पिछली बार जब हमने डेटा संगतता के बारे में बात की थी, तो उपयोगकर्ता की आंखों के माध्यम से लेनदेन के अलगाव के विभिन्न स्तरों के बीच अंतर को देखा, और पता लगाया कि यह जानना क्यों महत्वपूर्ण है। अब हम सीखना शुरू कर रहे हैं कि PostgreSQL छवि-आधारित अलगाव और बहु-संस्करण तंत्र को कैसे लागू करता है।
इस लेख में, हम देखेंगे कि डेटा फ़ाइलों और पृष्ठों में भौतिक रूप से कैसे स्थित है। यह हमें अलगाव के विषय से दूर ले जाता है, लेकिन आगे की सामग्री को समझने के लिए इस तरह के एक विषयांतर आवश्यक है। हमें यह समझने की आवश्यकता है कि निम्न-स्तरीय डेटा संग्रहण कैसे काम करता है।
रिश्ता (संबंधों)
यदि आप टेबल और इंडेक्स के अंदर देखते हैं, तो यह पता चला है कि वे एक समान तरीके से व्यवस्थित हैं। दोनों कि, और एक और - बेस ऑब्जेक्ट्स जिसमें कुछ डेटा होते हैं जिसमें लाइनें शामिल होती हैं।
तथ्य यह है कि तालिका में पंक्तियों के होते हैं संदेह से परे है; सूचकांक के लिए, यह कम स्पष्ट है। हालांकि, एक बी-पेड़ की कल्पना करें: इसमें नोड्स होते हैं जिनमें अनुक्रमित मान और अन्य नोड्स या टेबल पंक्तियों के लिंक होते हैं। इन नोड्स को इंडेक्स लाइन्स माना जा सकता है - वास्तव में, जिस तरह से यह है।
वास्तव में, अभी भी एक समान तरीके से कई ऑब्जेक्ट व्यवस्थित किए गए हैं: अनुक्रम (अनिवार्य रूप से एकल-पंक्ति टेबल), भौतिकवादी विचार (अनिवार्य रूप से तालिकाओं जो क्वेरी को याद करते हैं)। और फिर सामान्य विचार हैं, जो स्वयं डेटा संग्रहीत नहीं करते हैं, लेकिन अन्य सभी इंद्रियों में तालिकाओं की तरह हैं।
PostgreSQL में इन सभी वस्तुओं को सामान्य शब्द
संबंध कहा जाता है। यह शब्द अत्यंत दुर्भाग्यपूर्ण है क्योंकि यह संबंधपरक सिद्धांत से एक शब्द है। आप संबंध और तालिका (दृश्य) के बीच एक समानांतर आकर्षित कर सकते हैं, लेकिन निश्चित रूप से संबंध और सूचकांक के बीच नहीं। लेकिन ऐसा हुआ: PostgreSQL की अकादमिक जड़ें खुद को महसूस करती हैं। मुझे लगता है कि पहले इसे टेबल और व्यू कहा जाता था, और बाकी समय के साथ बढ़ता गया।
इसके अलावा, सादगी के लिए, हम केवल तालिकाओं और अनुक्रमितों के बारे में बात करेंगे, लेकिन बाकी
रिश्तों की संरचना बिल्कुल एक जैसी है।
परतें (कांटे) और फाइलें
आमतौर पर, प्रत्येक संबंध में कई
परतें (कांटे) होती हैं। परतें कई प्रकार की होती हैं और उनमें से प्रत्येक में एक निश्चित प्रकार का डेटा होता है।
यदि एक परत है, तो सबसे पहले यह एक एकल
फ़ाइल द्वारा दर्शाया गया है। फ़ाइल नाम में एक संख्यात्मक पहचानकर्ता होता है जिसमें परत के नाम के अनुरूप अंत जोड़ा जा सकता है।
फ़ाइल धीरे-धीरे बढ़ती है और जब इसका आकार 1 जीबी तक पहुंचता है, तो उसी परत की अगली फ़ाइल बनाई जाती है (ऐसी फाइलें कभी-कभी
खंड कहलाती
हैं )। खंड संख्या फ़ाइल नाम के अंत में संलग्न है।
1 GB फ़ाइल आकार सीमा विभिन्न फ़ाइल सिस्टम का समर्थन करने के लिए ऐतिहासिक रूप से उत्पन्न हुई है, जिनमें से कुछ बड़ी फ़ाइलों के साथ काम नहीं कर सकती हैं। PostgreSQL (
./configure --with-segsize ) का निर्माण करते समय प्रतिबंध को बदला जा सकता है।
इस प्रकार, कई फाइलें एक डिस्क पर एक संबंध के अनुरूप हो सकती हैं। उदाहरण के लिए, एक छोटी सी मेज के लिए उनमें से 3 होंगे।
एक तालिका स्थान और एक डेटाबेस से संबंधित वस्तुओं की सभी फाइलें एक निर्देशिका में रखी जाएंगी। इसे ध्यान में रखा जाना चाहिए क्योंकि फ़ाइल सिस्टम आमतौर पर एक निर्देशिका में बड़ी संख्या में फ़ाइलों के साथ बहुत अच्छी तरह से काम नहीं करता है।
बस ध्यान दें कि फ़ाइलें, बदले में,
पृष्ठों (या
ब्लॉक ) में विभाजित होती हैं, आमतौर पर 8 केबी। हम नीचे के पृष्ठों की आंतरिक संरचना के बारे में बात करेंगे।
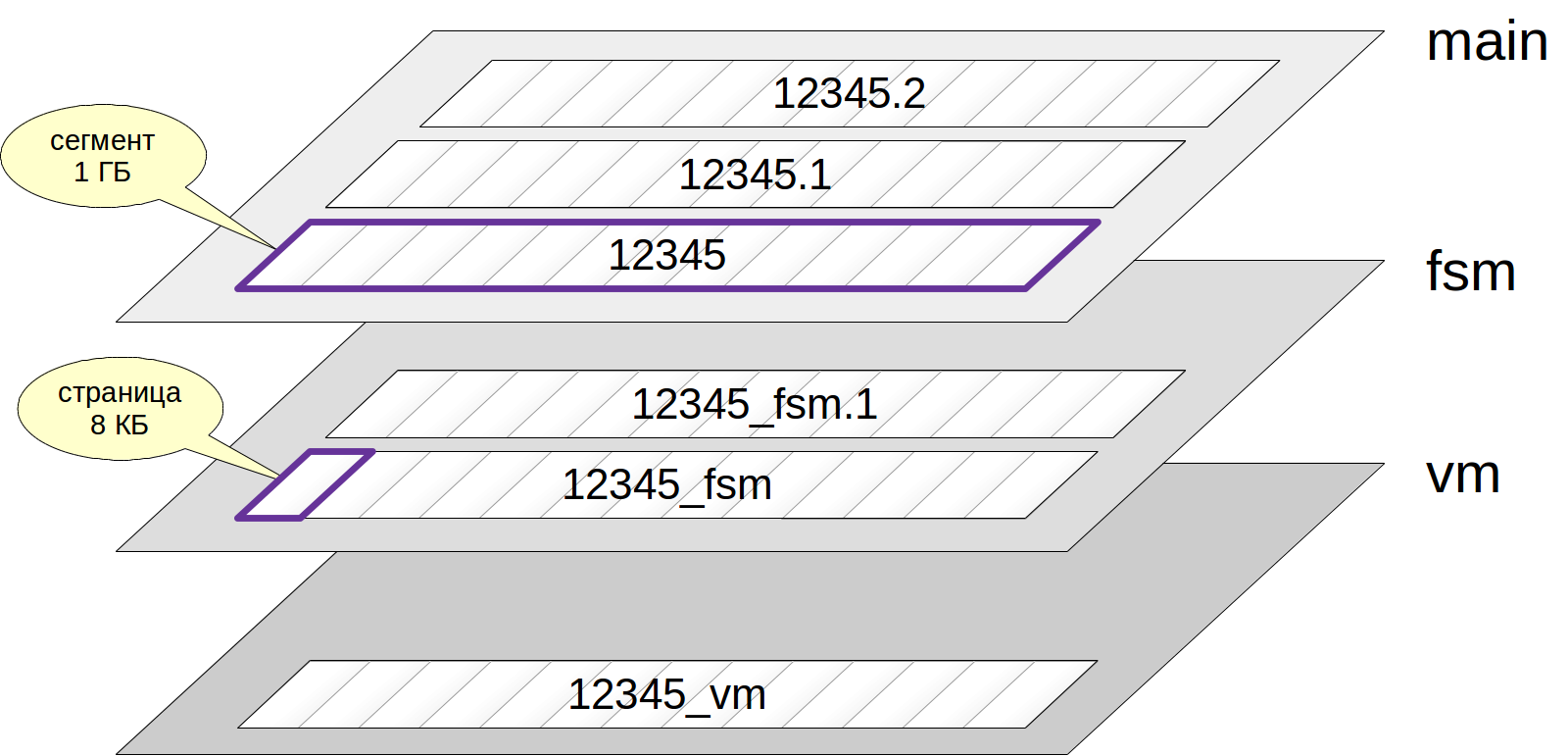
अब आइए परतों के प्रकारों को देखें।
मुख्य परत डेटा ही है: एक ही तालिका या सूचकांक पंक्तियाँ। किसी भी रिश्ते के लिए मुख्य परत मौजूद है (प्रतिनिधित्व के अलावा, जिसमें डेटा शामिल नहीं है)।
मुख्य परत में फ़ाइलों के नाम केवल एक संख्यात्मक पहचानकर्ता से मिलकर होते हैं। यहाँ टेबल फ़ाइल का एक उदाहरण पथ है जिसे हमने पिछली बार बनाया था:
=> SELECT pg_relation_filepath('accounts');
pg_relation_filepath ---------------------- base/41493/41496 (1 row)
ये पहचानकर्ता कहां से आते हैं? आधार निर्देशिका pg_default तालिकाओं से मेल खाती है, अगला उपनिर्देशिका डेटाबेस से मेल खाती है, और जिस फ़ाइल में हम रुचि रखते हैं, वह पहले से ही इसमें है:
=> SELECT oid FROM pg_database WHERE datname = 'test';
oid ------- 41493 (1 row)
=> SELECT relfilenode FROM pg_class WHERE relname = 'accounts';
relfilenode ------------- 41496 (1 row)
पथ सापेक्ष है, इसे डेटा निर्देशिका (PGDATA) से गिना जाता है। इसके अलावा, PostgreSQL में लगभग सभी पथ PGDATA से गिने जाते हैं। इसके लिए धन्यवाद, आप PGDATA को किसी अन्य स्थान पर सुरक्षित रूप से स्थानांतरित कर सकते हैं - यह कुछ भी नहीं रखता है (जब तक आपको पुस्तकालयों में LD_LIBRARY_PATH में पथ को कॉन्फ़िगर करने की आवश्यकता नहीं हो सकती है)।
हम फाइल सिस्टम में आगे देखते हैं:
postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41496
-rw------- 1 postgres postgres 8192 /var/lib/postgresql/11/main/base/41493/41496
एक प्रारंभिक परत केवल गैर-जर्नल तालिकाओं (UNLOGGED के साथ बनाई गई) और उनके अनुक्रमित के लिए मौजूद है। इस तरह की वस्तुएं आम लोगों से अलग नहीं होती हैं, सिवाय इसके कि उनके साथ की जाने वाली कार्रवाइयाँ पूर्ववर्ती लॉग में दर्ज नहीं होती हैं। इसके कारण, उनके साथ काम तेजी से होता है, लेकिन विफलता की स्थिति में एक सुसंगत स्थिति में डेटा को पुनर्स्थापित करना असंभव है। इसलिए, ठीक होने पर, PostgreSQL बस ऐसी वस्तुओं की सभी परतों को हटा देता है और प्रारंभिक परत को मुख्य परत के स्थान पर लिखता है। परिणाम एक "डमी" है। हम विस्तार से जर्नलिंग के बारे में बात करेंगे, लेकिन एक अलग चक्र में।
अकाउंट्स टेबल जर्नल की गई है, इसलिए इसके लिए कोई इनिशियलाइज़ेशन लेयर नहीं है। लेकिन प्रयोग के लिए, आप लॉगिंग को अक्षम कर सकते हैं:
=> ALTER TABLE accounts SET UNLOGGED; => SELECT pg_relation_filepath('accounts');
pg_relation_filepath ---------------------- base/41493/41507 (1 row)
फ्लाई पर जर्नलिंग को सक्षम और अक्षम करने की क्षमता, जैसा कि उदाहरण से देखा जा सकता है, विभिन्न नामों के साथ फाइलों में डेटा को ओवरराइट करना शामिल है।
आरंभीकरण परत का मुख्य परत के समान नाम है, लेकिन प्रत्यय "_init" के साथ:
postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41507_init
-rw------- 1 postgres postgres 0 /var/lib/postgresql/11/main/base/41493/41507_init
मुक्त स्थान का नक्शा (मुक्त स्थान का नक्शा) - एक परत जिसमें पृष्ठों के अंदर एक खाली जगह होती है। यह स्थान लगातार बदल रहा है: जब तारों के नए संस्करण जोड़े जाते हैं, तो यह कम हो जाता है, जबकि सफाई - यह बढ़ जाती है। रिक्त स्थान मानचित्र का उपयोग तब किया जाता है जब जल्दी से एक उपयुक्त पृष्ठ खोजने के लिए पंक्तियों के नए संस्करणों को सम्मिलित किया जाता है जिस पर जोड़ा जाने वाला डेटा फिट होगा।
मुक्त अंतरिक्ष मानचित्र में प्रत्यय "_fsm" है। लेकिन फ़ाइल तुरंत दिखाई नहीं देती है, लेकिन केवल यदि आवश्यक हो। इसे प्राप्त करने का सबसे आसान तरीका तालिका को साफ करना है (क्यों - चलो नियत समय में बात करते हैं):
=> VACUUM accounts;
postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41507_fsm
-rw------- 1 postgres postgres 24576 /var/lib/postgresql/11/main/base/41493/41507_fsm
एक दृश्यता मानचित्र एक परत है जिसमें ऐसे पृष्ठ होते हैं जिनमें केवल वर्तमान संस्करणों में तार एक बिट के साथ चिह्नित होते हैं। मोटे तौर पर, इसका मतलब है कि जब कोई लेन-देन ऐसे पृष्ठ से एक पंक्ति को पढ़ने की कोशिश करता है, तो लाइन को इसकी दृश्यता की जांच किए बिना प्रदर्शित किया जा सकता है। हम विस्तार से जांच करेंगे कि यह निम्नलिखित लेखों में कैसे होता है।
postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41507_vm
-rw------- 1 postgres postgres 8192 /var/lib/postgresql/11/main/base/41493/41507_vm
पेज
जैसा कि हमने पहले ही कहा, फाइलें तार्किक रूप से पृष्ठों में विभाजित हैं।
आमतौर पर, एक पृष्ठ आकार में 8 KB होता है। आप कुछ सीमाओं (16 KB या 32 KB) के भीतर आकार बदल सकते हैं, लेकिन केवल असेंबली (
./configure --with-blocksize ) के दौरान। इकट्ठे और चल रहे उदाहरण केवल एक आकार के पृष्ठों के साथ काम कर सकते हैं।
भले ही फाइलें किस लेयर की हों, उनका उपयोग सर्वर द्वारा लगभग उसी तरीके से किया जाता है। पृष्ठ पहले बफर कैश में पढ़े जाते हैं, जहां प्रक्रियाएं उन्हें पढ़ और संशोधित कर सकती हैं; फिर, यदि आवश्यक हो, तो पृष्ठ डिस्क पर वापस धकेल दिए जाते हैं।
प्रत्येक पृष्ठ में आंतरिक मार्कअप है और आम तौर पर निम्नलिखित अनुभाग होते हैं:
० + ----------------------------------- +
| शीर्षासन |
24 + ----------------------------------- +
| संस्करण स्ट्रिंग के लिए संकेत की सरणी |
निचला + ----------------------------------- +
| खाली स्थान |
ऊपरी + ----------------------------------- +
| पंक्ति संस्करण |
विशेष + ----------------------------------- +
| विशेष क्षेत्र |
पेजाइज़ + ----------------------------------- +
इन खंडों का आकार "शोध" पेजिन्सपेक्ट एक्सटेंशन के साथ पता लगाना आसान है:
=> CREATE EXTENSION pageinspect; => SELECT lower, upper, special, pagesize FROM page_header(get_raw_page('accounts',0));
lower | upper | special | pagesize -------+-------+---------+---------- 40 | 8016 | 8192 | 8192 (1 row)
यहां हम तालिका के पहले (शून्य) पृष्ठ का
शीर्षक देखते हैं। शेष क्षेत्रों के आकार के अलावा, हेडर में पृष्ठ के बारे में अन्य जानकारी होती है, लेकिन यह हमें अभी तक रुचि नहीं देता है।
पृष्ठ के निचले भाग में एक
विशेष क्षेत्र है , हमारे मामले में, खाली है। इसका उपयोग केवल अनुक्रमित के लिए किया जाता है, और फिर सभी के लिए नहीं। यहाँ "नीचे" तस्वीर से मेल खाती है; शायद "उच्च पते पर" कहना अधिक सही होगा।
विशेष क्षेत्र के बाद
पंक्ति संस्करण हैं - बहुत डेटा जो हम तालिका में संग्रहीत करते हैं, साथ ही कुछ ओवरहेड जानकारी।
शीर्षक के तुरंत बाद पृष्ठ के शीर्ष पर, सामग्री की तालिका है: पृष्ठ में उपलब्ध लाइनों के संस्करण के लिए
संकेत की एक
सरणी ।
लाइनों और बिंदुओं के संस्करणों के बीच
मुक्त स्थान हो सकता
है (जो मुक्त स्थान के नक्शे में चिह्नित है)। ध्यान दें कि पृष्ठ के अंदर कोई विखंडन नहीं है, सभी मुक्त स्थान हमेशा एक टुकड़े द्वारा दर्शाए जाते हैं।
संकेत
क्यों स्ट्रिंग संस्करणों के लिए संकेत आवश्यक हैं? तथ्य यह है कि सूचकांक पंक्तियों को किसी तरह तालिका में पंक्तियों के संस्करण का उल्लेख करना चाहिए। यह स्पष्ट है कि लिंक में फ़ाइल संख्या, फ़ाइल में पृष्ठ संख्या और लाइन के संस्करण के कुछ संकेत शामिल होने चाहिए। पृष्ठ की शुरुआत से एक ऑफसेट ऐसे संकेत के रूप में इस्तेमाल किया जा सकता है, लेकिन यह असुविधाजनक है। हम पृष्ठ के अंदर लाइन के संस्करण को स्थानांतरित करने में सक्षम नहीं होंगे क्योंकि यह मौजूदा लिंक को तोड़ देगा। और इससे पृष्ठों और अन्य अप्रिय परिणामों के अंदर अंतरिक्ष का विखंडन होगा। इसलिए, सूचकांक सूचकांक संख्या को संदर्भित करता है, और सूचक पृष्ठ में पंक्ति संस्करण की वर्तमान स्थिति को संदर्भित करता है। यह अप्रत्यक्ष रूप से संबोधित करता है।
प्रत्येक पॉइंटर में 4 बाइट्स होते हैं और इनमें शामिल होते हैं:
- स्ट्रिंग के संस्करण के लिए लिंक
- स्ट्रिंग के इस संस्करण की लंबाई;
- कई बिट्स जो एक स्ट्रिंग के संस्करण की स्थिति निर्धारित करते हैं।
डेटा प्रारूप
रैम में डेटा के प्रतिनिधित्व के साथ डिस्क पर डेटा प्रारूप पूरी तरह से मेल खाता है। पृष्ठ को बफ़र कैश में "जैसा है", बिना किसी परिवर्तन के पढ़ा जाता है। इसलिए, एक प्लेटफ़ॉर्म से डेटा फ़ाइलें अन्य प्लेटफ़ॉर्म के साथ असंगत हैं।
उदाहरण के लिए, x86 आर्किटेक्चर में, बाइट ऑर्डर को कम से कम महत्वपूर्ण से उच्चतम (छोटा-एंडियन) के लिए अपनाया जाता है, z / आर्किटेक्चर रिवर्स ऑर्डर (बिग-एंडियन) का उपयोग करता है, और एआरएम स्विच ऑर्डर में।
कई आर्किटेक्चर मशीन शब्द सीमाओं के पार डेटा संरेखण प्रदान करते हैं। उदाहरण के लिए, एक x86 32-बिट सिस्टम पर, पूर्णांक (पूर्णांक प्रकार, 4 बाइट्स) को 4-बाइट शब्दों की सीमा पर संरेखित किया जाएगा, साथ ही डबल-सटीक फ़्लोटिंग-पॉइंट नंबर (डबल सटीक प्रकार, 8 बाइट्स)। और 64-बिट सिस्टम पर, 8-बाइट शब्दों की सीमा पर दोहरे मूल्यों को संरेखित किया जाएगा। यह असंगति का एक और कारण है।
संरेखण के कारण, तालिका पंक्ति का आकार फ़ील्ड के क्रम पर निर्भर करता है। आमतौर पर यह प्रभाव बहुत ध्यान देने योग्य नहीं होता है, लेकिन कुछ मामलों में यह आकार में उल्लेखनीय वृद्धि कर सकता है। उदाहरण के लिए, यदि आप चार (1) और पूर्णांक फ़ील्ड को मिश्रित करते हैं, तो उनके बीच 3 बाइट आमतौर पर बर्बाद हो जाएंगे। इसके बारे में आप निकोलाई शापलोव की प्रस्तुति "
व्हाट्स इनसाइड इट " में देख सकते हैं।
स्ट्रिंग और टोस्ट संस्करण
स्ट्रिंग्स के संस्करणों को अंदर से कैसे व्यवस्थित किया जाता है, इसके बारे में हम अगली बार विस्तार से बात करेंगे। अब तक, हमारे लिए एकमात्र महत्वपूर्ण बात यह है कि प्रत्येक संस्करण को पूरी तरह से एक पृष्ठ पर फिट होना चाहिए: पोस्टग्रैसक्यूएल अगले पृष्ठ पर लाइन को "जारी" रखने का एक तरीका प्रदान नहीं करता है। इसके बजाय, TOAST (The Oversized Attributes Storage Technique) नामक तकनीक का उपयोग किया जाता है। नाम से ही पता चलता है कि स्ट्रिंग को टोस्ट में काटा जा सकता है।
गंभीरता से बोलते हुए, टोस्ट में कई रणनीतियाँ शामिल हैं। "लंबी" विशेषता मानों को एक अलग सेवा तालिका में भेजा जा सकता है, जो पहले टोस्ट के छोटे टुकड़ों में काटा जाता है। एक अन्य विकल्प मूल्य को संपीड़ित करना है ताकि पंक्ति का संस्करण अभी भी एक नियमित टेबल पेज पर फिट हो। और यह दोनों संभव है, और दूसरा: पहले से संपीड़ित करने के लिए, और उसके बाद ही कटौती और भेजने के लिए।
प्रत्येक मुख्य तालिका के लिए, यदि आवश्यक हो, एक अलग, लेकिन सभी विशेषताओं के लिए, टोस्ट तालिका (और इसके लिए एक विशेष सूचकांक) बनाई जाती है। आवश्यकता तालिका में संभावित लंबी विशेषताओं की उपस्थिति से निर्धारित होती है। उदाहरण के लिए, यदि किसी तालिका में टाइप न्यूमेरिक या टेक्स्ट का कॉलम है, तो एक TOAST तालिका तुरंत बनाई जाएगी, भले ही लंबे मानों का उपयोग न किया गया हो।
चूंकि टोस्ट टेबल अनिवार्य रूप से एक नियमित टेबल है, इसलिए इसमें अभी भी परतों का एक ही सेट है। और यह उन फ़ाइलों की संख्या को दोगुना करता है जो टेबल की "सेवा" करती हैं।
प्रारंभ में, रणनीतियों को स्तंभ डेटा प्रकारों द्वारा निर्धारित किया जाता है। आप उन्हें psql में
\d+ कमांड के साथ देख सकते हैं, लेकिन चूंकि यह बहुत अधिक अन्य जानकारी प्रदर्शित करता है, हम सिस्टम निर्देशिका के अनुरोध का उपयोग करेंगे:
=> SELECT attname, atttypid::regtype, CASE attstorage WHEN 'p' THEN 'plain' WHEN 'e' THEN 'external' WHEN 'm' THEN 'main' WHEN 'x' THEN 'extended' END AS storage FROM pg_attribute WHERE attrelid = 'accounts'::regclass AND attnum > 0;
attname | atttypid | storage ---------+----------+---------- id | integer | plain number | text | extended client | text | extended amount | numeric | main (4 rows)
रणनीतियों के नामों के निम्नलिखित अर्थ हैं:
- सादे - टोस्ट का उपयोग नहीं किया जाता है (स्पष्ट रूप से "शॉर्ट" डेटा प्रकारों के लिए उपयोग किया जाता है, जैसे पूर्णांक);
- विस्तारित - एक अलग टोस्ट तालिका में संपीड़न और भंडारण दोनों की अनुमति है;
- बाहरी - लंबे मान TOAST तालिका में संग्रहीत किए जाते हैं;
- मुख्य - लंबे मान पहले और केवल टोस्ट तालिका में संपीड़ित होते हैं यदि संपीड़न मदद नहीं करता है।
सामान्य शब्दों में, एल्गोरिथ्म इस प्रकार है। PostgreSQL कम से कम 4 लाइनों को एक पृष्ठ पर फिट करना चाहता है। इसलिए, यदि पंक्ति का आकार पृष्ठ के चौथे भाग से अधिक हो जाता है, तो शीर्षक को ध्यान में रखते हुए (सामान्य 8K पृष्ठ के साथ यह 2040 बाइट्स होता है), TOAST को मूल्यों के भाग पर लागू किया जाना चाहिए। हम नीचे बताए गए क्रम में कार्य करते हैं और जैसे ही लाइन थ्रेशोल्ड को पार करना बंद करते हैं:
- सबसे पहले, हम बाहरी और विस्तारित रणनीतियों के साथ विशेषताओं के माध्यम से सॉर्ट करते हैं, सबसे लंबे समय तक छोटे से आगे बढ़ते हैं। विस्तारित विशेषताएँ संपीड़ित होती हैं (यदि इसका प्रभाव होता है) और, यदि मान स्वयं पृष्ठ के एक चौथाई से अधिक है, तो इसे तुरंत TOAST तालिका में भेज दिया जाता है। बाहरी विशेषताओं को उसी तरह से संभाला जाता है, लेकिन संकुचित नहीं किया जाता है।
- यदि पहली पंक्ति के बाद का संस्करण अभी भी फिट नहीं होता है, तो हम बाहरी और विस्तारित रणनीतियों के साथ शेष विशेषताओं को टोस्ट टेबल पर भेजते हैं।
- यदि यह भी मदद नहीं करता है, तो मुख्य रणनीति के साथ विशेषताओं को संपीड़ित करने का प्रयास करें, जबकि उन्हें तालिका पृष्ठ में छोड़ दें।
- और इसके बाद ही यदि पंक्ति अभी भी कम नहीं है, तो मुख्य विशेषताओं को टोस्ट तालिका में भेज दिया जाता है।
कभी-कभी यह कुछ कॉलमों के लिए रणनीति बदलने के लिए उपयोगी हो सकता है। उदाहरण के लिए, यदि यह पहले से ज्ञात है कि कॉलम में डेटा संपीड़ित नहीं है, तो आप इसके लिए एक बाहरी रणनीति निर्धारित कर सकते हैं - यह बेकार संपीड़न प्रयासों को बचाएगा। यह निम्नानुसार किया जाता है:
=> ALTER TABLE accounts ALTER COLUMN number SET STORAGE external;
अनुरोध को दोहराते हुए, हम प्राप्त करते हैं:
attname | atttypid | storage ---------+----------+---------- id | integer | plain number | text | external client | text | extended amount | numeric | main
टोस्ट टेबल और इंडेक्स एक अलग pg_toast स्कीमा में स्थित हैं और इसलिए आमतौर पर दिखाई नहीं देते हैं। अस्थायी तालिकाओं के लिए, pg_toast_temp_
N योजना का उपयोग किया जाता है, सामान्य pg_temp_
N के समान
।बेशक, अगर वांछित है, तो कोई भी प्रक्रिया के आंतरिक यांत्रिकी में झांकने के लिए परेशान नहीं करता है। कहते हैं कि लेखा तालिका में तीन संभावित लंबी विशेषताएँ होती हैं, इसलिए एक टोस्ट तालिका होनी चाहिए। यहाँ यह है:
=> SELECT relnamespace::regnamespace, relname FROM pg_class WHERE oid = ( SELECT reltoastrelid FROM pg_class WHERE relname = 'accounts' );
relnamespace | relname --------------+---------------- pg_toast | pg_toast_33953 (1 row)
=> \d+ pg_toast.pg_toast_33953
TOAST table "pg_toast.pg_toast_33953" Column | Type | Storage ------------+---------+--------- chunk_id | oid | plain chunk_seq | integer | plain chunk_data | bytea | plain
यह तर्कसंगत है कि "टोस्ट्स" के लिए जिसमें लाइन को कटा हुआ है, सादा रणनीति लागू की जाती है: दूसरे स्तर का टोस्ट मौजूद नहीं है।
PostgreSQL सूचकांक अधिक सावधानी से छुपाता है, लेकिन इसे ढूंढना भी आसान है:
=> SELECT indexrelid::regclass FROM pg_index WHERE indrelid = ( SELECT oid FROM pg_class WHERE relname = 'pg_toast_33953' );
indexrelid ------------------------------- pg_toast.pg_toast_33953_index (1 row)
=> \d pg_toast.pg_toast_33953_index
Unlogged index "pg_toast.pg_toast_33953_index" Column | Type | Key? | Definition -----------+---------+------+------------ chunk_id | oid | yes | chunk_id chunk_seq | integer | yes | chunk_seq primary key, btree, for table "pg_toast.pg_toast_33953"
क्लाइंट कॉलम विस्तारित रणनीति का उपयोग करता है: इसमें मूल्य संपीड़ित होंगे। की जाँच करें:
=> UPDATE accounts SET client = repeat('A',3000) WHERE id = 1; => SELECT * FROM pg_toast.pg_toast_33953;
chunk_id | chunk_seq | chunk_data ----------+-----------+------------ (0 rows)
टोस्ट टेबल में कुछ भी नहीं है: दोहराए जाने वाले वर्ण पूरी तरह से संपीड़ित हैं और उसके बाद मूल्य एक नियमित टेबल पेज में फिट बैठता है।
अब ग्राहक का नाम यादृच्छिक वर्णों से मिलकर बनता है:
=> UPDATE accounts SET client = ( SELECT string_agg( chr(trunc(65+random()*26)::integer), '') FROM generate_series(1,3000) ) WHERE id = 1 RETURNING left(client,10) || '...' || right(client,10);
?column? ------------------------- TCKGKZZSLI...RHQIOLWRRX (1 row)
यह क्रम संकुचित नहीं किया जा सकता है, और यह टोस्ट तालिका में आता है:
=> SELECT chunk_id, chunk_seq, length(chunk_data), left(encode(chunk_data,'escape')::text, 10) || '...' || right(encode(chunk_data,'escape')::text, 10) FROM pg_toast.pg_toast_33953;
chunk_id | chunk_seq | length | ?column? ----------+-----------+--------+------------------------- 34000 | 0 | 2000 | TCKGKZZSLI...ZIPFLOXDIW 34000 | 1 | 1000 | DDXNNBQQYH...RHQIOLWRRX (2 rows)
जैसा कि आप देख सकते हैं, डेटा 2000 बाइट्स के टुकड़ों में कट जाता है।
"लंबे" मान तक पहुंचने पर, PostgreSQL स्वचालित रूप से, आवेदन के लिए पारदर्शी, मूल मूल्य को पुनर्स्थापित करता है और इसे क्लाइंट को लौटाता है।
बेशक, कटा हुआ संपीड़न और बाद में वसूली पर काफी संसाधन खर्च किए जाते हैं। इसलिए, PostgreSQL में वॉल्यूमिनस डेटा को संग्रहीत करना एक अच्छा विचार नहीं है, खासकर यदि यह सक्रिय रूप से उपयोग किया जाता है और उनके लिए लेनदेन संबंधी तर्क की आवश्यकता नहीं है (उदाहरण के लिए: लेखांकन दस्तावेजों के स्कैन किए गए मूल)। एक अधिक लाभदायक विकल्प फाइल सिस्टम पर इस तरह के डेटा को संग्रहीत कर सकता है, और डीबीएमएस में, संबंधित फाइलों के नाम।
एक TOAST तालिका का उपयोग केवल "लंबे" मान के लिए किया जाता है। इसके अलावा, टोस्ट टेबल का अपना संस्करण है: यदि डेटा अपडेट "लंबे" मूल्य को प्रभावित नहीं करता है, तो पंक्ति का नया संस्करण TOAST तालिका में समान मूल्य को संदर्भित करेगा - यह स्थान बचाता है।
ध्यान दें कि TOAST केवल तालिकाओं के लिए काम करता है, लेकिन अनुक्रमित के लिए नहीं। यह अनुक्रमित कुंजी के आकार पर एक सीमा लगाता है।
आप दस्तावेज़ में आंतरिक डेटा संगठन के बारे में अधिक पढ़ सकते हैं।
जारी रखा जाए ।