ASN.1 संरचित जानकारी का वर्णन करने वाली भाषा का एक मानक (ISO, ITU-T, GOST) है, साथ ही साथ इस जानकारी के लिए एन्कोडिंग नियम भी है। मेरे लिए एक प्रोग्रामर के रूप में, यह JSON, XML, XDR और अन्य के साथ डेटा को प्रस्तुत करने और प्रस्तुत करने के लिए सिर्फ एक और प्रारूप है। यह हमारे सामान्य जीवन में बेहद आम है, और कई लोग इसके पार आते हैं: सेलुलर, टेलीफोन, वीओआईपी संचार (UMTS, LTE, WiMAX, SS7, H.323) में, नेटवर्क प्रोटोकॉल में (LDAP, SNMP, कर्बरोस), सब कुछ में क्रिप्टोग्राफी (X.509, CMS, PKCS मानकों) के बारे में, बैंक कार्ड और बायोमेट्रिक पासपोर्ट में, और बहुत कुछ।
इस लेख में
PyDERASN : Python ASN.1 लाइब्रेरी की चर्चा की गई है, जो
एटलस में क्रिप्टोग्राफी से संबंधित परियोजनाओं में सक्रिय रूप से उपयोग की जाती है।
वास्तव में, यह क्रिप्टोग्राफिक कार्यों के लिए ASN.1 की सिफारिश करने लायक नहीं है: ASN.1 और इसके कोडक जटिल हैं। इसका मतलब है कि कोड सरल नहीं होगा, लेकिन यह हमेशा एक अतिरिक्त हमला वेक्टर है। बस ASN.1 पुस्तकालयों में कमजोरियों
की सूची देखें । ब्रूस श्नेयर, अपनी
क्रिप्टोग्राफी इंजीनियरिंग में, इसकी जटिलता के कारण इस मानक का उपयोग करने की अनुशंसा नहीं करता है: "सबसे प्रसिद्ध टीएलवी एन्कोडिंग ASN.1 है, लेकिन यह अविश्वसनीय रूप से जटिल है और हम इससे दूर भागते हैं।" लेकिन, दुर्भाग्यवश, आज हमारे पास
सार्वजनिक कुंजी इन्फ्रास्ट्रक्चर है जिसमें
X.509 सर्टिफिकेट , CRL, OCSP, TSP, CMP,
CMC ,
CMS संदेश और
PKCS मानकों के बहुत सारे सक्रिय रूप से उपयोग किए जाते हैं। इसलिए, यदि आप क्रिप्टोग्राफी से संबंधित कुछ कर रहे हैं तो आपको ASN.1 के साथ काम करने में सक्षम होना चाहिए।
ASN.1 को कई तरह से कूट-कूट कर भरा जा सकता है:
- BER (मूल एन्कोडिंग नियम)
- सीईआर (कैनोनिकल एन्कोडिंग नियम)
- डीईआर (विशिष्ट एन्कोडिंग नियम)
- जीएसईआर (जेनेरिक स्ट्रिंग एन्कोडिंग नियम)
- JER (JSON एन्कोडिंग नियम)
- LWER (लाइट वेट एन्कोडिंग नियम)
- OER (ऑक्टेट एन्कोडिंग नियम)
- प्रति (पैक्ड एन्कोडिंग नियम)
- SER (सिग्नलिंग विशिष्ट एन्कोडिंग नियम)
- XER (XML एन्कोडिंग नियम)
और दूसरों की संख्या। लेकिन व्यवहार में क्रिप्टोग्राफिक कार्यों में, दो का उपयोग किया जाता है: बीईआर और डीईआर। यहां तक कि हस्ताक्षर किए गए XML दस्तावेजों (
XMLDSig ,
XAdES ) में अभी भी बेस 64-एनकोडेड ASN.1 DER ऑब्जेक्ट होंगे, साथ ही लेट्स एनक्रिप्ट के JSON-आधारित
ACME प्रोटोकॉल में भी। आप लेख और पुस्तकों में इन सभी कोडेक्स और BER / CER / DER कोडिंग सिद्धांतों को बेहतर ढंग से समझ सकते हैं:
ASN.1 सरल शब्दों में ,
ASN.1 - ओलिवियर डबिसन द्वारा विषम प्रणालियों के बीच संचार ,
ASN.1 प्रोफेसर जॉन लारमाउथ द्वारा पूरा ।
बीईआर एक द्विआधारी बाइट-ओरिएंटेड है (उदाहरण के लिए, प्रति, मोबाइल संचार में लोकप्रिय - बिट-उन्मुख) टीएलवी प्रारूप। प्रत्येक तत्व के रूप में एन्कोड किया गया है: एक टैग (
टी एजी) तत्व के प्रकार की पहचान करके एन्कोड किया जा रहा है (पूर्णांक, स्ट्रिंग, तिथि, आदि), सामग्री की लंबाई (
एल ength) और सामग्री खुद (
वी एल्यू)। BER वैकल्पिक रूप से आपको एक विशेष अनिश्चित लंबाई मान सेट करके और एंड-ऑफ-ऑक्ट्स संदेश के साथ समाप्त करके लंबाई मान निर्दिष्ट नहीं करने देता है। लंबाई कोडिंग के अलावा, बीईआर में डेटा प्रकार एन्कोडिंग की विधि में बहुत अधिक परिवर्तनशीलता है, जैसे:
- INTEGER, OBJECT IDENTIFIER, BIT STRING और तत्व की लंबाई सामान्यीकृत नहीं की जा सकती (न्यूनतम रूप में एन्कोडेड नहीं);
- BOOLEAN किसी भी गैर-शून्य सामग्री के लिए सही है;
- BIT STRING में "अतिरिक्त" शून्य बिट्स हो सकते हैं;
- BIT STRING, OCTET STRING और उनके सभी व्युत्पन्न स्ट्रिंग प्रकार, दिनांक / समय सहित, चर लंबाई के टुकड़ों (चंक) में विभाजित किए जा सकते हैं, जिसकी लंबाई (डी) एन्कोडिंग के दौरान अग्रिम में ज्ञात नहीं है;
- UTCTime / GeneralizedTime में समय क्षेत्र ऑफसेट और सेकंड के "अतिरिक्त" शून्य अंश सेट करने के लिए अलग-अलग तरीके हो सकते हैं;
- DEFAULT SEQUENCE मान एन्कोड किया जा सकता है या नहीं;
- BIT STRING में अंतिम बिट्स के नामित मान वैकल्पिक रूप से एन्कोड किए जा सकते हैं;
- SEQUENCE (OF) / SET (OF) तत्वों का एक मनमाना क्रम हो सकता है।
उपरोक्त सभी के लिए, डेटा को एन्कोड करना हमेशा संभव नहीं होता है ताकि यह मूल रूप के समान हो। इसलिए, नियमों के एक सबसेट का आविष्कार किया गया था: डीईआर केवल एक वैध कोडिंग पद्धति का एक सख्त विनियमन है, जो क्रिप्टोग्राफिक कार्यों के लिए महत्वपूर्ण है, जहां, उदाहरण के लिए, एक बिट को बदलने से हस्ताक्षर या चेकसम अमान्य हो जाएगा। डीईआर में एक महत्वपूर्ण कमी है: एन्कोडिंग के दौरान सभी तत्वों की लंबाई पहले से ज्ञात होनी चाहिए, जो डेटा की धारा क्रमबद्धता की अनुमति नहीं देता है। सीईआर कोडेक इस खामी से मुक्त है, इसी तरह डेटा की अस्पष्ट प्रस्तुति की गारंटी देता है। दुर्भाग्य से (या सौभाग्य से, हमारे पास और भी अधिक जटिल डिकोडर्स नहीं हैं?), यह लोकप्रिय नहीं हुआ। इसलिए, व्यवहार में, हम BER और DER एन्कोडेड डेटा के "मिश्रित" उपयोग का सामना करते हैं। चूंकि CER और DER दोनों BER का सबसेट हैं, इसलिए कोई भी BER डिकोडर उन्हें प्रोसेस करने में सक्षम है।
Pyasn1 के साथ समस्या
काम पर, हम क्रिप्टोग्राफी से संबंधित कई पायथन कार्यक्रम लिखते हैं। और कुछ साल पहले व्यावहारिक रूप से मुक्त पुस्तकालयों का कोई विकल्प नहीं था: या तो ये बहुत ही निम्न-स्तर के पुस्तकालय हैं जो आपको केवल सांकेतिक शब्दों में बदलना / डिकोड करने की अनुमति देते हैं, उदाहरण के लिए, एक पूर्णांक और एक संरचना शीर्षलेख, या यह
pyasn1 पुस्तकालय है। हम कई वर्षों तक इस पर रहते थे और पहले तो बहुत प्रसन्न थे, क्योंकि यह आपको ASN.1 संरचनाओं के साथ उच्च-स्तरीय वस्तुओं के रूप में काम करने की अनुमति देता है: उदाहरण के लिए, एक डिकोड्ड X.509 सर्टिफिकेट ऑब्जेक्ट आपको डिक्शनरी इंटरफ़ेस के माध्यम से इसके खेतों तक पहुँचने की अनुमति देता है: सर्टिफिकेट [tbsCertificate]] ["SerialNumber"] हमें इस प्रमाण पत्र की क्रम संख्या दिखाएगा। इसी तरह, आप सूची, शब्दकोश के साथ उनके साथ काम करके जटिल वस्तुओं को "एकत्र" कर सकते हैं, और फिर बस pyasn1.codec.der.encoder.encode फ़ंक्शन को कॉल कर सकते हैं और दस्तावेज़ का क्रमबद्ध प्रतिनिधित्व प्राप्त कर सकते हैं।
हालांकि, कमजोरियों, समस्याओं और सीमाओं का पता चला था। वहाँ थे, और दुर्भाग्यवश अभी भी बने हुए हैं, pyasn1 में त्रुटियाँ: लेखन के समय, pyasn1 में, मूल प्रकारों में से एक, GeneralizedTime,
गलत तरीके से डीकोड और एन्कोडेड है।
हमारी परियोजनाओं में, अंतरिक्ष को बचाने के लिए, हम अक्सर फ़ाइल को केवल पथ को स्टोर करते हैं, जिस ऑब्जेक्ट को हम संदर्भित करना चाहते हैं, उसके बाइट्स में ऑफसेट और लंबाई। उदाहरण के लिए, एक मनमाने ढंग से हस्ताक्षरित फ़ाइल सबसे अधिक संभावना सीएमएस सिग्नेडडैट ASN.1 संरचना में स्थित होगी:
0 [1,3,1018] ContentInfo SEQUENCE 4 [1,1, 9] . contentType: ContentType OBJECT IDENTIFIER 1.2.840.113549.1.7.2 (id_signedData) 19-4 [0,0,1003] . content: [0] EXPLICIT [UNIV 16] ANY 19 [1,3, 999] . . DEFINED BY id_signedData: SignedData SEQUENCE 23 [1,1, 1] . . . version: CMSVersion INTEGER v3 (03) 26 [1,1, 19] . . . digestAlgorithms: DigestAlgorithmIdentifiers SET OF [...] 47 [1,3, 769] . . . encapContentInfo: EncapsulatedContentInfo SEQUENCE 51 [1,1, 8] . . . . eContentType: ContentType OBJECT IDENTIFIER 1.3.6.1.5.5.7.12.2 (id_cct_PKIData) 65-4 [1,3, 751] . . . . eContent: [0] EXPLICIT OCTET STRING 751 bytes OPTIONAL 751 820 [1,2, 199] . . . signerInfos: SignerInfos SET OF 823 [1,2, 196] . . . . 0: SignerInfo SEQUENCE 826 [1,1, 1] . . . . . version: CMSVersion INTEGER v3 (03) 829 [0,0, 22] . . . . . sid: SignerIdentifier CHOICE subjectKeyIdentifier [...] 956 [1,1, 64] . . . . . signature: SignatureValue OCTET STRING 64 bytes . . . . . . C1:B3:88:BA:F8:92:1C:E6:3E:41:9B:E0:D3:E9:AF:D8 . . . . . . 47:4A:8A:9D:94:5D:56:6B:F0:C1:20:38:D2:72:22:12 . . . . . . 9F:76:46:F6:51:5F:9A:8D:BF:D7:A6:9B:FD:C5:DA:D2 . . . . . . F3:6B:00:14:A4:9D:D7:B5:E1:A6:86:44:86:A7:E8:C9
और हम मूल हस्ताक्षरित फ़ाइल को 65 बाइट्स, 751 बाइट्स की भरपाई पर प्राप्त कर सकते हैं। pyasn1 अपनी डिकोड की गई वस्तुओं में इस जानकारी को संग्रहीत नहीं करता है। तथाकथित TLVSeeker लिखा गया था - एक छोटी सी लाइब्रेरी जो आपको वस्तुओं के टैग और लंबाई को डिकोड करने की अनुमति देती है, जिसके इंटरफ़ेस में हमने "अगले टैग पर जाएं", "टैग के अंदर जाएं" (ऑब्जेक्ट के दृश्य के अंदर जाएं), "अगले टैग पर जाएं", " ऑफसेट और उस वस्तु की लंबाई जहां हम हैं। " यह ASN.1 DER-serialized डेटा पर "मैन्युअल" चलना था। लेकिन इस तरह से BER-serialized डेटा के साथ काम करना संभव नहीं था, क्योंकि, उदाहरण के लिए, बाइट स्ट्रिंग OCTET STRING को कई chunk-s के रूप में एन्कोड किया जा सकता है।
हमारे pyasn1 कार्यों के लिए एक और दोष यह है कि डीकोड की गई वस्तुओं से समझने में असमर्थता है कि एक दिया क्षेत्र SEQUENCE में मौजूद था या नहीं। उदाहरण के लिए, यदि संरचना में Smth OPTIONAL क्षेत्र की फ़ील्ड शामिल है, तो यह प्राप्त डेटा (OPTIONAL) में पूरी तरह से अनुपस्थित हो सकता है, लेकिन यह मौजूद हो सकता है, लेकिन यह शून्य लंबाई (खाली सूची) हो सकता है। सामान्य मामले में, यह स्पष्ट नहीं किया जा सकता है। और यह प्राप्त आंकड़ों की वैधता की कठोर जांच के लिए आवश्यक है। कल्पना कीजिए कि कुछ प्रमाणन प्राधिकरण ASN.1 योजनाओं के दृष्टिकोण से "पूरी तरह से" वैध डेटा के साथ एक प्रमाण पत्र जारी करेगा! उदाहरण के लिए, इसके मूल प्रमाण पत्र में प्रमाणन प्राधिकरण TKRKTRUST Elektronik Sertifika Hizmet Sağlayıcısı विषय घटक की लंबाई के लिए अनुमेय
RFC 5280 सीमाओं से परे चला गया - यह योजना के अनुसार ईमानदारी से डिकोड नहीं किया जा सकता है। डीईआर कोडक की आवश्यकता होती है कि एक ऐसा क्षेत्र जिसका मान डिफॉल्ट है संचरण के दौरान एन्कोड नहीं किया गया है - ऐसे दस्तावेजों का जीवन में सामना होता है, और PyDERASN के पहले संस्करण ने भी जानबूझकर पिछड़े संगतता के लिए ऐसे अमान्य (डीईआर के दृष्टिकोण से) व्यवहार की अनुमति दी।
एक और सीमा आसानी से पता लगाने में असमर्थता है कि किस रूप में (BER / DER) एक या दूसरी वस्तु संरचना में एनकोड की गई थी। उदाहरण के लिए, CMS मानक कहता है कि संदेश BER- एन्कोडेड है, लेकिन हस्ताक्षर किए गए फ़ील्ड, जिस पर क्रिप्टोग्राफ़िक हस्ताक्षर बनते हैं, DER में होना चाहिए। यदि हम डीईआर के साथ डिकोड करते हैं, तो हम स्वयं सीएमएस के प्रसंस्करण पर गिर जाएंगे, अगर हम बीईआर के साथ डिकोड करते हैं, तो हमें पता नहीं होगा कि हस्ताक्षर किए गए फॉर्म क्या हैं। नतीजतन, यह TLVSeeker के लिए आवश्यक होगा (जिनमें से एनालॉग pyasn1 में नहीं है) प्रत्येक हस्ताक्षरित फ़ील्ड के स्थान की खोज करने के लिए, और इसे धारावाहिक दृश्य से डीईआर द्वारा अलग से डिकोड किया जाना चाहिए।
स्वचालित BY क्षेत्रों की स्वचालित प्रसंस्करण की संभावना, जो बहुत आम हैं, हमारे लिए बहुत ही वांछनीय था। ASN.1 संरचना को डिकोड करने के बाद, हमारे पास कई फ़ील्ड्स बचे रह सकते हैं, जिन्हें संरचना क्षेत्र में निर्दिष्ट OJJECT IDENTIFIER के आधार पर चयनित योजना के अनुसार आगे संसाधित किया जाना चाहिए। पायथन कोड में, इसका अर्थ है कि अगर किसी भी क्षेत्र के लिए डिकोडर को कॉल करना और फिर कॉल करना।
PyDERASN का आगमन
एटलस में, हम नियमित रूप से, किसी भी समस्या का पता लगाते हैं या उपयोग किए गए मुफ्त कार्यक्रमों को संशोधित करते हैं, शीर्ष पर पैच भेजते हैं। Pyasn1 में, हमने कई बार सुधार भेजे, लेकिन pyasn1 कोड समझना सबसे आसान नहीं है, और कभी-कभी इसमें असंगत एपीआई परिवर्तन होते हैं, जो हमें हाथों पर मारते हैं। इसके अलावा, हम जेनेटिक परीक्षण के साथ परीक्षण लिखने के लिए उपयोग किए जाते हैं, जो कि pyasn1 में नहीं था।
एक अच्छा दिन, मैंने फैसला किया कि मुझे यह सहना होगा और यह __slot __s के साथ अपनी लाइब्रेरी लिखने की कोशिश करने का समय था, ऑफसेट s, और खूबसूरती से प्रदर्शित बूँदें! बस एक ASN.1 कोडेक बनाना पर्याप्त नहीं होगा - आपको हमारी सभी आश्रित परियोजनाओं को इसमें स्थानांतरित करने की आवश्यकता है, और यह कोड की सैकड़ों हजारों लाइनें हैं जिसमें ASN.1-संरचनाओं के साथ बहुत काम है। यह इसके लिए आवश्यकताओं में से एक है: वर्तमान pyasn1 कोड के अनुवाद में आसानी। अपनी पूरी छुट्टी बिताने के बाद, मैंने इस पुस्तकालय को लिखा, सभी परियोजनाओं को इसमें स्थानांतरित कर दिया। चूंकि उनके पास परीक्षणों द्वारा लगभग 100% कवरेज है, इसका मतलब यह भी था कि पुस्तकालय पूरी तरह से चालू था।
इसी तरह PyDERASN के पास लगभग 100% परीक्षण कवरेज है। अद्भुत
परिकल्पना पुस्तकालय के साथ जेनेरिक परीक्षण का उपयोग किया जाता है। इसके अलावा 32 परमाणु मशीनों पर
पीज़-एफएल को भी किया गया। इस तथ्य के बावजूद कि हमारे पास लगभग कोई Python2 कोड नहीं बचा है, PyDERASN अभी भी इसके साथ संगतता बनाए रखता है और इस वजह से इसका एकल
छह निर्भरता है। इसके अलावा,
ASN.1: 2008 अनुपालन परीक्षण सूट के खिलाफ इसका परीक्षण किया
जाता है ।
इसके साथ काम करने का सिद्धांत pyasn1 के समान है - उच्च-स्तरीय पायथन वस्तुओं के साथ काम करना। ASN.1 सर्किट का विवरण समान है।
class TBSCertificate(Sequence): schema = ( ("version", Version(expl=tag_ctxc(0), default="v1")), ("serialNumber", CertificateSerialNumber()), ("signature", AlgorithmIdentifier()), ("issuer", Name()), ("validity", Validity()), ("subject", Name()), ("subjectPublicKeyInfo", SubjectPublicKeyInfo()), ("issuerUniqueID", UniqueIdentifier(impl=tag_ctxp(1), optional=True)), ("subjectUniqueID", UniqueIdentifier(impl=tag_ctxp(2), optional=True)), ("extensions", Extensions(expl=tag_ctxc(3), optional=True)), )
हालाँकि, PyDERASN में मजबूत टाइपिंग का एक गुण है। Pyasn1 में, यदि क्षेत्र CMSVersion (INTEGER) प्रकार का था, तो इसे एक int या INTEGER सौंपा जा सकता है। PyDERASN को सख्ती से आवश्यकता है कि असाइन की गई वस्तु बिल्कुल CMSVersion हो। Python3 कोड लिखने के अलावा, हम
टाइपिंग एनोटेशन का उपयोग करते
हैं , इसलिए हमारे फ़ंक्शंस में डीफ़ फ़ंक (धारावाहिक, सामग्री) जैसे अकाट्य तर्क नहीं होंगे, लेकिन डीफ़ फ़ेक (धारावाहिक: सर्टिफ़िकेटरीनंबर, सामग्री, EncapsulatedContentInfo), और PyDERASN ऐसे ट्रैक का ट्रैक रखने में मदद करता है। कोड।
इसी समय, PyDERASN के पास इस टाइपिंग के लिए बेहद सुविधाजनक रियायतें हैं। pyasn1 ने SubjectKeyIdentifier ()। सबटाइप (implicitTag = Tag (...)) को SubjectKeyIdentifier () (आवश्यक IMPLICIT TAG के बिना) ऑब्जेक्ट असाइन करने की अनुमति नहीं दी थी और अक्सर बदले हुए IMPLICIT / EXPLICIT टैग की वजह से ही वस्तुओं को कॉपी और रिक्रिएट करना पड़ता था। PyDERASN सख्ती से केवल मूल प्रकार का निरीक्षण करता है - यह स्वचालित रूप से मौजूदा ASN.1 संरचना से टैग स्थानापन्न करेगा। यह अनुप्रयोग कोड को बहुत सरल करता है।
यदि डिकोडिंग के दौरान कोई त्रुटि होती है, तो pyasn1 में यह समझना आसान नहीं है कि यह कहां हुआ है। उदाहरण के लिए, पहले से ही उल्लेखित तुर्की प्रमाण पत्र में हमें यह त्रुटि मिलती है: UTF8String (tbsCertificate: जारीकर्ता: rdnSequence: 3: 0: value: DEFINED BY 2.5.4.10:utf8String) (138 पर) असंतुष्ट सीमा: 1 ⇐ 77 ⇐ 64 ASN लिखते समय। .1 संरचनाएं लोग गलतियां कर सकते हैं, और यह अनुप्रयोगों को डीबग करने या विपरीत पक्ष के एन्कोडेड दस्तावेजों की समस्याओं का पता लगाने में आसान बनाता है।
PyDERASN के पहले संस्करण ने BER एन्कोडिंग का समर्थन नहीं किया। यह बहुत बाद में दिखाई दिया और समय क्षेत्रों के साथ UTCTime / GeneralizedTime प्रसंस्करण अभी भी समर्थित नहीं है। यह भविष्य में आएगा, क्योंकि परियोजना मुख्य रूप से खाली समय में लिखी गई है।
इसके अलावा पहले संस्करण में DEFINED BY खेतों के साथ कोई काम नहीं किया गया था। कुछ महीनों बाद यह
अवसर दिखाई दिया और सक्रिय रूप से उपयोग किया जाने लगा, आवेदन कोड को काफी कम कर दिया - एक डिकोडिंग ऑपरेशन में, पूरी संरचना को बहुत गहराई तक पहुंचाना संभव था। ऐसा करने के लिए, इस योजना में, किन क्षेत्रों को परिभाषित किया गया है कि "निर्धारित"। उदाहरण के लिए, CMS स्कीमा का विवरण:
class ContentInfo(Sequence): schema = ( ("contentType", ContentType(defines=((("content",), { id_authenticatedData: AuthenticatedData(), id_digestedData: DigestedData(), id_encryptedData: EncryptedData(), id_envelopedData: EnvelopedData(), id_signedData: SignedData(), }),))), ("content", Any(expl=tag_ctxc(0))), )
का कहना है कि अगर contentType में id_signData के साथ एक OID होता है, तो SignedData योजना का उपयोग करके सामग्री फ़ील्ड (उसी क्रम में स्थित) को डिकोड किया जाना चाहिए। इतने सारे कोष्ठक क्यों हैं? एक फ़ील्ड एक ही समय में कई फ़ील्ड्स को "परिभाषित" कर सकती है, जैसा कि EnvelopedData संरचनाओं में होता है। परिभाषित फ़ील्ड तथाकथित डिकोड पथ द्वारा पहचाने जाते हैं - यह सभी संरचनाओं में किसी भी तत्व का सटीक स्थान निर्धारित करता है।
यह हमेशा वांछनीय नहीं है या हमेशा सर्किट में इन परिभाषित करने के लिए तुरंत संभव नहीं है। आवेदन-विशिष्ट मामले हो सकते हैं जहां ओआईडी और संरचना केवल एक तृतीय-पक्ष परियोजना में जानी जाती हैं। PyDERASN संरचना को डिकोड करने के समय इन डिफाइनों को निर्दिष्ट करने की क्षमता प्रदान करता है:
ContentInfo().decode(data, ctx={"defines_by_path": (( ( "content", DecodePathDefBy(id_signedData), "certificates", any, "certificate", "tbsCertificate", "extensions", any, "extnID", ), ((("extnValue",), { id_ce_authorityKeyIdentifier: AuthorityKeyIdentifier(), id_ce_basicConstraints: BasicConstraints(), [...] id_ru_subjectSignTool: SubjectSignTool(), }),), ),)})
यहां हम कहते हैं कि सभी संलग्न प्रमाण पत्रों के लिए सीएमएस साइनडेडा में, उनके सभी एक्सटेंशन (अथॉरिटीकेडेंटिफायर, बेसिककॉन्स्ट्रेन्ट्स, सब्जेक्टसाइनटूल, आदि) को डीकोड करें। हम डिकोड पथ के माध्यम से इंगित करते हैं कि कौन सा तत्व "स्थानापन्न" परिभाषित करता है, जैसे कि यह सर्किट में परिभाषित किया गया था।
अंत में, PyDERASN के पास ASN.1 फ़ाइलों को डिकोड करने के लिए
कमांड लाइन से काम करने की क्षमता है और इसमें
बहुत सुंदर प्रिंटिंग है । आप ASN.1 को अनियंत्रित कर सकते हैं, या आप स्पष्ट रूप से परिभाषित योजना को निर्दिष्ट कर सकते हैं और कुछ इस तरह देख सकते हैं:
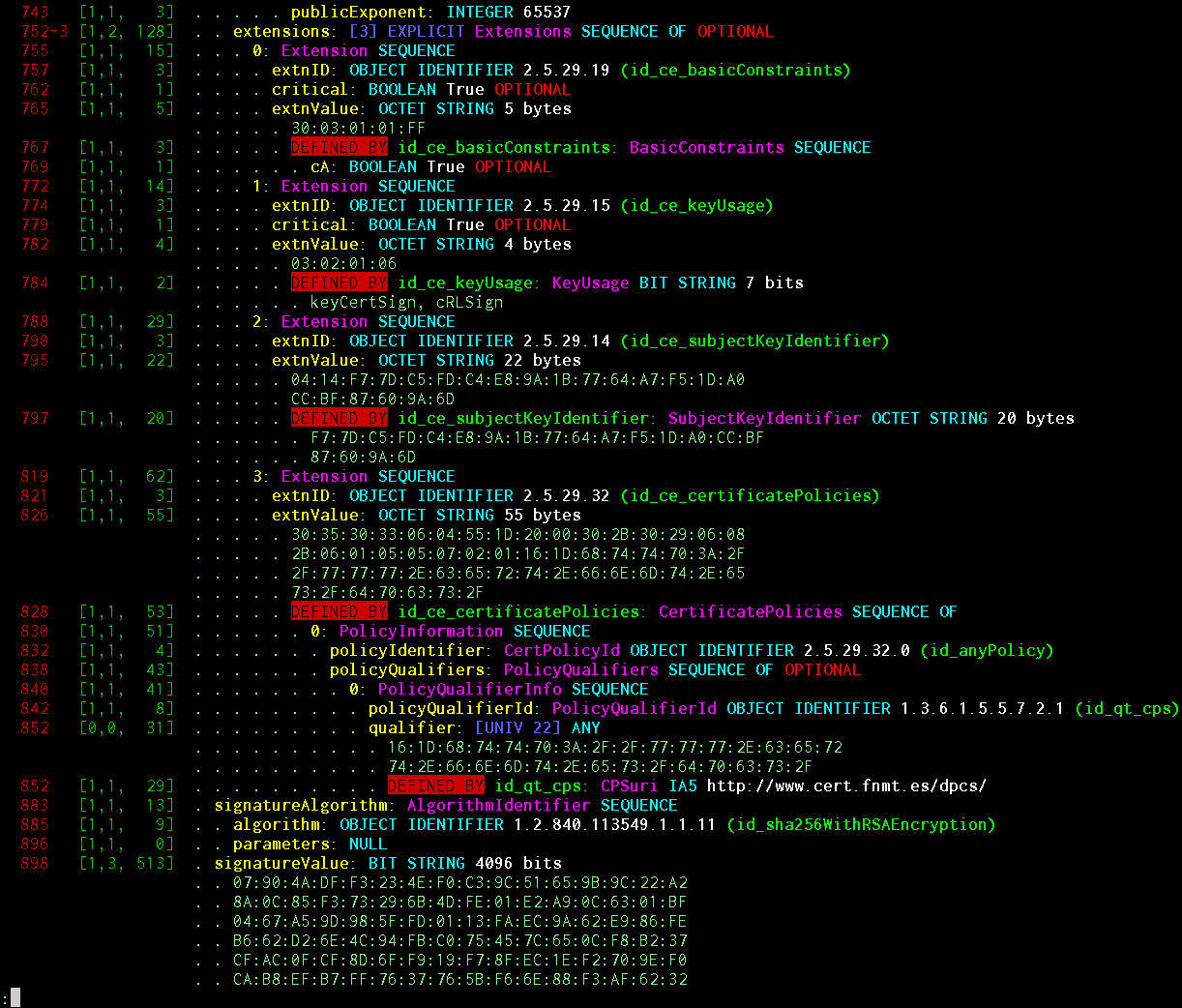
प्रदर्शित जानकारी: ऑब्जेक्ट ऑफ़सेट, टैग की लंबाई, लंबाई की लंबाई, सामग्री की लंबाई, EOC (एंड-ऑफ़-ओक्टेट्स) की उपस्थिति, BER एन्कोडिंग फ़्लैग, अनिश्चितकालीन-एन्कोडिंग फ़्लैग, EXPLICIT टैग की लंबाई और ऑफ़सेट (यदि कोई हो), ऑब्जेक्ट में गहराई से जाँच करना संरचनाएं, IMPLICIT / EXPLICIT टैग मूल्य, योजना के अनुसार वस्तु का नाम, इसका मूल ASN.1 प्रकार, अनुक्रम के अंदर सीरियल नंबर / सेट, मान का चयन (यदि कोई हो), मानव-पठनीय नाम INTEGER / ENUMERATED / BIT STRING योजना के अनुसार, किसी भी मूल प्रकार का मूल्य , सर्किट से अल्फा / वैकल्पिक ध्वज, एक संकेत है कि वस्तु स्वचालित रूप से बाद में के रूप में डिकोड किया गया था के ग्राम OID-और ऐसा हुआ, chelovekochitaemy OID।
सुंदर मुद्रण प्रणाली विशेष रूप से बनाई गई है ताकि यह पीपी वस्तुओं का एक अनुक्रम उत्पन्न करे जो पहले से ही अलग-अलग तरीकों से कल्पना कर रहे हैं। स्क्रीनशॉट सादे रंग के पाठ में रेंडरर दिखाता है। JSON / HTML प्रारूप में
रेंडरर्स हैं ताकि ASN.1 ब्राउज़र में
asn1ds प्रोजेक्ट के रूप में हाइलाइटिंग के साथ देखा जा सके।
अन्य पुस्तकालय
यह लक्ष्य नहीं था, लेकिन PyDERASN pyasn1 की तुलना में काफी
तेज था। उदाहरण के लिए, मेगाबाइट आकारों की CRL फ़ाइलों को डिकोड करने में इतना समय लग सकता है कि आपको डेटा (तेजी से) भंडारण के लिए मध्यवर्ती स्वरूपों के बारे में सोचना होगा और अनुप्रयोगों की वास्तुकला को बदलना होगा। pyasn1 ने मेरे लैपटॉप पर CRL
CACert.org को 20 मिनट से अधिक समय तक डीकोड किया, जबकि PyDERASN सिर्फ 28 सेकंड में! क्रिप्टोग्राफिक संरचनाओं के साथ जल्दी से काम करने के उद्देश्य से एक
एसएन 1 क्रिप्टोकरंसी प्रोजेक्ट है: यह 29 सेकंड में एक ही सीआरएल को पूरी तरह से डिकोड करता है (लेकिन पूरी तरह से आलसी नहीं), लेकिन पायथन 3 (983 एमआईबी बनाम 498) के तहत चलने पर यह लगभग दो बार रैम का उपयोग करता है। और पायथन 2 (487 के खिलाफ 1677) के तहत 3.5 गुना, जबकि pyasn1 की खपत 4.3 गुना ज्यादा (2093 488 के खिलाफ) है।
asn1crypto, जिसका मैंने उल्लेख किया, हमने विचार नहीं किया, क्योंकि परियोजना अभी अपनी प्रारंभिक अवस्था में थी, और हमने इसके बारे में नहीं सुना था। अब वे उसकी दिशा में देखना शुरू नहीं करेंगे, क्योंकि मैंने तुरंत ही पता लगा लिया था कि एक ही सामान्यीकृत समय यह एक मनमाना रूप नहीं लेता है, और धारावाहिक करते समय, यह चुपचाप एक सेकंड के अंशों को हटा देता है। यह X.509 प्रमाणपत्रों के साथ काम करने के लिए स्वीकार्य है, लेकिन सामान्य तौर पर यह काम नहीं करेगा।
फिलहाल, PyDERASN मुक्त Python / Go DER decoders मुझे पता है की सबसे कठोर है। मेरे पसंदीदा गो की एन्कोडिंग / asn1 लाइब्रेरी में, OBJECT IDENTIFIER और UTCTime / GeneralizedTime स्ट्रिंग्स
पर कोई सख्त जाँच नहीं है । कभी-कभी सख्ती हस्तक्षेप कर सकती है (सबसे पहले, पुराने अनुप्रयोगों के साथ पिछड़े संगतता के कारण जो कोई भी ठीक नहीं करेगा), इसलिए डिकोडिंग के दौरान PyDERASN में आप
विभिन्न सेटिंग्स कमजोर पड़ने वाले चेक पास कर सकते हैं।
प्रोजेक्ट कोड यथासंभव सरल होने की कोशिश करता है। पूरी लाइब्रेरी एक सिंगल फाइल है। अनावश्यक प्रदर्शन और DRY कोड अनुकूलन के बिना कोड को समझने में आसानी पर जोर देने के साथ लिखा गया है। ऐसा नहीं है, जैसा कि मैंने पहले ही कहा था, UTCTime / GeneralizedTime स्ट्रिंग्स के पूर्ण-विकसित BER डिकोडिंग के साथ-साथ REAL, RELATIVE OID, EXTERNAL, INSTANCE OF, EMBEDED PDV, CHARACTER STRING डेटा प्रकारों का समर्थन करें। अन्य सभी मामलों में, व्यक्तिगत रूप से, मुझे पायथन में अन्य पुस्तकालयों का उपयोग करने का कोई कारण नहीं दिखता है।
मेरी सभी परियोजनाओं की तरह, जैसे कि
PyGOST ,
GoGOST ,
NNCP ,
GoVPN , PyDERASN पूरी तरह से
LGPLv3 + की शर्तों के तहत वितरित
मुफ्त सॉफ्टवेयर है , और मुफ्त डाउनलोड के लिए उपलब्ध है। उपयोग के उदाहरण
यहां PyGOST परीक्षणों में हैं ।
सर्गेई मतवेव ,
सिफर बैंक ,
ओपन सोसाइटी फाउंडेशन फाउंडेशन के सदस्य, पायथन / गो-डेवलपर,
एफएसयूई के मुख्य विशेषज्ञ
"एसटीसी एटलस" ।