वेब स्क्रैपिंग के लिए केवल एक दृष्टिकोण जानने से समस्या का अल्पावधि में हल हो जाता है, लेकिन सभी तरीकों में उनकी ताकत और कमजोरियां हैं। इसके प्रति जागरूकता समय की बचत करती है और समस्या को अधिक कुशलता से हल करने में मदद करती है।

कई संसाधन एक वेब पेज से डेटा प्राप्त करने की एकमात्र सही विधि के बारे में बात करते हैं। लेकिन वास्तविकता यह है कि इसके लिए आप कई समाधानों और उपकरणों का उपयोग कर सकते हैं।
- प्रोग्राम को वेब पेज से डेटा पुनर्प्राप्त करने के लिए क्या विकल्प हैं?
- प्रत्येक दृष्टिकोण के पेशेवरों और विपक्षों?
- स्वचालन की डिग्री बढ़ाने के लिए क्लाउड संसाधनों का उपयोग कैसे करें?
लेख इन सवालों के जवाब पाने में मदद करेगा।
मुझे लगता है कि आप पहले से ही जानते हैं कि
HTTP रिक्वेस्ट,
DOM (डॉक्यूमेंट ऑब्जेक्ट मॉडल),
HTML ,
CSS सिलेक्टर्स और
Async जावास्क्रिप्ट क्या हैं ।
यदि नहीं, तो मैं आपको सिद्धांत में तल्लीन करने की सलाह देता हूं, और फिर लेख पर लौटता हूं।
स्थैतिक सामग्री
HTML स्रोतआइए सबसे सरल दृष्टिकोण से शुरू करें।
यदि आप वेब पृष्ठों को स्क्रैप करने की योजना बनाते हैं, तो यह सबसे पहली बात है। इसके लिए कम कंप्यूटर शक्ति और कम से कम समय की आवश्यकता होगी।
हालाँकि, यह केवल तभी काम करता है जब HTML स्रोत कोड में वह डेटा हो जिसे आप लक्षित कर रहे हैं। Chrome में इसका परीक्षण करने के लिए, पृष्ठ पर राइट-क्लिक करें और देखें पृष्ठ कोड का चयन करें। अब आपको HTML स्रोत कोड देखना चाहिए।
एक बार जब आप डेटा पा लेते हैं, तो एक
CSS चयनकर्ता लिखें जो रैपिंग तत्व से संबंधित हो ताकि आपके पास बाद में लिंक हो।
कार्यान्वयन के लिए, आप पृष्ठ के URL पर HTTP GET अनुरोध भेज सकते हैं और HTML स्रोत कोड वापस पा सकते हैं।
नोड में, आप कच्चे HTML को
पार्स करने के लिए
CheerioJS टूल का उपयोग कर सकते हैं और चयनकर्ता का उपयोग करके डेटा पुनः प्राप्त कर सकते हैं। कोड इस तरह दिखेगा:
const fetch = require('node-fetch'); const cheerio = require('cheerio'); const url = 'https://example.com/'; const selector = '.example'; fetch(url) .then(res => res.text()) .then(html => { const $ = cheerio.load(html); const data = $(selector); console.log(data.text()); });
गतिशील सामग्री
कई मामलों में, आप कच्चे HTML कोड से जानकारी तक नहीं पहुँच सकते क्योंकि DOM को पृष्ठभूमि में चल रहे जावास्क्रिप्ट द्वारा नियंत्रित किया गया था। इसका एक विशिष्ट उदाहरण एक एसपीए (एकल-पृष्ठ अनुप्रयोग) है, जहां एक HTML दस्तावेज़ में न्यूनतम जानकारी होती है और जावास्क्रिप्ट इसे रन टाइम पर भरता है।
इस स्थिति में, समाधान डोम बनाने और HTML स्रोत कोड में स्थित लिपियों को निष्पादित करने के लिए है, जैसा कि ब्राउज़र करता है। उसके बाद, चयनकर्ताओं का उपयोग करके इस ऑब्जेक्ट से डेटा निकाला जा सकता है।
हेडलेस ब्राउजरहेडलेस ब्राउजर सामान्य ब्राउजर की तरह ही होता है, केवल यूजर इंटरफेस के बिना। यह पृष्ठभूमि में चलता है, और आप कीबोर्ड से क्लिक करने और टाइप करने के बजाय इसे प्रोग्रामेटिक रूप से नियंत्रित कर सकते हैं।
Puppeteer सबसे लोकप्रिय हेडलेस ब्राउज़र में से एक है। यह एक आसानी से उपयोग होने वाला नोड पुस्तकालय है जो क्रोम ऑफ़लाइन प्रबंधन के लिए एक उच्च-स्तरीय एपीआई प्रदान करता है। इसे हेडर के बिना चलाने के लिए कॉन्फ़िगर किया जा सकता है, जो विकास के दौरान बहुत सुविधाजनक है। निम्नलिखित कोड पहले की तरह ही काम करता है, लेकिन यह गतिशील पृष्ठों के साथ काम करेगा:
const puppeteer = require('puppeteer'); async function getData(url, selector){ const browser = await puppeteer.launch(); const page = await browser.newPage(); await page.goto(url); const data = await page.evaluate(selector => { return document.querySelector(selector).innerText; }, selector); await browser.close(); return data; } const url = 'https://example.com'; const selector = '.example'; getData(url,selector) .then(result => console.log(result));
बेशक, आप Puppeteer के साथ अधिक दिलचस्प चीजें कर सकते हैं, इसलिए
दस्तावेज़ीकरण देखें । यहां कोड का एक स्निपेट है जो URL को नेविगेट करता है, एक स्क्रीनशॉट लेता है और उसे बचाता है:
const puppeteer = require('puppeteer'); async function takeScreenshot(url,path){ const browser = await puppeteer.launch(); const page = await browser.newPage(); await page.goto(url); await page.screenshot({path: path}); await browser.close(); } const url = 'https://example.com'; const path = 'example.png'; takeScreenshot(url, path);
ब्राउज़र को एक साधारण GET अनुरोध भेजने और प्रतिक्रिया का विश्लेषण करने की तुलना में बहुत अधिक कंप्यूटिंग शक्ति की आवश्यकता होती है। इसलिए, निष्पादन अपेक्षाकृत धीमा है। इतना ही नहीं, बल्कि एक निर्भरता के रूप में एक ब्राउज़र को जोड़ना पैकेज को बड़े पैमाने पर बनाता है।
दूसरी ओर, यह विधि बहुत लचीली है। आप इसका उपयोग पृष्ठों को नेविगेट करने, क्लिक, माउस आंदोलनों का अनुकरण करने और कीबोर्ड का उपयोग करने, फ़ॉर्म भरने, स्क्रीनशॉट बनाने या पीडीएफ पृष्ठ बनाने, कंसोल में कमांड निष्पादित करने, पाठ सामग्री निकालने के लिए आइटम का चयन करने के लिए कर सकते हैं। मूल रूप से, सब कुछ जो एक ब्राउज़र में मैन्युअल रूप से किया जा सकता है।
एक डोम का निर्माणआप सोचेंगे कि एक डोम बनाने के लिए पूरे ब्राउज़र को अनुकरण करना अनावश्यक है। वास्तव में, यह सच है, कम से कम कुछ परिस्थितियों में।
Jsdom एक नोड लाइब्रेरी है जो HTML को संचारित करती है, जैसे ब्राउज़र करता है। हालाँकि, यह एक ब्राउज़र नहीं है, बल्कि किसी
दिए गए HTML स्रोत कोड से DOM बनाने का उपकरण है , साथ ही इस HTML में जावास्क्रिप्ट कोड को निष्पादित करने के लिए भी है।
इस अमूर्तता के लिए धन्यवाद, जेस्डम हेडलेस ब्राउजर की तुलना में तेजी से चल सकता है। यदि यह तेज़ है, तो हर समय हेडलेस ब्राउज़र के बजाय इसका उपयोग क्यों न करें?
प्रलेखन से उद्धरण :
Jsdom का उपयोग करते समय लोगों को अक्सर अतुल्यकालिक रूप से स्क्रिप्ट लोड करने में समस्या होती है। कई पृष्ठ स्क्रिप्ट को अतुल्यकालिक रूप से लोड करते हैं, लेकिन यह निर्धारित करना असंभव है कि यह कब हुआ, और इसलिए कोड को चलाने के लिए और परिणामी DOM संरचना की जांच करने के लिए। यह एक मौलिक सीमा है।
यह समाधान उदाहरण में दिखाया गया है। प्रत्येक 100 एमएस, यह जांचा जाता है कि क्या कोई तत्व दिखाई दिया है या एक टाइमआउट हुआ है (2 सेकंड के बाद)।
यह अक्सर त्रुटि संदेश भी देता है जब Jsdom पृष्ठ पर कुछ ब्राउज़र सुविधाओं को लागू नहीं करता है, जैसे: "
त्रुटि: लागू नहीं: window.alert ..." या "त्रुटि: लागू नहीं: window.scrollTo ... "। यह समस्या कुछ वर्कअराउंड (
वर्चुअल कंसोल ) के साथ भी हल की जा सकती है।
यह आमतौर पर Puppeteer की तुलना में एक निम्न स्तर का एपीआई है, इसलिए आपको कुछ चीजों को स्वयं लागू करने की आवश्यकता है।
यह उपयोग को थोड़ा जटिल करता है, जैसा कि उदाहरण से देखा जा सकता है।
Jsdom उसी नौकरी के लिए एक त्वरित समाधान प्रदान करता है।
आइए एक ही उदाहरण देखें, लेकिन
Jsdom का उपयोग करते
हुए :
const jsdom = require("jsdom"); const { JSDOM } = jsdom; async function getData(url,selector,timeout) { const virtualConsole = new jsdom.VirtualConsole(); virtualConsole.sendTo(console, { omitJSDOMErrors: true }); const dom = await JSDOM.fromURL(url, { runScripts: "dangerously", resources: "usable", virtualConsole }); const data = await new Promise((res,rej)=>{ const started = Date.now(); const timer = setInterval(() => { const element = dom.window.document.querySelector(selector) if (element) { res(element.textContent); clearInterval(timer); } else if(Date.now()-started > timeout){ rej("Timed out"); clearInterval(timer); } }, 100); }); dom.window.close(); return data; } const url = "https://example.com/"; const selector = ".example"; getData(url,selector,2000).then(result => console.log(result));
रिवर्स इंजीनियरिंगJsdom एक त्वरित और आसान उपाय है, लेकिन आप इसे और भी सरल बना सकते हैं।
क्या हमें DOM मॉडल करने की आवश्यकता है?
जिस वेब पेज को आप स्क्रैप करना चाहते हैं, उसमें वही HTML और जावास्क्रिप्ट शामिल हैं, वही तकनीकें जो आप पहले से जानते हैं। इस प्रकार,
यदि आपको एक कोड मिलता है जिसमें से लक्ष्य डेटा प्राप्त किया गया था, तो आप उसी परिणाम को प्राप्त करने के लिए उसी ऑपरेशन को दोहरा सकते हैं ।
चीजों को सरल बनाने के लिए, आपके द्वारा खोजा जा रहा डेटा:
- HTML स्रोत कोड का हिस्सा (जैसा कि लेख के पहले भाग से देखा जा सकता है),
- HTML दस्तावेज़ में संदर्भित स्थिर फ़ाइल का एक भाग (उदाहरण के लिए, जावास्क्रिप्ट फ़ाइल में एक पंक्ति),
- नेटवर्क अनुरोध के जवाब में (उदाहरण के लिए, कुछ जावास्क्रिप्ट कोड ने एक AJAX अनुरोध एक सर्वर पर भेजा है जो JSON स्ट्रिंग के साथ प्रतिक्रिया करता है)।
ये डेटा स्रोत नेटवर्क प्रश्नों का उपयोग करके पहुँचा जा सकता है । इससे कोई फर्क नहीं पड़ता कि वेबपेज HTTP, WebSockets या किसी अन्य संचार प्रोटोकॉल का उपयोग करता है, क्योंकि वे सभी सिद्धांत रूप में प्रतिलिपि प्रस्तुत करने योग्य हैं।
एक बार जब आपको डेटा युक्त संसाधन मिल जाता है, तो आप मूल पृष्ठ के समान सर्वर के लिए एक समान नेटवर्क अनुरोध भेज सकते हैं। नतीजतन, आपको एक लक्ष्य मिलेगा जिसमें लक्ष्य डेटा होगा, जिसे नियमित अभिव्यक्ति, स्ट्रिंग विधियों, JSON.parent, आदि का उपयोग करके आसानी से निकाला जा सकता है।
सरल शब्दों में, आप उस संसाधन को ले सकते हैं जिस पर डेटा स्थित है, सभी सामग्री को संसाधित और लोड करने के बजाय। इस प्रकार, पिछले उदाहरणों में दिखाई गई समस्या को एक ब्राउज़र या जटिल जावास्क्रिप्ट ऑब्जेक्ट को नियंत्रित करने के बजाय एकल HTTP अनुरोध के साथ हल किया जा सकता है।
यह समाधान सिद्धांत रूप में सरल लगता है, लेकिन ज्यादातर मामलों में यह समय लेने वाला हो सकता है और इसके लिए वेब पेज और सर्वर के साथ अनुभव की आवश्यकता होती है।
नेटवर्क ट्रैफिक की निगरानी से शुरू करें। इसके लिए एक बढ़िया टूल
Chrome DevTools में नेटवर्क टैब
है । आप सभी निवर्तमान अनुरोधों को उत्तर के साथ देखेंगे (स्थैतिक फ़ाइलों, AJAX अनुरोधों सहित), उनके माध्यम से पुनरावृति करने और डेटा की खोज करने के लिए।
यदि स्क्रीन पर प्रदर्शित होने से पहले किसी भी कोड द्वारा उत्तर को बदल दिया जाता है, तो प्रक्रिया धीमी हो जाएगी। इस स्थिति में, आपको कोड का यह हिस्सा ढूंढना होगा और समझना होगा कि क्या चल रहा है।
जैसा कि आप देख सकते हैं, इस तरह की विधि को ऊपर वर्णित विधियों की तुलना में बहुत अधिक काम की आवश्यकता हो सकती है। दूसरी ओर, यह सर्वश्रेष्ठ प्रदर्शन प्रदान करता है।
चित्र Jsdom और Puppeteer की तुलना में आवश्यक रनटाइम और पैकेट आकार दिखाता है:
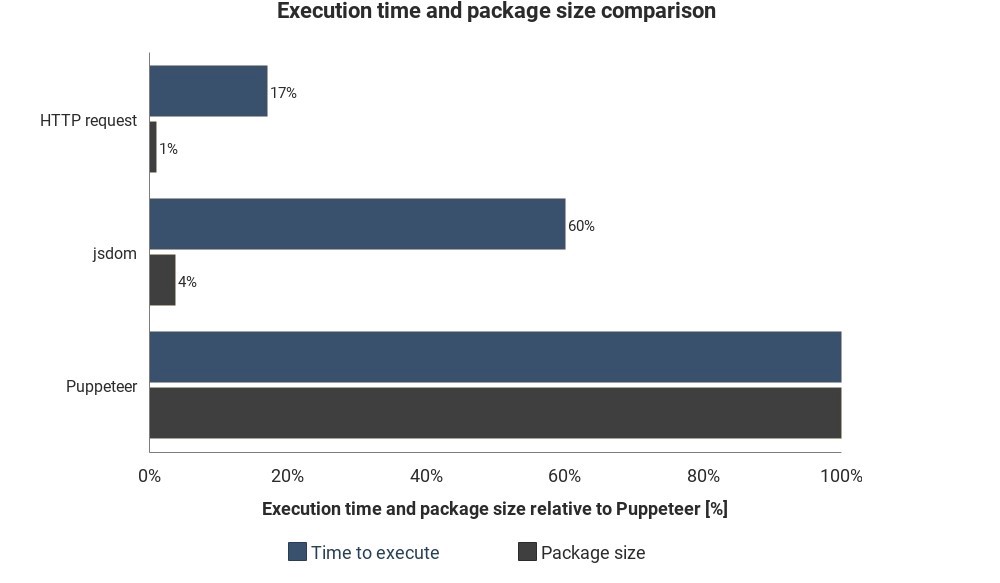
परिणाम सटीक माप पर आधारित नहीं हैं और भिन्न हो सकते हैं, लेकिन इन तरीकों के बीच अच्छा अनुमानित अंतर दिखाते हैं।
क्लाउड सेवा एकीकरण
मान लीजिए आपने इनमें से एक समाधान लागू किया है। स्क्रिप्ट को निष्पादित करने का एक तरीका कंप्यूटर चालू करना, टर्मिनल खोलना और इसे मैन्युअल रूप से शुरू करना है।
लेकिन यह कष्टप्रद और अक्षम हो जाएगा, इसलिए यह बेहतर होगा कि आप स्क्रिप्ट को सर्वर पर अपलोड कर सकते हैं और यह सेटिंग्स के आधार पर नियमित रूप से कोड निष्पादित करेगा।
यह स्क्रिप्ट को निष्पादित करने के लिए वास्तविक सर्वर शुरू करने और नियमों को सेट करके किया जा सकता है। अन्य मामलों में, क्लाउड फ़ंक्शन एक आसान तरीका है।
जब कोई घटना होती है तो क्लाउड फ़ंक्शंस डाउनलोड किए गए कोड को निष्पादित करने के लिए डिज़ाइन किए गए स्टोरेज होते हैं। इसका मतलब है कि आपको सर्वर को प्रबंधित करने की आवश्यकता नहीं है, यह स्वचालित रूप से आपके क्लाउड प्रदाता द्वारा किया जाता है।
ट्रिगर एक शेड्यूल, एक नेटवर्क अनुरोध और कई अन्य घटनाएं हो सकती हैं। आप एकत्रित डेटा को डेटाबेस में सहेज सकते हैं, इसे
Google शीट पर लिख सकते हैं या इसे
ई-मेल से भेज सकते हैं । यह सब आपकी कल्पना पर निर्भर करता है।
लोकप्रिय क्लाउड प्रदाता -
अमेज़न वेब सर्विसेज (AWS),
Google क्लाउड प्लेटफ़ॉर्म (GCP) और
Microsoft Azure :
आप इन सेवाओं का उपयोग मुफ्त में कर सकते हैं, लेकिन लंबे समय तक नहीं।
यदि आप Puppeteer का उपयोग करते हैं, तो
Google क्लाउड
सुविधाएं सबसे आसान समाधान हैं। हेडलेस क्रोम प्रारूप (~ 130 एमबी) में पैकेज का आकार एडब्ल्यूएस लैंबडा (50 एमबी) में अधिकतम स्वीकार्य संग्रह आकार से अधिक है। लैंबडा के साथ काम करने के लिए कई तरीके हैं, लेकिन डिफ़ॉल्ट रूप से
क्रोम के बिना डिफ़ॉल्ट
समर्थन द्वारा GCP फ़ंक्शन, आपको केवल Puppeteer को
package.json पर निर्भरता के रूप में शामिल करने की आवश्यकता है।
यदि आप सामान्य रूप से क्लाउड सुविधाओं के बारे में अधिक जानना चाहते हैं, तो सर्वर-कम आर्किटेक्चर की जानकारी देखें। इस विषय पर कई अच्छे ट्यूटोरियल पहले ही लिखे जा चुके हैं और अधिकांश प्रदाताओं के पास आसानी से समझ में आने वाले दस्तावेज़ हैं।