
यह एक शक्तिशाली, अत्यधिक भरी हुई प्रणाली बनाने के लिए हमारे कांटेदार पथ के बारे में एक लंबी कहानी की निरंतरता है जो एक्सचेंज के संचालन को सुनिश्चित करता है।
पहला भाग यहाँ है ।
रहस्यमयी गलती
कई परीक्षणों के बाद, अपडेटेड ट्रेडिंग और क्लियरिंग सिस्टम को चालू कर दिया गया था, और हम एक बग में भाग गए जिसके बारे में एक रहस्यमय जासूसी कहानी लिखना सही था।
मुख्य सर्वर पर शुरू होने के तुरंत बाद, लेनदेन में से एक को त्रुटि के साथ संसाधित किया गया था। उसी समय, बैकअप सर्वर पर सब कुछ क्रम में था। यह पता चला कि मुख्य सर्वर पर घातांक की गणना के एक सरल गणितीय ऑपरेशन ने एक वैध तर्क से नकारात्मक परिणाम दिया! सर्वेक्षण जारी रहा, और SSE2 रजिस्टर में उन्हें एक बिट में अंतर मिला, जो फ्लोटिंग पॉइंट नंबरों के साथ काम करने के दौरान राउंडिंग के लिए जिम्मेदार है।
उन्होंने घातांक बिट सेट के साथ प्रतिपादक की गणना के लिए एक सरल परीक्षण उपयोगिता लिखी। यह पता चला कि रेडहैट लिनक्स के जिस संस्करण का हमने उपयोग किया था, उसमें एक गणितीय फ़ंक्शन के साथ काम करने में एक बग था जब बीमार बिट को सम्मिलित किया गया था। हमने रेडहैट को इसकी सूचना दी, थोड़ी देर बाद हमने उनसे एक पैच प्राप्त किया और इसे रोल किया। त्रुटि अब नहीं हुई, लेकिन यह स्पष्ट नहीं था कि यह बिट कहां से आया है? सी से
fesetround फ़ंक्शन इसके लिए जिम्मेदार था। हमने कथित त्रुटि की तलाश में हमारे कोड का सावधानीपूर्वक विश्लेषण किया: सभी संभावित स्थितियों की जांच की; उन सभी कार्यों पर विचार किया जो गोलाई का उपयोग करते थे; एक असफल सत्र खेलने की कोशिश की; विभिन्न विकल्पों के साथ अलग-अलग संकलक का उपयोग किया; स्थिर और गतिशील विश्लेषण का उपयोग किया।
त्रुटि का कारण नहीं मिल सका।
फिर उन्होंने हार्डवेयर की जांच करना शुरू किया: उन्होंने प्रोसेसर का लोड परीक्षण किया; RAM की जाँच की; यहां तक कि एक सेल में एक बहु-बिट त्रुटि के बहुत ही संभावनाहीन परिदृश्य के लिए परीक्षण किए गए। कोई फायदा नहीं हुआ।
अंत में, वे उच्च-ऊर्जा भौतिकी की दुनिया से सिद्धांतों पर बस गए: कुछ उच्च-ऊर्जा कण हमारे डेटा सेंटर में उड़ गए, शरीर की दीवार के माध्यम से टूट गए, प्रोसेसर को मारा और ट्रिगर कुंडी को उसी बिट में छड़ी करने का कारण बना। इस बेतुके सिद्धांत को "न्यूट्रिनो" कहा जाता था। यदि आप प्राथमिक कण भौतिकी से दूर हैं: न्यूट्रिनोस शायद ही बाहरी दुनिया के साथ बातचीत करते हैं, और निश्चित रूप से वे प्रोसेसर को प्रभावित करने में सक्षम नहीं हैं।
चूंकि यह विफलता का कारण ढूंढना संभव नहीं था, बस मामले में उन्होंने ऑपरेशन से "अपराधी" सर्वर को बाहर कर दिया।
कुछ समय बाद, हमने हॉट स्टैंडबाय सिस्टम में सुधार करना शुरू किया: हमने तथाकथित "वार्म रिजर्व" (एसिंक्रोनस प्रतिकृति) को पेश किया। उन्हें लेनदेन की एक धारा मिली जो विभिन्न डेटा केंद्रों में हो सकती है, लेकिन गर्म अन्य सर्वरों के साथ सक्रिय बातचीत का समर्थन नहीं करती है।
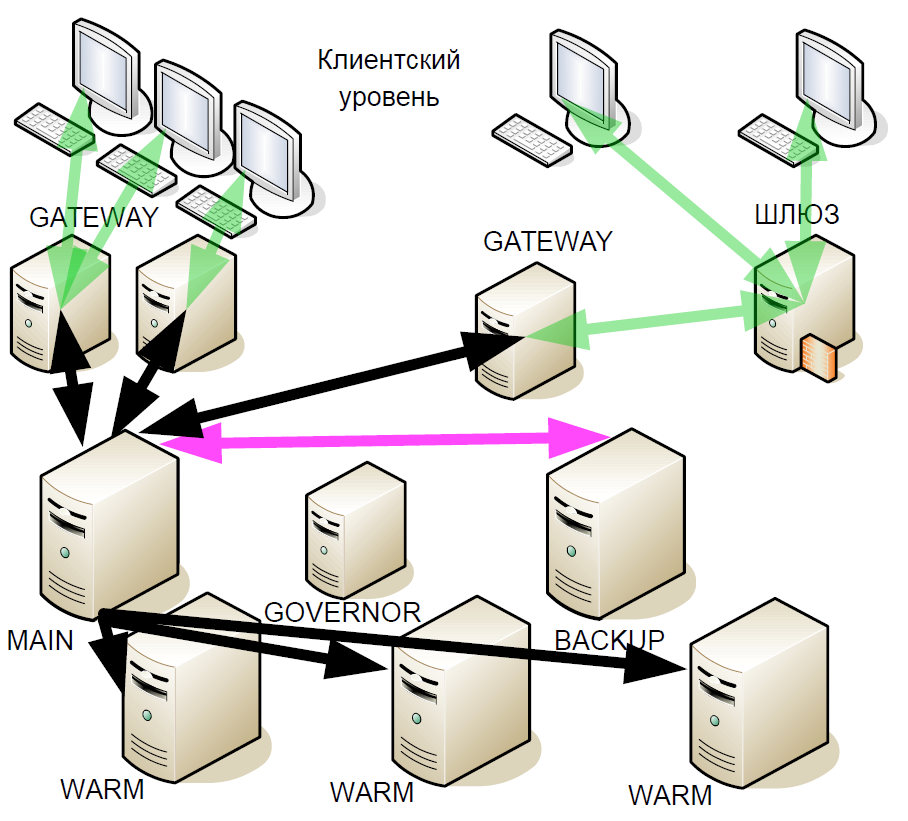
ऐसा क्यों किया गया? यदि बैकअप सर्वर विफल हो जाता है, तो मुख्य सर्वर से गर्म होना नया बैकअप बन जाता है। यही है, एक विफलता के बाद, सिस्टम एक मुख्य सर्वर के साथ ट्रेडिंग सत्र के अंत तक नहीं रहता है।
और जब सिस्टम के नए संस्करण का परीक्षण किया गया और ऑपरेशन में डाला गया, तो फिर से राउंडिंग बिट के साथ एक त्रुटि उत्पन्न हुई। इसके अलावा, वार्म-सर्वरों की संख्या में वृद्धि के साथ, त्रुटि अधिक बार दिखाई देने लगी। इस मामले में, विक्रेता के पास पेश करने के लिए कुछ भी नहीं था, क्योंकि कोई ठोस सबूत नहीं है।
स्थिति के अगले विश्लेषण के दौरान, यह सिद्धांत उत्पन्न हुआ कि समस्या ओएस से संबंधित हो सकती है। हमने एक सरल प्रोग्राम लिखा था जो एक अंतहीन लूप में
fesetround फ़ंक्शन को कॉल करता है, वर्तमान स्थिति को याद करता है और इसे नींद के माध्यम से जांचता है, और यह कई प्रतिस्पर्धी थ्रेड्स में किया जाता है। नींद के मापदंडों और थ्रेड्स की संख्या का चयन करने के बाद, हमने उपयोगिता के लगभग 5 मिनट के बाद बिट विफलता को सख्ती से पुन: उत्पन्न करना शुरू कर दिया। हालाँकि, Red Hat समर्थन इसे पुन: उत्पन्न करने में असमर्थ था। हमारे अन्य सर्वरों के परीक्षण से पता चला कि केवल कुछ निश्चित प्रोसेसर वाले ही त्रुटि से प्रभावित हैं। उसी समय, एक नए कोर में संक्रमण ने समस्या को हल किया। अंत में, हमने बस OS को बदल दिया, और बग का सही कारण स्पष्ट नहीं रहा।
और अचानक पिछले साल एक लेख "
हेराफेरी प्रोसेसर में बग मैं कैसे मिला " पर दिखाई दिया। इसमें वर्णित स्थिति हमारे लिए बहुत समान थी, लेकिन लेखक ने जांच में आगे बढ़ाया और सिद्धांत को उन्नत किया कि त्रुटि माइक्रोकोड में थी। और लिनक्स कर्नेल को अपडेट करते समय, निर्माता माइक्रोकोड को भी अपडेट करते हैं।
प्रणाली का और विकास
यद्यपि हमें त्रुटि से छुटकारा मिल गया, लेकिन इस कहानी ने हमें सिस्टम की वास्तुकला पर फिर से विचार किया। आखिरकार, हम इस तरह के कीड़े की पुनरावृत्ति से सुरक्षित नहीं थे।
निम्नलिखित सिद्धांतों ने बैकअप सिस्टम में और सुधार के लिए आधार बनाया:
- आप किसी पर भी भरोसा नहीं कर सकते। नौकर ठीक से काम नहीं कर सकते हैं।
- अधिकांश अतिरेक।
- सहमति निर्माण। बहुसंख्यक अतिरेक के लिए एक तार्किक पूरक के रूप में।
- दोहरी असफलताएं संभव हैं।
- जीवन शक्ति। नई गर्म स्पेयर योजना पिछले एक से भी बदतर नहीं होनी चाहिए। अंतिम सर्वर तक व्यापार सुचारू रूप से चलना चाहिए।
- देरी से थोड़ी वृद्धि। किसी भी डाउनटाइम में भारी वित्तीय नुकसान होता है।
- न्यूनतम नेटवर्क इंटरैक्शन ताकि देरी यथासंभव कम हो।
- सेकंड में एक नया मास्टर सर्वर चुनें।
बाजार पर उपलब्ध समाधानों में से कोई भी हमारे अनुकूल नहीं था, और रफ़ प्रोटोकॉल केवल अपनी प्रारंभिक अवस्था में था, इसलिए हमने अपना समाधान बनाया।

नेटवर्क कनेक्टिविटी
बैकअप सिस्टम के अलावा, हमने नेटवर्क कनेक्टिविटी को आधुनिक बनाना शुरू किया। आई / ओ सबसिस्टम प्रक्रियाओं की एक भीड़ थी, जो सबसे खराब तरीके से घबराहट और देरी से प्रभावित हुई। टीसीपी कनेक्शन को संसाधित करने वाली सैकड़ों प्रक्रियाओं के बाद, हमें उनके बीच लगातार स्विच करने के लिए मजबूर किया गया था, और एक माइक्रोसेकंड पैमाने पर, यह एक लंबा ऑपरेशन है। लेकिन सबसे बुरी बात यह है कि जब एक प्रक्रिया को प्रसंस्करण के लिए एक पैकेट मिला, तो उसने इसे एक SystemV कतार में भेज दिया, और फिर एक और SystemV कतार से घटनाओं की प्रतीक्षा की। हालांकि, बड़ी संख्या में नोड्स के साथ, एक प्रक्रिया में एक नया टीसीपी पैकेट का आगमन और एक कतार में डेटा की प्राप्ति ओएस के लिए दो प्रतिस्पर्धी घटनाओं का प्रतिनिधित्व करती है। इस मामले में, यदि दोनों कार्यों के लिए कोई भौतिक प्रोसेसर उपलब्ध नहीं हैं, तो एक को संसाधित किया जाएगा, और दूसरा प्रतीक्षा कतार में खड़ा होगा। परिणामों की भविष्यवाणी करना असंभव है।
ऐसी स्थितियों में, आप गतिशील प्रक्रिया प्राथमिकता नियंत्रण लागू कर सकते हैं, लेकिन इसके लिए संसाधन-गहन प्रणाली कॉल का उपयोग करना होगा। नतीजतन, हमने क्लासिक एपोल का उपयोग करके एक धागे पर स्विच किया, इससे गति में वृद्धि हुई और लेनदेन के प्रसंस्करण समय में कमी आई। हमने SystemV के माध्यम से नेटवर्क इंटरैक्शन और इंटरैक्शन की कुछ प्रक्रियाओं से भी छुटकारा पा लिया, सिस्टम कॉल की संख्या को काफी कम कर दिया और संचालन की प्राथमिकताओं को नियंत्रित करना शुरू कर दिया। केवल एक I / O सबसिस्टम का उपयोग करके, परिदृश्य के आधार पर लगभग 8-17 माइक्रोसेकंड को बचाना संभव था। यह एकल-पिरोया योजना तब से अपरिवर्तित है, जो सभी कनेक्शनों को सेवा देने के लिए पर्याप्त है।
लेनदेन प्रसंस्करण
हमारे सिस्टम पर बढ़ते लोड को इसके सभी घटकों के आधुनिकीकरण की आवश्यकता थी। लेकिन, दुर्भाग्य से, हाल के वर्षों में प्रोसेसर घड़ी की गति में वृद्धि में ठहराव ने हमें "सिर पर" प्रक्रियाओं को स्केल करने की अनुमति नहीं दी। इसलिए, हमने इंजन प्रक्रिया को तीन स्तरों में विभाजित करने का निर्णय लिया, जिसमें से सबसे अधिक लोड जोखिम सत्यापन प्रणाली है, जो खातों में धन की उपलब्धता का आकलन करता है और लेनदेन को स्वयं बनाता है। लेकिन पैसा विभिन्न मुद्राओं में हो सकता है, और अनुरोध प्रसंस्करण को विभाजित करने के लिए किस सिद्धांत पर यह पता लगाना आवश्यक था।
तार्किक समाधान मुद्रा द्वारा विभाजित करना है: एक सर्वर डॉलर में ट्रेड करता है, दूसरा पाउंड में, और तीसरा यूरो में। लेकिन अगर इस तरह की योजना के साथ, दो मुद्राएं अलग-अलग मुद्राओं की खरीद के लिए भेजी जाती हैं, तो आउट-ऑफ-सिंक वॉलेट की समस्या होगी। और सिंक्रनाइज़ करना मुश्किल और महंगा है। इसलिए, पर्स पर अलग से और टूल्स पर अलग से शार्द करना सही होगा। वैसे, अधिकांश पश्चिमी एक्सचेंजों में जोखिमों की जांच करने का कार्य हमारे जैसा तीव्र नहीं है, इसलिए अक्सर यह ऑफ़लाइन किया जाता है। हमें एक ऑनलाइन चेक लागू करने की आवश्यकता थी।
आइए एक उदाहरण से स्पष्ट करें। व्यापारी $ 30 खरीदना चाहता है, और अनुरोध लेनदेन को मान्य करने के लिए जाता है: हम जांचते हैं कि क्या इस व्यापारी को इस ट्रेडिंग मोड की अनुमति है, क्या उसके पास आवश्यक अधिकार हैं। यदि सब कुछ क्रम में है, तो अनुरोध जोखिम सत्यापन प्रणाली में जाता है, अर्थात। लेन-देन समाप्त करने के लिए धन की पर्याप्तता को सत्यापित करने के लिए। एक नोट है कि आवश्यक राशि वर्तमान में अवरुद्ध है। इसके अलावा, अनुरोध को ट्रेडिंग सिस्टम पर पुनर्निर्देशित किया जाता है, जो इस लेनदेन को मंजूरी देता है या नहीं करता है। मान लें कि लेन-देन स्वीकृत है - फिर जोखिम सत्यापन प्रणाली नोट करती है कि धन अनलॉक किया गया है और रूबल डॉलर में परिवर्तित हो गए हैं।
सामान्य तौर पर, जोखिम सत्यापन प्रणाली में जटिल एल्गोरिदम होते हैं और बड़ी मात्रा में बहुत संसाधन-गहन गणना करते हैं, और यह केवल "खाता शेष" की जांच नहीं करता है, क्योंकि यह पहली नज़र में लग सकता है।
जब हमने इंजन प्रक्रिया को स्तरों में विभाजित करना शुरू किया, तो हम एक समस्या में भाग गए: सत्यापन और सत्यापन के चरणों में उस समय उपलब्ध कोड ने समान डेटा सरणी का सक्रिय रूप से उपयोग किया, जिसके लिए संपूर्ण कोड आधार को फिर से लिखना आवश्यक था। नतीजतन, हमने आधुनिक प्रोसेसर से निर्देशों के प्रसंस्करण के लिए एक पद्धति उधार ली: उनमें से प्रत्येक को छोटे चरणों में विभाजित किया गया है और कई कार्यों को एक चक्र में समानांतर में किया जाता है।
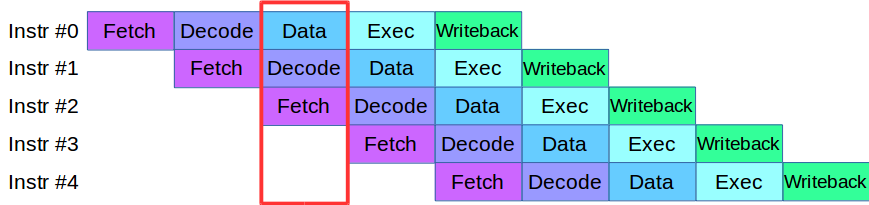
कोड के थोड़ा अनुकूलन के बाद, हमने लेनदेन के समानांतर प्रसंस्करण के लिए एक पाइपलाइन बनाई, जिसमें लेनदेन को पाइपलाइन के 4 चरणों में विभाजित किया गया था: नेटवर्क इंटरैक्शन, सत्यापन, निष्पादन और परिणाम का प्रकाशन।

एक उदाहरण पर विचार करें। हमारे पास दो प्रोसेसिंग सिस्टम, सीरियल और समानांतर हैं। पहला लेन-देन आता है, और दोनों प्रणालियों में यह सत्यापन के लिए जाता है। फिर दूसरा लेन-देन आता है: एक समानांतर प्रणाली में, इसे तुरंत काम पर ले जाया जाता है, और एक अनुक्रमिक प्रणाली में यह मौजूदा प्रसंस्करण चरण के माध्यम से जाने के लिए पहले लेनदेन की प्रतीक्षा में कतारबद्ध है। यही है, पाइपलाइनिंग का मुख्य लाभ यह है कि हम लेनदेन कतार को तेजी से संसाधित करते हैं।
तो हमें एएसटीएस + सिस्टम मिला।
सच है, कन्वेयर के साथ भी, सब कुछ इतना सहज नहीं है। मान लीजिए कि हमारे पास एक लेनदेन है जो पड़ोसी लेनदेन में डेटा सरणियों को प्रभावित करता है, यह विनिमय के लिए एक विशिष्ट स्थिति है। इस तरह के लेनदेन को पाइपलाइन में निष्पादित नहीं किया जा सकता है, क्योंकि यह दूसरों को प्रभावित कर सकता है। इस स्थिति को डेटा खतरा कहा जाता है, और इस तरह के लेनदेन को बस अलग से संसाधित किया जाता है: जब कतार में "तेज़" लेनदेन समाप्त होता है, तो पाइप लाइन बंद हो जाती है, सिस्टम "धीमी" लेनदेन की प्रक्रिया करता है और फिर पाइपलाइन को फिर से शुरू करता है। सौभाग्य से, कुल प्रवाह में इस तरह के लेनदेन का हिस्सा बहुत कम है, इसलिए पाइपलाइन शायद ही कभी बंद हो जाती है ताकि यह समग्र प्रदर्शन को प्रभावित न करे।

फिर हमने निष्पादन के तीन थ्रेड्स को सिंक्रनाइज़ करने की समस्या को हल करना शुरू किया। नतीजतन, निश्चित आकार के कोशिकाओं के साथ एक परिपत्र बफर पर आधारित एक प्रणाली का जन्म हुआ। इस प्रणाली में, सब कुछ प्रसंस्करण गति के अधीन है, डेटा की प्रतिलिपि नहीं बनाई गई है।
- सभी आने वाले नेटवर्क पैकेट आवंटन चरण में आते हैं।
- हम उन्हें एक सरणी में रखते हैं और चिह्नित करते हैं कि वे चरण संख्या 1 के लिए उपलब्ध हैं।
- दूसरा लेन-देन आया, यह फिर से चरण संख्या 1 के लिए उपलब्ध है।
- पहला प्रसंस्करण प्रवाह उपलब्ध लेनदेन को देखता है, उन्हें संसाधित करता है, और उन्हें दूसरे प्रसंस्करण प्रवाह के अगले चरण में स्थानांतरित करता है।
- फिर यह पहले लेनदेन को संसाधित करता है और
deleted ध्वज के साथ संबंधित सेल को चिह्नित करता है - अब यह नए उपयोग के लिए उपलब्ध है।
इस प्रकार, पूरी कतार संसाधित होती है।
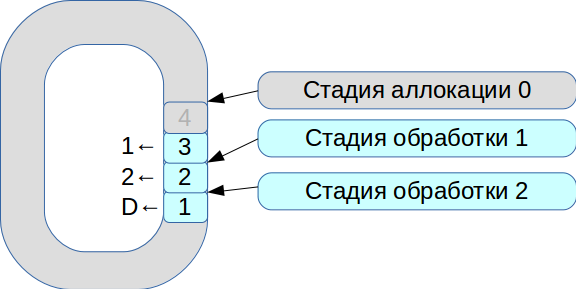
प्रत्येक चरण के प्रसंस्करण में माइक्रोसेकंड की इकाइयाँ या दसियों लगते हैं। और यदि आप मानक ओएस सिंक्रनाइज़ेशन योजनाओं का उपयोग करते हैं, तो हम सिंक्रनाइज़ेशन पर ही अधिक समय खो देंगे। इसलिए, हमने स्पिनलॉक का उपयोग करना शुरू कर दिया। हालांकि, यह एक वास्तविक समय प्रणाली में बहुत खराब स्वर है, और RedHat दृढ़ता से ऐसा नहीं करने की सिफारिश करता है, इसलिए हम 100 एमएस के लिए स्पिनलॉक का उपयोग करते हैं, और फिर गतिरोध की संभावना को बाहर करने के लिए सेमीफोर मोड में जाते हैं।
नतीजतन, हमने प्रति सेकंड लगभग 8 मिलियन लेनदेन का प्रदर्शन हासिल किया। और सिर्फ दो महीने बाद, एलमैक्स डिस्ट्रॉक्टर के बारे में एक
लेख में, उन्होंने उसी कार्यक्षमता के साथ एक सर्किट का विवरण देखा।
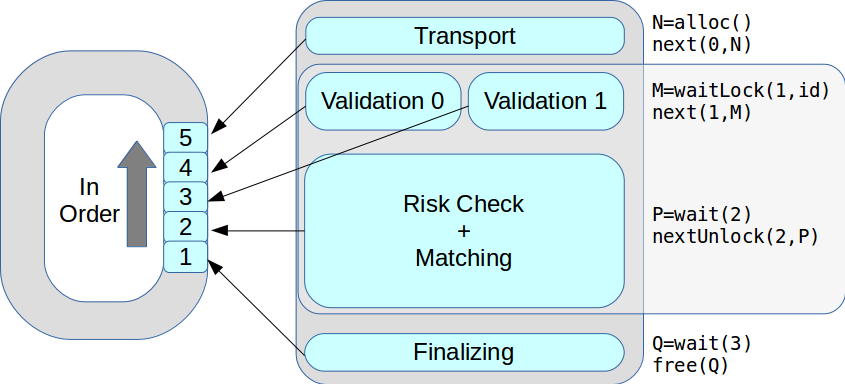
अब एक चरण में निष्पादन के कई सूत्र हो सकते हैं। प्राप्त आदेश में, सभी लेनदेन बदले में संसाधित किए गए थे। परिणामस्वरूप, चोटी का प्रदर्शन 18 हजार से बढ़कर 50 हजार प्रति सेकंड हो गया।
एक्सचेंज रिस्क मैनेजमेंट सिस्टम
पूर्णता की कोई सीमा नहीं है, और जल्द ही हमने फिर से आधुनिकीकरण करना शुरू किया: एएसटीएस + के ढांचे के भीतर, हमने जोखिम प्रबंधन प्रणालियों और निपटान कार्यों को स्वायत्त घटकों में स्थानांतरित करना शुरू कर दिया। हमने एक लचीली आधुनिक वास्तुकला और एक नया पदानुक्रमित जोखिम मॉडल विकसित किया, जहां भी संभव हो
double बजाय
fixed_point क्लास का उपयोग करने की कोशिश की।
लेकिन तुरंत समस्या पैदा हुई: कई वर्षों से काम कर रहे सभी व्यावसायिक तर्क को सिंक्रनाइज़ करने और इसे नई प्रणाली में स्थानांतरित करने के लिए कैसे? नतीजतन, नई प्रणाली के प्रोटोटाइप के पहले संस्करण को छोड़ना पड़ा। दूसरा संस्करण, जो वर्तमान में उत्पादन में काम कर रहा है, उसी कोड पर आधारित है जो व्यापारिक भाग और जोखिम दोनों में काम करता है। विकास के दौरान, सबसे कठिन काम दोनों संस्करणों के बीच गिट मर्ज करना था। हमारे सहयोगी एवगेनी मज़ुरेनोक ने हर हफ्ते इस ऑपरेशन को अंजाम दिया और हर बार बहुत लंबे समय तक शाप दिया।
एक नई प्रणाली का चयन करते समय, हमें तुरंत बातचीत की समस्या को हल करना पड़ा। डेटा बस चुनते समय, स्थिर घबराना और न्यूनतम देरी सुनिश्चित करना आवश्यक था। इसके लिए, InfiniBand RDMA नेटवर्क सबसे उपयुक्त है: औसत प्रसंस्करण समय 10 G ईथरनेट नेटवर्क की तुलना में 4 गुना कम है। लेकिन वास्तविक अंतर प्रतिशत में था - 99 और 99.9।
बेशक, InfiniBand की अपनी कठिनाइयाँ हैं। सबसे पहले, एक और एपीआई सॉकेट के बजाय ibverbs है। दूसरे, लगभग कोई भी व्यापक रूप से उपलब्ध ओपन सोर्स मैसेजिंग समाधान नहीं हैं। हमने अपना प्रोटोटाइप बनाने की कोशिश की, लेकिन यह बहुत मुश्किल हो गया, इसलिए हमने एक वाणिज्यिक समाधान चुना - कॉन्फिनिटी लो लेटेंसी मैसेजिंग (पूर्व में आईबीएम एमक्यू एलएलएम)।
तब जोखिम प्रणाली के सही पृथक्करण की समस्या उत्पन्न हुई। यदि आप केवल जोखिम इंजन को निकालते हैं और मध्यवर्ती नोड नहीं बनाते हैं, तो दो स्रोतों से लेनदेन को मिलाया जा सकता है।
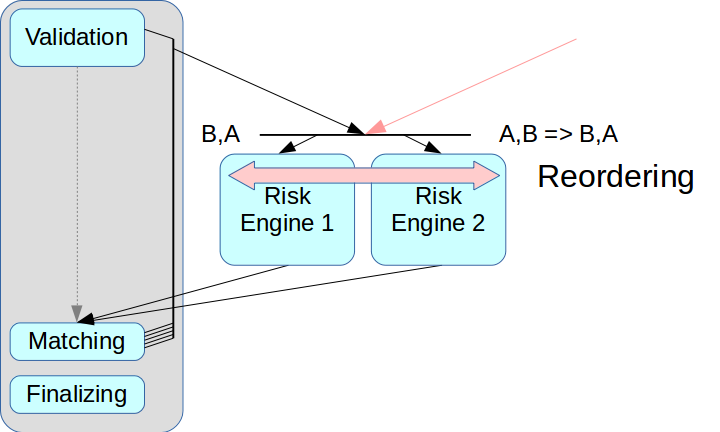
तथाकथित अल्ट्रा लो लेटेंसी सॉल्यूशंस में एक री-मोडिंग मोड होता है: दो स्रोतों से लेन-देन को रसीद पर सही क्रम में व्यवस्थित किया जा सकता है, यह अनुक्रम के बारे में जानकारी के आदान-प्रदान के लिए एक अलग चैनल का उपयोग करके महसूस किया जाता है। लेकिन हम इस मोड को अभी तक लागू नहीं करते हैं: यह पूरी प्रक्रिया को जटिल बनाता है, और कुछ समाधानों में यह बिल्कुल भी समर्थित नहीं है। इसके अलावा, प्रत्येक लेनदेन को उपयुक्त टाइमस्टैम्प सौंपा जाना चाहिए, और हमारी योजना में इस तंत्र को सही ढंग से लागू करना बहुत मुश्किल है। इसलिए, हमने संदेश ब्रोकर के साथ क्लासिक योजना का उपयोग किया, अर्थात् एक डिस्पैचर के साथ जो जोखिम इंजन के बीच संदेश वितरित करता है।
दूसरी समस्या क्लाइंट एक्सेस से संबंधित थी: यदि कई रिस्क गेटवे हैं, तो क्लाइंट को उनमें से प्रत्येक से कनेक्ट करने की आवश्यकता है, और इसके लिए आपको क्लाइंट लेयर में बदलाव करना होगा। हम इस स्तर पर इससे दूर होना चाहते थे, इसलिए वर्तमान जोखिम गेटवे योजना में वे संपूर्ण डेटा स्ट्रीम की प्रक्रिया करते हैं। यह गंभीर रूप से अधिकतम थ्रूपुट को सीमित करता है, लेकिन सिस्टम एकीकरण को बहुत सरल करता है।
प्रतिलिपि
हमारे सिस्टम में विफलता का एक भी बिंदु नहीं होना चाहिए, अर्थात, सभी घटकों को डुप्लिकेट किया जाना चाहिए, जिसमें एक संदेश ब्रोकर भी शामिल है। हमने CLLM सिस्टम का उपयोग करके इस समस्या को हल किया: इसमें RCMS क्लस्टर शामिल है जिसमें दो डिस्पैचर मास्टर-स्लेव मोड में काम कर सकते हैं, और जब कोई विफल होता है, तो सिस्टम स्वचालित रूप से दूसरे पर स्विच हो जाता है।
बैकअप डेटा सेंटर के साथ काम करें
InfiniBand को स्थानीय नेटवर्क के रूप में काम करने के लिए अनुकूलित किया गया है, अर्थात रैक-माउंट उपकरण को जोड़ने के लिए, और दो भौगोलिक रूप से वितरित डेटा केंद्रों के बीच InfiniBand नेटवर्क बिछाने का कोई तरीका नहीं है। इसलिए, हमने एक पुल / डिस्पैचर लागू किया जो नियमित ईथरनेट नेटवर्क के माध्यम से संदेश स्टोर से जुड़ता है और दूसरे आईबी नेटवर्क के लिए सभी लेनदेन को रिले करता है। जब आपको डेटा सेंटर से माइग्रेशन की आवश्यकता होती है, तो हम यह चुन सकते हैं कि अब किस डेटा सेंटर के साथ काम करना है।
परिणाम
उपरोक्त सभी एक बार में नहीं किया गया था, इसने एक नई वास्तुकला के विकास के कई पुनरावृत्तियों को लिया। हमने एक महीने में प्रोटोटाइप बनाया, लेकिन काम करने की स्थिति को अंतिम रूप देने में दो साल से अधिक का समय लगा। हमने लेनदेन प्रसंस्करण की अवधि बढ़ाने और प्रणाली की विश्वसनीयता बढ़ाने के बीच सबसे अच्छा समझौता करने की कोशिश की।
चूंकि सिस्टम बहुत अपडेट था, इसलिए हमने दो स्वतंत्र स्रोतों से डेटा रिकवरी को लागू किया। यदि किसी कारण से मैसेज स्टोर सही तरीके से काम नहीं कर रहा है, तो आप लेन-देन लॉग को दूसरे स्रोत - रिस्क इंजन से ले सकते हैं। पूरे सिस्टम में इस सिद्धांत का सम्मान किया जाता है।
अन्य बातों के अलावा, हम क्लाइंट एपीआई को बनाए रखने में कामयाब रहे ताकि न तो दलालों और न ही किसी और को नई वास्तुकला के लिए एक महत्वपूर्ण परिवर्तन की आवश्यकता हो। मुझे कुछ इंटरफेस बदलने पड़े, लेकिन मुझे काम के मॉडल में महत्वपूर्ण बदलाव करने की आवश्यकता नहीं थी।
हमने अपने मंच रीबस के वर्तमान संस्करण को बुलाया - वास्तुकला, जोखिम इंजन और बस में दो सबसे उल्लेखनीय नवाचारों के लिए एक संक्षिप्त नाम के रूप में।
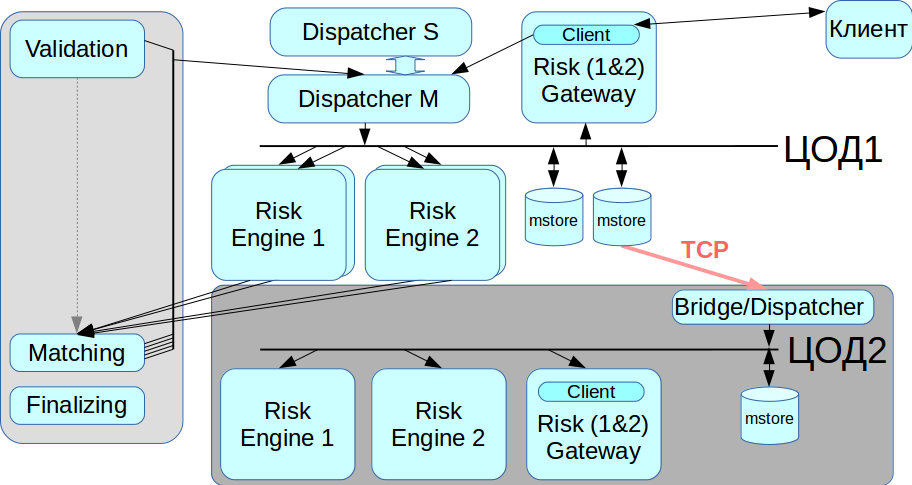
प्रारंभ में, हम केवल समाशोधन भाग को उजागर करना चाहते थे, लेकिन परिणाम एक बड़ी वितरित प्रणाली थी। अब ग्राहक या तो ट्रेडिंग गेटवे के साथ, या क्लियरिंग के साथ, या दोनों पर एक साथ बातचीत कर सकते हैं।
आखिरकार हमने क्या हासिल किया:

देरी के स्तर को कम किया। लेनदेन की एक छोटी मात्रा के साथ, सिस्टम पिछले संस्करण के समान ही काम करता है, लेकिन एक ही समय में बहुत अधिक भार का सामना करता है।
पीक उत्पादकता 50 हजार से बढ़कर 180 हजार लेनदेन प्रति सेकंड हो गई। सूचना की एक और धारा आगे की वृद्धि में बाधक है।
आगे सुधार करने के दो तरीके हैं: गेटवे के साथ काम की योजना का मिलान और परिवर्तन करना। अब सभी गेटवे प्रतिकृति योजना के अनुसार काम करते हैं, जो इस लोड पर सामान्य रूप से कार्य करना बंद कर देता है।अंत में, मैं उन लोगों को कुछ सलाह दे सकता हूं जो उद्यम प्रणाली विकसित कर रहे हैं:- हर समय सबसे खराब के लिए तैयार रहें। समस्याएं हमेशा अप्रत्याशित रूप से सामने आती हैं।
- आमतौर पर वास्तुकला को फिर से बनाना असंभव है। खासकर अगर आपको विभिन्न प्रकार के संकेतकों में अधिकतम विश्वसनीयता प्राप्त करने की आवश्यकता है। अधिक नोड्स, समर्थन के लिए अधिक संसाधनों की आवश्यकता होती है।
- सभी विशेष और मालिकाना समाधानों को अतिरिक्त रूप से अनुसंधान, सहायता और समर्थन के लिए संसाधनों की आवश्यकता होगी।
- विफलताओं के बाद विश्वसनीयता और सिस्टम पुनर्प्राप्ति के मुद्दों को हल करने को स्थगित न करें, उन्हें डिजाइन के प्रारंभिक चरण पर विचार करें।