
नमस्कार, हेब्र!
कागले में अंतिम गिरावट, हाथ से तैयार क्विक ड्रॉ डूडल रिकॉग्निशन चित्रों के वर्गीकरण के लिए एक प्रतियोगिता आयोजित की गई थी, जिसमें अन्य लोगों के अलावा आर-स्किक्स की एक टीम जिसमें
आर्टेम क्लेवत्सोव ,
फिलिप उप्रेविलेव और
एंड्रे ओगुरत्सोव शामिल थे। हम प्रतियोगिता का विस्तार से वर्णन नहीं करेंगे, यह पहले ही एक
हालिया प्रकाशन में हो चुका है।
इस बार फार्म फार्मास्यूटिकल्स के साथ कोई पदक नहीं थे, लेकिन बहुत मूल्यवान अनुभव प्राप्त किया गया था, इसलिए मैं कागेल पर और रोजमर्रा के काम में सबसे दिलचस्प और उपयोगी चीजों के बारे में समुदाय को बताना चाहूंगा। कवर किए गए विषयों में:
OpenCV के बिना कठिन जीवन, JSONs के पार्सिंग (ये उदाहरण
Rcpp का उपयोग करके R में लिपियों या पैकेजों में C ++ कोड
के एकीकरण को
दर्शाते हैं ), स्क्रिप्ट के मानकीकरण और अंतिम समाधान का डॉक्यूमेंटेशन। लॉन्च के लिए उपयुक्त फॉर्म में संदेश से सभी कोड
रिपॉजिटरी में उपलब्ध
है ।
सामग्री:
- CSV से MonetDB डेटाबेस में प्रभावी डेटा लोड हो रहा है
- बैचों की तैयारी
- डेटाबेस से बैचों को उतारने के लिए Iterators
- मॉडल वास्तुकला चयन
- स्क्रिप्ट पैरामीटर
- डॉकिंग स्क्रिप्ट
- Google क्लाउड में कई GPU का उपयोग करना
- एक निष्कर्ष के बजाय
1. CSV से MonetDB डेटाबेस में प्रभावी डेटा लोडिंग
इस प्रतियोगिता में डेटा तैयार चित्रों के रूप में प्रदान नहीं किया गया है, लेकिन बिंदु निर्देशांक के साथ JSON युक्त 340 CSV फ़ाइलों (प्रत्येक वर्ग के लिए एक फ़ाइल) के रूप में। इन बिंदुओं को लाइनों के साथ जोड़कर, हमें अंतिम छवि 256x256 पिक्सेल के आकार के साथ मिलती है। इसके अलावा, प्रत्येक रिकॉर्ड के लिए, एक लेबल दिया जाता है, जहां डेटा उस समय सही तरीके से पहचाना जाता था, जिस समय डेटासेट एकत्र किया जाता था, लेखक के निवास स्थान के दो-अक्षर कोड, एक विशिष्ट पहचानकर्ता, समय टिकट और क्लास का नाम जो फ़ाइल नाम से मेल खाता हो। स्रोत डेटा के एक सरलीकृत संस्करण का वजन संग्रह में 7.4 जीबी और अनपैकिंग के बाद लगभग 20 जीबी है, अनपैकिंग के बाद का पूरा डेटा 240 जीबी लगता है। आयोजकों ने गारंटी दी कि दोनों संस्करण एक ही चित्र को पुन: पेश करते हैं, यानी पूर्ण संस्करण निरर्थक है। किसी भी मामले में, ग्राफिक फ़ाइलों या सरणियों में 50 मिलियन छवियों को संग्रहीत करना तुरंत लाभहीन माना जाता था, और हमने एक डेटाबेस में train_simplified.zip संग्रह से डेटाबेस में प्रत्येक बैच के लिए सही आकार की छवियों की अगली पीढ़ी के साथ विलय करने का निर्णय लिया। ।
अच्छी तरह से स्थापित MonetDB को DBMS के रूप में चुना गया था, अर्थात्, MonetDBLite पैकेज के रूप में R के लिए कार्यान्वयन। पैकेज में डेटाबेस सर्वर का एक एम्बेडेड संस्करण शामिल है और आपको आर-सत्र से सीधे सर्वर को उठाने और इसके साथ काम करने की अनुमति देता है। डेटाबेस बनाना और इसे कनेक्ट करना एक कमांड द्वारा किया जाता है:
con <- DBI::dbConnect(drv = MonetDBLite::MonetDBLite(), Sys.getenv("DBDIR"))
हमें दो तालिकाओं को बनाने की आवश्यकता होगी: सभी डेटा के लिए एक, डाउनलोड की गई फ़ाइलों के बारे में ओवरहेड जानकारी के लिए अन्य (उपयोगी अगर कुछ गलत हो जाता है और प्रक्रिया को कई फ़ाइलों को लोड करने के बाद फिर से शुरू करना होगा):
टेबल बनाएं if (!DBI::dbExistsTable(con, "doodles")) { DBI::dbCreateTable( con = con, name = "doodles", fields = c( "countrycode" = "char(2)", "drawing" = "text", "key_id" = "bigint", "recognized" = "bool", "timestamp" = "timestamp", "word" = "text" ) ) } if (!DBI::dbExistsTable(con, "upload_log")) { DBI::dbCreateTable( con = con, name = "upload_log", fields = c( "id" = "serial", "file_name" = "text UNIQUE", "uploaded" = "bool DEFAULT false" ) ) }
डेटाबेस में डेटा लोड करने का सबसे तेज़ तरीका SQL का उपयोग करते हुए CSV फ़ाइलों को सीधे कॉपी करना था - कमांड COPY OFFSET 2 INTO tablename FROM path USING DELIMITERS ',','\\n','\"' NULL AS '' BEST EFFORT , जहाँ tablename है तालिका का नाम और path फ़ाइल का पथ है। बाद में , गति बढ़ाने का एक और तरीका खोजा गया था : बस BEST EFFORT को LOCKED BEST EFFORT प्रतिस्थापित करें। संग्रह के साथ काम करते समय, यह पता चला कि R में अंतर्निहित unzip कार्यान्वयन unzip से कई फ़ाइलों के साथ सही ढंग से काम नहीं करता है, इसलिए हमने इसका उपयोग किया। सिस्टम unzip ( getOption("unzip") पैरामीटर का उपयोग करके)।
डेटाबेस के लिए लिखने का कार्य #' @title #' #' @description #' CSV- ZIP- #' #' @param con ( `MonetDBEmbeddedConnection`). #' @param tablename . #' @oaram zipfile ZIP-. #' @oaram filename ZIP-. #' @param preprocess , . #' `data` ( `data.table`). #' #' @return `TRUE`. #' upload_file <- function(con, tablename, zipfile, filename, preprocess = NULL) { # checkmate::assert_class(con, "MonetDBEmbeddedConnection") checkmate::assert_string(tablename) checkmate::assert_string(filename) checkmate::assert_true(DBI::dbExistsTable(con, tablename)) checkmate::assert_file_exists(zipfile, access = "r", extension = "zip") checkmate::assert_function(preprocess, args = c("data"), null.ok = TRUE) # path <- file.path(tempdir(), filename) unzip(zipfile, files = filename, exdir = tempdir(), junkpaths = TRUE, unzip = getOption("unzip")) on.exit(unlink(file.path(path))) # if (!is.null(preprocess)) { .data <- data.table::fread(file = path) .data <- preprocess(data = .data) data.table::fwrite(x = .data, file = path, append = FALSE) rm(.data) } # CSV sql <- sprintf( "COPY OFFSET 2 INTO %s FROM '%s' USING DELIMITERS ',','\\n','\"' NULL AS '' BEST EFFORT", tablename, path ) # DBI::dbExecute(con, sql) # DBI::dbExecute(con, sprintf("INSERT INTO upload_log(file_name, uploaded) VALUES('%s', true)", filename)) return(invisible(TRUE)) }
यदि आपको डेटाबेस में लिखने से पहले तालिका को बदलने की आवश्यकता है, तो यह फ़ंक्शन को पास करने के लिए पर्याप्त है जो डेटा को preprocess तर्क में बदल देगा।
डेटाबेस में डेटा के अनुक्रमिक लोडिंग के लिए कोड:
डेटाबेस में डेटा लिखना # files <- unzip(zipfile, list = TRUE)$Name # , to_skip <- DBI::dbGetQuery(con, "SELECT file_name FROM upload_log")[[1L]] files <- setdiff(files, to_skip) if (length(files) > 0L) { # tictoc::tic() # pb <- txtProgressBar(min = 0L, max = length(files), style = 3) for (i in seq_along(files)) { upload_file(con = con, tablename = "doodles", zipfile = zipfile, filename = files[i]) setTxtProgressBar(pb, i) } close(pb) # tictoc::toc() } # 526.141 sec elapsed - SSD->SSD # 558.879 sec elapsed - USB->SSD
उपयोग किए गए ड्राइव की गति विशेषताओं के आधार पर डेटा लोडिंग समय भिन्न हो सकता है। हमारे मामले में, एक ही SSD के भीतर या SSD (डेटाबेस) में USB फ्लैश ड्राइव (स्रोत फ़ाइल) से पढ़ना और लिखना 10 मिनट से कम समय लेता है।
एक पूर्णांक वर्ग लेबल के साथ एक कॉलम बनाने के लिए कुछ और सेकंड लगते हैं और एक इंडेक्स कॉलम ( ORDERED INDEX ) लाइन नंबरों के साथ होता है, जिसका उपयोग बैच बनाते समय मामलों का चयन करने के लिए किया जाएगा:
अतिरिक्त कॉलम और इंडेक्स बनाएं message("Generate lables") invisible(DBI::dbExecute(con, "ALTER TABLE doodles ADD label_int int")) invisible(DBI::dbExecute(con, "UPDATE doodles SET label_int = dense_rank() OVER (ORDER BY word) - 1")) message("Generate row numbers") invisible(DBI::dbExecute(con, "ALTER TABLE doodles ADD id serial")) invisible(DBI::dbExecute(con, "CREATE ORDERED INDEX doodles_id_ord_idx ON doodles(id)"))
"मक्खी पर" एक बैच बनाने की समस्या को हल करने के लिए हमें doodles तालिका से यादृच्छिक तारों को निकालने की अधिकतम गति प्राप्त करने की आवश्यकता थी। इसके लिए हमने 3 ट्रिक का इस्तेमाल किया। पहला यह था कि जिस प्रकार का अवलोकन आईडी संग्रहीत है, उसके आयाम को कम करना। मूल डेटा सेट में, आईडी स्टोर करने के लिए bigint प्रकार की आवश्यकता होती है, लेकिन टिप्पणियों की संख्या सीरियल नंबर के बराबर अपने पहचानकर्ताओं को bigint प्रकार में फिट करने की अनुमति देती है। खोज बहुत तेज है। दूसरी चाल ORDERED INDEX का उपयोग करना था - यह निर्णय सभी उपलब्ध विकल्पों के माध्यम से क्रमिक रूप से किया गया था। तीसरा पैरामीटर प्रश्नों का उपयोग करना था। विधि का सार एक बार PREPARE कमांड को निष्पादित करना है और फिर एक ही प्रकार के प्रश्नों का ढेर बनाते समय तैयार की गई अभिव्यक्ति का उपयोग करना है, लेकिन वास्तव में साधारण SELECT की तुलना में लाभ सांख्यिकीय त्रुटि के क्षेत्र में है।
डेटा भरने की प्रक्रिया 450 एमबी से अधिक रैम की खपत नहीं करती है। यही है, वर्णित दृष्टिकोण आपको कुछ सिंगल-बोर्ड कंप्यूटरों सहित लगभग किसी भी बजट हार्डवेयर पर दसियों गीगाबाइट वजन वाले डेटासेट को घुमाने की अनुमति देता है, जो कि बहुत अच्छा है।
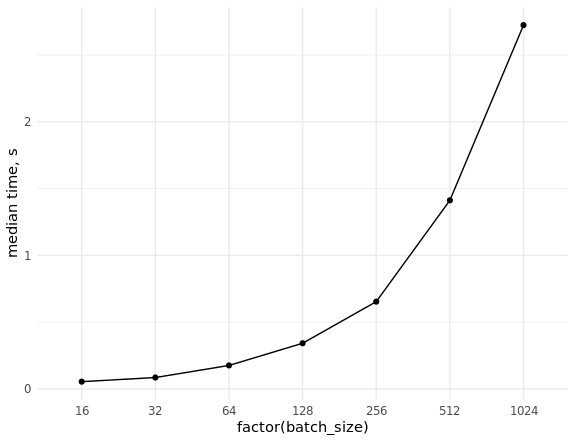
यह विभिन्न आकारों के बैचों का नमूना लेते समय (यादृच्छिक) डेटा के निष्कर्षण की दर का मापन करने और स्केलिंग का मूल्यांकन करने के लिए रहता है:
बेंचमार्क डेटाबेस library(ggplot2) set.seed(0) # con <- DBI::dbConnect(MonetDBLite::MonetDBLite(), Sys.getenv("DBDIR")) # prep_sql <- function(batch_size) { sql <- sprintf("PREPARE SELECT id FROM doodles WHERE id IN (%s)", paste(rep("?", batch_size), collapse = ",")) res <- DBI::dbSendQuery(con, sql) return(res) } # fetch_data <- function(rs, batch_size) { ids <- sample(seq_len(n), batch_size) res <- DBI::dbFetch(DBI::dbBind(rs, as.list(ids))) return(res) } # res_bench <- bench::press( batch_size = 2^(4:10), { rs <- prep_sql(batch_size) bench::mark( fetch_data(rs, batch_size), min_iterations = 50L ) } ) # cols <- c("batch_size", "min", "median", "max", "itr/sec", "total_time", "n_itr") res_bench[, cols] # batch_size min median max `itr/sec` total_time n_itr # <dbl> <bch:tm> <bch:tm> <bch:tm> <dbl> <bch:tm> <int> # 1 16 23.6ms 54.02ms 93.43ms 18.8 2.6s 49 # 2 32 38ms 84.83ms 151.55ms 11.4 4.29s 49 # 3 64 63.3ms 175.54ms 248.94ms 5.85 8.54s 50 # 4 128 83.2ms 341.52ms 496.24ms 3.00 16.69s 50 # 5 256 232.8ms 653.21ms 847.44ms 1.58 31.66s 50 # 6 512 784.6ms 1.41s 1.98s 0.740 1.1m 49 # 7 1024 681.7ms 2.72s 4.06s 0.377 2.16m 49 ggplot(res_bench, aes(x = factor(batch_size), y = median, group = 1)) + geom_point() + geom_line() + ylab("median time, s") + theme_minimal() DBI::dbDisconnect(con, shutdown = TRUE)
2. बैचों की तैयारी
बैच तैयार करने की पूरी प्रक्रिया में निम्नलिखित चरण होते हैं:
- बिंदु निर्देशांक के साथ लाइन वैक्टर वाले कई JSONs को पार्स करना।
- वांछित आकार (उदाहरण के लिए, 256x256 या 128x128) की छवि में बिंदुओं के निर्देशांक द्वारा रंगीन रेखाएं खींचना।
- परिणामी छवियों को एक टेंसर में बदलें।
पायथन में गिरी के बीच प्रतियोगिता के ढांचे में, मुख्य रूप से ओपनसीवी के माध्यम से समस्या का समाधान किया गया था। आर पर सबसे सरल और सबसे स्पष्ट एनालॉग्स में से एक इस तरह दिखेगा:
R पर दसवें रूपांतरण के लिए JSON लागू करें r_process_json_str <- function(json, line.width = 3, color = TRUE, scale = 1) { # JSON coords <- jsonlite::fromJSON(json, simplifyMatrix = FALSE) tmp <- tempfile() # on.exit(unlink(tmp)) png(filename = tmp, width = 256 * scale, height = 256 * scale, pointsize = 1) # plot.new() # plot.window(xlim = c(256 * scale, 0), ylim = c(256 * scale, 0)) # cols <- if (color) rainbow(length(coords)) else "#000000" for (i in seq_along(coords)) { lines(x = coords[[i]][[1]] * scale, y = coords[[i]][[2]] * scale, col = cols[i], lwd = line.width) } dev.off() # 3- res <- png::readPNG(tmp) return(res) } r_process_json_vector <- function(x, ...) { res <- lapply(x, r_process_json_str, ...) # 3- 4- res <- do.call(abind::abind, c(res, along = 0)) return(res) }
आरेखण मानक आर टूल्स का उपयोग करके किया जाता है और रैम में संग्रहीत एक अस्थायी पीएनजी में सहेजा जाता है (लिनक्स पर, अस्थायी आर निर्देशिका रैम में घुड़सवार /tmp में स्थित हैं)। फिर इस फ़ाइल को 0 से 1 तक की संख्या के साथ तीन-आयामी सरणी के रूप में पढ़ा जाता है। यह महत्वपूर्ण है क्योंकि अधिक आम बीएमपी को हेक्स रंग कोड के साथ कच्चे सरणी में पढ़ा जाएगा।
परिणाम का परीक्षण करें:
zip_file <- file.path("data", "train_simplified.zip") csv_file <- "cat.csv" unzip(zip_file, files = csv_file, exdir = tempdir(), junkpaths = TRUE, unzip = getOption("unzip")) tmp_data <- data.table::fread(file.path(tempdir(), csv_file), sep = ",", select = "drawing", nrows = 10000) arr <- r_process_json_str(tmp_data[4, drawing]) dim(arr) # [1] 256 256 3 plot(magick::image_read(arr))

इस प्रकार ही बैच का गठन किया जाएगा:
res <- r_process_json_vector(tmp_data[1:4, drawing], scale = 0.5) str(res) # num [1:4, 1:128, 1:128, 1:3] 1 1 1 1 1 1 1 1 1 1 ... # - attr(*, "dimnames")=List of 4 # ..$ : NULL # ..$ : NULL # ..$ : NULL # ..$ : NULL
यह कार्यान्वयन हमारे लिए इष्टतम नहीं था, क्योंकि बड़े बैचों के गठन में अनिश्चित रूप से बहुत समय लगता है, और हमने शक्तिशाली ओपनसीवी लाइब्रेरी का उपयोग करके अपने सहयोगियों के अनुभव का उपयोग करने का निर्णय लिया। उस समय, आर के लिए कोई तैयार पैकेज नहीं था (अब भी कोई नहीं है), इसलिए सी ++ में आवश्यक कार्यक्षमता का न्यूनतम कार्यान्वयन आरसीपी का उपयोग करके आर कोड में एकीकरण के साथ लिखा गया था।
समस्या को हल करने के लिए, निम्नलिखित पैकेज और लाइब्रेरी का उपयोग किया गया था:
- इमेजिंग और लाइन ड्राइंग के लिए OpenCV । हमने पूर्व-स्थापित सिस्टम लाइब्रेरी और हेडर फाइल, साथ ही डायनामिक लिंकिंग का उपयोग किया।
- बहुआयामी सरणियों और टेंसरों के साथ काम करने के लिए xtensor । हमने उसी नाम के आर-पैकेज में शामिल हेडर फ़ाइलों का उपयोग किया है। पुस्तकालय आपको बहु-आयामी सरणियों के साथ काम करने की अनुमति देता है, दोनों पंक्ति प्रमुख और स्तंभ प्रमुख क्रम में।
- JSON को पार्स करने के लिए ndjson । जब यह प्रोजेक्ट में उपलब्ध होता है तो यह लाइब्रेरी अपने आप xtensor में उपयोग की जाती है।
- JSON से एक वेक्टर के बहु-थ्रेडेड प्रसंस्करण के आयोजन के लिए RcppThread । इस पैकेज द्वारा दी गई हेडर फ़ाइलों का उपयोग किया। पैकेज अपने अंतर्निर्मित व्यवस्थापन तंत्र द्वारा अन्य चीजों के बीच अधिक लोकप्रिय RcppParallel से अलग है।
यह ध्यान देने योग्य है कि xtensor केवल एक खोज निकला: व्यापक कार्यक्षमता और उच्च प्रदर्शन करने के अलावा, इसके डेवलपर्स काफी संवेदनशील और त्वरित रूप से निकले और विस्तार से पूछे गए सवालों के जवाब दिए। उनकी मदद से, OpenCV मैट्रिसेस को xtensor टेनर्स में बदलना संभव है, साथ ही 3-आयामी छवि टेंसरों को सही आयाम के 4-आयामी टेंसर (वास्तव में बैच) में संयोजित करने की एक विधि है।
Rcpp, xtensor और RcppThread के लिए अध्ययन सामग्री सिस्टम फ़ाइलों और डायनेमिक लिंकिंग सिस्टम में स्थापित लाइब्रेरियों का उपयोग करके फाइल संकलित करने के लिए, हमने प्लग-इन मेकेनिज्म का उपयोग Rpppp पैकेज में लागू किया। स्वचालित रूप से पथ और झंडे खोजने के लिए, हमने लोकप्रिय लिनक्स उपयोगिता pkg-config का उपयोग किया ।
OpenCV लाइब्रेरी का उपयोग करने के लिए एक आरसीपी प्लगिन लागू करना Rcpp::registerPlugin("opencv", function() { # pkg_config_name <- c("opencv", "opencv4") # pkg-config pkg_config_bin <- Sys.which("pkg-config") # checkmate::assert_file_exists(pkg_config_bin, access = "x") # OpenCV pkg-config check <- sapply(pkg_config_name, function(pkg) system(paste(pkg_config_bin, pkg))) if (all(check != 0)) { stop("OpenCV config for the pkg-config not found", call. = FALSE) } pkg_config_name <- pkg_config_name[check == 0] list(env = list( PKG_CXXFLAGS = system(paste(pkg_config_bin, "--cflags", pkg_config_name), intern = TRUE), PKG_LIBS = system(paste(pkg_config_bin, "--libs", pkg_config_name), intern = TRUE) )) })
संकलन के दौरान, प्लगइन के परिणामस्वरूप, निम्नलिखित मूल्यों को प्रतिस्थापित किया जाएगा:
Rcpp:::.plugins$opencv()$env # $PKG_CXXFLAGS # [1] "-I/usr/include/opencv" # # $PKG_LIBS # [1] "-lopencv_shape -lopencv_stitching -lopencv_superres -lopencv_videostab -lopencv_aruco -lopencv_bgsegm -lopencv_bioinspired -lopencv_ccalib -lopencv_datasets -lopencv_dpm -lopencv_face -lopencv_freetype -lopencv_fuzzy -lopencv_hdf -lopencv_line_descriptor -lopencv_optflow -lopencv_video -lopencv_plot -lopencv_reg -lopencv_saliency -lopencv_stereo -lopencv_structured_light -lopencv_phase_unwrapping -lopencv_rgbd -lopencv_viz -lopencv_surface_matching -lopencv_text -lopencv_ximgproc -lopencv_calib3d -lopencv_features2d -lopencv_flann -lopencv_xobjdetect -lopencv_objdetect -lopencv_ml -lopencv_xphoto -lopencv_highgui -lopencv_videoio -lopencv_imgcodecs -lopencv_photo -lopencv_imgproc -lopencv_core"
JSON पार्सिंग को लागू करने और मॉडल को स्थानांतरित करने के लिए एक बैच बनाने का कोड स्पॉइलर के तहत दिया गया है। सबसे पहले, हेडर फ़ाइलों (ndjson के लिए आवश्यक) की खोज के लिए स्थानीय प्रोजेक्ट निर्देशिका जोड़ें:
Sys.setenv("PKG_CXXFLAGS" = paste0("-I", normalizePath(file.path("src"))))
C ++ में रूपांतरण को JSON लागू करना // [[Rcpp::plugins(cpp14)]] // [[Rcpp::plugins(opencv)]] // [[Rcpp::depends(xtensor)]] // [[Rcpp::depends(RcppThread)]] #include <xtensor/xjson.hpp> #include <xtensor/xadapt.hpp> #include <xtensor/xview.hpp> #include <xtensor-r/rtensor.hpp> #include <opencv2/core/core.hpp> #include <opencv2/highgui/highgui.hpp> #include <opencv2/imgproc/imgproc.hpp> #include <Rcpp.h> #include <RcppThread.h> // using RcppThread::parallelFor; using json = nlohmann::json; using points = xt::xtensor<double,2>; // JSON using strokes = std::vector<points>; // JSON using xtensor3d = xt::xtensor<double, 3>; // using xtensor4d = xt::xtensor<double, 4>; // using rtensor3d = xt::rtensor<double, 3>; // R using rtensor4d = xt::rtensor<double, 4>; // R // // const static int SIZE = 256; // // . https://en.wikipedia.org/wiki/Pixel_connectivity#2-dimensional const static int LINE_TYPE = cv::LINE_4; // const static int LINE_WIDTH = 3; // // https://docs.opencv.org/3.1.0/da/d54/group__imgproc__transform.html#ga5bb5a1fea74ea38e1a5445ca803ff121 const static int RESIZE_TYPE = cv::INTER_LINEAR; // OpenCV- template <typename T, int NCH, typename XT=xt::xtensor<T,3,xt::layout_type::column_major>> XT to_xt(const cv::Mat_<cv::Vec<T, NCH>>& src) { // std::vector<int> shape = {src.rows, src.cols, NCH}; // size_t size = src.total() * NCH; // cv::Mat xt::xtensor XT res = xt::adapt((T*) src.data, size, xt::no_ownership(), shape); return res; } // JSON strokes parse_json(const std::string& x) { auto j = json::parse(x); // if (!j.is_array()) { throw std::runtime_error("'x' must be JSON array."); } strokes res; res.reserve(j.size()); for (const auto& a: j) { // 2- if (!a.is_array() || a.size() != 2) { throw std::runtime_error("'x' must include only 2d arrays."); } // auto p = a.get<points>(); res.push_back(p); } return res; } // // HSV cv::Mat ocv_draw_lines(const strokes& x, bool color = true) { // auto stype = color ? CV_8UC3 : CV_8UC1; // auto dtype = color ? CV_32FC3 : CV_32FC1; auto bg = color ? cv::Scalar(0, 0, 255) : cv::Scalar(255); auto col = color ? cv::Scalar(0, 255, 220) : cv::Scalar(0); cv::Mat img = cv::Mat(SIZE, SIZE, stype, bg); // size_t n = x.size(); for (const auto& s: x) { // size_t n_points = s.shape()[1]; for (size_t i = 0; i < n_points - 1; ++i) { // cv::Point from(s(0, i), s(1, i)); // cv::Point to(s(0, i + 1), s(1, i + 1)); // cv::line(img, from, to, col, LINE_WIDTH, LINE_TYPE); } if (color) { // col[0] += 180 / n; } } if (color) { // RGB cv::cvtColor(img, img, cv::COLOR_HSV2RGB); } // float32 [0, 1] img.convertTo(img, dtype, 1 / 255.0); return img; } // JSON xtensor3d process(const std::string& x, double scale = 1.0, bool color = true) { auto p = parse_json(x); auto img = ocv_draw_lines(p, color); if (scale != 1) { cv::Mat out; cv::resize(img, out, cv::Size(), scale, scale, RESIZE_TYPE); cv::swap(img, out); out.release(); } xtensor3d arr = color ? to_xt<double,3>(img) : to_xt<double,1>(img); return arr; } // [[Rcpp::export]] rtensor3d cpp_process_json_str(const std::string& x, double scale = 1.0, bool color = true) { xtensor3d res = process(x, scale, color); return res; } // [[Rcpp::export]] rtensor4d cpp_process_json_vector(const std::vector<std::string>& x, double scale = 1.0, bool color = false) { size_t n = x.size(); size_t dim = floor(SIZE * scale); size_t channels = color ? 3 : 1; xtensor4d res({n, dim, dim, channels}); parallelFor(0, n, [&x, &res, scale, color](int i) { xtensor3d tmp = process(x[i], scale, color); auto view = xt::view(res, i, xt::all(), xt::all(), xt::all()); view = tmp; }); return res; }
इस कोड को src/cv_xt.cpp में रखा जाना चाहिए और कमांड Rcpp::sourceCpp(file = "src/cv_xt.cpp", env = .GlobalEnv) साथ संकलित किया जाना चाहिए; आपको काम करने के लिए भंडार से nlohmann/json.hpp की भी आवश्यकता होगी। कोड कई कार्यों में विभाजित है:
to_xt - छवि मैट्रिक्स ( cv::Mat ) को टेंसर xt::xtensor में बदलने के लिए एक टेम्प्लेट फ़ंक्शन xt::xtensor ;parse_json - फ़ंक्शन एक JSON स्ट्रिंग को पार्स करता है, बिंदुओं के निर्देशांक निकालता है, उन्हें एक वेक्टर में पैकिंग करता है;ocv_draw_lines - अंकों के प्राप्त वेक्टर से बहुरंगी रेखाएँ ocv_draw_lines ;process - उपरोक्त कार्यों को जोड़ती है, और परिणामी छवि को स्केल करने की क्षमता भी जोड़ती है;cpp_process_json_str - process फ़ंक्शन पर एक आवरण, जो परिणाम को आर-ऑब्जेक्ट (बहुआयामी सरणी) में निर्यात करता है;cpp_process_json_vector - cpp_process_json_str फ़ंक्शन पर एक आवरण, जो आपको मल्टी-थ्रेडेड मोड में एक स्ट्रिंग वेक्टर संसाधित करने की अनुमति देता है।
बहु-रंगीन लाइनों को खींचने के लिए, एचएसवी रंग मॉडल का उपयोग किया गया था, इसके बाद आरजीबी में रूपांतरण किया गया। परिणाम का परीक्षण करें:
arr <- cpp_process_json_str(tmp_data[4, drawing]) dim(arr) # [1] 256 256 3 plot(magick::image_read(arr))

आर और सी ++ में कार्यान्वयन की गति की तुलना res_bench <- bench::mark( r_process_json_str(tmp_data[4, drawing], scale = 0.5), cpp_process_json_str(tmp_data[4, drawing], scale = 0.5), check = FALSE, min_iterations = 100 ) # cols <- c("expression", "min", "median", "max", "itr/sec", "total_time", "n_itr") res_bench[, cols] # expression min median max `itr/sec` total_time n_itr # <chr> <bch:tm> <bch:tm> <bch:tm> <dbl> <bch:tm> <int> # 1 r_process_json_str 3.49ms 3.55ms 4.47ms 273. 490ms 134 # 2 cpp_process_json_str 1.94ms 2.02ms 5.32ms 489. 497ms 243 library(ggplot2) # res_bench <- bench::press( batch_size = 2^(4:10), { .data <- tmp_data[sample(seq_len(.N), batch_size), drawing] bench::mark( r_process_json_vector(.data, scale = 0.5), cpp_process_json_vector(.data, scale = 0.5), min_iterations = 50, check = FALSE ) } ) res_bench[, cols] # expression batch_size min median max `itr/sec` total_time n_itr # <chr> <dbl> <bch:tm> <bch:tm> <bch:tm> <dbl> <bch:tm> <int> # 1 r 16 50.61ms 53.34ms 54.82ms 19.1 471.13ms 9 # 2 cpp 16 4.46ms 5.39ms 7.78ms 192. 474.09ms 91 # 3 r 32 105.7ms 109.74ms 212.26ms 7.69 6.5s 50 # 4 cpp 32 7.76ms 10.97ms 15.23ms 95.6 522.78ms 50 # 5 r 64 211.41ms 226.18ms 332.65ms 3.85 12.99s 50 # 6 cpp 64 25.09ms 27.34ms 32.04ms 36.0 1.39s 50 # 7 r 128 534.5ms 627.92ms 659.08ms 1.61 31.03s 50 # 8 cpp 128 56.37ms 58.46ms 66.03ms 16.9 2.95s 50 # 9 r 256 1.15s 1.18s 1.29s 0.851 58.78s 50 # 10 cpp 256 114.97ms 117.39ms 130.09ms 8.45 5.92s 50 # 11 r 512 2.09s 2.15s 2.32s 0.463 1.8m 50 # 12 cpp 512 230.81ms 235.6ms 261.99ms 4.18 11.97s 50 # 13 r 1024 4s 4.22s 4.4s 0.238 3.5m 50 # 14 cpp 1024 410.48ms 431.43ms 462.44ms 2.33 21.45s 50 ggplot(res_bench, aes(x = factor(batch_size), y = median, group = expression, color = expression)) + geom_point() + geom_line() + ylab("median time, s") + theme_minimal() + scale_color_discrete(name = "", labels = c("cpp", "r")) + theme(legend.position = "bottom")
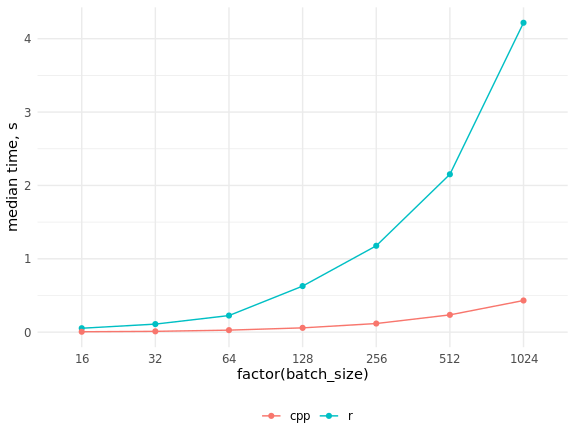
जैसा कि आप देख सकते हैं, गति वृद्धि बहुत महत्वपूर्ण हो गई है, और आर कोड को समानांतर करके सी ++ कोड के साथ पकड़ना संभव नहीं है।
3. डेटाबेस से बैचों को उतारने के लिए Iterators
R की रैम में स्थित डेटा को संसाधित करने के लिए एक भाषा के रूप में अच्छी तरह से लायक प्रतिष्ठा है, जबकि पायथन को पुनरावृत्त डेटा प्रसंस्करण की विशेषता है, जो आउट-ऑफ-कोर गणना (बाहरी मेमोरी का उपयोग करके गणना) को लागू करना आसान और आसान बनाता है। वर्णित समस्या के संदर्भ में हमारे लिए शास्त्रीय और प्रासंगिक है, इस तरह की गणना का एक उदाहरण गहरे तंत्रिका नेटवर्क है, जो टिप्पणियों के एक छोटे से हिस्से या एक मिनी-बैच द्वारा प्रत्येक चरण पर ढाल के सन्निकटन के साथ ढाल वंश की विधि द्वारा प्रशिक्षित है।
पायथन में लिखे गए डीप लर्निंग फ्रेमवर्क में विशेष कक्षाएं होती हैं जो डेटा के आधार पर पुनरावृत्तियों को लागू करती हैं: टेबल, फ़ोल्डर्स में चित्र, बाइनरी प्रारूप, आदि। आप तैयार किए गए विकल्पों का उपयोग कर सकते हैं या विशिष्ट कार्यों के लिए अपना स्वयं का लिख सकते हैं। आर में, हम उसी नाम के पैकेज का उपयोग करके अपने विभिन्न बैकेंड्स के साथ केरस पायथन लाइब्रेरी का पूरा लाभ उठा सकते हैं, जो बदले में रेटिकुलेट पैकेज के शीर्ष पर काम करता है। उत्तरार्द्ध एक अलग बड़े लेख का हकदार है; यह न केवल आपको आर से पायथन कोड चलाने की अनुमति देता है, बल्कि सभी आवश्यक प्रकार के रूपांतरणों को स्वचालित रूप से निष्पादित करते हुए, आर- और पायथन-सत्रों के बीच वस्तुओं के हस्तांतरण को भी प्रदान करता है।
हमें MonetDBLite के उपयोग के माध्यम से रैम में सभी डेटा को स्टोर करने की आवश्यकता से छुटकारा मिला, सभी "न्यूरल नेटवर्क" कार्य मूल पायथन कोड द्वारा किए जाएंगे, हमें बस डेटा के आधार पर एक पुनरावृत्त लिखना होगा, क्योंकि आर या पायथन में ऐसी स्थिति के लिए कोई तैयार नहीं है। : ( R ). R numpy-, keras .
:
train_generator <- function(db_connection = con, samples_index, num_classes = 340, batch_size = 32, scale = 1, color = FALSE, imagenet_preproc = FALSE) { # checkmate::assert_class(con, "DBIConnection") checkmate::assert_integerish(samples_index) checkmate::assert_count(num_classes) checkmate::assert_count(batch_size) checkmate::assert_number(scale, lower = 0.001, upper = 5) checkmate::assert_flag(color) checkmate::assert_flag(imagenet_preproc) # , dt <- data.table::data.table(id = sample(samples_index)) # dt[, batch := (.I - 1L) %/% batch_size + 1L] # dt <- dt[, if (.N == batch_size) .SD, keyby = batch] # i <- 1 # max_i <- dt[, max(batch)] # sql <- sprintf( "PREPARE SELECT drawing, label_int FROM doodles WHERE id IN (%s)", paste(rep("?", batch_size), collapse = ",") ) res <- DBI::dbSendQuery(con, sql) # keras::to_categorical to_categorical <- function(x, num) { n <- length(x) m <- numeric(n * num) m[x * n + seq_len(n)] <- 1 dim(m) <- c(n, num) return(m) } # function() { # if (i > max_i) { dt[, id := sample(id)] data.table::setkey(dt, batch) # i <<- 1 max_i <<- dt[, max(batch)] } # ID batch_ind <- dt[batch == i, id] # batch <- DBI::dbFetch(DBI::dbBind(res, as.list(batch_ind)), n = -1) # i <<- i + 1 # JSON batch_x <- cpp_process_json_vector(batch$drawing, scale = scale, color = color) if (imagenet_preproc) { # c [0, 1] [-1, 1] batch_x <- (batch_x - 0.5) * 2 } batch_y <- to_categorical(batch$label_int, num_classes) result <- list(batch_x, batch_y) return(result) } }
, , , , ( scale = 1 256256 , scale = 0.5 — 128128 ), ( color = FALSE , color = TRUE ) , imagenet-. , [0, 1] [-1, 1], keras .
, data.table samples_index , , SQL- . keras::to_categorical() . , , steps_per_epoch keras::fit_generator() , if (i > max_i) .
, , JSON- ( cpp_process_json_vector() , C++) , . one-hot , , . data.table — "" data.table - R.
Core i5 :
library(Rcpp) library(keras) library(ggplot2) source("utils/rcpp.R") source("utils/keras_iterator.R") con <- DBI::dbConnect(drv = MonetDBLite::MonetDBLite(), Sys.getenv("DBDIR")) ind <- seq_len(DBI::dbGetQuery(con, "SELECT count(*) FROM doodles")[[1L]]) num_classes <- DBI::dbGetQuery(con, "SELECT max(label_int) + 1 FROM doodles")[[1L]] # train_ind <- sample(ind, floor(length(ind) * 0.995)) # val_ind <- ind[-train_ind] rm(ind) # scale <- 0.5 # res_bench <- bench::press( batch_size = 2^(4:10), { it1 <- train_generator( db_connection = con, samples_index = train_ind, num_classes = num_classes, batch_size = batch_size, scale = scale ) bench::mark( it1(), min_iterations = 50L ) } ) # cols <- c("batch_size", "min", "median", "max", "itr/sec", "total_time", "n_itr") res_bench[, cols] # batch_size min median max `itr/sec` total_time n_itr # <dbl> <bch:tm> <bch:tm> <bch:tm> <dbl> <bch:tm> <int> # 1 16 25ms 64.36ms 92.2ms 15.9 3.09s 49 # 2 32 48.4ms 118.13ms 197.24ms 8.17 5.88s 48 # 3 64 69.3ms 117.93ms 181.14ms 8.57 5.83s 50 # 4 128 157.2ms 240.74ms 503.87ms 3.85 12.71s 49 # 5 256 359.3ms 613.52ms 988.73ms 1.54 30.5s 47 # 6 512 884.7ms 1.53s 2.07s 0.674 1.11m 45 # 7 1024 2.7s 3.83s 5.47s 0.261 2.81m 44 ggplot(res_bench, aes(x = factor(batch_size), y = median, group = 1)) + geom_point() + geom_line() + ylab("median time, s") + theme_minimal() DBI::dbDisconnect(con, shutdown = TRUE)

, ( 32 ). /dev/shm , . , /etc/fstab , tmpfs /dev/shm tmpfs defaults,size=25g 0 0 . , df -h .
, :
test_generator <- function(dt, batch_size = 32, scale = 1, color = FALSE, imagenet_preproc = FALSE) { # checkmate::assert_data_table(dt) checkmate::assert_count(batch_size) checkmate::assert_number(scale, lower = 0.001, upper = 5) checkmate::assert_flag(color) checkmate::assert_flag(imagenet_preproc) # dt[, batch := (.I - 1L) %/% batch_size + 1L] data.table::setkey(dt, batch) i <- 1 max_i <- dt[, max(batch)] # function() { batch_x <- cpp_process_json_vector(dt[batch == i, drawing], scale = scale, color = color) if (imagenet_preproc) { # c [0, 1] [-1, 1] batch_x <- (batch_x - 0.5) * 2 } result <- list(batch_x) i <<- i + 1 return(result) } }
4.
mobilenet v1 , . keras , , R. : (batch, height, width, 3) , . Python , , ( , keras- ):
mobilenet v1 library(keras) top_3_categorical_accuracy <- custom_metric( name = "top_3_categorical_accuracy", metric_fn = function(y_true, y_pred) { metric_top_k_categorical_accuracy(y_true, y_pred, k = 3) } ) layer_sep_conv_bn <- function(object, filters, alpha = 1, depth_multiplier = 1, strides = c(2, 2)) { # NB! depth_multiplier != resolution multiplier # https://github.com/keras-team/keras/issues/10349 layer_depthwise_conv_2d( object = object, kernel_size = c(3, 3), strides = strides, padding = "same", depth_multiplier = depth_multiplier ) %>% layer_batch_normalization() %>% layer_activation_relu() %>% layer_conv_2d( filters = filters * alpha, kernel_size = c(1, 1), strides = c(1, 1) ) %>% layer_batch_normalization() %>% layer_activation_relu() } get_mobilenet_v1 <- function(input_shape = c(224, 224, 1), num_classes = 340, alpha = 1, depth_multiplier = 1, optimizer = optimizer_adam(lr = 0.002), loss = "categorical_crossentropy", metrics = c("categorical_crossentropy", top_3_categorical_accuracy)) { inputs <- layer_input(shape = input_shape) outputs <- inputs %>% layer_conv_2d(filters = 32, kernel_size = c(3, 3), strides = c(2, 2), padding = "same") %>% layer_batch_normalization() %>% layer_activation_relu() %>% layer_sep_conv_bn(filters = 64, strides = c(1, 1)) %>% layer_sep_conv_bn(filters = 128, strides = c(2, 2)) %>% layer_sep_conv_bn(filters = 128, strides = c(1, 1)) %>% layer_sep_conv_bn(filters = 256, strides = c(2, 2)) %>% layer_sep_conv_bn(filters = 256, strides = c(1, 1)) %>% layer_sep_conv_bn(filters = 512, strides = c(2, 2)) %>% layer_sep_conv_bn(filters = 512, strides = c(1, 1)) %>% layer_sep_conv_bn(filters = 512, strides = c(1, 1)) %>% layer_sep_conv_bn(filters = 512, strides = c(1, 1)) %>% layer_sep_conv_bn(filters = 512, strides = c(1, 1)) %>% layer_sep_conv_bn(filters = 512, strides = c(1, 1)) %>% layer_sep_conv_bn(filters = 1024, strides = c(2, 2)) %>% layer_sep_conv_bn(filters = 1024, strides = c(1, 1)) %>% layer_global_average_pooling_2d() %>% layer_dense(units = num_classes) %>% layer_activation_softmax() model <- keras_model( inputs = inputs, outputs = outputs ) model %>% compile( optimizer = optimizer, loss = loss, metrics = metrics ) return(model) }
. , , , . , imagenet-. , . get_config() ( base_model_conf$layers — R- ), from_config() :
base_model_conf <- get_config(base_model) base_model_conf$layers[[1]]$config$batch_input_shape[[4]] <- 1L base_model <- from_config(base_model_conf)
keras imagenet- :
get_model <- function(name = "mobilenet_v2", input_shape = NULL, weights = "imagenet", pooling = "avg", num_classes = NULL, optimizer = keras::optimizer_adam(lr = 0.002), loss = "categorical_crossentropy", metrics = NULL, color = TRUE, compile = FALSE) { # checkmate::assert_string(name) checkmate::assert_integerish(input_shape, lower = 1, upper = 256, len = 3) checkmate::assert_count(num_classes) checkmate::assert_flag(color) checkmate::assert_flag(compile) # keras model_fun <- get0(paste0("application_", name), envir = asNamespace("keras")) # if (is.null(model_fun)) { stop("Model ", shQuote(name), " not found.", call. = FALSE) } base_model <- model_fun( input_shape = input_shape, include_top = FALSE, weights = weights, pooling = pooling ) # , if (!color) { base_model_conf <- keras::get_config(base_model) base_model_conf$layers[[1]]$config$batch_input_shape[[4]] <- 1L base_model <- keras::from_config(base_model_conf) } predictions <- keras::get_layer(base_model, "global_average_pooling2d_1")$output predictions <- keras::layer_dense(predictions, units = num_classes, activation = "softmax") model <- keras::keras_model( inputs = base_model$input, outputs = predictions ) if (compile) { keras::compile( object = model, optimizer = optimizer, loss = loss, metrics = metrics ) } return(model) }
. : get_weights() R- , ( - ), set_weights() . , , .
mobilenet 1 2, resnet34. , SE-ResNeXt. , , ( ).
5.
, docopt :
doc <- ' Usage: train_nn.R --help train_nn.R --list-models train_nn.R [options] Options: -h --help Show this message. -l --list-models List available models. -m --model=<model> Neural network model name [default: mobilenet_v2]. -b --batch-size=<size> Batch size [default: 32]. -s --scale-factor=<ratio> Scale factor [default: 0.5]. -c --color Use color lines [default: FALSE]. -d --db-dir=<path> Path to database directory [default: Sys.getenv("db_dir")]. -r --validate-ratio=<ratio> Validate sample ratio [default: 0.995]. -n --n-gpu=<number> Number of GPUs [default: 1]. ' args <- docopt::docopt(doc)
docopt http://docopt.org/ R. Rscript bin/train_nn.R -m resnet50 -c -d /home/andrey/doodle_db ./bin/train_nn.R -m resnet50 -c -d /home/andrey/doodle_db , train_nn.R ( resnet50 128128 , /home/andrey/doodle_db ). , . , mobilenet_v2 keras R - R- — , .
RStudio ( tfruns ). , RStudio.
6.
. R- .
« », . , NVIDIA, CUDA+cuDNN — , tensorflow/tensorflow:1.12.0-gpu , R-.
- :
Dockerfile FROM tensorflow/tensorflow:1.12.0-gpu MAINTAINER Artem Klevtsov <aaklevtsov@gmail.com> SHELL ["/bin/bash", "-c"] ARG LOCALE="en_US.UTF-8" ARG APT_PKG="libopencv-dev r-base r-base-dev littler" ARG R_BIN_PKG="futile.logger checkmate data.table rcpp rapidjsonr dbi keras jsonlite curl digest remotes" ARG R_SRC_PKG="xtensor RcppThread docopt MonetDBLite" ARG PY_PIP_PKG="keras" ARG DIRS="/db /app /app/data /app/models /app/logs" RUN source /etc/os-release && \ echo "deb https://cloud.r-project.org/bin/linux/ubuntu ${UBUNTU_CODENAME}-cran35/" > /etc/apt/sources.list.d/cran35.list && \ apt-key adv --keyserver keyserver.ubuntu.com --recv-keys E084DAB9 && \ add-apt-repository -y ppa:marutter/c2d4u3.5 && \ add-apt-repository -y ppa:timsc/opencv-3.4 && \ apt-get update && \ apt-get install -y locales && \ locale-gen ${LOCALE} && \ apt-get install -y --no-install-recommends ${APT_PKG} && \ ln -s /usr/lib/R/site-library/littler/examples/install.r /usr/local/bin/install.r && \ ln -s /usr/lib/R/site-library/littler/examples/install2.r /usr/local/bin/install2.r && \ ln -s /usr/lib/R/site-library/littler/examples/installGithub.r /usr/local/bin/installGithub.r && \ echo 'options(Ncpus = parallel::detectCores())' >> /etc/R/Rprofile.site && \ echo 'options(repos = c(CRAN = "https://cloud.r-project.org"))' >> /etc/R/Rprofile.site && \ apt-get install -y $(printf "r-cran-%s " ${R_BIN_PKG}) && \ install.r ${R_SRC_PKG} && \ pip install ${PY_PIP_PKG} && \ mkdir -p ${DIRS} && \ chmod 777 ${DIRS} && \ rm -rf /tmp/downloaded_packages/ /tmp/*.rds && \ rm -rf /var/lib/apt/lists/* COPY utils /app/utils COPY src /app/src COPY tests /app/tests COPY bin/*.R /app/ ENV DBDIR="/db" ENV CUDA_HOME="/usr/local/cuda" ENV PATH="/app:${PATH}" WORKDIR /app VOLUME /db VOLUME /app CMD bash
; . /bin/bash /etc/os-release . .
-, . , , , :
#!/bin/sh DBDIR=${PWD}/db LOGSDIR=${PWD}/logs MODELDIR=${PWD}/models DATADIR=${PWD}/data ARGS="--runtime=nvidia --rm -v ${DBDIR}:/db -v ${LOGSDIR}:/app/logs -v ${MODELDIR}:/app/models -v ${DATADIR}:/app/data" if [ -z "$1" ]; then CMD="Rscript /app/train_nn.R" elif [ "$1" = "bash" ]; then ARGS="${ARGS} -ti" else CMD="Rscript /app/train_nn.R $@" fi docker run ${ARGS} doodles-tf ${CMD}
- , train_nn.R ; — "bash", . : CMD="Rscript /app/train_nn.R $@" .
, , , .
7. GPU Google Cloud
(. , @Leigh.plt ODS-). , 1 GPU GPU . GoogleCloud ( ) - , $300. 4V100 SSD , . , . K80. — SSD c, dev/shm .
, GPU. CPU , :
with(tensorflow::tf$device("/cpu:0"), { model_cpu <- get_model( name = model_name, input_shape = input_shape, weights = weights, metrics =(top_3_categorical_accuracy, compile = FALSE ) })
( ) GPU, :
model <- keras::multi_gpu_model(model_cpu, gpus = n_gpu) keras::compile( object = model, optimizer = keras::optimizer_adam(lr = 0.0004), loss = "categorical_crossentropy", metrics = c(top_3_categorical_accuracy) )
, , , GPU .
tensorboard , :
# log_file_tmpl <- file.path("logs", sprintf( "%s_%d_%dch_%s.csv", model_name, dim_size, channels, format(Sys.time(), "%Y%m%d%H%M%OS") )) # model_file_tmpl <- file.path("models", sprintf( "%s_%d_%dch_{epoch:02d}_{val_loss:.2f}.h5", model_name, dim_size, channels )) callbacks_list <- list( keras::callback_csv_logger( filename = log_file_tmpl ), keras::callback_early_stopping( monitor = "val_loss", min_delta = 1e-4, patience = 8, verbose = 1, mode = "min" ), keras::callback_reduce_lr_on_plateau( monitor = "val_loss", factor = 0.5, # lr 2 patience = 4, verbose = 1, min_delta = 1e-4, mode = "min" ), keras::callback_model_checkpoint( filepath = model_file_tmpl, monitor = "val_loss", save_best_only = FALSE, save_weights_only = FALSE, mode = "min" ) )
8.
, , :
- keras (
lr_finder fast.ai ); , R , , ; - , GPU;
- , imagenet-;
- one cycle policy discriminative learning rates (osine annealing , skeydan ).
:
- ( ) . data.table in-place , , . .
- R C++ Rcpp . RcppThread RcppParallel , , R .
- Rcpp C++, . xtensor CRAN, , R C++. — ++ RStudio.
- docopt . , .. . RStudio , IDE .
- , . .
- Google Cloud — , .
- , R C++, bench — .
, .