग चलाए गए, जल्दी से समय लगा। फिर बड़ी तस्वीरें दी गईं, नेटवर्क सीखा, फिर और भी, और भी अधिक ताकि इसे खरोंच से प्रशिक्षित न करें और बहुत समय खर्च न करें।
आशावादियों के बारे में। हमने SGD और एडम का इस्तेमाल किया। इस तरह, एक एकल मॉडल प्राप्त करना संभव था, जिसने एक सार्वजनिक लीडरबोर्ड पर 0.941-0.946 की गति दी, जो बहुत अच्छा है।
यदि आप किसी तरह से मॉडल बनाते हैं, तो आपको कहीं न कहीं 0.951 मिलते हैं। यदि आप दूसरी तकनीक लागू करते हैं, तो आपको सार्वजनिक बोर्ड पर अंतिम गति 0.954 मिलेगी, जैसा कि हमने प्राप्त किया था। लेकिन उस पर और बाद में। आगे, मैं आपको बताऊंगा कि हमने मॉडल कैसे इकट्ठे किए, और इस तरह की अंतिम गति कैसे प्राप्त हुई।
इसके बाद मैं वार्म रेस्टार्ट्स के साथ कॉर्निंग एनीलिंग के बारे में बात करना चाहूंगा या वार्मस्टार्ट्स के साथ स्टोचैस्टिक ग्रेडिएंट डिसेंट। मोटे तौर पर, सिद्धांत रूप में, आप किसी भी आशावादी को छड़ी कर सकते हैं, लेकिन नीचे की रेखा यह है: यदि आप सिर्फ एक नेटवर्क को प्रशिक्षित करते हैं और धीरे-धीरे यह एक न्यूनतम में परिवर्तित हो जाता है, तो सब कुछ ठीक है, आपको एक नेटवर्क मिलेगा, यह कुछ गलतियां करता है, लेकिन आप उसे थोड़ा अलग तरीके से सिखा सकते हैं। आप कुछ प्रारंभिक सीखने की दर निर्धारित करेंगे, और इस सूत्र के अनुसार धीरे-धीरे इसे कम करेंगे। आप इसे कम आंकते हैं, आपका नेटवर्क एक निश्चित न्यूनतम पर आता है, फिर आप वज़न बचाते हैं, और फिर से सीखने की दर निर्धारित करते हैं, जो कि प्रशिक्षण की शुरुआत में थी, जिससे यह न्यूनतम कहीं ऊपर जाता है, और फिर से आपके सीखने की दर को कम करता है।
इस प्रकार, आप एक साथ कई चढ़ावों पर जा सकते हैं, जिसमें आपको नुकसान प्लस या माइनस होगा। लेकिन तथ्य यह है कि इन वज़न वाले नेटवर्क आपकी तिथि पर अलग-अलग त्रुटियां देंगे। उन्हें औसत करने से, आपको एक निश्चित अनुमान मिलेगा, और आपकी गति अधिक होगी।
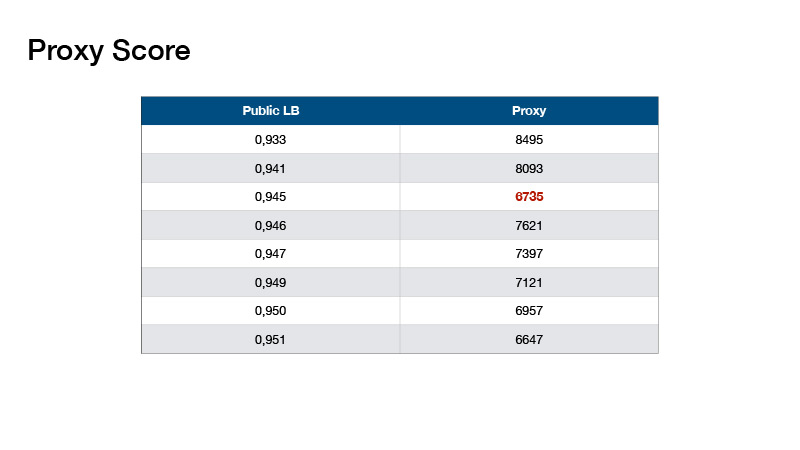
इस बारे में कि हमने अपने मॉडल कैसे इकट्ठे किए। प्रस्तुति की शुरुआत में, मैंने परीक्षण में डेटा की मात्रा और कक्षाओं की संख्या पर ध्यान देने के लिए कहा। यदि आप परीक्षण सेट में लक्ष्य की संख्या में 1 जोड़ते हैं और वर्गों की संख्या से विभाजित करते हैं, तो आपको संख्या 330 मिलती है, और यह मंच पर लिखा गया था - कि परीक्षण में कक्षाएं संतुलित हैं। इसका उपयोग किया जा सकता है।
इसके आधार पर, रोमन सोलोवोव ने मीट्रिक का आविष्कार किया, हमने इसे प्रॉक्सी स्कोर कहा, जो लीडरबोर्ड के साथ काफी अच्छी तरह से जुड़ा हुआ था। लब्बोलुआब यह है: आप एक भविष्यवाणी करते हैं, अपने शीर्षकों का शीर्ष -1 लेते हैं और प्रत्येक वर्ग के लिए वस्तुओं की संख्या गिनते हैं। प्रत्येक मान से 330 घटाएँ और परिणामी निरपेक्ष मान जोड़ें।
ऐसे मान गए। इससे हमें एक परीक्षण लीडरबोर्ड नहीं करने में मदद मिली, लेकिन स्थानीय रूप से मान्य करने और हमारे पहनावे के लिए गुणांक चुनने के लिए।
पहनावा के साथ आप इस तरह की गति प्राप्त कर सकते हैं। और क्या करना है? मान लीजिए कि आपने इस जानकारी का उपयोग किया है कि आपके परीक्षण में कक्षाएं संतुलित हैं।
संतुलन अलग था।
उनमें से एक का उदाहरण उन लोगों से संतुलन बना रहा है जो पहले स्थान पर जीते थे।
हमने क्या किया? हमारा संतुलन काफी सरल था, यह इवगेनी बाबाखिन द्वारा प्रस्तावित किया गया था। हमने पहले टॉप -1 और उनकी ओर से चयनित उम्मीदवारों द्वारा अपनी भविष्यवाणियों को क्रमबद्ध किया - ताकि कक्षाओं की संख्या 330 से अधिक न हो। लेकिन कुछ वर्गों के लिए, यह पता चला है कि 330 से कम पूर्वानुमान हैं। ठीक है, चलो शीर्ष -2 द्वारा क्रमबद्ध करें और शीर्ष 3, और उम्मीदवार भी चुनें।
पहली बार संतुलन बनाने से हमारा संतुलन कैसे अलग हुआ? उन्होंने एक पुनरावृत्त दृष्टिकोण का उपयोग किया, सबसे लोकप्रिय वर्ग लिया और कुछ छोटी संख्या द्वारा इस वर्ग के लिए संभावनाओं को कम कर दिया - जब तक कि यह वर्ग सबसे लोकप्रिय नहीं हो गया। उन्होंने अगला सबसे लोकप्रिय वर्ग लिया। इसलिए सभी वर्गों की संख्या बराबर होने तक इसे और कम किया गया।
हर कोई प्रशिक्षण नेटवर्क के लिए एक से अधिक या शून्य से एक दृष्टिकोण का उपयोग करता था, लेकिन हर कोई संतुलन का उपयोग नहीं करता था। संतुलन का उपयोग करते हुए, आप सोने में जा सकते हैं, और यदि आप भाग्यशाली थे, तो मणि में।
कैसे एक तारीख प्रीप्रोसेस करने के लिए? सभी ने प्लस-माइनस तिथि को उसी तरह से पूर्व-संसाधित किया - हस्तनिर्मित सुविधाओं को किया, अलग-अलग रंग के स्ट्रोक के साथ समय को सांकेतिक शब्दों में बदलना करने की कोशिश की, आदि यह वही है जो एलेक्सी नोज़ड्रिन-प्लॉट्नित्सकी ने कहा था, जिन्होंने 8 वां स्थान लिया था।

उसने अलग तरीके से किया। उन्होंने कहा कि आपके सभी हैंडक्राफ्टेड फीचर्स काम नहीं करते हैं, आपको ऐसा करने की आवश्यकता नहीं है, आपके नेटवर्क को यह सब स्वयं सीखना होगा। और इसके बजाय, वह सीखने के मॉड्यूल के साथ आया जिसने आपके डेटा का प्रीप्रोसेसिंग किया। उन्होंने उन्हें बिना पूर्व सूचना के स्रोत डेटा में फेंक दिया - अंक और समय के निर्देशांक।
इसके अलावा, उन्होंने निर्देशांक में अंतर लिया, और इसे समय पर औसत किया। और उसे एक लंबी मैट्रिक्स मिली। उन्होंने 64xn मैट्रिक्स प्राप्त करने के लिए कई बार 1D कनवल्शन का उपयोग किया, जहाँ n कुल अंकों की संख्या है, और 64 कन्ट्रोवर्शियल नेटवर्क की एक परत को परिणामी मैट्रिक्स को खिलाने के लिए 64 बनाया जाता है जो 64 चैनलों को स्वीकार करता है। यह 64xn मैट्रिक्स निकला, फिर इसमें से कुछ आकार के एक टेंसर की रचना करना आवश्यक था ताकि चैनलों की संख्या 64 हो जाए। उन्होंने 0 से 32 तक के सभी बिंदुओं X, Y को सामान्य कर दिया और आकार 32x32 का टेंसर बनाया। मुझे नहीं पता कि वह 32x32 क्यों चाहता है, ऐसा हुआ। और इस समन्वय में उन्होंने 64xn आकार के इस मैट्रिक्स का एक टुकड़ा रखा। इस प्रकार, उन्होंने केवल 32x32x64 टेंसर प्राप्त किया, जिसे आपके दृढ़ तंत्रिका नेटवर्क में और डाला जा सकता है। मेरे पास सब कुछ है।