हमले का पता लगाना दशकों से सूचना सुरक्षा का एक हिस्सा रहा है। पहला ज्ञात घुसपैठ पहचान प्रणाली (IDS) कार्यान्वयन 1980 के दशक की शुरुआत में हुआ।
आजकल, पूरे हमले का पता लगाने वाला उद्योग मौजूद है। कई प्रकार के उत्पाद हैं - जैसे आईडीएस, आईपीएस, डब्ल्यूएएफ, और फ़ायरवॉल समाधान - जिनमें से अधिकांश नियम-आधारित हमले का पता लगाने की पेशकश करते हैं। उत्पादन में हमलों की पहचान करने के लिए कुछ प्रकार के सांख्यिकीय विसंगति का उपयोग करने का विचार उतना वास्तविक नहीं लगता जितना कि इसका उपयोग किया जाता था। लेकिन क्या यह धारणा उचित है?
वेब अनुप्रयोगों में विसंगतियों का पता लगाना
1990 के दशक की शुरुआत में बाजार पर वेब एप्लिकेशन हमलों का पता लगाने के लिए तैयार पहली फायरवॉल। हमला करने की तकनीक और सुरक्षा तंत्र तब से नाटकीय रूप से विकसित हो गए हैं, जब हमलावर एक कदम आगे निकलने के लिए दौड़ रहे हैं।
अधिकांश वर्तमान वेब एप्लिकेशन फायरवॉल (WAFs) कुछ इसी प्रकार के रिवर्स प्रॉक्सी में नियम-आधारित इंजन के साथ एक समान फैशन में हमलों का पता लगाने का प्रयास करते हैं। सबसे प्रमुख उदाहरण mod_security है, जो Apache वेब सर्वर के लिए एक WAF मॉड्यूल है, जो 2002 में बनाया गया था। नियम-आधारित पहचान में कुछ नुकसान हैं: उदाहरण के लिए, यह उपन्यास हमलों (शून्य-दिनों) का पता लगाने में विफल रहता है, भले ही ये हमले हों एक मानव विशेषज्ञ द्वारा आसानी से पता लगाया जा सकता है। यह तथ्य आश्चर्यजनक नहीं है, क्योंकि मानव मस्तिष्क नियमित अभिव्यक्तियों के एक सेट की तुलना में बहुत अलग तरीके से काम करता है।
एक WAF के परिप्रेक्ष्य से, हमलों को क्रमिक रूप से आधारित लोगों (समय श्रृंखला) में विभाजित किया जा सकता है और जो एक एकल HTTP अनुरोध या प्रतिक्रिया से युक्त होते हैं। हमारे शोध ने बाद के प्रकारों के हमलों का पता लगाने पर ध्यान केंद्रित किया, जिनमें शामिल हैं:
- एसक्यूएल इंजेक्शन
- क्रॉस-साइट स्क्रिप्टिंग
- एक्सएमएल बाहरी एंटिटी इंजेक्शन
- पथ संचलन
- ओएस कमांडिंग
- वस्तु इंजेक्शन
लेकिन पहले खुद से पूछें: इंसान ऐसा कैसे करेगा?
एक ही निवेदन को देखकर मनुष्य क्या करेगा
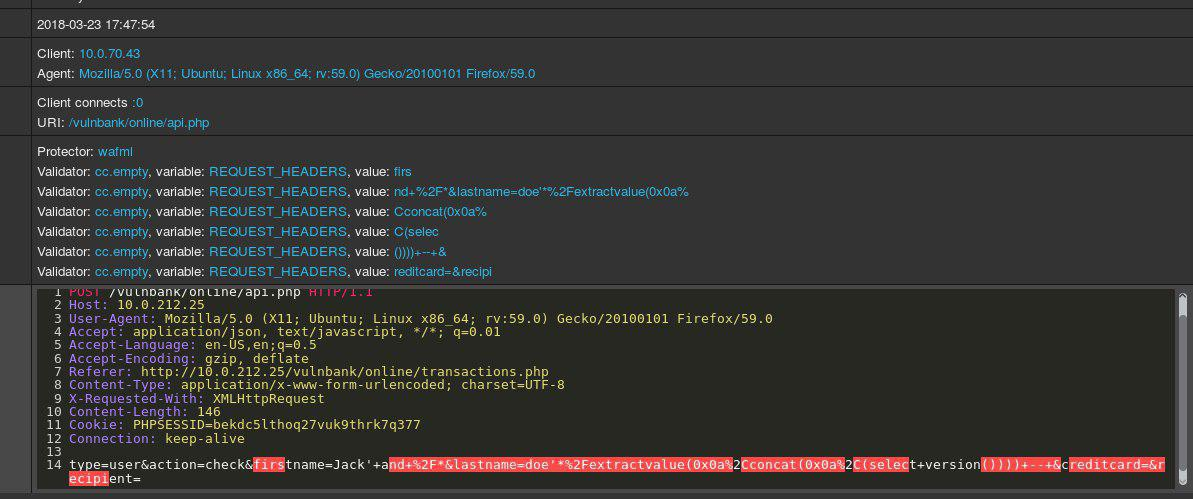
कुछ एप्लिकेशन के नियमित HTTP अनुरोध के नमूने पर एक नज़र डालें:
यदि आपको किसी एप्लिकेशन पर भेजे गए दुर्भावनापूर्ण अनुरोधों का पता लगाना था, तो सबसे अधिक संभावना है कि आप कुछ समय के लिए सौम्य अनुरोधों का पालन करना चाहते हैं। कई एप्लिकेशन निष्पादन समापन बिंदुओं के अनुरोधों को देखने के बाद, आपको यह सामान्य रूप से पता होगा कि सुरक्षित अनुरोधों को संरचित कैसे किया जाता है और उनमें क्या शामिल हैं।
अब आपको निम्नलिखित अनुरोध के साथ प्रस्तुत किया गया है:

आप तुरंत समझ लें कि कुछ गड़बड़ है। यह समझने में कुछ समय लगता है कि वास्तव में क्या है, और जैसे ही आप अनुरोध के सटीक टुकड़े का पता लगाते हैं, जो कि विसंगत है, आप यह सोचना शुरू कर सकते हैं कि यह किस प्रकार का हमला है। अनिवार्य रूप से, हमारा लक्ष्य हमारे हमले का पता लगाने वाले एआई को इस मानवीय तर्क से मिलता-जुलता है।
हमारे कार्य की शिकायत करना यह है कि कुछ ट्रैफ़िक, भले ही यह पहली नज़र में दुर्भावनापूर्ण हों, वास्तव में किसी विशेष वेबसाइट के लिए सामान्य हो सकते हैं।
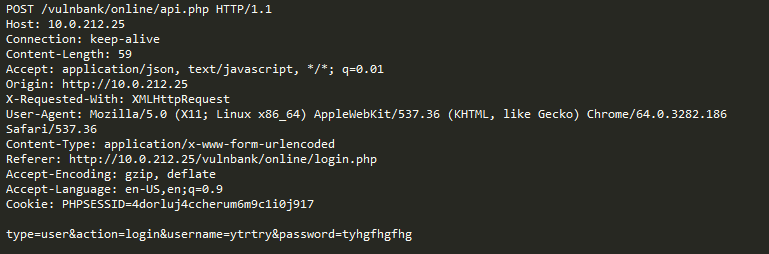
उदाहरण के लिए, आइए निम्नलिखित अनुरोध देखें:
क्या यह एक विसंगति है? दरअसल, यह अनुरोध सौम्य है: यह जीरा बग ट्रैकर पर बग प्रकाशन से संबंधित एक विशिष्ट अनुरोध है।
अब एक और मामले पर नज़र डालते हैं:

सबसे पहले अनुरोध जूमला सीएमएस द्वारा संचालित वेबसाइट पर विशिष्ट उपयोगकर्ता साइनअप की तरह दिखता है। हालाँकि, अनुरोधित ऑपरेशन सामान्य "पंजीकरण.ग्रिस्टर" के बजाय "user.register" है। पूर्व विकल्प को पदावनत किया जाता है और इसमें एक भेद्यता होती है जिससे कोई भी व्यवस्थापक के रूप में साइन अप कर सकता है।
इस कारनामे को "जूमला <3.6.4 अकाउंट क्रिएशन / प्रिविलेज एस्केलेशन" (CVE-2016-8869, CVE-2016-8870) के रूप में जाना जाता है।

हमने कैसे शुरुआत की
हमने पहले पिछले शोध पर एक नज़र डाली, क्योंकि हमलों का पता लगाने के लिए विभिन्न सांख्यिकीय या मशीन लर्निंग एल्गोरिदम बनाने के कई प्रयास पूरे दशकों में किए गए हैं। सबसे लगातार दृष्टिकोणों में से एक वर्ग ("सौम्य अनुरोध," "एसक्यूएल इंजेक्शन," "XSS," "CSRF," और इसके बाद) को असाइनमेंट के कार्य को हल करना है। जबकि कोई किसी दिए गए डेटासेट के लिए वर्गीकरण के साथ सभ्य सटीकता प्राप्त कर सकता है, यह दृष्टिकोण कुछ बहुत महत्वपूर्ण समस्याओं को हल करने में विफल रहता है:
- क्लास सेट का विकल्प । क्या होगा यदि सीखने के दौरान आपका मॉडल तीन वर्गों ("सौम्य," "SQLi," "XSS") के साथ प्रस्तुत किया जाता है, लेकिन उत्पादन में यह CSRF हमले या यहां तक कि एक ब्रांड-नई हमले तकनीक का सामना करता है?
- इन वर्गों का अर्थ । मान लीजिए कि आपको 10 ग्राहकों की रक्षा करने की आवश्यकता है, उनमें से प्रत्येक पूरी तरह से अलग वेब एप्लिकेशन चला रहा है। उनमें से ज्यादातर के लिए, आपको पता नहीं होगा कि उनके आवेदन के खिलाफ एक "SQL इंजेक्शन" हमला वास्तव में कैसा दिखता है। इसका मतलब है कि आपको किसी भी तरह से अपने सीखने के डेटासेट को कृत्रिम रूप से बनाना होगा - जो एक बुरा विचार है, क्योंकि आप अपने वास्तविक डेटा की तुलना में पूरी तरह से अलग वितरण के साथ डेटा से सीखेंगे।
- आपके मॉडल के परिणामों की व्याख्या । महान, इसलिए मॉडल "एसक्यूएल इंजेक्शन" लेबल के साथ आया था - अब क्या? आप और सबसे महत्वपूर्ण बात यह है कि आपका ग्राहक, जो अलर्ट को देखने वाला पहला व्यक्ति है और आमतौर पर वेब हमलों का विशेषज्ञ नहीं है, को यह अनुमान लगाना होगा कि मॉडल किस भाग को दुर्भावनापूर्ण मानता है।
इस बात को ध्यान में रखते हुए, हमने वर्गीकरण का प्रयास करने का निर्णय लिया।
चूंकि HTTP प्रोटोकॉल टेक्स्ट-आधारित है, इसलिए यह स्पष्ट था कि हमें आधुनिक टेक्स्ट क्लासिफायर पर एक नज़र डालनी थी। प्रसिद्ध उदाहरणों में से एक IMDB फिल्म समीक्षा डेटासेट का भाव विश्लेषण है। कुछ समाधान इन समीक्षाओं को वर्गीकृत करने के लिए आवर्तक तंत्रिका नेटवर्क (RNN) का उपयोग करते हैं। हमने कुछ समान अंतरों के साथ एक समान आरएनएन वर्गीकरण मॉडल का उपयोग करने का निर्णय लिया। उदाहरण के लिए, प्राकृतिक भाषा वर्गीकरण RNN शब्द एम्बेडिंग का उपयोग करते हैं, लेकिन यह स्पष्ट नहीं है कि HTTP पर गैर-प्राकृतिक भाषा में कौन से शब्द हैं। इसलिए हमने अपने मॉडल में चरित्र एम्बेडिंग का उपयोग करने का निर्णय लिया।
समस्या को हल करने के लिए तैयार किए गए एम्बेडिंग अप्रासंगिक हैं, यही वजह है कि हमने कई आंतरिक मार्करों जैसे कि
GO और
EOS के साथ वर्णों के सरल मैपिंग का उपयोग किया है।
हमने मॉडल के विकास और परीक्षण को समाप्त करने के बाद, पहले से बताई गई सभी समस्याओं को पारित कर दिया, लेकिन कम से कम हमारी टीम निष्क्रिय मसालों से कुछ उत्पादक तक पहुंच गई थी।
हम कैसे आगे बढ़े
वहां से, हमने अपने मॉडल के परिणामों को अधिक व्याख्यात्मक बनाने का प्रयास करने का निर्णय लिया। कुछ बिंदु पर हम "ध्यान" के तंत्र में आए और इसे अपने मॉडल में एकीकृत करना शुरू कर दिया। और इससे कुछ आशाजनक परिणाम मिले: अंत में, सब कुछ एक साथ आया और हमें कुछ मानव-व्याख्यात्मक परिणाम मिले। अब हमारे मॉडल ने न केवल लेबल, बल्कि इनपुट के हर चरित्र के लिए ध्यान देने योग्य गुणांक तैयार करना शुरू कर दिया।
यदि वह कल्पना की जा सकती है, तो कहें, एक वेब इंटरफेस में, हम उस सटीक स्थान को रंग सकते हैं जहां "SQL इंजेक्शन" हमला पाया गया है। यह एक आशाजनक परिणाम था, लेकिन अन्य समस्याएं अभी भी अनसुलझी हैं।
हमने यह देखना शुरू किया कि हम ध्यान तंत्र की दिशा में जाकर और वर्गीकरण से दूर रहकर लाभ उठा सकते हैं। उदाहरण से संबंधित कई शोधों को पढ़ने के बाद (उदाहरण के लिए, "ध्यान आप सभी की जरूरत है," Word2Vec, और एनकोडर - डिकोडर आर्किटेक्चर) अनुक्रम मॉडल पर और हमारे डेटा के साथ प्रयोग करके, हम एक विसंगति का पता लगाने वाला मॉडल बनाने में सक्षम थे जो इसमें काम करेगा एक मानव विशेषज्ञ के रूप में कमोबेश उसी तरह।
Autoencoders
कुछ बिंदु पर यह स्पष्ट हो गया कि एक अनुक्रम-टू-सीक्वेंस ऑटोएन्कोडर हमारे उद्देश्य को सबसे अच्छा फिट करता है।
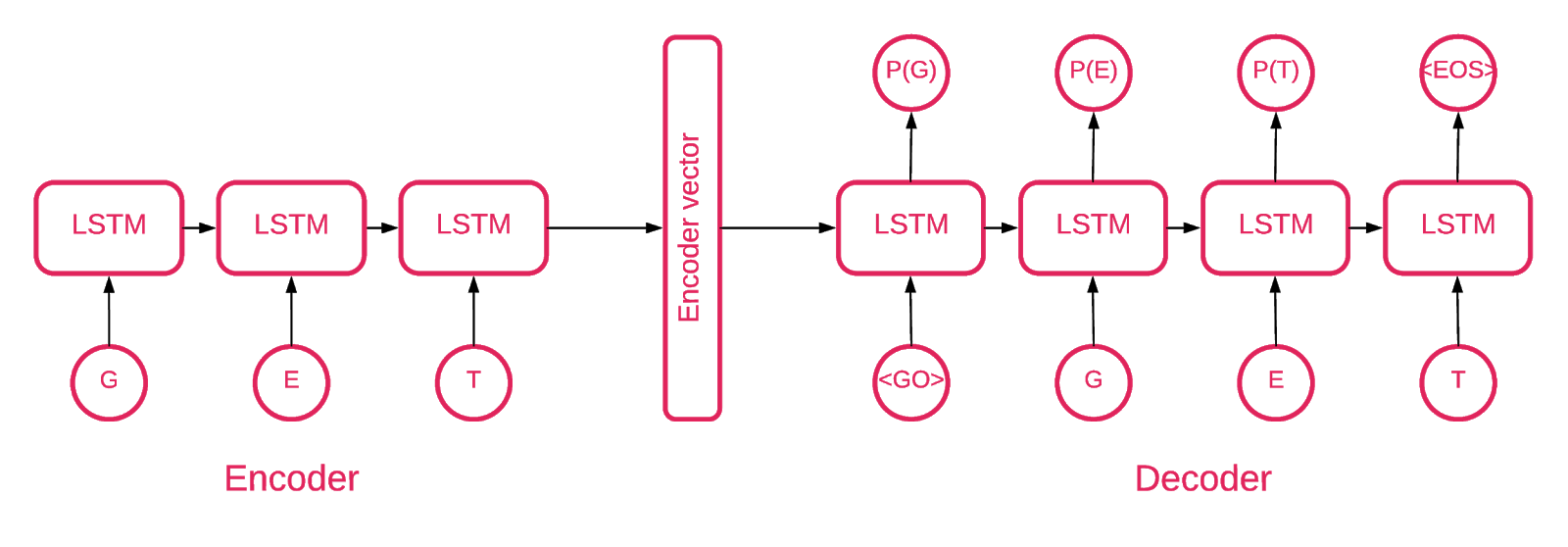
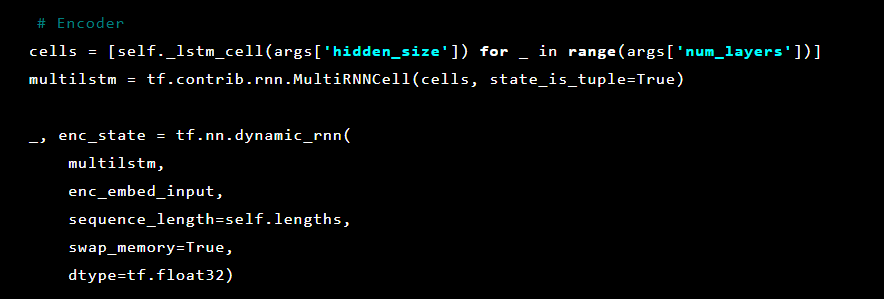
एक सीक्वेंस-टू-सीक्वेंस मॉडल में दो बहुस्तरीय दीर्घकालिक अल्पकालिक मेमोरी (LSTM) मॉडल होते हैं: एक एनकोडर और एक डिकोडर। एनकोडर निश्चित अनुक्रम की वेक्टर के इनपुट अनुक्रम को मैप करता है। डिकोडर एनकोडर के इस आउटपुट का उपयोग करके लक्ष्य वेक्टर को डीकोड करता है।
तो एक ऑटोसेंकोडर एक अनुक्रम-से-अनुक्रम मॉडल है जो अपने इनपुट मूल्यों के बराबर अपने लक्ष्य मान सेट करता है। विचार यह है कि नेटवर्क को चीजों को फिर से बनाने के लिए सिखाना है, या, दूसरे शब्दों में, एक पहचान समारोह के बारे में। यदि प्रशिक्षित ऑटोसेंकोडर को एक अनौपचारिक नमूना दिया जाता है, तो पहले कभी ऐसा नमूना नहीं देखने के कारण उच्च स्तर की त्रुटि के साथ इसे फिर से बनाने की संभावना है।
कोड
हमारा समाधान कई हिस्सों से बना है: मॉडल इनिशियलाइज़ेशन, ट्रेनिंग, प्रेडिक्शन, और वेलिडेशन।
रिपॉजिटरी में स्थित अधिकांश कोड स्व-व्याख्यात्मक है, हम केवल महत्वपूर्ण भागों पर ध्यान केंद्रित करेंगे।
मॉडल को Seq2Seq वर्ग के उदाहरण के रूप में आरंभीकृत किया गया है, जिसमें निम्नलिखित रचनाकार तर्क हैं:
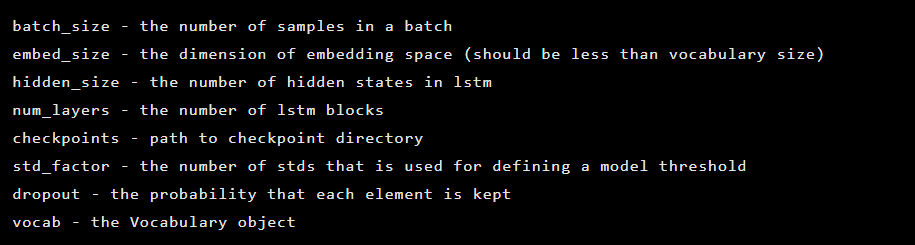
उसके बाद, ऑटोएन्कोडर परतों को आरंभीकृत किया जाता है। सबसे पहले, एनकोडर:
और फिर डिकोडर:
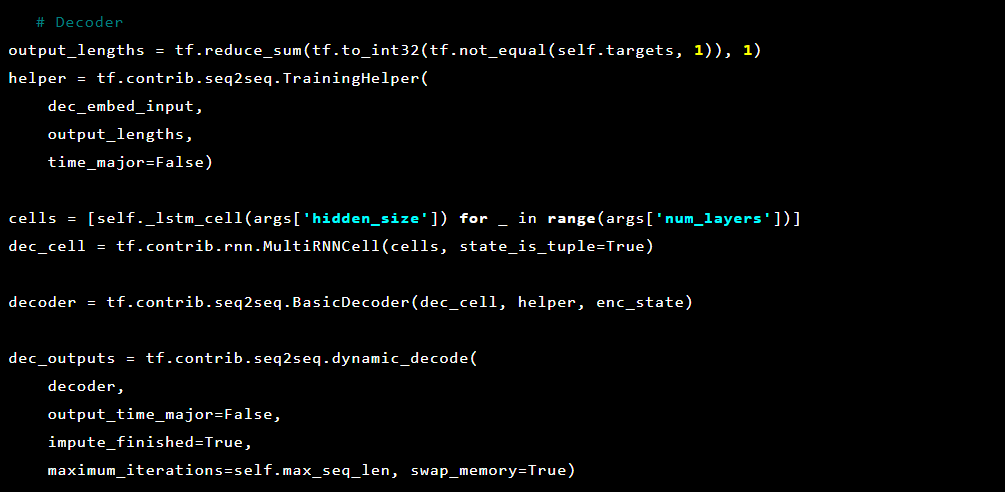
चूंकि हम विसंगति का पता लगाने का प्रयास कर रहे हैं, लक्ष्य और इनपुट समान हैं। इस प्रकार हमारा feed_dict इस प्रकार दिखता है:
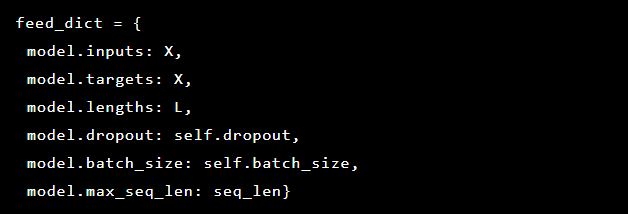
प्रत्येक युग के बाद सर्वश्रेष्ठ मॉडल को एक चेकपॉइंट के रूप में सहेजा जाता है, जिसे बाद में भविष्यवाणियों के लिए लोड किया जा सकता है। परीक्षण के प्रयोजनों के लिए एक लाइव वेब एप्लिकेशन को मॉडल द्वारा स्थापित और संरक्षित किया गया था ताकि परीक्षण करना संभव हो सके कि क्या वास्तविक हमले सफल थे या नहीं।
ध्यान तंत्र से प्रेरित होने के कारण, हमने इसे ऑटोकेनोडर पर लागू करने की कोशिश की लेकिन ध्यान दिया कि अंतिम परत से संभाव्यता आउटपुट अनुरोध के विसंगत भागों को चिह्नित करने में बेहतर काम करता है।

हमारे नमूनों के साथ परीक्षण के चरण में हमें बहुत अच्छे परिणाम मिले: सटीक और याद रखना 0.99 के करीब था। और आरओसी वक्र लगभग 1 था। निश्चित रूप से एक अच्छा दृश्य!
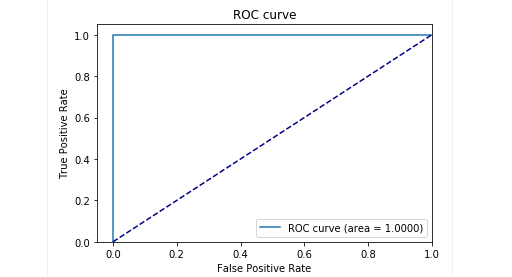
परिणाम
हमारा वर्णित Seq2Seq ऑटोएन्कोडर मॉडल उच्च सटीकता के साथ HTTP अनुरोधों में विसंगतियों का पता लगाने में सक्षम साबित हुआ।
यह मॉडल मानव की तरह कार्य करता है: यह केवल वेब अनुप्रयोग के लिए भेजे गए "सामान्य" उपयोगकर्ता अनुरोधों को सीखता है। यह अनुरोधों में विसंगतियों का पता लगाता है और अनुरोध में सटीक स्थान पर प्रकाश डालता है जिसे विसंगत माना जाता है। हमने परीक्षण आवेदन पर हमलों के खिलाफ इस मॉडल का मूल्यांकन किया और परिणाम आशाजनक दिखाई देते हैं। उदाहरण के लिए, पिछले स्क्रीनशॉट में दर्शाया गया है कि कैसे हमारे मॉडल ने दो वेब फ़ॉर्म मापदंडों में SQL इंजेक्शन विभाजन का पता लगाया। ऐसे SQL इंजेक्शन खंडित हैं, क्योंकि हमले का पेलोड कई HTTP मापदंडों में दिया जाता है। क्लासिक नियम-आधारित WAF खराब खंडित SQL इंजेक्शन प्रयासों का पता लगाने में खराब करते हैं क्योंकि वे आमतौर पर प्रत्येक पैरामीटर का निरीक्षण करते हैं।
मॉडल और ट्रेन / टेस्ट डेटा के कोड को जुपिटर नोटबुक के रूप में जारी किया गया है ताकि कोई भी हमारे परिणामों को पुन: पेश कर सके और सुधार का सुझाव दे सके।
निष्कर्ष
हमारा मानना है कि हमारा काम काफी गैर-तुच्छ था: न्यूनतम प्रयासों के साथ हमलों का पता लगाने का एक तरीका। एक तरफ, हमने समाधान पर ओवरकॉम्प्लिकेटिंग से बचने और हमलों का पता लगाने का एक तरीका बनाने की मांग की, जैसे कि जादू से, खुद से तय करना सीखता है कि क्या अच्छा है और क्या बुरा। उसी समय, हम मानव कारक के साथ समस्याओं से बचना चाहते थे जब (गिरने वाला) विशेषज्ञ यह तय कर रहा है कि हमले का संकेत क्या है और क्या नहीं। और इसलिए कुल मिलाकर Seq2Seq वास्तुकला के साथ ऑटोकेनोडर विसंगतियों का पता लगाने की हमारी समस्या को काफी अच्छी तरह से हल करता है।
हम डेटा व्याख्या की समस्या को भी हल करना चाहते थे। जटिल तंत्रिका नेटवर्क आर्किटेक्चर का उपयोग करते समय, किसी विशेष परिणाम की व्याख्या करना बहुत मुश्किल है। जब परिवर्तनों की एक पूरी श्रृंखला लागू होती है, तो एक निर्णय के पीछे सबसे महत्वपूर्ण डेटा की पहचान करना लगभग असंभव हो जाता है। हालांकि, मॉडल द्वारा डेटा व्याख्या के दृष्टिकोण पर पुनर्विचार करने के बाद, हम अंतिम परत से प्रत्येक चरित्र के लिए संभावनाएं प्राप्त करने में सक्षम थे।
यह ध्यान रखना महत्वपूर्ण है कि यह उत्पादन-तैयार संस्करण नहीं है। हम इस विवरण का खुलासा नहीं कर सकते कि वास्तविक उत्पाद में इस दृष्टिकोण को कैसे लागू किया जा सकता है। लेकिन हम आपको चेतावनी देंगे कि यह काम करना संभव नहीं है और इसे "प्लग इन" करें। हम यह चेतावनी देते हैं क्योंकि GitHub पर प्रकाशित होने के बाद, हमने कुछ उपयोगकर्ताओं को देखना शुरू किया, जिन्होंने असफल (और भद्दा) परिणामों के साथ अपने स्वयं के प्रोजेक्ट में हमारे वर्तमान समाधान थोक को लागू करने का प्रयास किया।
अवधारणा का प्रमाण
यहाँ उपलब्ध
है (github.com)।
लेखक: एलेक्जेंड्रा मुरज़िना (
मुरज़िना_ए ), इरिना स्टेप्यानुक (
गिटहब ), फेडर सखारोव (
गीथहब ), आर्सेनी
रुतोव (
आरजे ०आर )
आगे पढ़ रहे हैं
- LSTM नेटवर्क को समझना
- ध्यान और संवर्धित आवर्तक तंत्रिका नेटवर्क
- ध्यान आप सभी की जरूरत है
- ध्यान आप सभी की जरूरत है (एनोटेट)
- तंत्रिका मशीन अनुवाद (seq2seq) ट्यूटोरियल
- Autoencoders
- तंत्रिका नेटवर्क के साथ अनुक्रम सीखने के अनुक्रम
- केरस में ऑटोकारोडर्स का निर्माण