उनकी व्यावसायिक गतिविधियों के हिस्से के रूप में, डेवलपर्स, पैंटेस्टर्स और सुरक्षा पेशेवरों को वल्नेरेबिलिटी मैनेजमेंट (वीएम), (सिक्योर) एसडीएलसी जैसी प्रक्रियाओं से निपटना पड़ता है।
इन वाक्यांशों के तहत अलग-अलग प्रथाओं और साधनों का उपयोग किया जाता है, जिन्हें आपस में जोड़ा जाता है, हालांकि उनके उपभोक्ता भिन्न हैं।
तकनीकी प्रगति अभी तक बुनियादी ढांचे और सॉफ्टवेयर की सुरक्षा का विश्लेषण करने के लिए एक उपकरण के साथ एक व्यक्ति की जगह लेने के बिंदु तक नहीं पहुंची है।
यह समझना दिलचस्प है कि ऐसा क्यों है, और आपको किन समस्याओं का सामना करना पड़ता है।
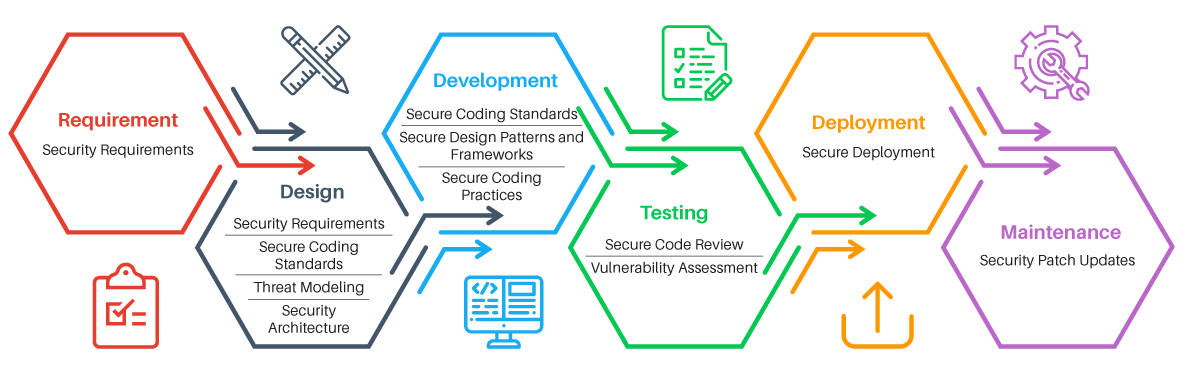
प्रक्रियाओं
बुनियादी ढांचे की सुरक्षा और पैच प्रबंधन की निरंतर निगरानी के लिए वल्नरेबिलिटी मैनेजमेंट प्रक्रिया का उद्देश्य है।
सिक्योर एसडीएलसी प्रक्रिया ("सुरक्षित विकास चक्र") को विकास और संचालन के दौरान अनुप्रयोग सुरक्षा का समर्थन करने के लिए डिज़ाइन किया गया है।
इन प्रक्रियाओं का एक समान हिस्सा कमजोरता मूल्यांकन प्रक्रिया है - भेद्यता मूल्यांकन, भेद्यता स्कैनिंग।
वीएम और एसडीएलसी के भीतर स्कैनिंग में मुख्य अंतर यह है कि पहले मामले में, लक्ष्य तीसरे पक्ष के सॉफ़्टवेयर में या कॉन्फ़िगरेशन में ज्ञात कमजोरियों का पता लगाना है। उदाहरण के लिए, विंडोज का एक पुराना संस्करण या एसएनएमपी के लिए डिफ़ॉल्ट समुदाय स्ट्रिंग।
दूसरे मामले में, लक्ष्य न केवल तीसरे पक्ष के घटकों (निर्भरता) में कमजोरियों का पता लगाना है, लेकिन मुख्य रूप से नए उत्पाद के कोड में है।
यह उपकरण और दृष्टिकोण में अंतर को जन्म देता है। मेरी राय में, एप्लिकेशन में नई कमजोरियों को खोजने का कार्य बहुत अधिक दिलचस्प है, क्योंकि यह फिंगरप्रिंटिंग संस्करणों, बैनर एकत्र करना, पासवर्ड सॉर्ट करना आदि के लिए नीचे नहीं आता है।
एप्लिकेशन की कमजोरियों की उच्च-गुणवत्ता वाली स्वचालित स्कैनिंग के लिए एल्गोरिदम की आवश्यकता होती है जो आवेदन के शब्दार्थ, इसके उद्देश्य, विशिष्ट खतरों को ध्यान में रखते हैं।
अवसंरचना स्कैनर को अक्सर टाइमर द्वारा प्रतिस्थापित किया जा सकता है, क्योंकि
एवेलोनोव ने इसे रखा था। मुद्दा यह है कि, विशुद्ध रूप से सांख्यिकीय रूप से, आप अपने बुनियादी ढांचे को कमजोर मान सकते हैं यदि आपने इसे अपडेट नहीं किया है, तो कहें, एक महीने।
उपकरण
स्कैनिंग, साथ ही साथ सुरक्षा विश्लेषण, एक ब्लैक बॉक्स या एक सफेद बॉक्स के रूप में किया जा सकता है।
ब्लैक बॉक्स
ब्लैकबॉक्स स्कैनिंग करते समय, उपकरण को उसी इंटरफेस के माध्यम से सेवा के साथ काम करने में सक्षम होना चाहिए जिसके माध्यम से उपयोगकर्ता इसके साथ काम करते हैं।
इन्फ्रास्ट्रक्चर स्कैनर (टेनबल नेसस, क्वालिस, मैक्सपैट्रॉल, रैपिड 7 नेक्सपोज आदि) खुले नेटवर्क पोर्ट की तलाश करते हैं, "बैनर" इकट्ठा करते हैं, इंस्टॉल किए गए सॉफ़्टवेयर संस्करणों को निर्धारित करते हैं और अपने ज्ञानकोष में इन संस्करणों में कमजोरियों के बारे में जानकारी की तलाश करते हैं। वे कॉन्फ़िगरेशन त्रुटियों का पता लगाने का भी प्रयास करते हैं, जैसे डिफ़ॉल्ट पासवर्ड या डेटा तक खुली पहुंच, कमजोर एसएसएल सिफर, आदि।
वेब एप्लिकेशन स्कैनर (एक्यूनेटिक्स डब्ल्यूवीएस, नेटस्केप, बर्प सूट, ओडब्ल्यूएएसपी जेडएपी, आदि) भी ज्ञात घटकों और उनके संस्करणों (उदाहरण के लिए, सीएमएस, फ्रेमवर्क, जेएस लाइब्रेरी) का निर्धारण करने का तरीका जानते हैं। स्कैनर के मुख्य चरण क्रॉलिंग और फ़ज़िंग हैं।
क्रॉलिंग के दौरान, स्कैनर मौजूदा एप्लिकेशन इंटरफेस, HTTP मापदंडों के बारे में जानकारी एकत्र करता है। फ़ज़िंग के दौरान, सभी ज्ञात मापदंडों को एक त्रुटि को भड़काने और भेद्यता का पता लगाने के लिए उत्परिवर्तित या उत्पन्न डेटा के साथ प्रतिस्थापित किया जाता है।
इस तरह के एप्लिकेशन स्कैनर क्रमशः DAST और IAST कक्षाओं के हैं - डायनेमिक और इंटरेक्टिव एप्लिकेशन सुरक्षा परीक्षण।
सफेद बॉक्स
व्हाइटबॉक्स स्कैन में अधिक अंतर है।
पूरी प्रक्रिया के दौरान, वीएम स्कैनर (वूलर्स, इंसिक्योरिटी काउच, वलस, टेनएबल नेसस इत्यादि) को अक्सर एक प्रामाणिक स्कैन करके सिस्टम तक पहुंच दी जाती है। इस प्रकार, स्कैनर नेटवर्क सेवाओं के बैनर पर अनुमान लगाए बिना, सिस्टम से सीधे संकुल और कॉन्फ़िगरेशन मापदंडों के स्थापित संस्करण डाउनलोड कर सकता है।
स्कैन अधिक सटीक और पूर्ण है।
यदि हम अनुप्रयोगों के व्हाइटबॉक्स स्कैनिंग (CheckMarx, HP Fortify, Coverity, RIPS, FindSecBugs, इत्यादि) के बारे में बात करते हैं, तो हम आमतौर पर स्थैतिक कोड विश्लेषण और SAST वर्ग के संगत उपकरणों के उपयोग के बारे में बात करते हैं - स्टेटिक अनुप्रयोग सुरक्षा परीक्षण।
समस्याओं
स्कैनिंग के साथ कई समस्याएं हैं! मुझे उनमें से अधिकांश के साथ व्यक्तिगत रूप से स्कैनिंग प्रक्रियाओं और सुरक्षित विकास के निर्माण के लिए एक सेवा प्रदान करने के ढांचे में, और साथ ही साथ जब विश्लेषण विश्लेषण कार्य करना है।
मैं समस्याओं के 3 मुख्य समूहों को एकल करूँगा, जो विभिन्न कंपनियों में सूचना सुरक्षा सेवाओं के इंजीनियरों और प्रबंधकों के साथ बातचीत द्वारा पुष्टि की जाती है।
वेब अनुप्रयोग स्कैन समस्याएँ
- कार्यान्वयन की जटिलता। स्कैनर्स को तैनात करने, कॉन्फ़िगर करने, प्रत्येक एप्लिकेशन के लिए अनुकूलित करने, स्कैन के लिए एक परीक्षण वातावरण आवंटित करने और CI / CD प्रक्रिया को लागू करने के लिए प्रभावी होने की आवश्यकता है। अन्यथा, यह एक बेकार औपचारिक प्रक्रिया होगी, जिससे केवल झूठी सकारात्मकता निकल जाएगी
- स्कैन अवधि। स्कैनर्स, 2019 में भी, इंटरफ़ेस कटौती के साथ खराब प्रदर्शन करते हैं और प्रत्येक पर 10 मापदंडों के साथ 10 दिनों के लिए हजारों पृष्ठों को स्कैन कर सकते हैं, उन्हें अलग-अलग मान सकते हैं, हालांकि उनके लिए एक ही कोड जिम्मेदार है। उसी समय, विकास चक्र के भीतर उत्पादन के लिए तैनात करने का निर्णय जल्दी से किया जाना चाहिए
- स्कैंटी की सिफारिशें। स्कैनर्स काफी सामान्य सिफारिशें देते हैं, और डेवलपर के लिए यह हमेशा संभव नहीं होता है कि वह जल्दी से यह समझ सके कि जोखिम के स्तर को कैसे कम किया जाए, और सबसे महत्वपूर्ण बात यह है कि इसे अभी करने की जरूरत है, या डरने की जरूरत नहीं है।
- आवेदन पर विनाशकारी प्रभाव। स्कैनर्स एप्लिकेशन पर एक DoS हमले को अच्छी तरह से अंजाम दे सकते हैं, और वे बड़ी संख्या में संस्थाएँ भी बना सकते हैं या मौजूदा लोगों को संशोधित कर सकते हैं (उदाहरण के लिए, एक ब्लॉग पर दसियों हज़ारों टिप्पणियाँ बनाएँ), इसलिए दिमाग़ी तौर पर उत्पादों में स्कैन न करें
- कम गुणवत्ता भेद्यता का पता लगाने। स्कैनर्स आमतौर पर एक निश्चित पेलोड सरणी का उपयोग करते हैं और आसानी से एक भेद्यता को अनदेखा कर सकते हैं जो उनके ज्ञात एप्लिकेशन व्यवहार परिदृश्य में फिट नहीं होती है।
- स्कैनर एप्लिकेशन के कार्यों को नहीं समझता है। स्कैनर्स खुद नहीं जानते कि "इंटरनेट बैंकिंग", "भुगतान" और "कमेंट्री" क्या हैं। उनके लिए, केवल लिंक और पैरामीटर हैं, ताकि व्यापार तर्क में संभावित कमजोरियों की एक बड़ी परत पूरी तरह से उजागर हो, वे दोहरे-लिखने का अनुमान नहीं लगाएंगे, आईडी द्वारा अन्य लोगों के डेटा को झांकना या गोलाई के माध्यम से संतुलन को हवा देना।
- पृष्ठ शब्दार्थ की स्कैनर गलतफहमी। स्कैनर्स एफएक्यू को पढ़ना नहीं जानते हैं, वे नहीं जानते कि कैप्चा कैसे पहचाना जाए, खुद से वे अनुमान नहीं लगाते हैं कि कैसे पंजीकरण करना है, और फिर लॉग इन करने की आवश्यकता है, कि आप "लॉगआउट" पर क्लिक नहीं कर सकते हैं, और पैरामीटर मान बदलते हुए अनुरोधों पर हस्ताक्षर कैसे करें। परिणामस्वरूप, अधिकांश एप्लिकेशन को स्कैन नहीं किया जा सकता है।
स्रोत कोड स्कैनिंग मुद्दे
- झूठी सकारात्मकता। स्थैतिक विश्लेषण एक मुश्किल काम है, जिसे हल करने में बहुत सारे समझौते का सहारा लेना आवश्यक है। अक्सर आपको सटीकता का बलिदान करना पड़ता है, और यहां तक कि महंगे उद्यम स्कैनर झूठी सकारात्मकता की एक बड़ी मात्रा का उत्पादन करते हैं
- कार्यान्वयन की जटिलता। स्थैतिक विश्लेषण की सटीकता और पूर्णता बढ़ाने के लिए, स्कैनिंग नियमों को परिष्कृत करना आवश्यक है, और इन नियमों को लिखना बहुत समय लेने वाला हो सकता है। कभी-कभी कोड में सभी स्थानों को किसी प्रकार की बग के साथ ढूंढना और उन्हें ठीक करना आसान होता है, जैसे कि इस तरह के मामलों का पता लगाने के लिए नियम लिखना
- निर्भरता समर्थन का अभाव। बड़ी परियोजनाएं बड़ी संख्या में पुस्तकालयों और रूपरेखाओं पर निर्भर करती हैं जो प्रोग्रामिंग भाषा की क्षमताओं का विस्तार करती हैं। यदि स्कैनर के नॉलेज बेस में इन फ्रेमवर्क में "सिंक" के बारे में जानकारी नहीं है, तो यह एक ब्लाइंड स्पॉट बन जाएगा और स्कैनर केवल कोड को भी समझ नहीं पाएगा
- स्कैन अवधि। एल्गोरिदम के संदर्भ में कोड में कमजोरियों को खोजना एक मुश्किल काम है। इसलिए, इस प्रक्रिया में देरी हो सकती है और महत्वपूर्ण कंप्यूटिंग संसाधनों की आवश्यकता होती है।
- कम कवरेज। संसाधनों की खपत और स्कैन की अवधि के बावजूद, SAST टूल के डेवलपर्स को अभी भी उन सभी परिस्थितियों से समझौता करने और विश्लेषण करने का सहारा लेना पड़ता है जिनमें कार्यक्रम हो सकता है
- खोज की पुनरुत्पादकता। एक विशिष्ट रेखा की ओर इशारा करते हुए और कॉल स्टैक जो एक भेद्यता की ओर ले जाता है, ठीक है, लेकिन वास्तव में स्कैनर अक्सर बाहरी भेद्यता की जांच करने के लिए पर्याप्त जानकारी प्रदान नहीं करता है। आखिरकार, एक दोष मृत कोड में भी हो सकता है, जो एक हमलावर के लिए अप्राप्य है
इन्फ्रास्ट्रक्चर स्कैनिंग मुद्दे
- अपर्याप्त इन्वेंट्री। बड़े इन्फ्रास्ट्रक्चर में, विशेष रूप से भौगोलिक रूप से अलग, यह समझने में अक्सर सबसे कठिन होता है कि कौन से मेजबानों को स्कैन करने की आवश्यकता है। दूसरे शब्दों में, स्कैन कार्य परिसंपत्ति प्रबंधन कार्य के साथ निकटता से संबंधित है।
- खराब प्राथमिकता। नेटवर्क स्कैनर अक्सर कमियों के साथ कई परिणाम उत्पन्न करते हैं जो व्यवहार में शोषक नहीं होते हैं, लेकिन औपचारिक रूप से उनका जोखिम स्तर अधिक होता है। उपभोक्ता को एक रिपोर्ट मिलती है जिसकी व्याख्या करना मुश्किल है, और यह स्पष्ट नहीं है कि पहले क्या तय किया जाना चाहिए
- स्कैंटी की सिफारिशें। स्कैनर के ज्ञान का आधार अक्सर भेद्यता और इसे ठीक करने के बारे में बहुत ही सामान्य जानकारी है, इसलिए प्रशासकों को Google के साथ स्वयं को जोड़ना होगा। व्हाइटबॉक्स स्कैनर के साथ स्थिति थोड़ी बेहतर है जो ठीक करने के लिए एक विशिष्ट आदेश जारी कर सकती है
- मैनुअल काम करते हैं। इन्फ्रास्ट्रक्चर में कई नोड्स हो सकते हैं, जिसका अर्थ है कि संभावित रूप से कई कमियां हैं, जिन पर रिपोर्ट को प्रत्येक पुनरावृत्ति पर मैन्युअल रूप से विघटित और विश्लेषण किया जाना है
- खराब कवरेज। इन्फ्रास्ट्रक्चर स्कैनिंग की गुणवत्ता सीधे कमजोरियों और सॉफ़्टवेयर संस्करणों के बारे में ज्ञान के आधार की मात्रा पर निर्भर करती है। इसी समय, यह पता चला है कि यहां तक कि बाजार के नेताओं के पास व्यापक ज्ञान का आधार नहीं है, और मुफ्त समाधान के डेटाबेस में बहुत सारी जानकारी है जो नेताओं के पास नहीं है
- पैचिंग की समस्या। बुनियादी ढांचे में कमजोरियों के लिए सबसे आम पैच पैकेज को अपडेट करना या कॉन्फ़िगरेशन फ़ाइल को बदलना है। यहां बड़ी समस्या यह है कि सिस्टम, विशेष रूप से विरासत, अपग्रेड के परिणामस्वरूप अप्रत्याशित व्यवहार कर सकता है। संक्षेप में, आपको उत्पादन में जीवित बुनियादी ढांचे पर एकीकरण परीक्षण करना होगा
दृष्टिकोण
कैसे हो सकता है?
मैं आपको उदाहरणों के बारे में अधिक बताऊंगा और निम्नलिखित भागों में इन समस्याओं से कैसे निपटा जाए, लेकिन अब मैं उन मुख्य क्षेत्रों के बारे में बताता हूँ जिनमें आप काम कर सकते हैं:
- विभिन्न स्कैनिंग उपकरणों का एकत्रीकरण। कई स्कैनर के सही उपयोग के साथ, ज्ञान के आधार और पहचान की गुणवत्ता में उल्लेखनीय वृद्धि हासिल की जा सकती है। आप अलग-अलग लॉन्च किए गए सभी स्कैनरों की तुलना में अधिक कमजोरियां पा सकते हैं, जबकि जोखिम के स्तर का अधिक सटीक आकलन करना और अधिक सिफारिशें देना संभव है
- SAST और DAST का एकीकरण। आप उनके बीच जानकारी साझा करके DAST कवरेज और SAST सटीकता बढ़ा सकते हैं। स्रोत से आप मौजूदा मार्गों के बारे में जानकारी प्राप्त कर सकते हैं, और डीएएसटी का उपयोग करके यह देख सकते हैं कि बाहर से भेद्यता दिखाई दे रही है या नहीं
- मशीन लर्निंग ™ । 2015 में, मैंने हैकर्स के अंतर्ज्ञान को देने और उन्हें गति देने के लिए आंकड़ों का उपयोग करने के बारे में (और अभी तक ) बात की । यह निश्चित रूप से भविष्य के स्वचालित सुरक्षा विश्लेषण के विकास के लिए भोजन है।
- ऑटोटैस्ट और ओपनएपीआई के साथ आईएएसटी का एकीकरण। CI / CD-पाइपलाइन के ढांचे के भीतर, HTTP प्रॉक्सी और HTTP पर काम करने वाले कार्यात्मक परीक्षणों के रूप में काम करने वाले टूल के आधार पर एक स्कैनिंग प्रक्रिया बनाना संभव है। OpenAPI / स्वैगर परीक्षण और अनुबंध स्कैनर को डेटा स्ट्रीम के बारे में गुम जानकारी देगा, और विभिन्न राज्यों में एप्लिकेशन को स्कैन करना संभव बना देगा
- सही विन्यास। प्रत्येक एप्लिकेशन और बुनियादी ढांचे के लिए, आपको एक उपयुक्त स्कैन प्रोफ़ाइल बनाने की आवश्यकता होती है जो उपयोग किए जाने वाले इंटरफेस, प्रौद्योगिकियों की संख्या और प्रकृति को ध्यान में रखता है
- स्कैनर का अनुकूलन। अक्सर, स्कैनर को अंतिम रूप दिए बिना किसी एप्लिकेशन को स्कैन नहीं किया जा सकता है। एक उदाहरण एक भुगतान गेटवे है जिसमें प्रत्येक अनुरोध पर हस्ताक्षर किए जाने चाहिए। गेटवे प्रोटोकॉल के लिए एक कनेक्टर को लिखे बिना, स्कैनर गलत हस्ताक्षर के साथ अनुरोधों को ध्यान से हरा देगा। एक विशेष प्रकार के दोष के लिए विशेष स्कैनर लिखना आवश्यक है, जैसे कि असुरक्षित प्रत्यक्ष वस्तु संदर्भ
- जोखिम प्रबंधन। बाहरी प्रणालियों के साथ विभिन्न स्कैनर और एकीकरण का उपयोग करना, जैसे कि एसेट मैनेजमेंट और थ्रेट मैनेजमेंट, आपको जोखिम के स्तर का आकलन करने के लिए कई मापदंडों का उपयोग करने की अनुमति देगा, ताकि प्रबंधन को विकास या बुनियादी ढांचे की वर्तमान सुरक्षा स्थिति की पर्याप्त तस्वीर मिल सके।
देखते रहो और चलो भेद्यता स्कैनिंग को बाधित!