अकेले संयुक्त राज्य अमेरिका में, 3 मिलियन विकलांग लोग हैं जो अपने घरों को नहीं छोड़ सकते हैं। हेल्पर रोबोट जो स्वचालित रूप से लंबी दूरी की यात्रा कर सकते हैं, इन लोगों को भोजन, दवा और पैकेज लाकर उन्हें अधिक स्वतंत्र बना सकते हैं। अध्ययनों से पता चलता है कि सुदृढीकरण (ओपी) के साथ गहन शिक्षण कच्चे इनपुट डेटा और कार्यों की तुलना करने के लिए अच्छी तरह से अनुकूल है, उदाहरण के लिए,
वस्तुओं को
पकड़ने या
रोबोट को स्थानांतरित करने के लिए सीखने के लिए, लेकिन आमतौर पर ओपी
एजेंटों में लंबी दूरी के लिए सुरक्षित अभिविन्यास के लिए आवश्यक बड़े भौतिक रिक्त स्थान की समझ की कमी होती है। मानव सहायता के बिना दूरियां और एक नए वातावरण के लिए अनुकूलन।
हाल के तीन कार्यों में, "
AOP के साथ खरोंच से ओरिएंटियरिंग प्रशिक्षण ", "
PRM-RL: सुदृढीकरण प्रशिक्षण और पैटर्न-आधारित योजना के संयोजन का उपयोग करके लंबी दूरी पर रोबोट ओरिएंटियरिंग को लागू करना " और "
PRM-RL के साथ लंबी दूरी की ओरिएंटियरिंग "
, हम स्वायत्त रोबोटों का अध्ययन करते हैं जो आसानी से एक नए वातावरण में अनुकूल हो जाते हैं, लंबी अवधि की योजना के साथ गहरे ओपी का संयोजन करते हैं। हम स्थानीय योजनाकार एजेंटों को सिखाते हैं कि अभिविन्यास के लिए आवश्यक बुनियादी क्रियाओं को कैसे किया जाए और चलती वस्तुओं के साथ टकराव के बिना छोटी दूरी कैसे तय की जाए। स्थानीय योजनाकार एक-आयामी लिडार जैसे सेंसर का उपयोग करके शोर पर्यावरणीय अवलोकन करते हैं जो एक बाधा को दूरी प्रदान करते हैं और रोबोट को नियंत्रित करने के लिए रैखिक और कोणीय गति प्रदान करते हैं। हम स्वचालित सुदृढीकरण सीखने (एओपी) का उपयोग करके सिमुलेशन में स्थानीय योजनाकार को प्रशिक्षित करते हैं, एक विधि जो ओपी के लिए पुरस्कार और तंत्रिका नेटवर्क की वास्तुकला के लिए खोज को स्वचालित करती है। 10-15 मीटर की सीमित सीमा के बावजूद, स्थानीय योजनाकार वास्तविक रोबोट और नए, पहले के अज्ञात वातावरण में उपयोग करने के लिए दोनों को अच्छी तरह से अनुकूलित करते हैं। यह आपको बड़े रिक्त स्थान पर अभिविन्यास के लिए बिल्डिंग ब्लॉक्स के रूप में उपयोग करने की अनुमति देता है। फिर हम एक रोड मैप बनाते हैं, एक ग्राफ जहां नोड्स अलग-अलग खंड होते हैं, और किनारों को नोड्स से केवल तभी कनेक्ट किया जाता है जब स्थानीय योजनाकार, अच्छी तरह से शोर सेंसर और नियंत्रण का उपयोग करके वास्तविक रोबोटों की नकल करते हैं, उनके बीच चल सकते हैं।
स्वचालित सुदृढीकरण अधिगम (AOP)
अपने पहले काम में, हम एक स्थानीय योजनाकार को एक छोटे स्थिर वातावरण में प्रशिक्षित
करते हैं। हालांकि, जब मानक
डीपी ओपी एल्गोरिदम के साथ सीखते हैं, उदाहरण के लिए, गहरी निर्धारक ढाल (
डीडीपीजी ), कई बाधाएं हैं। उदाहरण के लिए, स्थानीय योजनाकारों का वास्तविक लक्ष्य किसी दिए गए लक्ष्य को प्राप्त करना है, जिसके परिणामस्वरूप वे दुर्लभ पुरस्कार प्राप्त करते हैं। व्यवहार में, इसके लिए शोधकर्ताओं को एल्गोरिथ्म के चरण-दर-चरण कार्यान्वयन और पुरस्कारों के मैनुअल समायोजन पर काफी समय देना पड़ता है। शोधकर्ताओं को स्पष्ट, सफल व्यंजनों के बिना तंत्रिका नेटवर्क की वास्तुकला के बारे में भी निर्णय लेना है। अंत में, DDPG जैसे एल्गोरिदम अस्थिर रूप से सीखते हैं और अक्सर
भयावह विस्मृति का प्रदर्शन करते हैं।
इन बाधाओं को दूर करने के लिए, हमने सुदृढीकरण के साथ गहरी शिक्षा को स्वचालित किया। एओपी एक गहरी ओपी के आसपास एक विकासवादी स्वचालित आवरण है, जो
बड़े पैमाने पर हाइपरपरमेट अनुकूलन के माध्यम से पुरस्कार और तंत्रिका नेटवर्क वास्तुकला की मांग करता है। यह दो चरणों में काम करता है, पुरस्कार की खोज और वास्तुकला की खोज। पुरस्कारों की खोज के दौरान, AOP एक साथ कई पीढ़ियों के लिए DDPG एजेंटों की आबादी को प्रशिक्षित करता है, और प्रत्येक का अपना थोड़ा संशोधित इनाम समारोह होता है, जो स्थानीय योजनाकार के सही कार्य के लिए अनुकूलित होता है: पथ के समापन बिंदु तक पहुंचता है। इनाम खोज चरण के अंत में, हम एक का चयन करते हैं जो अक्सर एजेंटों को लक्ष्य की ओर ले जाता है। तंत्रिका नेटवर्क वास्तुकला के खोज चरण में, हम इस प्रक्रिया को दोहराते हैं, इस दौड़ के लिए चयनित पुरस्कार का उपयोग करते हुए और नेटवर्क परतों को समायोजित करते हुए, संचयी पुरस्कार का अनुकूलन करते हैं।
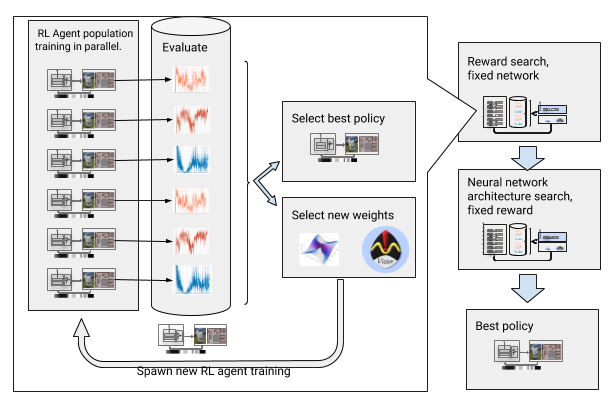 तंत्रिका नेटवर्क के पुरस्कार और वास्तुकला की खोज के साथ एओपी
तंत्रिका नेटवर्क के पुरस्कार और वास्तुकला की खोज के साथ एओपीहालाँकि, यह चरण-दर-चरण प्रक्रिया AOP को नमूनों की संख्या के संदर्भ में अप्रभावी बनाती है। 100 एजेंटों की 10 पीढ़ियों के साथ एओपी प्रशिक्षण के लिए 5 बिलियन नमूनों की आवश्यकता होती है, जो 32 वर्षों के अध्ययन के बराबर है! फायदा यह है कि एओपी के बाद, मैनुअल सीखने की प्रक्रिया स्वचालित है, और डीडीपीजी में भयावह भूल नहीं है। सबसे महत्वपूर्ण बात, अंतिम नीतियों की गुणवत्ता अधिक है - वे सेंसर, ड्राइव और स्थानीयकरण से शोर के प्रतिरोधी हैं, और नए वातावरण के लिए सामान्यीकृत हैं। हमारी सर्वोत्तम नीति हमारे परीक्षण स्थलों पर अन्य अभिविन्यास विधियों की तुलना में 26% अधिक सफल है।
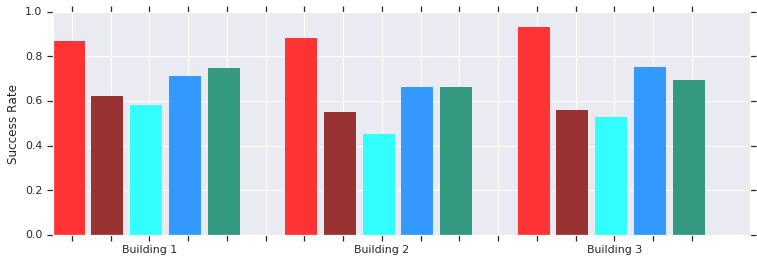 रेड - एओपी कई पूर्व अज्ञात इमारतों में कम दूरी (10 मीटर तक) पर सफल होता है। मैन्युअल रूप से प्रशिक्षित DDPG (गहरा लाल), कृत्रिम संभावित क्षेत्रों (नीला), गतिशील खिड़की (नीला) और व्यवहार क्लोनिंग (हरा) के साथ तुलना।स्थानीय AOP अनुसूचक नीति वास्तविक असंरचित वातावरण में रोबोट के साथ अच्छी तरह से काम करती है
रेड - एओपी कई पूर्व अज्ञात इमारतों में कम दूरी (10 मीटर तक) पर सफल होता है। मैन्युअल रूप से प्रशिक्षित DDPG (गहरा लाल), कृत्रिम संभावित क्षेत्रों (नीला), गतिशील खिड़की (नीला) और व्यवहार क्लोनिंग (हरा) के साथ तुलना।स्थानीय AOP अनुसूचक नीति वास्तविक असंरचित वातावरण में रोबोट के साथ अच्छी तरह से काम करती हैऔर यद्यपि ये राजनेता केवल स्थानीय अभिविन्यास में सक्षम हैं, वे चलती बाधाओं के प्रति प्रतिरोधी हैं और असंरचित वातावरण में वास्तविक रोबोटों द्वारा अच्छी तरह से सहन किए जाते हैं। और यद्यपि उन्हें स्थैतिक वस्तुओं के साथ सिमुलेशन में प्रशिक्षित किया गया था, वे प्रभावी रूप से गतिशील लोगों के साथ सामना करते हैं। अगला कदम AOP नीतियों को नमूना-आधारित योजना के साथ जोड़ना है ताकि उनके कार्य क्षेत्र का विस्तार किया जा सके और उन्हें लंबी दूरी तय करने का तरीका सिखाया जा सके।
पीआरएम-आरएल के साथ लंबी दूरी की अभिविन्यास
पैटर्न-आधारित नियोजक लंबी दूरी की अभिविन्यास के साथ काम करते हैं, रोबोट आंदोलनों को अनुमानित करते हैं। उदाहरण के लिए, एक रोबोट वर्गों के बीच संक्रमण रास्तों को खींचकर
संभाव्य रोडमैप (PRMs) बनाता
है । हमारे
दूसरे काम में , जिसने
आईसीआरए 2018 सम्मेलन में पुरस्कार जीता, हम स्थानीय रूप से रोबोटों को प्रशिक्षित करने और फिर उन्हें अन्य वातावरणों के अनुकूल बनाने के लिए पीआरएम को मैन्युअल रूप से ट्यून किए गए स्थानीय ओपी शेड्यूलर्स (बिना एओपी) के साथ जोड़ते हैं।
सबसे पहले, प्रत्येक रोबोट के लिए, हम एक सामान्यीकृत सिमुलेशन में स्थानीय अनुसूचक नीति को प्रशिक्षित करते हैं। फिर हम इस नीति को ध्यान में रखते हुए एक PRM बनाते हैं, तथाकथित PRM-RL, पर्यावरण के मानचित्र पर आधारित है जहाँ इसका उपयोग किया जाएगा। उसी कार्ड का उपयोग किसी भी रोबोट के लिए किया जा सकता है जिसे हम भवन में उपयोग करना चाहते हैं।
PRM-RL बनाने के लिए, हम नमूनों को नोड्स से तभी जोड़ते हैं जब स्थानीय ओपी-शेड्यूलर मज़बूती से और बार-बार उनके बीच आ-जा सकें। यह एक मोंटे कार्लो सिमुलेशन में किया गया है। परिणामस्वरूप मानचित्र किसी विशेष रोबोट की क्षमताओं और ज्यामिति के अनुरूप है। एक ही ज्यामिति वाले रोबोट के लिए कार्ड, लेकिन विभिन्न सेंसर और ड्राइव के साथ, अलग कनेक्टिविटी होगी। चूंकि एजेंट कोने के चारों ओर घूम सकता है, इसलिए नोड्स जो कि सीधी रेखा में नहीं हैं, उन्हें भी चालू किया जा सकता है। हालांकि, दीवारों और बाधाओं से सटे नोड्स सेंसर शोर के कारण मानचित्र में शामिल होने की कम संभावना होगी। रन टाइम पर, ओपी एजेंट एक से दूसरे सेक्शन में मैप पर जाता है।
 बेतरतीब ढंग से चयनित जोड़ी नोड्स के लिए तीन मोंटे कार्लो सिमुलेशन के साथ एक नक्शा बनाया गया है
बेतरतीब ढंग से चयनित जोड़ी नोड्स के लिए तीन मोंटे कार्लो सिमुलेशन के साथ एक नक्शा बनाया गया है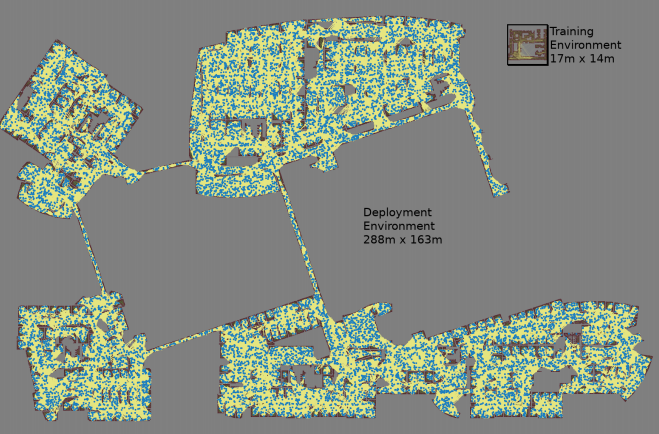 सबसे बड़ा नक्शा 288x163 मीटर आकार का था और इसमें लगभग 700,000 किनारे थे। 300 कर्मचारियों ने इसे 4 दिनों के लिए एकत्र किया, 1.1 बिलियन टकराव की जाँच की।तीसरा काम
सबसे बड़ा नक्शा 288x163 मीटर आकार का था और इसमें लगभग 700,000 किनारे थे। 300 कर्मचारियों ने इसे 4 दिनों के लिए एकत्र किया, 1.1 बिलियन टकराव की जाँच की।तीसरा काम मूल PRM-RL में कई सुधार प्रदान करता है। सबसे पहले, हम स्थानीय AOP अनुसूचियों के साथ मैन्युअल रूप से ट्यून किए गए DDPG की जगह ले रहे हैं, जो लंबी दूरी पर अभिविन्यास में सुधार देता है। दूसरे,
एक साथ स्थानीयकरण और अंकन (
एसएलएएम ) के
नक्शे जोड़े जाते हैं, जो रोबोट सड़क निर्माण के स्रोत के रूप में रनटाइम पर उपयोग करते हैं। SLAM कार्ड शोर के अधीन हैं, और यह "सिम्युलेटर और वास्तविकता के बीच अंतर" को बंद कर देता है, रोबोटिक्स में एक प्रसिद्ध समस्या है, जिसके कारण सिमुलेशन में प्रशिक्षित एजेंट वास्तविक दुनिया में बहुत बुरा व्यवहार करते हैं। सिमुलेशन में हमारी सफलता का स्तर वास्तविक रोबोटों की सफलता के स्तर के साथ मेल खाता है। और अंत में, हमने वितरित भवन मानचित्र जोड़े, इसलिए हम 700,000 नोड्स तक के बहुत बड़े मानचित्र बना सकते हैं।
हमने अपने एओपी एजेंट की मदद से इस पद्धति का मूल्यांकन किया, जिसने केवल पसलियों सहित 200 से अधिक बार क्षेत्र में प्रशिक्षण वातावरण से अधिक इमारतों के चित्र के आधार पर नक्शे बनाए, जो 20 प्रयासों में 90% मामलों में सफलतापूर्वक पूरा किया गया था। हमने PRM-RL की तुलना विभिन्न तरीकों से 100 मीटर तक की दूरी पर की, जो स्थानीय योजनाकार की सीमा से काफी अधिक थी। पीआरएम-आरएल ने नोड्स के सही कनेक्शन के कारण पारंपरिक तरीकों की तुलना में 2-3 गुना अधिक सफलता हासिल की, जो रोबोट की क्षमताओं के लिए उपयुक्त है।
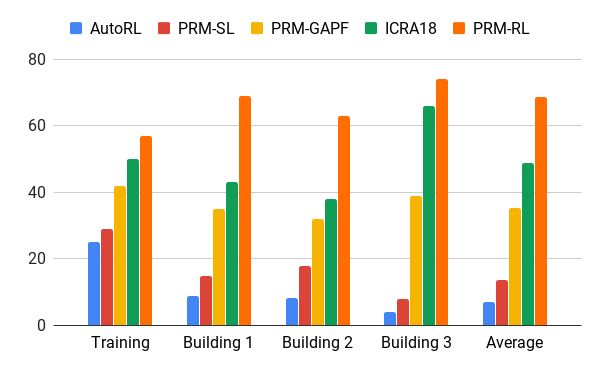 विभिन्न भवनों में 100 मीटर चलने में सफलता दर। ब्लू - स्थानीय एओपी अनुसूचक, पहली नौकरी; लाल - मूल पीआरएम; पीला - कृत्रिम संभावित क्षेत्र; हरा दूसरा काम है; लाल - तीसरी नौकरी, AOP के साथ PRM।
विभिन्न भवनों में 100 मीटर चलने में सफलता दर। ब्लू - स्थानीय एओपी अनुसूचक, पहली नौकरी; लाल - मूल पीआरएम; पीला - कृत्रिम संभावित क्षेत्र; हरा दूसरा काम है; लाल - तीसरी नौकरी, AOP के साथ PRM।हमने कई इमारतों में कई वास्तविक रोबोटों पर PRM-RL का परीक्षण किया। नीचे परीक्षण सूट में से एक है; रोबोट सबसे अधिक गड़बड़ स्थानों और क्षेत्रों को छोड़कर लगभग हर जगह चलता है, जो SLAM कार्ड से आगे निकलते हैं।

निष्कर्ष
मशीन अभिविन्यास गंभीरता से हानि वाले लोगों की स्वतंत्रता को बढ़ा सकता है। यह स्वायत्त रोबोटों को विकसित करके प्राप्त किया जा सकता है जो आसानी से पर्यावरण के लिए अनुकूल हो सकते हैं, और मौजूदा जानकारी के आधार पर नए वातावरण में कार्यान्वयन के लिए उपलब्ध तरीके। यह एओपी के साथ छोटी दूरी के लिए बुनियादी अभिविन्यास प्रशिक्षण को स्वचालित करके, और फिर रोडमैप बनाने के लिए एसएलएएम कार्ड के साथ अधिग्रहीत कौशल का उपयोग करके किया जा सकता है। रोडमैप में पसलियों से जुड़े नोड्स होते हैं, जिन पर रोबोट मज़बूती से कदम रख सकते हैं। नतीजतन, एक रोबोट व्यवहार नीति विकसित की जाती है, जिसे एक प्रशिक्षण के बाद, विभिन्न वातावरणों में इस्तेमाल किया जा सकता है और विशेष रूप से रोबोट के लिए अनुकूलित रोडमैप जारी कर सकता है।