मैं सब कुछ का एक बड़ा प्रशंसक रहा हूँ
Fabien Sanglard करता है, मुझे उनका ब्लॉग पसंद है, और मैंने उनकी
दोनों पुस्तकों को कवर करने के लिए पढ़ा है (हाल ही के
हंसलेमिन्यूट्स पॉडकास्ट में वर्णित है)।
फैबियन ने हाल ही में एक शानदार पोस्ट लिखा था, जहां उन्होंने
एक छोटे से रे ट्रेसर को
डिक्रिप्ट किया , कोड को deobfuscating और गणित को सुंदर तरीके से समझाते हुए। मैं वास्तव में इसे पढ़ने के लिए समय निकालने की सलाह देता हूं!
लेकिन यह मुझे आश्चर्यचकित
करता है कि
क्या इस C ++ कोड को C # में पोर्ट करना संभव है ? चूंकि मुझे अपनी
मुख्य नौकरी में हाल ही में बहुत सी सी + + लिखना पड़ा है, मैंने सोचा कि मैं इसे आज़मा सकता हूं।
लेकिन इससे भी महत्वपूर्ण बात, मैं एक बेहतर विचार प्राप्त करना चाहता था
कि क्या सी # निम्न स्तर की भाषा है ?
थोड़ा अलग, लेकिन संबंधित प्रश्न: "सिस्टम प्रोग्रामिंग" के लिए C # कितना उपयुक्त है? इस विषय पर, मैं वास्तव में
2013 से जो डफी की उत्कृष्ट पोस्ट की सिफारिश करता हूं।
लाइन पोर्ट
मैंने केवल C # के लिए लाइन द्वारा
सी ++ कोड लाइन को
डीबॉफ़सेटेड पोर्ट करके शुरू किया। यह बहुत आसान था: ऐसा लगता है कि सच अभी भी कहा जा रहा है कि C # C ++++ है !!!
उदाहरण मुख्य डेटा संरचना को दर्शाता है - 'वेक्टर', यहाँ एक तुलना है, बाईं ओर C ++, दाईं ओर C #:

इसलिए, कुछ वाक्यात्मक अंतर हैं, लेकिन चूंकि .NET आपको
अपने स्वयं के मूल्य प्रकारों को परिभाषित करने की अनुमति देता है, इसलिए मैं समान कार्यक्षमता प्राप्त करने में सक्षम था। यह महत्वपूर्ण है क्योंकि एक संरचना के रूप में 'वेक्टर' का इलाज करने का मतलब है कि हम एक बेहतर "डेटा स्थानीयता" प्राप्त कर सकते हैं और हमें .NET कचरा कलेक्टर को शामिल करने की आवश्यकता नहीं है, क्योंकि डेटा को स्टैक पर धकेल दिया जाएगा (हाँ, मुझे पता है कि यह एक कार्यान्वयन विवरण है)।
.NET में
structs या "मूल्य प्रकार" के बारे में अधिक जानकारी के लिए, यहां देखें:
विशेष रूप से, एरिक लिपर्ट की अंतिम पोस्ट में, हम एक ऐसी उपयोगी उद्धरण पाते हैं जो यह स्पष्ट करता है कि "मूल्य प्रकार" वास्तव में क्या हैं:
बेशक, मूल्यों के प्रकारों के बारे में सबसे महत्वपूर्ण तथ्य कार्यान्वयन विवरण नहीं है, उन्हें कैसे आवंटित किया जाता है , बल्कि "मूल्य का प्रकार" का मूल अर्थ अर्थ है , अर्थात् यह हमेशा "मूल्य द्वारा" कॉपी किया जाता है । यदि आवंटन की जानकारी महत्वपूर्ण थी, तो हम उन्हें "ढेर प्रकार" और "ढेर प्रकार" कहेंगे। लेकिन ज्यादातर मामलों में यह मायने नहीं रखता है। ज्यादातर समय, नकल और पहचान के शब्दार्थ प्रासंगिक होते हैं।
अब देखते हैं कि तुलना में कुछ अन्य तरीके क्या दिखते हैं (पुन: बाईं ओर C ++, दाईं ओर C #), पहले
RayTracing(..) :
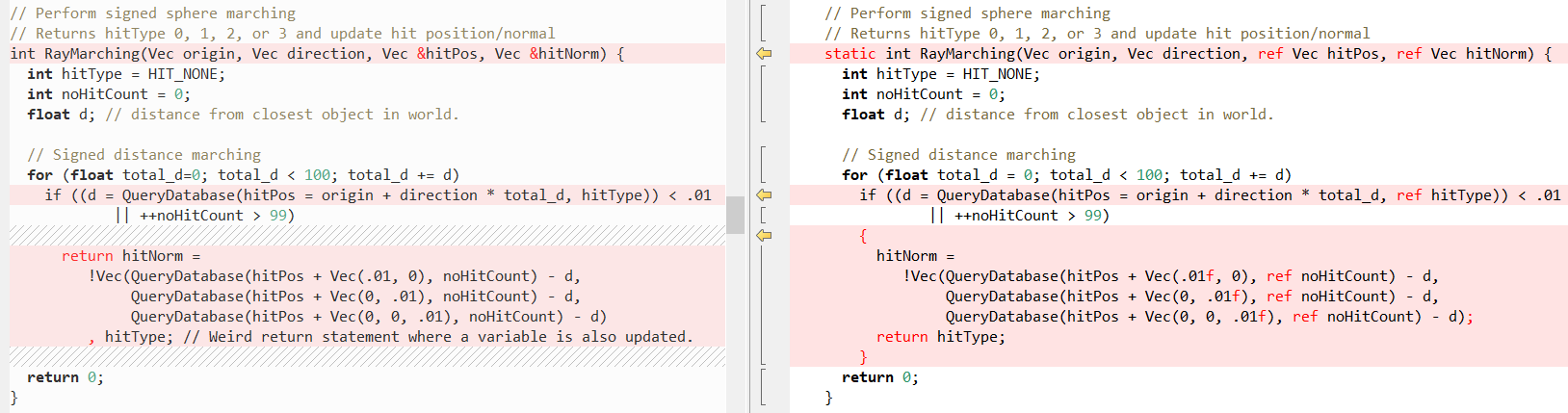
फिर
QueryDatabase (..) :
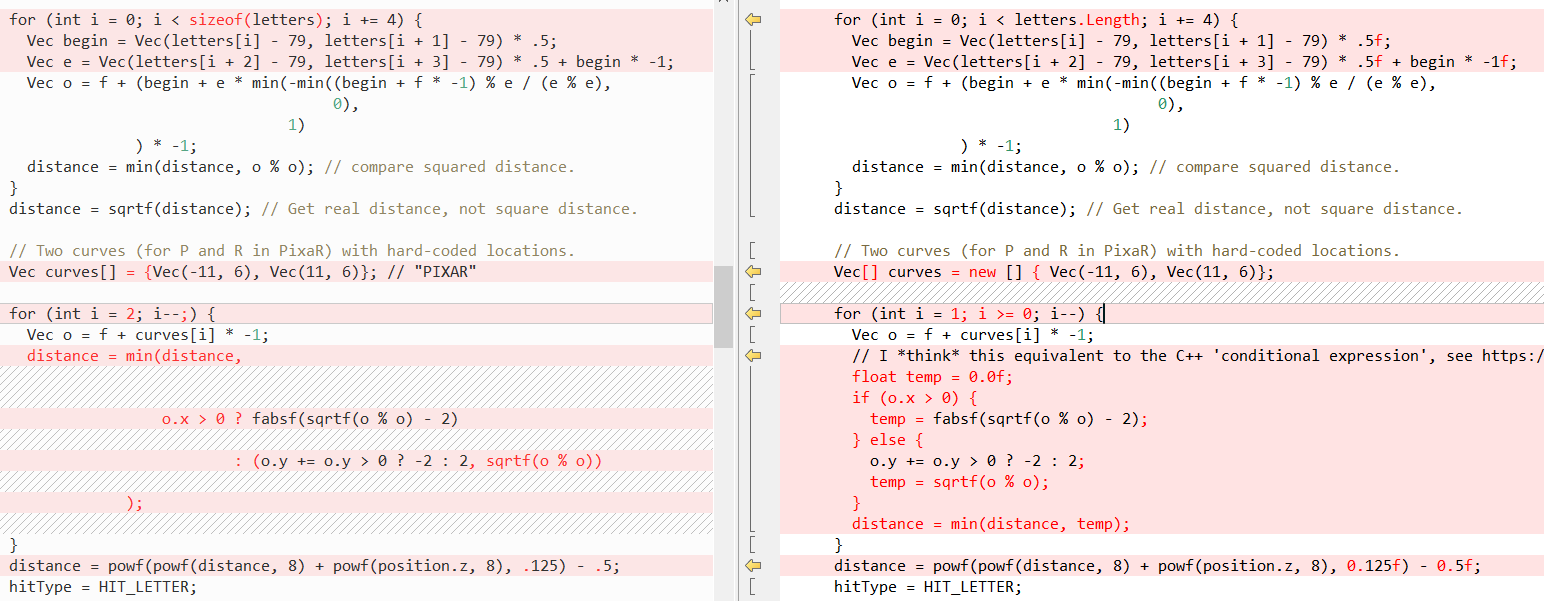
(इन दो कार्यों को करने के स्पष्टीकरण के लिए
फैबियन की पोस्ट देखें)
लेकिन फिर, तथ्य यह है कि C # C ++ कोड लिखना बहुत आसान बनाता है! इस मामले में,
ref कीवर्ड हमें सबसे अधिक मदद करता है, जो हमें
संदर्भ द्वारा एक
मान पारित करने की अनुमति देता है। हमने काफी समय से मेथड कॉल में
ref का उपयोग किया है, लेकिन हाल ही में,
ref कहीं और हल करने के प्रयास किए गए हैं:
अब
कभी-कभी ref का उपयोग करने से प्रदर्शन में सुधार होगा, क्योंकि तब संरचना को कॉपी करने की आवश्यकता नहीं होती है,
एडम स्टिनिक्स द्वारा पोस्ट में बेंचमार्क देखें और
"प्रदर्शन जाल स्थानीय लोगों को देखें और अधिक जानकारी के लिए
सी # में रिटर्न को रिफ्लेक्ट करें।
"लेकिन सबसे महत्वपूर्ण बात यह है कि ऐसी स्क्रिप्ट हमारे C # पोर्ट को C ++ स्रोत कोड के समान व्यवहार प्रदान करती है। यद्यपि मैं यह नोट करना चाहता हूं कि तथाकथित "प्रबंधित लिंक" काफी हद तक "पॉइंटर्स" के समान नहीं हैं, विशेष रूप से, आप उन पर अंकगणित नहीं कर सकते हैं, इसके बारे में यहां और देखें:
उत्पादकता
इस प्रकार, कोड को अच्छी तरह से चित्रित किया गया था, लेकिन प्रदर्शन भी मायने रखता है। विशेष रूप से किरण अनुरेखक में, जो कई मिनटों के लिए फ्रेम की गणना कर सकता है। C ++ कोड में वैरिएबल
sampleCount , जो अंतिम छवि की गुणवत्ता को नियंत्रित करता है, जिसके लिए
sampleCount = 2 निम्नानुसार है:

जाहिर है बहुत यथार्थवादी नहीं!
लेकिन जब आप
sampleCount = 2048 , तो सब कुछ
बहुत बेहतर दिखता है:

लेकिन
sampleCount = 2048 साथ शुरू करना
बहुत समय लेने वाला है, इसलिए अन्य सभी रन कम से कम एक मिनट मिलने के लिए
2 मूल्य के साथ किए जाते हैं।
sampleCount बदलना केवल बाहरी कोड लूप की पुनरावृत्तियों की संख्या को प्रभावित करता है,
इस विवरण को स्पष्टीकरण के लिए देखें।
"भोली" लाइन पोर्ट के बाद परिणाम
C ++ और C # की तुलना करने के लिए, मैंने
टाइम-विंडो टूल का उपयोग किया, यह
time यूनिक्स कमांड का पोर्ट है। प्रारंभिक परिणाम इस तरह दिखे:
| सी ++ (वीएस 2017) | .NET फ्रेमवर्क (4.7.2) | .NET कोर (2.2) |
|---|
| समय (सेकंड) | 47,40 | 80.14 | 78.02 |
| कोर (सेकंड) में | 0.14 (0.3%) | 0.72 (0.9%) | 0.63 (0.8%) |
| उपयोगकर्ता-स्थान (सेकंड) में | 43.86 (92.5%) | 73.06 (91.2%) | 70.66 (90.6%) |
| पृष्ठ दोष त्रुटियों की संख्या | 1143 | 4818 | 5945 |
| कार्य सेट (KB) | 4232 | १३ ६२४ | 17 052 |
| एक्सटेंडेड मेमोरी (KB) | 95 | 172 | 154 |
| गैर-प्रीमेप्टिव मेमोरी | 7 | 14 | 16 |
| स्वैप फ़ाइल (KB) | 1460 | १० ९ ३६ | ११ ०२४ |
प्रारंभ में, हम देखते हैं कि C # कोड C ++ संस्करण की तुलना में थोड़ा धीमा है, लेकिन यह बेहतर हो रहा है (नीचे देखें)।
लेकिन पहले देखते हैं कि .NET JIT इस “भोली” लाइन-बाय-लाइन पोर्ट के साथ भी क्या करता है। सबसे पहले, यह छोटे सहायक तरीकों को एम्बेड करने का एक अच्छा काम करता है। यह उत्कृष्ट
इनलाइनिंग एनालाइज़र टूल (ग्रीन = बिल्ट-इन) के आउटपुट में देखा जा सकता है:
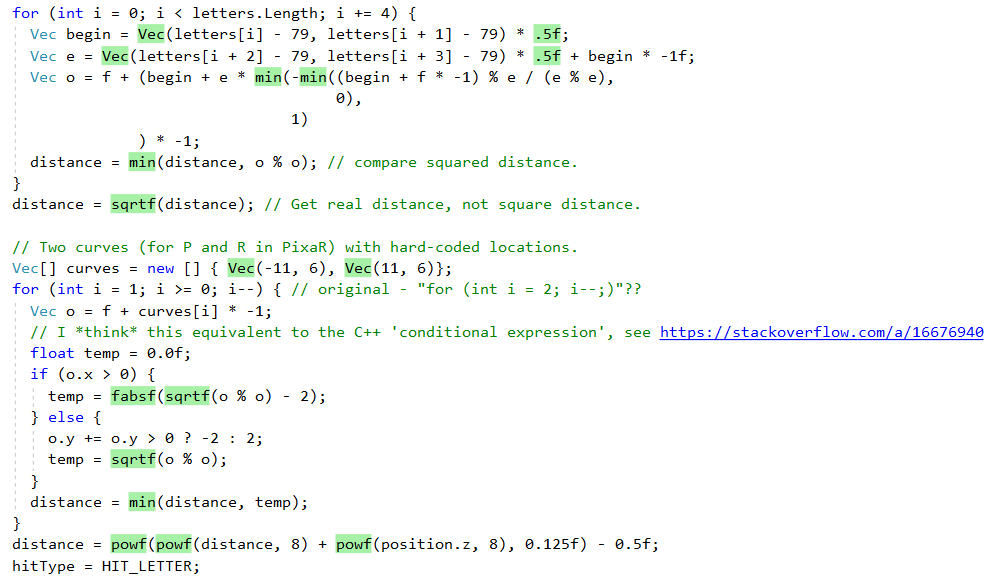
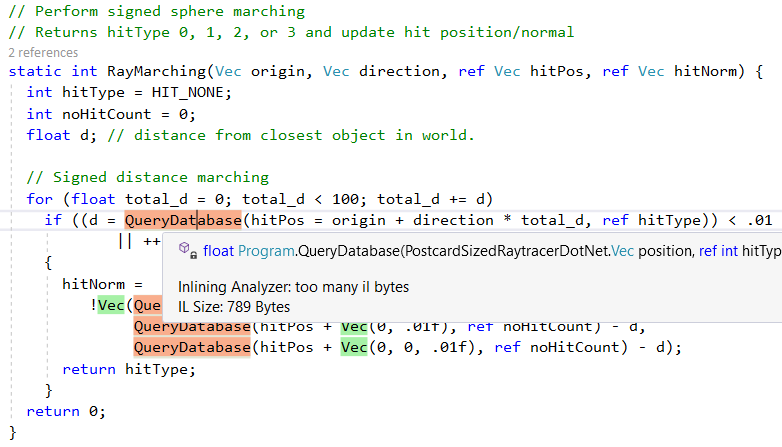
हालाँकि, यह सभी विधियों को एम्बेड नहीं करता है, उदाहरण के लिए, जटिलता के कारण,
QueryDatabase(..) छोड़ दिया जाता है:
एक अन्य .NET जस्ट-इन-टाइम (JIT) कंपाइलर फीचर संबंधित सीपीयू निर्देशों के लिए विशिष्ट विधि कॉल का रूपांतरण है। हम इसे
sqrt शेल फ़ंक्शन के साथ एक्शन में देख सकते हैं, यहाँ C # सोर्स कोड है (
Math.Sqrt कॉल करें):
और यहाँ कोडांतरक कोड है जो .NET JIT उत्पन्न करता है:
Math.Sqrt में कोई कॉल नहीं है और प्रोसेसर निर्देश
vsqrtsd का उपयोग किया जाता है :
; Assembly listing for method Program:sqrtf(float):float ; Emitting BLENDED_CODE for X64 CPU with AVX - Windows ; Tier-1 compilation ; optimized code ; rsp based frame ; partially interruptible ; Final local variable assignments ; ; V00 arg0 [V00,T00] ( 3, 3 ) float -> mm0 ;# V01 OutArgs [V01 ] ( 1, 1 ) lclBlk ( 0) [rsp+0x00] "OutgoingArgSpace" ; ; Lcl frame size = 0 G_M8216_IG01: vzeroupper G_M8216_IG02: vcvtss2sd xmm0, xmm0 vsqrtsd xmm0, xmm0 vcvtsd2ss xmm0, xmm0 G_M8216_IG03: ret ; Total bytes of code 16, prolog size 3 for method Program:sqrtf(float):float ; ============================================================
(इस मुद्दे को प्राप्त करने के लिए,
इन निर्देशों का पालन करें,
"Disasmo" VS2019 ऐड-ऑन का उपयोग करें या
SharpLab.io पर
देखें )
इन प्रतिस्थापनों को
आंतरिक के रूप में भी जाना जाता
है , और नीचे दिए गए कोड में हम देख सकते हैं कि जेआईटी उन्हें कैसे उत्पन्न करता है। यह स्निपेट केवल
AMD64 लिए मैपिंग दिखाता है, लेकिन JIT
X86 ,
ARM और
ARM64 को भी
यहां पूर्ण विधि से लक्षित करता
है ।
bool Compiler::IsTargetIntrinsic(CorInfoIntrinsics intrinsicId) { #if defined(_TARGET_AMD64_) || (defined(_TARGET_X86_) && !defined(LEGACY_BACKEND)) switch (intrinsicId) {
जैसा कि आप देख सकते हैं, कुछ विधियों जैसे
Sqrt और
Abs को लागू किया जाता है, जबकि अन्य C ++ रनटाइम फ़ंक्शन का उपयोग करते हैं, उदाहरण के लिए,
powf ।
इस पूरी प्रक्रिया को
".NET फ्रेमवर्क में कैसे लागू किया गया है? कैसे Math.Pow () लेख में बहुत अच्छी तरह से समझाया गया है
?" , यह CoreCLR स्रोत में भी देखा जा सकता है:
सरल प्रदर्शन में सुधार के बाद परिणाम
मुझे आश्चर्य है कि क्या आप तुरंत भोली लाइन-दर-पोर्ट पोर्ट में सुधार कर सकते हैं। कुछ रूपरेखा के बाद, मैंने दो बड़े बदलाव किए:
- इनलाइन ऐरे इनिशियलाइज़ेशन को हटाना
Math.XXX(..) के एनालॉग्स के साथ Math.XXX(..) के कार्यों को Math.XXX(..)
इन परिवर्तनों को नीचे और अधिक विस्तार से समझाया गया है।
इनलाइन ऐरे इनिशियलाइज़ेशन को हटाना
यह क्यों आवश्यक है, इस बारे में अधिक जानकारी के लिए,
आंद्रेई अकिंशिन से बेंचमार्क और कोडांतरक कोड के साथ
यह उत्कृष्ट स्टैक ओवरफ्लो उत्तर देखें। वह निम्नलिखित निष्कर्ष पर आता है:
निष्कर्ष
- क्या .NET कैश हार्ड-कोडेड लोकल एरेज देता है? जैसे मेटाडेटा में रोजलिन कंपाइलर लगाते हैं।
- इस मामले में, ओवरहेड होगा? दुर्भाग्य से, हाँ: प्रत्येक कॉल के लिए, जेआईटी मेटाडेटा से सरणी की सामग्री की नकल करेगा, जो एक स्थिर सरणी की तुलना में अतिरिक्त समय लेता है। रनटाइम ऑब्जेक्ट का चयन भी करता है और मेमोरी में ट्रैफ़िक बनाता है।
- क्या इस बारे में चिंता करने की कोई जरूरत है? हो सकता है कि। यदि यह एक गर्म विधि है और आप अच्छे स्तर का प्रदर्शन हासिल करना चाहते हैं, तो आपको एक स्टेटिक ऐरे का उपयोग करना होगा। यदि यह एक ठंडी विधि है जो अनुप्रयोग प्रदर्शन को प्रभावित नहीं करती है, तो आपको संभवतः "अच्छा" स्रोत कोड लिखने और सरणी को विधि क्षेत्र में रखने की आवश्यकता है।
आप
इस अंतर में किए गए परिवर्तनों को देख सकते हैं।
मैथ के बजाय मैथफ फंक्शंस का उपयोग करना
दूसरे, और सबसे महत्वपूर्ण बात, मैंने निम्नलिखित बदलाव करके प्रदर्शन में काफी सुधार किया है:
#if NETSTANDARD2_1 || NETCOREAPP2_0 || NETCOREAPP2_1 || NETCOREAPP2_2 || NETCOREAPP3_0
.NET मानक 2.1 के साथ शुरू,
float आम गणितीय कार्यों के ठोस कार्यान्वयन मौजूद हैं। वे
System.MathF वर्ग में स्थित हैं। इस API और इसके कार्यान्वयन पर अधिक जानकारी के लिए, यहां देखें:
इन परिवर्तनों के बाद, C # और C ++ कोड प्रदर्शन का अंतर लगभग 10% तक कम हो गया था:
| C ++ (VS C ++ 2017) | .NET फ्रेमवर्क (4.7.2) | .NET कोर (2.2) टीसी ऑफ | .NET कोर (2.2) टीसी ऑन |
|---|
| समय (सेकंड) | 41.38 | 58.89 | 46.04 | 44.33 |
| कोर (सेकंड) में | 0.05 (0.1%) | 0.06 (0.1%) | 0.14 (0.3%) | 0.13 (0.3%) |
| उपयोगकर्ता-स्थान (सेकंड) में | 41.19 (99.5%) | 58.34 (99.1%) | 44.72 (97.1%) | 44.03 (99.3%) |
| पृष्ठ दोष त्रुटियों की संख्या | 1119 | 4749 | 5776 | 5661 |
| कार्य सेट (KB) | 4136- | 13440 | 16,788 | 16652 |
| एक्सटेंडेड मेमोरी (KB) | 89 | 172 | 150 | 150 |
| गैर-प्रीमेप्टिव मेमोरी | 7 | 13 | 16 | 16 |
| स्वैप फ़ाइल (KB) | 1428 | १० ९ ०४ | 10 960 | 11 044 |
TC - बहुस्तरीय संकलन,
Tiered Compilation (
मुझे लगता है
कि यह .NET कोर 3.0 में डिफ़ॉल्ट रूप से सक्षम हो जाएगा)
पूर्णता के लिए, यहां कई रन के परिणाम दिए गए हैं:
| रन | C ++ (VS C ++ 2017) | .NET फ्रेमवर्क (4.7.2) | .NET कोर (2.2) टीसी ऑफ | .NET कोर (2.2) टीसी ऑन |
|---|
| TestRun-01 | 41.38 | 58.89 | 46.04 | 44.33 |
| TestRun-02 | 41.19 | 57.65 | 46.23 | 45.96 |
| TestRun-03 | 42.17 | 62.64 | 46.22 | 48,73 |
नोट : .NET कोर और .NET फ्रेमवर्क के बीच का अंतर .NET फ्रेमवर्क 4.7.2 में मैथएफ एपीआई की कमी के कारण है, अधिक जानकारी के लिए,
नेटस्ट्रीम 2.1 के लिए समर्थन टिकट। नेट फ्रेमवर्क (4.8?) देखें ।
उत्पादकता में और वृद्धि
मुझे यकीन है कि कोड अभी भी सुधारा जा सकता है!
यदि आप प्रदर्शन अंतर को हल करने में रुचि रखते हैं, तो
यहां C # कोड है । तुलना के लिए, आप उत्कृष्ट
कंपाइलर एक्सप्लोरर सेवा से C ++ कोडांतरक कोड देख सकते हैं।
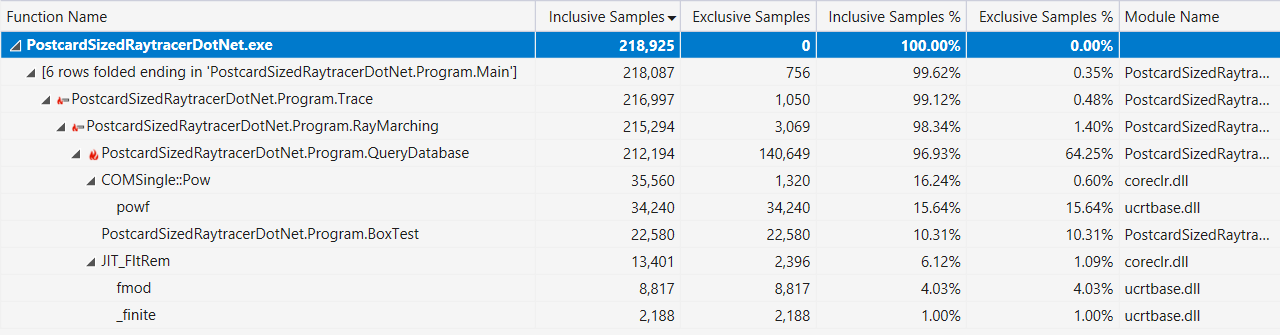
अंत में, यदि वह मदद करता है, तो यहां "हॉट पाथ" डिस्प्ले के साथ विजुअल स्टूडियो प्रोफाइलर आउटपुट है (ऊपर वर्णित प्रदर्शन में सुधार के बाद):
C # एक निम्न स्तर की भाषा है?
या अधिक विशेष रूप से:
C # / F # / VB.NET या BCL / रनटाइम फ़ंक्शनलिटी की किस भाषा की विशेषताओं का अर्थ "निम्न स्तर" * प्रोग्रामिंग है?
* हाँ, मैं समझता हूँ कि "निम्न स्तर" एक व्यक्तिपरक शब्द है।
नोट: प्रत्येक C # डेवलपर का अपना विचार है कि "निम्न स्तर" क्या है, इन कार्यों को C ++ या Rust प्रोग्रामर द्वारा प्रदान किया जाएगा।
यहाँ मैंने जो सूची बनाई है:
- रेफरी और स्थानीय लोगों को रेफरी
- “बड़ी संरचनाओं की नकल से बचने के लिए संदर्भ द्वारा पासिंग और वापसी। सुरक्षित प्रकार और मेमोरी असुरक्षित से भी तेज हो सकती है! "
- .NET में असुरक्षित कोड
- "मूल सी # भाषा, जैसा कि पिछले अध्यायों में परिभाषित किया गया है, सी और सी ++ से बहुत अलग है, क्योंकि इसमें डेटा प्रकार के रूप में पॉइंटर्स का अभाव है। इसके बजाय, C # लिंक और कचरा कलेक्टर द्वारा शासित वस्तुओं को बनाने की क्षमता प्रदान करता है। यह डिज़ाइन, अन्य विशेषताओं के साथ, C # को C या C ++ की तुलना में अधिक सुरक्षित भाषा बनाता है। "
- .NET में प्रबंधित पॉइंटर्स
- “सीएलआर में एक और प्रकार का सूचक है - एक प्रबंधित सूचक। इसे अधिक सामान्य प्रकार के लिंक के रूप में परिभाषित किया जा सकता है जो अन्य स्थानों पर इंगित कर सकता है, न कि केवल वस्तु की शुरुआत के लिए। "
- सी # 7 सीरीज, भाग 10: स्पैन <टी> और यूनिवर्सल मेमोरी मैनेजमेंट
- “System.Span <T> केवल एक स्टैक प्रकार (
ref struct ) है जो सभी मेमोरी एक्सेस पैटर्न को लपेटता है, यह यूनिवर्सल मेमोरी एक्सेस के लिए एक प्रकार है। हम एक डमी संदर्भ और एक लंबाई के साथ एक स्पैन कार्यान्वयन की कल्पना कर सकते हैं जो सभी तीन प्रकार के मेमोरी एक्सेस को स्वीकार करता है। "
- संगतता ("C # प्रोग्रामिंग गाइड")
- ".NET फ्रेमवर्क प्लेटफ़ॉर्म इनवोकेशन सेवाओं,
System.Runtime.InteropServices , C ++ संगतता, और COM (COM इंटरऑपरिबिलिटी) संगतता के माध्यम से अप्रबंधित कोड के साथ इंटरऑपरेबिलिटी प्रदान करता है।"
मैंने ट्विटर पर भी रोना फेंक दिया और सूची में शामिल करने के लिए बहुत अधिक विकल्प प्राप्त किए:
- बेन एडम्स : "प्लेटफार्मों के लिए निर्मित उपकरण (सीपीयू निर्देश)"
- मार्क ग्रेवेल : "वेक्टर के माध्यम से सिम (जो स्पैन के साथ अच्छी तरह से चला जाता है) * सुंदर * कम है; .NET कोर (जल्द ही?) विशिष्ट सीपीयू निर्देशों के अधिक स्पष्ट उपयोग के लिए प्रत्यक्ष सीपीयू एम्बेडेड उपकरणों की पेशकश करें ”
- मार्क ग्रेवेल : "शक्तिशाली जेआईटी: सरणियों / अंतरालों पर सीमा विस्तार, साथ ही प्रति-संरचना-टी नियमों का उपयोग करके कोड के बड़े टुकड़ों को निकालने के लिए जो जेआईटी को पता है कि वे उस टी के लिए उपलब्ध नहीं हैं या किसी विशिष्ट पर CPU (BitConverter.IsLittleEndian, Vector.IsHardwareAccelerated, आदि) "
- केविन जोन्स : "मैं विशेष रूप से
MemoryMarshal और Unsafe वर्ग, और शायद System.Runtime.CompilerServices में कुछ अन्य बातों का उल्लेख करेंगे"
- थियोडोरस चैटसिगानियाकिंस : "आप
__makeref और बाकी को भी शामिल कर सकते हैं"
- हंटबॉय : "कोड को गतिशील रूप से उत्पन्न करने की क्षमता जो कि अपेक्षित इनपुट से मेल खाती है, यह देखते हुए कि उत्तरार्द्ध केवल रन टाइम पर जाना जाएगा और समय-समय पर बदल सकता है?"
- रॉबर्ट हैकेन : "आईएल का गतिशील उत्सर्जन"
- विक्टर बेबकोव : “स्टैकलोक का उल्लेख नहीं किया गया था। शुद्ध आईएल लिखना भी संभव है (गतिशील नहीं है, इसलिए इसे एक फ़ंक्शन कॉल पर सहेजा जाता है), उदाहरण के लिए, कैश्ड
ldftn उपयोग करें और उन्हें calli माध्यम से कॉल करें। VS2017 में एक proj टेम्प्लेट है जो बाहरी तरीकों + MethodImplOptions.ForwardRef + ilasm.ex »को फिर से लिखकर इस तुच्छ बनाता है।
- विक्टर बायबेकॉव : "मेथडिमप्लेओस.आग्रेसिवइन्लाइनिंग भी" निम्न-स्तरीय प्रोग्रामिंग को सक्रिय करता है "इस अर्थ में कि यह आपको कई छोटे तरीकों के साथ उच्च-स्तरीय कोड लिखने की अनुमति देता है और फिर भी एक अनुकूलित परिणाम प्राप्त करने के लिए जेआईटी के व्यवहार को नियंत्रित करता है। अन्यथा, सैकड़ों LOC तरीकों की कॉपी-पेस्ट ... "
- बेन एडम्स : "बेस प्लेटफॉर्म के समान कॉलिंग कन्वेंशन (एबीआई) का उपयोग करना, और बातचीत के लिए पी / इनवॉइस?"
- विक्टर बैबकोव : "इसके अलावा, चूंकि आपने #fsharp का उल्लेख किया है - इसमें एक
inline जो IL स्तर पर JIT तक काम करता है, इसलिए इसे भाषा के स्तर पर महत्वपूर्ण माना जाता था। लैम्बदास के लिए सी # यह पर्याप्त (अब तक) नहीं है, जो हमेशा आभासी कॉल होते हैं, और वर्कअराउड अक्सर अजीब (सीमित जेनरिक) होते हैं "
- अलेक्जेंड्रे म्यूटेल : "नया एम्बेडेड सिमड, अनसेफ यूटिलिटी क्लास / आईएल का पोस्ट-प्रोसेसिंग (उदाहरण के लिए, कस्टम, फ़ोडी, आदि)। C # 8.0 के लिए, आगामी फ़ंक्शन संकेत ... "
- अलेक्जेंडर मुटेल : "आईएल के बारे में, एफ # सीधे एक भाषा में आईएल का समर्थन करता है, उदाहरण के लिए"
- ओमारीओ : “ बाइनरीप्रिमेट्स । निम्न स्तर, लेकिन सुरक्षित "
- कोजी मात्सुई : “कैसे अपने खुद के अंतर्निहित कोडांतरक के बारे में? टूलकिट और रनटाइम दोनों के लिए यह मुश्किल है, लेकिन यह वर्तमान पी / इनवॉइस समाधान को बदल सकता है और एम्बेडेड कोड को लागू कर सकता है, यदि "
- फ्रैंक ए। क्रूगर : "लडोबज, स्टोबज, इनितोबज, इनिटब्लक, खोपबेलक"
- कॉनराड नारियल : "शायद स्थानीय भंडारण स्ट्रीमिंग? निश्चित आकार बफ़र्स? आपको शायद अप्रबंधित बाधाओं और प्रक्षालित प्रकारों का उल्लेख करना चाहिए :) ”
- सेबेस्टियानो मंडला : "बस इतना ही कहा गया कि इसके अलावा एक छोटा सा: कैसे कुछ सरल के बारे में, जैसे कि संरचनाओं की व्यवस्था करना और मेमोरी और फ़ील्ड ऑर्डरिंग को कैसे भरना और संरेखित करना कैश प्रदर्शन को प्रभावित कर सकता है? यह कुछ ऐसा है जो मुझे खुद तलाशना चाहिए। "
- Nino Floris : "रीडऑनलीस्पैन, स्टैकलॉक, फाइनलर्स, वीकरेफेरेंस, ओपन डेलिगेट्स, मेथेमप्लॉएशंस, मेमोरीबेरियर्स, टाइपराइरेंस, वैरगैड्स, SIMD, Unsafe.AsRef के माध्यम से एम्बेड किए गए कंटेंट, लेआउट के साथ सटीक संरचना के प्रकार सेट कर सकते हैं (टास्कएटर राइटर के लिए प्रयुक्त)
इसलिए अंत में, मैं कहूंगा कि C # निश्चित रूप से आपको C ++ की तरह दिखने वाला कोड लिखने की अनुमति देता है, और रनटाइम और बेस क्लास लाइब्रेरीज़ के संयोजन में निम्न स्तर के बहुत सारे फ़ंक्शंस मिलते हैं।आगे पढ़ रहे हैं
एकता फट कम्पाइलर: